数据结构复习总结
数据结构复习总结 ———南昌理工ACM集训队
- 栈与队列
-
- 单调栈
- 单调队列
- 字典树(tire树)
- 并查集
-
- 扩展域并查集
- 带权值并查集
- 哈希表
-
- 一般哈希
- 字符串哈希
栈与队列
单调栈
栈是STL库中非常实用的一个容器,它具有先入后出的性质。而单调栈为了满足单调的要求,增加了一个性质: 从栈顶到栈底的元素是严格递增(or递减)
----对于单调递增栈,若当前进栈元素为e,从栈顶开始遍历元素,把小于e或者等于e的元素弹出栈,直接遇到一个大于e的元素或者栈为空为止,然后再把e压入栈中。
----对于单调递减栈,则每次弹出的是大于e或者等于e的元素。
常见模型:找出每个数左边离它最近的比它大/小的数
int tt = 0;
for (int i = 1; i <= n; i ++ )
{
while (tt && check(stk[tt], i)) tt -- ;
stk[ ++ tt] = i;
}
单调队列
对于单调队列,从单调栈的性质我们可以类推出:从队列头到队列尾的元素是严格递增
----对于单调递增队列,设当前准备入队的元素为e,从队尾开始把队列中的元素逐个与e对比,把比e大或者与e相等的元素逐个删除,直到遇到一个比e小的元素或者队列为空为止,然后把当前元素e插入到队尾。
----对于单调递减队列也是同样道理,只不过从队尾删除的是比e小或者与e相等的元素。
常见模型:找出滑动窗口中的最大值/最小值
int hh = 0, tt = -1;
for (int i = 0; i < n; i ++ )
{
while (hh <= tt && check_out(q[hh])) hh ++ ; // 判断队头是否滑出窗口
while (hh <= tt && check(q[tt], i)) tt -- ;
q[ ++ tt] = i;
}
字典树(tire树)
tire树的核心思想是用空间换时间,即处理字符串的公共前缀来降低查询时所费时间提高查询效率。
基本性质
----根节点不包含字符,除根节点外的每一个子节点都包含一个字符
从根节点到某一节点。路径上经过的字符连接起来,就是该节点对应的字符串
----每个节点的所有子节点包含的字符都不相同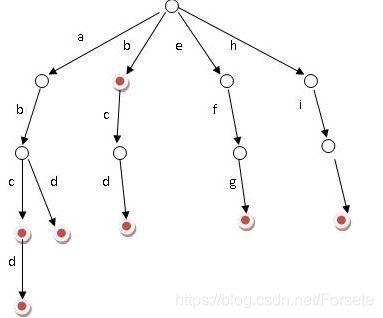
应用场景
统计字符串出现的个数
#include 并查集
并查集是一种树型的数据结构,用于处理一些不相交集合的合并及查询问题(即所谓的并、查)。比如说,我们可以用并查集来判断一个森林中有几棵树、某个节点是否属于某棵树等。
find()函数
首先要定义一个数组:int f [ ] 。这个数组记录了每个元素的父结点是谁。比如说 f [16] = 6 就表示16号元素的父结点是6号。如果一个元素的父结点就是他自己,那说明他就是根结点了,查找到此结束。也有一个元素自及组成一个集合的,那么这个集合的根结点就是自己。
int find(int x) //查找x的根结点
{
if(f[x] != x) //如果x的父结点不是自己
x = find(f[x); //路径压缩,把在x前面的结点的父节点都更新成根结点
return f[x];
} // 函数返回 x 的根结点
扩展域并查集
并查集擅长的是动态维护图中具有传递性的关系。有的时候,我们需要传递的关系比较单一,但有的时候,传递的关系会比较复杂。这时候就需要用到并查集的扩展域。
例题:食物链
#include 带权值并查集
普通的并查集仅仅记录的是集合的关系,这个关系无非是同属一个集合或者是不在一个集合。而带权并查集,不仅记录集合的关系,还记录着集合内元素的关系或者说是元素连接线的权值。
例题:银河英雄传说
//238.银河英雄传说
#include 哈希表
哈希表(Hash Table)也叫散列表,是根据关键码值而直接进行访问的数据结构。它通过把关键码值映射到哈希表中的一个位置来访问记录,以加快查找的速度。这个映射函数就做散列函数,存放记录的数组叫做散列表。
思路:
以数据中每个元素的关键字K为自变量,通过散列函数H(k)计算出函数值,以该函数值作为一块连续存储空间的的单元地址,将该元素存储到函数值对应的单元中。
一般哈希
常用的哈希方法:
- 开放寻址法
int hash(int x)
{
int t = (x % N + N) % N;
while (h[t] != null && h[t] != x) // h【t】不为空,且 值不等于 x
{ // 说明该位置有其他数 ,有冲突 , 往后延一位
t ++ ;
if (t == N) t = 0;
}
return t;// 返回 x 的哈希值
}
- 拉链法
void insert(int x)
{
int k = (x % N + N) % N; //哈希值对应下标,存储的是原值
e[idx] = x;
ne[idx] = h[k];
h[k] = idx ++ ;
}
字符串哈希
将一个字符串转化成一个整数,并保证字符串不同,得到的哈希值不同,这样就可以用来判断一个该字串是否重复出现过。
核心思想:
将字符串看成P进制数,P的经验值是131或13331,取这两个值的冲突概率低
小技巧:
取模的数用2^64,这样直接用unsigned long long存储,溢出的结果就是取模的结果
核心代码如下:
typedef unsigned long long ULL;
ULL h[N], p[N]; // h[k]存储字符串前k个字母的哈希值, p[k]存储 P^k mod 2^64
// 初始化
p[0] = 1;
for (int i = 1; i <= n; i ++ )
{
h[i] = h[i - 1] * P + str[i];
p[i] = p[i - 1] * P;
}
// 计算子串 str[l ~ r] 的哈希值
ULL get(int l, int r)
{
return h[r] - h[l - 1] * p[r - l + 1];
}
例题:判断两字符串是否相等
// 快速比较两个字符串是否相等
#include 感谢观看~