分布式事务 - XA协议 以及2PC ,3PC, TCC,消息事务
背景
分布式事务:是每一个分布式系统架构中都会涉及到的一个东西,特别是在微服务架构中,几乎可以说是无法避免。
ACID

指数据库事务正确执行的四个基本要素:
- 原子性(Atomicity)
- 一致性(Consistency)
- 隔离性(Isolation)
- 持久性(Durability)
关于CAP
CAP原则
上百度百科 : 本词条由“科普中国”科学百科词条编写与应用工作项目 审核 。
CAP原则又称CAP定理,指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。

- 一致性:在分布式系统中的所有数据备份,在同一时刻是否同样的值。
- 可用性:在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。
- 分区容忍性:以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
“这三个要素最多只能同时实现两点,不可能三者兼顾 " 实际上都是以P为出发点,保障分区容错的前提下,是选择一致性,还是可用性。在分布式前提下,需要网络通信,因为网络本身无法做到 100% 可靠,所以P必选要素。如果, 选择了 CA(一致性 + 可用性) 而放弃了 P(分区容忍性),当发分区错误时,为了保证 C(一致性)需要禁止写入 ,这又和 A(可用性) 冲突了。因此,分布式系统理论上不可能选择 CA (一致性 + 可用性)架构,只能, 选择 CP(一致性 + 分区容忍性) 或者 AP (可用性 + 分区容忍性)架构,在一致性和可用性做折中选择。
关于BASE理论
BASE理论是对CAP中的一致性和可用性进行一个权衡的结果(偏向高可用)。
理论的核心思想就是:我们无法做到强一致,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性。
- Basically Available(基本可用)
- Soft state(软状态)
- Eventually consistent(最终一致性)
关于XA协议
这里可以参考The Open Group 的 文档 : https://pubs.opengroup.org/onlinepubs/009680699/toc.pdf
(1):什么是XA协议:
Distributed Transaction Processing(DTP)
DTP是一种实现分布式事务处理系统的概念模型,OSI和Open/X都有正式文档来定义它:
- X/Open Guide, Distributed Transaction Processing Reference Model, X/Open Company Ltd., October 1991.
- The ISO/IEC Open Systems Interconnection (OSI) Distributed Transaction Processing (DTP) standard.
- ISO/IEC DIS 10026-1 (1991) (model)
- ISO/IEC DIS 10026-2 (1991) (service)
- ISO/IEC DIS 10026-3 (1991) (protocol)
在DTP的经典结构图中,整套系统由三种角色构成:

应用程序 (Application Program,AP)
AP要做两件事:
1,一方面是定义构成整个事务所需要的所有操作,
2,另一方面是亲自访问资源节点来执行操作。
The AP defines ** transactions ** and accesses ** resources **
within transaction boundaries.
资源管理器(Resource Managers,RM)
RM是管理着某些共享资源的自治域 :
比如说一个MySQL数据库实例。
在DTP里面有两个要求:
一是RM自身必须是支持事务的。
二是RM能够根据 分布式事务标识定位到自己内部的对应事务。
Every RM in the DTP environment must support transactions as
described in Section 2.2.1 on page 4
An RM is responsible for mapping its recoverable units of work to
the global transaction
事务管理器(Transaction Manager,TM)
TM能与AP和RM直接通信:
协调AP和RM来实现分布式事务的完整性。
主要的工作是提供AP注册全局事务的接口,颁发全局事务标识(GTID之类 的),存储/管理全局事务的内容和决策并指挥RM做commit/rollback。
(2)什么时候使用XA协议:
首先,考虑尽量不要使用XA,因为这样可能会增加系统的复杂程度,和维护成本。
其次,如果应用可能使用到多个资源,且这些资源必须在同一个事务范畴内被协调时,才有必要用到XA。
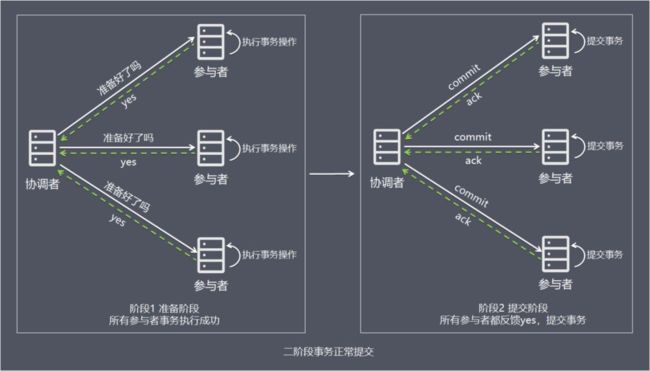
两阶段提交2PC
基于XA协议的两阶段提交,2PC即两阶段提交协议, 是将整个事务流程分为两个阶段 :
阶段1:准备阶段(Prepare phase),声明后是否可以开启事务.
阶段2: 提交阶段(commit phase),是否可以提交事务.
2PC的传统方案是在数据库层面实现的,如Oracle、MySQL都支持2PC协议,商业数据库实现了XA协议,使用分布式事务的成本也比较低。
但是,2PC 在实际项目中使用比较少见,因为:
- 性能问题:当有高并发时,参与者在事务提交阶段处于同步阻塞状态,占用系统资源。特别是在交易下单链路,往往并发量很高,XA无法满足高并发场景。
- 可靠性问题:如果协调者出现故障,参与者将一直处于锁定状态。( CP )
- 数据一致性问题:在mysql数据库中支持的不太理想,mysql的XA实现,在阶段 1 中,没有记录prepare阶段日志,主备切换导致主库与备库数据不一致。在阶段 2 中,如果发生局部网络问题,一部分事务参与者收到了提交,另一部分事务参与者没收到提交消息,导致了节点之间数据的不一致。
- 应用场景少:许多nosql也没有支持XA,这让XA的应用场景变得非常狭隘。
未完待续 ........
三阶段提交3PC
三阶段提交是在二阶段提交上的改进版本,主要是加入了超时机制。同时在协调者和参与者中都引入超时机制。

除了引入超时机制之外,3PC把2PC的准备阶段再次一分为二,这样三阶段提交就有CanCommit、PreCommit、DoCommit三个阶段。
CanCommit阶段
CanCommit阶段其实和2PC的准备阶段很像。协调者向参与者发送commit请求,
参与者如果可以提交就返回Yes响应,否则返回No响应。
PreCommit阶段
协调者根据参与者的反应情况来决定是否可以记性事务的PreCommit操作。有以下两种可能:
1.假如协调者从所有的参与者获得的反馈都是Yes响应,那么就会执行事务的预执行。
2.假如有任何一个参与者向协调者发送了No响应,或者等待超时之后,协调者都没有接到参与者的响应,那么就执行事务的中断。
doCommit阶段
该阶段进行真正的事务提交,可以分为以下两种:
1.执行提交
2.中断事务
优点:
1,相比二阶段提交,三阶段提交降低了阻塞范围,在等待超时后协调者或参与者会中断事务。
2,避免了协调者单点问题,阶段 3 中协调者出现问题时,参与者会继续提交事务。
缺点:
数据不一致问题依然存在,当在参与者收到 preCommit 请求后等待 do commite 指令时,此时如果协调者请求中断事务,而协调者无法与参与者正常通信,会导致参与者继续提交事务,造成数据不一致。
2PC与3PC的区别
相对于2PC,3PC主要解决的单点故障问题,并减少阻塞,因为一旦参与者无法及时收到来自协调者的信息之后,他会默认执行commit。而不会一直持有事务资源并处于阻塞状态。
但是这种机制也会导致数据一致性问题,因为,由于网络原因,协调者发送的abort响应没有及时被参与者接收到,那么参与者在等待超时之后执行了commit操作。
这样就和其他接到abort命令并执行回滚的参与者之间存在数据不一致的情况。
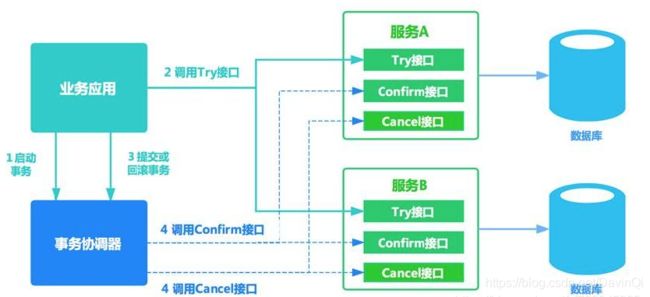
补偿事务TCC
TCC 事务的 Try、Confirm、Cancel 可以理解为 SQL 事务中的 Lock、Commit、Rollback。TCC事务处理流程和 2PC 二阶段提交类似,不过 2PC通常都是在跨库的DB层面,而TCC本质就是一个应用层面的2PC .
Try:预留业务资源/数据效验
Confirm:确认执行业务操作
Cancel:取消执行业务操作
TCC 优缺点 TCC优点:让应用自己定义数据库操作的粒度,使得降低锁冲突、提高吞吐量成为可能。
TCC不足之处:
1、对应用的侵入性强。业务逻辑的每个分支都需要实现try、confirm、cancel三个操作,应用侵入性较强,改造成本高。
2、实现难度较大。需要按照网络状态、系统故障等不同的失败原因实现不同的回滚策略。为了满足一致性的要求,confirm和cancel接口必须实现幂等。
TCC 事务应用场景
我们通过用户下单使用余额+红包支付来看一下TCC事务的具体应用。
MQ消息事务
参考: 阿里云事务消息 https://help.aliyun.com/document_detail/43348.html
事务消息 就是基于消息中间件的两阶段提交,本质上是对消息中间件的一种特殊利用,它是将本地事务和发消息放在了一个分布式事务里,保证要么本地操作成功成功并且对外发消息成功,要么两者都失败,开源的RabbitMQ , RocketMQ就支持这一特性。
虽然上面的方案能够完成多个子程序操作,但是并不是严格一致的,而是最终一致的,我们在这里牺牲了一致性,换来了性能的大幅度提升。

基于RocketMQ解决分布式事务

原理分析:
生产者向Broker投递半消息,(半消息是不能被消费者进行消费的)
Broker返回消息投递成功的结果
生产者执行本地事务,再将本地事务的结果返回给Broker
本地事务提交有两种情况,如果返回的成功是,COMMIT,则代表事务成功执行,然后标记该半消息可以为消费者消费。如果事务返回的是ROLLBACK,则代表事务执行失败,进行了回滚,Broker将会把该半消息移除
broker根据事务结果决定该半消息是否让消费者消费
如果本地事务执行时间太久,或者是因为网络原因导致本地事务结果没有告诉Broker,Broker将每隔一分钟主动查询一次本地事务执行的结果。总共重试15次。以此判断半消息是否可以被消费
优点
RocketMQ具有重试机制、持久化机制、分区机制、天生抗并发能力强。
RocketMQ已经帮我们解决了分布式事务
缺点

- 2PC/3PC:依赖于数据库,能够很好的提供强一致性和强事务性,但相对来说延迟比较高,比较适合传统的单体应用,在同一个方法中存在跨库操作的情况,不适合高并发和高性能要求的场景。
- TCC:适用于执行时间确定且较短,实时性要求高,对数据一致性要求高,比如互联网金融企业最核心的三个服务:交易、支付、账务。
- 本地消息表/MQ 事务:都适用于事务中参与方支持操作幂等,对一致性要求不高,业务上能容忍数据不一致到一个人工检查周期,事务涉及的参与方、参与环节较少,业务上有对账/校验系统兜底。
- Saga 事务:由于 Saga 事务不能保证隔离性,需要在业务层控制并发,适合于业务场景事务并发操作同一资源较少的情况。 Saga 相比缺少预提交动作,导致补偿动作的实现比较麻烦,例如业务是发送短信,补偿动作则得再发送一次短信说明撤销,用户体验比较差。Saga 事务较适用于补偿动作容易处理的场景。
| 解决方案 |
协议 |
优缺点 |
优缺点 |
应用场景 |
|
| 强一致性 |
两阶段提交协议(2PC) |
XA协议,由Tuxedo提出 |
1、 同步阻塞问题; 2、 单点故障; |
1、极端情况下数据的不一致性; 2、引入事务管理者(协调者),单点故障; 3、系统可伸缩性存在问题; 4、全局事务结束才能释放资源,性能问题; |
在高并发场景下很少使用。 |
| 三阶段提交协议(3PC) |
1、超时机制解决同步阻塞问题; 2、预备阶段尽可能提早发现问题; |
||||
| 最终一致性 |
TCC 模式(Try、Confirm、Cancel)可以理解为SQL事务中的 Lock、Commit、Rollback |
阿里提出 |
1、对于事务恢复,基于 Quartz调度,按照一定频率进行重试。2、要按具体业务来实现,业务耦合度较高,提高了开发成本。 |
部分控制的好处是并发量和性能很好,缺点是数据一致性减弱了,完全控制则是牺牲了性能,保障了一致性,具体用哪种方式,最终还是取决于业务场景。作为技术人员,一定不能忘了技术是为业务服务的,不要为了技术而技术,针对不同业务进行技术选型也是一种很重要的能力! 世界上解决一个计算机问题最简单的方法:“恰好”不需要解决它!如果系统要实现回滚流程的话,有可能系统复杂度将大大提升,且很容易出现 Bug,估计出现 Bug 的概率会比需要事务回滚的概率大很多。可以考虑当出现这个概率很小的问题,能否采用人工解决的方式。 |
tcc-transaction 框架,@Compensable 注解 |
| 补偿模式 |
|
1、重试机制:同步通知、消息队列、定时任务。2、每次更新的时候进行自我恢复和修正。3、定时校对:未完成的定时重试、定时核对。 |
|
||
| 可靠事件模式 |
|
1、正向发送消息:消息持久化到本地数据库,标志状态:待发送、结束、已发送、完成等。2、正向接受消息:ACK机制。3、逆向消息:弥补消息主动丢弃。4、补偿机制:定时任务扫描“未完成”的消息并重新投递。 缺点:1、一次消息发送需要两次网络请求(half 消息+ commit/ rollback消息) 。2、业务处理服务需要实现消息状态回查接口。 |
|
分布式事务框架
微服务中单个服务跨数据库是不规范的,每个服务只能操作自己的数据库。所以JTA方案不常用。
| LCN | LCN模式,TCC模式,TXC模式 主要特点: 支持各种基于spring的db框架 |
具体示例参看:https://www.txlcn.org | |
| ByteTCC | ByteTCC特性 1、支持Spring容器的声明式事务管理; 2、支持普通事务、TCC事务、业务补偿型事务等事务机制; 3、支持多数据源、跨应用、跨服务器等分布式事务场景; 4、支持长事务; 5、支持dubbo服务框架; 6、支持spring cloud; |
具体示例参看 https://github.com/liuyangming/ByteTCC | |
-
Spring+JTA
-
华为servicecomb-pack
-
Hmily
-
byteTCC 基于TCC
-
tcc-transaction
-
阿里 Seata(fescar)
-
PolarDB-X
-
Apache Saga
-
LCN
1. 首先看是否能扩展机器,在有成本的情况下,尽量考虑mq,毕竟已经帮我们做好了重试,消息持久化等功能。
2. RabbitMQ和RockteMQ选型,尽量采用RocketMQ,RabbitMQ扩展和并发能力与RocktMQ相差很远
3. lcn和seata之间选型, 需要保证强一致性CP,就选择lcn(已经停止更新)。如果需要AP,就选择seata。。
参考文档:
https://maimai.cn/article/detail?fid=1122653559&efid=jewbG8cL4Wikr2CJ3r_fAw
https://www.cnblogs.com/monkeyblog/p/10449363.html
https://www.liangzl.com/get-article-detail-525.html