Python网络爬虫入门
Python网络爬虫入门
网络爬虫(web crawler),也叫网络蜘蛛(Web Spider)、网络机器人(Internet Bot)。简单地说,抓取万维网(World Wide Web)上所需要的数据(对于我们有价值的信息)的程序就叫网络爬虫。
网络爬虫常见分类:
通用网络爬虫(General Purpose Web Crawler)又称全网爬虫(Scalable Web Crawler)爬行对象从一些种子 URL 扩充到整个 Web,主要为门户站点搜索引擎和大型 Web 服务提供商采集数据。这类网络爬虫的爬行范围和数量巨大,对于爬行速度和存储空间要求较高,由于商业原因,它们的技术细节很少公布出来,不是本文关注的。
聚焦网络爬虫(Focused Web Crawler)又称主题网络爬虫(Topical Crawler),聚焦爬虫并不追求大的覆盖,而将目标定为抓取与某一特定主题内容相关的网页,为面向主题的用户查询准备数据资源。这是本文关注的,本文介绍使用Python 实现这类爬虫的入门技术。
【网络爬虫及分类的更多情况,可参见 网络爬虫_百度百科 】
特别说明,本文不涉及爬虫合法性问题,仅从技术实验出发,但为慎重起见,建议设计的爬虫应当约束自己的抓取资料及使用方式,应需要考虑限定在一个合理值之内。
爬虫技术这个主题知识点很多全面掌握比较难,网络爬虫涉及的一些技术:
Web前端的知识;
正则表达式,能提取正常一般网页中想要的信息;
熟悉HTTP,HTTPS协议的基础知识;
一些开源框架Scrapy;
知道什么是深度优先,广度优先的抓取算法,及实践中的使用规则;
常用的数据库进行数据查询存储;
并发下载,通过并行下载加速数据抓取;多线程的使用;
作为入门尝试,在此不可能涉及这么多,本文将介绍一些我认为应当掌握的入门技术。想要入门Python 爬虫首先需要如下基本知识:
熟悉python编程
了解web技术
了解网络爬虫的基本原理
学习使用python爬虫库
下面介绍在Windows 10中使用Python 实现聚焦网络爬虫(主题网络爬虫)入门技术。
爬虫处理过程大致可以分为:发送请求——>获得页面——>解析页面——>抽取并储存内容。这也是我们用浏览器访问网页的过程。爬虫就是一个探测机器,它模拟人的行为去访问各个网站,拿到有用的信息。我们每天使用最多的百度,就是利用了爬虫技术,每天爬取大量网站信息用于用户的搜索和展示。
爬虫三要素
抓取: 爬虫向网站发送一个请求,获取到目标网页源代码,从中获取有价值的信息。Python中urllib库、requests库可帮助我们实现HTTP请求操作。
分析: 对获取的数据进行分析提取有价值的信息,提取信息常用到正则表达式。还可根据网页节点属性、CSS选择器或XPath来提取网页信息的库,如Beautiful Soup、pyquery、lxml等。
存储: 分析提取信息后,需进行存储,数据保存形式有TXT、JSON,还可以保存到MySQL和MongoDB中。
基础爬虫的架构以及运行流程简略框图
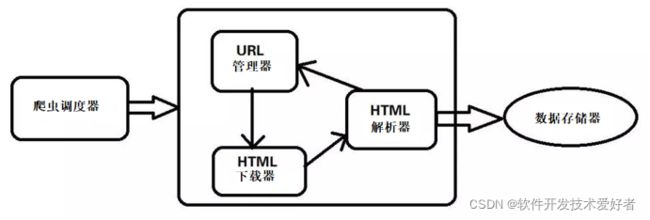
下面给大家依次来介绍一下这5个大类的功能:
1. 爬虫调度器:主要是配合调用其他四个模块,所谓调度就是取调用其他的模板。
2. URL管理器:就是负责管理URL链接的,URL链接分为已经爬取的和未爬取的,这就需要URL管理器来管理它们,同时它也为获取新URL链接提供接口。
3. HTML下载器:就是将要爬取的页面的HTML下载下来。
4. HTML解析器:就是将要爬取的数据从HTML源码中获取出来,同时也将新的URL链接发送给URL管理器以及将处理后的数据发送给数据存储器。
5.数据存储器:就是将HTML下载器发送过来的数据存储到本地。
在Python3中,可以使用相关的库进行网页爬取:
urllib库是python内置的,无需我们额外安装,只要安装了Python就可以使用这个库。但用起来比较麻烦,缺少很多实用的高级功能。
requests库是第三方库,需要我们自己安装。
beautifulsoup4(BS4) 是第三方库,解析,遍历,维护“标签树”代码的功能库。
scrapy 框架
urllib库
python内置库urllib,官方文档urllib --- URL 处理模块 — Python 3.10.1 文档
urllib 是一个收集了多个涉及 URL 的模块的包(package),包括下列模块(module):
urllib.request 打开和读取 URL
urllib.error 包含 urllib.request 抛出的异常
urllib.parse 用于解析 URL
urllib.robotparser 用于解析 robots.txt 文件
urllib.request 模块(module)的 urlopen 函数来打开一个 URL,语法格式如下:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
url:url 地址。
data:发送到服务器的其他数据对象,默认为 None。
timeout:设置访问超时时间。
特别提示:3.6 版后已移除: cafile 、 capath 和 cadefault,转而推荐使用 context。请改用 ssl.SSLContext.load_cert_chain() 或让 ssl.create_default_context() 选取系统信任的 CA 证书。
context:ssl.SSLContext类型,用来指定 SSL 设置。
urlopen 返回一个类文件对象,并提供了如下方法:
read() , readline() , readlines() , fileno() , close() :这些方法的使用方式与文件对象完全一样; info():返回一个httplib.HTTPMessage对象,表示远程服务器返回的头信息;可以通过Quick Reference to Http Headers查看 Http Header 列表。 getcode():返回Http状态码。如果是http请求,200表示请求成功完成;404表示网址未找到; geturl():返回获取页面的真实 URL。在 urlopen(或 opener 对象)可能带一个重定向时,此方法很有帮助。获取的页面 URL 不一定跟真实请求的 URL 相同。
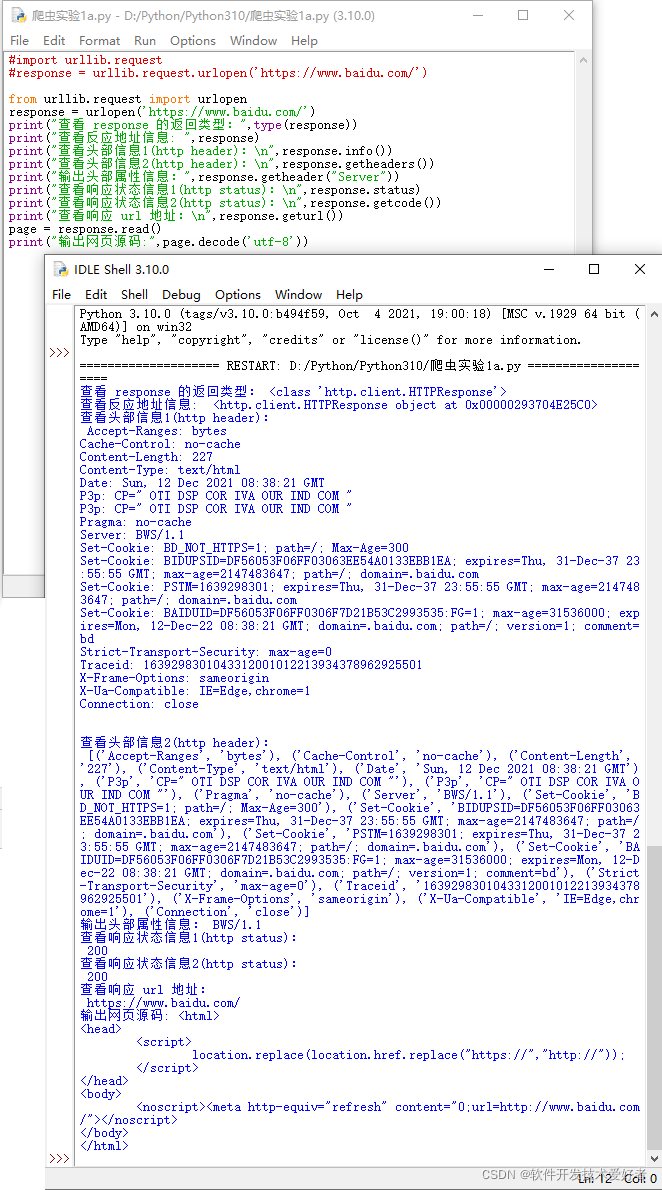
例、源码如下:
#import urllib.request
#response = urllib.request.urlopen('https://www.baidu.com/')
from urllib.request import urlopen
response = urlopen('https://www.baidu.com/')
print("查看 response 的返回类型:",type(response))
print("查看反应地址信息: ",response)
print("查看头部信息1(http header):\n",response.info())
print("查看头部信息2(http header):\n",response.getheaders())
print("输出头部属性信息:",response.getheader("Server"))
print("查看响应状态信息1(http status):\n",response.status)
print("查看响应状态信息2(http status):\n",response.getcode())
print("查看响应 url 地址:\n",response.geturl())
page = response.read()
print("输出网页源码:",page.decode('utf-8'))
运行效果如下图:
关于urllib库的request模块更多情况可参见:python3中urllib库的request模块详解python3中urllib库的request模块详解 - lincappu - 博客园
Requests库
requests库强大好用,所以本文使用requests库获取网页的HTML信息。requests库的github地址:GitHub - psf/requests: A simple, yet elegant, HTTP library.
requests库的开发者为我们提供了详细的中文教程,官方中文教程地址:
快速上手 — Requests 2.18.1 文档
(1)requests安装
在学习使用requests库之前,我们需要在电脑中安装好requests库。在cmd中,使用如下指令安装requests库:
pip install requests
测试:
(2)requests库的基础方法
Requests库的7个主要方法
方法 说明
requests.request() 构造一个请求,支撑一下个方法的基础方法。
requests.get() 获取HTML网页的主要方法,对应HTTP的GET
requests.head() 获取HTML网页投信息的方法,对应HTTP的HEAD
requests.post() 向HTML网页提交POST请求的方法,对应HTTP的POST
requests.put() 向HTML网页提交PUT请求的方法,对应HTTP的PUT
requests.patch() 向HTML网页提交局部修改请求,对应HTTP的PATCH
requests.delete() 向HTML网页提交删除请求,对应HTTP的DELETE
首先,让我们看下requests.get()方法,它用于向服务器发起GET请求,不了解GET请求没有关系。我们可以这样理解:get的中文意思是得到、抓住,那这个requests.get()方法就是从服务器得到、抓住数据,也就是获取数据。
requests.request(method,url,**kwargs)
method:请求方式,对应get/put/post等7种
url:获取页面的url链接
**kwargs:控制访问的参数,均为可选项,共13个
params:字典或字节系列,作为参数增加到url中
requests库的使用
安装requests库,打开cmd输入:
pip install requests
若你的电脑上,安装了多个版本的python,想为指定版本如-3.10安装requests
py -3.10 -m pip install requests
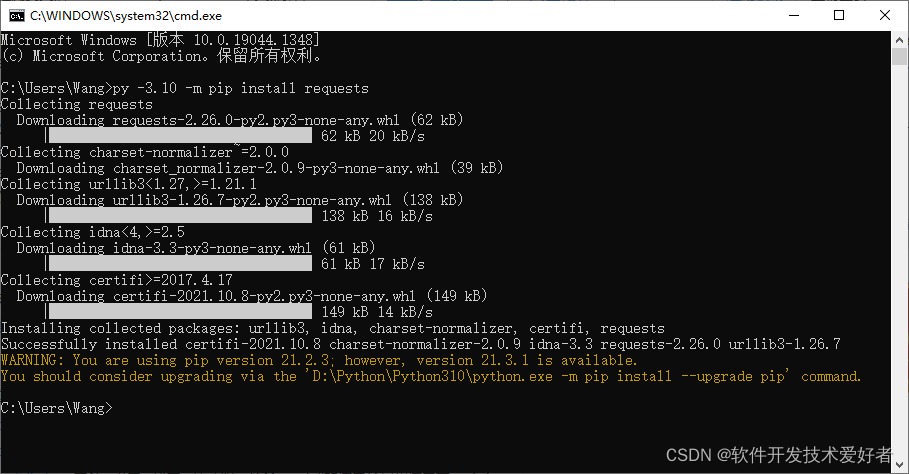
【我的计算机中安装了多个版本的python,在此为版本-3.10安装requests
Successfully installed(已成功安装)
最后有一条警告,大意是:pip版本有新版本可用,您cmd中输入"D:\Python\Python310\python.exe -m pip install --upgrade pip"升级。可以不用管。】
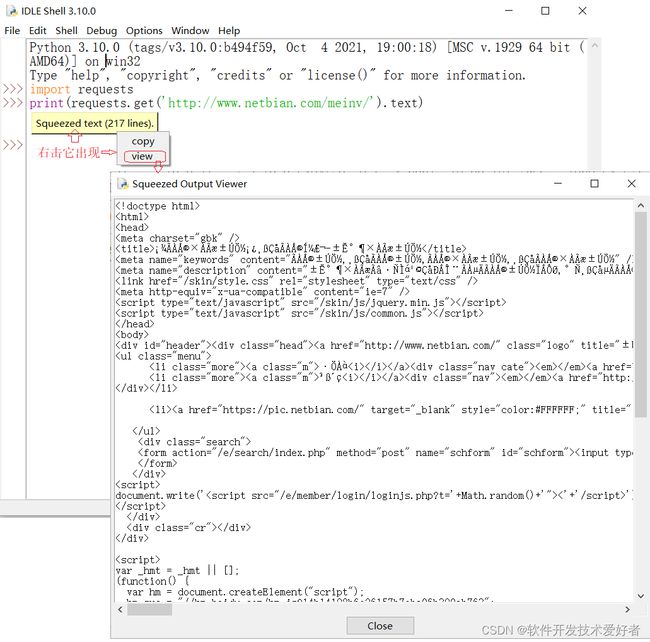
例1、使用requests 库,最简单的爬虫示例,两行代码:
import requests
print(requests.get('http://www.netbian.com/meinv/').text)
因为代码不长,可以在IDLE Shell中实验,参见下图:
例2、一个简单的例子,目标:到网站 http://www.netbian.com/meinv/,找到其中一张图片地址下载之。
用浏览器打开上述网站,找到合适页面,再参见下图,如此操作:按下F12键(打开开发者工具),在“元素”选项页中,单击“元素检查工具”后再单击你要选的图片,可以找到图片地址,可双击选中复制之:"http://img.netbian.com/file/2021/1025/small4f9ea5c08763bc2de22b043cf83d1c241635130725.jpg"

下载该图片的源码如下 :
import requests
import os
url = "http://img.netbian.com/file/2021/1025/small4f9ea5c08763bc2de22b043cf83d1c241635130725.jpg"
dir = "D:\\pics\\" #图片保存路径
path = dir + url.split('/')[-1] #设置图片保存路径并以原图名名字命名
try:
if not os.path.exists(dir):
os.mkdir(dir)
if not os.path.exists(path):
r = requests.get(url)
with open(path,'wb') as f:
f.write(r.content)
f.close()
print("文件保存成功")
else:
print("文件已存在")
except IOError as e:
print(str(e))
在D:\pics文件夹中可以看到图片已下载

requests库一般与BeautifulSoup库搭配使用。BeautifulSoup是Python里的第三方库,处理数据十分实用,有了这个库,我们就可以根据网页源代码里对应的HTML标签对数据进行有目的性的提取。BeautifulSoup库一般与requests库搭配使用。
BeautifulSoup库
BeautifulSoup库因为其易用性并且非常适合初学者,所以可以说是当前Web爬取中使用最广泛的Python库。BeautifulSoup创建了一个解析树,用于解析HTML和XML文档。BeautifulSoup会自动将输入文档转换为Unicode,将输出文档转换为UTF-8。我们可以将BeautifulSoup与其他解析器(如lxml)结合使用,可以应对设计欠佳的HTML。
官网Beautiful Soup Documentation — Beautiful Soup 4.9.0 documentation
中文 Beautiful Soup 4.2.0 文档 — Beautiful Soup 4.2.0 documentation
使用BeautifulSoup()函数创建一个对象。该对象是一个树形结构,它包含HTML页面中的每一个Tag(标签)元素,如
、等也作为子对象。然后可用find()和find_all()函数按照条件返回标签内容。find() 返回第一个符合要求的数据
find_all() 返回所有符合要求的数据
BeautifulSoup(简写BS)库,是第三方库,需要我们自己安装:
打开cmd输入:
pip install beautifulsoup4
若你的电脑上,安装了多个版本的python,想为指定版本如-3.10安装requests
py -3.10 -m pip install beautifulsoup4
参见下图:
【我的计算机中安装了多个版本的python,在此为版本-3.10安装requests
其中Successfully installed(已成功安装)
最后有一条警告,大意是:pip版本有新版本可用,您cmd中输入"D:\Python\Python310\python.exe -m pip install --upgrade pip"升级。可以不用管。】
在使用BS时需要指定一个“解析器”(利用它方便抓取网页特定内容,而不必使用正则表达式):
html.parse- python 自带,但容错性不够高,对于一些写得不太规范的网页会丢失部分内容。
lxml- 解析速度快,需要安装。
html5lib- 最好的容错性,但速度稍慢,需要安装。
解析器使用方法:
| 解析器 |
使用方法 |
| Python标准库 |
BeautifulSoup(markup, "html.parser") |
| lxml HTML 解析器 |
BeautifulSoup(markup, "lxml") |
| html5lib |
BeautifulSoup(markup, "html5lib") |
lxml库
lxml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据。
文档:lxml - Processing XML and HTML with Python
中文文档 lxml 中文文档_w3cschool
安装lxml(lxml HTML 解析器):
打开cmd输入:
pip install lxml
若你的电脑上,安装了多个版本的python,想为指定版本如-3.10安装requests
py -3.10 -m pip install lxml
参见下图:
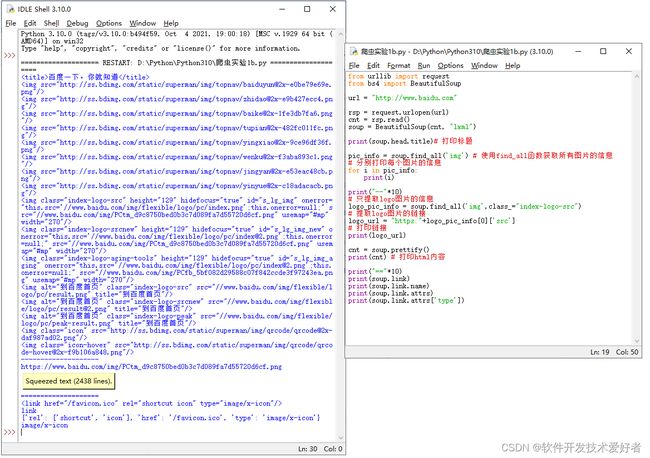
例、这里尝试获取百度首页“https://www.baidu.com/”的HTML内容,利用urllib.request 模块(module)的 urlopen 函数和BS、lxml HTML 解析器,源码如下:
from urllib import request
from bs4 import BeautifulSoup
url = "http://www.baidu.com"
rsp = request.urlopen(url)
cnt = rsp.read()
soup = BeautifulSoup(cnt, "lxml")
print(soup.head.title)# 打印标题
pic_info = soup.find_all('img') # 使用find_all函数获取所有图片的信息
# 分别打印每个图片的信息
for i in pic_info:
print(i)
print("--"*10)
# 只提取logo图片的信息
logo_pic_info = soup.find_all('img',class_="index-logo-src")
# 提取logo图片的链接
logo_url = "https:"+logo_pic_info[0]['src']
# 打印链接
print(logo_url)
cnt = soup.prettify()
print(cnt) # 打印html内容
print("=="*10)
print(soup.link)
print(soup.link.name)
print(soup.link.attrs)
print(soup.link.attrs['type'])
运行效果如下图:
Scrapy框架
Scrapy 是一种快速的高级 web crawling 和 web scraping 框架,用于对网站进行爬网并从其页面提取结构化数据。Scrapy最大的优点是非阻塞(又名异步)爬取,它可以同时发出多个HTTP请求,所以,爬取效率很高。它有广泛的用途,从数据挖掘到监控和自动化测试。
源码管理地址 GitHub - scrapy/scrapy: Scrapy, a fast high-level web crawling & scraping framework for Python.
官网文档Scrapy 2.5 documentation — Scrapy 2.5.1 documentation
中文文档Scrapy 2.5 documentation — Scrapy 2.5.0 文档
基于Scrapy的爬虫解决方案基于Scrapy的爬虫解决方案
(待续)