前端面试题题库
前端知识库
HTML+CSS
1. 什么是 DOCTYPE, 有何作用?
Doctype是HTML5的文档声明,通过它可以告诉浏览器,使用哪一个HTML版本标准解析文档。
在浏览器发展的过程中,HTML出现过很多版本,不同的版本之间格式书写上略有差异。
如果没有事先告诉浏览器,那么浏览器就不知道文档解析标准是什么?此时,大部分浏览器将开启最大兼容模式来解析网页,我们一般称为怪异模式,这不仅会降低解析效率,而且会在解析过程中产生一些难以预知的bug,所以文档声明是必须的。
2.html 语义化
HTML标签的语义化,简单来说,就是用正确的标签做正确的事情,给某块内容用上一个最恰当最合适的标签,使页面有良好的结构,页面元素有含义,无论是谁都能看懂这块内容是什么。
语义化的优点如下:
- 在没有CSS样式情况下也能够让页面呈现出清晰的结构
- 有利于SEO和搜索引擎建立良好的沟通,有助于爬虫抓取更多的有效信息,爬虫是依赖于标签来确定上下文和各个关键字的权重
- 方便团队开发和维护,语义化更具可读性,遵循W3C标准的团队都遵循这个标准,可以减少差异化3.src 和 href 的区别
src和href都是HTML中特定元素的属性,都可以用来引入外部的资源。两者区别如下:
- src:全称source,它通常用于img、video、audio、script元素,通过src指向请求外部资源的来源地址,指向的内容会嵌入到文档中当前标签所在位置,在请求src资源时,它会将资源下载并应用到文档内,比如说:js脚本、img图片、frame等元素。当浏览器解析到该元素时,会暂停其它资源下载,直到将该资源加载、编译、执行完毕。这也是为什么将js脚本放在底部而不是头部的原因。
- href:全称hyper reference,意味着超链接,指向网络资源,当浏览器识别到它指向的⽂件时,就会并⾏下载资源,不会停⽌对当前⽂档的处理,通常用于a、link元素。
3.HTML5新增了哪些新特性?移除了哪些元素?
HTML5主要是关于图像、位置、存储、多任务等功能的增加:
- 语义化标签,如:article、footer、header、nav等
- 视频video、音频audio
- 画布canvas
- 表单控件,calemdar、date、time、email
- 地理
- 本地离线存储,localStorage长期存储数据,浏览器关闭后数据不丢失,sessionStorage的数据在浏览器关闭后自动删除
- 拖拽释放
移除的元素:
- 纯表现的元素:
basefont、font、s、strike、tt、u、big、center - 对可选用性产生负面影响的元素:
frame、frameset、noframes
4.CSS3 新增了那些东西?
CSS3 新增东西众多,这里列举出一些关键的新增内容:
- 选择器
- 盒子模型属性:border-radius、box-shadow、border-image
- 背景:background-size、background-origin、background-clip
- 文本效果:text-shadow、word-wrap
- 颜色:新增 RGBA,HSLA 模式
- 渐变:线性渐变、径向渐变
- 字体:@font-face
- 2D/3D转换:transform、transform-origin
- 过渡与动画:transition、@keyframes、animation
- 多列布局
- 媒体查询
5.行内元素和块级元素的区别
| 区别 | 行内元素 | 块级元素 |
|---|---|---|
| 宽高 | 无效 | 有效 |
| padding | 有效 | 有效 |
| margin | 水平方向有效 | 有效 |
| 自动换行 | 不可以 | 可以 |
| 多个元素排列 | 默认从左到右 | 默认从上到下 |
6.行内元素和块级元素分别有哪些?有何区别?怎样转换?
常见的块级元素:p、div、form、ul、li、ol、table、h1、h2、h3、h4、h5、h6、dl、dt、dd
常见的行级元素:span、a、img、button、input、select
块级元素:
- 总是在新行上开始,就是每个块级元素独占一行,默认从上到下排列
- 宽度缺少时是它的容器的100%,除非设置一个宽度
- 高度、行高以及外边距和内边距都是可以设置的
- 块级元素可以容纳其它行级元素和块级元素
行内元素:
- 和其它元素都会在一行显示
- 高、行高以及外边距和内边距可以设置
- 宽度就是文字或者图片的宽度,不能改变
- 行级元素只能容纳文本或者其它行内元素
使用行内元素需要注意的是:
- 行内元素设置宽度
width无效 - 行内元素设置
height无效,但是可以通过line-height来设置 - 设置
margin只有左右有效,上下无效 - 设置
padding只有左右有效,上下无效
可以通过display属性对行内元素和块级元素进行切换(主要看第 2、3、4三个值):
7.title* 与 h1 的区别、b 与 strong 的区别、i 与 em 的区别?
- title 属性表示网页的标题,h1 元素则表示层次明确的页面内容标题,对页面信息的抓取也有很大的影响
- strong 是标明重点内容,有语气加强的含义,使用阅读设备阅读网络时:strong会重读,而b是展示强调内容
- i 是italic(斜体)的简写,是早期的斜体元素,表示内容展示为斜体,而 em 是emphasize(强调)的简写,表示强调的文本
8. img上 title 与 alt
- alt:全称
alternate,切换的意思,如果无法显示图像,浏览器将显示alt指定的内容 - title:当鼠标移动到元素上时显示title的内容
区别:
一般当鼠标滑动到元素身上的时候显示title,而alt是img标签特有的属性,是图片内容的等价描述,用于图片无法加载时显示,这样用户还能看到关于丢失了什么东西的一些信息,相对来说比较友好。
9.label的作用是什么?是怎么用的?
label元素不会向用户呈现任何特殊效果,但是,它为鼠标用户改进了可用性,当我们在label元素内点击文本时就会触发此控件。也就是说,当用户选择该标签时,浏览器就会自动将焦点转到和标签相关的表单控件上。最常用label的地方就是表单中的性别单选框了,当点击文字时也能够自动聚焦绑定的表单控件。
<form>
<label for="male">男label>
<input type="radio" name="sex" id="male">
<label for="female">女label>
<input type="radio" name="sex" id="female">
form>
10.对于Web标准以及W3C的理解
Web标准简单来说可以分为结构、表现、行为。其中结构是由HTML各种标签组成,简单来说就是body里面写入标签是为了页面的结构。表现指的是CSS层叠样式表,通过CSS可以让我们的页面结构标签更具美感。行为指的是页面和用户具有一定的交互,这部分主要由JS组成
W3C,全称:world wide web consortium是一个制定各种标准的非盈利性组织,也叫万维网联盟,标准包括HTML、CSS、ECMAScript等等,web标准的制定有很多好处,比如说:
- 可以统一开发流程,统一使用标准化开发工具(VSCode、WebStorm、Sublime),方便多人协作
- 学习成本降低,只需要学习标准就行,否则就要学习各个浏览器厂商标准
- 跨平台,方便迁移都不同设备
- 降低代码维护成本
11.怎么处理HTML5新标签兼容问题?
主要有两种方式:
- 实现标签被识别:通过
document.createElement(tagName)方法可以让浏览器识别新的标签,浏览器支持新标签后。还可以为新标签添加CSS样式 - 用JavaScript解决:使用HTML5的shim框架,在
head标签中调用以下代码:
<!--[if lt IE 9]>
<script> src="http://html5shim.googlecode.com/svn/trunk/html5.js"</script>
<![endif]-->
12.如何实现在一张图片上的某个区域做到点击事件
我们可以通过图片热区技术:
- 插入一张图片,并设置好图像的有关参数,在``标记中设置参数
usemap="#Map",以表示对图像地图的引用。 - 用``标记设定图像地图的作用区域,并取名:Map;
- 分别用``标记针对相应位置互粉出多个矩形作用区域,并设定好链接参数
href
例:
<body>
<img src="./image.jpg" alt="" usemap="#Map" />
<map name="Map" id="Map">
<area alt="" title="" href="#" shape="poly"
coords="65,71,98,58,114,90,108,112,79,130,56,116,38,100,41,76,52,53,83,34,110,33,139,46,141,75,145,101,127,115,113,133,85,132,82,131,159,117" />
<area alt="" title="" href="#" shape="poly" coords="28,22,57,20,36,39,27,61" />
map>
body>
13.a元素除了用于导航外,还有什么作用?
href属性中的url可以是浏览器支持的任何协议,所以a标签可以用来手机拨号[110](tel:110),也可以用来发送短信[110](sms:110),还有邮件等等
当然,a元素最常见的就是用来做锚点和 下载文件。
锚点可以在点击时快速定位到一个页面的某个位置,而下载的原理在于a标签所对应的资源浏览器无法解析,于是浏览器会选择将其下载下来。
14.px 和 em 的区别
px全称pixel像素,是相对于屏幕分辨率而言的,它是一个绝对单位,但同时具有一定的相对性。因为在同一个设备上每个像素代表的物理长度是固定不变的,这点表现的是绝对性。但是在不同的设备之间每个设备像素所代表的物理长度是可以变化的,这点表现的是相对性
em是一个相对长度单位,具体的大小需要相对于父元素计算,比如父元素的字体大小为80px,那么子元素1em就表示大小和父元素一样为80px,0.5em就表示字体大小是父元素的一半为40px
15. vw、vh 是什么?
vw 和 vh 是 CSS3 新单位,即 view width 可视窗口宽度 和 view height 可视窗口高度。1vw 就等于可视窗口宽度的百分之一,1vh 就等于可视窗口高度的百分之一。
16.块格式化上下文(Block Formatting Context,BFC)
BFC: 块格式化上下文(Block Formatting Context,BFC)是Web页面的可视化CSS渲染的一部分,是布局过程中生成块级盒子的区域,也是浮动元素与其他元素的交互限定区域。
通俗的讲,BFC是一个独立的环境布局,可以理解为一个容器,在这个容器中按照一定的规则进行物品摆放,并且不会影响其他环境中的物品。如果一个元素符合触发BFC的条件,则BFC中的元素布局不受外部影响。
BFC的创建条件
- 根元素:body
- 元素设置浮动:float除none以外的值
- 元素设置绝对定位:position设置为absolute或fixed
- display设置为inline-block、table-cell、table-caption、flex等
- overflow设置为hidden、auto、scroll
BFC的特点
- 垂直方向上,自上而下排列,和文档流的排列方式一致
- 在BFC中上下相邻的的两个容器的margin会重叠
- 计算BFC的高度时,需要计算浮动元素的高度
- BFC区域不会与浮动的容器发生重叠
- BFC是独立的容器,容器内部元素不会影响外部元素
- 每个元素的margin-left值和容器的border-left相接处
BFC的作用
- 解决margin的重叠问题:由于BFC是一个独立的区域,内部的元素和外部的元素互不影响,将两个元素变为两个BFC,就解决了margin重叠的问题
- 解决高度塌陷的问题:对子元素设置浮动后,父元素会发生高度塌陷,即height变为0。只需将父元素变成一个BFC即可,常用的办法是给父元素设置
overflow:hidden - 创建自适应两栏布局:左边的宽度固定,右边的宽度自适应。左侧设置
float:left,右侧设置overflow: hidden。这样右边就触发了BFC,BFC的区域不会与浮动元素发生重叠,所以两侧就不会发生重叠,实现了自适应两栏布局
17.BFC 及其应用
所谓 BFC,指的是一个独立的布局环境,BFC 内部的元素布局与外部互不影响。
触发 BFC 的方式有很多,常见的有:
- 设置浮动
- overflow 设置为 auto、scroll、hidden
- positon 设置为 absolute、fixed
常见的 BFC 应用有:
- 解决浮动元素令父元素高度坍塌的问题
- 解决非浮动元素被浮动元素覆盖问题
- 解决外边距垂直方向重合的问题
18.BFC、IFC、GFC 和 FFC
BFC:块级格式上下文,指的是一个独立的布局环境,BFC 内部的元素布局与外部互不影响。
IFC:行内格式化上下文,将一块区域以行内元素的形式来格式化。
GFC:网格布局格式化上下文,将一块区域以 grid 网格的形式来格式化。
FFC:弹性格式化上下文,将一块区域以弹性盒的形式来格式化。
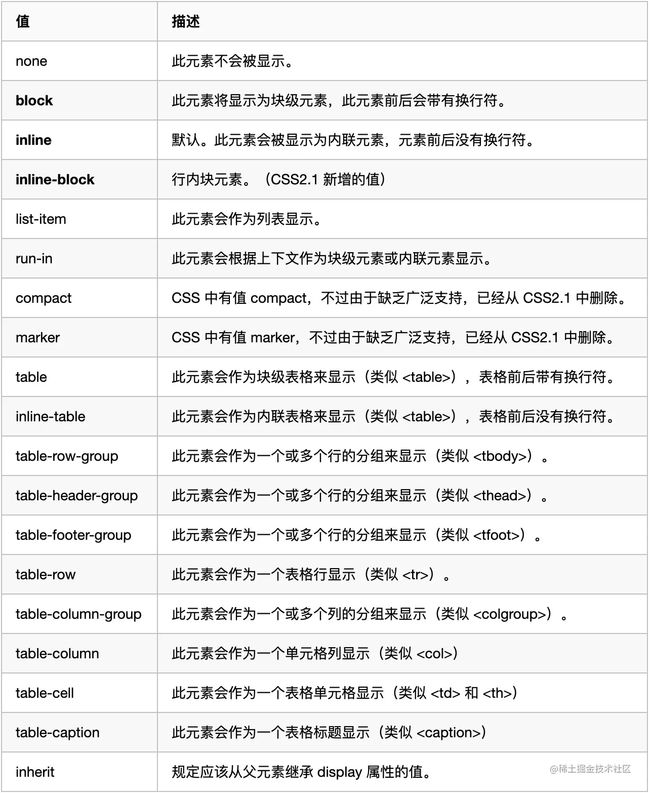
19.display属性值及其作用
| 属性值 | 作用 |
|---|---|
| none | 元素不显示,并且会从文档流中移除 |
| block | 块元素类型。默认宽度为父元素宽度,可设置宽高,换行显示 |
| inline | 行内元素类型。默认宽度为内容宽度,不可设置宽高,同行显示 |
| inline-block | 行内块元素类型。默认宽度为内容宽度,可以设置宽高,同行显示 |
| list-item | 像块类型元素一样显示,并添加样式列表标记 |
| table | 此元素会作为块级表格来显示 |
| inherit | 规定应该从父元素继承display属性的值 |
20.block、inline和inline-block的区别
| 区别 | block | inline | inline-block |
|---|---|---|---|
| 独占一行 | 是 | 否 | 否 |
| width | 是 | 否 | 是 |
| height | 是 | 否 | 是 |
| margin | 是 | 水平方向有效 | 是 |
| padding | 是 | 是 | 是 |
21.flex 布局如何使用?
flex 是 Flexible Box 的缩写,意为"弹性布局"。指定容器display: flex即可。
容器有以下属性:flex-direction,flex-wrap,flex-flow,justify-content,align-items,align-content。
- flex-direction属性决定主轴的方向;
- flex-wrap属性定义,如果一条轴线排不下,如何换行;
- flex-flow属性是flex-direction属性和flex-wrap属性的简写形式,默认值为row nowrap;
- justify-content属性定义了项目在主轴上的对齐方式。
- align-items属性定义项目在交叉轴上如何对齐。
- align-content属性定义了多根轴线的对齐方式。如果项目只有一根轴线,该属性不起作用。
项目(子元素)也有一些属性:order,flex-grow,flex-shrink,flex-basis,flex,align-self。
- order属性定义项目的排列顺序。数值越小,排列越靠前,默认为0。
- flex-grow属性定义项目的放大比例,默认为0,即如果存在剩余空间,也不放大。
- flex-shrink属性定义了项目的缩小比例,默认为1,即如果空间不足,该项目将缩小。
- flex-basis属性定义了在分配多余空间之前,项目占据的主轴空间(main size)。
- flex属性是flex-grow, flex-shrink 和 flex-basis的简写,默认值为0 1 auto。后两个属性可选。
- align-self 属性允许单个项目有与其他项目不一样的对齐方式,可覆盖 align-items 属性。默认值为 auto,表示继承父元素的align-items属性,如果没有父元素,则等同于stretch。
22.隐藏元素的方法
| 方法 | 说明 |
|---|---|
| display: none; | 渲染树不会包含该渲染对象,因此该元素不会在页面中占据位置,也不会响应绑定的监听事件 |
| visibility: hidden; | 元素在页面中仍占据空间,但是不会响应绑定的监听事件 |
| opacity: 0; | 透明度设置为0,来隐藏元素。元素在页面中仍然占据空间,并且能够响应元素绑定的监听事件 |
| position: absolute; | 通过使用绝对定位将元素移除可视区域内,以此来实现元素的隐藏 |
| z-index: -10; | 使用其余元素遮盖当前元素实现隐藏 |
| clip/clip-path | 使用元素裁剪的方法来实现元素的隐藏,这种方法下,元素仍在页面中占据位置,但是不会响应绑定的监听事件 |
| transform: scale(0,0) | 将元素缩放为 0,来实现元素的隐藏。这种方法下,元素仍在页面中占据位置,但是不会响应绑定的监听事件 |
23.transition和animation的区别
| transition | animation |
|---|---|
| 过渡属性,强调过渡,需要触发事件来实现过渡效果。 | 动画属性,不需要触发事件,可自己执行,并且可以循环 |
24.分析比较 opacity: 0、visibility: hidden、display: none 优劣和适用场景
结构: display:none: 会让元素完全从渲染树中消失,渲染的时候不占据任何空间, 不能点击, visibility: hidden:不会让元素从渲染树消失,渲染元素继续占据空间,只是内容不可见,不能点击 opacity: 0: 不会让元素从渲染树消失,渲染元素继续占据空间,只是内容不可见,可以点击
继承: display: none和opacity: 0:是非继承属性,子孙节点消失由于元素从渲染树消失造成,通过修改子孙节点属性无法显示。 visibility: hidden:是继承属性,子孙节点消失由于继承了hidden,通过设置visibility: visible;可以让子孙节点显式。
性能: displaynone : 修改元素会造成文档回流,读屏器不会读取display: none元素内容,性能消耗较大 visibility:hidden: 修改元素只会造成本元素的重绘,性能消耗较少读屏器读取visibility: hidden元素内容 opacity: 0 : 修改元素会造成重绘,性能消耗较少
display: none (不占空间,不能点击)(场景,显示出原来这里不存在的结构)
visibility: hidden(占据空间,不能点击)(场景:显示不会导致页面结构发生变动,不会撑开)
opacity: 0(占据空间,可以点击)(场景:可以跟transition搭配)
25.如何用 css 或 js 实现多行文本溢出省略效果,考虑兼容性
CSS 实现方式
单行:
overflow: hidden;
text-overflow:ellipsis;
white-space: nowrap;
多行:
display: -webkit-box;
-webkit-box-orient: vertical;
-webkit-line-clamp: 3; //行数
overflow: hidden;
兼容:
p{position: relative; line-height: 20px; max-height: 40px;overflow: hidden;}
p::after{content: "..."; position: absolute; bottom: 0; right: 0; padding-left: 40px;
background: -webkit-linear-gradient(left, transparent, #fff 55%);
background: -o-linear-gradient(right, transparent, #fff 55%);
background: -moz-linear-gradient(right, transparent, #fff 55%);
background: linear-gradient(to right, transparent, #fff 55%);
}
JS 实现方式:
- 使用split + 正则表达式将单词与单个文字切割出来存入words
- 加上 ‘…’
- 判断scrollHeight与clientHeight,超出的话就从words中pop一个出来
26.说出 space-between 和 space-around 的区别?
这个是 flex 布局的内容,其实就是一个边距的区别,按水平布局来说,space-between是两端对齐,在左右两侧没有边距,而space-around是每个 子项目左右方向的 margin 相等,所以两个item中间的间距会比较大。
27.CSS3 中 transition 和 animation 的属性分别有哪些
transition 过渡动画:
- transition-property:指定过渡的 CSS 属性
- transition-duration:指定过渡所需的完成时间
- transition-timing-function:指定过渡函数
- transition-delay:指定过渡的延迟时间
animation 关键帧动画:
- animation-name:指定要绑定到选择器的关键帧的名称
- animation-duration:动画指定需要多少秒或毫秒完成
- animation-timing-function:设置动画将如何完成一个周期
- animation-delay:设置动画在启动前的延迟间隔
- animation-iteration-count:定义动画的播放次数
- animation-direction:指定是否应该轮流反向播放动画
- animation-fill-mode:规定当动画不播放时(当动画完成时,或当动画有一个延迟未开始播放时),要应用到元素的样式
- animation-play-state:指定动画是否正在运行或已暂停
28.如何用 CSS 实现一个三角形
可以利用 border 属性
利用盒模型的 border 属性上下左右边框交界处会呈现出平滑的斜线这个特点,通过设置不同的上下左右边框宽度或者颜色即可得到三角形或者梯形。
如果想实现其中的任一个三角形,把其他方向上的 border-color 都设置成透明即可。
示例代码如下:
<div>div>
div{
width: 0;
height: 0;
border: 10px solid red;
border-top-color: transparent;
border-left-color: transparent;
border-right-color: transparent;
}
29.如何实现一个自适应的正方形
方法1:利用 CSS3 的 vw 单位
vw 会把视口的宽度平均分为 100 份
.square {
width: 10vw;
height: 10vw;
background: red;
}
方法2:利用 margin 或者 padding 的百分比计算是参照父元素的 width 属性
.square {
width: 10%;
padding-bottom: 10%;
height: 0; // 防止内容撑开多余的高度
background: red;
}
30.浮动
非IE浏览器下,容器不设置高度且子元素浮动时,容器高度不能被撑开。此时,内容会溢出到容器外面影响布局
浮动的工作原理
- 浮动元素脱离文档流,不占据空间(引起“高度塌陷”)
- 浮动元素碰到包含它的边框或者其它浮动元素的边框停留
浮动元素可以左右移动,知道遇到另一个浮动元素或者遇到它外边缘的包含框。浮动框不属于文档流中的普通流,但元素浮动之后,不会影响块级元素的布局,只会影响内联元素的布局。此时文档流中的普通流就会表现得该浮动框不存在一样的布局模式。当包含框的高度小于浮动框的时候,此时就会出现“高度塌陷”
浮动元素引起的问题
- 父元素的高度无法撑开,影响与父元素同级的元素
- 与浮动元素同级的非浮动元素会跟随其后
- 若浮动的元素不是第一个元素,则该元素之前的元素元素也要浮动,否则会影响页面的显示结构
清除浮动的方式
- 给父级元素设置高度
- 最后一个浮动元素之后添加一个空div标签,并添加
clear: both样式 - 包含浮动元素的父级元素添加
overflow: hidden或overflow: auto样式 - 使用
::after伪元素 - 使用clear属性清除浮动
31.清除浮动的方法
clear 清除浮动(添加空div法)在浮动元素下方添加空div,并给该元素写css样式: {clear:both;height:0;overflow:hidden;}
给浮动元素父级设置高度
父级同时浮动(需要给父级同级元素添加浮动)
父级设置成inline-block,其margin: 0 auto居中方式失效
给父级添加overflow:hidden 清除浮动方法
万能清除法 ::after 伪元素清浮动(现在主流方法,推荐使用)
32.盒模型
盒模型由四个部分组成,分别是margin、border、padding、content
标准盒模型和IE盒模型的区别在于:在设置width和height时,所对应的范围不同
- 标准盒模型的width和height属性的范围只包含了content
- IE盒模型的width和height属性的范围包含了border、padding和content
可以通过修改元素的box-sizing属性来改变元素的盒模型:
box-sizing: content-box表示标准盒模型(默认值)box-sizing: border-box表示IE盒模型(怪异盒模型)
33.说说两种盒模型以及区别
盒模型也称为框模型,就是从盒子顶部俯视所得的一张平面图,用于描述元素所占用的空间。它有两种盒模型,W3C盒模型和IE盒模型(IE6以下,不包括IE6以及怪异模式下的IE5.5+)
理论上两者的主要区别是二者的盒子宽高是否包括元素的边框和内边距。当用CSS给给某个元素定义高或宽时,IE盒模型中内容的宽或高将会包含内边距和边框,而W3C盒模型并不会。
34.如何触发重排和重绘?
任何改变用来构建渲染树的信息都会导致一次重排或重绘:
- 添加、删除、更新DOM节点
- 通过display: none隐藏一个DOM节点-触发重排和重绘
- 通过visibility: hidden隐藏一个DOM节点-只触发重绘,因为没有几何变化
- 移动或者给页面中的DOM节点添加动画
- 添加一个样式表,调整样式属性
- 用户行为,例如调整窗口大小,改变字号,或者滚动。
如何减少重排?
- 使用 transform 代替 top
- 不要把节点的属性值放在一个循环里,当成循环里的变量
- 不要使用 table 布局,可能很小的一个改动会造成整个 table 的重新布局
- 把 DOM 离线后修改。如:使用 documentFragment 对象在内存里操作 DOM
- 不要一条一条的修改样式,可以预先定义好 class,然后修改 DOM 的 className
- 使用 absolute 或 fixed 使元素脱离文档流
35.重绘与重排的区别?
重排: 部分渲染树(或者整个渲染树)需要重新分析并且节点尺寸需要重新计算,表现为重新生成布局,重新排列元素
重绘: 由于节点的几何属性发生改变或者由于样式发生改变,例如改变元素背景色时,屏幕上的部分内容需要更新,表现为某些元素的外观被改变
单单改变元素的外观,肯定不会引起网页重新生成布局,但当浏览器完成重排之后,将会重新绘制受到此次重排影响的部分
重排和重绘代价是高昂的,它们会破坏用户体验,并且让UI展示非常迟缓,而相比之下重排的性能影响更大,在两者无法避免的情况下,一般我们宁可选择代价更小的重绘。
『重绘』不一定会出现『重排』,『重排』必然会出现『重绘』。
36.如何优化图片
- 对于很多装饰类图片,尽量不用图片,因为这类修饰图片完全可以用 CSS 去代替。
- 对于移动端来说,屏幕宽度就那么点,完全没有必要去加载原图浪费带宽。一般图片都用 CDN 加载,可以计算出适配屏幕的宽度,然后去请求相应裁剪好的图片。
- 小图使用 base64 格式
- 将多个图标文件整合到一张图片中(雪碧图)
- 选择正确的图片格式:
-
对于能够显示 WebP 格式的浏览器尽量使用 WebP 格式。因为 WebP 格式具有更好的图像数据压缩算法,能带来更小的图片体积,而且拥有肉眼识别无差异的图像质量,缺点就是兼容性并不好
-
小图使用 PNG,其实对于大部分图标这类图片,完全可以使用 SVG 代替
-
照片使用 JPEG
37.margin重叠问题
两个块级元素的上外边距和下外边距可能会合并(折叠)为一个外边距,其大小会取其中外边距值大的那个,这种行为就是外边距折叠。需要注意的是,浮动的元素和绝对定位这种脱离文档流的元素的外边距不会折叠。重叠只会出现在垂直方向。
计算原则
- 如果两者都是正数,取较大的那个
- 如果一正一负,取正值减去负值后的绝对值
- 都是负值是,用0减去两个中绝对值大的那个
解决办法
对于折叠的情况,主要有两种:兄弟之间重叠和父子之间重叠
兄弟间折叠:
- 底部元素变为行内盒子:
display: inline-block - 底部元素设置浮动:
float - 底部元素的position的值为
absolute/fixed
父子间的折叠:
- 父元素加入:
overflow: hidden - 父元素添加透明边框:
border: 1px solid transparent - 子元素变为行内盒子:
display: inline-block - 子元素加入浮动属性或定位
38.什么是严格模式与混杂模式?
- 严格模式:是以浏览器支持的最高标准运行
- 混杂模式:页面以宽松向下兼容的方式显示,模拟老式浏览器的行为
39.前端页面有哪三层构成,分别是什么?
构成:结构层、表示层、行为层
-
结构层(structural layer)
结构层类似于盖房子需要打地基以及房子的悬梁框架,它是由HTML超文本标记语言来创建的,也就是页面中的各种标签,在结构层中保存了用户可以看到的所有内容,比如说:一段文字、一张图片、一段视频等等
-
表示层(presentation layer)
表示层是由CSS负责创建,它的作用是如何显示有关内容,学名:
层叠样式表,也就相当于装修房子,看你要什么风格的,田园的、中式的、地中海的,总之CSS都能办妥 -
行为层(behaviorlayer)
行为层表示网页内容跟用户之间产生交互性,简单来说就是用户操作了网页,网页给用户一个反馈,这是
JavaScript和DOM主宰的领域
40.iframe的作用以及优缺点
iframe也称作嵌入式框架,嵌入式框架和框架网页类似,它可以把一个网页的框架和内容嵌入到现有的网页中。
优点:
- 可以用来处理加载缓慢的内容,比如:广告
- iframe 能原封不动的把嵌入的网页展现出来。
如果有多个网页引用 iframe,只需修改 iframe 的内容,就可以实现调用每一个页面的更改,方便快捷。
缺点:
- iframe会阻塞主页面的Onload事件
- iframe和主页面共享连接池,而浏览器对相同域的连接有限制,所以会影响页面的并行加载。但是可以通过JS动态给ifame添加src属性值来解决这个问题,当然也可以解决iframe会阻塞主页面的Onload事件的问题
- 会产生很多页面,不易管理,iframe 框架页面会增加服务器的 http 请求,对于大型网站不可取。
- 浏览器的后退按钮没有作用
- 无法被一些搜索引擎识别,很多移动设备无法完全显示框架,设备兼容性差。
- iframe 和主页面共享链接池,而浏览器对相同域的链接有限制,所以会影响页面的并行加载。
不利于 SEO,代码复杂,无法一下被搜索引擎索引到。
注意:通过动态给 iframe 添加 src 属性值,可解决前两个问题。
41.常见CSS选择器
注意事项
!important声明的样式的优先级最高- 如果优先级一致,则最后出现的样式生效
- 继承得到的样式的优先级最低
- 样式来源不同时,优先级顺序为:内联样式 > 内部样式 > 外部样式 > 浏览器用户自定义样式 > 浏览器默认样式
42.伪元素和伪类的区别和作用
| 伪元素 | 伪类 |
|---|---|
| 在元素前后插入额外的元素或样式,插入的元素没有子文档中生成,它们只在外部显示可见 | 将特殊的效果添加到特定的选择器上。它是在现有元素上添加类别,并不会产生新的元素 |
| css3中伪元素在书写是使用双冒号::,比如::before | 冒号:用于伪类,比如:hover |
伪类是通过在元素选择器上加入伪类改变元素的状态,而伪元素通过对元素的操作来改变元素
43.隐藏页面中的某个元素的方法有哪些?
隐藏类型
屏幕并不是唯一的输出机制,比如说屏幕上看不见的元素(隐藏的元素),其中一些依然能够被读屏软件阅读出来(因为读屏软件依赖于可访问性树来阐述)。为了消除它们之间的歧义,我们将其归为三大类:
- 完全隐藏:元素从渲染树中消失,不占据空间。
- 视觉上的隐藏:屏幕中不可见,占据空间。
- 语义上的隐藏:读屏软件不可读,但正常占据空。
完全隐藏
(1) display 属性
display: none;
(2) hidden 属性 HTML5 新增属性,相当于 display: none
<div hidden>div>
视觉上的隐藏
(1) 设置 posoition 为 absolute 或 fixed,通过设置 top、left 等值,将其移出可视区域。
position:absolute;
left: -99999px;
(2) 设置 position 为 relative,通过设置 top、left 等值,将其移出可视区域。
position: relative;
left: -99999px;
height: 0
(3) 设置 margin 值,将其移出可视区域范围(可视区域占位)。
margin-left: -99999px;
height: 0;
语义上隐藏
aria-hidden 属性
读屏软件不可读,占据空间,可见。
<div aria-hidden="true"></div>
45.实现单行、多行文本溢出隐藏
单行文本溢出
overflow: hidden; // 溢出隐藏
text-overflow: ellipsis; // 溢出部分使用省略号显示
white-space: nowrap; // 规定段落中的文本不可换行
多行文本溢出
overflow: hidden; // 溢出隐藏
text-overflow: ellipsis; // 溢出用省略号显示
display:-webkit-box; // 作为弹性伸缩盒子模型显示。
-webkit-box-orient:vertical; // 设置伸缩盒子的子元素排列方式:从上到下垂直排列
-webkit-line-clamp:3; // 显示的行数
46.实现水平垂直居中
利用绝对定位(一)
.parent {
position: relative;
}
.child {
position: absolute;
left: 50%;
top: 50%;
transform: translate(-50%, -50%)
}
利用绝对定位(二):适用于已知盒子宽高
.parent {
position: relative;
}
.child {
position: absolute;
top: 0;
bottom: 0;
left: 0;
right: 0;
margin: auto;
}
利用绝对定位(三):适用于已知盒子宽高
.parent {
position: relative;
}
.child {
position: absolute;
top: 50%;
left: 50%;
margin-top: -50px; /* 自身 height 的一半 */
margin-left: -50px; /* 自身 width 的一半 */
}
flex布局
.parent {
display: flex;
justify-content: center;
align-items: center;
}
47.网页布局有哪几种,有什么区别
静态、自适应、流式、响应式四种网页布局
静态布局:意思就是不管浏览器尺寸具体是多少,网页布局就按照当时写代码的布局来布置;
自适应布局:就是说你看到的页面,里面元素的位置会变化而大小不会变化;
流式布局:你看到的页面,元素的大小会变化而位置不会变化——这就导致如果屏幕太大或者太小都会导致元素无法正常显示。
自适应布局:每个屏幕分辨率下面会有一个布局样式,同时位置会变而且大小也会变。
48.SGML、HTML、XML 和 XHTML的区别
SGML是标准通用标记语言,是一种定义电子文档结构和描述其内容的国际标准语言,是所有电子文档标记语言的起源。HTML是超文本标记语言,主要是用于规定怎样显示网页。XML是可扩展标记语言,是未来网页语言的发展方向,XML 和 HTML 的最大区别就在于 XML 的标签是可以自己创建的,数量无限多,而 HTML 的标签都是固定的而且数量有限。XHTML也是现在基本上所有网页都在用的标记语言,他其实和 HTML 没什么本质的区别,标签都一样,用法也都一样,就是比 HTML 更严格,比如标签必须都用小写,标签都必须有闭合标签等
49.对浏览器内核的理解
主要分为两部分:渲染引擎和JS引擎。
渲染引擎:其职责就是渲染,即在浏览器窗口中显示所请求的内容。默认情况下,渲染引擎可以显示 HTML、 XML 文档及图片,它也可以借助一些浏览器扩展插件显示其他类型数据,如:使用PDF阅读器插件可以显示 PDF 格式。JS引擎:解析和执行 JavaScript 来实现网页的动态效果。
最开始渲染引擎和JS引擎并没有区分的很明显,后来JS引擎越来越独立,内核就倾向于只指渲染引擎了。
50.什么是文档的预解析?
当执行 JavaScript 脚本时,另一个线程解析剩下的文档,并加载后面需要通过网络加载的资源。这种方式可以使资源并行加载,从而使整体速度更快。
需要注意的是,预解析并不改变DOM树,它将这个工作交给主解析过程,自己只解析外部资源的引用,比如:外部脚本、样式及图片。
51.浏览器的渲染原理
简记: 生成DOM树 --> 生成CSS规则树 --> 构建渲染树 --> 布局 --> 绘制
- 首先解析收到的文档,根据文档定义构建一颗
DOM 树,DOM 树是由 DOM 元素及属性节点组成的。 - 然后对 CSS 进行解析,生成一颗
CSS 规则树。 - 根据 DOM 树和 CSS 规则树构建
渲染树。渲染树的节点被称为渲染对象,它是一个包含有颜色等属性的矩形。渲染对象和 DOM 元素相对应,但这种关系不是一对一的,不可见的 DOM 元素不会插入渲染树。还有一些 DOM 元素对应几个可见对象,它们一般是一些具有复杂结构的元素,无法用一个矩形来描述。 - 当渲染对象被创建并添加到树中,它们没有位置和大小,所以当浏览器生成渲染树以后,就会根据渲染树来进行
布局(也可以叫做回流)。这一阶段浏览器要做的是计算出各个节点在页面中确切位置和大小。通常这一行为也被称为自动重排。 - 布局阶段结束后是
绘制阶段,遍历渲染树并调用渲染对象的 paint 方法将它们的内容显示到屏幕上。值得注意的是,这个过程是逐步完成的,为了更好的用户体验,渲染引擎会尽早的将内容呈现到屏幕上,并不会等到所有 HMTL 内容都解析完之后再去构建和布局渲染树,它是解析完一部分内容就显示一部分内容,同时,可能还通过网络下载其余内容。
52.什么是 canvas,基本用法是什么?
canvas 元素是 HTML5 的一部分,允许脚步语言动态渲染位图像。canvas 由一个可控制区域 HTML 代码中的属性定义决定高度和宽度。JavaScript 代码可以访问该区域,通过一套完整的绘图功能类似于其他通用二维的 API,从而生成动态的图形。
- 创建 canvas 标签
- 渲染上下文
var canvas = document.getElementById('myCanvas');
var ctx = canvas.getContext('2d');
代码第一行通过使用 document.getElementById() 方法获取 `` 元素对应的 DOM 对象,然后可以通过使用它的 getContext() 方法来绘制上下文。 创建 canvas 标签时可以在标签内写上不支持的提示信息;也可以通过 getContext() 方法判读是否支持编程。
var canvas = document.getElementById('myCanvas');
if (canvas.getContext) {
var ctx = canvas.getContext('2d');
// other code
} else {
// 不支持 canvas 的其他代码
}
用途:
canvas 可用于游戏和图表(echarts.js、heightchart.js 都是基于 canvas 来绘图)制作。
53.style 标签写在 body 后与 body 前有什么区别?
- 写在 body 标签前有利于浏览器逐步渲染: resources downloading --> cssDOM + DOM --> Render Tree --> layout --> paint
- 写在 body 标签后: 由于浏览器以逐行方式对 HTML 文档进行解析,当解析到写在尾部的样式表(外联或写在 style 标签)会导致浏览器停止之前的渲染,等待加载且解析样式完成后重新渲染;在 windows 的 IE 下可能出现样式失效导致的页面闪烁问题。
54.rgba() 和 opacity 设置透明度的区别是什么?
rgba() 和 opacity 都能实现透明效果,但最大的不同是 opacity 作用于元素,以及元素内的所有内容的透明度;而 rgba() 只作用于元素的颜色或其背景色,设置 rgba() 透明的元素的子元素不会继承透明效果。
55.浏览器是如何解析 css 选择器的?
从右向左解析的。若从左向右匹配,发现不符合规则,需要回溯,会损失很多性能。若从右向左匹配,先找到所有的最后节点,对于每一个节点,向上寻找其父节点直到查找至根元素或满足条件的匹配规则,则结束这个分支的遍历。
在 css 解析完毕后,需将解析结果 css 规则树和 DOM Tree 一起进行分析建立一颗 Render Tree,最终用来进行绘图。
56.简述 transform,transition,animation 的作用
transform:描述了元素的静态样式,本身不会呈现动画效果,可以对元素进行旋转 rotate、扭曲 skew、缩放 scale 和移动 translate 以及矩阵变形 matrix。transition和animation两者都能实现动画效果。transform常配合transition和animation使用。transition:样式过渡,从一种效果逐渐改变为另一种效果,它是一个合写属性。transition: transition-property transition-duration transition-timing-function transition-delay 从左到右,依次是:过渡效果的css属性名称、过渡效果花费时间、速度曲线、过渡开始的延迟时间transition通常和 hover 等事件配合使用,需要由事件来触发过渡。animation:动画,有@keyframes来描述每一帧的样式。
区别:
transform仅描述元素的静态样式,常配合transition和animation使用。transition通常和 hover 等事件配合使用;animation是自发的,立即播放。animation可以设置循环次数。animation可以设置每一帧的样式和时间,transition只能设置头尾。transition可以与 js 配合使用, js 设定要变化的样式,transition负责动画效果。
57.box-sizing 属性
content-box,对应标准盒模型。border-box,IE盒模型。inherit,继承父元素的 box-sizing 值。
58.实现图片懒加载的原理
懒加载原理:先设置图片的 data-set 属性值(也可以是其他任意的,只要不发生 http 请求就可以,作用是为了存取值)为图片路径,由于不是 src 属性,故不会发生 http 请求。然后计算出页面的 scrollTop 的高度和浏览器的高度之和,如果图片距页面顶端距离小于前两者之和,说明图片要显示出来了,这时将 data-set 属性替换为 src 属性即可。
59.css sprites (雪碧图/精灵图)
css sprites 就是把网页中一些小图片整合到一张图片文件中,再利用 css 的 background-image、background-repeat、background-position 的组合进行背景定位。
优点: 减少图片体积;减少 http 请求次数
缺点:维护比较麻烦;不能随便改变大小,会失真模糊
60.什么是字体图标?
字体图标简单的说,就是一种特殊的字体,通过这种字体,显示给用户的就像一个个图片一样。字体图标最大的好处,在于它不会变形和加载速度快。字体图标可以像文字一样,随意通过 css 来控制它的大小和颜色,非常方便。
61.主流浏览器内核私有属性 css 前缀?
- mozilla(firefox、flock等): -moz
- webkit 内核(safari、chrome等): -webkit
- opera 内核(opera浏览器): -o
- trident 内核(ie 浏览器): -ms
HTTP
1.什么是 HTTP?
HTTP (HyperText Transfer Protocol),即超文本传输协议,是一种实现网络通信的规范。它定义了客户端和服务器之间交换报文的格式和方式,默认使用的是80端口,其底层使用TCP作为传输层协议,保证了数据传输的可靠性。
特点:
- 简单快速:客户端向服务器请求服务时,只需传送请求方法和路径。由于
HTTP协议简单,使得HTTP服务器的规模小,因而通信速度很快。 - 灵活:
HTTP允许传输任意类型的数据对象。 - 无连接:限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。
- 无状态:
HTTP协议无法根据之前的状态进行本次的请求处理。 - 明文:
HTTP是以明文的形式传递内容。
2.HTTP 和 HTTPS 的区别?
HTTPS是HTTP协议的安全版本。HTTPS的出现主要是为了解决HTTP明文传输内容导致其不安全的特性。为保证数据加密传输,让HTTP运行安全的SSL/TLS协议上,即 HTTPS = HTTP + SSL/TLS。通过SSL证书来验证服务器的身份,并为浏览器和服务器之间的通信进行加密。
二者的区别:
- 安全性:
HTTP协议的数据传输是明文的,是不安全的;HTTPS使用了SSL/TLS协议进行加密处理,相对更加安全。 - 连接方式:二者使用的连接方式不同,
HTTP是三次握手,HTTPS是三次握手+数字证书。 - 默认端口:
HTTP的默认端口是80;HTTPS的默认端口是443。 - 响应速度:由于
HTTPS需要进行加解密过程,因此速度不如HTTP。 - 费用:
HTTPS需要使用SSL证书,功能越强大的证书其费用越高;HTTP不需要。
3.HTTP 1.0 和 1.1 的区别?
- 连接:
HTTP 1.0默认使用非持久连接,HTTP 1.1则默认使用持久连接。HTTP 1.1通过使用持久连接来使多个HTTP请求复用同一个TCP连接,避免了HTTP 1.0中使用非持久连接造成的每次请求都需要建立连接的时延。 - 缓存:
HTTP 1.0主要使用header中的If-Modified-Since,Expires来做为缓存判断的标准;HTTP 1.1则引入了更多的缓存控制策略,例如:Etag、If-Unmodified-Since、If-Match、If-None-Match等更多可供选择的缓存头来控制缓存策略。 - 资源请求:
HTTP 1.0中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能;HTTP 1.1则在请求头引入了range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。 - host:
HTTP 1.1引入了host,用来指定服务器的域名。 - 方法:
HTTP 1.1相较于HTTP 1.0新增了许多方法,如:put、delete、options等。
4.HTTP 状态码有哪些?
状态码第一位数字决定了不同的响应状态:
1xx表示请求已被接受,需要继续处理;
2xx表示请求成功;
3xx表示重定向;
4xx表示客户端错误;
5xx表示服务端错误。
常见的状态码:
101:服务器根据客户端的请求切换协议,主要用于websocket或http2升级200:请求已成功,请求所希望的数据将随响应一起返回。201:请求成功并且服务器创建了新的资源。202:服务器已接受响应请求,但尚未处理。301:请求的网页已永久移动至新的位置。302:临时重定向/临时转移。服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。304:本次获取到的内容是读取缓存中的数据,会每次去服务器校验。401:请求需要进行身份验证,尚未认证,没有登录网站。403:禁止访问,服务器拒绝请求。404:服务器没有找到相应资源。500:服务器遇到错误,无法完成对请求的处理。503:服务器无法使用。
5.GET和POST的请求的区别
| 区别 | GET | POST |
|---|---|---|
| 幂等性 | 是 | 否 |
| 应用场景 | 用于对服务器资源不会产生影响的场景(比如请求一个网页的资源等) | 用于对服务器资源会产生影响的情景(比如注册用户等) |
| 是否缓存 | 是 | 否 |
| 传参方式 | 查询字符串传参 | 请求体传参 |
| 安全性 | 将参数放入url中向服务器发送,不安全 | 在请求体中,安全 |
| 请求长度 | 浏览器对于url长度有限制,会受到影响 | 在请求体中,不会收到浏览器影响 |
| 参数类型 | ASCII字符 | 文件、图片等 |
幂等性:指一个请求方法执行一次和多次的效果完全相同
6.POST和PUT的请求的区别
| 区别 | POST | PUT |
|---|---|---|
| 作用 | 创建数据 | 更新数据 |
为什么POST请求会发送两次?
- 第一次请求为options预检请求,状态码为204
作用1:询问服务器是否支持修改的请求头,如果服务器支持,则在第二次中发送真正的请求
作用2: 检测服务器是否为同源请求,是否支持跨域
- 第二次请求为真正的POST请求
7.常见的HTTP请求头和响应头
| HTTP Request Header | 定义 |
|---|---|
| Accept | 浏览器能够处理的内容类型 |
| Accept-Charset | 浏览器能够显示的字符集 |
| Accept-Encoding | 浏览器能够处理的压缩编码 |
| Accept-Language | 浏览器当前设置的语言 |
| Connection | 浏览器与服务器之间连接的类型 |
| Cookie | 浏览器当前页面设置的任何Cookie |
| Host | 当前发出请求的页面所在的域 |
| Referer | 当前发出请求的页面的URL |
| User-Agent | 浏览器的用户代理字符串 |
| HTTP Responses Header | 定义 |
|---|---|
| Date | 表示消息发送的时间,时间的描述格式由rfc822定义 |
| server | 服务器名称 |
| Connection | 浏览器与服务器之间连接的类型 |
| Cache-Control | 控制HTTP缓存 |
| content-type | 表示后面的文档属于什么MIME类型 |
| Content-Type | 定义 |
|---|---|
| application/x-www-form-urlencoded | 浏览器原生form表单 |
| multipart/form-data | 表单上传文件 |
| application/json | 服务器消息主体是序列化后的 JSON 字符串 |
| text/xml | 提交 XML 格式的数据 |
8.状态码304
为什么会有304?
服务器为了提高网站访问速度,对之前访问的部分页面指定缓存机制。当客户端再次请求页面时,服务器会判断请求的页面是否已被缓存,若已经被缓存则返回304,此时客户端将调用缓存内容。
状态码304不应该被认为是一种错误,而是对客户端有缓存情况下服务端的一种响应。
产生较多304状态码的原因是什么?
- 页面更新周期长或者长时间未更新
- 纯静态页面或强制生成静态HTML
304状态码过多会造成什么问题?
- 网站快照停止
- 收录减少
- 权重下降
9.常见的HTTP请求方法
| 方法 | 作用 |
|---|---|
| GET | 向服务器获取数据 |
| POST | 向服务器发送数据 |
| PUT | 修改数据 |
| PATCH | 用于对资源进行部分修改 |
| DELETE | 删除指定数据 |
10.如何解决跨域问题?
JSONP:Jsonp(JSON with Padding) 是 json 的一种"使用模式",可以让网页从别的域名(网站)那获取资料,即跨域读取数据。ajax 请求受同源策略影响,不允许进行跨域请求,而 script 标签 src 属性中的链接却可以访问跨域的 js 脚本,利用这个特性,服务端不再返回 JSON 格式的数据,而是返回一段调用某个函数的 js 代码,在 src 中进行了调用,这样实现了跨域。CORS:CORS(Cross-origin resource sharing)跨域资源共享,服务器设置对 CORS 的支持。其原理是,服务器设置 Access-Control-Allow-Origin HTTP响应头之后,浏览器将会允许跨域请求。实现CORS通信的关键是服务器。只要服务器实现了CORS接口,就可以跨源通信。proxy代理:最常用多方式。通俗点说就是客户端浏览器发起一个请求会存在跨域问题,但是服务端向另一个服务端发起请求并无跨域,因为跨域问题归根结底源于同源策略,而同源策略只存在于浏览器。那么我们是不是可以通过 Nginx 配置一个代理服务器,反向代理访问跨域的接口,并且我们还可以修改 Cookie 中 domain 信息,方便当前域 Cookie 写入。
11.正向代理和反向代理?
正向代理隐藏了真实的请求客户端,服务端不知道真实的客户端是谁,客户端请求的服务都被代理服务器代替来请求。
反向代理隐藏了真实的服务端,当发送一个请求时,其背后可能有很多台服务器为我们服务,但具体是哪一台,我们不知道,也不需要知道,我们只需要知道反向代理服务器是谁就好了,反向代理服务器会帮我们把请求转发到真实的服务器那里去。反向代理器一般用来实现负载平衡。
12.从输入URL到看到页面的过程,发生了什么?
-
url解析:首先会判断输入的是一个合法 url还是关键词,并根据输入的内容进行相应的操作。 -
查找缓存:浏览器会判断所请求的资源是否在浏览器缓存中,以及是否失效。如果没有失效就直接使用;如果没有缓存或失效了,就继续下一步。 -
DNS解析:此时需要获取url中域名对应的IP地址。浏览器会依次查看浏览器缓存、操作系统缓存中是否有ip地址,如果缓存中没有就会向本地域名服务器发起请求,获取ip地址。本地域名服务器也会先检查缓存,有则直接返回;如果也没有,则采用迭代查询方式,向上级域名服务器查询。先向根域名服务器发起请求,获取顶级域名服务器的地址;再向顶级域名服务器发起请求以获取权限域名服务器地址;然后向权限域名服务器发起请求并得到url中域名对应的IP地址。 -
建立TCP连接:根据ip地址,三次握手与服务器建立TCP连接。 -
发起请求:浏览器向服务器发起HTTP请求。 -
响应请求:服务器响应HTTP请求,将相应的HTML文件返回给浏览器。 -
关闭TCP连接:四次挥手关闭TCP连接。 -
渲染页面:浏览器解析HTML内容,并开始渲染。
浏览器渲染过程
如下:
构建DOM树:词法分析然后解析成DOM树,DOM树是由DOM元素及属性节点组成,树的根是document对象。构建CSS规则树:生成CSS 规则树。构建渲染树:将DOM树和CSS规则树结合,构建出渲染树。布局:计算每个节点的位置。绘制:使用浏览器的UI接口进行绘制。
13.即时通讯的实现方式?
主要有四种方式,它们分别是轮询、长轮询(comet)、长连接(SSE)、WebSocket。它们大体可以分为两类,一种是在HTTP基础上实现的,包括短轮询、comet和SSE;另一种不是在HTTP基础上实现是,即WebSocket。
轮询
短轮询的基本思路就是浏览器每隔一段时间向浏览器发送http请求,服务器在收到请求后,不论是否有数据更新,都直接进行响应。这种方式实现的即时通信,本质上还是浏览器发送请求,服务器接受请求的一个过程,通过让客户端不断的进行请求,使得客户端能够模拟实时地收到服务器端的数据的变化。
优点:比较简单,易于理解,实现起来没有什么技术难点。
缺点:由于需要不断的建立http连接,严重浪费了服务器端和客户端的资源。长轮询
当服务器收到客户端发来的请求后,服务器端不会直接进行响应,而是先将这个请求挂起,然后判断服务器端数据是否有更新。如果有更新,则进行响应;如果一直没有数据,则到达一定的时间限制(服务器端设置)才返回。
优点:长轮询和短轮询比起来,明显减少了很多不必要的http请求次数,相比之下节约了资源。
缺点:连接挂起也会导致资源的浪费。长连接
SSE是HTML 5新增的功能,全称为Server-Sent Events。它可以允许服务推送数据到客户端。SSE在本质上就与之前的长轮询、短轮询不同,虽然都是基于http协议的,但是轮询需要客户端先发送请求。而SSE最大的特点就是不需要客户端发送请求,可以实现只要服务器端数据有更新,就可以马上发送到客户端。 优点:不需要建立或保持大量的客户端发往服务器端的请求,节约了很多资源,提升应用性能;实现非常简单,并且不需要依赖其他插件。WebSocket
WebSocket是HTML 5定义的一个新协议,与传统的http协议不同,该协议可以实现服务器与客户端之间全双工通信。简单来说,首先需要在客户端和服务器端建立起一个连接,这部分需要http。连接一旦建立,客户端和服务器端就处于平等的地位,可以相互发送数据,不存在请求和响应的区别。
优点:实现了双向通信。
缺点:服务器端的逻辑非常复杂。
14.Cookie
Cookie是最早被提出来的本地存储方式,在此之前,服务端是无法判断网络中的两个请求是否是同一用户发起的,为解决这个问题,Cookie就出现了。Cookie的大小只有4kb,它是一种纯文本文件,每次发起HTTP请求都会携带Cookie
特性
- Cookie一旦创建成功,就无法修改
- Cookie是无法跨域的
- 每个域名下Cookie的数量不能超过20个,每个Cookie的大小不能超过4kb
- 存在安全问题,一旦被拦截,即可获得session的所有信息
- Cookie在请求一个新的页面的时候都会被发送出去
如何解决无法跨域问题?
- 使用Nginx反向代理
- 在一个站点登陆之后,往其他网站写Cookie。服务端的Session存储到一个节点,Cookie存储sessionId
应用场景
- 和session结合使用,将sessionId存储到Cookie中,每次发送请求都会携带这个sessionId,以便于服务端识别和响应
- 可以用来统计页面的点击次数
15.LocalStorage
LocalStorage是HTML5新引入的特性,由于有的时候我们存储的信息较大,Cookie就不能满足我们的需求,这时候LocalStorage就派上用场了
优点
- LocalStorage能存储5MB的信息
- LocalStorage能够持久化存储数据,数据不会随着页面的关闭而消失,除非手动清除
- 仅存储在本地,发起HTTP请求的时候不会被携带
缺点
- 存在兼容性问题,IE8以下版本浏览器不支持
- 如果浏览器设置为隐私模式,我们将无法获取到LocalStorage
- 受到同源策略的限制,即端口、协议、主机地址有任何一个不相同,都不会访问
常用API
| API | 注释 |
|---|---|
| localStorage.setItem(key, value) | 保存数据到 localStorage |
| localStorage.getItem(key) | 从 localStorage 获取数据 |
| localStorage.removeItem(key) | 从 localStorage 删除key对应的数据 |
| localStorage.clear() | 从 localStorage 删除所有保存的数据 |
| localStorage.key(index) | 获取某个索引的Key |
应用场景
- 一些网站配置个人设置的时候,比如肤色、字体等会将数据保存在LocalStorage中
- 保存一些不经常变动的个人信息或用户浏览信息
16.SessionStorage
SessionStorage和LocalStorage都是在HTML5才提出来的存储方案,SessionStorage 主要用于临时保存同一窗口(或标签页)的数据,刷新页面时不会删除,关闭窗口或标签页之后将会删除这些数据
SessionStorage与LocalStorage对比
- SessionStorage和LocalStorage都在本地进行数据存储
- SessionStorage也有同源策略的限制,但是SessionStorage有一条更加严格的限制,SessionStorage只有在同一浏览器的同一窗口下才能够共享
- LocalStorage和SessionStorage都不能被爬虫爬取
常用API
| API | 注释 |
|---|---|
| sessionStorage.setItem(key, value) | 保存数据到 sessionStorage |
| sessionStorage.getItem(key) | 从 sessionStorage获取数据 |
| sessionStorage.removeItem(key) | 从 sessionStorage删除key对应的数据 |
| sessionStorage.clear() | 从 sessionStorage删除所有保存的数据 |
| sessionStorage.key(index) | 获取某个索引的Key |
应用场景
- 由于SessionStorage具有时效性,所以可以用来存储一些网站的游客登录的信息,还有临时的浏览记录的信息。当关闭网站之后,这些信息也就随之消除了
17.Cookie、LocalStorage、SessionStorage区别
| Cookie | LocalStorage | SessionStorage |
|---|---|---|
| 实最开始是服务器端用于记录用户状态的一种方式,由服务器设置,在客户端存储,然后每次发起同源请求时,发送给服务器端。cookie 最多能存储 4 k 数据,它的生存时间由 expires 属性指定,并且 cookie 只能被同源的页面访问共享 | html5 提供的一种浏览器本地存储的方法,它一般也能够存储 5M 或者更大的数据。它和 sessionStorage 不同的是,除非手动删除它,否则它不会失效,并且 localStorage 也只能被同源页面所访问共享 | html5 提供的一种浏览器本地存储的方法,它借鉴了服务器端 session 的概念,代表的是一次会话中所保存的数据。它一般能够存储 5M 或者更大的数据,它在当前窗口关闭后就失效了,并且 sessionStorage 只能被同一个窗口的同源页面所访问共享 |
- 共同点:都是保存在浏览器端,且同源的
- 区别:
- cookie 始终在同源的 http 请求中携带(即使不需要),即 cookie 在浏览器和服务器之间来回传递;而 sessionStorage 和 localStorage 不会自动把数据发送到服务器,仅在本地保存。cookie 还有路径(path)的概念,可以限制 cookie 只属于某个路径下。
- 存储大小限制不同。cookie 不能超过 4K,因为每次 http 请求都会携带 cookie,所以 cookie 只适合保存很小的数据,如:会话标识。sessionStorage 和 localStorage 虽然也有存储大小限制,但比 cookie 大得多,可以达到 5M 或更大。
- 数据有效期不同。sessionStorage 仅在当前浏览器窗口关闭之前有效;localStorage 始终有效,窗口或浏览器关闭也一直保存,因此用作持久数据;cookie 只在设置的 cookie 过期时间之前有效。
- 作用域不同。sessionStorage 不在不同的浏览器窗口中共享,即使是同一个页面;localStorage 和 cookie 在所有同源窗口中都是共享的。
18.ajax
AJAX Ajax 即“AsynchronousJavascriptAndXML”(异步 JavaScript 和 XML),是指一种创建交互式网页应用的网页开发技术。它是一种在无需重新加载整个网页的情况下,能够更新部分网页的技术。通过在后台与服务器进行少量数据交换,Ajax 可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。传统的网页(不使用 Ajax)如果需要更新内容,必须重载整个网页页面。其缺点如下:
- 本身是针对MVC编程,不符合前端MVVM的浪潮
- 基于原生XHR开发,XHR本身的架构不清晰
- 不符合关注分离(Separation of Concerns)的原则
- 配置和调用方式非常混乱,而且基于事件的异步模型不友好
(1)创建对象
var xhr = new XMLHttpRequest();
(2)打开请求
xhr.open('GET', 'example.txt', true);
(3)发送请求
xhr.send(); 发送请求到服务器
(4)接收响应
xhr.onreadystatechange =function(){}
(1)当readystate值从一个值变为另一个值时,都会触发readystatechange事件。
(2)当readystate==4时,表示已经接收到全部响应数据。
(3)当status ==200时,表示服务器成功返回页面和数据。
(4)如果(2)和(3)内容同时满足,则可以通过xhr.responseText,获得服务器返回的内容。
19.fetch
Fetch fetch号称是AJAX的替代品,是在ES6出现的,使用了ES6中的promise对象。Fetch是基于promise设计的。Fetch的代码结构比起ajax简单多。fetch不是ajax的进一步封装,而是原生js,没有使用XMLHttpRequest对象
| 优点 | 缺点 |
|---|---|
| 语法简洁,更加语义化 | fetch只对网络请求报错,对400,500都当做成功的请求,服务器返回 400,500 错误码时并不会 reject,只有网络错误这些导致请求不能完成时,fetch 才会被 reject。 |
| 基于标准 Promise 实现,支持 async/await | fetch默认不会带cookie,需要添加配置项: fetch(url, {credentials: ‘include’}) |
| 更加底层,提供的API丰富(request, response) | fetch不支持abort,不支持超时控制,使用setTimeout及Promise.reject的实现的超时控制并不能阻止请求过程继续在后台运行,造成了流量的浪费 |
| 脱离了XHR,是ES规范里新的实现方式 | fetch没有办法原生监测请求的进度,而XHR可以 |
20.axios
Axios 是一种基于Promise封装的HTTP客户端
- 浏览器端发起XMLHttpRequests请求
- node端发起http请求
- 支持Promise API
- 监听请求和返回
- 对请求和返回进行转化
- 取消请求
- 自动转换json数据
- 客户端支持抵御XSRF攻击
21.Promise
ES6新增的一种异步编程的解决方案,比传统的回调函数和事件更加的合理和强大。通过
Promise可以将异步操作以同步操作的流程表达出来,避免了层层嵌套的回调函数。Promise可以解决异步的问题,但不能说Promise是异步的
特点
- 对象的状态不受外界影响。
Promise对象代表一个异步操作,有三种状态: pending——进行中resolved——已成功rejected——已失败- 一旦状态改变,就不会再发生变化,任何时候都可以得到这个结果。
Promise对象状态的改变只有两种可能: pending——resolvedpending——rejectedPromise内部发生错误,不会影响到外部程序的执行。Promise一旦执行则无法取消:- 一旦创建就会立即执行,无法中途取消(*缺点1*)
- 如果不设置回调函数,
Promise内部抛出的错误将不会反应到外部(*缺点2*) - 当处于
pending状态时,无法得知目前进展到哪一阶段,即无法预测是刚刚开始还是即将完成(*缺点3*)
用法
创建Promise实例时,必须传入一个函数作为参数:
new Promise(() => {})
该函数可以接收另外两个由JavaScript引擎提供的函数,resolve和reject:
resolve——将Promise对象的状态从pending变为resolved,将异步操作的结果作为参数传递出去reject——将Promise对象的状态从pending变为rejected,将异步操作报出的错误作为参数传递出去
const promise = new Promise((resolve, reject) => {
if (true) resolve('value')
else reject('error')
})
Promise实例生成以后,可以用then方法分别指定resolved状态和rejected状态的回调函数:
promise.then(value => {
console.log(value) // 'value'
}, error => {
console.log(error) // 'error'
})
当then方法只有一个函数参数时,此时为resolved状态的回调方法:
promise.then(value => {
// 只有状态为resolved时才能调用,如果返回的是rejected状态,则报错 Uncaught (in promise) error
console.log(value)
})
只有当
promise的状态变为resolved或者rejected时,then方法才会被调用
Promise新建后就会立即执行,并且调用resolve或reject后不会终结 Promise的参数函数的执行。
let promise = new Promise(resolve => {
console.log('1')
resolve()
console.log('2')
})
promise.then(resolved => {
console.log('3')
})
console.log('3')
resolve返回的是另外一个Promise实例:
const p1 = new Promise((_, reject) => {
setTimeout(() => reject('error'), 3000);
})
const p2 = new Promise(resolve => {
setTimeout(() => resolve(p1), 1000);
})
p2.then(
result => console.log(result),
error => console.log(error) // error
)
上面代码中,
p1是一个Promise,3 秒之后变为rejected。p2的状态在 1 秒之后改变,resolve方法返回的是p1。由于p2返回的是另一个 Promise,导致p2自己的状态无效了,由p1的状态决定p2的状态。所以,后面的then语句都变成针对后者(p1)。又过了 2 秒,p1变为rejected,导致触发catch方法指定的回调函数。可以理解成p2.then实际上是p1.then
当resolve返回的是另一个Promise实例的时候,当前Promise实例的状态会根据返回的Promise实例的状态来决定
常用API
Promise.resolve()
有时需要将现有对象转为 Promise 对象,Promise.resolve()方法就起到这个作用,且实例状态为resolve:
Promise.resolve('foo')
// 等价于
return new Promise(resolve => resolve('foo'))
Promise.resolve()的参数有以下几种情况:
- 参数是一个
Promise实例:
const promise = new Promise(resolve => {
resolve('resolve')
})
let p = Promise.resolve(promise)
// p 相当于
let p = new Promise(resolve => {
resolve(promise)
})
console.log(p === promise) // true
- 参数是一个
thenable对象:
thenable对象指的是具有then方法的对象,Promise.resolve()会将这个对象转为Promise对象,然后立即执行thenable对象的then方法
const thenable = {
then(resolve, reject) {
resolve('resolved')
}
}
const p1 = Promise.resolve(thenable)
p1.then(res => {
console.log(res) // 'resolved'
})
上面代码中,
thenable对象的then()方法执行后,对象p1的状态就变为resolved,从而立即执行最后那个then()方法指定的回调函数,输出’resolved’
- 参数不是具有
then()方法的对象,或者根本不是对象
const promise = Promise.resolve({name: 'James'})
promise.then(res => {
console.log(res) // {name: 'James'}
})
当参数是不含有
then()方法的对象,或者根本不是对象时,会直接返回该参数
- 不带有任何参数
const promise = Promise.resolve()
promise.then(res => {
console.log(res) // undefined
})
Promise.resolve()`方法允许调用时不带参数,直接返回一个`resolved`状态的 `Promise` 对象,传参为`undefined
Promise.reject()
Promise.reject(reason)`方法也会返回一个新的 `Promise` 实例,该实例的状态为`rejected
const promise = Promise.reject('Error')
// 等价于
const promise = new Promise((resolve, reject) => {
reject('Error')
})
Promise.all()
Promise.all()方法用于将多个 Promise 实例,包装成一个新的 Promise 实例
const p1 = new Promise((resolve, reject) => {})
const p1 = new Promise((resolve, reject) => {})
const p1 = new Promise((resolve, reject) => {})
const promise = Promise.all([p1, p2, p3])
promise.then(result => {}, error => {})
面代码中,Promise.all()方法接受一个数组作为参数,p1、p2、p3都是 Promise 实例,如果不是,就会调用Promise.resolve方法,将参数转为 Promise 实例,再进一步处理。另外,Promise.all()方法的参数可以不是数组,但必须具有 Iterator 接口,且返回的每个成员都是 Promise 实例。p的状态由p1、p2、p3决定,分成两种情况:
- 只有
p1、p2、p3的状态都变成fulfilled,p的状态才会变成fulfilled,此时p1、p2、p3的返回值组成一个数组,传递给p的回调函数 - 只要
p1、p2、p3之中有一个被rejected,p的状态就变成rejected,此时第一个被reject的实例的返回值,会传递给p的回调函数
const number = 35
const p1 = new Promise((resolve, reject) => {
if (number >= 10) resolve('p1 success!')
else reject('p1 failed!')
})
const p2 = new Promise((resolve, reject) => {
if (number >= 20) resolve('p2 success!')
else reject('p2 failed!')
})
const p3 = new Promise((resolve, reject) => {
if (number >= 30) resolve('p3 success!')
else reject('p3 failed!')
})
const promise = Promise.all([p1, p2, p3]).then(res => {
console.log(res) // 当number为35时,res值为[ 'p1 success!', 'p2 success!', 'p3 success!' ]
}, error => {
console.log(error) // 当number为25时,p3会返回rejected,promise状态会变成rejected,error值为p3 failed!
})
如果作为参数的
Promise实例,自己定义了catch方法,那么它一旦被rejected,并不会触发Promise.all()的catch方法
const p1 = new Promise(resolve => {
resolve("hello");
}).then(result => result).catch(e => e);
const p2 = new Promise(() => {
throw new Error("报错了");
}).then(result => result).catch(e => e); // p2实际上是catch返回的promise实例
Promise.all([p1, p2]).then(result => console.log(result)).catch(e => console.log(e));
22.async/await
async声明function是一个异步函数,返回一个promise对象,可以使用 then 方法添加回调函数。
async函数内部return语句返回的值,会成为then方法回调函数的参数。
如果async函数没有返回值 async函数返回一个undefined的promise对象
async function test() {
return 'test'
}
console.log(test) // [AsyncFunction: test] async函数是[`AsyncFunction`]构造函数的实例
console.log(test()) // Promise { 'test' }
// async返回的是一个promise对象
test().then(res => {
console.log(res) // 'test'
})
await 操作符只能在异步函数 async function 内部使用
如果一个 Promise 被传递给一个 await 操作符,await 将等待 Promise 正常处理完成并返回其处理结果,也就是说它会阻塞后面的代码,等待 Promise 对象结果;如果等待的不是 Promise 对象,则返回该值本身
async function test() {
return new Promise((resolve)=>{
setTimeout(() => {
resolve('test 1000');
}, 1000);
})
}
function fn() {
return 'fn';
}
async function next() {
let res0 = await fn(),
res1 = await test(),
res2 = await fn();
console.log(res0);
console.log(res1);
console.log(res2);
}
next(); // 1s 后才打印出结果 为什么呢 就是因为 res1在等待promise的结果 阻塞了后面代码。
错误处理
如果
await后面的异步操作出错,那么等同于async函数返回的 Promise 对象被reject
async function test() {
await Promise.reject('错误了')
}
test().then(res=>{
console.log('success',res)
},err=>{
console.log('err ',err) // err 错误了
})
防止出错的方法,也是将其放在
try...catch代码块之中
async function test() {
try {
await new Promise(function (resolve, reject) {
throw new Error('错误了');
});
} catch(e) {
console.log('err', e)
}
return await('成功了');
}
多个
await命令后面的异步操作,如果不存在继发关系(即互不依赖),最好让它们同时触发
let foo = await getFoo();
let bar = await getBar();
// 上面这样写法 getFoo完成以后,才会执行getBar
// 同时触发写法 ↓
// 写法一
let [foo, bar] = await Promise.all([getFoo(), getBar()]);
// 写法二
let fooPromise = getFoo();
let barPromise = getBar();
let foo = await fooPromise;
let bar = await barPromise;
优点
async/await的优势在于处理由多个Promise组成的 then 链,在之前的Promise文章中提过用then处理回调地狱的问题,async/await相当于对promise的进一步优化。 假设一个业务,分多个步骤,且每个步骤都是异步的,而且依赖上个步骤的执行结果
// 假设表单提交前要通过俩个校验接口
async function check(ms) { // 模仿异步
return new Promise((resolve)=>{
setTimeout(() => {
resolve(`check ${ms}`);
}, ms);
})
}
function check1() {
console.log('check1');
return check(1000);
}
function check2() {
console.log('check2');
return check(2000);
}
// -------------promise------------
function submit() {
console.log('submit');
// 经过俩个校验 多级关联 promise传值嵌套较深
check1().then(res1=>{
check2(res1).then(res2=>{
/*
* 提交请求
*/
})
})
}
submit();
// -------------async/await-----------
async function asyncAwaitSubmit() {
let res1 = await check1(),
res2 = await check2(res1);
console.log(res1, res2);
/*
* 提交请求
*/
}
23.TCP 的三次握手和四次挥手?
三次握手:
- 第一次握手:客户端给服务器发送一个
SYN报文。 - 第二次握手:服务器收到
SYN报文后,应答一个ACK报文,同时发出自己的SYN报文,即应答了一个SYN + ACK报文。 - 第三握手:客户端收到
SYN + ACK报文后,回应一个ACk报文。服务器收到ACK报文之后,三次握手完毕。
四次挥手:
- 第一次挥手:客户端认为没有数据需要继续发送,于是向服务器发送一个
FIN报文,申请断开客户端到服务器端的连接,报文中同时会指定一个序列号seq(等于已传送数据的最后一个字节的序号加1)。此时,客户端进入FIN_WAIT_1状态。 - 第二次挥手:服务器接收到
FIN报文后,向客户端发送一个确认报文ACK,表示已经接收到了客户端释放连接的请求,以后不会再接收客户端发送过来的数据。同时会把客户端报文中的序列号seq加1,作为ACK报文中的序列号值。此时,服务端处于CLOSE_WAIT状态。客户端接收到报文之后,进入FIN_WAIT_2状态,等待服务器发送连接释放报文(由于TCP连接是全双工的,此时客户端到服务区器的连接已释放,但是服务器仍可以发送数据给客户端)。 - 第三次挥手:服务器端发送完所有的数据,会向客户端发送一个
FIN报文,申请断开服务器端到客户端的连接。此时,服务器进入LAST_ACK状态。 - 第四次挥手:客户端接收到
FIN报文之后,向服务器发送一个ACK报文作为应答,且把服务器报文中的序列号值加1作为ACK报文的序列号值。此时,客户端就进入TIME_WAIT状态。需要注意的是,该阶段会持续一段时间,以确保服务器收到了该ACK报文。这个时间是2 * MSL(最长报文段时间),如果在这个时间内,没有收到服务器的重发请求,时间过后,客户端就进入CLOSED状态;如果收到了服务器的重发请求就需要重新发送确认报文。服务器只要一收到ACK报文,就会立即进入CLOSED状态。
24.理解web安全吗?都有哪几种,介绍以及如何预防
1.XSS,也就是跨站脚本注入
攻击方法:
1. 手动攻击
编写注入脚本,比如”/> created --> beforeMount --> mounted --> activated --> beforeUpdate --> updated --> deactivated
再次进入组件时:activated --> beforeUpdate --> updated --> deactivated
27.mixin
mixin(混入), 它提供了一种非常灵活的方式,来分发 Vue 组件中的可复用功能。
使用场景: 不同组件中经常会用到一些相同或相似的代码,这些代码的功能相对独立。可以通过mixin 将相同或相似的代码提出来。
缺点:
- 变量来源不明确
- 多 mixin 可能会造成命名冲突(解决方式:Vue 3的组合API)
- mixin 和组件出现多对多的关系,使项目复杂度变高。
28.对 SPA 的理解?
-
概念:
SPA(Single-page application),即单页面应用,它是一种网络应用程序或网站的模型,通过动态重写当前页面来与用户交互,这种方法避免了页面之间切换时打断用户体验。在SPA中,所有必要的代码(HTML、JavaScript 和 CSS)都通过单个页面的加载而检索,或者根据需要(通常是响应用户操作)动态装载适当的资源并添加到页面。页面在任何时间点都不会重新加载,也不会将控制转移到其他页面。举个例子,就像一个杯子,上午装的是牛奶,中午装的是咖啡,下午装的是茶,变得始终是内容,杯子始终不变。
-
SPA与MPA的区别:
MPA(Muti-page application),即多页面应用。在MPA中,每个页面都是一个主页面,都是独立的,每当访问一个页面时,都需要重新加载 Html、CSS、JS 文件,公共文件则根据需求按需加载。
SPA
MPA
组成
一个主页面和多个页面片段
多个主页面
url模式
hash模式
history模式
SEO搜索引擎优化
难实现,可使用SSR方式改善
容易实现
数据传递
容易
通过url、cookie、localStorage等传递
页面切换
速度快,用户体验良好
切换加载资源,速度慢,用户体验差
维护成本
相对容易
相对复杂
-
SPA的优缺点:
优点:
- 具有桌面应用的即时性、网站的可移植性和可访问性
- 用户体验好、快,内容的改变不需要重新加载整个页面
- 良好的前后端分离,分工更明确
缺点:
- 不利于搜索引擎的抓取
- 首次渲染速度相对较慢
29.子组件是否可以直接改变父组件的数据?
- 所有的
prop都遵循着单项绑定原则,props因父组件的更新而变化,自然地将新状态向下流往子组件,而不会逆向传递。这避免了子组件意外修改父组件的状态的情况,不然应用的数据流将很容易变得混乱而难以理解。
另外,每次父组件更新后,所有的子组件中的props都会被更新为最新值,这就意味着不应该子组件中去修改一个prop,若这么做了,Vue 会在控制台上抛出警告。
- 实际开发过程中通常有两个场景导致要修改
prop:
prop被用于传入初始值,而子组件想在之后将其作为一个局部数据属性。这种情况下,最好是新定义一个局部数据属性,从props获取初始值即可。- 需要对传入的
prop值做进一步转换。最好是基于该prop值定义一个计算属性。
- 实践中,如果确实要更改父组件属性,应
emit一个事件让父组件变更。当对象或数组作为props被传入时,虽然子组件无法更改props绑定,但仍然可以更改对象或数组内部的值。这是因为JS的对象和数组是按引用传递,而对于 Vue 来说,禁止这样的改动虽然可能,但是有很大的性能损耗,比较得不偿失。
30.动态路由?
很多时候,我们需要将给定匹配模式的路由映射到同一个组件,这种情况就需要定义动态路由。例如,我们有一个 User组件,对于所有 ID 各不相同的用户,都要使用这个组件来渲染。那么,我们可以在 vue-router 的路由路径中使用动态路径参数(dynamic segment)来达到这个效果:{path: '/user/:id', compenent: User},其中:id就是动态路径参数。
31.对Vuex的理解?
- 概念:
Vuex 是 Vue 专用的状态管理库,它以全局方式集中管理应用的状态,并以相应的规则保证状态以一种可预测的方式发生变化。
- 解决的问题:
Vuex 主要解决的问题是多组件之间状态共享。利用各种通信方式,虽然也能够实现状态共享,但是往往需要在多个组件之间保持状态的一致性,这种模式很容易出问题,也会使程序逻辑变得复杂。Vuex 通过把组件的共享状态抽取出来,以全局单例模式管理,这样任何组件都能用一致的方式获取和修改状态,响应式的数据也能够保证简洁的单向流动,使代码变得更具结构化且易于维护。
- 什么时候用:
Vuex 并非是必须的,它能够管理状态,但同时也带来更多的概念和框架。如果我们不打算开发大型单页应用或应用里没有大量全局的状态需要维护,完全没有使用Vuex的必要,一个简单的 store 模式就够了。反之,Vuex将是自然而然的选择。
- 用法:
Vuex 将全局状态放入state对象中,它本身是一颗状态树,组件中使用store实例的state访问这些状态;然后用配套的mutation方法修改这些状态,并且只能用mutation修改状态,在组件中调用commit方法提交mutation;如果应用中有异步操作或复杂逻辑组合,需要编写action,执行结束如果有状态修改仍需提交mutation,组件中通过dispatch派发action。最后是模块化,通过modules选项组织拆分出去的各个子模块,在访问状态(state)时需注意添加子模块的名称,如果子模块有设置namespace,那么提交mutation和派发action时还需要额外的命名空间前缀。
32.页面刷新后Vuex 状态丢失怎么解决?
Vuex 只是在内存中保存状态,刷新后就会丢失,如果要持久化就需要保存起来。
localStorage就很合适,提交mutation的时候同时存入localStorage,在store中把值取出来作为state的初始值即可。
也可以使用第三方插件,推荐使用vuex-persist插件,它是为 Vuex 持久化储存而生的一个插件,不需要你手动存取storage,而是直接将状态保存至 cookie 或者 localStorage中。
33.关于 Vue SSR 的理解?
SSR即服务端渲染(Server Side Render),就是将 Vue 在客户端把标签渲染成 html 的工作放在服务端完成,然后再把 html 直接返回给客户端。
- 优点:
有着更好的 SEO,并且首屏加载速度更快。
- 缺点:
开发条件会受限制,服务器端渲染只支持 beforeCreate 和 created 两个钩子,当我们需要一些外部扩展库时需要特殊处理,服务端渲染应用程序也需要处于 Node.js 的运行环境。服务器会有更大的负载需求。
34.了解哪些 Vue 的性能优化方法?
- 路由懒加载。有效拆分应用大小,访问时才异步加载。
keep-alive缓存页面。避免重复创建组件实例,且能保留缓存组件状态。v-for遍历避免同时使用v-if。实际上在 Vue 3 中已经是一个错误用法了。- 长列表性能优化,可采用虚拟列表。
v-once。不再变化的数据使用v-once。- 事件销毁。组件销毁后把全局变量和定时器销毁。
- 图片懒加载。
- 第三方插件按需引入。
- 子组件分割。较重的状态组件适合拆分。
- 服务端渲染。
35.vue 中使用了哪些设计模式
1.工厂模式 - 传入参数即可创建实例
虚拟 DOM 根据参数的不同返回基础标签的 Vnode 和组件 Vnode
2.单例模式 - 整个程序有且仅有一个实例
vuex 和 vue-router 的插件注册方法 install 判断如果系统存在实例就直接返回掉
3.发布-订阅模式 (vue 事件机制)
4.观察者模式 (响应式数据原理)
5.装饰模式: (@装饰器的用法)
6.策略模式 策略模式指对象有某个行为,但是在不同的场景中,该行为有不同的实现方案-比如选项的合并策略
36.Vue 的生命周期方法有哪些 一般在哪一步发请求
beforeCreate 在实例初始化之后,数据观测(data observer) 和 event/watcher 事件配置之前被调用。在当前阶段 data、methods、computed 以及 watch 上的数据和方法都不能被访问
created 实例已经创建完成之后被调用。在这一步,实例已完成以下的配置:数据观测(data observer),属性和方法的运算, watch/event 事件回调。这里没有el,如果非要想与Dom进行交互,可以通过vm.el,如果非要想与 Dom 进行交互,可以通过 vm.el,如果非要想与Dom进行交互,可以通过vm.nextTick 来访问 Dom
beforeMount 在挂载开始之前被调用:相关的 render 函数首次被调用。
mounted 在挂载完成后发生,在当前阶段,真实的 Dom 挂载完毕,数据完成双向绑定,可以访问到 Dom 节点
beforeUpdate 数据更新时调用,发生在虚拟 DOM 重新渲染和打补丁(patch)之前。可以在这个钩子中进一步地更改状态,这不会触发附加的重渲染过程
updated 发生在更新完成之后,当前阶段组件 Dom 已完成更新。要注意的是避免在此期间更改数据,因为这可能会导致无限循环的更新,该钩子在服务器端渲染期间不被调用。
beforeDestroy 实例销毁之前调用。在这一步,实例仍然完全可用。我们可以在这时进行善后收尾工作,比如清除计时器。
destroyed Vue 实例销毁后调用。调用后,Vue 实例指示的所有东西都会解绑定,所有的事件监听器会被移除,所有的子实例也会被销毁。 该钩子在服务器端渲染期间不被调用。
activated keep-alive 专属,组件被激活时调用
deactivated keep-alive 专属,组件被销毁时调用
异步请求在哪一步发起?
可以在钩子函数 created、beforeMount、mounted 中进行异步请求,因为在这三个钩子函数中,data 已经创建,可以将服务端端返回的数据进行赋值。
如果异步请求不需要依赖 Dom 推荐在 created 钩子函数中调用异步请求,因为在 created 钩子函数中调用异步请求有以下优点:
- 能更快获取到服务端数据,减少页面 loading 时间;
- ssr 不支持 beforeMount 、mounted 钩子函数,所以放在 created 中有助于一致性;
37.vue3.0 特性你有什么了解的吗?
Vue 3.0 正走在发布的路上,Vue 3.0 的目标是让 Vue 核心变得更小、更快、更强大,因此 Vue 3.0 增加以下这些新特性:
(1)监测机制的改变
3.0 将带来基于代理 Proxy 的 observer 实现,提供全语言覆盖的反应性跟踪。这消除了 Vue 2 当中基于 Object.defineProperty 的实现所存在的很多限制:
- 只能监测属性,不能监测对象
- 检测属性的添加和删除;
- 检测数组索引和长度的变更;
- 支持 Map、Set、WeakMap 和 WeakSet。
新的 observer 还提供了以下特性:
- 用于创建 observable 的公开 API。这为中小规模场景提供了简单轻量级的跨组件状态管理解决方案。
- 默认采用惰性观察。在 2.x 中,不管反应式数据有多大,都会在启动时被观察到。如果你的数据集很大,这可能会在应用启动时带来明显的开销。在 3.x 中,只观察用于渲染应用程序最初可见部分的数据。
- 更精确的变更通知。在 2.x 中,通过 Vue.set 强制添加新属性将导致依赖于该对象的 watcher 收到变更通知。在 3.x 中,只有依赖于特定属性的 watcher 才会收到通知。
- 不可变的 observable:我们可以创建值的“不可变”版本(即使是嵌套属性),除非系统在内部暂时将其“解禁”。这个机制可用于冻结 prop 传递或 Vuex 状态树以外的变化。
- 更好的调试功能:我们可以使用新的 renderTracked 和 renderTriggered 钩子精确地跟踪组件在什么时候以及为什么重新渲染。
(2)模板
模板方面没有大的变更,只改了作用域插槽,2.x 的机制导致作用域插槽变了,父组件会重新渲染,而 3.0 把作用域插槽改成了函数的方式,这样只会影响子组件的重新渲染,提升了渲染的性能。
同时,对于 render 函数的方面,vue3.0 也会进行一系列更改来方便习惯直接使用 api 来生成 vdom 。
(3)对象式的组件声明方式
vue2.x 中的组件是通过声明的方式传入一系列 option,和 TypeScript 的结合需要通过一些装饰器的方式来做,虽然能实现功能,但是比较麻烦。3.0 修改了组件的声明方式,改成了类式的写法,这样使得和 TypeScript 的结合变得很容易。
此外,vue 的源码也改用了 TypeScript 来写。其实当代码的功能复杂之后,必须有一个静态类型系统来做一些辅助管理。现在 vue3.0 也全面改用 TypeScript 来重写了,更是使得对外暴露的 api 更容易结合 TypeScript。静态类型系统对于复杂代码的维护确实很有必要。
(4)其它方面的更改
vue3.0 的改变是全面的,上面只涉及到主要的 3 个方面,还有一些其他的更改:
- 支持自定义渲染器,从而使得 weex 可以通过自定义渲染器的方式来扩展,而不是直接 fork 源码来改的方式。
- 支持 Fragment(多个根节点)和 Protal(在 dom 其他部分渲染组建内容)组件,针对一些特殊的场景做了处理。
- 基于 treeshaking 优化,提供了更多的内置功能。
38.为什么在 Vue3.0 采用了 Proxy,抛弃了 Object.defineProperty?
Object.defineProperty 本身有一定的监控到数组下标变化的能力,但是在 Vue 中,从性能/体验的性价比考虑,尤大大就弃用了这个特性。为了解决这个问题,经过 vue 内部处理后可以使用以下几种方法来监听数组
push();
pop();
shift();
unshift();
splice();
sort();
reverse();
由于只针对了以上 7 种方法进行了 hack 处理,所以其他数组的属性也是检测不到的,还是具有一定的局限性。
Object.defineProperty 只能劫持对象的属性,因此我们需要对每个对象的每个属性进行遍历。Vue 2.x 里,是通过 递归 + 遍历 data 对象来实现对数据的监控的,如果属性值也是对象那么需要深度遍历,显然如果能劫持一个完整的对象是才是更好的选择。
Proxy 可以劫持整个对象,并返回一个新的对象。Proxy 不仅可以代理对象,还可以代理数组。还可以代理动态增加的属性。
39.Vue3.0 和 2.0 的响应式原理区别
Vue3.x 改用 Proxy 替代 Object.defineProperty。因为 Proxy 可以直接监听对象和数组的变化,并且有多达 13 种拦截方法。
相关代码如下
import { mutableHandlers } from "./baseHandlers"; // 代理相关逻辑
import { isObject } from "./util"; // 工具方法
export function reactive(target) {
// 根据不同参数创建不同响应式对象
return createReactiveObject(target, mutableHandlers);
}
function createReactiveObject(target, baseHandler) {
if (!isObject(target)) {
return target;
}
const observed = new Proxy(target, baseHandler);
return observed;
}
const get = createGetter();
const set = createSetter();
function createGetter() {
return function get(target, key, receiver) {
// 对获取的值进行放射
const res = Reflect.get(target, key, receiver);
console.log("属性获取", key);
if (isObject(res)) {
// 如果获取的值是对象类型,则返回当前对象的代理对象
return reactive(res);
}
return res;
};
}
function createSetter() {
return function set(target, key, value, receiver) {
const oldValue = target[key];
const hadKey = hasOwn(target, key);
const result = Reflect.set(target, key, value, receiver);
if (!hadKey) {
console.log("属性新增", key, value);
} else if (hasChanged(value, oldValue)) {
console.log("属性值被修改", key, value);
}
return result;
};
}
export const mutableHandlers = {
get, // 当获取属性时调用此方法
set, // 当修改属性时调用此方法
};
40.Vue 项目进行哪些优化?
(1)代码层面的优化
- v-if 和 v-show 区分使用场景
- computed 和 watch 区分使用场景
- v-for 遍历必须为 item 添加 key,且避免同时使用 v-if
- 长列表性能优化
- 事件的销毁
- 图片资源懒加载
- 路由懒加载
- 第三方插件的按需引入
- 优化无限列表性能
- 服务端渲染 SSR or 预渲染
(2)Webpack 层面的优化
- Webpack 对图片进行压缩
- 减少 ES6 转为 ES5 的冗余代码
- 提取公共代码
- 模板预编译
- 提取组件的 CSS
- 优化 SourceMap
- 构建结果输出分析
- Vue 项目的编译优化
(3)基础的 Web 技术的优化
- 开启 gzip 压缩
- 浏览器缓存
- CDN 的使用
- 使用 Chrome Performance 查找性能瓶颈
41.Vue中v-html会导致哪些问题
- 可能会导致
xss 攻击
v-html 会替换掉标签内部的子元素
let template = require('vue-template-compiler');
let r = template.compile(``)
// with(this){return _c('div',{domProps: {"innerHTML":_s('hello')}})}
console.log(r.render);
// _c 定义在core/instance/render.js
// _s 定义在core/instance/render-helpers/index,js
if (key === 'textContent' || key === 'innerHTML') {
if (vnode.children) vnode.children.length = 0
if (cur === oldProps[key]) continue // #6601 work around Chrome version <= 55 bug where single textNode // replaced by innerHTML/textContent retains its parentNode property
if (elm.childNodes.length === 1) {
elm.removeChild(elm.childNodes[0])
}
}
42.Vue与React的区别
相同点:
Virtual DOM。其中最大的一个相似之处就是都使用了Virtual DOM。(当然Vue是在Vue2.x才引用的)也就是能让我们通过操作数据的方式来改变真实的DOM状态。因为其实Virtual DOM的本质就是一个JS对象,它保存了对真实DOM的所有描述,是真实DOM的一个映射,所以当我们在进行频繁更新元素的时候,改变这个JS对象的开销远比直接改变真实DOM要小得多。- 组件化的开发思想。第二点来说就是它们都提倡这种组件化的开发思想,也就是建议将应用分拆成一个个功能明确的模块,再将这些模块整合在一起以满足我们的业务需求。
Props。Vue和React中都有props的概念,允许父组件向子组件传递数据。- 构建工具、Chrome插件、配套框架。还有就是它们的构建工具以及Chrome插件、配套框架都很完善。比如构建工具,
React中可以使用CRA,Vue中可以使用对应的脚手架vue-cli。对于配套框架Vue中有vuex、vue-router,React中有react-router、redux。
不同点
- 模版的编写。最大的不同就是模版的编写,
Vue鼓励你去写近似常规HTML的模板,React推荐你使用JSX去书写。
- 状态管理与对象属性。在
React中,应用的状态是比较关键的概念,也就是state对象,它允许你使用setState去更新状态。但是在Vue中,state对象并不是必须的,数据是由data属性在Vue对象中进行管理。
- 虚拟
DOM的处理方式不同。Vue中的虚拟DOM控制了颗粒度,组件层面走watcher通知,而组件内部走vdom做diff,这样,既不会有太多watcher,也不会让vdom的规模过大。而React走了类似于CPU调度的逻辑,把vdom这棵树,微观上变成了链表,然后利用浏览器的空闲时间来做diff
43.函数式组件优势和原理
函数组件的特点
- 函数式组件需要在声明组件是指定
functional:true
- 不需要实例化,所以没有
this,this通过render函数的第二个参数context来代替
- 没有生命周期钩子函数,不能使用计算属性,
watch
- 不能通过
$emit 对外暴露事件,调用事件只能通过context.listeners.click的方式调用外部传入的事件
- 因为函数式组件是没有实例化的,所以在外部通过
ref去引用组件时,实际引用的是HTMLElement
- 函数式组件的
props可以不用显示声明,所以没有在props里面声明的属性都会被自动隐式解析为prop,而普通组件所有未声明的属性都解析到$attrs里面,并自动挂载到组件根元素上面(可以通过inheritAttrs属性禁止)
优点
- 由于函数式组件不需要实例化,无状态,没有生命周期,所以渲染性能要好于普通组件
- 函数式组件结构比较简单,代码结构更清晰
使用场景:
- 一个简单的展示组件,作为容器组件使用 比如
router-view 就是一个函数式组件
- “高阶组件”——用于接收一个组件作为参数,返回一个被包装过的组件
例子
Vue.component('functional',{ // 构造函数产生虚拟节点的
functional:true, // 函数式组件 // data={attrs:{}}
render(h){
return h('div','test')
}
})
const vm = new Vue({
el: '#app'
})
源码相关
// functional component
if (isTrue(Ctor.options.functional)) { // 带有functional的属性的就是函数式组件
return createFunctionalComponent(Ctor, propsData, data, context, children)
}
// extract listeners, since these needs to be treated as
// child component listeners instead of DOM listeners
const listeners = data.on // 处理事件
// replace with listeners with .native modifier
// so it gets processed during parent component patch.
data.on = data.nativeOn // 处理原生事件
// install component management hooks onto the placeholder node
installComponentHooks(data) // 安装组件相关钩子 (函数式组件没有调用此方法,从而性能高于普通组件)
44.Vue-router 路由钩子在生命周期的体现
一、Vue-Router导航守卫
有的时候,需要通过路由来进行一些操作,比如最常见的登录权限验证,当用户满足条件时,才让其进入导航,否则就取消跳转,并跳到登录页面让其登录。 为此有很多种方法可以植入路由的导航过程:全局的,单个路由独享的,或者组件级的
- 全局路由钩子
vue-router全局有三个路由钩子;
- router.beforeEach 全局前置守卫 进入路由之前
- router.beforeResolve 全局解析守卫(2.5.0+)在 beforeRouteEnter 调用之后调用
- router.afterEach 全局后置钩子 进入路由之后
具体使用∶
- beforeEach(判断是否登录了,没登录就跳转到登录页)
router.beforeEach((to, from, next) => {
let ifInfo = Vue.prototype.$common.getSession('userData'); // 判断是否登录的存储信息
if (!ifInfo) {
// sessionStorage里没有储存user信息
if (to.path == '/') {
//如果是登录页面路径,就直接next()
next();
} else {
//不然就跳转到登录
Message.warning("请重新登录!");
window.location.href = Vue.prototype.$loginUrl;
}
} else {
return next();
}
})
- afterEach (跳转之后滚动条回到顶部)
router.afterEach((to, from) => {
// 跳转之后滚动条回到顶部
window.scrollTo(0,0);
});
- 单个路由独享钩子
beforeEnter 如果不想全局配置守卫的话,可以为某些路由单独配置守卫,有三个参数∶ to、from、next
export default [
{
path: '/',
name: 'login',
component: login,
beforeEnter: (to, from, next) => {
console.log('即将进入登录页面')
next()
}
}
]
- 组件内钩子
beforeRouteUpdate、beforeRouteEnter、beforeRouteLeave
这三个钩子都有三个参数∶to、from、next
- beforeRouteEnter∶ 进入组件前触发
- beforeRouteUpdate∶ 当前地址改变并且改组件被复用时触发,举例来说,带有动态参数的路径foo/∶id,在 /foo/1 和 /foo/2 之间跳转的时候,由于会渲染同样的foa组件,这个钩子在这种情况下就会被调用
- beforeRouteLeave∶ 离开组件被调用
注意点,beforeRouteEnter组件内还访问不到this,因为该守卫执行前组件实例还没有被创建,需要传一个回调给 next来访问,例如:
beforeRouteEnter(to, from, next) {
next(target => {
if (from.path == '/classProcess') {
target.isFromProcess = true
}
})
}
二、Vue路由钩子在生命周期函数的体现
- 完整的路由导航解析流程(不包括其他生命周期)
- 触发进入其他路由。
- 调用要离开路由的组件守卫beforeRouteLeave
- 调用局前置守卫∶ beforeEach
- 在重用的组件里调用 beforeRouteUpdate
- 调用路由独享守卫 beforeEnter。
- 解析异步路由组件。
- 在将要进入的路由组件中调用 beforeRouteEnter
- 调用全局解析守卫 beforeResolve
- 导航被确认。
- 调用全局后置钩子的 afterEach 钩子。
- 触发DOM更新(mounted)。
- 执行beforeRouteEnter 守卫中传给 next 的回调函数
- 触发钩子的完整顺序
路由导航、keep-alive、和组件生命周期钩子结合起来的,触发顺序,假设是从a组件离开,第一次进入b组件∶
- beforeRouteLeave:路由组件的组件离开路由前钩子,可取消路由离开。
- beforeEach:路由全局前置守卫,可用于登录验证、全局路由loading等。
- beforeEnter:路由独享守卫
- beforeRouteEnter:路由组件的组件进入路由前钩子。
- beforeResolve:路由全局解析守卫
- afterEach:路由全局后置钩子
- beforeCreate:组件生命周期,不能访问tAis。
- created;组件生命周期,可以访问tAis,不能访问dom。
- beforeMount:组件生命周期
- deactivated:离开缓存组件a,或者触发a的beforeDestroy和destroyed组件销毁钩子。
- mounted:访问/操作dom。
- activated:进入缓存组件,进入a的嵌套子组件(如果有的话)。
- 执行beforeRouteEnter回调函数next。
- 导航行为被触发到导航完成的整个过程
- 导航行为被触发,此时导航未被确认。
- 在失活的组件里调用离开守卫 beforeRouteLeave。
- 调用全局的 beforeEach守卫。
- 在重用的组件里调用 beforeRouteUpdate 守卫(2.2+)。
- 在路由配置里调用 beforeEnteY。
- 解析异步路由组件(如果有)。
- 在被激活的组件里调用 beforeRouteEnter。
- 调用全局的 beforeResolve 守卫(2.5+),标示解析阶段完成。
- 导航被确认。
- 调用全局的 afterEach 钩子。
- 非重用组件,开始组件实例的生命周期:beforeCreate&created、beforeMount&mounted
- 触发 DOM 更新。
- 用创建好的实例调用 beforeRouteEnter守卫中传给 next 的回调函数。
- 导航完成
45.Vue-router 导航守卫有哪些
- 全局前置/钩子:beforeEach、beforeResolve、afterEach
- 路由独享的守卫:beforeEnter
- 组件内的守卫:beforeRouteEnter、beforeRouteUpdate、beforeRouteLeave
46.mixin 和 mixins 区别
mixin 用于全局混入,会影响到每个组件实例,通常插件都是这样做初始化的。
Vue.mixin({
beforeCreate() {
// ...逻辑 // 这种方式会影响到每个组件的 beforeCreate 钩子函数
},
});
虽然文档不建议在应用中直接使用 mixin,但是如果不滥用的话也是很有帮助的,比如可以全局混入封装好的 ajax 或者一些工具函数等等。
mixins 应该是最常使用的扩展组件的方式了。如果多个组件中有相同的业务逻辑,就可以将这些逻辑剥离出来,通过 mixins 混入代码,比如上拉下拉加载数据这种逻辑等等。
另外需要注意的是 mixins 混入的钩子函数会先于组件内的钩子函数执行,并且在遇到同名选项的时候也会有选择性的进行合并。
47.vuex是什么?怎么使用?哪种功能场景使用它?
Vuex 是一个专为 Vue.js 应用程序开发的状态管理模式。vuex 就是一个仓库,仓库里放了很多对象。其中 state 就是数据源存放地,对应于一般 vue 对象里面的 data 里面存放的数据是响应式的,vue 组件从 store 读取数据,若是 store 中的数据发生改变,依赖这相数据的组件也会发生更新它通过 mapState 把全局的 state 和 getters 映射到当前组件的 computed 计算属性
vuex 一般用于中大型 web 单页应用中对应用的状态进行管理,对于一些组件间关系较为简单的小型应用,使用 vuex 的必要性不是很大,因为完全可以用组件 prop 属性或者事件来完成父子组件之间的通信,vuex 更多地用于解决跨组件通信以及作为数据中心集中式存储数据。- 使用
Vuex解决非父子组件之间通信问题 vuex 是通过将 state 作为数据中心、各个组件共享 state 实现跨组件通信的,此时的数据完全独立于组件,因此将组件间共享的数据置于 State 中能有效解决多层级组件嵌套的跨组件通信问题
vuex 的 State 在单页应用的开发中本身具有一个“数据库”的作用,可以将组件中用到的数据存储在 State 中,并在 Action 中封装数据读写的逻辑。这时候存在一个问题,一般什么样的数据会放在 State 中呢? 目前主要有两种数据会使用 vuex 进行管理:
- 组件之间全局共享的数据
- 通过后端异步请求的数据
包括以下几个模块
state:Vuex 使用单一状态树,即每个应用将仅仅包含一个store 实例。里面存放的数据是响应式的,vue 组件从 store 读取数据,若是 store 中的数据发生改变,依赖这相数据的组件也会发生更新。它通过 mapState 把全局的 state 和 getters 映射到当前组件的 computed 计算属性mutations:更改Vuex的store中的状态的唯一方法是提交mutationgetters:getter 可以对 state 进行计算操作,它就是 store 的计算属性虽然在组件内也可以做计算属性,但是 getters 可以在多给件之间复用如果一个状态只在一个组件内使用,是可以不用 gettersaction:action 类似于 muation, 不同在于:action 提交的是 mutation,而不是直接变更状态action 可以包含任意异步操作modules:面对复杂的应用程序,当管理的状态比较多时;我们需要将vuex的store对象分割成模块(modules)
48.实现双向绑定
我们还是以Vue为例,先来看看Vue中的双向绑定流程是什么的
new Vue()首先执行初始化,对data执行响应化处理,这个过程发生Observe中- 同时对模板执行编译,找到其中动态绑定的数据,从
data中获取并初始化视图,这个过程发生在Compile中
- 同时定义⼀个更新函数和
Watcher,将来对应数据变化时Watcher会调用更新函数
- 由于
data的某个key在⼀个视图中可能出现多次,所以每个key都需要⼀个管家Dep来管理多个Watcher
- 将来data中数据⼀旦发生变化,会首先找到对应的
Dep,通知所有Watcher执行更新函数
流程图如下:

先来一个构造函数:执行初始化,对data执行响应化处理
class Vue {
constructor(options) {
this.$options = options;
this.$data = options.data;
// 对data选项做响应式处理
observe(this.$data);
// 代理data到vm上
proxy(this);
// 执行编译
new Compile(options.el, this);
}
}
对data选项执行响应化具体操作
function observe(obj) {
if (typeof obj !== "object" || obj == null) {
return;
}
new Observer(obj);
}
class Observer {
constructor(value) {
this.value = value;
this.walk(value);
}
walk(obj) {
Object.keys(obj).forEach((key) => {
defineReactive(obj, key, obj[key]);
});
}
}
编译Compile
对每个元素节点的指令进行扫描跟解析,根据指令模板替换数据,以及绑定相应的更新函数

class Compile {
constructor(el, vm) {
this.$vm = vm;
this.$el = document.querySelector(el); // 获取dom
if (this.$el) {
this.compile(this.$el);
}
}
compile(el) {
const childNodes = el.childNodes;
Array.from(childNodes).forEach((node) => { // 遍历子元素
if (this.isElement(node)) { // 判断是否为节点
console.log("编译元素" + node.nodeName);
} else if (this.isInterpolation(node)) {
console.log("编译插值⽂本" + node.textContent); // 判断是否为插值文本 {{}}
}
if (node.childNodes && node.childNodes.length > 0) { // 判断是否有子元素
this.compile(node); // 对子元素进行递归遍历
}
});
}
isElement(node) {
return node.nodeType == 1;
}
isInterpolation(node) {
return node.nodeType == 3 && /\{\{(.*)\}\}/.test(node.textContent);
}
}
依赖收集
视图中会用到data中某key,这称为依赖。同⼀个key可能出现多次,每次都需要收集出来用⼀个Watcher来维护它们,此过程称为依赖收集多个Watcher需要⼀个Dep来管理,需要更新时由Dep统⼀通知

实现思路
defineReactive时为每⼀个key创建⼀个Dep实例- 初始化视图时读取某个
key,例如name1,创建⼀个watcher1
- 由于触发
name1的getter方法,便将watcher1添加到name1对应的Dep中
- 当
name1更新,setter触发时,便可通过对应Dep通知其管理所有Watcher更新
// 负责更新视图
class Watcher {
constructor(vm, key, updater) {
this.vm = vm
this.key = key
this.updaterFn = updater
// 创建实例时,把当前实例指定到Dep.target静态属性上
Dep.target = this
// 读一下key,触发get
vm[key]
// 置空
Dep.target = null
}
// 未来执行dom更新函数,由dep调用的
update() {
this.updaterFn.call(this.vm, this.vm[this.key])
}
}
声明Dep
class Dep {
constructor() {
this.deps = []; // 依赖管理
}
addDep(dep) {
this.deps.push(dep);
}
notify() {
this.deps.forEach((dep) => dep.update());
}
}
创建watcher时触发getter
class Watcher {
constructor(vm, key, updateFn) {
Dep.target = this;
this.vm[this.key];
Dep.target = null;
}
}
依赖收集,创建Dep实例
function defineReactive(obj, key, val) {
this.observe(val);
const dep = new Dep();
Object.defineProperty(obj, key, {
get() {
Dep.target && dep.addDep(Dep.target);// Dep.target也就是Watcher实例
return val;
},
set(newVal) {
if (newVal === val) return;
dep.notify(); // 通知dep执行更新方法
},
});
}
49.watch 原理
watch 本质上是为每个监听属性 setter 创建了一个 watcher,当被监听的属性更新时,调用传入的回调函数。常见的配置选项有 deep 和 immediate,对应原理如下
deep:深度监听对象,为对象的每一个属性创建一个 watcher,从而确保对象的每一个属性更新时都会触发传入的回调函数。主要原因在于对象属于引用类型,单个属性的更新并不会触发对象 setter,因此引入 deep 能够很好地解决监听对象的问题。同时也会引入判断机制,确保在多个属性更新时回调函数仅触发一次,避免性能浪费。immediate:在初始化时直接调用回调函数,可以通过在 created 阶段手动调用回调函数实现相同的效果
50.Vue computed 实现
- 建立与其他属性(如:
data、 Store)的联系;
- 属性改变后,通知计算属性重新计算
实现时,主要如下
- 初始化
data, 使用 Object.defineProperty 把这些属性全部转为 getter/setter。
- 初始化
computed, 遍历 computed 里的每个属性,每个 computed 属性都是一个 watch 实例。每个属性提供的函数作为属性的 getter,使用 Object.defineProperty 转化。
Object.defineProperty getter 依赖收集。用于依赖发生变化时,触发属性重新计算。- 若出现当前
computed 计算属性嵌套其他 computed 计算属性时,先进行其他
51.Vue中如何扩展一个组件
此题属于实践题,考察大家对vue常用api使用熟练度,答题时不仅要列出这些解决方案,同时最好说出他们异同
答题思路:
- 按照逻辑扩展和内容扩展来列举
- 逻辑扩展有:
mixins、extends、composition api
- 内容扩展有
slots;
- 分别说出他们使用方法、场景差异和问题。
- 作为扩展,还可以说说
vue3中新引入的composition api带来的变化
回答范例:
- 常见的组件扩展方法有:
mixins,slots,extends等
- 混入
mixins是分发 Vue 组件中可复用功能的非常灵活的方式。混入对象可以包含任意组件选项。当组件使用混入对象时,所有混入对象的选项将被混入该组件本身的选项
// 复用代码:它是一个配置对象,选项和组件里面一样
const mymixin = {
methods: {
dosomething(){}
}
}
// 全局混入:将混入对象传入
Vue.mixin(mymixin)
// 局部混入:做数组项设置到mixins选项,仅作用于当前组件
const Comp = {
mixins: [mymixin]
}
3.插槽主要用于vue组件中的内容分发,也可以用于组件扩展
子组件Child
<div>
<slot>这个内容会被父组件传递的内容替换slot>
div>
父组件Parent
<div>
<Child>来自父组件内容Child>
div>
如果要精确分发到不同位置可以使用具名插槽,如果要使用子组件中的数据可以使用作用域插槽
4.组件选项中还有一个不太常用的选项extends,也可以起到扩展组件的目的
// 扩展对象
const myextends = {
methods: {
dosomething(){}
}
}
// 组件扩展:做数组项设置到extends选项,仅作用于当前组件
// 跟混入的不同是它只能扩展单个对象
// 另外如果和混入发生冲突,该选项优先级较高,优先起作用
const Comp = {
extends: myextends
}
5.混入的数据和方法不能明确判断来源且可能和当前组件内变量产生命名冲突,vue3中引入的composition api,可以很好解决这些问题,利用独立出来的响应式模块可以很方便的编写独立逻辑并提供响应式的数据,然后在setup选项中组合使用,增强代码的可读性和维护性。例如
// 复用逻辑1
function useXX() {}
// 复用逻辑2
function useYY() {}
// 逻辑组合
const Comp = {
setup() {
const {xx} = useXX()
const {yy} = useYY()
return {xx, yy}
}
}
52.双向绑定的原理是什么
我们都知道 Vue 是数据双向绑定的框架,双向绑定由三个重要部分构成
- 数据层(Model):应用的数据及业务逻辑
- 视图层(View):应用的展示效果,各类UI组件
- 业务逻辑层(ViewModel):框架封装的核心,它负责将数据与视图关联起来
而上面的这个分层的架构方案,可以用一个专业术语进行称呼:MVVM这里的控制层的核心功能便是 “数据双向绑定” 。自然,我们只需弄懂它是什么,便可以进一步了解数据绑定的原理
理解ViewModel
它的主要职责就是:
- 数据变化后更新视图
- 视图变化后更新数据
当然,它还有两个主要部分组成
- 监听器(
Observer):对所有数据的属性进行监听
- 解析器(
Compiler):对每个元素节点的指令进行扫描跟解析,根据指令模板替换数据,以及绑定相应的更新函数
53.Vue为什么需要虚拟DOM?优缺点有哪些
由于在浏览器中操作 DOM是很昂贵的。频繁的操作 DOM,会产生一定的性能问题。这就是虚拟 Dom 的产生原因。Vue2 的 Virtual DOM 借鉴了开源库 snabbdom 的实现。Virtual DOM 本质就是用一个原生的 JS 对象去描述一个 DOM 节点,是对真实 DOM 的一层抽象
优点:
- 保证性能下限 : 框架的虚拟
DOM 需要适配任何上层 API 可能产生的操作,它的一些 DOM 操作的实现必须是普适的,所以它的性能并不是最优的;但是比起粗暴的 DOM 操作性能要好很多,因此框架的虚拟 DOM 至少可以保证在你不需要手动优化的情况下,依然可以提供还不错的性能,即保证性能的下限;
- 无需手动操作 DOM : 我们不再需要手动去操作
DOM,只需要写好 View-Model 的代码逻辑,框架会根据虚拟 DOM 和 数据双向绑定,帮我们以可预期的方式更新视图,极大提高我们的开发效率;
- 跨平台 : 虚拟
DOM 本质上是 JavaScript 对象,而 DOM 与平台强相关,相比之下虚拟 DOM 可以进行更方便地跨平台操作,例如服务器渲染、weex 开发等等。
缺点:
- 无法进行极致优化:虽然虚拟
DOM + 合理的优化,足以应对绝大部分应用的性能需求,但在一些性能要求极高的应用中虚拟 DOM 无法进行针对性的极致优化。
- 首次渲染大量
DOM时,由于多了一层虚拟 DOM 的计算,会比 innerHTML 插入慢。
虚拟 DOM 实现原理?
虚拟 DOM 的实现原理主要包括以下 3 部分:
- 用
JavaScript 对象模拟真实 DOM 树,对真实 DOM 进行抽象;
diff 算法 — 比较两棵虚拟 DOM 树的差异;pach 算法 — 将两个虚拟 DOM 对象的差异应用到真正的 DOM 树。
说说你对虚拟 DOM 的理解?回答范例
思路
vdom是什么- 引入
vdom的好处
vdom如何生成,又如何成为dom- 在后续的
diff中的作用
回答范例
- 虚拟
dom顾名思义就是虚拟的dom对象,它本身就是一个 JavaScript 对象,只不过它是通过不同的属性去描述一个视图结构
- 通过引入
vdom我们可以获得如下好处:
- 将真实元素节点抽象成
VNode,有效减少直接操作 dom 次数,从而提高程序性能
- 直接操作
dom 是有限制的,比如:diff、clone 等操作,一个真实元素上有许多的内容,如果直接对其进行 diff 操作,会去额外 diff 一些没有必要的内容;同样的,如果需要进行 clone 那么需要将其全部内容进行复制,这也是没必要的。但是,如果将这些操作转移到 JavaScript 对象上,那么就会变得简单了
- 操作
dom 是比较昂贵的操作,频繁的dom操作容易引起页面的重绘和回流,但是通过抽象 VNode 进行中间处理,可以有效减少直接操作dom的次数,从而减少页面重绘和回流
- 方便实现跨平台
- 同一
VNode 节点可以渲染成不同平台上的对应的内容,比如:渲染在浏览器是 dom 元素节点,渲染在 Native( iOS、Android)变为对应的控件、可以实现 SSR 、渲染到 WebGL 中等等
Vue3 中允许开发者基于 VNode 实现自定义渲染器(renderer),以便于针对不同平台进行渲染
vdom如何生成?在vue中我们常常会为组件编写模板 - template, 这个模板会被编译器 - compiler编译为渲染函数,在接下来的挂载(mount)过程中会调用render函数,返回的对象就是虚拟dom。但它们还不是真正的dom,所以会在后续的patch过程中进一步转化为dom。

- 挂载过程结束后,
vue程序进入更新流程。如果某些响应式数据发生变化,将会引起组件重新render,此时就会生成新的vdom,和上一次的渲染结果diff就能得到变化的地方,从而转换为最小量的dom操作,高效更新视图
为什么要用vdom?案例解析
现在有一个场景,实现以下需求:
[
{ name: "张三", age: "20", address: "北京"},
{ name: "李四", age: "21", address: "武汉"},
{ name: "王五", age: "22", address: "杭州"},
]
将该数据展示成一个表格,并且随便修改一个信息,表格也跟着修改。 用jQuery实现如下:
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Documenttitle>
head>
<body>
<div id="container">div>
<button id="btn-change">改变button>
<script src="https://cdn.bootcss.com/jquery/3.2.0/jquery.js">script>
<script>
const data = [{
name: "张三",
age: "20",
address: "北京"
},
{
name: "李四",
age: "21",
address: "武汉"
},
{
name: "王五",
age: "22",
address: "杭州"
},
];
//渲染函数
function render(data) {
const $container = $('#container');
$container.html('');
const $table = $('');
// 重绘一次
$table.append($('name age address ${item.name} ${item.age} ${item.address}
- 这样点击按钮,会有相应的视图变化,但是你审查以下元素,每次改动之后,
table标签都得重新创建,也就是说table下面的每一个栏目,不管是数据是否和原来一样,都得重新渲染,这并不是理想中的情况,当其中的一栏数据和原来一样,我们希望这一栏不要重新渲染,因为DOM重绘相当消耗浏览器性能。
- 因此我们采用JS对象模拟的方法,将
DOM的比对操作放在JS层,减少浏览器不必要的重绘,提高效率。
- 当然有人说虚拟DOM并不比真实的
DOM快,其实也是有道理的。当上述table中的每一条数据都改变时,显然真实的DOM操作更快,因为虚拟DOM还存在js中diff算法的比对过程。所以,上述性能优势仅仅适用于大量数据的渲染并且改变的数据只是一小部分的情况。
如下DOM结构:
<ul id="list">
<li class="item">Item1li>
<li class="item">Item2li>
ul>
映射成虚拟DOM就是这样:
{
tag: "ul",
attrs: {
id: "list"
},
children: [
{
tag: "li",
attrs: { className: "item" },
children: ["Item1"]
}, {
tag: "li",
attrs: { className: "item" },
children: ["Item2"]
}
]
}
使用snabbdom实现vdom
这是一个简易的实现vdom功能的库,相比vue、react,对于vdom这块更加简易,适合我们学习vdom。vdom里面有两个核心的api,一个是h函数,一个是patch函数,前者用来生成vdom对象,后者的功能在于做虚拟dom的比对和将vdom挂载到真实DOM上
简单介绍一下这两个函数的用法:
h('标签名', {属性}, [子元素])
h('标签名', {属性}, [文本])
patch(container, vnode) // container为容器DOM元素
patch(vnode, newVnode)
现在我们就来用snabbdom重写一下刚才的例子:
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Documenttitle>
head>
<body>
<div id="container">div>
<button id="btn-change">改变button>
<script src="https://cdn.bootcss.com/snabbdom/0.7.3/snabbdom.js">script>
<script src="https://cdn.bootcss.com/snabbdom/0.7.3/snabbdom-class.js">script>
<script src="https://cdn.bootcss.com/snabbdom/0.7.3/snabbdom-props.js">script>
<script src="https://cdn.bootcss.com/snabbdom/0.7.3/snabbdom-style.js">script>
<script src="https://cdn.bootcss.com/snabbdom/0.7.3/snabbdom-eventlisteners.min.js">script>
<script src="https://cdn.bootcss.com/snabbdom/0.7.3/h.js">script>
<script>
let snabbdom = window.snabbdom;
// 定义patch
let patch = snabbdom.init([
snabbdom_class,
snabbdom_props,
snabbdom_style,
snabbdom_eventlisteners
]);
//定义h
let h = snabbdom.h;
const data = [{
name: "张三",
age: "20",
address: "北京"
},
{
name: "李四",
age: "21",
address: "武汉"
},
{
name: "王五",
age: "22",
address: "杭州"
},
];
data.unshift({name: "姓名", age: "年龄", address: "地址"});
let container = document.getElementById('container');
let vnode;
const render = (data) => {
let newVnode = h('table', {}, data.map(item => {
let tds = [];
for(let i in item) {
if(item.hasOwnProperty(i)) {
tds.push(h('td', {}, item[i] + ''));
}
}
return h('tr', {}, tds);
}));
if(vnode) {
patch(vnode, newVnode);
} else {
patch(container, newVnode);
}
vnode = newVnode;
}
render(data);
let btnChnage = document.getElementById('btn-change');
btnChnage.addEventListener('click', function() {
data[1].age = 30;
data[2].address = "深圳";
//re-render
render(data);
})
script>
body>
html>
你会发现, 只有改变的栏目才闪烁,也就是进行重绘 ,数据没有改变的栏目还是保持原样,这样就大大节省了浏览器重新渲染的开销
vue中使用h函数生成虚拟DOM返回
const vm = new Vue({
el: '#app',
data: {
user: {name:'poetry'}
},
render(h){
// h()
// h(App)
// h('div',[])
let vnode = h('div',{},'hello world');
return vnode
}
});
54.使用vue渲染大量数据时应该怎么优化?说下你的思路!
分析
企业级项目中渲染大量数据的情况比较常见,因此这是一道非常好的综合实践题目。
回答
- 在大型企业级项目中经常需要渲染大量数据,此时很容易出现卡顿的情况。比如大数据量的表格、树
- 处理时要根据情况做不同处理:
- 可以采取分页的方式获取,避免渲染大量数据
- vue-virtual-scroller (opens new window)等虚拟滚动方案,只渲染视口范围内的数据
- 如果不需要更新,可以使用v-once方式只渲染一次
- 通过v-memo (opens new window)可以缓存结果,结合
v-for使用,避免数据变化时不必要的VNode创建
- 可以采用懒加载方式,在用户需要的时候再加载数据,比如
tree组件子树的懒加载
3.还是要看具体需求,首先从设计上避免大数据获取和渲染;实在需要这样做可以采用虚表的方式优化渲染;最后优化更新,如果不需要更新可以v-once处理,需要更新可以v-memo进一步优化大数据更新性能。其他可以采用的是交互方式优化,无线滚动、懒加载等方案
55.怎么缓存当前的组件?缓存后怎么更新
缓存组件使用keep-alive组件,这是一个非常常见且有用的优化手段,vue3中keep-alive有比较大的更新,能说的点比较多
思路
- 缓存用
keep-alive,它的作用与用法
- 使用细节,例如缓存指定/排除、结合
router和transition
- 组件缓存后更新可以利用
activated或者beforeRouteEnter
- 原理阐述
回答范例
- 开发中缓存组件使用
keep-alive组件,keep-alive是vue内置组件,keep-alive包裹动态组件component时,会缓存不活动的组件实例,而不是销毁它们,这样在组件切换过程中将状态保留在内存中,防止重复渲染DOM
<keep-alive>
<component :is="view">component>
keep-alive>
- 结合属性
include和exclude可以明确指定缓存哪些组件或排除缓存指定组件。vue3中结合vue-router时变化较大,之前是keep-alive包裹router-view,现在需要反过来用router-view包裹keep-alive
<router-view v-slot="{ Component }">
<keep-alive>
<component :is="Component">component>
keep-alive>
router-view>
- 缓存后如果要获取数据,解决方案可以有以下两种
beforeRouteEnter:在有vue-router的项目,每次进入路由的时候,都会执行beforeRouteEnter
beforeRouteEnter(to, from, next){
next(vm=>{
console.log(vm)
// 每次进入路由执行
vm.getData() // 获取数据
})
},
actived:在keep-alive缓存的组件被激活的时候,都会执行actived钩子
activated(){
this.getData() // 获取数据
},
keep-alive是一个通用组件,它内部定义了一个map,缓存创建过的组件实例,它返回的渲染函数内部会查找内嵌的component组件对应组件的vnode,如果该组件在map中存在就直接返回它。由于component的is属性是个响应式数据,因此只要它变化,keep-alive的render函数就会重新执行
56.Vue.extend 作用和原理
官方解释:Vue.extend 使用基础 Vue 构造器,创建一个“子类”。参数是一个包含组件选项的对象。
其实就是一个子类构造器 是 Vue 组件的核心 api 实现思路就是使用原型继承的方法返回了 Vue 的子类 并且利用 mergeOptions 把传入组件的 options 和父类的 options 进行了合并
extend是构造一个组件的语法器。然后这个组件你可以作用到Vue.component这个全局注册方法里还可以在任意vue模板里使用组件。 也可以作用到vue实例或者某个组件中的components属性中并在内部使用apple组件。Vue.component你可以创建 ,也可以取组件。
相关代码如下
export default function initExtend(Vue) {
let cid = 0; //组件的唯一标识
// 创建子类继承Vue父类 便于属性扩展
Vue.extend = function (extendOptions) {
// 创建子类的构造函数 并且调用初始化方法
const Sub = function VueComponent(options) {
this._init(options); //调用Vue初始化方法
};
Sub.cid = cid++;
Sub.prototype = Object.create(this.prototype); // 子类原型指向父类
Sub.prototype.constructor = Sub; //constructor指向自己
Sub.options = mergeOptions(this.options, extendOptions); //合并自己的options和父类的options
return Sub;
};
}
57.Vue中的过滤器了解吗?过滤器的应用场景有哪些?
过滤器实质不改变原始数据,只是对数据进行加工处理后返回过滤后的数据再进行调用处理,我们也可以理解其为一个纯函数
Vue 允许你自定义过滤器,可被用于一些常见的文本格式化
ps: Vue3中已废弃filter
如何用
vue中的过滤器可以用在两个地方:双花括号插值和 v-bind 表达式,过滤器应该被添加在 JavaScript表达式的尾部,由“管道”符号指示:
{ message | capitalize }
<div v-bind:id="rawId | formatId">div>
定义filter
在组件的选项中定义本地的过滤器
filters: {
capitalize: function (value) {
if (!value) return ''
value = value.toString()
return value.charAt(0).toUpperCase() + value.slice(1)
}
}
定义全局过滤器:
Vue.filter('capitalize', function (value) {
if (!value) return ''
value = value.toString()
return value.charAt(0).toUpperCase() + value.slice(1)
})
new Vue({
// ...
})
注意:当全局过滤器和局部过滤器重名时,会采用局部过滤器
过滤器函数总接收表达式的值 (之前的操作链的结果) 作为第一个参数。在上述例子中,capitalize 过滤器函数将会收到 message 的值作为第一个参数
过滤器可以串联:
{ message | filterA | filterB }
在这个例子中,filterA 被定义为接收单个参数的过滤器函数,表达式 message 的值将作为参数传入到函数中。然后继续调用同样被定义为接收单个参数的过滤器函数 filterB,将 filterA 的结果传递到 filterB 中。
过滤器是 JavaScript函数,因此可以接收参数:
{{ message | filterA('arg1', arg2) }}
这里,filterA 被定义为接收三个参数的过滤器函数。
其中 message 的值作为第一个参数,普通字符串 'arg1' 作为第二个参数,表达式 arg2 的值作为第三个参数
举个例子:
<div id="app">
<p>{{ msg | msgFormat('疯狂','--')}}p>
div>
<script>
// 定义一个 Vue 全局的过滤器,名字叫做 msgFormat
Vue.filter('msgFormat', function(msg, arg, arg2) {
// 字符串的 replace 方法,第一个参数,除了可写一个 字符串之外,还可以定义一个正则
return msg.replace(/单纯/g, arg+arg2)
})
script>
小结:
- 部过滤器优先于全局过滤器被调用
- 一个表达式可以使用多个过滤器。过滤器之间需要用管道符“|”隔开。其执行顺序从左往右
应用场景
平时开发中,需要用到过滤器的地方有很多,比如单位转换、数字打点、文本格式化、时间格式化之类的等
比如我们要实现将30000 => 30,000,这时候我们就需要使用过滤器
Vue.filter('toThousandFilter', function (value) {
if (!value) return ''
value = value.toString()
return .replace(str.indexOf('.') > -1 ? /(\d)(?=(\d{3})+\.)/g : /(\d)(?=(?:\d{3})+$)/g, '$1,')
})
原理分析
使用过滤器
{{ message | capitalize }}
在模板编译阶段过滤器表达式将会被编译为过滤器函数,主要是用过parseFilters,我们放到最后讲
_s(_f('filterFormat')(message))
首先分析一下_f:
_f 函数全名是:resolveFilter,这个函数的作用是从this.$options.filters中找出注册的过滤器并返回
// 变为
this.$options.filters['filterFormat'](message) // message为参数
关于resolveFilter
import { indentity,resolveAsset } from 'core/util/index'
export function resolveFilter(id){
return resolveAsset(this.$options,'filters',id,true) || identity
}
内部直接调用resolveAsset,将option对象,类型,过滤器id,以及一个触发警告的标志作为参数传递,如果找到,则返回过滤器;
resolveAsset的代码如下:
export function resolveAsset(options,type,id,warnMissing){ // 因为我们找的是过滤器,所以在 resolveFilter函数中调用时 type 的值直接给的 'filters',实际这个函数还可以拿到其他很多东西
if(typeof id !== 'string'){ // 判断传递的过滤器id 是不是字符串,不是则直接返回
return
}
const assets = options[type] // 将我们注册的所有过滤器保存在变量中
// 接下来的逻辑便是判断id是否在assets中存在,即进行匹配
if(hasOwn(assets,id)) return assets[id] // 如找到,直接返回过滤器
// 没有找到,代码继续执行
const camelizedId = camelize(id) // 万一你是驼峰的呢
if(hasOwn(assets,camelizedId)) return assets[camelizedId]
// 没找到,继续执行
const PascalCaseId = capitalize(camelizedId) // 万一你是首字母大写的驼峰呢
if(hasOwn(assets,PascalCaseId)) return assets[PascalCaseId]
// 如果还是没找到,则检查原型链(即访问属性)
const result = assets[id] || assets[camelizedId] || assets[PascalCaseId]
// 如果依然没找到,则在非生产环境的控制台打印警告
if(process.env.NODE_ENV !== 'production' && warnMissing && !result){
warn('Failed to resolve ' + type.slice(0,-1) + ': ' + id, options)
}
// 无论是否找到,都返回查找结果
return result
}
下面再来分析一下_s:
_s 函数的全称是 toString,过滤器处理后的结果会当作参数传递给 toString函数,最终 toString函数执行后的结果会保存到Vnode中的text属性中,渲染到视图中
function toString(value){
return value == null
? ''
: typeof value === 'object'
? JSON.stringify(value,null,2)// JSON.stringify()第三个参数可用来控制字符串里面的间距
: String(value)
}
最后,在分析下parseFilters,在模板编译阶段使用该函数阶段将模板过滤器解析为过滤器函数调用表达式
function parseFilters (filter) {
let filters = filter.split('|')
let expression = filters.shift().trim() // shift()删除数组第一个元素并将其返回,该方法会更改原数组
let i
if (filters) {
for(i = 0;i < filters.length;i++){
experssion = warpFilter(expression,filters[i].trim()) // 这里传进去的expression实际上是管道符号前面的字符串,即过滤器的第一个参数
}
}
return expression
}
// warpFilter函数实现
function warpFilter(exp,filter){
// 首先判断过滤器是否有其他参数
const i = filter.indexof('(')
if(i<0){ // 不含其他参数,直接进行过滤器表达式字符串的拼接
return `_f("${filter}")(${exp})`
}else{
const name = filter.slice(0,i) // 过滤器名称
const args = filter.slice(i+1) // 参数,但还多了 ‘)’
return `_f('${name}')(${exp},${args}` // 注意这一步少给了一个 ')'
}
}
小结:
- 在编译阶段通过
parseFilters将过滤器编译成函数调用(串联过滤器则是一个嵌套的函数调用,前一个过滤器执行的结果是后一个过滤器函数的参数)
- 编译后通过调用
resolveFilter函数找到对应过滤器并返回结果
- 执行结果作为参数传递给
toString函数,而toString执行后,其结果会保存在Vnode的text属性中,渲染到视图
58.组件通信
组件通信的方式如下:
(1) props / $emit
父组件通过props向子组件传递数据,子组件通过$emit和父组件通信
1. 父组件向子组件传值
props只能是父组件向子组件进行传值,props使得父子组件之间形成了一个单向下行绑定。子组件的数据会随着父组件不断更新。props 可以显示定义一个或一个以上的数据,对于接收的数据,可以是各种数据类型,同样也可以传递一个函数。props属性名规则:若在props中使用驼峰形式,模板中需要使用短横线的形式
// 父组件
<template>
<div id="father">
<son :msg="msgData" :fn="myFunction"></son>
</div>
</template>
<script>
import son from "./son.vue";
export default {
name: father,
data() {
msgData: "父组件数据";
},
methods: {
myFunction() {
console.log("vue");
},
},
components: { son },
};
</script>
// 子组件
<template>
<div id="son">
<p>{{ msg }}</p>
<button @click="fn">按钮</button>
</div>
</template>
<script>
export default { name: "son", props: ["msg", "fn"] };
</script>
2. 子组件向父组件传值
$emit绑定一个自定义事件,当这个事件被执行的时就会将参数传递给父组件,而父组件通过v-on监听并接收参数。
// 父组件
<template>
<div class="section">
<com-article
:articles="articleList"
@onEmitIndex="onEmitIndex"
></com-article>
<p>{{ currentIndex }}</p>
</div>
</template>
<script>
import comArticle from "./test/article.vue";
export default {
name: "comArticle",
components: { comArticle },
data() {
return { currentIndex: -1, articleList: ["红楼梦", "西游记", "三国演义"] };
},
methods: {
onEmitIndex(idx) {
this.currentIndex = idx;
},
},
};
</script>
//子组件
<template>
<div>
<div
v-for="(item, index) in articles"
:key="index"
@click="emitIndex(index)"
>
{{ item }}
</div>
</div>
</template>
<script>
export default {
props: ["articles"],
methods: {
emitIndex(index) {
this.$emit("onEmitIndex", index); // 触发父组件的方法,并传递参数index
},
},
};
</script>
(2)eventBus事件总线($emit / $on)
eventBus事件总线适用于父子组件、非父子组件等之间的通信,使用步骤如下: (1)创建事件中心管理组件之间的通信
// event-bus.js
import Vue from 'vue'
export const EventBus = new Vue()
(2)发送事件 假设有两个兄弟组件firstCom和secondCom:
<template>
<div>
<first-com></first-com>
<second-com></second-com>
</div>
</template>
<script>
import firstCom from "./firstCom.vue";
import secondCom from "./secondCom.vue";
export default { components: { firstCom, secondCom } };
</script>
在firstCom组件中发送事件:
<template>
<div>
<button @click="add">加法</button>
</div>
</template>
<script>
import { EventBus } from "./event-bus.js"; // 引入事件中心
export default {
data() {
return { num: 0 };
},
methods: {
add() {
EventBus.$emit("addition", { num: this.num++ });
},
},
};
</script>
(3)接收事件 在secondCom组件中发送事件:
<template>
<div>求和: {{ count }}</div>
</template>
<script>
import { EventBus } from "./event-bus.js";
export default {
data() {
return { count: 0 };
},
mounted() {
EventBus.$on("addition", (param) => {
this.count = this.count + param.num;
});
},
};
</script>
在上述代码中,这就相当于将num值存贮在了事件总线中,在其他组件中可以直接访问。事件总线就相当于一个桥梁,不用组件通过它来通信。
虽然看起来比较简单,但是这种方法也有不变之处,如果项目过大,使用这种方式进行通信,后期维护起来会很困难。
(3)依赖注入(provide / inject)
这种方式就是Vue中的依赖注入,该方法用于父子组件之间的通信。当然这里所说的父子不一定是真正的父子,也可以是祖孙组件,在层数很深的情况下,可以使用这种方法来进行传值。就不用一层一层的传递了。
provide / inject是Vue提供的两个钩子,和data、methods是同级的。并且provide的书写形式和data一样。
provide 钩子用来发送数据或方法inject钩子用来接收数据或方法
在父组件中:
provide() {
return {
num: this.num
};
}
在子组件中:
inject: ['num']
还可以这样写,这样写就可以访问父组件中的所有属性:
provide() {
return {
app: this
};
}
data() {
return {
num: 1
};
}
inject: ['app']
console.log(this.app.num)
注意: 依赖注入所提供的属性是非响应式的。
(3)ref / $refs
这种方式也是实现父子组件之间的通信。
ref: 这个属性用在子组件上,它的引用就指向了子组件的实例。可以通过实例来访问组件的数据和方法。
在子组件中:
export default {
data () {
return {
name: 'JavaScript'
}
},
methods: {
sayHello () {
console.log('hello')
}
}
}
在父组件中:
<template>
<child ref="child"></component-a>
</template>
<script>
import child from "./child.vue";
export default {
components: { child },
mounted() {
console.log(this.$refs.child.name); // JavaScript
this.$refs.child.sayHello(); // hello
},
};
</script>
(4)$parent / $children
- 使用
$parent可以让组件访问父组件的实例(访问的是上一级父组件的属性和方法)
- 使用
$children可以让组件访问子组件的实例,但是,$children并不能保证顺序,并且访问的数据也不是响应式的。
在子组件中:
<template>
<div>
<span>{{ message }}</span>
<p>获取父组件的值为: {{ parentVal }}</p>
</div>
</template>
<script>
export default {
data() {
return { message: "Vue" };
},
computed: {
parentVal() {
return this.$parent.msg;
},
},
};
</script>
在父组件中:
// 父组件中
<template>
<div class="hello_world">
<div>{{ msg }}</div>
<child></child>
<button @click="change">点击改变子组件值</button>
</div>
</template>
<script>
import child from "./child.vue";
export default {
components: { child },
data() {
return { msg: "Welcome" };
},
methods: {
change() {
// 获取到子组件
this.$children[0].message = "JavaScript";
},
},
};
</script>
在上面的代码中,子组件获取到了父组件的parentVal值,父组件改变了子组件中message的值。 需要注意:
- 通过
$parent访问到的是上一级父组件的实例,可以使用$root来访问根组件的实例
- 在组件中使用
$children拿到的是所有的子组件的实例,它是一个数组,并且是无序的
- 在根组件
#app上拿$parent得到的是new Vue()的实例,在这实例上再拿$parent得到的是undefined,而在最底层的子组件拿$children是个空数组
$children 的值是数组,而$parent是个对象
(5)$attrs / $listeners
考虑一种场景,如果A是B组件的父组件,B是C组件的父组件。如果想要组件A给组件C传递数据,这种隔代的数据,该使用哪种方式呢?
如果是用props/$emit来一级一级的传递,确实可以完成,但是比较复杂;如果使用事件总线,在多人开发或者项目较大的时候,维护起来很麻烦;如果使用Vuex,的确也可以,但是如果仅仅是传递数据,那可能就有点浪费了。
针对上述情况,Vue引入了$attrs / $listeners,实现组件之间的跨代通信。
先来看一下inheritAttrs,它的默认值true,继承所有的父组件属性除props之外的所有属性;inheritAttrs:false 只继承class属性 。
$attrs:继承所有的父组件属性(除了prop传递的属性、class 和 style ),一般用在子组件的子元素上$listeners:该属性是一个对象,里面包含了作用在这个组件上的所有监听器,可以配合 v-on="$listeners" 将所有的事件监听器指向这个组件的某个特定的子元素。(相当于子组件继承父组件的事件)
A组件(APP.vue):
<template>
<div id="app">
//此处监听了两个事件,可以在B组件或者C组件中直接触发
<child1
:p-child1="child1"
:p-child2="child2"
@test1="onTest1"
@test2="onTest2"
></child1>
</div>
</template>
<script>
import Child1 from "./Child1.vue";
export default {
components: { Child1 },
methods: {
onTest1() {
console.log("test1 running");
},
onTest2() {
console.log("test2 running");
},
},
};
</script>
B组件(Child1.vue):
<template>
<div class="child-1">
<p>props: {{ pChild1 }}</p>
<p>$attrs: {{ $attrs }}</p>
<child2 v-bind="$attrs" v-on="$listeners"></child2>
</div>
</template>
<script>
import Child2 from "./Child2.vue";
export default {
props: ["pChild1"],
components: { Child2 },
inheritAttrs: false,
mounted() {
this.$emit("test1"); // 触发APP.vue中的test1方法
},
};
</script>
C 组件 (Child2.vue):
<template>
<div class="child-2">
<p>props: {{ pChild2 }}</p>
<p>$attrs: {{ $attrs }}</p>
</div>
</template>
<script>
export default {
props: ["pChild2"],
inheritAttrs: false,
mounted() {
this.$emit("test2"); // 触发APP.vue中的test2方法
},
};
</script>
在上述代码中:
- C组件中能直接触发test的原因在于 B组件调用C组件时 使用 v-on 绑定了
$listeners 属性
- 在B组件中通过v-bind 绑定
$attrs属性,C组件可以直接获取到A组件中传递下来的props(除了B组件中props声明的)
(6)总结
(1)父子组件间通信
- 子组件通过 props 属性来接受父组件的数据,然后父组件在子组件上注册监听事件,子组件通过 emit 触发事件来向父组件发送数据。
- 通过 ref 属性给子组件设置一个名字。父组件通过
$refs 组件名来获得子组件,子组件通过 $parent 获得父组件,这样也可以实现通信。
- 使用 provide/inject,在父组件中通过 provide提供变量,在子组件中通过 inject 来将变量注入到组件中。不论子组件有多深,只要调用了 inject 那么就可以注入 provide中的数据。
(2)兄弟组件间通信
- 使用 eventBus 的方法,它的本质是通过创建一个空的 Vue 实例来作为消息传递的对象,通信的组件引入这个实例,通信的组件通过在这个实例上监听和触发事件,来实现消息的传递。
- 通过
$parent/$refs 来获取到兄弟组件,也可以进行通信。
(3)任意组件之间
- 使用 eventBus ,其实就是创建一个事件中心,相当于中转站,可以用它来传递事件和接收事件。
如果业务逻辑复杂,很多组件之间需要同时处理一些公共的数据,这个时候采用上面这一些方法可能不利于项目的维护。这个时候可以使用 vuex ,vuex 的思想就是将这一些公共的数据抽离出来,将它作为一个全局的变量来管理,然后其他组件就可以对这个公共数据进行读写操作,这样达到了解耦的目的。
58.什么是 mixin ?
- Mixin 使我们能够为 Vue 组件编写可插拔和可重用的功能。
- 如果希望在多个组件之间重用一组组件选项,例如生命周期 hook、 方法等,则可以将其编写为 mixin,并在组件中简单的引用它。
- 然后将 mixin 的内容合并到组件中。如果你要在 mixin 中定义生命周期 hook,那么它在执行时将优化于组件自已的 hook。
59.Vue.mixin的使用场景和原理
- 在日常的开发中,我们经常会遇到在不同的组件中经常会需要用到一些相同或者相似的代码,这些代码的功能相对独立,可以通过
Vue 的 mixin 功能抽离公共的业务逻辑,原理类似“对象的继承”,当组件初始化时会调用 mergeOptions 方法进行合并,采用策略模式针对不同的属性进行合并。当组件和混入对象含有同名选项时,这些选项将以恰当的方式进行“合并”;如果混入的数据和本身组件的数据冲突,会以组件的数据为准
mixin有很多缺陷如:命名冲突、依赖问题、数据来源问题
基本使用
<script>
// Vue.options
Vue.mixin({ // 如果他是对象 每个组件都用mixin里的对象进行合并
data(){
return {a: 1,b: 2}
}
});
// Vue.extend
Vue.component('my',{ // 组件必须是函数 Vue.extend => render(xxx)
data(){
return {x:1}
}
})
// 没有 new 没有实例 _init()
// const vm = this
new Vue({
el:'#app',
data(){ // 根可以不是函数
return {c:3}
}
})
script>
相关源码
export default function initMixin(Vue){
Vue.mixin = function (mixin) {
// 合并对象
this.options=mergeOptions(this.options,mixin)
};
}
};
// src/util/index.js
// 定义生命周期
export const LIFECYCLE_HOOKS = [
"beforeCreate",
"created",
"beforeMount",
"mounted",
"beforeUpdate",
"updated",
"beforeDestroy",
"destroyed",
];
// 合并策略
const strats = {};
// mixin核心方法
// mixin核心方法
export function mergeOptions(parent, child) {
const options = {};
// 遍历父亲
for (let k in parent) {
mergeFiled(k);
}
// 父亲没有 儿子有
for (let k in child) {
if (!parent.hasOwnProperty(k)) {
mergeFiled(k);
}
}
//真正合并字段方法
function mergeFiled(k) {
// strats合并策略
if (strats[k]) {
options[k] = strats[k](parent[k], child[k]);
} else {
// 默认策略
options[k] = child[k] ? child[k] : parent[k];
}
}
return options;
}
60.关于Vue中el,template,render,$mount的渲染
- 渲染根节点:
- 先判断有无el属性,有的话直接获取el根节点,没有的话调用$mount去获取根节点。
- 渲染模板:
- 有render:这时候优先执行render函数,render优先级 > template。
- 无render:有template时拿template去解析成render函数的所需的格式,并使用调用render函数渲染。无template时拿el根节点的outerHTML去解析成render函数的所需的格式,并使用调用render函数渲染
渲染的方式:无论什么情况,最后都统一是要使用render函数渲染
失败
61.怎么实现路由懒加载呢
这是一道应用题。当打包应用时,JavaScript 包会变得非常大,影响页面加载。如果我们能把不同路由对应的组件分割成不同的代码块,然后当路由被访问时才加载对应组件,这样就会更加高效
// 将
// import UserDetails from './views/UserDetails'
// 替换为
const UserDetails = () => import('./views/UserDetails')
const router = createRouter({
// ...
routes: [{ path: '/users/:id', component: UserDetails }],
})
回答范例
- 当打包构建应用时,JavaScript 包会变得非常大,影响页面加载。利用路由懒加载我们能把不同路由对应的组件分割成不同的代码块,然后当路由被访问的时候才加载对应组件,这样会更加高效,是一种优化手段
- 一般来说,对所有的路由都使用动态导入是个好主意
- 给
component选项配置一个返回 Promise 组件的函数就可以定义懒加载路由。例如:{ path: '/users/:id', component: () => import('./views/UserDetails') }
- 结合注释
() => import(/* webpackChunkName: "group-user" */ './UserDetails.vue') 可以做webpack代码分块
62.Vue-router 除了 router-link 怎么实现跳转
声明式导航
<router-link to="/about">Go to About</router-link>
编程式导航
// literal string path
router.push('/users/1')
// object with path
router.push({ path: '/users/1' })
// named route with params to let the router build the url
router.push({ name: 'user', params: { username: 'test' } })
回答范例
vue-router导航有两种方式:声明式导航和编程方式导航- 声明式导航方式使用
router-link组件,添加to属性导航;编程方式导航更加灵活,可传递调用router.push(),并传递path字符串或者RouteLocationRaw对象,指定path、name、params等信息
- 如果页面中简单表示跳转链接,使用
router-link最快捷,会渲染一个a标签;如果页面是个复杂的内容,比如商品信息,可以添加点击事件,使用编程式导航
- 实际上内部两者调用的导航函数是一样的
63.Vue中组件和插件有什么区别
1. 组件是什么
组件就是把图形、非图形的各种逻辑均抽象为一个统一的概念(组件)来实现开发的模式,在Vue中每一个.vue文件都可以视为一个组件
组件的优势
- 降低整个系统的耦合度,在保持接口不变的情况下,我们可以替换不同的组件快速完成需求,例如输入框,可以替换为日历、时间、范围等组件作具体的实现
- 调试方便,由于整个系统是通过组件组合起来的,在出现问题的时候,可以用排除法直接移除组件,或者根据报错的组件快速定位问题,之所以能够快速定位,是因为每个组件之间低耦合,职责单一,所以逻辑会比分析整个系统要简单
- 提高可维护性,由于每个组件的职责单一,并且组件在系统中是被复用的,所以对代码进行优化可获得系统的整体升级
2. 插件是什么
插件通常用来为 Vue 添加全局功能。插件的功能范围没有严格的限制——一般有下面几种:
- 添加全局方法或者属性。如:
vue-custom-element
- 添加全局资源:指令/过滤器/过渡等。如
vue-touch
- 通过全局混入来添加一些组件选项。如
vue-router
- 添加
Vue 实例方法,通过把它们添加到 Vue.prototype 上实现。
- 一个库,提供自己的
API,同时提供上面提到的一个或多个功能。如vue-router
3. 两者的区别
两者的区别主要表现在以下几个方面:
- 编写形式
- 注册形式
- 使用场景
3.1 编写形式
编写组件
编写一个组件,可以有很多方式,我们最常见的就是vue单文件的这种格式,每一个.vue文件我们都可以看成是一个组件
vue文件标准格式
<template>
template>
<script>
export default{
...
}
script>
<style>
style>
我们还可以通过template属性来编写一个组件,如果组件内容多,我们可以在外部定义template组件内容,如果组件内容并不多,我们可直接写在template属性上
<template id="testComponent"> // 组件显示的内容
<div>component!div>
template>
Vue.component('componentA',{
template: '#testComponent'
template: `<div>componentdiv>` // 组件内容少可以通过这种形式
})
编写插件
vue插件的实现应该暴露一个 install 方法。这个方法的第一个参数是 Vue 构造器,第二个参数是一个可选的选项对象
MyPlugin.install = function (Vue, options) {
// 1. 添加全局方法或 property
Vue.myGlobalMethod = function () {
// 逻辑...
}
// 2. 添加全局资源
Vue.directive('my-directive', {
bind (el, binding, vnode, oldVnode) {
// 逻辑...
}
...
})
// 3. 注入组件选项
Vue.mixin({
created: function () {
// 逻辑...
}
...
})
// 4. 添加实例方法
Vue.prototype.$myMethod = function (methodOptions) {
// 逻辑...
}
}
3.2 注册形式
组件注册
vue组件注册主要分为全局注册与局部注册
全局注册通过Vue.component方法,第一个参数为组件的名称,第二个参数为传入的配置项
Vue.component('my-component-name', { /* ... */ })
局部注册只需在用到的地方通过components属性注册一个组件
const component1 = {...} // 定义一个组件
export default {
components:{
component1 // 局部注册
}
}
插件注册
插件的注册通过Vue.use()的方式进行注册(安装),第一个参数为插件的名字,第二个参数是可选择的配置项
Vue.use(插件名字,{ /* ... */} )
注意的是:
注册插件的时候,需要在调用 new Vue() 启动应用之前完成
Vue.use会自动阻止多次注册相同插件,只会注册一次
4. 使用场景
- 组件 (Component) 是用来构成你的 App 的业务模块,它的目标是
App.vue
- 插件 (Plugin) 是用来增强你的技术栈的功能模块,它的目标是 Vue 本身
简单来说,插件就是指对Vue的功能的增强或补充
64.怎么监听vuex数据的变化
分析
vuex数据状态是响应式的,所以状态变视图跟着变,但是有时还是需要知道数据状态变了从而做一些事情。- 既然状态都是响应式的,那自然可以
watch,另外vuex也提供了订阅的API:store.subscribe()
回答范例
- 我知道几种方法:
- 可以通过
watch选项或者watch方法监听状态
- 可以使用
vuex提供的API:store.subscribe()
watch选项方式,可以以字符串形式监听$store.state.xx;subscribe方式,可以调用store.subscribe(cb),回调函数接收mutation对象和state对象,这样可以进一步判断mutation.type是否是期待的那个,从而进一步做后续处理。watch方式简单好用,且能获取变化前后值,首选;subscribe方法会被所有commit行为触发,因此还需要判断mutation.type,用起来略繁琐,一般用于vuex插件中
实践
watch方式
const app = createApp({
watch: {
'$store.state.counter'() {
console.log('counter change!');
}
}
})
subscribe方式:
store.subscribe((mutation, state) => {
if (mutation.type === 'add') {
console.log('counter change in subscribe()!');
}
})
react
1.如何创建一个react的项目(使用脚手架)
- 安装cr脚手架:npm install -g create-react-app
- 进入文件夹:create-react-app 项目名称
- 进入项目:cd 项目名称
- 运行项目:npm start
2.如何不使用脚手架创建一个项目
- yarn init 初始化package.json文件
- 安装react和react-dom
- 配置webpack
- 配置babel支持ES6
- 配置@babel/preset-react支持react
- 支持ts:ts-loader @types/react @types/react-dom
- 支持antd
- 支持less:less-loader,css-loader,style-loader
- 配置plugins,常用的有html-webpack-plugin(当使用 webpack 打包时,创建一个 html 文件,并把 webpack 打包后的静态文件自动插入到这个 html 文件当中。)和 clean-webpack-plugin(是一个清除文件的插件。 在每次打包后,磁盘空间会存有打包后的资源,在再次打包的时候,我们需要先把本地已有的打包后的资源清空,来减少它们对磁盘空间的占用。 插件clean-webpack-plugin就可以帮我们做这个事情)
- 安装router
- 安装redux
3.对于React 框架的理解(React的特性有哪些)
React是一个用于构建用户界面的 JavaScript 库,只提供了 UI 层面的解决方案。
它有以下特性:
-
组件化:将界面成了各个独立的小块,每一个块就是组件,这些组件之间可以组合、嵌套,构成整体页面,提高代码的复用率和开发效率。
-
数据驱动视图:
React通过setState实现数据驱动视图,通过setState来引发一次组件的更新过程从而实现页面的重新渲染。- 数据驱动视图是我们只需要关注数据的变化,不用再去操作dom。同时也提升了性能。
-
JSX 语法:用于声明组件结构,是一个 JavaScript 的语法扩展。
-
单向数据绑定:从高阶组件到低阶组件的单向数据流,单向响应的数据流会比双向绑定的更安全,速度更快
-
虚拟 DOM:使用虚拟 DOM 来有效地操作 DOM
-
声明式编程:
如实现一个标记的地图: 通过命令式创建地图、创建标记、以及在地图上添加的标记的步骤如下:
// 创建地图
const map = new Map.map(document.getElementById("map"), {
zoom: 4,
center: { lat, lng },
});
// 创建标记
const marker = new Map.marker({
position: { lat, lng },
title: "Hello Marker",
});
// 地图上添加标记
marker.setMap(map);
而用 React 实现上述功能则如下:
<Map zoom={4} center={(lat, lng)}>
<Marker position={(lat, lng)} title={"Hello Marker"} />
</Map>
声明式编程方式使得 React 组件很容易使用,最终的代码简单易于维护
4.对于React虚拟DOM的理解
- js对象,保存在内存中
- 是对真实DOM结构的映射
虚拟 DOM 的工作流程:
挂载阶段:React 将结合 JSX 的描述,构建出虚拟 DOM 树,然后通过 ReactDOM.render 实现虚拟 DOM 到真实 DOM 的映射(触发渲染流水线);
更新阶段:页面的变化先作用于虚拟 DOM,虚拟 DOM 将在 JS 层借助算法先对比出具体有哪些真实 DOM 需要被改变,然后再将这些改变作用于真实 DOM。
虚拟 DOM 解决的关键问题有以下三个:
- 减少 DOM 操作:虚拟 DOM 可以将多次 DOM 操作合并为一次操作
- 研发体验/研发效率的问题:虚拟 DOM 的出现,为数据驱动视图这一思想提供了高度可用的载体,使得前端开发能够基于函数式 UI 的编程方式实现高效的声明式编程。
- 跨平台的问题:虚拟 DOM 是对真实渲染内容的一层抽象。同一套虚拟 DOM,可以对接不同平台的渲染逻辑,从而实现“一次编码,多端运行”
既然是虚拟 DOM,那就意味着它和渲染到页面上的真实 DOM 之间还有一定的距离,这个距离通过 ReactDOM.render 方法填充:
ReactDOM.render(
// 需要渲染的元素(ReactElement)
element,
// 元素挂载的目标容器(一个真实DOM)
container,
// 回调函数,可选参数,可以用来处理渲染结束后的逻辑
[callback]
)
5.VDOM 和 DOM 的区别
- 真实DOM存在重排和重绘,虚拟DOM不存在;
- 虚拟 DOM 的总损耗是“虚拟 DOM 增删改+真实 DOM 差异增删改+排版与重绘(可能比直接操作真实DOM要少)”,真实 DOM 的总损耗是“真实 DOM 完全增删改+排版与重绘”
传统的原生 api 或 jQuery 去操作 DOM 时,浏览器会从构建 DOM 树开始从头到尾执行一遍流程。
当你在一次操作时,需要更新 10 个 DOM 节点,浏览器没这么智能,收到第一个更新 DOM 请求后,并不知道后续还有 9 次更新操作,因此会马上执行流程,最终执行 10 次流程。
而通过 VNode,同样更新 10 个 DOM 节点,虚拟 DOM 不会立即操作 DOM,而是将这 10 次更新的 diff 内容保存到本地的一个 js 对象中,最终将这个 js 对象一次性 attach 到 DOM 树上,避免大量的无谓计算。
6.VDOM 和 DOM 优缺点
真实 DOM 的优势:
- 易用
真实 DOM 的缺点:
- 效率低,解析速度慢,内存占用量过高
- 性能差:频繁操作真实 DOM,易于导致重绘与回流
虚拟 DOM 的优势:
- 简单方便:如果使用手动操作真实 DOM 来完成页面,繁琐又容易出错,在大规模应用下维护起来也很困难
- 性能方面:使用 Virtual DOM,能够有效避免真实 DOM 数频繁更新,减少多次引起重绘与回流,提高性能
- 跨平台:React 借助虚拟 DOM,带来了跨平台的能力,一套代码多端运行
虚拟 DOM 的缺点:
- 在一些性能要求极高的应用中虚拟 DOM 无法进行针对性的极致优化,首次渲染大量 DOM 时,由于多了一层虚拟 DOM 的计算,速度比正常稍慢
7.react 的生命周期
react生命周期图解
初始化阶段:
- getDefaultProps:获取实例的默认属性
- getInitialState:获取每个实例的初始化状态
- componentWillMount:组件即将被装载、渲染到页面上
- render:组件在这里生成虚拟的 DOM 节点
- componentDidMount:组件真正在被装载之后
运行中状态:
- componentWillReceiveProps:组件将要接收到属性的时候调用
- shouldComponentUpdate:组件接受到新属性或者新状态的时候(可以返回 false,接收数据后不更新,阻止 render 调用,后面的函数不会被继续执行了)
- componentWillUpdate:组件即将更新不能修改属性和状态
- render:组件重新描绘
- componentDidUpdate:组件已经更新
销毁阶段:
- componentWillUnmount:组件即将销毁
挂载
当组件实例被创建并插入 DOM 中时,其生命周期调用顺序如下:
- constructor()
- static getDerivedStateFromProps()
- render()
- componentDidMount()
getDerivedStateFromProps
该方法是新增的生命周期方法,是一个静态的方法,因此不能访问到组件的实例。
执行时机:组件创建和更新阶段,不论是props变化还是state变化,都会调用。
在每次render方法前调用,第一个参数为即将更新的props,第二个参数为上一个状态的state,可以比较props 和 state来加一些限制条件,防止无用的state更新
该方法需要返回一个新的对象作为新的state或者返回null表示state状态不需要更新
更新
当组件的 props 或 state 发生变化时会触发更新。组件更新的生命周期调用顺序如下:
- static getDerivedStateFromProps()
- shouldComponentUpdate()
- render()
- getSnapshotBeforeUpdate()
- componentDidUpdate()
getSnapshotBeforeUpdate
该周期函数在render后执行,执行之时DOM元素还没有被更新
该方法返回的一个Snapshot值(不返回报错),作为componentDidUpdate第三个参数传入
getSnapshotBeforeUpdate(prevProps, prevState) {
console.log('#enter getSnapshotBeforeUpdate');
return 'foo';
}
componentDidUpdate(prevProps, prevState, snapshot) {
console.log('#enter componentDidUpdate snapshot = ', snapshot);
}
此方法的目的在于获取组件更新前的一些信息,比如组件的滚动位置之类的,在组件更新后可以根据这些信息恢复一些UI视觉上的状态
卸载
当组件从 DOM 中移除时会调用如下方法:
- componentWillUnmount()
错误处理
当渲染过程,生命周期,或子组件的构造函数中抛出错误时,会调用如下方法:
- static getDerivedStateFromError():更改状态,从而显示降级组件
- componentDidCatch():打印错误信息
8.state和props有什么区别
一个组件的数据可以来源于组件内部,也可以来源于组件外部(比如父组件)。
组件内部的状态就是state,一般在constructor中定义。通过setState修改,会调用render方法重新渲染组件。 setState 还可以接受第二个参数,它是一个函数,会在 setState 调用完成并且组件开始重新渲染时被调用,可以用来监听渲染是否完成。
组件外部定义的状态是props,组件中的props不可以修改,只能通过传入新的props。
相同点:
- 两者都是 JavaScript 对象
- 两者都是用于保存状态
- props 和 state 都能触发渲染更新
区别:
- props 是外部传递给组件的,而 state 是在组件内被组件自己管理的,一般在 constructor 中初始化
- props 在组件内部是不可修改的,但 state 在组件内部可以进行修改 state 是多变的、可以修改
9.super和super(props)的区别
在ES6的class中:
class sup {
constructor(name) {
this.name = name;
}
printName() {
console.log(this.name);
}
}
class sub extends sup {
constructor(name, age) {
super(name); // super代表的是父类的构造函数
this.age = age;
}
printAge() {
console.log(this.age);
}
}
let jack = new sub("jack", 20);
jack.printName(); //输出 : jack
jack.printAge(); //输出 : 20
在上面的例子中,可以看到通过 super 关键字实现调用父类,super 代替的是父类的构建函数,使用 super(name) 相当于调用sup.prototype.constructor.call(this,name)
如果在子类中不使用 super关键字,则会引发报错,报错的原因是子类是没有自己的 this 对象的,它只能继承父类的 this 对象,然后对其进行加工。
而 super() 就是将父类中的 this 对象继承给子类的,没有 super() 子类就得不到 this 对象。
如果先调用 this,再初始化 super(),同样是禁止的行为。所以在子类 constructor 中,必须先代用 super 才能引用 this。
在 React 中,类组件是基于 ES6 的规范实现的,继承 React.Component,因此如果用到 constructor 就必须写 super() 才初始化 this。
这时候,在调用 super() 的时候,我们一般都需要传入 props 作为参数,如果不传进去,React 内部也会将其定义在组件实例中。 所以无论有没有 constructor,在 render 中 this.props 都是可以使用的,这是 React 自动附带的,是可以不写的。
综上所述:
- 在 React 中,类组件基于 ES6,所以在 constructor 中必须使用 super
- 在调用 super 过程,无论是否传入 props,React 内部都会将 porps 赋值给组件实例 porps 属性中
- 如果只调用了 super(),那么 this.props 在 super() 和构造函数结束之间仍是 undefined
10.react引入css的方式有哪些
组件式开发选择合适的css解决方案尤为重要
通常会遵循以下规则:
- 可以编写局部css,不会随意污染其他组件内的原生;
- 可以编写动态的css,可以获取当前组件的一些状态,根据状态的变化生成不同的css样式;
- 支持所有的css特性:伪类、动画、媒体查询等;
- 编写起来简洁方便、最好符合一贯的css风格特点
在这一方面,vue使用css起来更为简洁:
- 通过 style 标签编写样式
- scoped 属性决定编写的样式是否局部有效
- lang 属性设置预处理器
- 内联样式风格的方式来根据最新状态设置和改变css
而在react中,引入CSS就不如Vue方便简洁,其引入css的方式有很多种,各有利弊
常见的CSS引入方式有以下:
-
行内样式:
{{
width:'200px',
height:'80px',
}}>测试数据
-
组件中引入 .css 文件
-
组件中引入 .module.css 文件
-
CSS in JS
通过上面四种样式的引入,各自的优缺点:
- 在组件内直接使用css该方式编写方便,容易能够根据状态修改样式属性,但是大量的演示编写容易导致代码混乱
- 组件中引入 .css 文件符合我们日常的编写习惯,但是作用域是全局的,样式之间会层叠
- 引入.module.css 文件能够解决局部作用域问题,但是不方便动态修改样式,需要使用内联的方式进行样式的编写
- 通过css in js 这种方法,可以满足大部分场景的应用,可以类似于预处理器一样样式嵌套、定义、修改状态等
11.react事件绑定方式有哪些
绑定方式
- render方法中使用bind
test。- 这种方式在组件每次render渲染的时候,都会重新进行bind的操作,影响性能
- render方法中使用箭头函数
this.handleClick(e)}>test- 每一次render的时候都会生成新的方法,影响性能
- constructor中bind:
this.handleClick = this.handleClick.bind(this);
- 定义阶段使用箭头函数绑定
区别
- 编写方面:方式一、方式二、方式四写法简单,方式三的编写过于冗杂
- 性能方面:方式一和方式二在每次组件render的时候都会生成新的方法实例,性能问题欠缺。若该函数作为属性值传给子组件的时候,都会导致额外的渲染。而方式三、方式四只会生成一个方法实例
综合上述,方式四是最优的事件绑定方式。
12.react组件的创建方式以及区别
创建方式
- 函数组件:通过一个函数,return 一个jsx语法声明的结构
- React.createClass 方法创建:语法冗余,目前已经不太使用
- 继承 React.Component 创建的类组件:最终会被编译成createClass
区别
由于React.createClass创建的方式过于冗杂,并不建议使用。
而像函数式创建和类组件创建的区别主要在于需要创建的组件是否需要为有状态组件:对于一些无状态的组件创建,建议使用函数式创建的方式。
在考虑组件的选择原则上,能用无状态组件则用无状态组件。
不过,由于react hooks的出现,函数式组件创建的组件通过使用hooks方法也能使之成为有状态组件,再加上目前推崇函数式编程,所以这里建议都使用函数式的方式来创建组件。
13.react 中组件之间如何通信
组件传递的方式有很多种,根据传送者和接收者可以分为如下:
- 父组件向子组件传递:props
- 子组件向父组件传递:父组件向子组件传一个函数,然后通过这个函数的回调,拿到子组件传过来的值
- 兄弟组件之间的通信:状态提升,在公共的父组件中进行状态定义
- 父组件向后代组件传递:React.createContext创建一个context进行组件传递
- 非关系组件传递:redux
14.React中key的作用
官网中对于diff有如下规则:
- 对比不同类型的元素:当元素类型变化时,会销毁重建
- 对比同一类型的元素:当元素类型不变时,比对及更新有改变的属性并且“在处理完当前节点之后,React 继续对子节点进行递归。”
- 对子节点进行递归:React 使用 key 来匹配原有树上的子元素以及最新树上的子元素。若key一致,则进行更新,若key不一致,就销毁重建
15.react函数组件和类组件的区别
针对两种React组件,其区别主要分成以下几大方向:
- 编写形式:类组件的编写形式更加的冗余
- 状态管理:在hooks之前函数组件没有状态,在hooks提出之后,函数组件也可以维护自身的状态
- 生命周期:函数组件没有生命周期,这是因为生命周期钩子都来自于继承的React.Component,但是可以通过useEffect实现类似生命周期的效果
- 调用方式:函数组件通过执行函数调用,类组件通过实例化然后调用实例的render方法
- 获取渲染的值:函数组件存在闭包陷阱,类组件不存在(Props在 React中是不可变的所以它永远不会改变,但是 this 总是可变的,以便您可以在 render 和生命周期函数中读取新版本)
16.ReactRouter 组件的理解,常用的react router组件
react-router等前端路由的原理大致相同,可以实现无刷新的条件下切换显示不同的页面。
路由的本质就是页面的URL发生改变时,页面的显示结果可以根据URL的变化而变化,但是页面不会刷新。
因此,可以通过前端路由可以实现单页(SPA)应用
react-router主要分成了几个不同的包:
- react-router: 实现了路由的核心功能
- react-router-dom: 基于 react-router,加入了在浏览器运行环境下的一些功能
- react-router-native:基于 react-router,加入了 react-native 运行环境下的一些功能
- react-router-config: 用于配置静态路由的工具库
常用组件
react-router-dom的常用的一些组件:
- BrowserRouter、HashRouter:使用两者作为最顶层组件包裹其他组件,分别匹配history模式和hash模式
- Route:Route用于路径的匹配,然后进行组件的渲染,对应的属性如下:
- path 属性:用于设置匹配到的路径
- component 属性:设置匹配到路径后,渲染的组件
- render 属性:设置匹配到路径后,渲染的内容
- exact 属性:开启精准匹配,只有精准匹配到完全一致的路径,才会渲染对应的组件
- Link、NavLink:通常路径的跳转是使用Link组件,最终会被渲染成a元素,其中属性to代替a标题的href属性 NavLink是在Link基础之上增加了一些样式属性,例如组件被选中时,发生样式变化,则可以设置NavLink的一下属性:
- activeStyle:活跃时(匹配时)的样式
- activeClassName:活跃时添加的class
- switch:swich组件的作用适用于当匹配到第一个组件的时候,后面的组件就不应该继续匹配
- redirect:路由的重定向
hooks
除了一些路由相关的组件之外,react-router还提供一些hooks,如下:
- useHistory:组件内部直接访问history,无须通过props获取
- useParams:获取路由参数
- useLocation:返回当前 URL的 location对象
传参
路由传递参数主要分成了三种形式:
动态路由的方式(params):
路由配置:
{ path: '/detail/:id/:name', component: Detail }
路由跳转:
import { useHistory,useParams } from 'react-router-dom';
const history = useHistory();
// 跳转路由 地址栏:/detail/2/zora
history.push('/detail/2/zora')
<!--或者-->
this.props.history.push( '/detail/2/zora' )
获取参数:
// 获取路由参数
const params = useParams()
console.log(params) // {id: "2",name:"zora"}
<!-- 或者 -->
this.props.match.params
优点:
- 刷新页面,参数不丢失
缺点:
- 只能传字符串,传值过多url会变得很长
- 参数必须在路由上配置
search传递参数
路由不需要特别配置
路由跳转:
import { useHistory } from 'react-router-dom';
const history = useHistory();
// 路由跳转 地址栏:/detail?id=2
history.push('/detail?id=2')
// 或者
history.push({pathname:'/detail',search:'?id=2'})
获取参数:所获取的是查询字符串,所以,还需要进一步的解析,自己自行解析,也可以使用第三方模块:qs,或者nodejs里的query-string
const params = useLocation()
<!--或者-->
this.props.location.search
优点:
- 刷新页面,参数不丢失
缺点:
- 只能传字符串,传值过多url会变得很长,获取参数需要自定义hooks
state传参
路由不需要单独配置
路由跳转:
import { useHistory,useLocation } from 'react-router-dom';
const history = useHistory();
const item = {id:1,name:"zora"}
// 路由跳转
history.push(`/user/role/detail`, { id: item });
<!--或者-->
this.props.history.push({pathname:"/sort ",state : { name : 'sunny' }});
获取参数:
// 参数获取
const {state} = useLocation()
console.log(state) // {id:1,name:"zora"}
<!--或者-->
this.props.location.state
优点:
- 可以传对象
缺点:
< BrowserRouter>, < BrowserRouter>页面刷新参数也不会丢失
query
路由不需要特别配置
路由跳转:
this.props.history.push({pathname:"/query",query: { name : 'sunny' }});
获取参数:
this.props.location.query.name
优势:
- 传参优雅,传递参数可传对象;
缺点:
- 刷新地址栏,参数丢失
17.React Router有几种模式,实现原理是什么
react Router 有四个库:
- react router:核心库,封装了
Router,Route,Switch等核心组件,实现了从路由的改变到组件的更新的核心功能,
- react router dom:dom环境下的router。在
react-router的核心基础上,添加了用于跳转的Link组件,和histoy模式下的BrowserRouter和hash模式下的HashRouter组件等。所谓BrowserRouter和HashRouter,也只不过用了history库中createBrowserHistory和createHashHistory方法
- react router native:RN环境下的router
- react router config
在单页应用中,一个web项目只有一个html页面,一旦页面加载完成之后,就不用因为用户的操作而进行页面的重新加载或者跳转,其特性如下:
- 改变 url 且不让浏览器像服务器发送请求
- 在不刷新页面的前提下动态改变浏览器地址栏中的URL地址
react router dom其中主要分成了两种模式:
- hash 模式:在url后面加上#,如http://127.0.0.1:5500/home/#/page1
- history 模式:允许操作浏览器的曾经在标签页或者框架里访问的会话历史记录
React Router对应的hash模式和history模式对应的组件为:
- HashRouter
- BrowserRouter
这两个组件的使用都十分的简单,作为最顶层组件包裹其他组件
原理
参考
单页面应用路由实现原理是,切换url,监听url变化,从而渲染不同的页面组件。
主要的方式有history模式和hash模式。
history模式
①改变路由
history.pushState
history.pushState(state,title,path)
1 state:一个与指定网址相关的状态对象, popstate 事件触发时,该对象会传入回调函数。如果不需要可填 null。
2 title:新页面的标题,但是所有浏览器目前都忽略这个值,可填 null。
3 path:新的网址,必须与当前页面处在同一个域。浏览器的地址栏将显示这个地址。
history.replaceState
history.replaceState(state,title,path)
参数和pushState一样,这个方法会修改当前的history对象记录, history.length 的长度不会改变。
②监听路由
popstate事件
window.addEventListener('popstate',function(e){
/* 监听改变 */
})
同一个文档的 history 对象出现变化时,就会触发 popstate 事件 history.pushState 可以使浏览器地址改变,但是无需刷新页面。注意⚠️的是:用 history.pushState() 或者 history.replaceState() 不会触发 popstate 事件。 popstate 事件只会在浏览器某些行为下触发, 比如点击后退、前进按钮或者调用 history.back()、history.forward()、history.go()方法。
hash模式
①改变路由
window.location.hash
通过window.location.hash 属性获取和设置 hash 值。
在hash模式下 ,history.push 底层是调用了window.location.href来改变路由。history.replace底层是调用 window.location.replace改变路由。
②监听路由
onhashchange
window.addEventListener('hashchange',function(e){
/* 监听改变 */
})
18.react render原理,在什么时候触发
render存在两种形式:
- 类组件中的render方法
- 函数组件的函数本身
触发时机:
- 类组件setState
- 函数组件通过useState hook修改状态
一旦执行了setState就会执行render方法(无论值是否发生变化),useState 会判断当前值有无发生改变确定是否执行render方法,一旦父组件发生渲染,子组件也会渲染
19.如何提高组件的渲染效率
在之前文章中,我们了解到render的触发时机,简单来讲就是类组件通过调用setState方法, 就会导致render,父组件一旦发生render渲染,子组件一定也会执行render渲染
父组件渲染导致子组件渲染,子组件并没有发生任何改变,这时候就可以从避免无谓的渲染,具体实现的方式有如下:
- shouldComponentUpdate:
- 通过shouldComponentUpdate生命周期函数来比对 state和 props,确定是否要重新渲染
- 默认情况下返回true表示重新渲染,如果不希望组件重新渲染,返回 false 即可
- PureComponent:
- 跟shouldComponentUpdate原理基本一致,通过对 props 和 state的浅比较结果来实现 shouldComponentUpdate
- React.memo
- React.memo用来缓存组件的渲染,避免不必要的更新,其实也是一个高阶组件,与 PureComponent 十分类似。但不同的是, React.memo 只能用于函数组件
- 如果需要深层次比较,这时候可以给memo第二个参数传递比较函数
20.react diff
跟Vue一致,React通过引入Virtual DOM的概念,极大地避免无效的Dom操作,使我们的页面的构建效率提到了极大的提升
而diff算法就是更高效地通过对比新旧Virtual DOM来找出真正的Dom变化之处
传统diff算法通过循环递归对节点进行依次对比,效率低下,算法复杂度达到 O(n^3),react将算法进行一个优化,复杂度降为O(n)
react中diff算法主要遵循三个层级的策略:
- tree层级
- DOM节点跨层级的操作不做优化,只会对相同层级的节点进行比较
- 只有删除、创建操作,没有移动操作
- conponent 层级
- 如果是同一个类的组件,则会继续往下diff运算,如果不是一个类的组件,那么直接删除这个组件下的所有子节点,创建新的
- element 层级
- 对于比较同一层级的节点们,每个节点在对应的层级用唯一的key作为标识
- 提供了 3 种节点操作,分别为 INSERT_MARKUP(插入)、MOVE_EXISTING (移动)和 REMOVE_NODE (删除)
- 通过key可以准确地发现新旧集合中的节点都是相同的节点,因此无需进行节点删除和创建,只需要将旧集合中节点的位置进行移动,更新为新集合中节点的位置
- 由于dom节点的移动操作开销是比较昂贵的,在只修改文本的情况下,没有key的情况下要比有key的性能更好
22.react 性能优化的手段
-
避免不必要的render:通过shouldComponentUpdate、PureComponent、React.memo
-
使用 Immutable:在做react性能优化的时候,为了避免重复渲染,我们会在shouldComponentUpdate()中做对比,当返回true执行render方法。Immutable通过is方法则可以完成对比,而无需像一样通过深度比较的方式比较
-
避免使用内联函数:每次调用render函数时都会创建一个新的函数实例
-
事件绑定方式:避免在render函数中声明函数,通过在constructor绑定this,或者在声明函数的时候使用箭头函数
-
使用 React Fragments 避免额外标记:用户创建新组件时,每个组件应具有单个父标签。这个额外标签除了充当父标签之外,并没有其他作用,这时候则可以使用fragement
-
懒加载组件:从工程方面考虑,webpack存在代码拆分能力,可以为应用创建多个包,并在运行时动态加载,减少初始包的大小。而在react中使用到了Suspense和 lazy组件实现代码拆分功能,基本使用如下:
const johanComponent = React.lazy(() => import(/* webpackChunkName: "johanComponent" */ './myAwesome.component'));
export const johanAsyncComponent = props => (
<React.Suspense fallback={<Spinner />}>
<johanComponent {...props} />
</React.Suspense>
);
-
服务端渲染:采用服务端渲染端方式,可以使用户更快的看到渲染完成的页面
23.在React项目中如何捕获错误
错误在我们日常编写代码是非常常见的
举个例子,在react项目中去编写组件内JavaScript代码错误会导致 React 的内部状态被破坏,导致整个应用崩溃,这是不应该出现的现象
作为一个框架,react也有自身对于错误的处理的解决方案。
为了解决出现的错误导致整个应用崩溃的问题,react16引用了错误边界新的概念
错误边界是一种 React 组件,这种组件可以捕获发生在其子组件树任何位置的 JavaScript 错误,并打印这些错误,同时展示降级 UI,而并不会渲染那些发生崩溃的子组件树
错误边界在渲染期间、生命周期方法和整个组件树的构造函数中捕获错误
形成错误边界组件的两个条件:
- 使用了 static getDerivedStateFromError()
- 使用了 componentDidCatch()
抛出错误后,请使用 static getDerivedStateFromError() 渲染备用 UI ,使用 componentDidCatch() 打印错误信息,如下:
class ErrorBoundary extends React.Component {
constructor(props) {
super(props);
this.state = { hasError: false };
}
static getDerivedStateFromError(error) {
// 更新 state 使下一次渲染能够显示降级后的 UI
return { hasError: true };
}
componentDidCatch(error, errorInfo) {
// 你同样可以将错误日志上报给服务器
logErrorToMyService(error, errorInfo);
}
render() {
if (this.state.hasError) {
// 你可以自定义降级后的 UI 并渲染
return <h1>Something went wrong.</h1>;
}
return this.props.children;
}
}
然后就可以把自身组件的作为错误边界的子组件,如下:
<ErrorBoundary>
<MyWidget />
ErrorBoundary>
下面这些情况无法捕获到异常:
- 事件处理
- 异步代码
- 服务端渲染
- 自身抛出来的错误
对于错误边界无法捕获的异常,如事件处理过程中发生问题并不会捕获到,是因为其不会在渲染期间触发,并不会导致渲染时候问题
这种情况可以使用js的try…catch…语法,如下:
class MyComponent extends React.Component {
constructor(props) {
super(props);
this.state = { error: null };
this.handleClick = this.handleClick.bind(this);
}
handleClick() {
try {
// 执行操作,如有错误则会抛出
} catch (error) {
this.setState({ error });
}
}
render() {
if (this.state.error) {
return <h1>Caught an error.</h1>
}
return <button onClick={this.handleClick}>Click Me</button>
}
}
除此之外还可以通过监听onerror事件:
window.addEventListener('error', function(event) { ... })
24.Redux和Vuex的异同点,以及用到的相同的思想
相同点
- state共享数据
- 流程一致:定义全局state,触发修改方法,修改state
- 全局注入store
不同点:
- redux使用的是不可变数据,而Vuex是可变的。
- redux每次都是用新的state替换旧的state,vuex是直接修改。
- redux在检测数据变化时是通过diff算法比较差异的;vuex是通过getter/setter来比较的
- vuex定义了state,getter,mutation,action;redux定义了state,reducer,action
- vuex中state统一存放,方便理解;react中state依赖reducer初始值
- vuex的mapGetters可以快捷得到state,redux中是mapStateToProps
- vuex同步使用mutation,异步使用action;redux同步异步都使用reducer
相同思想
- 单一数据源
- 变化可预测
- MVVM思想
25.什么是状态提升
使用 react 经常会遇到几个组件需要共用状态数据的情况。这种情况下,我们最好将这部分共享的状态提升至他们最近的父组件当中进行管理。我们来看一下具体如何操作吧。
import React from 'react'
class Child_1 extends React.Component{
constructor(props){
super(props)
}
render(){
return (
<div>
<h1>{this.props.value+2}</h1>
</div>
)
}
}
class Child_2 extends React.Component{
constructor(props){
super(props)
}
render(){
return (
<div>
<h1>{this.props.value+1}</h1>
</div>
)
}
}
class Three extends React.Component {
constructor(props){
super(props)
this.state = {
txt:"牛逼"
}
this.handleChange = this.handleChange.bind(this)
}
handleChange(e){
this.setState({
txt:e.target.value
})
}
render(){
return (
<div>
<input type="text" value={this.state.txt} onChange={this.handleChange}/>
<p>{this.state.txt}</p>
<Child_1 value={this.state.txt}/>
<Child_2 value={this.state.txt}/>
</div>
)
}
}
export default Three
26.对 React context 的理解
在React中,数据传递一般使用props传递数据,维持单向数据流,这样可以让组件之间的关系变得简单且可预测,但是单项数据流在某些场景中并不适用。单纯一对的父子组件传递并无问题,但要是组件之间层层依赖深入,props就需要层层传递显然,这样做太繁琐了。
Context 提供了一种在组件之间共享此类值的方式,而不必显式地通过组件树的逐层传递 props。
可以把context当做是特定一个组件树内共享的store,用来做数据传递。简单说就是,当你不想在组件树中通过逐层传递props或者state的方式来传递数据时,可以使用Context来实现跨层级的组件数据传递。
JS的代码块在执行期间,会创建一个相应的作用域链,这个作用域链记录着运行时JS代码块执行期间所能访问的活动对象,包括变量和函数,JS程序通过作用域链访问到代码块内部或者外部的变量和函数。
假如以JS的作用域链作为类比,React组件提供的Context对象其实就好比一个提供给子组件访问的作用域,而 Context对象的属性可以看成作用域上的活动对象。由于组件 的 Context 由其父节点链上所有组件通 过 getChildContext()返回的Context对象组合而成,所以,组件通过Context是可以访问到其父组件链上所有节点组件提供的Context的属性。
27.React声明组件有哪几种方法,有什么不同?
React 声明组件的三种方式:
- 函数式定义的
无状态组件
- ES5原生方式
React.createClass定义的组件
- ES6形式的
extends React.Component定义的组件
(1)无状态函数式组件 它是为了创建纯展示组件,这种组件只负责根据传入的props来展示,不涉及到state状态的操作 组件不会被实例化,整体渲染性能得到提升,不能访问this对象,不能访问生命周期的方法
(2)ES5 原生方式 React.createClass // RFC React.createClass会自绑定函数方法,导致不必要的性能开销,增加代码过时的可能性。
(3)E6继承形式 React.Component // RCC 目前极为推荐的创建有状态组件的方式,最终会取代React.createClass形式;相对于 React.createClass可以更好实现代码复用。
无状态组件相对于于后者的区别: 与无状态组件相比,React.createClass和React.Component都是创建有状态的组件,这些组件是要被实例化的,并且可以访问组件的生命周期方法。
React.createClass与React.Component区别:
① 函数this自绑定
- React.createClass创建的组件,其每一个成员函数的this都有React自动绑定,函数中的this会被正确设置。
- React.Component创建的组件,其成员函数不会自动绑定this,需要开发者手动绑定,否则this不能获取当前组件实例对象。
② 组件属性类型propTypes及其默认props属性defaultProps配置不同
- React.createClass在创建组件时,有关组件props的属性类型及组件默认的属性会作为组件实例的属性来配置,其中defaultProps是使用getDefaultProps的方法来获取默认组件属性的
- React.Component在创建组件时配置这两个对应信息时,他们是作为组件类的属性,不是组件实例的属性,也就是所谓的类的静态属性来配置的。
③ 组件初始状态state的配置不同
- React.createClass创建的组件,其状态state是通过getInitialState方法来配置组件相关的状态;
- React.Component创建的组件,其状态state是在constructor中像初始化组件属性一样声明的。
27.React中constructor和getInitialState的区别?
两者都是用来初始化state的。前者是ES6中的语法,后者是ES5中的语法,新版本的React中已经废弃了该方法。
getInitialState是ES5中的方法,如果使用createClass方法创建一个Component组件,可以自动调用它的getInitialState方法来获取初始化的State对象,
var APP = React.creatClass ({
getInitialState() {
return {
userName: 'hi',
userId: 0
};
}
})
React在ES6的实现中去掉了getInitialState这个hook函数,规定state在constructor中实现,如下:
Class App extends React.Component{
constructor(props){
super(props);
this.state={};
}
}
28.React 组件中怎么做事件代理?它的原理是什么?
React基于Virtual DOM实现了一个SyntheticEvent层(合成事件层),定义的事件处理器会接收到一个合成事件对象的实例,它符合W3C标准,且与原生的浏览器事件拥有同样的接口,支持冒泡机制,所有的事件都自动绑定在最外层上。
在React底层,主要对合成事件做了两件事:
- 事件委派: React会把所有的事件绑定到结构的最外层,使用统一的事件监听器,这个事件监听器上维持了一个映射来保存所有组件内部事件监听和处理函数。
- 自动绑定: React组件中,每个方法的上下文都会指向该组件的实例,即自动绑定this为当前组件。
29.React-Router怎么设置重定向?
使用``组件实现路由的重定向:
<Switch>
<Redirect from='/users/:id' to='/users/profile/:id'/>
<Route path='/users/profile/:id' component={Profile}/>
</Switch>
当请求 /users/:id 被重定向去 '/users/profile/:id':
- 属性
from: string:需要匹配的将要被重定向路径。
- 属性
to: string:重定向的 URL 字符串
- 属性
to: object:重定向的 location 对象
- 属性
push: bool:若为真,重定向操作将会把新地址加入到访问历史记录里面,并且无法回退到前面的页面。
30.setState 是同步异步?为什么?实现原理?
1. setState是同步执行的
setState是同步执行的,但是state并不一定会同步更新
2. setState在React生命周期和合成事件中批量覆盖执行
在React的生命周期钩子和合成事件中,多次执行setState,会批量执行
具体表现为,多次同步执行的setState,会进行合并,类似于Object.assign,相同的key,后面的会覆盖前面的
当遇到多个setState调用时候,会提取单次传递setState的对象,把他们合并在一起形成一个新的
单一对象,并用这个单一的对象去做setState的事情,就像Object.assign的对象合并,后一个
key值会覆盖前面的key值
经过React 处理的事件是不会同步更新 this.state的. 通过 addEventListener || setTimeout/setInterval 的方式处理的则会同步更新。
为了合并setState,我们需要一个队列来保存每次setState的数据,然后在一段时间后执行合并操作和更新state,并清空这个队列,然后渲染组件。
31.如何将两个或多个组件嵌入到一个组件中?
可以通过以下方式将组件嵌入到一个组件中:
class MyComponent extends React.Component{
render(){
return(
<div>
<h1>Hello</h1>
<Header/>
</div>
);
}
}
class Header extends React.Component{
render(){
return
<h1>Header Component</h1>
};
}
ReactDOM.render(
<MyComponent/>, document.getElementById('content')
);
32.React Hooks 和生命周期的关系?
函数组件 的本质是函数,没有 state 的概念的,因此不存在生命周期一说,仅仅是一个 render 函数而已。 但是引入 Hooks 之后就变得不同了,它能让组件在不使用 class 的情况下拥有 state,所以就有了生命周期的概念,所谓的生命周期其实就是 useState、 useEffect() 和 useLayoutEffect() 。
即:Hooks 组件(使用了Hooks的函数组件)有生命周期,而函数组件(未使用Hooks的函数组件)是没有生命周期的。
下面是具体的 class 与 Hooks 的生命周期对应关系:
constructor:函数组件不需要构造函数,可以通过调用 **useState 来初始化 state**。如果计算的代价比较昂贵,也可以传一个函数给 useState。
const [num, UpdateNum] = useState(0)
getDerivedStateFromProps:一般情况下,我们不需要使用它,可以在渲染过程中更新 state,以达到实现 getDerivedStateFromProps 的目的。
function ScrollView({row}) {
let [isScrollingDown, setIsScrollingDown] = useState(false);
let [prevRow, setPrevRow] = useState(null);
if (row !== prevRow) {
// Row 自上次渲染以来发生过改变。更新 isScrollingDown。
setIsScrollingDown(prevRow !== null && row > prevRow);
setPrevRow(row);
}
return `Scrolling down: ${isScrollingDown}`;
}
React 会立即退出第一次渲染并用更新后的 state 重新运行组件以避免耗费太多性能。
shouldComponentUpdate:可以用 **React.memo** 包裹一个组件来对它的 props 进行浅比较
const Button = React.memo((props) => { // 具体的组件});
注意:**React.memo 等效于 **``**PureComponent**,它只浅比较 props。这里也可以使用 useMemo 优化每一个节点。
render:这是函数组件体本身。componentDidMount, componentDidUpdate: useLayoutEffect 与它们两的调用阶段是一样的。但是,我们推荐你一开始先用 useEffect,只有当它出问题的时候再尝试使用 useLayoutEffect。useEffect 可以表达所有这些的组合。
// componentDidMount
useEffect(()=>{
// 需要在 componentDidMount 执行的内容
}, [])
useEffect(() => {
// 在 componentDidMount,以及 count 更改时 componentDidUpdate 执行的内容
document.title = `You clicked ${count} times`;
return () => {
// 需要在 count 更改时 componentDidUpdate(先于 document.title = ... 执行,遵守先清理后更新)
// 以及 componentWillUnmount 执行的内容
} // 当函数中 Cleanup 函数会按照在代码中定义的顺序先后执行,与函数本身的特性无关
}, [count]); // 仅在 count 更改时更新
请记得 React 会等待浏览器完成画面渲染之后才会延迟调用 ,因此会使得额外操作很方便
componentWillUnmount:相当于 useEffect 里面返回的 cleanup 函数
// componentDidMount/componentWillUnmount
useEffect(()=>{
// 需要在 componentDidMount 执行的内容
return function cleanup() {
// 需要在 componentWillUnmount 执行的内容
}
}, [])
componentDidCatch and getDerivedStateFromError:目前还没有这些方法的 Hook 等价写法,但很快会加上。
class 组件
Hooks 组件
constructor
useState
getDerivedStateFromProps
useState 里面 update 函数
shouldComponentUpdate
useMemo
render
函数本身
componentDidMount
useEffect
componentDidUpdate
useEffect
componentWillUnmount
useEffect 里面返回的函数
componentDidCatch
无
getDerivedStateFromError
无
33.为什么 useState 要使用数组而不是对象
useState 的用法:
const [count, setCount] = useState(0)
可以看到 useState 返回的是一个数组,那么为什么是返回数组而不是返回对象呢?
这里用到了解构赋值,所以先来看一下ES6 的解构赋值:
数组的解构赋值
const foo = [1, 2, 3];
const [one, two, three] = foo;
console.log(one); // 1
console.log(two); // 2
console.log(three); // 3
对象的解构赋值
const user = {
id: 888,
name: "xiaoxin"
};
const { id, name } = user;
console.log(id); // 888
console.log(name); // "xiaoxin"
看完这两个例子,答案应该就出来了:
- 如果 useState 返回的是数组,那么使用者可以对数组中的元素命名,代码看起来也比较干净
- 如果 useState 返回的是对象,在解构对象的时候必须要和 useState 内部实现返回的对象同名,想要使用多次的话,必须得设置别名才能使用返回值
下面来看看如果 useState 返回对象的情况:
// 第一次使用
const { state, setState } = useState(false);
// 第二次使用
const { state: counter, setState: setCounter } = useState(0)
这里可以看到,返回对象的使用方式还是挺麻烦的,更何况实际项目中会使用的更频繁。 **总结:*useState 返回的是 array 而不是 object 的原因就是为了*降低使用的复杂度,返回数组的话可以直接根据顺序解构,而返回对象的话要想使用多次就需要定义别名了。
34.如何在React中使用innerHTML
增加dangerouslySetInnerHTML属性,并且传入对象的属性名叫_html
function Component(props){
return <div dangerouslySetInnerHTML={{_html:'你好'}}>
</div>
}
小程序
1.什么是微信小程序
- 小程序是一种全新的连接用户与服务的方式,它可以在微信内被便捷地获取和传播,同时具有出色的使用体验。
- 寄生于宿主应用,可以调用宿主应用的其他能力,也可以调用设备本身的能力。
2.微信小程序为什么会越来越受欢迎/优点是什么?
- 不占内存,随用随走。 小程序不需要存储空间,不用下载、注册等一系列繁琐的操作,用户使用简介方便,随用随走。
- 成本低、利润大。 相对于APP,小程序的开发成本更低,小程序还可以结合线上线下的营销活动,争取更大的利润。
- 宣传应用范围广。 不管是餐饮、旅游、教培、电商,还是政务,几乎每个领域都可以通过小程序实现自己的业务。而且小程序、社群、直播等多种方式都可以进行宣传,相对于传统的实体门店宣传范围更广泛。
- 日活量丰富,用户基数大。 那微信小程序来说,小程序是基于微信的,微信的十亿日活量,带给小程序巨大的流量池,用转化更容易。
3.小程序与H5 通信方式
3.1 :小程序->H5 通过 URL 拼接参数
http://127.0.0.1:8080/test?key=123
3.2:H5->小程序wx.miniProgram.postMessage api
实现方式:
- 引入js SDK
<script type="text/javascript" src="https://res.wx.qq.com/open/js/jweixin-1.6.0.js">script>
- vue 项目需要安装依赖
npm install weixin-webview-jssdk
- 小程序绑定方法
<web-view bindmessage="bindGetMsg"></web-view>
bindGetMsg:function(res){
console.log('从h5页面获取到的信息----->',res)
}
- h5端 调用wx.miniProgram.postMessage
import wx from "weixin-webview-jssdk";
wx.miniProgram.postMessage({ data: { foo: {} } });
 优点:接入成本低
优点:接入成本低
缺点:向小程序发送消息,会在特定时机(小程序后退、组件销毁、分享)触发组件的 message 事件,只能这些特定时机,基本宣布postMessage没用!因为这些时机很苛刻,不符合我们要求。反人类设计!
3.3:小程序-> H5 url 携带信息navigateTo、reLaunch、redirectTo
实现方式:
wx.miniProgram.navigateTo({
url: '../h5/loading-page',
})
wx.miniProgram.navigateTo({
url: '../h5/loading-page?type=aaa',
})
缺点:url 数据量有限,且需要打开界面
3.4 :内存共享(无法实现)
无法实现,原因 wx.setStorage 与localStorage 隔离
localStorage.setItem('h5key','value')
wx.setStorageSync('wx-key', 'value')
3.5:长连-Websocket
- Websocket 简介:WebSocket 是 HTML5 开始提供的一种在单个 TCP 连接上进行全双工通讯的协议;
- 建立在 TCP 协议之上,服务器端的实现比较容易。
- 与 HTTP 协议有着良好的兼容性。默认端口也是80和443,并且握手阶段采用 HTTP 协议,因此握手时不容易屏蔽,能通过各种 HTTP 代理服务器。
- 数据格式比较轻量,性能开销小,通信高效。
- 可以发送文本,也可以发送二进制数据。
- 没有同源限制,客户端可以与任意服务器通信。
- 协议标识符是ws(如果加密,则为wss),服务器网址就是 URL。
优点:可以实现实时通信
缺点:成本高,服务器压力大等;放弃此方式。
总结
- 微信并不鼓励在小程序中大范围嵌入 H5,为了避免开发者把小程序变成“浏览器”,微信对小程序与内嵌 H5 的通讯做了诸多限制
- 尽量使用单一方式实现,比如纯小程序原生,将h5功能移至小程序原生
- 原生页面与 H5 之间通过 URL 进行通信
- 不要尝试越过wx 限制
- 不得不用混合开发时,尽量做好优化,引入骨架屏等优化方式提高用户体验感
- 以上三种方式均未很好实现web-view 与H5双向通信
4.请谈谈微信小程序主要目录和文件的作用?
- project.config.json:项目配置文件,用的最多的就是配置是否开启https校验
- App.js:设置一些全局的基础数据等
- App.json:底部tab,标题栏和路由等设置
- App.wxss:公共样式,引入iconfont等
- pages:里面包含一个个具体的页面
- index.json:配置当前页面标题和引入组件
- index.wxml:页面结构
- index.wxss:页面样式表
- index.js:页面的逻辑,请求和数据处理
- wxml 模板文件,是框架设计的一套标签预言,结合基础组件,事件系统,可以构建出页面的结构 wxss 样式文件,是一套样式语言,用于描述WXML的组件样式 js脚本逻辑文件。逻辑处理网络请求 json配置文件,小程序设置,如页面注册,页面标题及tabBar
- app.json是整个小程序的全局配置,包括:
- pages:所有页面路径
- 网络设置(网络超时事件)
- 页面表现(页面注册)
- window:(背景色,导航样式,默认标题)
- 底部tab等
- app.js 监听并处理小程序的生命周期函数,声明全局变量
- app.wxss 全局配置的样式文件
5.请谈谈wxml与标准的html的异同?
- 都是用来描述页面的结构
- 都由标签,属性等构成
- 标签名字不一样,且小程序标签更少,单一标签更多
- 多了一些 wx:if 这样的属性以及{{}} 这样的表达式
- WXML仅能在微信小程序开发者工具中预览,而HTML可以在浏览器内预览
- 组件封装不同,WXML对组件进行了重新封装
- 小程序运行在JS Core内,没有DOM树和windiw对象,小程序中无法使用window对象和document对象。
6.请谈谈WXSS和CSS的异同?
都是用来描述页面的样子
- WXSS具有CSS大部分的特性,也做了一些扩充和修改
- WXSS新增了尺寸单位,WXSS在底层支持新的尺寸单位rpx
- WXSS仅支持部分CSS选择器
- WXSS提供全局样式与局部样式
7.你是怎么封装微信小程序的数据请求的?
- 在根目录下创建util目录及api.js文件和apiConfig.js文件
- 在apiConfig.js封装基础的get,post和put,upload等请求方法,设置请求体,带上token和异常处理等
- 在api中引入apiConfig.js封装好的请求方法.根据页面数据请求的urls,设置对应的方法并导出
- 在具体的页面中导入或将所有的接口放在统一的js文件中并导出
- 在app.js中创建封装请求数据的方法
- 在子页面中调用封装的请求数据
8.(重要)小程序页面之间有哪些(传值)传递数据的方法?
- 页面跳转或重定向时,使用url带参数传递数据
- 使用组件模板 template传递参数
- 使用缓存传递参数
- 使用数据库传递参数
- 给html元素添加data-*属性来传递值,然后通过e.currentTarget.dataset或onload的param参数获取(data- 名称不能有大写字母,不可以存放对象)
- 设置id 的方法标识来传值,通过e.currentTarget.id获取设置的id值,然后通过设置全局对象的方式来传递数据
- 在navigator中添加参数数值
- 使用全局遍历实现数据传递
9.请谈谈小程序的双向绑定和vue的异同?
大体相同,但小程序之间this.data的属性是不可以同步到视图的,必须调用this.setData()方法
10.请谈谈小程序的生命周期函数
- onLoad():页面加载时触发,只会调用一次,可获取当前页面路径中的参数
- onShow():页面显示/切入前台时候触发,一般用来发送数据请求
- onReady():页面初次渲染完成时触发,只会调用一次,代表页面已可和视图层进行交互
- onHide():页面隐藏/切入后台时触发,如底部tab切换到其他页面或小程序切入后台等
11.简述微信小程序原理
小程序本质就是一个单页面应用,所有的页面渲染和事件处理,都在一个页面内进行,但又可以通过微信客户端调用原生的各种接口;
它的架构,是数据驱动的架构模式,它的UI和数据是分离的,所有的页面更新,都需要通过对数据的更改来实现;
它从技术讲和现有的前端开发差不多,采用JavaScript、WXML、WXSS三种技术进行开发;
功能可分为webview和APPService两个部分:
- webview主要用来展示UI,appservice用来处理业务逻辑,数据及接口调用,它们在两个进程中进行,通过系统层JSBridge实现通信,实现UI的渲染,事件处理;
- appService用来处理业务逻辑、数据及接口调用;
两个部分在两个进程中运行,通过系统层JSBridge实现通信,实现UI的渲染、事件的处理等。
javaScript的代码是运行在微信App中的,因此一些h5技术的应用需要微信APP提供对应的API支持 wxml 微信自己基于xml语法开发的,因此在开发时只能使用微信提供的现有标签,html的标签是无法使用的 wxss具有css的大部分特性,但并不是所有都支持,没有详细文档
wxss的图片引入需要使用外链地址,没有body,样式可以使用import导入。
12.那些方法来提高微信小程序的应用速度?
- 提高页面的加载速度
- 用户行为预测
- 减少默认的data的大小
- 组件化方案
13.分析微信小程序的优劣势?
优势:
- 容易上手,基础组件库比较全,基本不需要考虑兼容问题
- 开发文档比较完善,开发社区比较活跃,支持插件式开发
- 良好的用户体验,无需下载,通过搜索和扫一扫就可以打开,打开速度快,安卓上可以添加到桌面,与原生APP差不多
- 开发成本比APP要低
- 为用户提供良好的保障(小程序发布,严格是审查流程)
劣势:
- 限制较多,页面大小不能超过1M,不能打开超过5个层级的页面
- 样式单一,部分组件已经是成型的,样式不可修改,例如:幻灯片,导航
- 推广面窄,不能分享朋友圈,只能通过分享给朋友,附加小程序推广
- 依托与微信,无法开发后台管理功能
- 后台调试麻烦,因为api接口必须https请求且公网地址
- 真机测试,个别安卓和苹果表现迥异,例如安卓的定位功能加载很慢
14.怎么解决微信小程序的异步请求问题?
在回调函数中调用下一个组件的函数
*/app.js*/
success:function(info){
that.apirtnCallback(info)
}
*/index.js*/
onLoad:function(){
app.apirtnCallback = res =>{
console.log(res)
}
}
14. 小程序关联微信公众号如何确定用户的唯一性?
使用wx.getUserlnfo方法 withCredentials为true时,可获取encryptedData,里面有union_id,后端需要进行对称解密
15. 使用webview直接加载要注意那些事项?
- 必须要在小程序后台使用管理员添加业务域名
- h5页面跳转至小程序的脚步必须是1.3.1以上
- 微信分享只可以是小程序的主名称,如要自定义分享内容,需小程序版本在1.7.1以上
- h5的支付不可以是微信公众号的appid,必须是小程序的appid,而且用户的openid也必须是用户和小程序的
16. 小程序调用后台接口遇到那些问题?
- 数据的大小限制,超过范围会直接导致整个小程序崩溃,除非重启小程序
- 小程序不可以直接渲染文章内容这类型的html文本,显示需要借助插件注:插件渲染会导致页面加载变慢,建议在后台对文章内容的html进行过滤,后台直接处理批量替换p标签div标签为view标签,然后其他的标签让插件来做
17. 微信小程序如何实现下拉刷新?
用view代替scroll-view,设置onPullDownRefresh函数实现
1、先在 app.json 或 page.json 中配置 enablePullDownRefresh:true
2、page 里用 onPullDownRefresh 函数,在下拉刷新时执行
3、在下拉函数执行时发起数据请求,请求返回后,调用 wx.stopPullDownRefresh
4、停止下拉刷新的状态
18.webview中的页面怎么跳转回小程序?
// 1.
wx.miniProgram.navigateTo({
url:'pages/login/login'+'$params'
})
//跳转到小程序导航页面
wx.miniProgram.switchTab({
url:'/pages/index/index'
})
// 2.
// 首先,需要在你的html页面中引用一个js文件
<script type="text/javascript" src="https://res.wx.qq.com/open/js/jweixin-1.3.0.js"></script>
//然后为你的按钮标签注册一个点击事件
$(".kaiqi").click(function(){
wx.miniProgram.redirectTo({url: '/pages/indexTwo/indexTwo'})
});
// 这里的redirectTo跟小程序的wx.redirectTo()跳转页面是一样的,会关闭当前跳转到页面,换成navigateTo,跳转页面就不会关闭当前页面
18. bindtap和catchtap的区别?
- bind事件绑定不会阻止冒泡事件向上冒泡
- catch事件绑定可以阻止冒泡事件向上冒泡
19. (重要)简述小程序路由的区别
- wx.navigateTo():保留当前页面,跳转到应用内的某个页面。但是不能跳到 tabbar 页面
- wx.redirectTo():关闭当前页面,跳转到应用内的某个页面。但是不能跳转 tabbar 页面
- wx.switchTab():跳转到 tabBar 页面,并关闭其他所有非 tabBar 页面
- wx.navigateBack():关闭当前页面,返回上一页面或多级页面。可通过 getCurrentPages() 获取当前的页面栈,决定需要返回几层
- wx.reLaunch():关闭所有页面,打开到应用内的某个页面
20.小程序和Vue写法的区别?
1. 遍历的时候:
小程序:wx:for="list"
Vue:v-for="item in list"
2. 调用data模型(赋值)的时候:
小程序: this.data.item // 调用
this.setDate({item:1})//赋值
Vue: this.item //调用
this.item=1 //赋值
21. 小程序与原生App那个好?
各有各自的优点,都又有缺点
小程序的优点:
- 基于微信平台开发,享受微信自带的流量,这个优点最大
- 无需安装,只要打开微信就能用,不占手机内存,体验好
- 开发周期段,一般最多一个月就可以上线完成
- 开发所需的资金少,所需资金是开发原生APP的一半不到
- 小程序名称是唯一的,在微信的搜索里权重很高
- 容易上手,只要之前有HTML+CSS+JS基础知识,写小程序基本没有大问题
- 基本不需要考虑兼容性问题,只要微信可以正常运行的机器,就可以运行小程序
- 发布,审核高效,基本上午发布审核,下午就审核通过,升级简单,支持灰度发布
- 开发文档完善,社区活跃
- 支持插件式开发,一些基本功能可以开发成插件,供多个小程序使用
小程序缺点:
- 局限性很强(比如页面大小不能超过1M,不能打开超过5个层级的页面,样式单一,小程序的部分组件已经是成型的了,样式不能修改,比如幻灯片,导航)只能依赖于微信依托与微信,无法开发后台管理功能
- 不利于推广,推广面窄,不能分享朋友圈,只能分享给朋友,附近小程序推广,其中附加小程序也收到微信限制
- 后台调试麻烦,因为API接口必须https请求,且公网地址,也就是说后台代码必须发布到远程服务器上;当然我们可以修改host进行dns映射把远程服务器转到本地,或者开启tomcat远程调试;不管怎么说终归调试比较麻烦
- 前台测试有诸多坑,最头疼莫过于模拟器与真机显示不一致
- js引用只能使用绝对路径,不能操作DOM
原生App优点:
- 原生的相应速度快
- 对于有无网络操作时,譬如离线操作基本选用原生开发
- 需要调用系统硬件的功能(摄像头,拨号,短信蓝牙…)
- 在无网络或者弱网情况下体验好
原生App缺点:
- 开发周期长,开发成本高,需要下载
22.小程序的发布流程(开发流程)
- 注册微信小程序账号
- 获取微信小程序的AppID
- 下载微信小程序开发者工具
- 创建demo项目
- 去微信公众号配置域名
- 手机浏览
- 代码上传
- 提交审核
- 小程序发布
23. (重要)小程序授权登录 + 支付流程
授权,微信登录获取code,微信登录,获取 iv , encryptedData 传到服务器后台,如果没有注册就需要注册。
//1.小程序注册,要以公司的身份去注册一个小程序,才有微信支付权限
//2.绑定商户号
//3.在小程序填写合法域
//4.调用 wx.login() 获取 appid
//5.调用 wx.requestPayment
wx.requestPayment({
'timeStamp': '',//时间戳从1970年1月1日00:00:00至今的秒数,即当前的时间
'nonceStr': '',//随机字符串,长度为32个字符以下。
'package': '',//统一下单接口返回的 prepay_id 参数值,提交格式如:prepay_id=*
'signType': 'MD5',//签名类型,默认为MD5,支持HMAC-SHA256和MD5。注意此处需与统一下单的签名类型一致
'paySign': '',//签名,具体签名方案参见微信公众号支付帮助文档;
'success':function(res){},//成功回调
'fail':function(res){},//失败
'complete':function(res){}//接口调用结束的回调函数(调用成功、失败都会执行)
})
24.小程序还有那些功能?
客服功能,录音,视频,音频,地图,定位,拍照,动画,canvas
25. 小程序的常见问题:
- rpx:小程序的尺寸单位,规定屏幕为750rpx,可适配不同分辨率屏幕 本地资源无法通过wxss获取:background-image:可以使用网络图片,或者base64,或者使用标签
- wx.navigateTo无法打开页面:一个应用同时只能打开5个页面,请避免多层级的交互方式,或使用wx.redirectTo
- tabBar设置不显示:
- 1.tabBar的数量少于2项或超过5项都不会显示。
- 2.tabBar写法错误导致不会显示。
- 3.tabBar没有写pagePath字段(程序启动后显示的第一个页面)
26.小程序的生命周期
首先他有两个生命周期,一个是小程序的生命周期,一个是页面的生命周期:
26.1 小程序的:
onLaunch:当小程序初始化完成时,会触发 onLaunch(全局只触发一次)。
onShow:当小程序启动,或从后台进入前台显示,会触发 onShow
onHide:当小程序从前台进入后台,会触发 onHide。
onError:当小程序发生脚本错误,或者 api 调用失败时,会触发 onError 并带上错误信息
26.2 页面的:
onLoad: 监听页面加载.
onReady:监听页面初次渲染完成.
onShow: 监听页面显示.
onHide: 监听页面隐藏.
onUnload: 监听页面卸载
27. 微信小程序用哪种响应式方案?
flex +rpx
rpx(responsive pixel): 可以根据屏幕宽度进行自适应。规定屏幕宽为750rpx。如在 iPhone6 上,屏幕宽度为375px,共有750个物理像素,则750rpx = 375px = 750物理像素,1rpx = 0.5px = 1物理像素。
因为小程序是以微信为平台运行的,可以同时运行在android与ios的设备上,所以不可避免的会遇到布局适配问题,特别是在iphone5上,因为屏幕尺寸小的缘故,也是适配问题最多的机型,下面就简单介绍几种适配方法。
rpx适配 rpx是小程序中的尺寸单位,它有以下特征:
小程序的屏幕宽固定为750rpx(即750个物理像素),在所有设备上都是如此 1rpx=(screenWidth / 750)px,其中screenWidth为手机屏幕的实际的宽度(单位px),例如iphone6的screenWidth=375px,则在iphone6中1rpx=0.5px 由上可知,在不同设备上rpx与px的转换是不相同的,但是宽度的rpx却是固定的,所以可以使用rpx作为单位,来设置布局的宽高。
vw、vh适配 vw和vh是css3中的新单位,是一种视窗单位,在小程序中也同样适用。
小程序中,窗口宽度固定为100vw,将窗口宽度平均分成100份,1份是1vw 小程序中,窗口高度固定为100vh ,将窗口高度平均分成100份,1份是1vh 所以,我们在小程序中也可以使用vw、vh作为尺寸单位使用在布局中进行布局,但是一般情况下,百分比+rpx就已经足够使用了,所以它们的出场机会很少。
28.授权验证登录怎么做,用户退出后下次进入还需要再次授权吗
wx.login 获取到一个 code,拿这 code 去请求后台得到 openId, sessionKey, unionId。
调 wx.getUserInfo
一次性授权:
永久授权:调取授权登录接口并把获取到的用户公开信息存入数据库
29.小程序组件通信
1. 父传子
- 在父组件中的子组件标签绑定属性 传递要传输的变量
- 在子组件中用properties来接收数据 可以直接使用
- 改变组件的properties数据使用setData()
2. 子传父
- 在父组件的子组件标签上定义一个事件,绑定要执行的方法
- 在子组件中通过 this.triggerEvent来触发自定义事件,传递数据
- 在父组件中接收传递的数据,通过事件对象e来接收
3.获取其他组件数据
this.selectComponent(“.类名”):想获取哪个组件的数据
29.如何提高小程序的首屏加载时间
- 提前请求:异步数据数据请求不需要等待页面渲染完成、
- 利用缓存:利用 storage API 对异步请求数据进行缓存,二次启动时先利用缓存数据渲染页面,再进行后台更新
- 避免白屏:先展示页面骨架和基础内容
- 及时反馈:及时地对需要用户等待的交互操作给出反馈,避免用户以 为小程序没有响应
- 性能优化:避免不当使用 setdata 和 onpagescroll
包体积优化
- 分包加载(优先采用,大幅降低主包体积)。
- 图片优化(1.使用tinypng压缩图片素材; 2.服务器端支持,可采用webp格式)。
- 组件化开发(易维护)。
- 减少文件个数及冗余数据。
请求优化
- 关键数据尽早请求(onLoad()阶段请求,次要数据可以通过事件触发再请求);整合请求数据,降低请求次数。
- 采用cdn缓存静态的接口数据(如判断用户登录状态,未登录则请求缓存接口数据),cdn稳定且就近访问速度快(针对加载总时长波动大)。
- 缓存请求的接口数据。
首次渲染优化
- 图片懒加载(节省带宽)。
- setData优化(不要一次性设置过多的数据等)。
- DOM渲染优化(减少DOM节点)
30.微信小程序实现跳转到另外一个小程序的方法
1,首先需要在当前小程序app.json中定义:需要跳转的小程序的app-id
app.josn
"navigateToMiniProgramAppIdList": [
"*******" //appid
],
第一种方法:wx.navigateToMiniProgram(打开另一个小程序)
wx.navigateToMiniProgram({
appId: '**********',
path: 'page/index/index?id=123', //路径和携带的参数
extraData: {
foo: 'bar'
},
envVersion: 'develop',
success(res) {
// 打开成功
},
fail(res){
// 打开失败
},
complete(res){
// 调用结束 不管成功还是失败都执行
}
})
- appId:跳转到的小程序app-id
- path:打开的页面路径,如果为空则打开首页,path 中 ? 后面的部分会成为 query,在小程序的 App.onLaunch、App.onShow 和 Page.onLoad的回调函数中获取query数据
- extraData:需要传递给目标小程序的数据,目标小程序可在 App.onLaunch、App.onShow 中获取到这份数据
- envVersion:要打开的小程序版本,有效值: develop(开发版),trial(体验版),release(正式版),仅在当前小程序为开发版或体验版时此参数有效,如果当前小程序是正式版,则打开的小程序必定是正式版
第二种方法:navigator(跳转)
点击跳转另一个小程序
- target:在哪个目标上发生跳转,默认当前小程序,有效值: self(当前小程序),miniProgram(其它小程序)
- open-type:跳转方式 “avigate 对应 wx.navigateTo 或 wx.navigateToMiniProgram 的功能”
- app-id:跳转到的小程序app-id
- version:要打开的小程序版本,有效值: develop(开发版),trial(体验版),release(正式版),仅在当前小程序为开发版或体验版时此参数有效,如果当前小程序是正式版,则打开的小程序必定是正式版
31.小程序页面之间有哪些(传值)传递数据的方法?
- 页面跳转或重定向时,使用url带参数传递数据
- 使用组件模板 template传递参数
- 使用缓存传递参数
- 使用数据库传递参数
- 给html元素添加data-*属性来传递值,然后通过e.currentTarget.dataset或onload的param参数获取(data- 名称不能有大写字母,不可以存放对象)
- 设置id 的方法标识来传值,通过e.currentTarget.id获取设置的id值,然后通过设置全局对象的方式来传递数据
- 在navigator中添加参数数值
32.微信小程序和H5的区别?
- 运行环境不同(小程序在微信运行,h5在浏览器运行)
- 开发成本不同(h5需要兼容不同的浏览器)
- 获取系统权限不同(系统级权限可以和小程序无缝衔接)
- 应用在生成环境的运行速度流程(h5需不断对项目优化来提高用户体验)
作者:觉晓
链接:https://juejin.cn/post/7211775653167071291
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
33.小程序调用后台接口遇到那些问题?
-
数据的大小限制,超过范围会直接导致整个小程序崩溃,除非重启小程序
-
小程序不可以直接渲染文章内容这类型的html文本,显示需要借助插件
注:插件渲染会导致页面加载变慢,建议在后台对文章内容的html进行过滤,后台直接处理批量替换p标签div标签为view标签,然后其他的标签让插件来做
34.微信支付步骤
1.打开小程序,点击直接下单
2.用wx.login获取到用户临时登录凭证code,发送到后端服务器换取openid
3.在下单时,小程序需要将购买的商品id,数量,以及用户的openid传送到服务器
4.服务器在接收到商品id数量,openid后,生成服务器订单数据,同时经过一定的签名算法,向微信支付发起请求,获取预付单信息,同时将获取的数据再次进行相应规则的签名,向小程序端响应必要的信息
5.小程序端在获取到对应的参数之后,调用wx.requestPayment()发起微信支付,唤醒支付工作台,进行支付
6.接下来一系列操作都是由用户来操作的包括了微信支付密码,指纹等验证,确认支付后指向鉴权调起支付
7.鉴权调起支付:在微信后台进行鉴权,微信后台直接返回给前端支付结果,前端收到返回数据后对支付结果进行展示
8.推送支付结果:微信后台在给前端返回支付的结果后,也会向后台返回一个支付的结果,后台通过这个支付结果来更新订单的状态
35.小程序授权登录
1.当用户进入小程序的时候首先需要判断用户是否授权过小程序
2.如果没授权,需要通过一个按钮来实现授权登录
3.通过调用getuserInfo(),可以获取到个人信息
4.用户可以授权登录也可以取消登录
5.根据登录接口返回的code,判断用户是否为新用户
6.当用户注册成功之后,再调用登录接口,保存token
36.如何自定义tabbar
- 取消当前的 tabbar
- 插入自定义 tabbar 组件
- app.json 调用组件
- 页面显示 tabbar 组件
37.小程序怎样使用自定义组件
- 新建自定义组件目录,生成目录结构;
- 写好组件内容;
- 在要使用的目标页面的 json 文件中配置下
usingComponents,引入组件;
- 以标签的形式在页面中使用该组件即可;
- 传递数据和 vue 一样,通过自定义属性,然后在组件里通过
properties 接收就可以使用了
38.tabBar设置不显示
tabBar设置不显示有如下几个原因:
tabBar 的数量少于2项或超过5项都不会显示;tabBar 写法错误导致不显示;tabBar 没有写 pagePath 字段(程序启动后显示的第一个页面)
39.登录流程?
登录流程是调wx.login获取code传给后台服务器获取微信用户唯一标识openid及本次登录的会话密钥(session_key)等)。拿到开发者服务器传回来的会话密钥(session_key)之后,前端要保存wx.setStorageSync(‘sessionKey’, ‘value’)
持久登录状态:session信息存放在cookie中以请求头的方式带回给服务端,放到request.js里的wx.request的header里
40.小程序简单介绍下三种事件对象的属性列表?
1. 基础事件(BaseEvent)
-
type:事件类型
-
timeStamp:事件生成时的时间戳
-
target:触发事件的组件的属性值集合
-
currentTarget:当前组件的一些属性集合
2. 自定义事件(CustomEvent)
detail
3. 触摸事件(TouchEvent)
-
touches
-
changedTouches
41.app.json 是对当前小程序的全局配置,讲述三个配置各个项的含义?
- pages字段 —— 用于描述当前小程序所有页面路径,这是为了让微信客户端知道当前你的小程序页面定义在哪个目录。
- window字段 —— 小程序所有页面的顶部背景颜色,文字颜色定义在这里的
- tab字段—小程序全局顶部或底部
tab
42.简述下 wx.navigateTo(), wx.redirectTo(), wx.switchTab(), wx.navigateBack(), wx.reLaunch()的区别
- wx.navigateTo():
保留当前页面,跳转到应用内的某个页面。但是不能跳到 tabbar` 页面
- wx.redirectTo():
关闭当前页面,跳转到应用内的某个页面。但是不允许跳转到 tabbar` 页面
- wx.switchTab():
跳转到 abBar页面,并关闭其他所有非tabBar` 页面
- wx.navigateBack():
关闭当前页面,返回上一页面或多级页面。可通过getCurrentPages()` 获取当前的页面栈,决定需要返回几层
- **wx.reLaunch():**关闭所有页面,打开到应用内的某个页面
uniapp
1.uniapp进行条件编译的两种方法?小程序端和H5的代表值是什么?
通过 #ifdef、#ifndef 的方式 H5 : H5 MP-WEIXIN : 微信小程序
2.uniapp的配置文件、入口文件、主组件、页面管理部分
pages.json 配置文件 main.js 入口文件 App.vue 主组件 pages 页面管理部分
3.uniapp上传文件时用到api是什么 格式是什么?
uni.uploadFile({
url: '要上传的地址',
fileType:'image',
filePath:'图片路径',
name:'文件对应的key',
success: function(res){
console.log(res)
},
})
4.uniapp获取地理位置的API是什么?
uni.getLocation
5.rpx、px、em、rem、%、vh、vw的区别是什么?
- rpx 相当于把屏幕宽度分为750份,1份就是1rpx
- px 绝对单位,页面按精确像素展示
- em 相对单位,相对于它的父节点字体进行计算
- rem 相对单位,相对根节点html的字体大小来计算
- % 一般来说就是相对于父元素
- vh 视窗高度,1vh等于视窗高度的1%
- vw 视窗宽度,1vw等于视窗宽度的1%
6.uniapp如何监听页面滚动?
使用 onPageScroll 监听
7.如何让图片宽度不变,高度自动变化,保持原图宽高比不变?
给image标签添加 mode='widthFix'
8.uni-app的优缺点
优点:
- 一套代码可以生成多端
- 学习成本低,语法是vue的,组件是小程序的
- 拓展能力强
- 使用HBuilderX开发,支持vue语法
- 突破了系统对H5条用原生能力的限制
缺点:
- 问世时间短,很多地方不完善
- 社区不大
- 官方对问题的反馈不及时
- 在Android平台上比微信小程序和iOS差
- 文件命名受限
9.分别写出jQuery、vue、小程序、uni-app中的本地存储数据和接受数据是什么?
jQuery
存:$.cookie('key','value')
取:$.cookie('key')
vue
存储:localstorage.setItem(‘key’,‘value’)
接收:localstorage.getItem(‘key’)
微信小程序
存储:通过wx.setStorage/wx.setStorageSync写数据到缓存
接收:通过wx.getStorage/wx.getStorageSync读取本地缓存,
uni-app
存储:uni.setStorage({key:“属性名”,data:“值”})
接收:uni.getStorage({key:“属性名”,success(e){e.data//这就是你想要取的token}})
10.jq、vue、uni-app、小程序的页面传参方式
jq传参
通过url拼接参数进行传参。
vue传参
vue可以通过标签router-link跳转传参,通过path+路径,query+参数
也可以通过事件里的this.$router.push({})跳转传参
小程序传参
通过跳转路径后面拼接参数来进行跳转传参
11.vue , 微信小程序 , uni-app绑定变量属性
vue和uni-app动态绑定一个变量的值为元素的某个属性的时候,会在属性前面加上冒号":";
小程序绑定某个变量的值为元素属性时,会用两个大括号{{}}括起来,如果不加括号,为被认为是字符串。
12.vue,小程序,uni-app的生命周期
vue
1. beforeCreate(创建前)
2. created(创建后)
3. beforeMount(载入前),(挂载)
4. mounted(载入后)
5. beforeUpdate(更新前)
6. updated(更新后)
7. beforeDestroy(销毁前)
8. destroyed(销毁后)
小程序/uni-app
1. onLoad:首次进入页面加载时触发,可以在 onLoad 的参数中获取打开当前页面路径中的参数。
2. onShow:加载完成后、后台切到前台或重新进入页面时触发
3. onReady:页面首次渲染完成时触发
4. onHide:从前台切到后台或进入其他页面触发
5. onUnload:页面卸载时触发
6. onPullDownRefresh:监听用户下拉动作
7. onReachBottom:页面上拉触底事件的处理函数
8. onShareAppMessage:用户点击右上角转发
webpack&git
1.对webpack的理解?
webpack 是一个用于现代 JavaScript 应用程序的静态模块打包工具。我们可以使用webpack管理模块。因为在webpack看来,项目中的所有资源皆为模块,通过分析模块间的依赖关系,在其内部构建出一个依赖图,最终编绎输出模块为 HTML、JavaScript、CSS 以及各种静态文件(图片、字体等),让我们的开发过程更加高效。

webpack的主要作用如下:
模块打包。可以将不同模块的文件打包整合在一起,并且保证它们之间的引用正确,执行有序。利用打包我们就可以在开发的时候根据我们自己的业务自由划分文件模块,保证项目结构的清晰和可读性。编译兼容。在前端的“上古时期”,手写一堆浏览器兼容代码一直是令前端工程师头皮发麻的事情,而在今天这个问题被大大的弱化了,通过webpack的Loader机制,不仅仅可以帮助我们对代码做polyfill,还可以编译转换诸如.less,.vue,.jsx这类在浏览器无法识别的格式文件,让我们在开发的时候可以使用新特性和新语法做开发,提高开发效率。能力扩展。通过webpack的Plugin机制,我们在实现模块化打包和编译兼容的基础上,可以进一步实现诸如按需加载,代码压缩等一系列功能,帮助我们进一步提高自动化程度,工程效率以及打包输出的质量。
2.webpack的构建流程?
webpack的运行流程是一个串行的过程,从启动到结束会依次执行以下流程:
初始化参数:从配置文件和 Shell 语句中读取与合并参数,得出最终的参数开始编译:用上一步得到的参数初始化 Compiler 对象,加载所有配置的插件,执行对象的 run 方法开始执行编译确定入口:根据配置中的 entry 找出所有的入口文件编译模块:从入口文件出发,调用所有配置的 loader 对模块进行翻译,再找出该模块依赖的模块,再递归本步骤直到所有入口依赖的文件都经过了本步骤的处理完成模块编译:在经过上一步使用 loader 翻译完所有模块后,得到了每个模块被翻译后的最终内容以及它们之间的依赖关系输出资源:根据入口和模块之间的依赖关系,组装成一个个包含多个模块的 Chunk,再把每个 Chunk 转换成一个单独的文件加入到输出列表,这步是可以修改输出内容的最后机会输出完成:在确定好输出内容后,根据配置确定输出的路径和文件名,把文件内容写入到文件系统
在以上过程中,webpack会在特定的时间点广播出特定的事件,插件在监听到感兴趣的事件后会执行特定的逻辑,并且插件可以调用webpack提供的 API 改变webpack的运行结果。
简单说:
- 初始化:启动构建,读取与合并配置参数,加载 Plugin,实例化 Compiler
- 编译:从 entry 出发,针对每个 Module 串行调用对应的 loader 去翻译文件的内容,再找到该 Module 依赖的 Module,递归地进行编译处理
- 输出:将编译后的 Module 组合成 Chunk,将 Chunk 转换成文件,输出到文件系统中
3.常见的loader有哪些?
默认情况下,webpack只支持对js和json文件进行打包,但是像css、html、png等其他类型的文件,webpack则无能为力。因此,就需要配置相应的loader进行文件内容的解析转换。
常用的loader如下:
image-loader:加载并且压缩图片文件。less-loader: 加载并编译 LESS 文件。sass-loader:加载并编译 SASS/SCSS 文件。css-loader:加载 CSS,支持模块化、压缩、文件导入等特性,使用css-loader必须要配合使用style-loader。style-loader:用于将 CSS 编译完成的样式,挂载到页面的 style 标签上。需要注意 loader 执行顺序,style-loader 要放在第一位,loader 都是从后往前执行。babel-loader:把 ES6 转换成 ES5postcss-loader:扩展 CSS 语法,使用下一代 CSS,可以配合 autoprefixer 插件自动补齐 CSS3 前缀。eslint-loader:通过 ESLint 检查 JavaScript 代码。vue-loader:加载并编译 Vue 组件。file-loader:把文件输出到一个文件夹中,在代码中通过相对 URL 去引用输出的文件 (处理图片和字体)url-loader:与 file-loader 类似,区别是用户可以设置一个阈值,大于阈值会交给 file-loader 处理,小于阈值时返回文件 base64 形式编码 (处理图片和字体)
4.常见的plugin有哪些?
webpack中的plugin赋予其各种灵活的功能,例如打包优化、资源管理、环境变量注入等,它们会运行在webpack的不同阶段(钩子 / 生命周期),贯穿了webpack整个编译周期。目的在于解决 loader 无法实现的其他事。
常用的plugin如下:
HtmlWebpackPlugin:简化 HTML 文件创建 (依赖于 html-loader)mini-css-extract-plugin: 分离样式文件,CSS 提取为独立文件,支持按需加载 (替代extract-text-webpack-plugin)clean-webpack-plugin: 目录清理
5.loader和plugin的区别?
loader是文件加载器,能够加载资源文件,并对这些文件进行一些处理,诸如编译、压缩等,最终一起打包到指定的文件中;plugin赋予了webpack各种灵活的功能,例如打包优化、资源管理、环境变量注入等,目的是解决 loader无法实现的其他事。
在运行时机上,loader 运行在打包文件之前;plugin则是在整个编译周期都起作用。
在配置上,loader在module.rules中配置,作为模块的解析规则,类型为数组。每一项都是一个 Object,内部包含了 test(类型文件)、loader、options (参数)等属性;plugin在 plugins中单独配置,类型为数组,每一项是一个 plugin 的实例,参数都通过构造函数传入。
6.webpack的热更新原理是?
模块热替换(HMR - hot module replacement),又叫做热更新,在不需要刷新整个页面的同时更新模块,能够提升开发的效率和体验。热更新时只会局部刷新页面上发生了变化的模块,同时可以保留当前页面的状态,比如复选框的选中状态等。
热更新的核心就是客户端从服务端拉去更新后的文件,准确的说是 chunk diff (chunk 需要更新的部分),实际上webpack-dev-server与浏览器之间维护了一个websocket,当本地资源发生变化时,webpack-dev-server会向浏览器推送更新,并带上构建时的hash,让客户端与上一次资源进行对比。客户端对比出差异后会向webpack-dev-server发起 Ajax 请求来获取更改内容(文件列表、hash),这样客户端就可以再借助这些信息继续向webpack-dev-server发起 jsonp 请求获取该chunk的增量更新。
后续的部分(拿到增量更新之后如何处理?哪些状态该保留?哪些又需要更新?)由HotModulePlugin 来完成,提供了相关 API 以供开发者针对自身场景进行处理,像react-hot-loader和vue-loader都是借助这些 API 实现热更新。
7.如何提高webpack的构建速度?
-
代码压缩
-
JS压缩
webpack 4.0默认在生产环境的时候是支持代码压缩的,即mode=production模式下。 实际上webpack 4.0默认是使用terser-webpack-plugin这个压缩插件,在此之前是使用 uglifyjs-webpack-plugin,两者的区别是后者对 ES6 的压缩不是很好,同时我们可以开启 parallel参数,使用多进程压缩,加快压缩。
-
CSS压缩
CSS 压缩通常是去除无用的空格等,因为很难去修改选择器、属性的名称、值等。可以使用另外一个插件:css-minimizer-webpack-plugin。
-
HTML压缩
使用HtmlWebpackPlugin插件来生成 HTML 的模板时候,通过配置属性minify进行 html 优化。
module.exports = {
plugin:[
new HtmlwebpackPlugin({
minify:{
minifyCSS: false, // 是否压缩css
collapseWhitespace: false, // 是否折叠空格
removeComments: true // 是否移除注释
}
})
]
}
-
图片压缩
配置image-webpack-loader
-
Tree Shaking
Tree Shaking是一个术语,在计算机中表示消除死代码,依赖于ES Module的静态语法分析(不执行任何的代码,可以明确知道模块的依赖关系)。 在webpack实现Tree shaking有两种方案:
-
usedExports:通过标记某些函数是否被使用,之后通过 Terser 来进行优化的
module.exports = {
...
optimization:{
usedExports
}
}
使用之后,没被用上的代码在webpack打包中会加入unused harmony export mul注释,用来告知Terser在优化时,可以删除掉这段代码。
-
sideEffects:跳过整个模块/文件,直接查看该文件是否有副作用sideEffects:跳过整个模块/文件,直接查看该文件是否有副作用
sideEffects用于告知webpack compiler哪些模块时有副作用,配置方法是在package.json中设置sideEffects属性。如果sideEffects设置为false,就是告知webpack可以安全的删除未用到的exports。如果有些文件需要保留,可以设置为数组的形式,如:
"sideEffecis":[
"./src/util/format.js",
"*.css" *// 所有的css文件*
]
4.缩小打包域
排除webpack不需要解析的模块,即在使用loader的时候,在尽量少的模块中去使用。可以借助 include和exclude这两个参数,规定loader只在那些模块应用和在哪些模块不应用。
5.减少ES6转为ES5的冗余代码
使用bable-plugin-transform-runtime插件
6.提取公共代码
通过配置CommonsChunkPlugin插件,将多个页面的公共代码抽离成单独的文件
8.git是什么?git的五个命令,git和svn的区别
git是什么
1. git是目前世界上最先进的分布式管理系统。
git的常用命令
1. git init 把这个目录变成git可以管理的仓库
2. git add README.md 文件添加到仓库
3. git add 不但可以跟单一文件,也可以跟通配符,更可以跟目录。一个点就把当前目录下所有未追踪的文件全部add了
4. git commit -m ‘first commit’把文件提交到仓库
5. git remote add origin git@github.com:wangjiax9/practice.git //关联远程仓库
6. git push -u origin master //把本地库的所有内容推送到远程库上
Git和SVN的区别
1. Git是分布式版本控制工具 , SVN是集中式版本控制工具
2. Git没有一个全局的版本号,而SVN有。
3. Git和SVN的分支不同
4. git吧内容按元数据方式存储,而SVN是按文件
5. Git内容的完整性要优于SVN
6. Git无需联网就可使用(无需下载服务端),而SVN必须要联网(须下载服务端)因为git的版本区就在自己电脑上,而svn在远程服务器上。
9. Git项目如何配置,如何上传至GitHub。描述其详细步骤
1. 注册登录github
2. 创建github仓库
3. 安装git客户端
4. 绑定用户信息
5. 设置ssh key
6. 创建本地项目以及仓库
7. 关联github仓库
8. 推送项目到github仓库
10.常用命令
- 初始化一个仓库:git init
- 查看分支:git branch
- 将已修改或未跟踪的文件添加到暂存区:git add [file] 或 git add .
- 提交至本地仓库:git commit -m “提及记录xxxx”
- 本地分支推送至远程分支:git push
- 查看当前工作目录和暂存区的状态: git status
- 查看提交的日志记录: git log
- 从远程分支拉取代码:git pull
- 合并某分支(xxx)到当前分支: git merge xxx
- 切换到分支xxx:git checkout xxx
- 创建分支xxx并切换到该分支:git checkout -b xxx
- 删除分支xxx:git branch -d xxx
- 将当前分支到改动保存到堆栈中:git stash
- 恢复堆栈中缓存的改动内容:git stash pop
11.git merge 和git rebase的区别?
相同点:
git merge和git rebase两个命令都⽤于从⼀个分⽀获取内容并合并到当前分⽀。
不同点:
git merge会⾃动创建⼀个新的commit,如果合并时遇到冲突的话,只需要修改后重新commit。
- 优点:能记录真实的
commit情况,包括每个分⽀的详情
- 缺点:由于每次
merge会⾃动产⽣⼀个commit,因此在使用⼀些可视化的git工具时会看到这些自动产生的commit,这些commit对于程序员来说没有什么特别的意义,多了反而会影响阅读。
git rebase会合并之前的commit历史。
- 优点:可以得到更简洁的提交历史,去掉了merge 产生的
commit
- 缺点:因为合并而产生的代码问题,就不容易定位,因为会重写提交历史信息
场景:
- 当需要保留详细的合并信息,建议使⽤
git merge, 尤其是要合并到master上
- 当发现⾃⼰修改某个功能时提交比较频繁,并觉得过多的合并记录信息对自己来说没有必要,那么可尝试使用
git rebase
12.对GitFlow的理解?
GitFlow重点解决的是由于源代码在开发过程中的各种冲突导致开发活动混乱的问题。重点是对各个分支的理解。
master:主分支。develop:主开发分支,平行于master分支。feature:功能分支,必须从develop分支建立,开发完成后合并到develop分支。release:发布分支,发布的时候用,一般测试时候发现的 bug 在该分支进行修复。从develop分支建立,完成后合并回develop与master分支。hotfix:紧急修复线上bug使用,必须从master分支建立,完成后合并回develop与master分支。
��������
你可能感兴趣的:(vue.js,javascript,前端,vue,react.js)