linux内核学习6:Linux的CPU高速缓存cache和页高速缓存cache,buffer
一、CPU高速缓存(cache)
参考:https://blog.csdn.net/u014470361/article/details/80060701
参考:https://blog.csdn.net/u012319493/article/details/85238918
cache,中译名高速缓冲存储器,其作用是为了更好的利用局部性原理,减少CPU访问主存的次数。简单地说,CPU正在访问的指令和数据,其可能会被以后多次访问到,或者是该指令和数据附近的内存区域,也可能会被多次访问。因此,第一次访问这一块区域时,将其复制到cache中,以后访问该区域的指令或者数据时,就不用再从主存中取出。
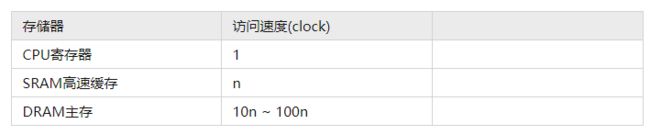
注意:这里的cache一般是SRAM,主存一般是DRAM,CPU指CPU寄存器,所以整个过程是CPU寄存器——SRAM——DRAM
cache对于程序员是不可见的,它完全是由硬件控制的
在以前,CPU的主频比较慢,CPU和内存DRAM之间速度差别不是很大,存储数据或者指令还OK。但是CPU的飞速发展,CPU大哥速度已经飞快,而内存速度却跟不上大哥的步伐,所以大哥每次要读取或者写入内存的时候都要等一等小弟,这个时候怎么办。cache就出来了,它类似与一个第三方。位于内存和CPU之间,速度非常快,所以CPU就把数据直接写入cache,然后CPU就可以干其他的了,剩下的事情就交给cache这个跑腿的,cache在合适的时机可以慢慢的把数据写入内存,也就是相当于解了CPU的燃眉之急。
说白了,CPU要读数据首先是在cache中读,如果cache命中,也叫cache hit,CPU就可以极快的得到该地址处的值。如果cache miss 也就是没有命中,它就会通过总线在内存中去读,并把连续的一块单元加载到cache中,下次好使用。
- cache大多是SRAM(静态RAM),而内存大多是DRAM(动态随即存储)或者DDR(双倍动态随机存储)。
- cache容量一般非常小,因为价格贵,所以cache小是有道理的。一级cache一般就几KB,cache 的单位又分成cache line ,它是从内存单元加载到cache中的最小单元,一般为几个字大小,32字节或者64字节偏多。(因为时间局部性和空间局部性所以加载一次是以一个cache单元为最小单位)
cache有两种模式(写回模式) 和 (写通模式)
写回(Write-back)和写通(Write-through)的对象都是内存
- 简单介绍,写通也就是当CPU写入cache的时候,将数据再从cache 中写到内存中,这两个过程要都结束后,CPU的写入操作才算完成,也就是时刻保持内存和缓存的同步,这显然是很耗时的,因为写到内存比较耗时。
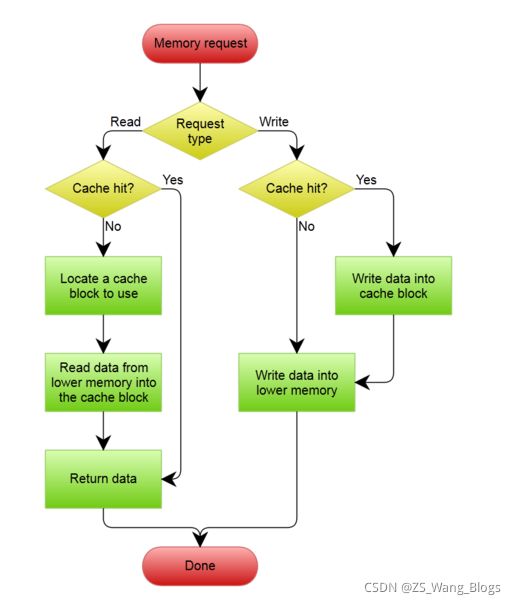
- 写回也就是当CPU写入cache中的时候,数据不会马上从cache中写到内存里面,而是等待时机成熟后写入(比如 发生cache miss,其他内存要占用该cache line的时候将该单元写回到内存中,或者一定周期后写入到内存中 ,或者其它地核需要读取该内存的时候)。
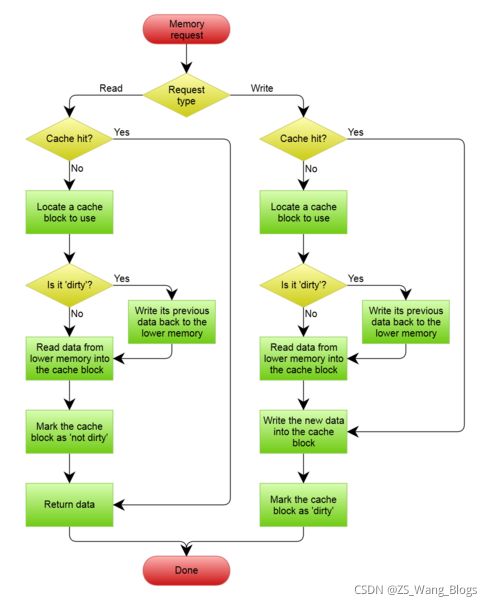
多级cache
一级cache 有指令cache和数据cache之分,这使整个系统更加高效,因为1Lcache 容量小,所以有了多级cache ,比如二级cache ,他容量大,但是速度就要比1Lcache 慢些,但比内存快多了。三级cache就更一些了。
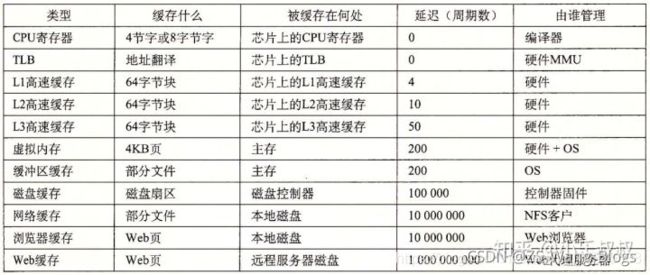
存储器层次结构
一种典型的存储器层级结构如下:
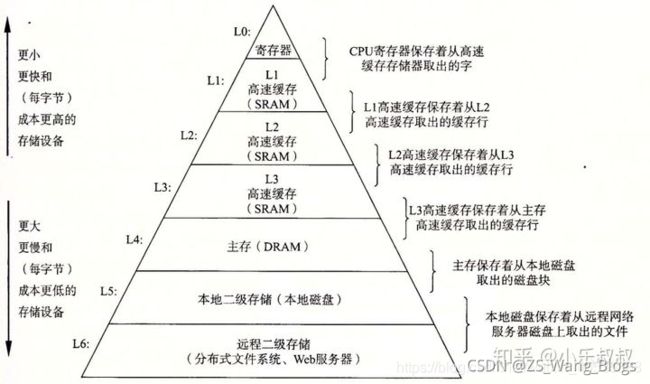
高速缓存的定义
其实cache就是高速缓存,高速缓存不是一个特指的东西,高速缓存是相对于速度慢的存储而言。 存储器层次结构的主要思想是上一层的存储器作为低一层存储器的高速缓存。因此,寄存器文件就是Ll 的高速缓存, Ll 是L2 的高速缓存, L2 是L3 的高速缓存, L3 是主存的高速缓存,而主存又是磁盘的高速缓存。在某些具有分布式文件系统的网络系统中,本地磁盘就是存储在其他系统中磁盘上的数据的高速缓存。
几个关键的层次访问速度:
除了本文主角CPU高速缓存外,计算机系统还有很多利用“缓存”的地方:
-
缓存(cache)大小是CPU的重要指标之一,其结构与大小对CPU速度的影响非常大。简单地讲,缓存就是用来存储一些常用或即将用到的数据或指令,当需要这些数据或指令的时候直接从缓存中读取,这样比到内存甚至硬盘中读取要快得多,能够大幅度提升cpu的处理速度。
-
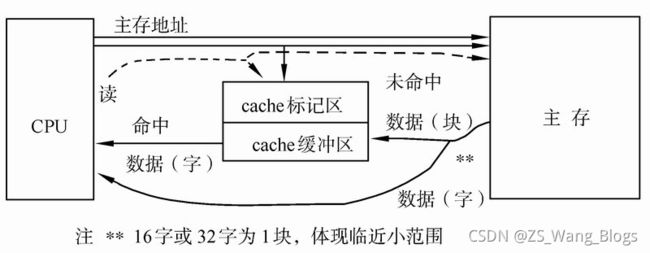
CPU与cache之间的数据交换是以”字”为单位,而cache与主存之间的数据交换是以”块”为单位,一个块由若干字组成,是定长的,以体现”保存下级存储器刚才被存取过的数据及其邻近小范围的数据”这一概念。
-
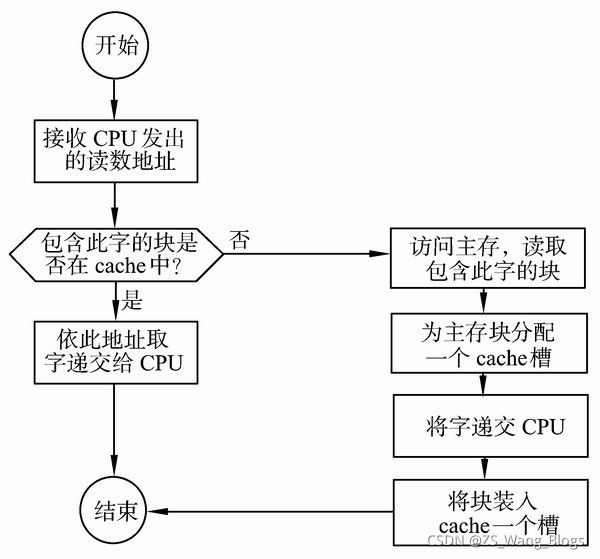
CPU进行存储器读操作时,根据主存地址可分成命中和未命中两种情况。对于前者,从Cache中可直接读到所需的数据;对于后者,需访问主存,并将访问单元所在的整个块从内存中全部调入Cache,接着要修改Cache标记。若Cache已满,需按一定的替换算法,替换掉一个旧块。
-
一级缓存中还分数据缓存(data cache,d-cache)和指令缓存(instruction cache,i-cache)。二者分别用来存放数据和执行这些数据的指令,而且两者可以同时被cpu访问,减少了争用cache所造成的冲突,提高了处理器效能。
-
采用分立Cache技术,也就是将指令和数据分开,分别存放在指令Cache 和数据Cache中。这种分立Cache技术有利于CPU采用流水线方式执行指令。在流水线中,往往会发生在同一个操作周期同时需要预取一条指令和执行另一条指令的取数据操作的情况。若采用指令和数据统一的Cache,则这种情况会造成取指令和取数据的访存冲突,冲突的结果就是使得流水线产生断流的情况发生,从而严重影响流水线的效率。采用分立Cache技术,因为取指令和取数据分别在不同的Cache中同时进行,因而不会产生冲突,有利于流水线的实现
-
二级缓存(L2 CACHE)出现是为了协调一级缓存与内存之间的速度。最初缓存只有一级,后来处理器速度又提升了,一级缓存不够用了,于是就添加了二级缓存。二级缓存是比一级缓存速度更慢,容量更大的内存,主要就是做一级缓存和内存之间数据临时交换的地方用。“L1级Cache-L2级Cache-主存”这种层次从工作原理上讲与前述的Cache工作原理是完全相同的,即CPU首先访L1级Cache,若不命中,再访问L2级Cache和主存。
Cache/主存系统的读操作原理:
当CPU试图读取主存一个字时,发出此字内存地址同时到达cache和主存,此时cache控制逻辑依据地址的标记部分进行判断此字当前是否在cache中。若是(命中),此字立即递交给CPU,若否(未命中),则要用主存读取周期把这个字从主存读出送到CPU,与此同时把含有这个字的整个数据块从主存读出送到cache中。由于程序的存储器访问具有局部性,当为满足一次访问需求而取来一个数据块时,下面的多次访问很可能是读取此块中的其它字。
二、linux的页高速缓存(cache)
细心的朋友到这里会发现,怎么又有一个cache,刚才说cache是CPU高速缓存,怎么这里又叫页高速缓存,一个类型?
其实不然,两个同名,但是意思不同。
- CPU高速缓存是CPU——SRAM(cache)——DRAM(主存)
- 页高速缓存是内核读写——DRAM(主存)——ROM(磁盘),页高速缓存cache在主存里
页高速缓存(cache)是Linux内核实现磁盘缓存。磁盘高速缓存是一种软件机制,**它允许系统把通常存放在磁盘上的一些数据保留在 RAM 中,以便对那些数据的进一步访问不用再访问磁盘而能尽快得到满足。**它主要用来减少对磁盘I/O操作。是通过把磁盘中的数据缓存到 物理内存中,把对磁盘的访问变为对物理内存的访问。
注:页高速缓存叫cache,也叫page cache
页高速缓存(cache)和CPU高速缓存cache的工作模式相似
- 当内核从磁盘中读取数据时,内核试图先从高速缓冲中读。如果数据已经在该高速缓冲中,则内核可以不必从磁盘上读。如果数据不在该高速缓冲中,则内核从磁盘上读数据,并将其缓冲起来。
- 写操作与之类似,要往磁盘上写的数据也被暂存于高速缓冲中,以便如果内核随后又试图读它时,它能在高速缓冲中。内核也通过判定是否数据必须真的需要存储到磁盘上,或数据是否是将要很快被重写的暂时性数据,来减少磁盘写操作的频率。
几乎所有的文件读和写操作都依赖于页高速缓存。只有在O_DIRECT标志被置位而进程打开文件的情况下才会出现例外:此时,IO数据绕过了页高速缓存,而使用了进程用户态地址空间的缓冲区;少数数据库应用软件为了能采用自己的磁盘高速缓存算法而使用O_DIRECT标志。
O_DIRECT:
一般如果在Linux内核中读写一个文件,其IO流程都需要经过Kernel内的page cache层次,若想要使用自己开发的缓存系统,那么就可以在打开这个文件的时候,对该文件加以O_DIRECT的标志位,这样一来就可以让程序对该文件的IO直接在磁盘上进行,从而避开了Kernel的page cache,进而对IO流程里的块数据进行拦截,让其流入到自己开发的缓存系统内。
作者:Nothing_655f
链接:https://www.jianshu.com/p/7c891a002a4e
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
页高速缓存中的信息单位是一个完整的页。
一个页包含的磁盘块在物理上不一定相邻,所以不能用设备号和块号标识,而是通过页的所有者和所有者数据中的索引来识别。
2.1 address_space 对象
页高速缓存的核心数据结构是 address_space 对象,它是一个嵌入在页所有者的索引节点对象中的数据结构。
高速缓存中的许多页可能属于同一个所有者,从而可能被链接到同一个 address_space 对象该对象还在所有者的页和对这些页的操作之间建立起链接关系。
- 每个页描述符都包括把页链接到页高速缓存的两个字段mapping和index。mapping字段指向拥有页的索引节点的address_space对象,index字段表示在所有者的地址空间中以页大小为单位的偏移量,也就是在所有者的磁盘映像中页中数据位置。在页高速缓存中查找页时使用这两个字段。
- address_space 对象的字段
struct address_space {
struct inode *host; /* owner: inode, block_device 指向拥有该对象的索引节点的指针*/
struct radix_tree_root page_tree; /* radix tree of all pages 表示拥有者页的基数radix tree 的根*/
spinlock_t tree_lock; /* and lock protecting it 保护基树的自旋锁 */
atomic_t i_mmap_writable;/* count VM_SHARED mappings 地址空间中共享内存映射的个数*/
struct rb_root i_mmap; /* tree of private and shared mappings radix优先搜索树的根 */
struct rw_semaphore i_mmap_rwsem; /* protect tree, count, list */
/* Protected by tree_lock together with the radix tree */
unsigned long nrpages; /* number of total pages */
unsigned long nrshadows; /* number of shadow entries */
pgoff_t writeback_index;/* writeback starts here */
const struct address_space_operations *a_ops; /* methods */
unsigned long flags; /* error bits/gfp mask */
spinlock_t private_lock; /* for use by the address_space */
struct list_head private_list; /* ditto */
void *private_data; /* ditto */
}
- address_space对象就嵌入在VFS索引节点(inode)对象的i_data字段中。
- 索引节点(inode)的i_mapping字段总是指向索引节点的数据页所有者的address_space对象。
- address_space对象的host字段指向其所有者的索引节点对象。
address_space 对象的方法
- writepage 写操作,从页写到所有者的磁盘映像
- readpage 读操作,从所有者的磁盘映像读到页
- sync_page 如果对所有者页进行的操作已准备好,则立刻开始I/O数据的传输
- writepages 把指定数量的所有者脏页写回磁盘。
- set_page_dirty 把所有者的页设置为脏页
- readpages 从磁盘中读所有者页的链表
- prepare_write 为写操作做准备(由磁盘文件系统使用)
- commit_write 完成写操作(由磁盘文件系统使用)
- bmap 从文件块索引中获取逻辑块号
- invalidatepage 是所有者的页无效(截断文件时使用)
- releasepage 由日志文件系统使用以准备释放页
- direct_IO 所有者页的直接I/O传输 (绕过了页高速缓存 page cache)
2.2 基树
address_space 对象的page_tree字段是基树(radix tree)的根。
找页的工作原理:内核可以通过此索引结构树快速判断所需要的页是否在页高速缓存中。当查找所需要的页时,内核把页索引转换为基树的路径,并快速找到页描述符所在位置。如果找到,内核可以从基树获得页描述符,并且确定所找到的页是否是脏页,以及其数据是否正在进行。
什么是脏页:
linux是以页作为高速缓存的单位,当进程修改了高速缓存里的数据时,该页就被内核标记为脏页,内核将会在合适的时间把脏页的数据写到磁盘中去,以保持高速缓存中的数据和磁盘中的数据是一致的。
2.3 页高速缓存的处理函数
- 查找页
- find_get_page()
- 增加页
- add_to_page_cache(); 把新的页描述符插入到页高速缓存中。
- 删除页
- remove_from_page_cache()
- 更新页
- read_cache_page() 确保高速缓存中包含最新版本的指定页。
- 基树的标记
- 页高速缓存允许内核快速获得含有块设备中指定数据的页。
- 允许内核从高速缓存中快速获得给定状态的页。
- 基树中的每个中间节点都包含一个针对每个孩子节点(或叶子节点)的脏标记PG_dirty。目的:当内核遍历基树搜索脏页时,就可以跳过脏标记为0的中间节点的所有子树:中间结点的脏标记为0说明其子树中的所有页描述符都不是脏的。 同样的想法应用到PG_writeback,该标志表表示页正在被写回磁盘。设置这两个标记时调用函数radix_tree_tag_set().清除标志时调用函数radix_tree_tag_clear()。
- 从基树删除页描述符时,必须更新从根结点到叶子结点的路径中结点的相应标记。radix_tree_delete()函数来完成。但是radix_tree_insert()函数不更新标记(上面的两个),如果需要调用radix_tree_tag_set()。
- 函数find_get_pages_tag() 和find_get_pages()类似,前者返回的是只是那些用tag参数标记的页。
2.4 把块放在页高速缓存中
VFS(映射层)和各种文件系统以“块”的逻辑单位组织磁盘数据。
在linux内核旧版本中,主要有两种不同的磁盘高速缓存:页高速缓存和缓冲区高速缓存,前者用来存放磁盘文件内容时生成的磁盘数据页,后者把VFS访问的块的内容保留在内存中。当时2.4.10后缓冲区高速缓存不再存在。也就是我们说的buffer cache不再存在,而是统一都存放进了page cache中。-----把它们存放在叫做“缓冲区页”的专门页中。
为什么buffer cache不再存在?
对于上面的描述可以查看https://lwn.net/Articles/712467/

Now, the buffer cache still exists, but its entries point into the page cache.
可以通过查看sys_read和sys_write的系统调用流程可知,读写操作基本都是page_cache, map也是使用page_cache,即在linux内核,已经没有buffer cache,被page cache代替。但是查看mmc的代码,还是有buffer的概念,因为无论你怎么变 最终还是要写回到磁盘
笔者在学page cache的时候,被这句“buffer cache不再存在,而是统一都存放进了page cache中”,深感疑惑,最终查阅代码证实确实如此,其实,当你有疑惑的时候,就得去实践加深,因为你有疑惑很大原因是你的知识体系支撑不了你对概念的理解,学习是螺旋上升的过程,要理论和实践相结合
我们也不要被概念束缚住,无论是buffer cache还是page
cache都是磁盘缓存,作用是把数据缓存到物理内存(主存)中,以便写的时候CPU可以去做其他事,读的时候,可以立刻从物理内存中命中。
然后去配合代码去看看真实的世界是不是和作者说的一样,书中的是别人的理解,你自己的理解,最终要你自己去实践,去感悟总结

块缓冲区和缓冲区首部
上面说了VFS(映射层)和各种文件系统以“块”的逻辑单位组织磁盘数据,并且buffer cache不再存在,而是统一都存放进了page cache中。-----把它们存放在叫做“缓冲区页”的专门页中。
Linux为了加速读写速度,采用了pagecache机制,用内存缓存磁盘内容,而buffer_head正是连接page和磁盘块的关键结构
每个块缓冲区都有 buffer_head 类型的缓冲区首部描述符,包含内核必须了解的、有关如何处理块的所有信息。
buffer_head 的一些字段:
- b_dev:包含块的块设备,通常是磁盘或分区。
- b_blocknr:逻辑块号,即块在磁盘或分区中的编号。
- b_data:块缓冲区在缓冲区页中的位置。
如果页在高端内存,则 b_data 存放的是块缓冲区相对于页的起始位置的偏移量,否则,b_data 存放块缓冲区的线性地址。 - b_state:几个标志。
块缓冲区是页框的一部分,因此不用特别描述块缓冲区中的数据。每个块缓冲区都对应一个块缓冲区头buffer_head,他们的关系如同物理页框和物理页框描述符,前者用来存储数据,后者是对前者的属性以及控制信息的描述。 块缓冲区头、块缓冲区以及页框的关系如下:

以一个宏观的图来看块缓存区
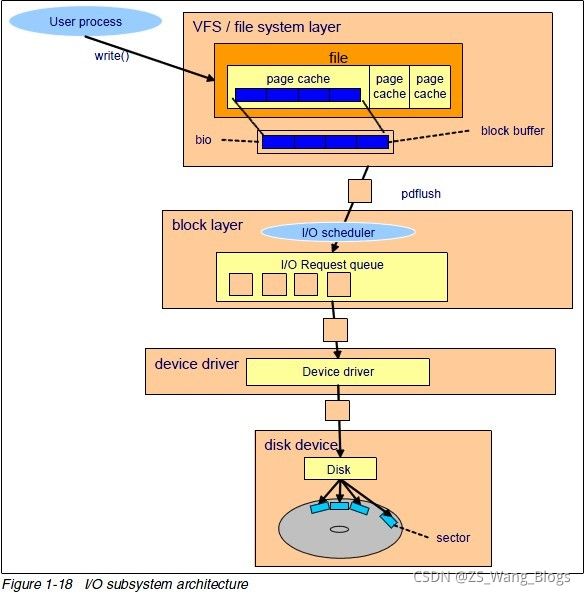
在上面的图中,
- 文件的读写通过page_cache
- page_cache存储数据,buffer_head对page_cache的属性以及控制信息的进行描述
bio是对block的IO操作结构体,为通用块层请求,代表来自上层的请求, 每个bio表示不同的访问上下文。
最后请求到磁盘中,linux上是用结构体gendisk来代表块设备,disk表示磁盘,sector表示扇区
Linux 页高速缓存之buffer head可以参考:https://blog.csdn.net/bin_linux96/article/details/111315531
页大小查看: getconf PAGE_SIZE,常见为4K;
磁盘块大小查看:stat /boot/|grep “IO Block”,常见为4K;
扇区大小查看:fdisk -l,常见为512Byte;
向通用块层提交缓冲区首部
submit_bh() 和 ll_rw_block() 允许内核对缓冲区首部描述的一个或多个缓冲区进行 I/O 数据传送。
- submit_bh()
向通过块层传递一个缓冲区首部,并由此请求传输一个数据块。
参数为数据传输的方向(READ 或 WRITE)和指向描述符块缓冲区的缓冲区首部的指针 bh。
submit_bh() 只是一个起连接作用的函数,它根据缓冲区首部的内容创建一个 bio 请求,随后调用generic_make_request()。 - ll_rw_block
要传输的几个数据块不一定物理上相邻。
参数由数据传输的方向(READ 或 WRITE)、要传输的数据块的块号、指向块缓冲区所对应的缓冲区首部的指针数组。
2.5 脏页
只要进程修改了数据,相应的页就被标记为脏页,其 PG_dirty 标志置位。
在下列条件下把脏页写入磁盘:
- 页高速缓存变得太满,但还需要更多的页,或脏页的数据已经太多。
- 自从页变成脏页以来已经过去太长时间。
- 进程请求对块设备或特定文件任何带动的变化都进行刷新。通过调用 sync()、fsync() 或 fdatasync() 实现。
与每个缓冲区页相关的缓冲区首部使内核能了解每个独立块缓冲区的状态。
如果至少有一个缓冲区首部的 BH_Dirty 标志被置位,就设置相应缓冲区页的 PG_dirty 标志。
当内核选择要刷新的缓冲区页时,它扫描相应的缓冲区首部,并只把脏块的内容写到磁盘。
一旦内核把缓冲区的所有脏页刷新到磁盘,就把页的 PG_dirty 标记清 0。
脏页的作用:标记那些数据还没有更新到磁盘里
进程修改了数据,相应的页就被标记为脏页,置1,更新到磁盘后,置0
2.6 pdflush 内核线程
早期版本的Linux使用bdflush内核线程系统地扫描页高速缓存以搜索要刷新的脏页,并且使用另一个内核线程kupdate来保证所有的页不会“脏”太长的时间。Linux 2.6用一组通用内核线程pdflush代替上述两个线程。
回写陈旧的脏页
脏页在保留一定时间后,内核就显式地开始进行 I/O 数据的传输,把脏页的内容写到磁盘。
回写陈旧脏页的工作委托给了被定期唤醒的 pdflush 内核线程。
在内核初始化期间, page_writeback_init() 建立 wb_timer 动态定时器,以便定时器的到期时间发生在 dirty_writeback_ccentisecs 文件中规定的几百分之一秒后。
sync()、fsync() 和 fdatasync() 系统调用
- sync():允许进程把所有脏缓冲区刷新到磁盘。
- fsync():允许进程把属于特定打开文件的所有块刷新到磁盘。
- fdatasync():与 fsync() 相似,但不刷新文件的索引节点块。
我们可以通过cat /proc/meminfo查看脏页的大小:

当我们在终端执行sync后,再次查看:

可以看到Dirty已经变成了0,即脏页已经被更新到磁盘里,已经清0
2.7 linux的free
参考:https://www.cnblogs.com/chenpingzhao/p/5161844.html
参考:https://www.cnblogs.com/blackangeldsf/p/9360701.html
参考:http://blog.chinaunix.net/uid-24020646-id-2939696.html
前面我们介绍了CPU高速缓存cache,知道它的存在是因为CPU的速度大于内存的速度,需要cache作为中间人来做数据的缓存,以便不耽误CPU做其他事情。并且介绍了页高速缓存,知道它是把磁盘的数据缓存到RAM中,以便后面内核快速读写
通过free命令,可以看到
[root@localhost ~]# free -m
total used free shared buffers cached
Mem: 7869 7651 218 1 191 5081
-/+ buffers/cache: 2378 5490
Swap: 478 139 339
其中:
这里使用1、2 分别代表第一行和第二行的数据
total1:表示物理 内存总量
used1:表示总计分配给缓存(包含buffers 与cache )使用的数量,但其中可能部分缓存并未实际使用
free1:未被分配的内存
shared1:共享内存,一般系统不会用到,这里也不讨论
buffers1: 系统分配但未被使用的buffers 数量
cached1:系统分配但未被使用的cache 数量
used2:实际使用的buffers 与cache 总量,也是实际使用的内存总量
free2:未被 使用的buffers 与cache 和未被分配的内存之和,这就是系统当前实际可用内存
可以整理出如下等式
total1 = used1 + free1
total1 = used2 + free2
used1 = buffers1 + cached1 + used2
free2 = buffers1 + cached1 + free1
具体计算:
7869 = 7651 + 218
7869 = 2378 + 5490 #7868基本相等,因为有shared)
7651 = 191 + 5081 + 2378 #7650 基本相等,因为有shared)
5490 = 191 + 5081 + 218
为什么这样计算呢,因为buffers和cache其实也是内存的一部分,这部分特殊的内存是可以回收的,甚至如果需要我们还可以将这部分buffers和cache给释放出来
Buffers :说明缓存块设备读写的内存大小(buffer cache),这部分缓存主要用于
目录项、inode等文件系统元数据。如果ls一个包含很多内容的目录,可以
发现这个值明显增大。
Cache :说明用于缓存文件系统读写的内存大小(page cache),这部分缓存主要用于
打开的文件,如果 cache 的值很大,说明缓存的文件较多,在进行读写时,命
中率也将提高,如果频繁访问到的文件大部分被缓存,则必然减少磁盘的读IO。
It is similar like "Buffers", only this time it caches pages from file reading.
2.7.1 区别
page cache和buffer cache
在前面已经说了,现在内核已经没有buffer cache了,已经统一成page cache
那为什么free里还是有buffers呢,因为2.6内核中的buffer cache和page cache在处理上是保持一致的,但是存在概念上的差别,page cache针对文件的cache,buffer是针对磁盘块数据的cache,仅此而已。 当page cache的数据需要刷新时,page cache中的数据交给buffer cache,但是这种处理在2.6版本的内核之后就变的很简单了,没有真正意义上的cache操作。
参考2.4 把块放在页高速缓存中,虽然统一成page cache,但是内核仍有块缓存区,仍有buffer的定义,笔者认为,linux开发者free里保留了buffers和cache,应该只是为了历史区分,毕竟两者的定义不一样,只是后期把他整合到page cache。
注意:不要过多纠结page cache和buffer cache,以作用为主(感觉说多了我自己都带偏了,-_-||,以后学精了,再回来吧,先留下一个坑)
2.7 页高速缓存的总结:
这么的知识点大多是块设备的知识点,这里不做过多讨论,对于页高速缓存page cache
,我们记住以下几点:
- 了解的页高速缓存page cache定义和作用
- 内核读写在没有O_DIRECT时,会使用到页高速缓存page cache进行数据缓存
- 在有O_DIRECT时,会跳过page cache直接对磁盘进行读写
- 了解page cache和块设备怎么建立连接
- 什么是脏页,脏页的作用,哪个进程来负责脏页的更新
- 怎么通过命令来把所有脏缓冲区刷新到磁盘。
- bio,sector的定义