神级外挂 | 网络性能优化,2个补丁就足够
随着单核 CPU 速度已经达到极限, CPU 已向多核方向发展,甚至可以达到十几核、几十核,而网卡硬件队列则才 4 个、 8 个,这种发展的不匹配造成了 CPU 负载的不均衡。比如过多的网卡收包和发包中断集中在一个 CPU 上,在系统繁忙时, CPU 对网卡的中断无法响应,导致了服务器端的网络性能降低。
而要想持续提高网络处理带宽,传统的提升硬件设备、智能处理处理办法已不足够。因此有工程师提出了 RPS/RFS 两个补丁,来解决这个问题。

以一个具有 8 核 CPU 和一个普通 NIC 连接在网络中的主机来说,对于由该主机产生并通过 NIC 发送到网络中的数据, CPU 核的并行性是自然而然的事情:
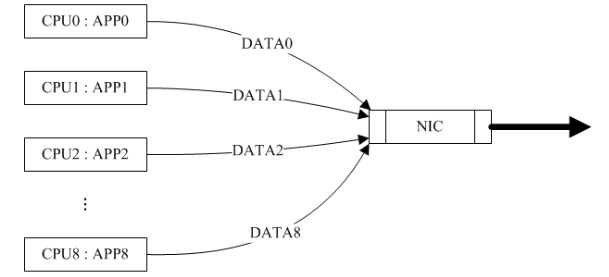
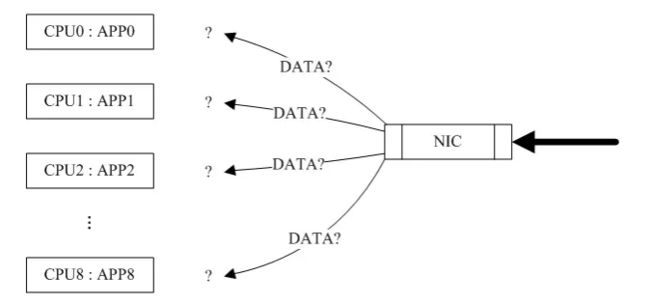
问题主要在于当该主机通过 NIC 收到从网络发往本机的数据包时,产生中断后应该将数据包分发给哪个 CPU 核来处理(有些具有多条接收队列和多重中断线路的 NIC 可以帮助数据包并行分发,这里考虑普通的 NIC ,普通的 NIC 通过 RPS 来模拟实现并行分发):
使用基于简单的中断负载均衡(如系统自带的 irqbalance 进程),通过设置 /proc/irq/smp_affinity ,可以设置中断的亲和性。在用户态也有 irqbalance 来根据系统各 CPU 的实时情况来设置亲和性,从而达到中断的负载均衡。
但是 irqbalance 虽能够利用多核计算特性, 但是显而易见的 cache 利用率非常低效。因为其并不识别网络流,只识别到这是一个数据包,不能识别到数据包的元组信息。如果一个数据流的第一个数据包被分发到了 CPU1 ,而第二个数据包分发到了 CPU2 ,那么对于流的公共数据,比如 nf_conntrack 中记录的东西,CPU cache的利用率就会比较低。且 CPU 的 cache 需要保持一致性,即如果其中一个 CPU 修改了自己的 CPU cache ,它就必须判断该数据是否包含在其它 CPU 的 cache 中,如果存在,必须通知其它 CPU 更新其 cache ,而这样会导致 CPU cache 的刷新频率变高;
另外 TCP 的 IP 包的分段重组问题,一旦乱序就要重传,一个 linux 主机如果只是作为一台路由器的话,那么进入系统的一个 TCP 包的不同分段如果被不同的 CPU 处理并向一个网卡转发了,那么同步问题会很麻烦,如果不做同步处理,那么很可能后面的段被一个 CPU 先发出去了,那最后接收方接收到乱序的包后就会请求重发,这样则还不如是一个 CPU 串行处理。
而以上这些问题都可以通过 RPS/RFS 解决,那么, RPS/RFS 究竟是什么呢?

RPS 全称是 Receive Packet Steering , 这是 Google 工程师 Tom Herbert 提交的内核补丁, 在 2.6.35 进入 Linux 内核. 这个 patch 采用软件模拟的方式,实现了多队列网卡所提供的功能,分散了在多 CPU 系统上数据接收时的负载, 把软中断分到各个 CPU 处理,而不需要硬件支持,大大提高了网络性能。
RPS 实现了数据流的 hash 归类,它通过数据包相关的信息(比如 IP 地址和端口号)来创建 CPU 核分配的 hash 表项,当一个数据包从 NIC 转到内核网络子系统时就从该 hash 表内获取其对应分配的 CPU 核(首次会创建表项)。并把软中断的负载均衡分到各个 CPU ,实现了类似多队列网卡的功能。
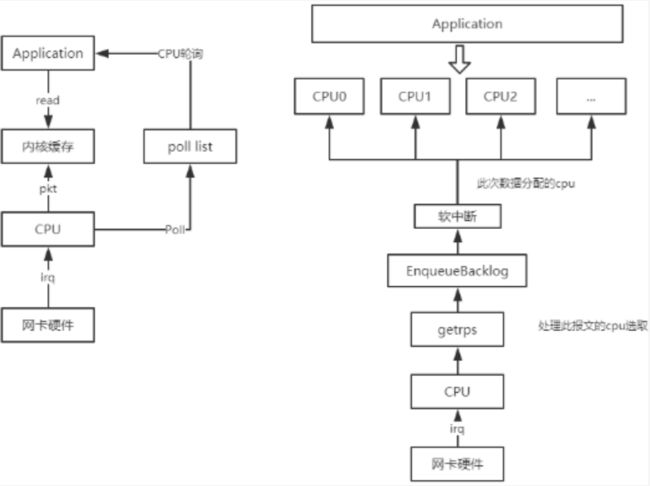
从上面流程图中可以看出,相比传统的中断 CPU 去处理数据包,现变为中断 CPU 将数据存入 backlog ,等待 rps 实现的软中断自行分配到映射到的 CPU 处理,进而交付给报文所属 app 正在运行的 CPU 处理。

配置如下参数即可启用 RPS 功能:
● echo ff > /sys/class/net/queues/rx-*/rps_cpus
● echo 4096 > /sys/class/net/queues/rx-*/rps_flow_cnt
8 核的机器为 ff ,具体计算方法是第以个 CPU 是 00000001 ,第二个 CPU 是 00000010 ,第三个 CPU 是 00000100 。设置为 0 则表示不支持此功能。
rps_flow_cnt 就是 RFS ,表示当前网络设备 RPS 队列的流表数,需要设置为 2 的整数次幂,建议设置为 4096 。数值越大,同时所能处理的 RPS 流越多。

由于 RPS 只是单纯的把同一流的数据包分发给同一个 CPU 核来处理了,但是有可能出现这样的情况,即给该数据流分发的 CPU 核和执行处理该数据流的应用程序的 CPU 核不是同一个(即:数据包均衡到不同的 CPU ),这个时候如果应用程序所在的 CPU 和软中断处理的 CPU 不是同一个,此时对于 CPU cache 的影响会很大。
换句话说, RFS 是用来配合 RPS 补丁使用的,是 RPS 补丁的扩展补丁,它可以把接收的数据包送达应用所在的 CPU 上,提高 cache 的命中率。因此,这两个补丁往往都会同时进行设置,以达到最好的优化效果。
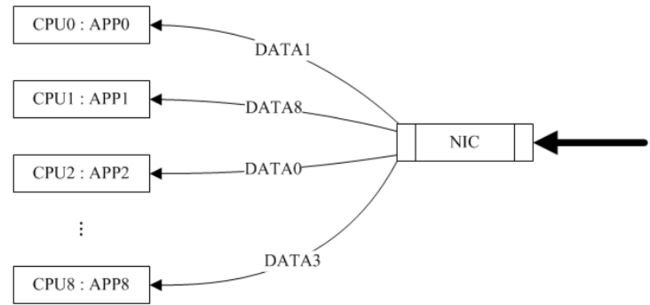
RFS 不仅要把同一流的数据包分发给同一个 CPU 核来处理,还要分发给其‘被期望’的 CPU 核来处理就是 RFS 需要解决的问题。

RFS 会创建两个与数据包相关信息(比如 IP 地址和端口号)的 CPU 核映射 hash 表:
-
期望 CPU 表:
用于表示期望处理具有该类相关信息数据包的CPU核映射。通过 recvmsg() 或 sendmsg() 等系统调用信息来创建该 hash 表。
比如运行于 CPU0 核上的某应用程序调用了 recvmsg() 从远程机器 host1 上获取数据,那么 NIC 对从 host1 上发过来的数据包的分发期望 CPU 核就是 CPU0 。
-
当前 CPU 表:
用于表示最近处理过具有该类相关信息数据包的 CPU 核映射。
该表的存在是因为有多线程的情况,比如运行在两个 CPU 核上的多线程程序(每个核运行一个线程)交替调用 recvmsg() 系统函数从同一个 socket 上获取远程机器 host1 上的数据会导致期望 CPU 表频繁更改。
如果数据包的分发仅由期望 CPU 表决定则会导致数据包交替分发到这两个 CPU 核上,很明显,这不是我们想要的效果。那么怎么解决这个问题呢?
既然 CPU 核的分配由两个 hash 表值决定,那么就可以有一个算法来描述这个决定过程:

如果当前 CPU 表对应表项未设置或者当前 CPU 表对应表项映射的 CPU 核处于离线状态,那么使用期望 CPU 表对应表项映射的 CPU 核。
如果当前 CPU 表对应表项映射的 CPU 核和期望 CPU 表对应表项映射的 CPU 核为同一个,那么好办,就使用这一个核。
如果当前 CPU 表对应表项映射的 CPU 核和期望 CPU 表对应表项映射的 CPU 核不为同一个,那么:
-
如果同一流的前一段数据包未处理完,那么必须使用当前 CPU 表对应表项映射的 CPU 核,以避免乱序。
-
如果同一流的前一段数据包已经处理完,那么则可以使用期望 CPU 表对应表项映射的 CPU 核。
算法的前两步比较好理解,而对于第三步可以用下面两个图来帮助理解。
应用程序 APP0 有两个线程 THD0 和 THD1 分别运行在 CPU0 核和 CPU1 核上,同时 CPU1 核上还运行有应用程序 APP1 。首先 THD1 调用 recvmsg() 获取远程数据(数据流称之为 FLOW0 ),此时 FLOW0 的期望 CPU 核为 CPU1 ,随着数据块 FLOW0 : 0 的到来并交给 CPU1 核处理,此时 FLOW0 的当前 CPU 核也为 CPU1 。如果此时 THD0 也在同一个 socket 上调用 recvmsg() 获取远程数据(数据流同样也是 FLOW0 ),那么 FLOW0 的期望 CPU 核就改变为 CPU0 (当前 CPU 核仍然为 CPU1 )。与此同时, NIC 收到数据块 FLOW0 : 1 ,如何将该数据块分发给 CPU 核就到了上面算法的第三步。
此时我们可以结合实际情况进行判断:
如果同一流的前一段数据包 FLOW0 : 0 未处理完,那么必须使用当前 CPU 核 CPU1 来处理新到达的数据块,以避免乱序。如下图所示( FLOW1 流是应用程序 APP1 的):
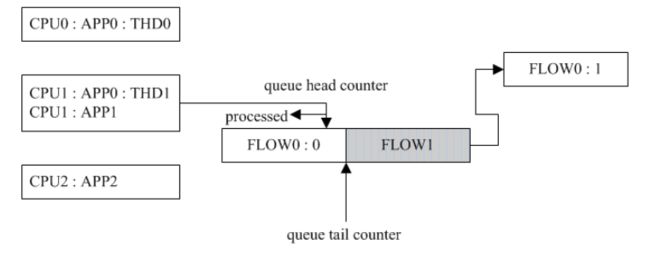
如果同一流的前一段数据包 FLOW0 : 0 已经处理完毕,那么可以使用期望CPU核 CPU0 来处理新到达的数据块。如下图所示( FLOW1 流是应用程序 APP1 的):
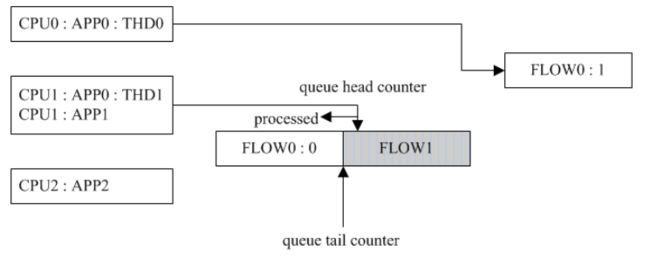

-
/proc/sys/net/core/rps_sock_flow_entries:
指定并发活动连接的最大预期数量。对于中等服务器负载,建议使用 32768 。在实践中,所有输入的值都被四舍五入到最接近的 2 次方。
-
/sys/class/net/device/queues/rx-queue/rps_flow_cnt:
它的值为 rps_sock_flow_entries 的值除以接收队列的数量。例如,如果 rps_flow_ 条目设置为 32768 ,并且有 16 个配置的接收队列,则 rps_flow_cnt 应设置为 2048 。对于单队列设备, rps_flow_cnt 的值与 rps_sock_flow_ 条目的值相同。

总的来说,网络 RPS 和 RFS 可在高负载网络环境中提供更好的性能和扩展性。通过合理配置和优化这些功能,我们可以充分利用多核系统的计算能力,提高网络应用的响应速度和吞吐量,以提高设备的响应速度,给用户更流程的操作体验。
在配置 RPS 和 RFS 的过程中,应该根据具体的系统和网络环境随时进行调整。在实际应用中,我们更需要根据系统负载、网络流量和硬件配置等因素进行实验和调优,以找到最佳的配置参数和策略,才可以实现更好的性能优化。