用户端Web自动化测试-L2
目录:
- 高级定位-css
- 高级定位-xpath
- 显式等待高级使用
- 高级控件交互方法
- 网页 frame 与多窗口处理
- 文件上传,弹框处理
- 自动化关键数据记录
- 电子商务产品实战
-
测试人论坛搜索功能实战
1.高级定位-css
css 选择器概念
- css 选择器有自己的语法规则和表达式
- css 定位通常分为绝对定位和相对定位
- 和Xpath一起常用于UI自动化测试中的元素定位
CSS 常用的选择器_常用选择器_阿瞒有我良计15的博客-CSDN博客
css 定位场景
- 支持web产品
- 支持app端的webview
css 相对定位的优点
- 可维护性更强
- 语法更加简洁
- 解决各种复杂的定位场景
# 绝对定位
$("#ember63 > td.main-link.clearfix.topic-list-data > span > span > a")
# 相对定位
$("#ember63 [title='新话题']")css 定位的调试方法
- 进入浏览器的console
- 输入:
$("css表达式")- 或者
$$("css表达式")
css基础语法
| 类型 | 表达式 |
|---|---|
| 标签 | 标签名 |
| 类 | .class属性值 |
| ID | #id属性值 |
| 属性 | [属性名='属性值'] |
//在console中的写法
// https://www.baidu.com/
//标签名
$('input')
//.类属性值
$('.s_ipt')
//#id属性值
$('#kw')
//[属性名='属性值']
$('[name="wd"]')css关系定位
| 类型 | 格式 |
|---|---|
| 并集 | 元素,元素 |
| 邻近兄弟(了解即可) | 元素+元素 |
| 兄弟(了解即可) | 元素1~元素2 |
| 父子 | 元素>元素 |
| 后代 | 元素 元素 |
//在console中的写法
//元素,元素
$('.bg,.s_ipt_wr,.new-pmd,.quickdelete-wrap')
//元素+元素,了解即可
$('.soutu-btn+input')
//元素1~元素2,了解即可
$('.soutu-btn~i')
//元素>元素
$('#s_kw_wrap>input')
//元素 元素
$('#form input')
css 顺序关系
| 类型 | 格式 |
|---|---|
| 父子关系+顺序 | 元素 元素 |
| 父子关系+标签类型+顺序 | 元素 元素 |
//:nth-child(n)
$('#form>input:nth-child(2)')
//:nth-of-type(n)
$('#form>input:nth-of-type(1)')2.高级定位-xpath
xpath基本概念
- XPath 是一门在 XML 文档中查找信息的语言
- XPath 使用路径表达式在 XML 文档中进行导航
- XPath 的应用非常广泛
- XPath 可以应用在UI自动化测试
xpath 定位场景
- web自动化测试
- app自动化测试
xpath 相对定位的优点
- 可维护性更强
- 语法更加简洁
- 相比于css可以支持更多的方式

# 复制的绝对定位
$x('//*[@id="ember75"]/td[1]/span/a')
# 编写的相对行为
$x("//*[text()='技术分享 | SeleniumIDE用例录制']")xpath 定位的调试方法
- 浏览器-console
$x("xpath表达式")
- 浏览器-elements
- ctrl+f 输入xpath或者css
xpath 基础语法(包含关系)
| 表达式 | 结果 |
|---|---|
| / | 从该节点的子元素选取 |
| // | 从该节点的子孙元素选取 |
| * | 通配符 |
| nodename | 选取此节点的所有子节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
# 整个页面
$x("/")
# 页面中的所有的子元素
$x("/*")
# 整个页面中的所有元素
$x("//*")
# 查找页面上面所有的div标签节点
$x("//div")
# 查找id属性为site-logo的节点
$x('//*[@id="site-logo"]')
# 查找节点的父节点
$x('//*[@id="site-logo"]/..')xpath 顺序关系(索引)
- xpath通过索引直接获取对应元素
# 获取此节点下的所有的li元素
$x("//*[@id='ember21']//li")
# 获取此节点下【所有的节点的】第一个li元素
$x("//*[@id='ember21']//li[1]")xpath 高级用法
[last()]: 选取最后一个[@属性名='属性值' and @属性名='属性值']: 与关系[@属性名='属性值' or @属性名='属性值']: 或关系[text()='文本信息']: 根据文本信息定位[contains(text(),'文本信息')]: 根据文本信息包含定位- 注意:所有的表达式需要和
[]结合
# 选取最后一个input标签
//input[last()]
# 选取属性name的值为passward并且属性pwd的值为123456的input标签
//input[@name='passward' and @pwd='123456']
# 选取属性name的值为passward或属性pwd的值为123456的input标签
//input[@name='passward' or @pwd='123456']
# 选取所有文本信息为'hello world'的元素
//*[text()='hello world']
# 选取所有文本信息包'hello'的元素
//*[contains(text(),'hello')]3.显式等待高级使用
显式等待原理
- 在代码中定义等待一定条件发生后再进一步执行代码
- 在最长等待时间内循环执行结束条件的函数
- WebDriverWait(driver 实例, 最长等待时间, 轮询时间).until(结束条件函数)

显式等待-expected_conditions
- Selenium 显式等待官网说明
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
def test_wait_until():
driver = webdriver.Chrome()
driver.get("https://vip.ceshiren.com/#/ui_study")
WebDriverWait(driver, 10, 0.5).until(expected_conditions.element_to_be_clickable((By.CSS_SELECTOR, '#success_btn')))
driver.find_element(By.CSS_SELECTOR, "#success_btn").click()
常见 expected_conditions
| 类型 | 示例方法 | 说明 |
|---|---|---|
| element | element_to_be_clickable() visibility_of_element_located() |
针对于元素,比如判断元素是否可以点击,或者元素是否可见 |
| url | url_contains() | 针对于 url |
| title | title_is() | 针对于标题 |
| frame | frame_to_be_available_and_switch_to_it(locator) | 针对于 frame |
| alert | alert_is_present() | 针对于弹窗 |
显式等待-封装等待条件
- 官方的 excepted_conditions 不可能覆盖所有场景
- 定制封装条件会更加灵活、可控
显式等待-封装等待条件
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions
class TestWebdriverWait:
def setup(self):
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.driver.implicitly_wait(5)
self.driver.get("https://vip.ceshiren.com/#/ui_study")
def teardown(self):
self.driver.quit()
def test_wait_until(self):
WebDriverWait(self.driver, 10, 0.5).until(
expected_conditions.element_to_be_clickable((By.CSS_SELECTOR, '#success_btn')))
self.driver.find_element(By.CSS_SELECTOR, "#success_btn").click()
def test_webdriver_wait(self):
# 解决的问题:有的按钮点击一次没有反应,可能要点击多次,比如企业微信的添加成员
# 解决的方案:一直点击按钮,直到下个页面出现,封装成显式等待的一个条件
def muliti_click(button_element, until_ele):
# 函数封装
def inner(driver):
# 封装点击方法
driver.find_element(By.XPATH, button_element).click()
return driver.find_element(By.XPATH, until_ele)
return inner
time.sleep(5)
# 在限制时间内会一直点击按钮,直到展示弹框
WebDriverWait(self.driver, 10).until(muliti_click("//*[text()='点击两次响应']", "//*[text()='该弹框点击两次后才会弹出']"))
time.sleep(5)
4.高级控件交互方法
| 使用场景 | 对应事件 |
|---|---|
| 复制粘贴 | 键盘事件 |
| 拖动元素到某个位置 | 鼠标事件 |
| 鼠标悬停 | 鼠标事件 |
| 滚动到某个元素 | 滚动事件 |
| 使用触控笔点击 | 触控笔事件(了解即可) |
官网:
https://www.selenium.dev/documentation/webdriver/actions_api
ActionChains解析
- 实例化类ActionChains,参数为driver实例。
- 中间可以有多个操作。
.perform()代表确定执行。
ActionChains(self.driver).操作.perform()键盘事件
- 按下、释放键盘键位
- 结合send_keys回车
- Keyboard actions | Selenium
键盘事件-使用shift实现大写
ActionChains(self.driver): 实例化ActionChains类key_down(Keys.SHIFT, ele): 按下shift键实现大写send_keys("selenium"): 输入大写的seleniumperform(): 确认执行
代码示例:
import time
from selenium import webdriver
from selenium.webdriver import ActionChains, Keys
from selenium.webdriver.common.by import By
class TestKeyBoardDemo:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
def teardown_class(self):
self.driver.quit()
def test_key_down_up(self):
self.driver.get("https://ceshiren.com/")
self.driver.find_element(By.ID, "search-button").click()
ele = self.driver.find_element(By.ID, "search-term")
ActionChains(self.driver).key_down(Keys.SHIFT, ele).send_keys("selenium").perform()
time.sleep(2)键盘事件-输入后回车
- 直接输入回车: 元素.send_keys(Keys.ENTER)
- 使用ActionChains: key_down(Keys.ENTER)
代码示例:
import time
from selenium import webdriver
from selenium.webdriver import ActionChains, Keys
from selenium.webdriver.common.by import By
class TestKeyBoardDemo:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
def teardown_class(self):
self.driver.quit()
def test_key_down_up(self):
self.driver.get("https://ceshiren.com/")
self.driver.find_element(By.ID, "search-button").click()
ele = self.driver.find_element(By.ID, "search-term")
ActionChains(self.driver).key_down(Keys.SHIFT, ele).send_keys("selenium").perform()
time.sleep(2)
def test_enter_by_send_keys(self):
self.driver.get("https://www.sogou.com/")
ele = self.driver.find_element(By.ID, "query")
ele.send_keys("selenium")
# 第一种方式
# ele.send_keys(Keys.ENTER)
# 第二种方式
ActionChains(self.driver).key_down(Keys.ENTER).perform()
time.sleep(3)
键盘事件-复制粘贴
- 多系统兼容
- mac 的复制按钮为 COMMAND
- windows 的复制按钮为 CONTROL
- 左箭头:
Keys.ARROW_LEFT - 按下COMMAND或者CONTROL:
key_down(cmd_ctrl) - 按下剪切与粘贴按钮:
send_keys("xvvvvv")
import sys
import time
from selenium import webdriver
from selenium.webdriver import ActionChains, Keys
from selenium.webdriver.common.by import By
class TestKeyBoardDemo:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
def teardown_class(self):
self.driver.quit()
def test_key_down_up(self):
self.driver.get("https://ceshiren.com/")
self.driver.find_element(By.ID, "search-button").click()
ele = self.driver.find_element(By.ID, "search-term")
ActionChains(self.driver).key_down(Keys.SHIFT, ele).send_keys("selenium").perform()
time.sleep(2)
def test_enter_by_send_keys(self):
self.driver.get("https://www.sogou.com/")
ele = self.driver.find_element(By.ID, "query")
ele.send_keys("selenium")
# 第一种方式
# ele.send_keys(Keys.ENTER)
# 第二种方式
ActionChains(self.driver).key_down(Keys.ENTER).perform()
time.sleep(3)
def test_copy_and_paste(self):
self.driver.get("https://ceshiren.com/")
cmd_ctrl = Keys.COMMAND if sys.platform == 'darwin' else Keys.CONTROL
self.driver.find_element(By.ID, "search-button").click()
ele = self.driver.find_element(By.ID, "search-term")
# 打开搜索,选择搜索框,输入selenium,剪切后复制,几个v就代表复制几次
ActionChains(self.driver) \
.key_down(Keys.SHIFT, ele) \
.send_keys("Selenium!") \
.send_keys(Keys.ARROW_LEFT) \
.send_keys(Keys.ARROW_LEFT) \
.send_keys(Keys.ARROW_LEFT) \
.key_down(cmd_ctrl) \
.send_keys("xvvvvv") \
.key_up(cmd_ctrl) \
.perform()
time.sleep(10)
鼠标事件
- 双击
- 拖动元素
- 指定位置(悬浮)
- Mouse actions | Selenium
鼠标事件-双击
double_click(元素对象): 双击元素
代码示例:
import time
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
class TestMouseDemo:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
def teardown_class(self):
self.driver.quit()
def test_double_click(self):
# 演练环境
self.driver.get("https://vip.ceshiren.com/#/ui_study")
ele = self.driver.find_element(By.ID, "primary_btn")
ActionChains(self.driver).double_click(ele).perform()
time.sleep(2)
鼠标事件-拖动元素
drag_and_drop(起始元素对象, 结束元素对象): 拖动并放开元素
代码示例:
import time
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
class TestMouseDemo:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
def teardown_class(self):
self.driver.quit()
def test_double_click(self):
# 演练环境
self.driver.get("https://vip.ceshiren.com/#/ui_study")
ele = self.driver.find_element(By.ID, "primary_btn")
ActionChains(self.driver).double_click(ele).perform()
time.sleep(2)
def test_drag_and_drop(self):
self.driver.get("https://vip.ceshiren.com/#/ui_study/action_chains")
item_left = self.driver.find_element(By.CSS_SELECTOR, '#item1')
item_right = self.driver.find_element(By.CSS_SELECTOR, '#item3')
ActionChains(self.driver).drag_and_drop(item_left, item_right).perform()
time.sleep(5)
鼠标事件-悬浮(下拉框)
move_to_element(元素对象): 移动到某个元素
import time
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
class TestMouseDemo:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
def teardown_class(self):
self.driver.quit()
def test_double_click(self):
# 演练环境
self.driver.get("https://vip.ceshiren.com/#/ui_study")
ele = self.driver.find_element(By.ID, "primary_btn")
ActionChains(self.driver).double_click(ele).perform()
time.sleep(2)
def test_drag_and_drop(self):
self.driver.get("https://vip.ceshiren.com/#/ui_study/action_chains")
item_left = self.driver.find_element(By.CSS_SELECTOR, '#item1')
item_right = self.driver.find_element(By.CSS_SELECTOR, '#item3')
ActionChains(self.driver).drag_and_drop(item_left, item_right).perform()
time.sleep(5)
def test_hover(self):
self.driver.get("https://vip.ceshiren.com/#/ui_study/action_chains2")
time.sleep(2)
title = self.driver.find_element(By.CSS_SELECTOR, '.title')
ActionChains(self.driver).move_to_element(title).perform()
options = self.driver.find_element(By.CSS_SELECTOR, '.options>div:nth-child(3)')
ActionChains(self.driver).click(options).perform()
time.sleep(5)
滚轮/滚动操作
- 滚动到元素
- 根据坐标滚动
- 注意: selenium 版本需要在 4.2 之后
- Scroll wheel actions | Selenium
滚轮/滚动操作-滚动到元素
scroll_to_element(WebElement对象):滚动到某个元素
代码示例:
import time
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
class TestScrollDemo:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
def teardown_class(self):
self.driver.quit()
def test_scoll_to_element(self):
# 演练环境
self.driver.get("https://ceshiren.com")
# 4.2 之后才提供这个方法
time.sleep(2)
ele = self.driver.find_element(By.XPATH, "//*[text()='性能测试的目的']")
ActionChains(self.driver).scroll_to_element(ele).perform()
time.sleep(2)
滚轮/滚动操作-根据坐标滚动
import time
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
class TestScrollDemo:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
def teardown_class(self):
self.driver.quit()
def test_scoll_to_element(self):
# 演练环境
self.driver.get("https://ceshiren.com")
# 4.2 之后才提供这个方法
time.sleep(2)
ele = self.driver.find_element(By.XPATH, "//*[text()='性能测试的目的']")
ActionChains(self.driver).scroll_to_element(ele).perform()
time.sleep(2)
def test_scroll_to_amount(self):
# 演练环境
self.driver.get("https://ceshiren.com/")
# 4.2 之后才提供这个方法
ActionChains(self.driver).scroll_by_amount(0, 10000).perform()
time.sleep(2)
5.网页 frame 与多窗口处理
- selenium⾥⾯如何处理多窗口场景
- 多个窗⼜识别
- 多个窗⼜之间切换
- selenium⾥⾯如何处理frame
- 多个frame识别
- 多个frame之间切换
多窗口处理
- 点击某些链接,会重新打开⼀个窗口,对于这种情况,想在新页⾯上操作,就得先切换窗口了。
- 获取窗口的唯⼀标识⽤句柄表⽰,所以只需要切换句柄,就可以在多个页⾯灵活操作了。
多窗口处理流程
- 先获取到当前的窗⼜句柄(driver.current_window_handle)
- 再获取到所有的窗⼜句柄(driver.window_handles)
- 判断是否是想要操作的窗⼜,如果是,就可以对窗⼜进⾏操作,如果不是,跳转到另外⼀个窗⼜,对另⼀个窗⼜进⾏操作(driver.switch_to_window)
多窗⼜切换案例
- 打开百度页⾯
- 点击登录,
- 弹框中点击‘⽴即注册’,输⼊⽤户名和帐号
- 返回刚才的登录页,点击登录
- 输⼊⽤户名和密码,点击登录
base.py
from selenium import webdriver
class Base():
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
def teardown_class(self):
self.driver.quit()
test_window.py
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from web_automation_testing.test_keyboard_incident.base import Base
class TestWindow(Base):
def test_window(self):
self.driver.get("https://www.baidu.com")
self.driver.find_element(By.LINK_TEXT, "登录").click()
print(self.driver.current_window_handle)
print(self.driver.window_handles)
self.driver.find_element(By.XPATH,'//*[@id="TANGRAM__PSP_11__regLink"]').click()
print(self.driver.current_window_handle)
print(self.driver.window_handles)
windows = self.driver.window_handles
self.driver.switch_to.window(windows[-1])
self.driver.find_element(By.CSS_SELECTOR,'#TANGRAM__PSP_4__userName').send_keys("username")
self.driver.find_element(By.CSS_SELECTOR,'#TANGRAM__PSP_4__phone').send_keys("password")
time.sleep(2)
self.driver.switch_to.window(windows[0])
self.driver.find_element(By.CSS_SELECTOR,'#TANGRAM__PSP_11__userName').send_keys("username")
self.driver.find_element(By.CSS_SELECTOR,'#TANGRAM__PSP_11__password').send_keys("password")
time.sleep(5)
frame介绍
- 在web⾃动化中,如果⼀个元素定位不到,那么很⼤可能是在iframe中。
- 什么是frame?
- frame是html中的框架,在html中,所谓的框架就是可以在同⼀个浏览器中显⽰不⽌⼀个页⾯。
- 基于html的框架,又分为垂直框架和⽔平框架(cols,rows)
- Frame分类
- frame标签包含frameset、frame、iframe三种,
- frameset和普通的标签⼀样,不会影响正常的定位,可以使⽤index、id、name、webelement任意种⽅式定位frame。
- ⽽frame与iframe对selenium定位⽽⾔是⼀样的。selenium有⼀组⽅法对frame进⾏操作
多frame切换
- frame存在两种:
- ⼀种是嵌套的,⼀种是未嵌套的
- 切换frame
- driver.switch_to.frame() #根据元素id或者index切换切换frame
- driver.switch_to.default_content() #切换到默认frame
- driver.switch_to.parent_frame() #切换到⽗级frame
frame未嵌套
- 处理未嵌套的iframe
- driver.switch_to_frame(“frame的id”)
- driver.switch_to_frame(“frame - index”) frame⽆ID的时候依据索引来处理,索引从0开始driver.switch_to_frame(0)
Frame嵌套
- 处理嵌套的iframe
- 对于嵌套的先进⼊到iframe的⽗节点,再进到⼦节点,然后可以对⼦节点⾥⾯的对象进⾏处理和操作
- driver.switch_to.frame(“⽗节点”)
- driver.switch_to.frame(“⼦节点”)
多frame切换案例
- 多frame切换案例:
- 打开包含frame的web页⾯菜鸟教程在线编辑器
- 打印’请拖拽我’元素的⽂本
- 打印’点击运⾏’元素的⽂本
base.py
from selenium import webdriver
class Base():
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
def teardown_class(self):
self.driver.quit()
test_frame.py
from selenium.webdriver.common.by import By
from web_automation_testing.test_keyboard_incident.base import Base
class TestFrame(Base):
def test_frame(self):
self.driver.get("https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable")
self.driver.switch_to.frame("iframeResult")
print(self.driver.find_element(By.ID,'draggable').text)
self.driver.switch_to.parent_frame()
print(self.driver.find_element(By.ID, "submitBTN").text)
6.文件上传,弹框处理
- ⽂件上传的⾃动化
- 弹框处理机制
⽂件上传
- input标签可以直接使⽤send_keys(⽂件地址)上传⽂件
- ⽤法:
- el = driver.find_element_by_id('上传按钮id')
- el.send_keys(”⽂件路径+⽂件名")
⽂件上传实例
- 测试案例:
- 打开百度图⽚⽹址:https://image.baidu.com
- 识别上传按钮
- 点击上传按钮
- 将本地的图⽚⽂件上传
base.py
from selenium import webdriver
class Base():
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
def teardown_class(self):
self.driver.quit()
test_file.py
import time
from selenium.webdriver.common.by import By
from web_automation_testing.test_keyboard_incident.base import Base
class TestFile(Base):
def test_up_file(self):
self.driver.get("https://image.baidu.com/")
self.driver.find_element(By.CSS_SELECTOR,'#sttb > img.st_camera_off').click()
self.driver.find_element(By.ID,'stfile').send_keys("E:\pictures\water.png")
time.sleep(5)
chrome开启debug模式
有时候登录⽅式⽐较繁琐,需要动态⼿机密码,⼆维码登录之类的。⾃动话实现⽐较⿇烦。⼿⼯登录后,不想让selenium启动⼀个新浏览器。可以使⽤chrome的debug⽅式来执⾏测试。
- 启动chrome的时候需要先退出所有chrome进程。使⽤ps aux|grep chrome|grep -v 'grep'查看是否有chrome进程存在。确保没有chrome进程被启动过。
- 正常启动chrome的debug模式
- #默认macOS系统
- /Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome --remote-debugging-port=9222
- # Windows下找到chrome.exe位置执⾏下⾯的命令
- chrome.exe --remote-debugging-port=9222
- #默认macOS系统
启动后的提⽰信息,代表chrome运⾏正常,不要关闭⾃动打开的chrome窗口。
弹框处理机制
- 在页⾯操作中有时会遇到JavaScript所⽣成的alert、confirm以及prompt弹框,可以使⽤switch_to.alert()⽅法定位到。然后使⽤text/accept/dismiss/send_keys等⽅法进⾏操作。参考教你分辨alert、window、div模态框,以及操作
- 操作alert常⽤的⽅法:
- switch_to.alert():获取当前页⾯上的警告框。
- text:返回alert/confirm/prompt中的⽂字信息。
- accept():接受现有警告框。
- dismiss():解散现有警告框。
- send_keys(keysToSend):发送⽂本⾄警告框。keysToSend:将⽂本发送⾄警告框。
alert窗⼜处理案例
- 测试案例:
- 打开⽹页https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable
- 操作窗⼜右侧页⾯,将元素1拖拽到元素2
- 这时候会有⼀个alert弹框,点击弹框中的’确定
- 然后再按’点击运⾏
- 关闭⽹页
base.py
from selenium import webdriver
class Base():
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
def teardown_class(self):
self.driver.quit()
test_alert.py
import time
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from web_automation_testing.test_keyboard_incident.base import Base
class TestAlert(Base):
def test_alert(self):
self.driver.get("https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable")
self.driver.switch_to.frame("iframeResult")
drag = self.driver.find_element(By.ID, "draggable")
drop = self.driver.find_element(By.ID, "droppable")
action = ActionChains(self.driver)
action.drag_and_drop(drag, drop).perform()
time.sleep(2)
self.driver.switch_to.alert.accept()
self.driver.switch_to.default_content()
self.driver.find_element(By.ID, "submitBTN").click()
time.sleep(3)
7.自动化关键数据记录
什么是关键数据?
- 代码的执行日志
- 代码执行的截图
- page source(页面源代码)
记录关键数据的作用
| 内容 | 作用 |
|---|---|
| 日志 | 1. 记录代码的执行记录,方便复现场景 2. 可以作为bug依据 |
| 截图 | 1. 断言失败或成功截图 2.异常截图达到丰富报告的作用 3. 可以作为bug依据 |
| page source | 1. 协助排查报错时元素当时是否存在页面上 |
行为日志记录
- 日志配置
- 脚本日志级别
- debug记录步骤信息
- info记录关键信息,比如断言等
代码示例:
from selenium import webdriver
from selenium.webdriver.common.by import By
from web_automation_testing.test_key_data.utils.log_util import logger
class TestDataRecord:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
def teardown_class(self):
self.driver.quit()
def test_log_data_record(self):
# 实例化self.driver
search_content = "海贼王"
# 打开百度首页
self.driver.get("https://www.sogou.com/")
logger.debug("打开搜狗首页")
# 输入海贼王
self.driver.find_element(By.CSS_SELECTOR, "#query").send_keys(search_content)
logger.debug(f"搜索的内容为{search_content}")
# 点击搜索
self.driver.find_element(By.CSS_SELECTOR, "#stb").click()
# 搜索结果
search_res = self.driver.find_element(By.ID, "sogou_vr_70060202_title_0")
logger.info(f"搜索结果为{search_res.text}")
assert search_res.text == search_content步骤截图记录
save_screenshot(截图路径+名称)- 记录关键页面
- 断言页面
- 重要的业务场景页面
- 容易出错的页面
from selenium import webdriver
from selenium.webdriver.common.by import By
from web_automation_testing.test_key_data.utils.log_util import logger
class TestDataRecord:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
def teardown_class(self):
self.driver.quit()
def test_log_data_record(self):
# 实例化self.driver
search_content = "海贼王"
# 打开百度首页
self.driver.get("https://www.sogou.com/")
logger.debug("打开搜狗首页")
# 输入海贼王
self.driver.find_element(By.CSS_SELECTOR, "#query").send_keys(search_content)
logger.debug(f"搜索的内容为{search_content}")
# 点击搜索
self.driver.find_element(By.CSS_SELECTOR, "#stb").click()
# 搜索结果
search_res = self.driver.find_element(By.ID, "sogou_vr_70060202_title_0")
logger.info(f"搜索结果为{search_res.text}")
assert search_res.text == search_content
def test_screenshot_record(self):
# 实例化self.driver
search_content = "海贼王"
# 打开百度首页
self.driver.get("https://www.sogou.com/")
logger.debug("打开搜狗首页")
# 输入海贼王
self.driver.find_element(By.CSS_SELECTOR, "#query").send_keys(search_content)
logger.debug(f"搜索的内容为{search_content}")
# 点击搜索
self.driver.find_element(By.CSS_SELECTOR, "#stb").click()
# 搜索结果
search_res = self.driver.find_element(By.ID, "sogou_vr_70060202_title_0")
logger.info(f"搜索结果为{search_res.text}")
self.driver.save_screenshot("./datas/screenshot/search_res.png")
assert search_res.text == search_contentpage_source记录
- 使用page_source属性获取页面源码
- 在调试过程中,如果有找不到元素的错误可以保存当时的page_source调试代码
from selenium import webdriver
from selenium.webdriver.common.by import By
from web_automation_testing.test_key_data.utils.log_util import logger
class TestDataRecord:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
def teardown_class(self):
self.driver.quit()
def test_log_data_record(self):
# 实例化self.driver
search_content = "海贼王"
# 打开百度首页
self.driver.get("https://www.sogou.com/")
logger.debug("打开搜狗首页")
# 输入海贼王
self.driver.find_element(By.CSS_SELECTOR, "#query").send_keys(search_content)
logger.debug(f"搜索的内容为{search_content}")
# 点击搜索
self.driver.find_element(By.CSS_SELECTOR, "#stb").click()
# 搜索结果
search_res = self.driver.find_element(By.ID, "sogou_vr_70060202_title_0")
logger.info(f"搜索结果为{search_res.text}")
assert search_res.text == search_content
def test_screenshot_record(self):
# 实例化self.driver
search_content = "海贼王"
# 打开百度首页
self.driver.get("https://www.sogou.com/")
logger.debug("打开搜狗首页")
# 输入海贼王
self.driver.find_element(By.CSS_SELECTOR, "#query").send_keys(search_content)
logger.debug(f"搜索的内容为{search_content}")
# 点击搜索
self.driver.find_element(By.CSS_SELECTOR, "#stb").click()
# 搜索结果
search_res = self.driver.find_element(By.ID, "sogou_vr_70060202_title_0")
logger.info(f"搜索结果为{search_res.text}")
self.driver.save_screenshot("./datas/screenshot/search_res.png")
assert search_res.text == search_content
def test_page_source_record(self):
# 实例化self.driver
search_content = "海贼王"
# 打开百度首页
self.driver.get("https://www.sogou.com/")
logger.debug("打开搜狗首页")
with open("./datas/page_source/record.html", "w", encoding="utf8") as f:
f.write(self.driver.page_source)
8.电子商务产品实战
产品分析:
- 产品:litemall管理后台
- 功能:商品类目
- 使用账户
- 用户名: manage
- 密码: manage123
litemall
测试用例分析
| 用例标题 | 前提条件 | 用例步骤 | 预期结果 | 实际结果 |
|---|---|---|---|---|
| 添加商品类目 | 1. 登录并进入用户管理后台 2. 登录账号有商场管理的权限 |
1. 点击增加 2. 输入类目名称 3. 点击确定 |
1. 跳转商品类目列表 2. 新增在最后一行,新增成功 |
|
| 删除商品类目 | 1. 进入用户管理后台 2. 商品列表里面有已存在的商品(新增) |
1. 点击删除按钮 | 1. 是否有删除成功提示 2. 被删除商品不在商品类目列表展示 |
编写脚本思路:
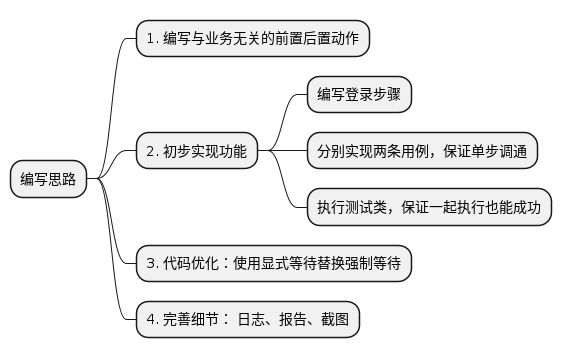
前置后置
- 在setup_class打开浏览器
- teardown_class关闭浏览器进程
- 添加隐式等待配置
test_litemall.py
import time
import allure
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from web_automation_testing.test_litemall.utils.log_util import logger
class TestLitemall:
# 前置动作
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
# 登录
self.driver.get("http://litemall.hogwarts.ceshiren.com/")
# 问题,输入框内有默认值,此时send——keys不回清空只会追加
# 解决方案: 在输入信息之前,先对输入框完成清空
# 输入用户名密码
self.driver.find_element(By.NAME, "username").clear()
self.driver.find_element(By.NAME, "username").send_keys("manage")
self.driver.find_element(By.NAME, "password").clear()
self.driver.find_element(By.NAME, "password").send_keys("manage123")
# 点击登录按钮
self.driver.find_element(By.CSS_SELECTOR, ".el-button--primary").click()
# 窗口最大化
self.driver.maximize_window()
# 后置动作
def teardown_class(self):
self.driver.quit()
def get_screen(self):
timestamp = int(time.time())
# 注意:!! 一定要提前创建好images 路径
image_path = f"./datas/screenshot/image_{timestamp}.PNG"
# 截图
self.driver.save_screenshot(image_path)
# 讲截图放到报告的数据中
allure.attach.file(image_path, name="picture",attachment_type=allure.attachment_type.PNG)
# 新增功能
def test_add_type(self):
# 点击商场管理/商品类目,进入商品类目页面
# 进入商品类目页面
self.driver.find_element(By.XPATH, "//*[text()='商场管理']").click()
self.driver.find_element(By.XPATH, "//*[text()='商品类目']").click()
# 添加商品类目操作
self.driver.find_element(By.XPATH, "//*[text()='添加']").click()
self.driver.find_element(By.CSS_SELECTOR, ".el-input__inner").send_keys("新增商品测试")
# ===============使用显式等待优化
# ele = WebDriverWait(self.driver,10).until(
# expected_conditions.element_to_be_clickable(
# (By.CSS_SELECTOR, ".dialog-footer .el-button--primary")))
# ele.click()
# ==============显示等待优化方案2: 自定义显式等待条件
def click_exception(by, element, max_attempts=5):
def _inner(driver):
# 多次点击按钮
actul_attempts = 0 # 实际点击次数
while actul_attempts < max_attempts:
# 进行点击操作
actul_attempts += 1 # 每次循环,实际点击次数加1
try:
# 如果点击过程报错,则直接执行 except 逻辑,并切继续循环
# 没有报错,则直接return 循环结束
driver.find_element(by, element).click()
return True
except Exception:
logger.debug("点击的时候出现了一次异常")
# 当实际点击次数大于最大点击次数时,结束循环并抛出异常
raise Exception("超出了最大点击次数")
# return _inner() 错误写法
return _inner
WebDriverWait(self.driver, 10).until(click_exception(By.CSS_SELECTOR, ".dialog-footer .el-button--primary"))
# ===========================使用显式等待优化
# self.driver.find_element(By.CSS_SELECTOR, ".dialog-footer .el-button--primary").click()
# finds 如果没找到会返回空列表, find 如果没找到则会直接报错
# 如果没找到,程序也不应该报错
res = self.driver.find_elements(By.XPATH, "//*[text()='新增商品测试']")
self.get_screen()
# 数据的清理一定到放在断言操作之后完成,要不然可能会影响断言结果
self.driver.find_element(By.XPATH, "//*[text()='新增商品测试']/../..//*[text()='删除']").click()
logger.info(f"断言获取到的实际结果为{res}")
# 断言产品新增后是否成功找到,如果找到,证明新增成功,如果没找到则新增失败
# 判断查找的结果是否为空列表,如果为空列表证明没找到,反之代表元素找到,用例执行成功
assert res != []
# 删除功能
def test_delete_type(self):
# ================ 造数据步骤
# 点击商场管理/商品类目,进入商品类目页面
# 进入商品类目页面
self.driver.find_element(By.XPATH, "//*[text()='商场管理']").click()
self.driver.find_element(By.XPATH, "//*[text()='商品类目']").click()
# 添加商品类目操作
self.driver.find_element(By.XPATH, "//*[text()='添加']").click()
self.driver.find_element(By.CSS_SELECTOR, ".el-input__inner").send_keys("删除商品测试")
ele = WebDriverWait(self.driver, 10).until(
expected_conditions.element_to_be_clickable(
(By.CSS_SELECTOR, ".dialog-footer .el-button--primary")))
ele.click()
# ============完成删除步骤
self.driver.find_element(By.XPATH, "//*[text()='删除商品测试']/../..//*[text()='删除']").click()
# 断言: 删除之后获取这个 删除商品测试的 这个商品类目是否还能获取到,如果获取到,证明没有删除成功,反之删除成功
WebDriverWait(self.driver, 10).until_not(
expected_conditions.visibility_of_any_elements_located((By.XPATH, "//*[text()='删除商品测试']")))
# 问题: 因为代码执行速度过快,元素还未消失就捕获了。
# 解决: 确认该元素不存在后,再捕获
res = self.driver.find_elements(By.XPATH, "//*[text()='删除商品测试']")
logger.info(f"断言获取到的实际结果为{res}")
assert res == []
目录结构:

9.测试人论坛搜索功能实战
项目简介
ceshiren 论坛是一个面向测试人员的社区论坛,主要讨论软件测试、自动化测试、性能测试等方面的话题。它的目标是为测试从业者提供一个交流学习的平台,分享测试经验、解决问题、探讨新技术和趋势等。论坛的搜索功能能够根据用户的搜索词汇和上下文,智能推测用户真正需要的结果。它能够自动匹配相关词汇和拼写错误,并提供相关的搜索建议。
被测产品地址:https://ceshiren.com/
具体操作内容:
- 要求实现搜索功能的Web自动化测试。
- Selenium 常用操作与用例编写。
- 使用显式等待优化代码。
- 考虑特殊场景的验证。
- 输入内容过长。
- 特殊字符。
- 其他。
- 使用参数化优化代码。
- 步骤截图。
场景描述
-
打开测试人论坛,截图。
-
跳转到高级搜索页面,添加显式等待判断页面跳转成功并截图。
-
搜索输入框输入搜索关键字,截图。关键字清单如下:
Selenium Appium 面试 -
打印当前结果页面的pagesource并截图。
-
打印搜索结果的第一个标题。
-
断言:第一个标题是否包含关键字。
代码示例:template: 用来存放开发模版 - Gitee.com
项目结构:
test_ceshiren_forum_search.py
import os
import time
import allure
import pytest
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from web_automation_testing.test_ceshiren_forum_search.utils.deserialization_util import Utils
from web_automation_testing.test_ceshiren_forum_search.utils.log_util import logger
# 从文件中获取测试用例
def get_datas(level):
root_path = os.path.dirname(os.path.abspath(__file__))
# print(root_path)
yaml_path = os.sep.join([root_path, 'datas\\doc\\search.yaml'])
# print(yaml_path)
yaml_datas = Utils.get_yaml_data(yaml_path)
# print(yaml_datas)
datas = yaml_datas.get('search').get(level).get('datas')
return datas
class TestSearch():
def setup_method(self, method):
# 实例化chromedriver
self.driver = webdriver.Chrome()
# 添加全局隐式等待
self.driver.implicitly_wait(5)
self.driver.maximize_window()
def teardown_method(self, method):
# 关闭driver
self.driver.quit()
# 截图
def get_screenshot(self):
timestamp = int(time.time())
img_path = f"./datas/screenshot/image_{timestamp}.png"
self.driver.save_screenshot(img_path)
allure.attach.file(img_path, name="picture", attachment_type=allure.attachment_type.PNG)
# pagesource
def get_page_source(self):
timestamp = int(time.time())
page_source_path = f"./datas/pagesource/page_source_{timestamp}.html"
with open(page_source_path, 'w', encoding='utf8') as f:
f.write(self.driver.page_source)
allure.attach.file(page_source_path, name="pagesource", attachment_type=allure.attachment_type.TEXT)
@pytest.mark.parametrize('param', get_datas("P0"))
def test_search(self, param):
self.driver.get('https://ceshiren.com/search')
logger.info(f'打开测试人论坛')
input_field = self.driver.find_element(By.CSS_SELECTOR, "[placeholder='搜索']")
input_field.send_keys(param)
WebDriverWait(self.driver, 10).until(
expected_conditions.element_to_be_clickable((By.CSS_SELECTOR, '.search-cta')))
search_button = self.driver.find_element(By.CSS_SELECTOR, '.search-cta')
search_button.click()
time.sleep(1)
logger.info(f'搜索{param}完毕')
self.get_page_source()
self.get_screenshot()
title_first = self.driver.find_element(By.CSS_SELECTOR, '.topic-title')
print(title_first.text)
assert param.lower() in title_first.text.lower()
@pytest.mark.parametrize('param', get_datas("P1"))
def test_search_the_input_is_too_long(self, param):
self.driver.get('https://ceshiren.com/search')
logger.info(f'打开测试人论坛')
input_field = self.driver.find_element(By.CSS_SELECTOR, "[placeholder='搜索']")
input_field.send_keys(param)
WebDriverWait(self.driver, 10).until(
expected_conditions.element_to_be_clickable((By.CSS_SELECTOR, '.search-cta')))
search_button = self.driver.find_element(By.CSS_SELECTOR, '.search-cta')
search_button.click()
time.sleep(1)
logger.info(f'搜索{param}完毕')
self.get_page_source()
self.get_screenshot()
title_first = self.driver.find_element(By.CSS_SELECTOR, '.no-results-suggestion')
print(title_first.text)
assert "找不到您要找的内容?" in title_first.text
@pytest.mark.parametrize('param', get_datas("P2"))
def test_search_special_characters(self, param):
self.driver.get('https://ceshiren.com/search')
logger.info(f'打开测试人论坛')
input_field = self.driver.find_element(By.CSS_SELECTOR, "[placeholder='搜索']")
input_field.send_keys(param)
WebDriverWait(self.driver, 10).until(
expected_conditions.element_to_be_clickable((By.CSS_SELECTOR, '.search-cta')))
search_button = self.driver.find_element(By.CSS_SELECTOR, '.search-cta')
search_button.click()
time.sleep(1)
logger.info(f'搜索{param}完毕')
self.get_page_source()
self.get_screenshot()
title_first = self.driver.find_element(By.CSS_SELECTOR, '.no-results-suggestion')
print(title_first.text)
assert "找不到您要找的内容?" in title_first.text
具体源码去我的gitee上看.....