Hive3第四章:分区表和分桶表
系列文章目录
Hive3第一章:环境安装
Hive3第二章:简单交互
Hive3第三章:DML数据操作
Hive3第三章:DML数据操作(二)
Hive3第四章:分区表和分桶表
文章目录
- 系列文章目录
- 前言
- 一、分区表
-
- 分区表
- 1.准备数据
- 2.创建分区表
- 3.加载数据
- 4.查询
- 5.增加分区
- 6.删除分区
- 7.查看分区表
- 二、二级分区
-
- 1.创建二级分区
- 2.上传数据
- 3.数据关联
- 三、分桶表(了解)
-
- 1.数据准备
- 2.创建分桶表
- 3.上传数据
- 总结
前言
这一次我们来学习分区表和分桶表,分区表是重点,分桶表作为了解内容。
提示:以下是本篇文章正文内容,下面案例可供参考
一、分区表
分区表
分区表实际上就是对应一个 HDFS 文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive 中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过 WHERE 子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。
1.准备数据
由于之前创建的文件太多了,我把之前的本地的数据都删除了,现在重新创建数据目录。
数据
10 ACCOUNTING 1700
20 RESEARCH 1800
30 SALES 1900
40 OPERATIONS 1700
50 TEST 2000
60 DEV 1900
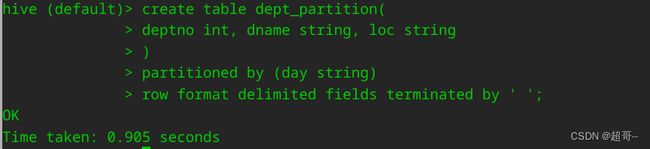
2.创建分区表
create table dept_paryion(
deptno int, dname string, loc string
)
partitioned by (day string)
row format delimited fields terminated by ' ';
之前集群的数据也删除了。

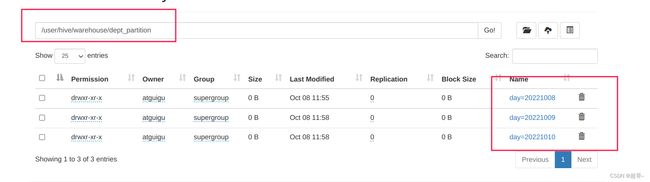
3.加载数据

load data local inpath
'/opt/module/hive/datas/dept_1.txt' into table dept_partition
partition(day='20221008');
注意最后一个参数,我用的是日期,用来分区的单位。
依次把其它表也插入。

load data local inpath
'/opt/module/hive/datas/dept_2.txt' into table dept_partition
partition(day='20221009');
load data local inpath
'/opt/module/hive/datas/dept_3.txt' into table dept_partition
partition(day='20221010');
4.查询
- 单分区查询
select * from dept_partition where day='20221008';

- 多分区联合查询
select * from dept_partition where day='20221008
union
select * from dept_partition where day='20221009'
union
select * from dept_partition where day='20221010';

因为要走MR时间还是有点长。
但是在拥有大量数据的时候,使用分区表,相当于给数据做了一定程度的分类,所以还是比较常用的。
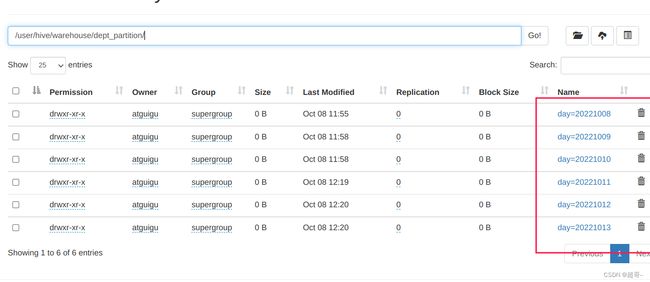
5.增加分区
单个分区
alter table dept_partition add partition(day='20221011');
多个分区
alter table dept_partition add partition(day='20221012') partition(day='20221013');

6.删除分区
- 单个分区
alter table dept_partition drop partition(day='20221012') partition(day='20221013');
- 多个分区
alter table dept_partition drop partition(day='20221012'),partition(day='20221013');
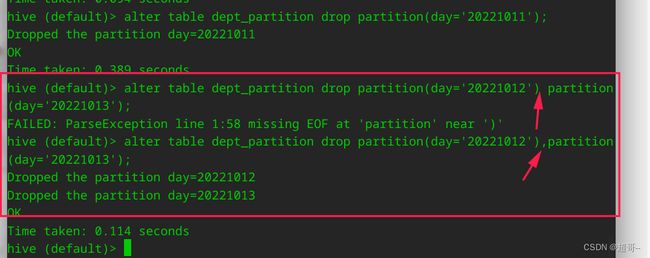
注意添加分区的时候,用空格隔开,但是删除分区的时候使用逗号,这里要注意。
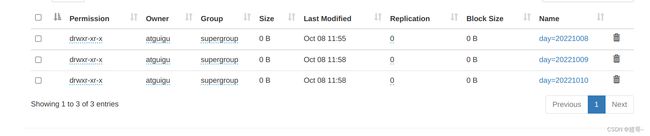
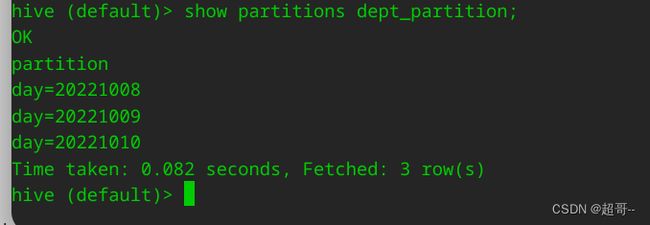
7.查看分区表
show partitions dept_partition;
二、二级分区
思考: 如何一天的日志数据量也很大,如何再将数据拆分?
1.创建二级分区
我们只需要在增加一个参数即可。
create table dept_partition2(
deptno int, dname string, loc string
)
partitioned by (day string, hour string)
row format delimited fields terminated by ' ';

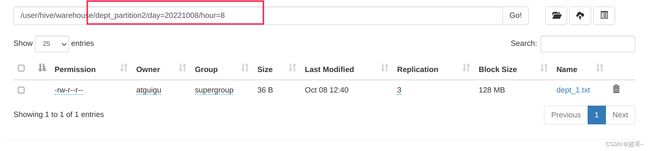
2.上传数据
load data local inpath
'/opt/module/hive/datas/dept_1.txt' into table
dept_partition2 partition(day='20221008', hour='8');

3.数据关联
-
load上传
就是之前咱们使用的方法,因为load会修改元数据 -
数据修复
我们可以使用hdfs创建目录然后直接上传数据
hadoop fs -mkdir -p /user/hive/warehouse/dept_partition2/day=20221009/hour=9;
hadoop fs -put /opt/module/hive/datas/dept_1.txt /user/hive/warehouse/dept_partition2/day=20221009/hour=9;

这个时候我们使用select查询

并没有查到数据,所以我们要进行元数据和hdfs关联
msck repair table dept_partition2;

之后就可以进行查询了。
三、分桶表(了解)
分区提供一个隔离数据和优化查询的便利方式。不过,并非所有的数据集都可形成合理
的分区。对于一张表或者分区,Hive 可以进一步组织成桶,也就是更为细粒度的数据范围划分。
分桶是将数据集分解成更容易管理的若干部分的另一个技术。
分区针对的是数据的存储路径;分桶针对的是数据文件。
1.数据准备
vim /opt/module/hive/datas/students.txt
1001 ss1
1002 ss2
1003 ss3
1004 ss4
1005 ss5
1006 ss6
1007 ss7
1008 ss8
1009 ss9
1010 ss10
1011 ss11
1012 ss12
1013 ss13
1014 ss14
1015 ss15
1016 ss16
2.创建分桶表
create table stu_buck(id int, name string)
clustered by(id)
into 4 buckets
row format delimited fields terminated by ' ';

3.上传数据
load data inpath '/opt/module/hive/datas/students.txt' into table stu_buck;

会默认分成四个桶。
总结
这次内容基本就到这里。