Python爬虫获取网页数据笔记(一)
一、涉及的Python库
requests:获取网页源代码
BeautifulSoup:从网页中抓取数据
xlwt:导出表格
(一)requests
1.requests库文档:
requests库文档链接
2.request库的常用方法:
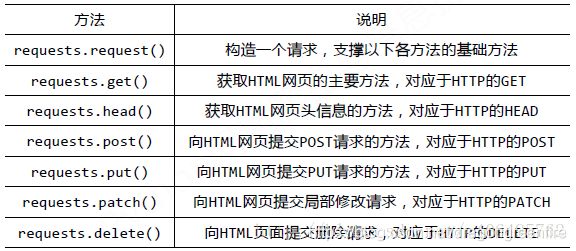
3.编写代码
#导入requests模块
import requests
#输入想获取的网页
url = 'https://movie.douban.com/chart'
#创建一个名为html的response对象
html = requests.get(url)
#设置系统默认编码为UTF-8,防止乱码
html.encoding='utf-8'
(二)beautifulsoup
1.简介:Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库,它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式
2.beautifulsoup官方文档:
Beautiful Soup 4.4.0 文档链接
3.基本操作
from bs4 import BeautifulSoup
#使用BeautifulSoup解析这段代码,得到一个BeautifulSoup对象
soup=BeautifulSoup(html,'html.parser')
#按照标准的缩进格式的结构输出
print(soup.prettify())
执行后提示错误信息:
TypeError: object of type ‘Response’ has no len()
查找相关资料后,确认错误原因是BeautifulSoup库不能解析response类型,只需要将html变量的text赋值给新变量然后解析,或者直接:
soup = BeautifulSoup(hmtl.text, ‘lxml’)
修改代码如下:
#将HTML赋值给a,或者直接转换成文本
a=html.text
#使用BeautifulSoup解析这段代码,得到一个BeautifulSoup对象
#BeautifulSoup(markup,'html.parser')指使用Python的内置标准库,执行速度适中,文档容错能力强
#BeautifulSoup(markup,'lxml')指使用lxml HTML解析器,速度快,文档容错能力强,一般推荐使用lxml
soup1=BeautifulSoup(a,'html.parser')
soup2=BeautifulSoup(html.text,'lxml')
#按照标准的缩进格式的结构输出
print(soup1.prettify())
print(soup2.prettify())
#soup1和soup2等价
执行时报错:
bs4.FeatureNotFound: Couldn’t find a tree builder with the features you requested: lxml. Do you need to install a parser library?
报错语句:“soup2=BeautifulSoup(html.text,‘lxml’)”
解决方法:命令提示符下pip install lxml
顺便提一下刚使用VScode时运行语句总是输出乱码,但是在.py语句所在文件夹使用shift+右键选择“在此处打开命令窗口”,输入“Python ***.py”执行就没有乱码。经搜索,解决方法是新增环境变量(变量名:PYTHONIOENCODING、变量值:UTF8)
(三)分析网页,提取所需信息
1.HTML前置知识点:HTML(超文本标记语言)是一种标记性语言,是基于文档对象模型(DOM)的一长串字符串,以树的结构存储各种类似、这样的标签来识别内容,通过浏览器的实现标准来翻译成页面
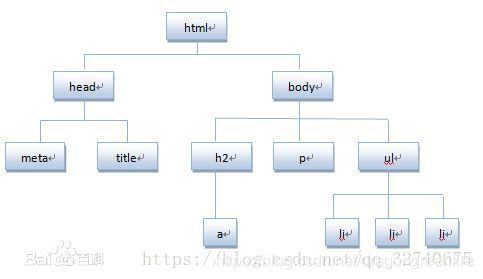
2.了解浏览器和服务器之间常见的通信方式:
GET:向服务器请求资源,请求以明文的方式传输,一般就在URL上能看到请求的参数
POST:从网页提交表单,以报文的形式传输,请求资源
3.简单的爬虫例子:单线程的静态页面
使用浏览器自带的F12审查(或者Google浏览器-右键-检查;火狐浏览器-右键-检查元素)元素
执行find_all语句时提示错误信息:
D:\python\lib\requests_init_.py:89: RequestsDependencyWarning: urllib3 (1.26.3) or chardet (4.0.0) doesn’t match a supported version!
warnings.warn("urllib3 ({}) or chardet ({}) doesn’t match a supported "
原因:python库中urllib3 (1.26.3) or chardet (4.0.0) 的版本不兼容
解决方案:
(1)卸载requests:pip uninstall requests
(2)卸载urllib3和chardet:方法同上
(3)重装requests:在网上下载了“requests-2.25.1”文件解压后放在Python安装文件夹,执行“pip install requests”
再次执行后发现输出为空,用其他网址测试非空,测试了一下发现该网页反爬虫(建议爬取网页之前先测试是否有反爬虫机制)
测试代码如下:
#导入各个模块
import requests
from bs4 import BeautifulSoup
#输入想获取的网页
url = 'https://movie.douban.com/chart'
#创建一个名为html的response对象
html = requests.get(url)
#防止乱码
html.encoding='utf-8'
#判断是否反爬虫
print(html.status_code)
输出结果为418
常见的状态码类别有:
1XX:Informational(信息性状态码) 接受的请求正在处理
2XX :Success(成功状态码) 请求正常处理完毕
3XX :Redirection(重定向状态码) 需要进行附加操作以完成请求
4XX :Client Error(客户端错误状态码) 服务器无法处理请求
5XX :Server Error(服务器错误状态码) 服务器处理请求出错
(相关HTTP状态码的解释可参考《HTTP状态码详解》、《HTTP常用的14种状态码》等文章)
总之,status_code为200时才是get成功了。
解决方案是添加请求header的UserAgent防止被反爬虫识别。
获取浏览器用户代理的方式:
1.chrome浏览器:在地址栏搜索“chrome://version/”,复制显示的“用户代理”
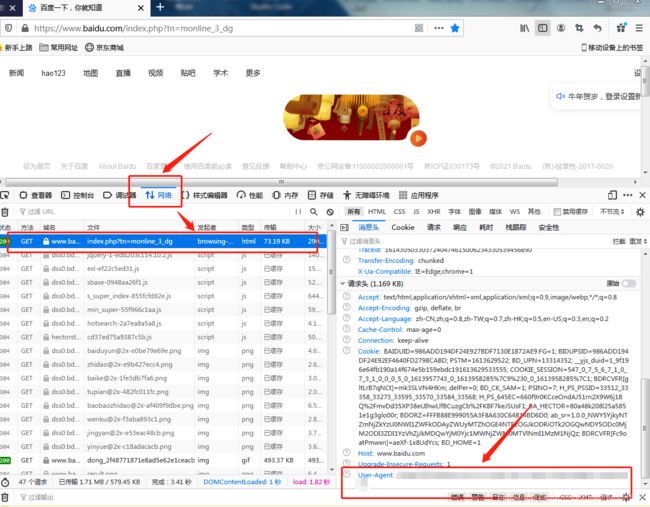
2.火狐浏览器:随便打开一个网页,快捷键F12调出开发人员工具,点击“网络”后随便选中一条数据,在右侧的“请求头”一栏拉到最后找到“User-Agent”复制,具体操作详见图片
其他浏览器不再详述
修改后的代码如下:
#反反爬虫机制:设置请求头消息User-Agent模拟浏览器(火狐浏览器)
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:85.0) Gecko/20100101 Firefox/85.0'}
#输入想获取的网页
url = 'https://movie.douban.com/chart'
#创建一个名为html的response对象
html=requests.get(url,headers=headers)
#防止乱码
html.encoding='utf-8'
#判断是否反爬虫
print(html.status_code)
输出结果为200,成功get该网页从而获取html内容
在使用find_all等抓取网页元素时出现取数不准的情况,因此有必要补充学习一下html页面基本元素构成知识
1.查看页面基本元素
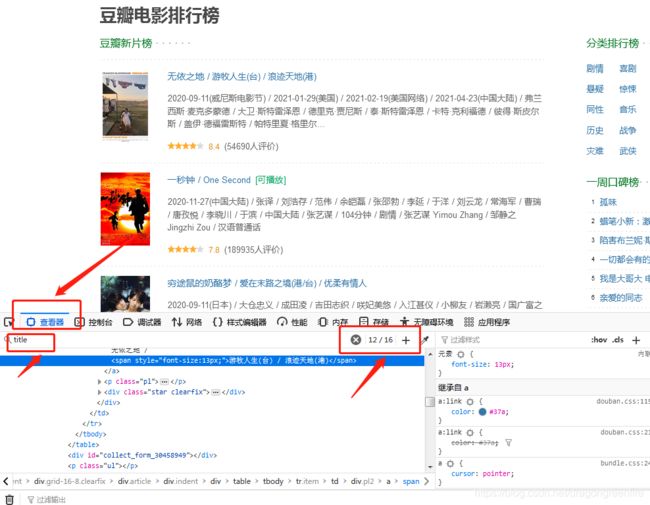
(1)火狐浏览器:选择想要提取的元素,右键“检查元素”即可查看对应信息;找到元素的名称后,可点击“查看器”,在输入框输入查找的元素名,搜索后可查看元素出现位置和次数
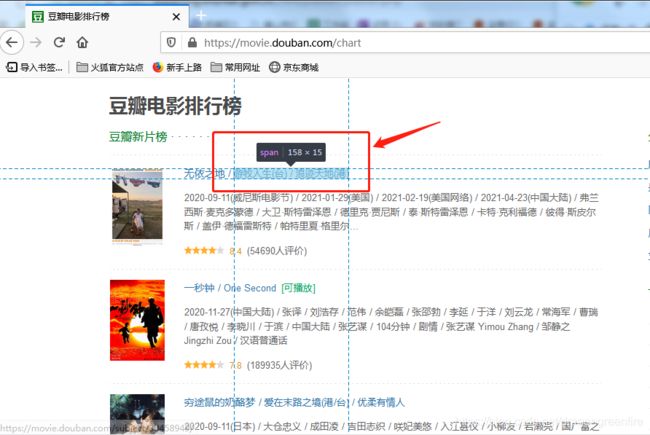
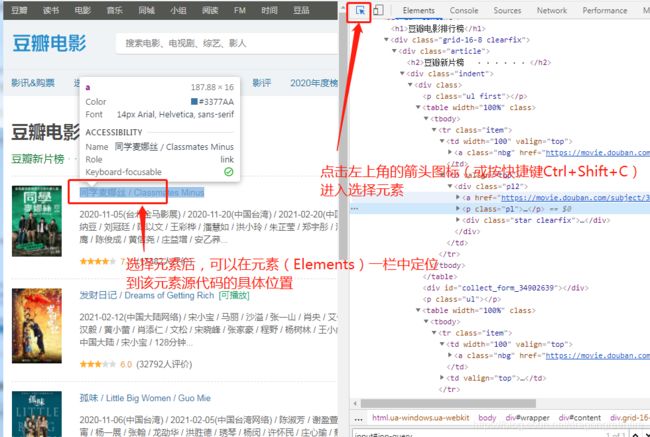
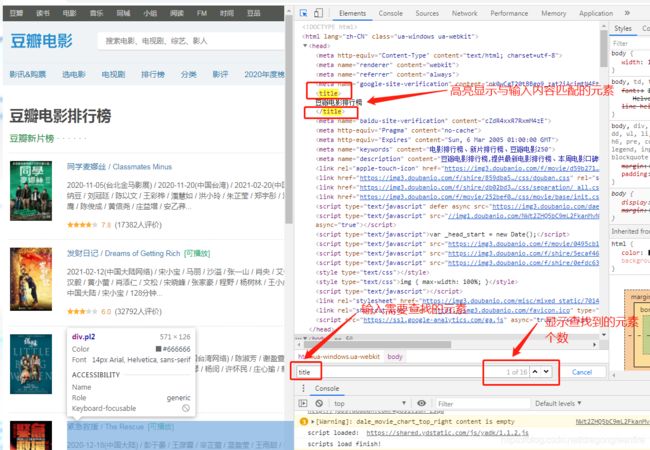
(2) Google浏览器:
详细内容参考:Chrome浏览器F12开发者工具简单使用
未完待续
备注:本文主要参考了《我的第一个Python爬虫——谈心得》等多篇文章