代码搜索技巧
在IDE中搜索代码时,经常会被相近的无关代码干扰,如筛选所有使用协程的代码段,
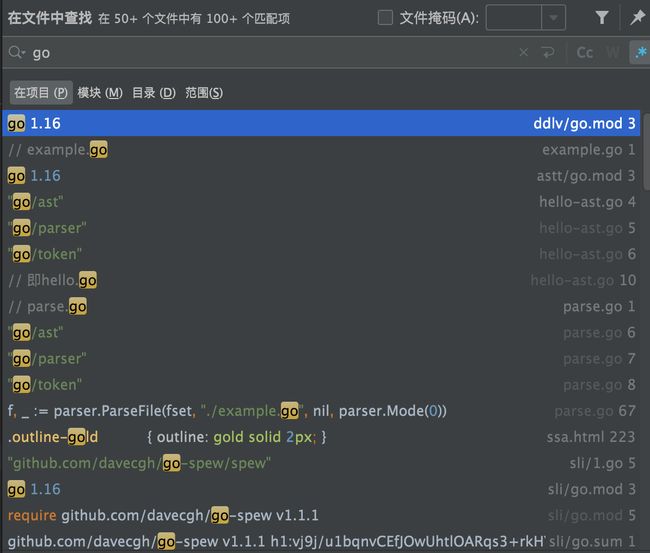
可见有大量“噪音”。
可使用IDE提供的正则表达式功能
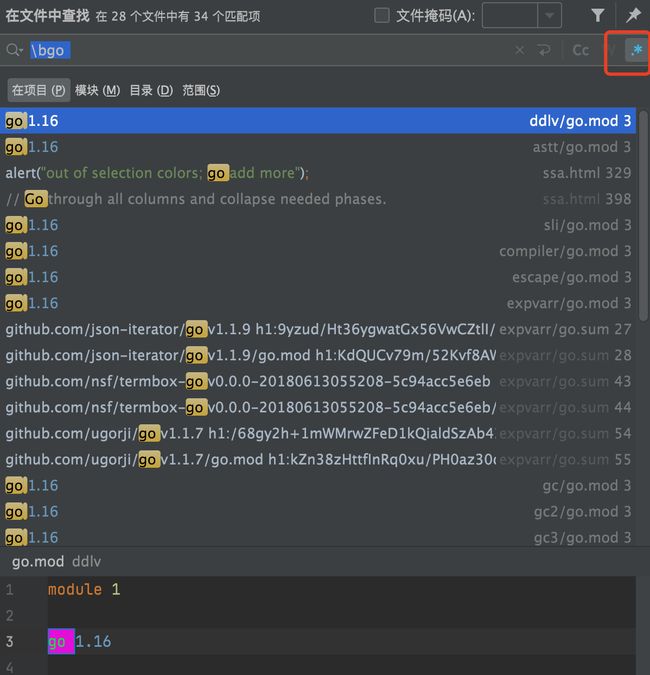
如 使用 \bgo ,即匹配go开头的,且之后为空格的所有选项
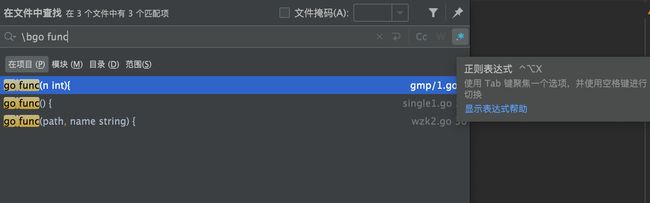
使用 \bgo func,即匹配到了所有使用协程的代码段
IDE还提供了常用正则表达式语法:
Summary of regular-expression constructs
Construct Matches
Characters
x The character x
\\ The backslash character
\0n The character with octal value 0n (0 <= n <= 7)
\0nn The character with octal value 0nn (0 <= n <= 7)
\0mnn The character with octal value 0mnn (0 <= m <= 3, 0 <= n <= 7)
\xhh The character with hexadecimal value 0xhh
\uhhhh The character with hexadecimal value 0xhhhh
\t The tab character ('\u0009')
\n The newline (line feed) character ('\u000A')
\r The carriage-return character ('\u000D')
\f The form-feed character ('\u000C')
\a The alert (bell) character ('\u0007')
\e The escape character ('\u001B')
\cx The control character corresponding to x
Character classes
[abc] a, b, or c (simple class)
[^abc] Any character except a, b, or c (negation)
[a-zA-Z] a through z or A through Z, inclusive (range)
[a-d[m-p]] a through d, or m through p: [a-dm-p] (union)
[a-z&&[def]] d, e, or f (intersection)
[a-z&&[^bc]] a through z, except for b and c: [ad-z] (subtraction)
[a-z&&[^m-p]] a through z, and not m through p: [a-lq-z(subtraction)
Predefined character classes
. Any character (may or may not match line terminators)
\d A digit: [0-9]
\D A non-digit: [^0-9]
\s A whitespace character: [ \t\n\x0B\f\r]
\S A non-whitespace character: [^\s]
\w A word character: [a-zA-Z_0-9]
\W A non-word character: [^\w]
POSIX character classes (US-ASCII only)
\p{Lower} A lower-case alphabetic character: [a-z]
\p{Upper} An upper-case alphabetic character:[A-Z]
\p{ASCII} All ASCII:[\x00-\x7F]
\p{Alpha} An alphabetic character:[\p{Lower}\p{Upper}]
\p{Digit} A decimal digit: [0-9]
\p{Alnum} An alphanumeric character:[\p{Alpha}\p{Digit}]
\p{Punct} Punctuation: One of !"#$%&'()*+,-./:;=>?@[\]^_`{|}~
\p{Graph} A visible character: [\p{Alnum}\p{Punct}]
\p{Print} A printable character: [\p{Graph}\x20]
\p{Blank} A space or a tab: [ \t]
\p{Cntrl} A control character: [\x00-\x1F\x7F]
\p{XDigit} A hexadecimal digit: [0-9a-fA-F]
\p{Space} A whitespace character: [ \t\n\x0B\f\r]
java.lang.Character classes (simple java character type)
\p{javaLowerCase} Equivalent to java.lang.Character.isLowerCase()
\p{javaUpperCase} Equivalent to java.lang.Character.isUpperCase()
\p{javaWhitespace} Equivalent to java.lang.Character.isWhitespace()
\p{javaMirrored} Equivalent to java.lang.Character.isMirrored()
Classes for Unicode blocks and categories
\p{InGreek} A character in the Greek block (simple block)
\p{Lu} An uppercase letter (simple category)
\p{Sc} A currency symbol
\P{InGreek} Any character except one in the Greek block (negation)
[\p{L}&&[^\p{Lu}]] Any letter except an uppercase letter (subtraction)
Boundary matchers
^ The beginning of a line
$ The end of a line
\b A word boundary
\B A non-word boundary
\A The beginning of the input
\G The end of the previous match
\Z The end of the input but for the final terminator, if any
\z The end of the input
Greedy quantifiers
X? X, once or not at all
X* X, zero or more times
X+ X, one or more times
X{n} X, exactly n times
X{n,} X, at least n times
X{n,m} X, at least n but not more than m times
Reluctant quantifiers
X?? X, once or not at all
X*? X, zero or more times
X+? X, one or more times
X{n}? X, exactly n times
X{n,}? X, at least n times
X{n,m}? X, at least n but not more than m times
Possessive quantifiers
X?+ X, once or not at all
X*+ X, zero or more times
X++ X, one or more times
X{n}+ X, exactly n times
X{n,}+ X, at least n times
X{n,m}+ X, at least n but not more than m times
Logical operators
XY X followed by Y
X|Y Either X or Y
(X) X, as a capturing group
Back references
\n Whatever the nth capturing group matched
Quotation
\ Nothing, but quotes the following character
\Q Nothing, but quotes all characters until \E
\E Nothing, but ends quoting started by \Q
Special constructs (non-capturing)
(?:X) X, as a non-capturing group
(?idmsux-idmsux) Nothing, but turns match flags on - off
(?idmsux-idmsux:X) X, as a non-capturing group with the given flags on - off
(?=X) X, via zero-width positive lookahead
(?!X) X, via zero-width negative lookahead
(?<=X) X, via zero-width positive lookbehind
(?(?>X) X, as an independent, non-capturing group
More on Regular Expressions: Full Java Regular Expressions syntax description, Using Regular Expressions in Java.
每一行都是正则表达式中的一个构造方法及其对应的匹配规则的简要说明,解释如下:
- Characters:用于匹配单个字符的正则表达式构造方法,例如 x 匹配字符 x。
- Character classes:用于匹配一组字符中的任意一个字符的正则表达式构造方法,例如 [\d] 匹配所有的数字。
- Predefined character classes:已经预定义好的字符类,例如 \s 匹配所有的空格字符。
- POSIX character classes (US-ASCII only):根据 POSIX 规范定义的字符类,与预定义字符类类似。
- java.lang.Character classes:对 Java 字符类型的封装,例如 \p{javaLowerCase} 匹配所有的小写字母。
- Classes for Unicode blocks and categories:用于匹配 Unicode 块和类的正则表达式构造方法,例如 \p{InGreek} 匹配属于希腊字符集的字符。
- Boundary matchers:用于匹配文本边界的正则表达式构造方法,例如 ^ 匹配字符串开头。
- Greedy quantifiers:用于指定重复次数的正则表达式构造方法,例如 X* 匹配 X 重复 0 或多次。
- Reluctant quantifiers:与贪婪量词相似,但是会尽可能地匹配更少的字符,例如 X*? 只匹配到 X 出现的第一个位置。
- Possessive quantifiers:与贪婪量词相似,但是不会后退以找到更好的匹配,例如 X*+ 会匹配连续出现的所有 X。
- Logical operators:用于将多个子表达式组合在一起的正则表达式构造方法,例如 X|Y 匹配 X 或 Y。
- Back references:用于引用分组的内容的正则表达式构造方法,例如 \1 表示匹配分组 1 中的内容。
- Quotation:转义字符和引号的正则表达式构造方法。
- Special constructs (non-capturing):一些没有捕获子表达式的正则表达式构造方法,例如 (?:X) 表示匹配但不捕获 X。
Character classes
[abc] a, b, or c (simple class) [^abc] Any character except a, b, or c (negation) [a-zA-Z] a through z or A through Z, inclusive (range) [a-d[m-p]] a through d, or m through p: [a-dm-p] (union) [a-z&&[def]] d, e, or f (intersection) [a-z&&[^bc]] a through z, except for b and c: [ad-z] (subtraction) [a-z&&[^m-p]] a through z, and not m through p: [a-lq-z(subtraction) 中文 这些都是正则表达式中的字符类,用于在字符串中匹配某些特定的字符:
- [abc] 匹配单个字符为 "a"、"b" 或 "c"。
- [^abc] 匹配单个字符不为 "a"、"b" 或 "c" 的任何字符。
- [a-zA-Z] 匹配单个字母字符,包括小写和大写字母。
- [a-d[m-p]] 匹配单个字符为 "a"、"b"、"c"、"d"、"m"、"n"、"o" 或 "p" 中的任意一个。
- [a-z&&[def]] 匹配单个字符为 "d"、"e" 或 "f" 中的任意一个。
- [a-z&&[^bc]] 匹配单个字符为从 "a" 到 "z" 中的任意一个字母,但不包括 "b" 和 "c"。
- [a-z&&[^m-p]] 匹配单个字符为从 "a" 到 "z" 中的任意一个字母,但不包括从 "m" 到 "p" 的字母。
本文由 mdnice 多平台发布