python-多进程&多线程
参考资料:https://www.liaoxuefeng.com/wiki/1016959663602400/1017628290184064
目录
1.多进程
1.1进程组成
1.2进程状态和转换
1.2.1使用Process方法创建进程
1.2.2使用继承方法创建进程
1.3进程通信
1.3.1共享存储
1.3.2消息传递
1.3.3管道通信
1.4进程同步和互斥
1.4.1进程同步
1.4.2进程互斥
1.4.3生产者消费者问题
1.4.4读者写者问题
1.4.5哲学家进餐问题
1.5多进程锁
1.5.1封锁协议
1.6进程池
2.多线程
1.多进程
想象一下,我办了一个工厂,专门生产中性笔,我请了一个工人,负责生产。这个工人先制造笔帽花了一个小时,再制造笔杆,也花了一个小时,但是只有一个工人,所以花了两个小时才组装一只中性笔。如果我雇佣了两个工人,同时进行笔帽和笔杆的生产,这时两个小时生产了两只中性笔。操作系统下面是计算机硬件,上面承载应用。支持多进程的操作系统,也就是多道操作系统,允许多个任务同时进行。好比我是双核的电脑,就对应于上面有两个工人,同时干活。单核电脑,也就是只有一个工人的情况下,能允许多个任务同时进行吗?答案是肯定的,我的一个工人可以1分钟制造笔帽,下一分钟制造笔杆……采用时间片流转的方式,去完成任务。
总结一下,
为什么需要多进程,是因为我们想要同时处理多个任务,也叫并发。
多进程是如何实现的,是把处理器的运行时间分成很小的时间片,当该时间片内该程序无法执行完毕,则暂停该任务,下一时间片内运行其它任务,如果操作系统中只有两个任务,则轮流执行。
这里可以看出来,实现多进程,必须有任务的启动,执行,暂停等。对应的就是就绪态-运行态-阻塞态相互转化。
多进程的作用,比如我们是单核处理器,进行计算任务的时候,也就是只调用CPU的计算资源,多进程效果不大,而且越多的进程,阻塞态和就绪态不停的切换,反而会比单线程执行的更慢,毕竟计算资源就那么多,你一起做完,还是1秒钟做这个,下一秒做那个,没有区别。多核处理器有倍数的提升。而当我们的任务更加复杂话,比如爬虫过程,我们通过http协议请求数据,分析处理数据,存储数据,这三个过程占用的资源各不一样,请求数据和处理数据,主要占用计算资源,也就是CPU,内存,存储数据,主要是IO过程,占用资源是磁盘。CPU和磁盘的速度是不一样的,可能计算时间是存储时间的1/10不到,可以考虑使用多线程,进行异步操作,当磁盘读写时,使CPU不至于闲置,进行充分利用。
还有一点,并发和并行的区别,并发指的是某一时间间隔内执行多个任务,精确到具体某一时间,只有一个任务在执行,
并行的话,具体某一时间,有多个任务在执行,也就是说并行一定是并发的。
最后说一下,什么是多进程,进程究竟是什么?
1.1进程组成
进程由程序段,数据段,PCB三部分组成,PCB中文名进程控制块,进程是系统资源分配调度的基本单位。通俗来说,就是程序的一次执行过程。
程序段:程序代码段
数据段:存储在内存中的数据
PCB:这里采用维基百科的解释
操作系统使用过程控制信息来管理过程本身。这包括:
- 进程调度状态-进程的状态,如“就绪”,“挂起”等,以及其他调度信息,例如优先级值,自从进程获得CPU控制或自从获得控制以来经过的时间它被暂停了。同样,在流程暂停的情况下,必须为该流程正在等待的事件记录事件标识数据。
- 流程结构信息–流程的子代ID,或以某种功能方式与当前流程相关的其他流程的ID,可以表示为队列,环或其他数据结构
- 进程间通信信息–与独立进程之间的通信关联的标志,信号和消息
- 进程特权-允许/禁止访问系统资源
- 流程状态-新的,准备就绪,正在运行,正在等待,已失效
- 进程号(PID)–每个进程的唯一标识号(也称为进程ID)
- 程序计数器(PC)–指向要为此过程执行的下一条指令的地址的指针
- CPU寄存器-寄存器集,需要在其中存储过程以在运行状态下执行
- CPU调度信息-信息调度CPU时间
- 内存管理信息–页表,内存限制,段表
- 记帐信息- 用于进程执行的CPU数量,时间限制,执行ID等。
- I / O状态信息-分配给进程的I / O设备列表。
内容有点多,我们简单一点,只需要记住进程描述信息pid和uid,一个PCB肯定包含进程标识符pid和用户标识符uid,不同的进程用pcb来区分,pcb上记录了pid,我们可以使用pid来区分不同的进程。
在讲解下面的代码的时候,还是再次强调一遍进程的状态和转换,
1.2进程状态和转换

网上随便找的图
解释一下这五个词
创建:新建进程后,不会马上执行该进程,我们前面讲到了,进程由程序段,数据段,PCB三部分组成,创建过程中会申请空白pcb并写入信息,系统向该进程分配资源,接下来转入就绪态。打个比方,创建进程的过程就好比手机开机的过程,开机后才能打开APP,开机这个过程,创建了可以打开APP的“条件”
就绪:进程所占用的资源分两类,一个是处理机资源,一个是非处理机资源,当进程申请到除了处理机的所有其它资源,只要提供处理机,就可以执行程序,这种状态叫就绪态。同样就绪态提供了运行态的“条件”,运行态当然就是执行APP了。打个比方,好比我们考试,发卷子后不能答题,只能看题,我们看题的过程就拿到了非处理机资源,也就是知道怎么写了,就等着可以答题了,监考老师一声令下,马上答题,也就是就绪态到运行态,是因为我们拿到了处理机资源,手可以开始动了。
在分时操作系统中,我们按时间片去划分处理机资源,比如1秒为间隔,且只有两个进程,第一秒进程1运行,一秒过后,时间片用完了,第二秒要给进程2使用,第三秒又给进程1使用……当第一秒过去后,进程1还未执行完毕,则进程1要从运行态转为就绪态,等待下一个时间片,再转为运行态
运行:程序正在执行,对比上面的例子,就是手在书写答案
阻塞:进程执行过程中,由于未能成功申请非处理机资源,而主动由运行态转为阻塞态,等待资源,当资源可用的时候,再转为就绪态,当时间片流转过来的时候,再转为就绪态
退出:执行完毕,退出,系统回收PCB
讲的有点多,直接对着代码来说更直观一点,我们现在创建一个最简单进程
1.2.1使用Process方法创建进程
from multiprocessing import Process
def myProcess(name):
print("正在执行的进程名称是", name)
if __name__ == "__main__":
p = Process(target=myProcess, args=("进程1",))
p.start()
结果如下
![]()
我们使用Process方法创建了一个进程,这个进程需要执行的内容由target指定,也就是方法myProcess。
p.start()方法启动一个进程,也就是从就绪态转为运行态
myProcess方法接收一个传入参数name,name的值由args指定,args接收一个元组,假如我们传入多个变量,可以这么写
from multiprocessing import Process
def myProcess(name1,name2):
print("传入的第一个name是", name1)
print("传入的第二个name是", name2)
if __name__ == "__main__":
p = Process(target=myProcess, args=("进程1","进程2"))
p.start()
效果如下
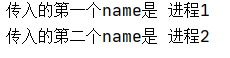
前面讲到的PID,我们也可以打印出来
from multiprocessing import Process
import os
def myProcess(*name):
print("传入的name有:",name)
print("os.getpid():",os.getpid())
if __name__ == "__main__":
p = Process(target=myProcess, args=("进程1","进程2"))
p.start()
print("p.pid:",p.pid)结果如下

上面的myProcess方法传入参数是*name,表示可变参数,更加灵活
Process有一个方法叫join,可以阻塞其它线程,包括主线程,我们尝试一下
from multiprocessing import Process
import os
import time
def myProcess(name,s):
print(name,"执行开始")
time.sleep(s)#睡眠s秒
print(name, "执行结束")
if __name__ == "__main__":
p1 = Process(target=myProcess, args=("p1",1))
p2 = Process(target=myProcess, args=("p2",0))
p1.start()
p2.start()结果如下

我们创建了两个进程p1,p2,并先后启动,由于p1睡眠了一秒,导致p2执行完毕后,p1才执行完毕,我们能让p1执行完毕后再让p2执行么,我们试试join方法
from multiprocessing import Process
import os
import time
def myProcess(name,s):
print(name,"执行开始")
time.sleep(s)#睡眠s秒
print(name, "执行结束")
if __name__ == "__main__":
p1 = Process(target=myProcess, args=("p1",1))
p2 = Process(target=myProcess, args=("p2",0))
p1.start()
p1.join()
p2.start()结果如下

p1.join()阻塞了所有其他进程
虽然看到的是只有两个进程p1,p2,但p1,p2实际上是运行在主进程下,我们可以分别打印出这个进程PID
from multiprocessing import Process
import os
import time
def myProcess(name,s):
print(name,"执行开始")
time.sleep(s)#睡眠s秒
print(name, "执行结束")
if __name__ == "__main__":
p1 = Process(target=myProcess, args=("p1",1))
p2 = Process(target=myProcess, args=("p2",0))
p1.start()
p1.join()
p2.start()
#打印进程ID
print("p1的pid是",p1.pid)
print("p2的pid是",p2.pid)
print("主进程的pid是",os.getpid())

也就是说,p1.join()除了阻塞p2,还会阻塞主进程,我们看下一个例子
from multiprocessing import Process
import os
import time
def myProcess(name,s):
print(name,"执行开始")
time.sleep(s)#睡眠s秒
print(name, "执行结束")
if __name__ == "__main__":
p1 = Process(target=myProcess, args=("p1",1))
p1.start()
print("这正在执行主进程的内容") 

如果按程序从上 到下的执行顺序,“这正在执行主进程的内容应该在最后出现,所以理解多进程,要抛弃这种观念,p1.start()将进程p1进入就绪态,其实已经脱离了这个主进程执行流,我这个界面的内容就是主进程,p1.start()相当于新开了一个执行界面,在这个执行界面执行p1进程定义的任务myProcess。由于进程p1睡眠了1秒,而主进程创建进程p1,将p1转为就绪态,打印信息“正在执行主进程”,肯定不需要1秒,所以就看到主进程的内容在代码后面出现,却在console界面先出现
红框内的代码,都是执行在主进程的内容,现在我们使用join阻塞主线程,打印结果将会是
p1执行开始,p1执行结束,正在执行主进程
代码如下
from multiprocessing import Process
import os
import time
def myProcess(name,s):
print(name,"执行开始")
time.sleep(s)#睡眠s秒
print(name, "执行结束")
if __name__ == "__main__":
p1 = Process(target=myProcess, args=("p1",1))
p1.start()
p1.join()
print("这正在执行主进程的内容")

看看上图的执行顺序
直观对比一下,能更好认识join方法
1.2.2使用继承方法创建进程
from multiprocessing import Process
import os
import time
def myProcess(name,s):
print(name,"执行开始")
time.sleep(s)#睡眠s秒
print(name, "执行结束")
class myProcessC(Process):
def __init__(self,*name):
super().__init__()
self.name=name[0]
self.s = name[1]
def run(self):
myProcess(self.name,self.s)
if __name__ == "__main__":
p=myProcessC("进程p",1)
p.start()
p.join()
print("这正在执行主进程的内容")

这里class myProcess继承自Process,__init__方法是构造方法,第一行是super().__init__()方法调用了Process的构造方法,
run()方法就是该进程需要执行的任务,这里调用了之前写的myPrcess方法
if__name__=="__main__",简单理解就是,假如我不加这段代码,该模块被其它模块导入时,会自动执行下面的四行代码。
1.3进程通信
进程之间不共享资源,进程通信有三种方式:共享存储,消息传递,管道通信
1.3.1共享存储
两个进程p1,p2,p1访问一个文件,往里面写数据,然后关闭文件,p2打开文件读数据,这样就能使数据从p1传递给p2。
这里的“文件"实际上是一个共享空间,是一种半双工通信
1.3.2消息传递
进程p1往消息缓冲区里写数据,进程 p2往消息缓存区读数据。缓冲区实际上是一个队列
我们可以使用multiprocessing.Queue队列实现消息传递,如下
from multiprocessing import Process, Queue
class ReadProcess(Process):
def __init__(self, queue):
self.queue = queue
super().__init__()
def run(self):
while not self.queue.empty():
result = self.queue.get()
print("读入的数据是:", result)
if result==10:
exit()
class WriteProcess(Process):
def __init__(self, queue):
self.queue = queue
super().__init__()
def run(self):
i = 0
while not self.queue.full():
i = i + 1
self.queue.put(i)
print("写入的数据是:", i)
if i==10:
exit()
if __name__ == "__main__":
queue = Queue()
w=ReadProcess(queue)
r=WriteProcess(queue)
r.start()
w.start()
1.3.3管道通信
进程p1往管道写数据,进程p2往管道读数据管道不满,就可以一直写,管道不空,就可以一直读。管道实际上是一个文件
代码以后补
1.4进程同步和互斥
什么是进程同步,就是先做什么,再做什么,我得先穿好袜子,再穿鞋。
什么是互斥,就是上厕所,只有一个位置,我上厕所的时候,别人不能上。
要实现进程同步和互斥需要一个东西,叫信号量。
这里就不详细介绍信号量的实现方式了,我们只需要了解信号量有两个原语,P操作和V操作
P操作申请资源,V操作释放资源。
记录型信号量S初始为0,当调用P(S)时,S信号量会减一,此时S<0则进程会自我阻塞,放弃处理机,如果>=0则继续往下执行,
V(S)则会释放资源,将S加一,此时S仍旧小于等于0,则唤醒阻塞队列的进程。
伪代码如下:
P(S){
S=S-1
if(S<0)
{
将本进程加入到等待队列Q
阻塞本进程
}
}
V(S)
{
S=S+1
if(s<=0){
释放等待队列Q中的第一个进程
将该进程唤醒,也就是从阻塞态变成就绪态
}上面出现得“资源”这个名词就是除了处理机之外得其它资源。进程占用的资源的两大类大类就是“资源”(除开处理机的资源)和处理机资源。
1.4.1进程同步
我们要做的同步操作,就是p1先执行,然后p2再执行
S=0
p1(){
穿袜子
V(S)
}
p2(){
P(S)
穿鞋子
}
这里有两个进程p1,p2,当我们start后,p1和p2同时进行,p2执行的时候,p(S)=p(0),S=0的时候,该进程会阻塞,所以p2进程就一直在等待。p1执行的时候,直接就把袜子穿好了,然后V(S)释放资源,这时S=1,,此时P2进程的P(S)=P(1),P2开始穿鞋子。达到了操作同步的效果。
代码如下:
from multiprocessing import Process,Semaphore
s = Semaphore(0)
class wearSocks(Process):
def __init__(self):
super().__init__()
def run(self):
global s
print("穿袜子")#先执行操作
s.release()
print("p1:",s)
class wearShoes(Process):
def __init__(self):
super().__init__()
def run(self):
global s
print("p2:",s)
s.acquire()#先p
print("穿鞋子")#后执行操作
if __name__ == '__main__':
p1=wearSocks()
p2=wearShoes()
p1.start()
p2.start()
代码运行结果有误,所以只给出用法参考
搜到了一篇文章https://blog.csdn.net/hlg1995/article/details/81638732
说的是进程之间不共享变量,我以为只要声明了全局变量就可以共享,现在按照链接的例子,给出代码
import multiprocessing
import time
# 定义全局变量
my_list = list()
# 写入数据
def write_data():
global my_list
for i in range(5):
my_list.append(i)
time.sleep(0.2)
print("write_data:", my_list)
# 读取数据
def read_data():
global my_list
print(my_list)
if __name__ == '__main__':
# 创建写入数据的进程
write_process = multiprocessing.Process(target=write_data)
read_process = multiprocessing.Process(target=read_data)
write_process.start()
write_process.join()
# 主进程等待写入进程执行完成以后代码 再继续往下执行
read_process.start()
read_process.join()还是回到之前的进程通信问题,使用Queue进行进程通信,代码如下
import multiprocessing
import time
q=multiprocessing.Queue()
def write_data(q):
my_list = list()
for i in range(5):
my_list.append(i)
time.sleep(0.2)
q.put(my_list)
print("write_data:", my_list)
def read_data(q):
my_list=q.get()
print("read_data:",my_list)
if __name__ == '__main__':
write_process = multiprocessing.Process(target=write_data,args=(q,))
read_process = multiprocessing.Process(target=read_data,args=(q,))
write_process.start()
write_process.join()
read_process.start()
read_process.join()所以我们不考虑全局变量的形式,除了消息传递,还有共享存储的方式进行消息传递。我们首先解决利用信号量实现进程同步的问题,也就是先穿袜子,再穿鞋子的问题。由于进程之间不能共享变量,我们试试把信号量变量存入队列中,看看是否可行
from multiprocessing import Process,Semaphore
import time
s = Semaphore(0)
class wearSocks(Process):
def __init__(self):
super().__init__()
def run(self):
#global s
#print("穿袜子")#先执行操作
#s.release()
#print("p1:",s)
time.sleep(2)
print("穿袜子")
class wearShoes(Process):
def __init__(self):
super().__init__()
def run(self):
#global s
#print("p2:",s)
#s.acquire()#先p
#print("穿鞋子")#后执行操作
print("穿鞋子")
if __name__ == '__main__':
p1=wearSocks()
p2=wearShoes()
p1.start()
p2.start()
用信号量实现先穿袜子,再穿鞋子的,以及互斥关系,生产资消费者,读者写者问题,哲学家进餐问题,放到后面的线程去研究。
这里使用全局变量不行,如果我主动传入信号量是否可以
from multiprocessing import Process,Semaphore
import time
class wearSocks(Process):
def __init__(self,s):
super().__init__()
self.s = s
def run(self):
time.sleep(3)
self.s.release()
print("穿袜子")
class wearShoes(Process):
def __init__(self,s):
super().__init__()
self.s=s
def run(self):
self.s.acquire()#先p
print("穿鞋子")
if __name__ == '__main__':
s = Semaphore(0)
p2=wearShoes(s)
p2.start()
p1 = wearSocks(s)
p1.start()
结果
1.4.2进程互斥
我们不是使用文件,Queue,管道,也不使用全局变量,看看能不能通过传入信号量的方式实现互斥
伪代码如下:
S=1
p1(){
P(S)
打印100个1
V(S)
}
p2(){
v(S)
打印100个2
P(S)
}
进程同步就是先V后P,P1进程做完事情,释放资源后,P2进程P的时候才能获取资源,获取不到资源就会阻塞。
进程互斥就是用P和V夹,夹一下就表示互斥
我们先实现上面的代码
from multiprocessing import Process,Semaphore
import time
class wearSocks(Process):
def __init__(self,s):
super().__init__()
self.s = s
def run(self):
self.s.acquire()
for i in range(10):
time.sleep(0.1)
print("1")
self.s.release()
class wearShoes(Process):
def __init__(self,s):
super().__init__()
self.s=s
def run(self):
self.s.acquire()#先p
for i in range(10):
time.sleep(0.1)
print("2")
self.s.release()
if __name__ == '__main__':
s = Semaphore(1)
p2=wearShoes(s)
p2.start()
p1 = wearSocks(s)
p1.start()结果如下

循环次数改为10是不想等太久,各位可以尝试一下
那么我们如果取消这些互斥,会怎么样,代码如下
from multiprocessing import Process,Semaphore
import time
class wearSocks(Process):
def __init__(self,s):
super().__init__()
self.s = s
def run(self):
#self.s.acquire()
for i in range(10):
time.sleep(0.1)
print("1")
#self.s.release()
class wearShoes(Process):
def __init__(self,s):
super().__init__()
self.s=s
def run(self):
#self.s.acquire()#先p
for i in range(10):
time.sleep(0.1)
print("2")
#self.s.release()
if __name__ == '__main__':
s = Semaphore(1)
p2=wearShoes(s)
p2.start()
p1 = wearSocks(s)
p1.start()
其实我有一个问题,这两个进程虽然靠全局变量无法通信,但是可以传入变量的方式进程通信,但是要是这两个进程运行在两个界面中,也就是两个代码文件中,要怎么传递变量呢?
1.4.3生产者消费者问题
若干(比如5个)生产者和10个消费者共享一个缓冲区,缓冲区作为临界资源,只能同时一个生产者或者一个消费者访问
缓冲区不满,则生产者写入数据,缓冲区不空,则消费者读入数据。
这里有两个同步关系,一个互斥关系,
生产者先生产,消费者后消费(同步)
消费者先创造空位,生产者后填补空位(同步)
生产和消费不能同时进行(互斥)
代码如下:
from multiprocessing import Process,Semaphore,Queue
import time
class producer(Process):
def __init__(self,pro,com,s,name,productName,q):
super().__init__()
self.pro = pro
self.com = com
self.s = s
self.name=name
self.productName=productName
self.q=q
def run(self):
while True:
print(self.name,"生产了",self.productName)
self.com.acquire()#只P不V的后做
self.s.acquire()#p
print(self.name,"填入缓冲区",self.productName)
self.q.put(self.productName)
self.s.release()#v 互斥
self.pro.release()#只V不P的先做
class comsumer(Process):
def __init__(self,pro,com,s,name,productName,q):
super().__init__()
self.pro = pro
self.com = com
self.s = s
self.name = name
self.productName = productName
self.q=q
def run(self):
while True:
self.pro.acquire() # 只P不V的后做
self.s.acquire() # p
productName=self.q.get()
print(self.name, "从缓冲区拿出", productName)
self.s.release() # v 互斥
self.com.release() # 只V不P的先做
print("消费了产品",productName)
if __name__ == '__main__':
q=Queue()
s = Semaphore(1)
com=Semaphore(10)
pro=Semaphore(0)
for i in range(5):
producerName="生产者"+str(i)
comsumerName="消费者"+str(i)
productName="产品p"+str(i)
p=producer(pro,com,s,producerName,productName,q)
c =comsumer(pro,com,s,comsumerName,productName,q)
p.start()
c.start()
1.4.4读者写者问题
略
1.4.5哲学家进餐问题
略
1.5多进程锁
在数据库锁中,有读锁和写锁,也就是S锁(共享锁)X锁(排它锁),这两个锁的排列组合,又会出现下面三个封锁协议,虽然进程锁跟数据库锁可能不太一样,但是写出来供大家了解
1.5.1封锁协议
网上找了一张封锁相容矩阵

两句话:
加了X锁之后不能加任何锁,
加了S锁之后,只能加S锁
一级封锁协议:
在写之前必须加X锁,可以防止丢失修改;
丢失修改是这样,假如初始值是1,p1的操作是取数,乘以2,写回文件。p2的操作是取数,乘以3,写回文件。
p1进程先执行,取数的时候值为1,乘以2,写入2为2。p1写的过程中还未提交,p2就可以取数,仍旧取1,乘以3,写入3。最后结果是3,而不是6。
当加入一级封锁后,初始值为1,p1要修改数据,则加上X锁,这时出现两种情况,
(1).写入2并提交,这时释放X锁,p2取数后乘以2,将6写回文件
(2).还未写入2,所以X锁未释放,p2取数1,乘以3,准备将3写回文件,因为一级封锁协议,未申请到x锁,所以无法将3写入文件,等到p1释放x锁之后,p2在将3写入文件,这样看,好像加了x锁还是3,但是出现这种情况是因为p1未释放X锁的情况下,P2就进行了读操作,取出来了1,虽然跟下面不可重复读的例子有点差别,但是我认为这种情况也能称之为不可重复读,可以用二级封锁解决
二级封锁协议:
写之前加X锁,这是一级封锁的内容,在一级封锁的基础上,引入S锁,读之前加S锁,读完就释放,S锁和X锁满足封锁相容矩阵。
三级封锁协议:
在二级封锁的基础上,读之前加S锁,读完后不释放S锁,事务结束后再释放S锁。
仿照多线程Lock进行多进程锁代码如下(因为结果有误,所以只给出用法,仅供参考)
from multiprocessing import Lock,Process
shared_resource_with_no_lock = 0
shared_resource_with_lock=0
COUNT = 1000000
shared_resource_lock = Lock()
# 有锁的情况
def increment_with_lock():
global shared_resource_with_lock
for i in range(COUNT):
shared_resource_lock.acquire()
shared_resource_with_lock += 1
shared_resource_lock.release()
def decrement_with_lock():
global shared_resource_with_lock
for i in range(COUNT):
shared_resource_lock.acquire()
shared_resource_with_lock -= 1
shared_resource_lock.release()
# 没有锁的情况
def increment_without_lock():
global shared_resource_with_no_lock
for i in range(COUNT):
shared_resource_with_no_lock += 1
def decrement_without_lock():
global shared_resource_with_no_lock
for i in range(COUNT):
shared_resource_with_no_lock -= 1
if __name__ == "__main__":
t1 = Process(target=increment_with_lock)
t2 = Process(target=decrement_with_lock)
t3 = Process(target=increment_without_lock)
t4 = Process(target=decrement_without_lock)
t1.start()
t2.start()
t3.start()
t4.start()
t1.join()
t2.join()
t3.join()
t4.join()
print ("the value of shared variable with lock management is %s" % shared_resource_with_lock)
print ("the value of shared variable with race condition is %s" % shared_resource_with_no_lock)
所以核心还是不能共享变量造成的。
from multiprocessing import Process,Lock
import random
import time
import os
class write(Process):
def __init__(self,lock,word):
super().__init__()
self.lock=lock
self.word=word
def run(self):
#self.lock.acquire()
for i in range(5):
time.sleep(random.uniform(0,2))
print(self.word)
#self.lock.release()
if __name__=="__main__":
lock=Lock()
w1=write(lock,"1")
w2=write(lock,"2")
w3=write(lock,"3")
w1.start()
w2.start()
w3.start()我们想要的结果是5个相同的字符连续输出,上面的结果如下

现在加上lock
from multiprocessing import Process,Lock
import random
import time
import os
class write(Process):
def __init__(self,lock,word):
super().__init__()
self.lock=lock
self.word=word
def run(self):
self.lock.acquire()
for i in range(5):
time.sleep(random.uniform(0,2))
print(self.word)
self.lock.release()
if __name__=="__main__":
lock=Lock()
w1=write(lock,"1")
w2=write(lock,"2")
w3=write(lock,"3")
w1.start()
w2.start()
w3.start()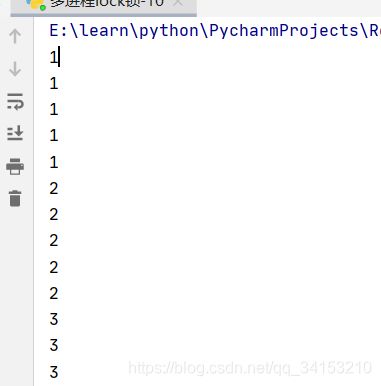
这个锁有点类似X锁
进程中除了LOCK,还有RLOK,这里一段描述非常好, 我拿过来
如果你想让只有拿到锁的线程才能释放该锁,那么应该使用 RLock() 对象。和 Lock() 对象一样, RLock() 对象有两个方法: acquire() 和 release() 。当你需要在类外面保证线程安全,又要在类内使用同样方法的时候 RLock() 就很实用了。
(译者注:RLock原作解释的太模糊了,译者在此擅自添加一段。RLock其实叫做“Reentrant Lock”,就是可以重复进入的锁,也叫做“递归锁”。这种锁对比Lock有是三个特点:1. 谁拿到谁释放。如果线程A拿到锁,线程B无法释放这个锁,只有A可以释放;2. 同一线程可以多次拿到该锁,即可以acquire多次;3. acquire多少次就必须release多少次,只有最后一次release才能改变RLock的状态为unlocked)来源:https://python-parallel-programmning-cookbook.readthedocs.io/zh_CN/latest/chapter2/07_Thread_synchronization_with_RLock.html
我们不花费太多时间在进程的信号量,lock,rlock上,在线程一章中我们再去去探究这三个东西
1.6进程池
搜到一篇文章写的不错,这里我就不写了
https://blog.csdn.net/brucewong0516/article/details/85788202
http://c.biancheng.net/view/2634.html
2.多线程
进程是占用计算资源(CPU)和非计算资源(内存,磁盘,网卡),来执行任务。当使用多进程去缩短执行时间时,涉及到进程切换,有较大的时空开销。那么我们把计算资源和非计算资源分散,非计算资源交给进程,计算资源交给进程下的线程,当线程切换时,不涉及到资源的占用和解除占用,开销较小。由于进程下的每一个线程都不占用非计算资源,也就是说他们共享这些资源,同一进程下,线程与线程之间可以很方便通信。(而不同的进程通信方式有管道通信,共享存储,消息传递等)。
如果要通俗理解,多进程就是多个人,一个人写数学作业,一个人写英语作业……。
多线程是,只有一个人,脑子同时思考数学和英语,但是手只能写一个作业,因此这一分钟写数学,下一分钟写英语。脑子就相当于非计算资源,手就相当计算资源,除非两只手都可以写作业,这就是并行,而不是并发了,所以并行效率会更高。
2.1创建线程
2.1.1函数创建
最简单的,我们创建5个线程,打印1,2,3,4,5,五个数
import threading
import time
import random
def printout(i):
print(i)
def myThread(i):
t=threading.Thread(name="打印数字"+str(i),target=printout,args=(i,))
t.start()
time.sleep(random.uniform(0,1))
if __name__=="__main__":
for i in range(5):
myThread(i)或者换一种写法
import threading
import time
import random
def printout(i):
print(i)
def myThread(i,l):
t=threading.Thread(name="打印数字"+str(i),target=printout,args=(i,))
l.append(t)
time.sleep(random.uniform(0,1))
if __name__=="__main__":
l=[]
for i in range(5):
myThread(i,l)
for r in l:
r.start()结果很奇怪,感觉像同步了一样

我换成多进程写一下
import threading
import time
import random
from multiprocessing import Process
def printout(i):
print(i)
def myThread(i):
t=threading.Thread(name="打印数字"+str(i),target=printout,args=(i,))
t.start()
#time.sleep(random.uniform(1))
def myProcess(i):
t=Process(target=printout,args=(i,))
t.start()
#time.sleep(random.uniform(0, 1))
if __name__=="__main__":
for i in range(50):
myThread(i)
#myProcess(i)怎么感觉多线程是同步的
是否同步后面解决,先留个坑
2.1.2继承方式创建线程
import threading
import time
import random
class MyThread(threading.Thread):
def __init__(self,i):
super().__init__()
self.i=i
def run(self):
print(self.i)
if __name__=="__main__":
for i in range(5):
t=MyThread(i)
t.start()
我们可以打印线程的名称
import threading
import time
import random
class MyThread(threading.Thread):
def __init__(self,i):
super().__init__()
self.name="线程"+str(i)
self.i=i
def run(self):
print(self.i)
print(threading.currentThread().getName())
if __name__=="__main__":
for i in range(5):
t=MyThread(i)
t.start()
2.3用多线程实现一个归并排序
当然我们也可以写一个快排
首先写一个不借助多线程写的一个归并排序
import time
def Merge(A,low,mid,high):
B=A[low:high+1]
i=low
j=mid+1
k=i
while(i<=mid and j<=high):
if B[i-low]<=B[j-low]:
A[k]=B[i-low]
i=i+1
else:
A[k]=B[j-low]
j=j+1
k=k+1
if i<=mid:
A[k:k+mid-i+1]=B[i-low:mid+1-low]
if j<=high:
A[k:k+high-j+1]=B[j-low:high+1-low]
def MergeSort(A,low,high):
if(low1百万居然要排60秒

我们用两个线程优化一下
import time
import threading
def Merge(A,low,mid,high):
B=A[low:high+1]
i=low
j=mid+1
k=i
while(i<=mid and j<=high):
if B[i-low]<=B[j-low]:
A[k]=B[i-low]
i=i+1
else:
A[k]=B[j-low]
j=j+1
k=k+1
if i<=mid:
A[k:k+mid-i+1]=B[i-low:mid+1-low]
if j<=high:
A[k:k+high-j+1]=B[j-low:high+1-low]
def MergeSort(A,low,high):
if(low

居然是一点用都没有,大家可以搜索一下关键词“GIL”,能找到答案

那么线程在计算密集任务下效果不好,我们试试多进程有没有效果
import time
from multiprocessing import Process
def Merge(A,low,mid,high):
B=A[low:high+1]
i=low
j=mid+1
k=i
while(i<=mid and j<=high):
if B[i-low]<=B[j-low]:
A[k]=B[i-low]
i=i+1
else:
A[k]=B[j-low]
j=j+1
k=k+1
if i<=mid:
A[k:k+mid-i+1]=B[i-low:mid+1-low]
if j<=high:
A[k:k+high-j+1]=B[j-low:high+1-low]
def MergeSort(A,low,high):
if(low不是没有效果的问题,是根本得不出结果,暂时挖个坑吧,以后填这个坑
感兴趣的小伙伴如果能解决这个问题,可以在评论区给出答案
我个人猜测是不是要通过Queue传递这个数组
3协程
3.1什么是协程
这里直接给出别人的解释
https://www.liaoxuefeng.com/wiki/1016959663602400/1017968846697824
3.2如何创建协程
3.2.1生成器
def odd():
yield 1
yield 3
yield 6
o = odd()
result=next(o)
print(result)
result=next(o)
print(result)
result=next(o)
print(result)
result=next(o)
print(result)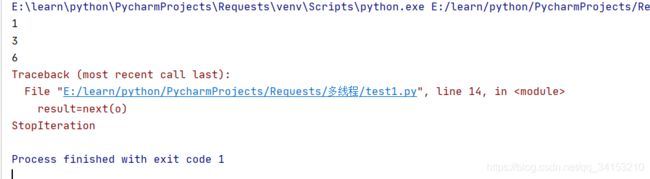
用 yield修饰的函数就是一个生成器,yield相当于return。
如果我们把odd的yield换成return,则该函数只会执行一次就退出。换成yield后,使用next()方法会执行到第一个yield,并返回值。直接返回1,执行第二次next()方法后,则从上次退出的地方继续执行。所以我们可以利用这个特性写一个计数器,比如我有10口罩,用完一次少一个,用完后提示需要再买口罩:
def getQuantity(n):
while n>1:
n = n - 1
yield n
yield("已用完,请重新购买")
q=getQuantity(10)
#拿出一个,还剩多少个
remaining=next(q)
print("拿一个剩余:",remaining)#打印剩下的口罩
#在拿一个
remaining=next(q)
print("再拿一个剩余:",remaining)#打印剩下的口罩
print("一次性拿完剩下所有的口罩")
for i in q:
print(i)
未完待续……