Spring Bean生命周期的源码分析(超级详细)

文章目录
- 一. 问题背景
- 二. 储备知识
- 三. 问题引入
-
- 3.1 循环依赖
- 3.2 对循环依赖的分析
- 3.3 两个小结论
- 3.4 验证两个小结论
- 四. Spring如何创建一个Bean
-
- 4.1 预备知识
- 4.2 Java对象和Spring对象的产生过程的区别:
- 4.3 BeanDefinition对象是什么
-
- 4.3.1 BeanDefinition对象存了什么
- 4.4 Spring bean的实例化过程
-
- 4.4.1 总体概览图
- 4.4.2 细节过程图
- 4.5 实现简单的Spring扩展
- 4.6 初步debug分析spring实例化bean的步骤在哪里
- 4.7 总结spring bean生命周期过程大概过程
- 4.8 属性注入
-
- 4.8.1 回顾
- 4.8.2 搭建代码
- 4.8.3 debug分析属性注入
- 4.8.4 总结
- 4.9 Spring如何解决循环依赖的?
-
- 4.9.1 回顾
- 4.9.2 代码
- 4.9.3 debug分析Spring如何解决循环依赖
- 4.9.4 总结
- 4.10 解决循环依赖的3个map
-
- 4.10.1 3个map的作用
- 4.10.2 为什么要有三级缓存?(即第三个map存在的原因是什么)
- 4.10.3 为什么第二个map存的是factory(即存工厂,而不是对象)?
-
- 4.10.3.1 引入后面验证分析需要用到的知识(储备知识)
- 4.10.3.2 代码
- 4.10.3.3 分析以及验证
- 4.11 再次分析属性注入
- 4.12 分析InitializeBean()(即分析生命周期的回调方法)
-
- 4.12.1 生命周期的回调方法的三种方式
- 4.12.2 InitializeBean()里面的实现
- 4.13 spring bean完整生命周期总结
- 4.14 面试题:为什么需要3级缓存?
一. 问题背景
遇到面试题“Spring Bean的生命周期是怎么样?”,很多网上的博客博文都有总结性的阐述,但是笔者想知道是从哪里开始切入到Spring Bean的生命周期,从什么时候开始,从哪句代码开始研究。因此今天研究一下Spring源码分析Spring Bean的生命周期。
此笔记仅供自己参考,如有错误请指正
参考自:
- 请别再问Spring Bean的生命周期了!
- 【spring源码全集】B站唯一阿里P8级别的架构师教程
笔者建议:若是第一次接触Spring Bean的生命周期,可以先参考第一篇文章请别再问Spring Bean的生命周期了!。然后想要继续深入研究可以参考【spring源码全集】B站唯一阿里P8级别的架构师教程
二. 储备知识
在此之前我们需要对spring bean的生命周期有一个大概了解,后面源码分析时才进行细致分类,现在粗略地认知它有4个阶段:(大概了解有初步认识即可,无需背下来。这是方便后面理解源码作准备)
- 实例化(Instantiation)
- 属性赋值(Populate)
- 初始化(Initialization)
- 销毁(Destruction)
三. 问题引入
从循环依赖情景引入Spring Bean的生命周期。首先搭建循环依赖的场景。搭建好后再作分析以及小总结。
3.1 循环依赖
情景:2个类分别为IndexService和UserService。IndexService类中有属性UserService;UserService类中有属性IndexService。 这种彼此之间都有彼此的属性,属于循环依赖情况。
搭建循环依赖场景,工程目录结构如下:
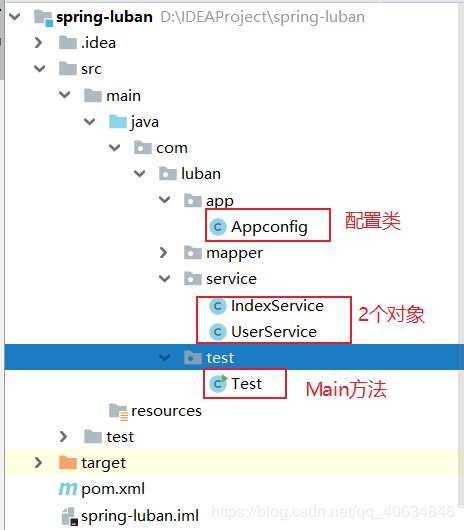
工程pom文件依赖(主要是spring的一些核心依赖:core、aop、context、txt)如下:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.lubangroupId>
<artifactId>spring-lubanartifactId>
<version>1.0-SNAPSHOTversion>
<dependencies>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.0version>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-beansartifactId>
<version>4.0.0.RELEASEversion>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-contextartifactId>
<version>4.0.0.RELEASEversion>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-context-supportartifactId>
<version>4.0.0.RELEASEversion>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-aopartifactId>
<version>4.0.0.RELEASEversion>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-coreartifactId>
<version>4.0.0.RELEASEversion>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-expressionartifactId>
<version>4.0.0.RELEASEversion>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-testartifactId>
<version>4.3.5.RELEASEversion>
dependency>
dependencies>
project>
代码如下:
UserService.java
package com.luban.service;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class UserService {
@Autowired
IndexService indexService;
public UserService(){
System.out.println("Constructor from userService");
}
}
IndexService.java
package com.luban.service;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class IndexService {
@Autowired
UserService userService;
public IndexService(){
System.out.println("Constructor from indexService");
}
public void getService(){ //为了测试是否装配了userService
System.out.println(userService);
}
}
Appconfig.java
package com.luban.app;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
@Configuration
@ComponentScan("com.luban")
public class Appconfig {
}
Test.java
package com.luban.test;
import com.luban.app.Appconfig;
import com.luban.service.IndexService;
import com.luban.service.UserService;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
public class Test {
public static void main(String[] args) {
AnnotationConfigApplicationContext ac =
new AnnotationConfigApplicationContext(Appconfig.class);
ac.getBean(IndexService.class).getService();
}
}
结果如下:
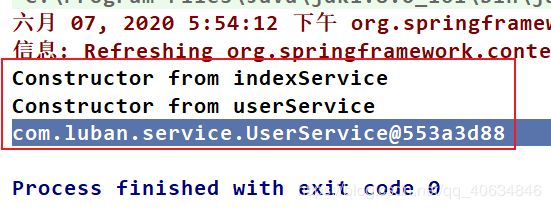
3.2 对循环依赖的分析
上面代码中,IndexService中有UserService属性,UserService中有IndexService属性,2者互相依赖,但是Spring却没有报错,能正常将属性装配好并实例化对象。即spring循环依赖,也就是属性注入的问题,即依赖注入(DI,Denpendency Injection)。
因此研究Spring Bean生命周期的切入点分析:spring是怎么解决循环依赖的?->即需要知道spring怎么实现依赖注入的?->即首先要知道依赖注入是什么时候发生的->就要知道spring bean的生命周期->就要知道spring是怎么实例化一个对象的
3.3 两个小结论
为了能更加容易理解,在此首先给出结论,让大家有一个总体宏观的架构印象。后面会进行验证
结论1:依赖注入是在spring bean生命周期的其中一个步骤完成的。而spring bean生命周期是在IOC容器初始化的时候完成的。比如spring bean生命周期有1,2,3,…,N,N个步骤。依赖注入在其中的一个步骤(比如在第3步,只是打个比方)。
结论2:初始化的顺序是,IOC容器首先会被spring内部初始化,IOC容器初始化的过程中,会有spring bean的初始化(即spring bean的生命周期),依赖注入就在spring bean生命周期的一个步骤。
3.4 验证两个小结论
代码如下:
UserService.java
package com.luban.service;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class UserService {
@Autowired
IndexService indexService;
public UserService(){
System.out.println("Constructor from userService");
}
}
IndexService.java
package com.luban.service;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class IndexService {
@Autowired
UserService userService;
public IndexService(){
System.out.println("Constructor from indexService");
}
public void getService(){ //为了测试是否装配了userService
System.out.println(userService);
}
}
Appconfig.java
package com.luban.app;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
@Configuration
@ComponentScan("com.luban")
public class Appconfig {
}
Test.java
package com.luban.test;
import com.luban.app.Appconfig;
import com.luban.service.IndexService;
import com.luban.service.UserService;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
public class Test {
public static void main(String[] args) {
AnnotationConfigApplicationContext ac =
new AnnotationConfigApplicationContext(Appconfig.class);
}
}
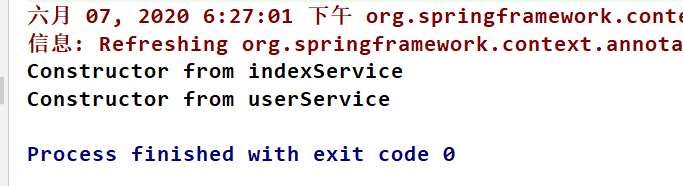
注意:这次代码在main方法里面并没有使用IOC容器(即代码中的
ac变量)获取Bean
但是测试结果仍然打印了构造器里面的信息,测试结果如下:
四. Spring如何创建一个Bean
上面讲到了要理解Spring的循环依赖,即要理解依赖注入(DI),即要了解Spring bean生命周期,即要知道Spring bean的产生过程(bean是由什么产生的)
4.1 预备知识
为了后面更加容易理解Spring bean产生的过程,在这里给出2个非官方的概念:
- Java对象(简称它对象):当在java中使用new关键字,就能把一个对象new出来,随后就可以使用这个对象了。
- bean:Bean,即Spring bean。bean不仅需要经历new的过程,还需要经历一系列过程,才能成为一个Spring bean,才可以正常地使用它。
注意:再次强调这2个概念只是为了更加容易理解后面的分析,它们并不是官方给出的概念。
总结:Java对象不是一个bean,而bean是一个Java对象。只有经历过一系列的过程,才能成为bean。
4.2 Java对象和Spring对象的产生过程的区别:
区别在于多了一个BeanDefinition对象,如下:
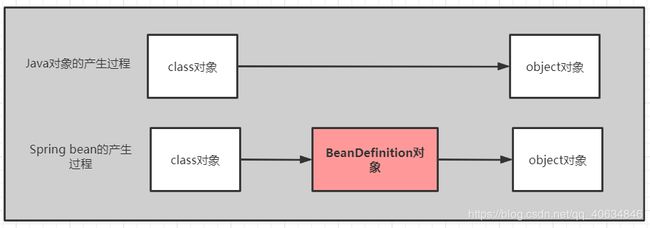
如上图可见,最大的区别就是bean的产生过程有一个BeanDefinition对象。这个BeanDefiniton是非常重要的!!!它在spring源码中起到了很大的作用!!!
4.3 BeanDefinition对象是什么
上面阐述了bean的产生过程最重要的一环是BeanDefinition对象。现在了解这个BeanDefinition对象到底是什么。
源码中对BeanDefinition的定义如下:
/**
* A BeanDefinition describes a bean instance, which has property values,
* constructor argument values, and further information supplied by
* concrete implementations.
* 大概意思:一个BeanDefinition描述一个bean实例,记录了该bean实例的属性值、构造器参数值、以及
* 该实例具体实现的更多信息
*
* This is just a minimal interface: The main intention is to allow a
* {@link BeanFactoryPostProcessor} such as {@link PropertyPlaceholderConfigurer}
* to introspect and modify property values and other bean metadata.
* 大概意思:这只是一个小型接口:该接口的目的是允许一个BeanFactoryPostProcessor
* (比如PropertyPlaceholderConfigurer)去反省(笔者认为这里反省的意思是回调的意思)以及修改属性值
* 和其他的bean元数据(配合前面出现的Configurer,元数据大概是指注解,比如@Lazy、@DependsOn)。
*
* @author Juergen Hoeller
* @author Rob Harrop
* @since 19.03.2004
* @see ConfigurableListableBeanFactory#getBeanDefinition
* @see org.springframework.beans.factory.support.RootBeanDefinition
* @see org.springframework.beans.factory.support.ChildBeanDefinition
*/
public interface BeanDefinition extends AttributeAccessor, BeanMetadataElement
BeanDefinition是一个接口,说明它可以有很多实现类。它继承了
AttributeAccessor,BeanMetadataElement。再来看看它的父接口。
源码中对AttributeAccessor的定义如下:
/**
* Interface defining a generic contract for attaching and accessing metadata
* to/from arbitrary objects.
* 大概意思是:该接口定义一个总的协议去设置以及访问元数据(metadata,即那些标注在类、方法、属性上的注解)
*
* @author Rob Harrop
* @since 2.0
*/
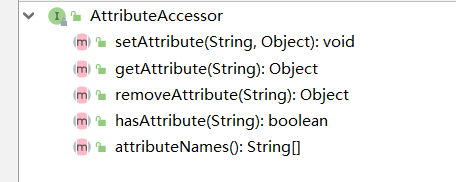
public interface AttributeAccessor
AttributeAccessor里面也有很多getAttribute()方法、setAttribute()方法,可见它确实是设置、访问元数据的。如下:
源码中对BeanMetadataElement的定义如下:
/**
* Interface to be implemented by bean metadata elements
* that carry a configuration source object.
* 大概意思是:该接口是被那些bean的元数据们实现的,功能是携带一个配置源的对象。
* 也就是获取标注在类、方法、属性上的注解。
*
* @author Juergen Hoeller
* @since 2.0
*/
public interface BeanMetadataElement
该接口里面只有一个getSource()方法,如下:
/**
* Return the configuration source {@code Object} for this metadata element
* (may be {@code null}).
* 大概意思是:返回该元数据的配置源对象(即用一个配置源对象描述(或者可以理解为代替)该元数据)
*/
Object getSource();
4.3.1 BeanDefinition对象存了什么
前面说了BeanDefinition是描述一个bean实例的接口(虽然这里用了“bean实例”,但实际上它仍未被实例化,只是描述了它被实例化时要用到的属性,后面有一个验证阶段根据这些属性决定是否实例化该bean),描述了该bean实例的属性值、构造器参数值、以及该实例具体实现的更多信息。那么再来结合方法看看它具体存了什么信息?,如下:
- 记录该bean是否懒加载(即如果是懒加载,那么容器初始化时将不会初始化这个bean。只有当bean是单例(singleton)时,才会在容器初始化时就进行初始化。)
/**
* Return whether this bean should be lazily initialized, i.e. not
* eagerly instantiated on startup. Only applicable to a singleton bean.
*/
boolean isLazyInit();
- 记录该bean是否自动装配
/**
* Return whether this bean is a candidate for getting autowired into some other bean.
*/
boolean isAutowireCandidate();
- 记录该bean是否自动装配的主要候选者
/**
* Return whether this bean is a primary autowire candidate.
* If this value is true for exactly one bean among multiple
* matching candidates, it will serve as a tie-breaker.
*/
boolean isPrimary();
- 记录该bean是否单例(singleton)。容器初始化就必将该单例bean初始化,而且仅初始化一次。后面从容器获取该bean都是同一个bean
/**
* Return whether this a Singleton, with a single, shared instance
* returned on all calls.
* @see #SCOPE_SINGLETON
*/
boolean isSingleton();
- 记录该bean是否原型(prototype)。该bean不在容器初始化时进行初始化。每次获取该bean都是重新从容器中获取,都不是同一个bean。
/**
* Return whether this a Prototype, with an independent instance
* returned for each call.
* @see #SCOPE_PROTOTYPE
*/
boolean isPrototype();
- 记录该bean是否抽象的。如果是抽象的,则意味着没必要实例化
/**
* Return whether this bean is "abstract", that is, not meant to be instantiated.
*/
boolean isAbstract();
除了记录上面这些信息,BeanDefinition还记录了很多信息,比如beanName、parentName、beanClassName、factoryBeanName、factoryMethodName、scope、dependsOn、description等等。如下:
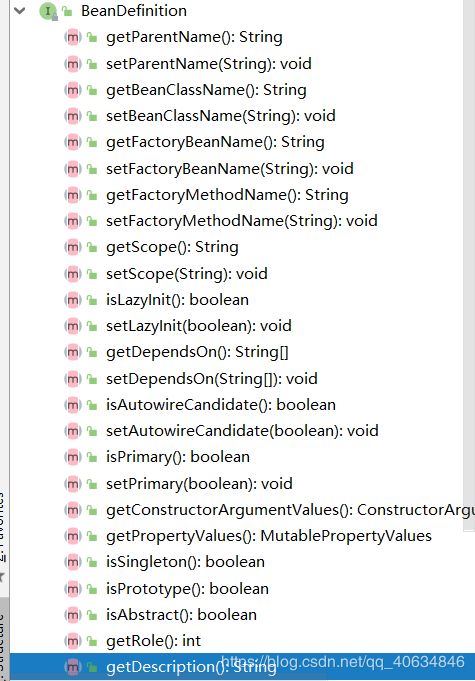

总结:每一个class对象都对应着一个BeanDefinition。BeanDefinition存储了一些该class的信息,这些信息是标注在该class中的一些注解,比如@Lazy、@DependsOn、@Autowired、@Scope等等。
4.4 Spring bean的实例化过程
是实例化的过程(即new),不是生命周期的过程,因为没有涉及到属性注入等等阶段。
先给出大概流程使我们更容易理解源码,后面从源码分析验证。(图片模糊可右击图片选择”在新标签页打开“)
4.4.1 总体概览图

4.4.2 细节过程图
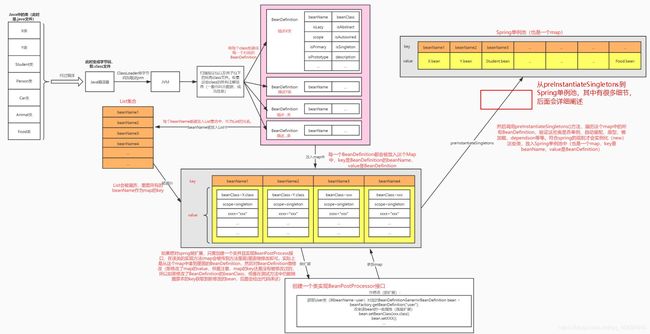
4.5 实现简单的Spring扩展
再次强调上面的过程是实例化的过程,而非生命周期,因为没有涉及到属性注入等各个阶段。
从上面的过程中知道BeanDefition会被放入map中,只要我们创建一个类并实现BeanPostProcessor接口即可做spring的扩展,现在来试试效果。
需求:修改BeanDefinition的beanClass属性的内容,看看在main方法获取该bean会有什么效果
代码如下:
IndexService.java
package com.luban.service;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class IndexService {
@Autowired
UserService userService;
public IndexService(){
System.out.println("Constructor from indexService");
}
public void getService(){ //为了测试是否装配了userService
System.out.println(userService);
}
}
UserService.java
package com.luban.service;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
public class UserService {
IndexService indexService;
public UserService(){
System.out.println("Constructor from userService");
}
}
AppConfig.java
package com.luban.app;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
@Configuration
@ComponentScan("com.luban")
public class Appconfig {
}
ZiluBeanFactoryPostProcessor.java
package com.luban.mapper;
import com.luban.service.UserService;
import org.springframework.beans.BeansException;
import org.springframework.beans.factory.config.BeanDefinition;
import org.springframework.beans.factory.config.BeanFactoryPostProcessor;
import org.springframework.beans.factory.config.ConfigurableListableBeanFactory;
import org.springframework.beans.factory.support.GenericBeanDefinition;
import org.springframework.stereotype.Component;
@Component
public class ZiluBeanFactoryPostProcessor implements BeanFactoryPostProcessor {
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
//获取indexService的BeanDfinition
GenericBeanDefinition indexService =
(GenericBeanDefinition) beanFactory.getBeanDefinition("indexService");
//修改它的beanClass,看看在main方法中获取indexService有什么效果
indexService.setBeanClass(UserService.class);
}
}
Main.java
package com.luban.test;
import com.luban.app.Appconfig;
import com.luban.service.IndexService;
import com.luban.service.UserService;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
public class Test {
public static void main(String[] args) {
AnnotationConfigApplicationContext ac =
new AnnotationConfigApplicationContext(Appconfig.class);
System.out.println(ac.getBean(IndexService.class));//根据类型获取bean
}
}
测试结果:

可以看到,经过BeanPostProcessor处理,我们修改了indexService的BeanDefinition里面的beanClass属性,在main方法中就获取不到indexService这个bean了。而且打印出来的是UserService的信息,而不是IndexService的信息(即调用了UserService的构造器,没有调用IndexService的构造器)。
得出结论:jvm加载进去的类,与spring产生出来的bean是没有关系的,而是与BeanDefinition有关,我们修改了BeanDefiniton的信息,得到的spring bean也会发生改变
在main方法中我们使用根据beanName获取bean的方法试试有什么效果:
package com.luban.test;
import com.luban.app.Appconfig;
import com.luban.service.IndexService;
import com.luban.service.UserService;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
public class Test {
public static void main(String[] args) {
AnnotationConfigApplicationContext ac =
new AnnotationConfigApplicationContext(Appconfig.class);
System.out.println(ac.getBean("indexService"));
}
}
测试结果:
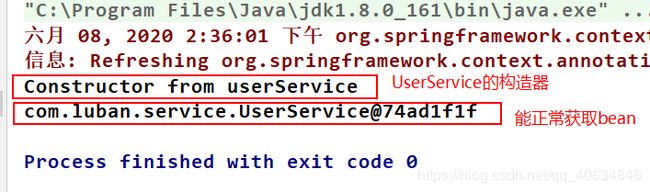
这个例子验证了spring是从单例池(即map)中拿bean的,因为即使我修改了BeanDefinition,但是BeanDefinition对应的key没有改变,我在main方法中仍可以根据原本的key获取到bean。
得出结论:spring是从单例池(map)中拿bean的。即使我们修改了BeanDefinition,其对应的key没有改变,我们仍可以根据原本的key获取bean
4.6 初步debug分析spring实例化bean的步骤在哪里
从上面spring实例化对象的细节过程图中初步了解了大概过程。现在开始debug一下代码,看看是不是真的这样。debug的过程中还会验证某些地方是不是与前面给出的结论一致。如果忘了,需要时不时看一下前面给出的bean实例化细节过程图。
首先贴出debug的代码:
IndexService.java
package com.luban.service;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
@Component
public class IndexService {
@Autowired
UserService userService;
public IndexService(){
System.out.println("Constructor from indexService");
}
public void getService(){ //为了测试是否装配了userService
System.out.println(userService);
}
@PostConstruct
public void aa(){
System.out.println("init.");
}
}
UserService.java
package com.luban.service;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class UserService {
public UserService(){
System.out.println("Constructor from userService");
}
}
Appconfig.java
package com.luban.app;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
@Configuration
@ComponentScan("com.luban")
public class Appconfig {
}
Test.java
package com.luban.test;
import com.luban.app.Appconfig;
import com.luban.service.IndexService;
import com.luban.service.UserService;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
public class Test {
public static void main(String[] args) {
AnnotationConfigApplicationContext ac =
new AnnotationConfigApplicationContext(Appconfig.class);
}
}
分析:前面已经事先给出了spring bean实例化是发生在spring bean生命周期中,而spring bean生命周期是发生在spring容器初始化中,因此测试方法main()只给出了初始化容器的方法。因此,如果当console打印了IndexService以及UserService的构造方法里面信息(即“
Constructor from indexService,Constructor from userService”),则代表IndexService以及UserService已经被实例化了。因此,我们debug通过判断何时打印了构造器信息来定位出实例化的步骤到底在哪里。
现在开始debug,首先在下面打断点:

点击绿色按钮,选择Debug ‘Test.main()’,如下:

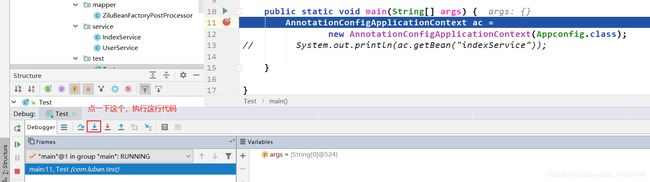
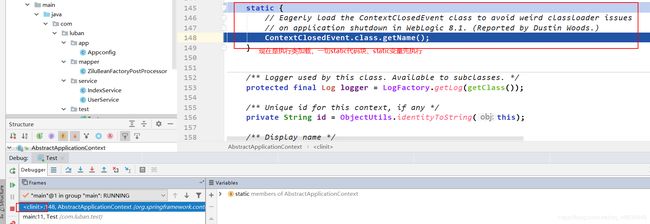
控制台console没有打印信息,所以继续执行:
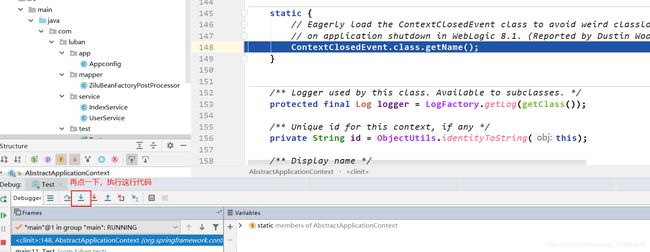
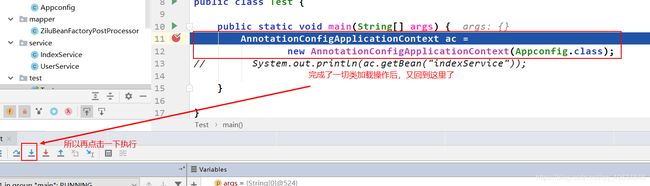
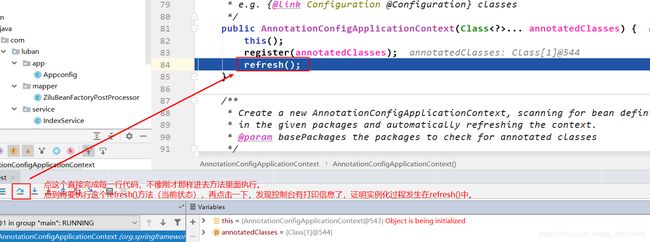
上面发现控制台打印信息了,定位到实例化阶段发生在构造方法的refresh()中。
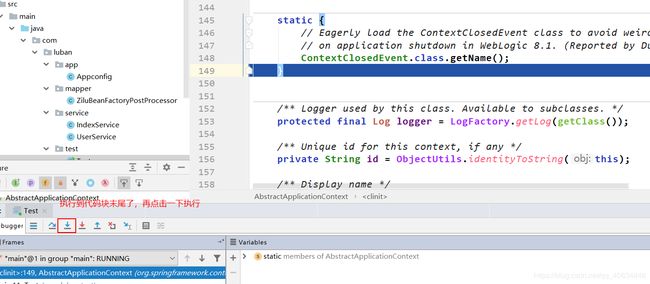
接下来重新启动debug模式,把它执行到上图的状态,然后点击进入方法里面执行,如下:
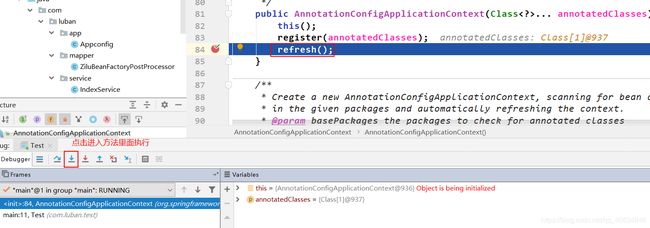
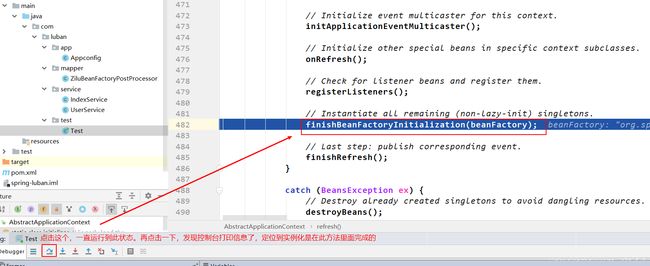
定位到实例化阶段在finishBeanFactoryInitialization(beanFactory)里面。
重新启动debug模式,然后调试到上图的状态,然后点击如下:
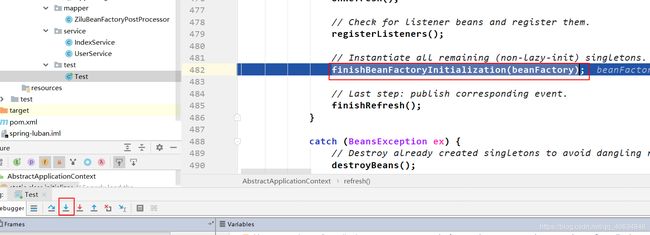
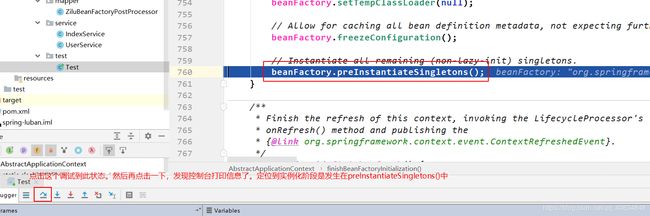
定位到实例化阶段发生在preInstantiateSingletons()中。
重新启动debug模式,调试到上图的状态,然后点击如下:
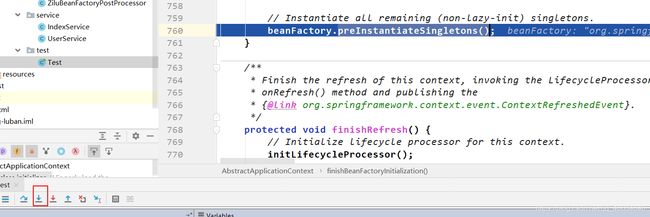
点击后,如下图:
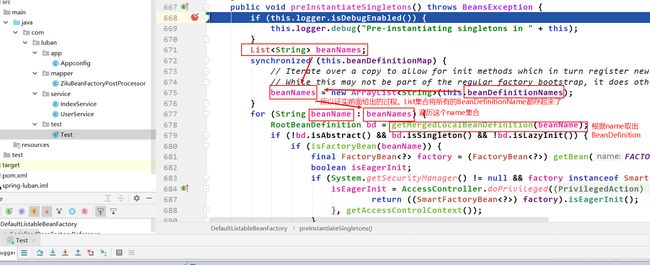
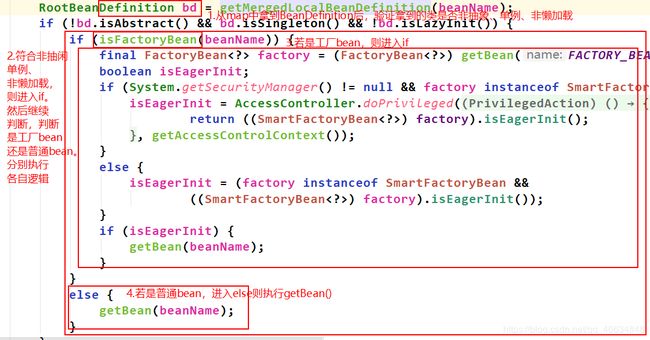
点进入看看getMergedLocalBeanDefinition()这个方法,如下:

如下图:从map中拿到BeanDefinition后,开始验证信息,符合验证则判断拿到的这个BeanDefinition是以工厂bean实例化还是普通bean**实例化。**我们知道只要我们创建一个类并实现BeanFactory接口并实现对应方法,在里面写自己的逻辑即可参与bean的初始化过程。所以它就是在preInstantiateSingletons()方法里面执行的。
继续定位实例化阶段发生在哪里,重启debug模式,调试到如下状态:
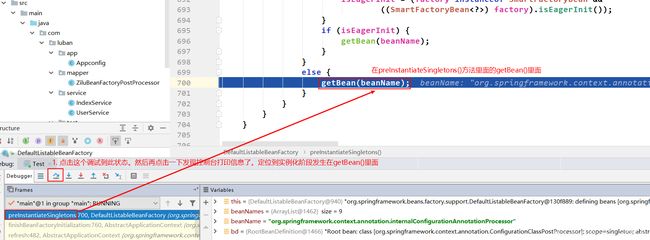
定位到实例化阶段是在getBean()里面完成的。
重启debug模式,调试到上图的状态,点击如下:
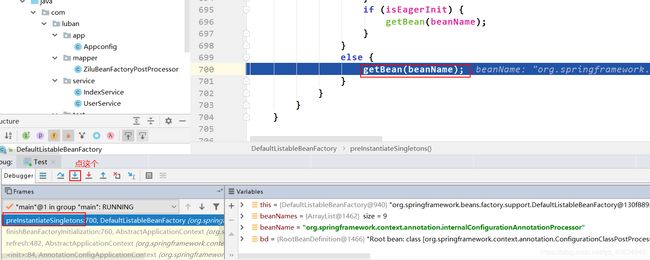
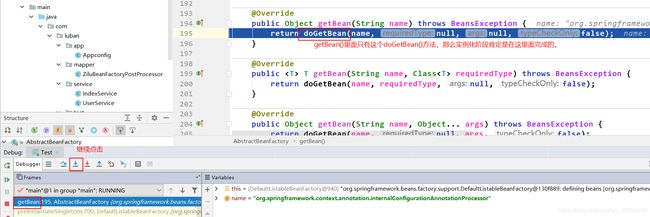
定位到实例化阶段是在doGetBean()中完成的。
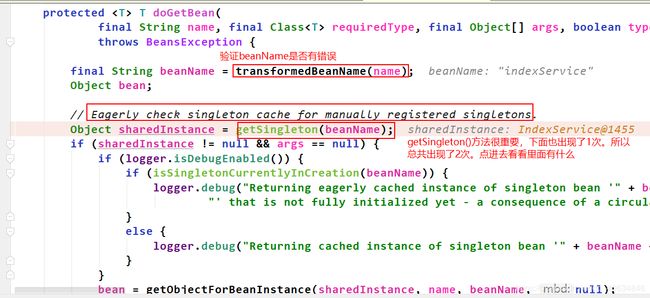
getSingleton()方法里面如下:

getSingleton(beanName, true)方法如下:
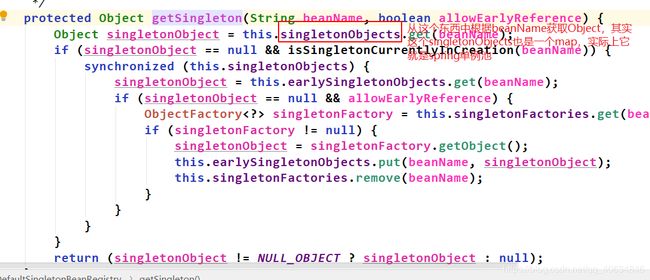
点击singletonObjects看到它是一个map

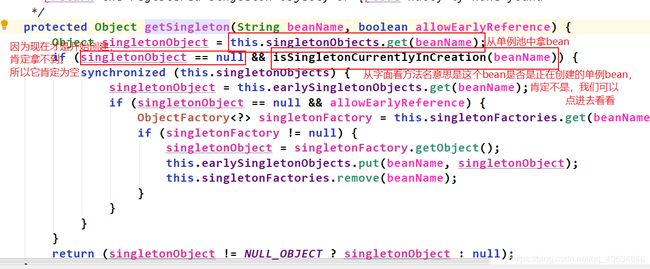


由于当前只是从map中拿出BeanDefinition而已,仍未创建bean(实例化都还没开始,肯定不是正在创建bean),所以singletonsCurrentlyInCreation里面是没有正在创建的bean的beanName的,所以singletonsCurrentlyInCreation.contains(beanName)返回false。
继续分析这个getSingleton()方法:
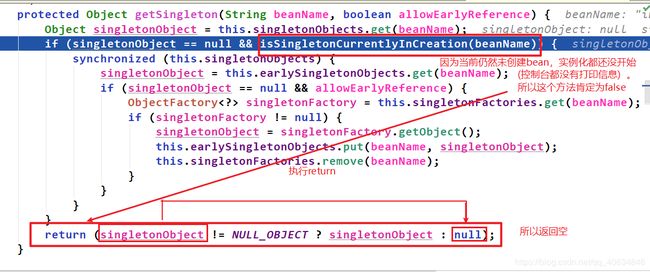

bean都还没有创建,为什么就已经从单例池map中获取bean呢?作者有什么用意?
**解释:首先明白这个getSingleton()方法是在doGetBean()方法里面的。spring的作者为什么这么做?其中缘由很复杂。与这部分知识有关的便是为了解决循环依赖。无论是创建Bean还是getBean()都会调用这个doGetBean()方法,而getSingleton()方法在doGetBean()里面。即无论前者还是后者这2种情况都会调用getSingleton()。由于循环引用需要在创建Bean的时候去获取被引用的那个类,而被引用的那个类如果没有被创建成Bean,则会调用createBean来创建这个bean,在创建这个被引用的bean的过程中会判断这个bean的对象有没有被实例化。
上图中的sharedInstance什么时候不为null?
答:当容器初始化完成,程序员直接使用getBean()的时候不为null
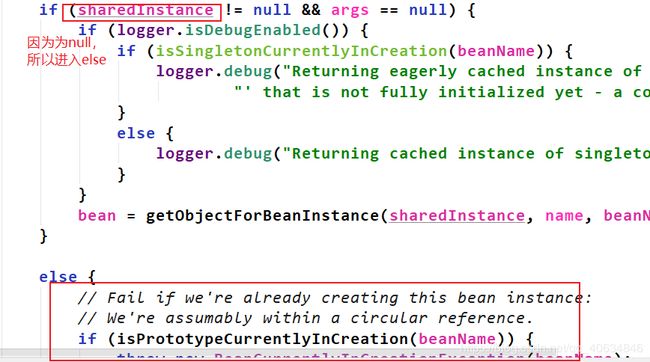

isPrototypeCurrentlyInCreation()方法后面的几个if都是验证类是否有dependsOn之类的,都没有。直到遇到isSingleton()方法。进入它的if。如下:
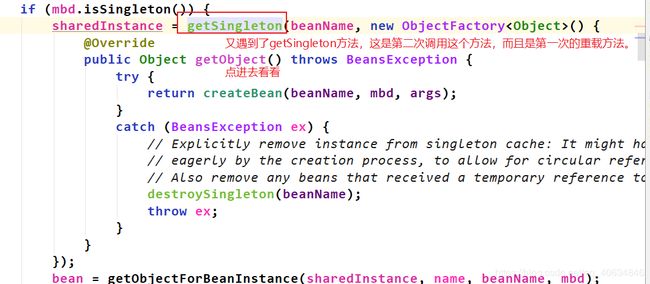
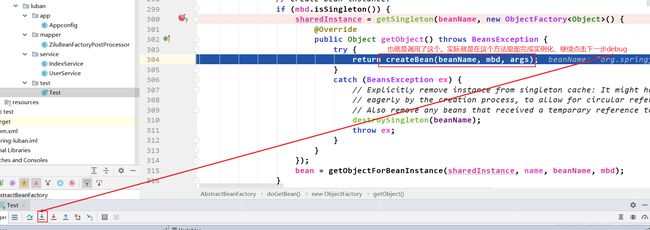
从上图看到,定位到实例化就是在createBean()中完成的,这里不再作定位验证了,继续往下分析createBean()里面有什么。
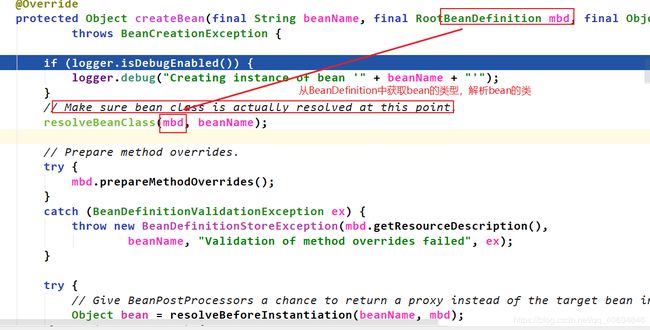
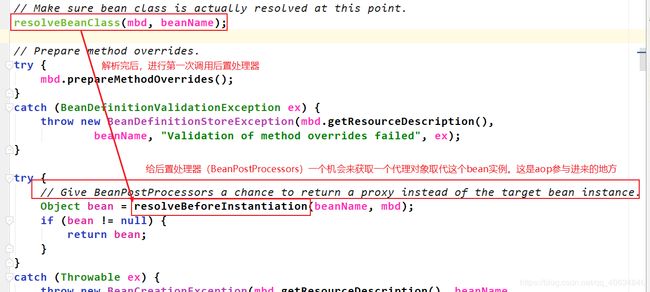
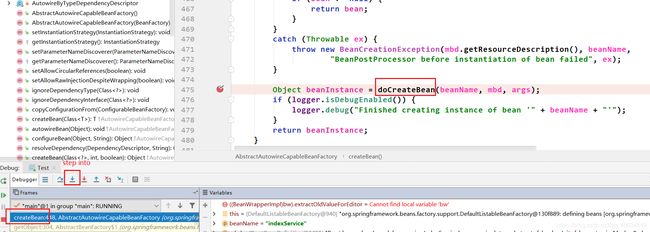
在createBean()里面,doCreateBean()的前面,resolveBeforeInstantiation()是第一次调用了后置处理器(spring初始化过程中一共调用了9次后置处理器,而且每次的内容以及位置都不同)
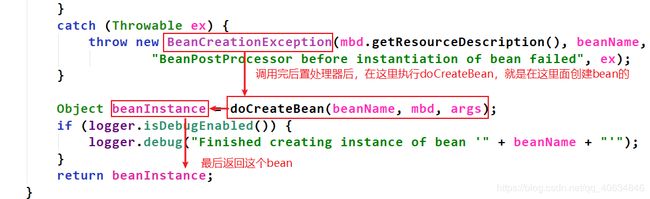
**执行完doCreateBean,控制台有信息打印出来了。定位到实例化阶段是在createBean()中的doCreateBean()中完成的。 我们继续看看doCreateBean()里面有什么。如下:
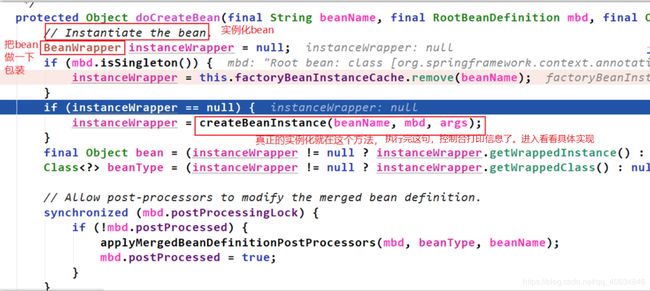
定位到实例化阶段是在createBeanInstance()里面,进入看看具体实现:

在createBeanInstance()里面第二次调用后置处理器。第一次是在createBean里面(即doCreateBean()前面)。
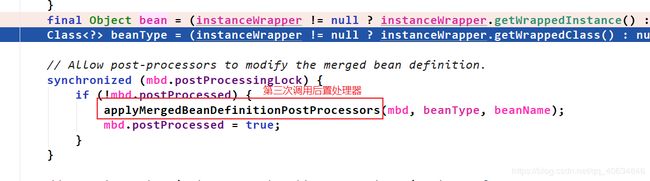
如上图,第三次调用后置处理器发生在doCreateBean()里面。**(生命周期中一共有9次调用后置处理器。第一次在createBean()里面,叫做resolveBeforeInstantiation(),发生在doCreateBean()前面;第二次是在createBeanInstance()里面。)继续往下看:

上图的allowCircularReferences就是spring默认支持循环依赖的原因。它的默认值是true。 如果想关闭循环依赖,可以通过在容器的构造器中设置它为false(需对源码修改,一般只能从github上fork spring源码才可以修改源码),或在main中使用提供的api设置它为false。
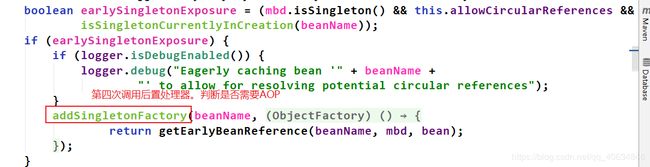
第四次调用后置处理器也是在doCreateBean()中。

最后作出总结:
要研究spring的循环依赖->就要研究spring bean的生命周期(因为循环依赖是发生在生命周期中的)->就要研究spring如何实例化一个bean(因为研究生命周期,就要实例化bean)
4.7 总结spring bean生命周期过程大概过程
从以上所有的debug分析,总结如下:

解释:
AnnotationConfigApplicationContext的构造方法里面的
refresh() 方法,里面的
finshBeanFactoryInitialization() 方法,里面的
preInstantiateSingletons() 方法,里面的
getBean() 方法,里面的
doGetBean() 方法,里面的
第二次的getSingleton() 方法,里面的
getObject()【lambda表达式实现的方法】方法,里面的
createBean() 方法,里面的
doCreateBean()【里面有完成实例化createBeanInstance()、属性注入populateBean()、初始化initializeBean()这个3个阶段。属性注入populateBean()之前还有判断是否需要循环依赖allowCircularReferences】方法,里面的
createBeanInstance()【就是在这里面完成实例化】
4.8 属性注入
4.8.1 回顾
在本博文最前面一开始就抛出问题——循环依赖。spring是默认支持循环依赖,那么那的原理机制是怎么样的?
要研究循环依赖->就得研究spring bean的生命周期(因为循环依赖是发生在spring生命周期里面的)->就得研究spring如何实例化一个对象(因为研究生命周期就肯定要实例化对象)
前面几个小节对实例化的过程做了debug分析,4.7小节对整个生命周期流程做了总结。为了后面更加容易、更加方便理解spring bean的属性注入阶段,笔者建议把4.7小节中的图背下来,因为后面debug代码的跨度非常大**,必须对整个生命周期哪个阶段发生在哪里有一个大致了解才能更加容易理解后面的属性注入分析。**
4.8.2 搭建代码
后面将对属性注入阶段作出debug分析,先了解属性注入,再去了解循环依赖是怎么解决的,这样比较清晰
工程目录:
为了能让后面的出现的情况和大家一致,这里给出debug的代码:
IndexService.java
package com.luban.service;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
@Component
public class IndexService {
@Autowired
UserService userService;
public IndexService(){
System.out.println("Constructor from indexService");
}
public void getService(){ //为了测试是否装配了userService
System.out.println(userService);
}
@PostConstruct
public void aa(){
System.out.println("init.");
}
}
UserService.java
package com.luban.service;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class UserService {
@Autowired
IndexService indexService;
public UserService(){
System.out.println("Constructor from userService");
}
}
AppConfig.java
package com.luban.app;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
@Configuration
@ComponentScan("com.luban")
public class Appconfig {
}
Test.java
package com.luban.test;
import com.luban.app.Appconfig;
import com.luban.service.IndexService;
import com.luban.service.UserService;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
public class Test {
public static void main(String[] args) {
AnnotationConfigApplicationContext ac =
new AnnotationConfigApplicationContext(Appconfig.class);
}
}
4.8.3 debug分析属性注入
这里是对属性注入阶段作出debug分析,先了解属性注入,再去了解循环依赖是怎么解决的,这样比较清晰
首先给出结论bean的属性注入是发生在populateBean()中的。在这里打一个断点,进入该方法里面看看:
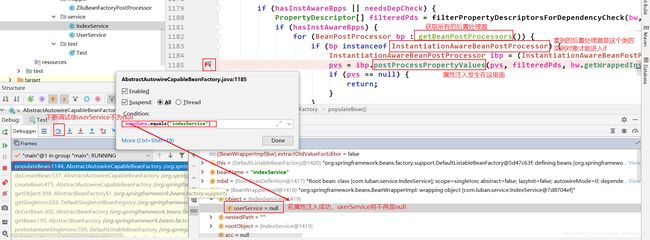
接下来拿到的后置处理器是CommonAnnotationBeanPostProcessor,再然后拿到的是AutowiredAnnotationBeanPostProcessor。
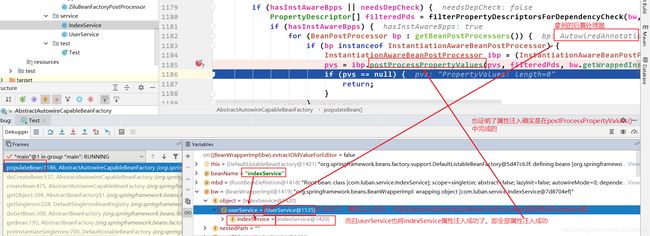
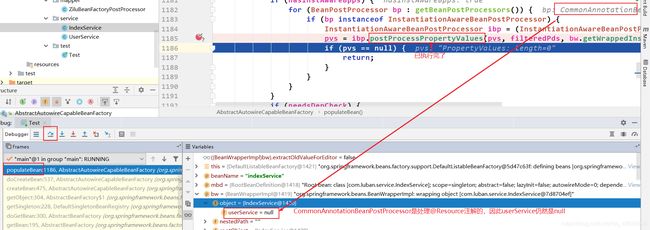
面试官经常会问到“@Resource和@Autowired的区别是什么?”
这里就可以回答:区别是他们的类不一样。@Resource的类是CommonAnnotationBeanPostProcessor,而@Autowired的类是AutowiredAnnotationBeanPostProcessor。
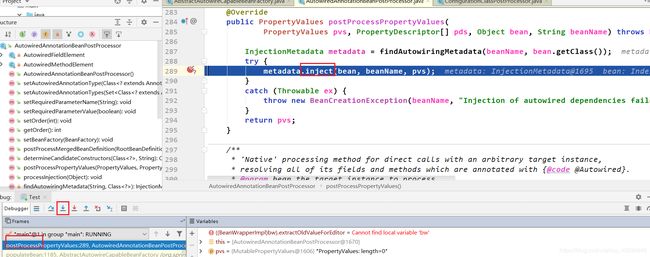
因为属性注入在postProcessPropertyValues(),debug点进去看看:
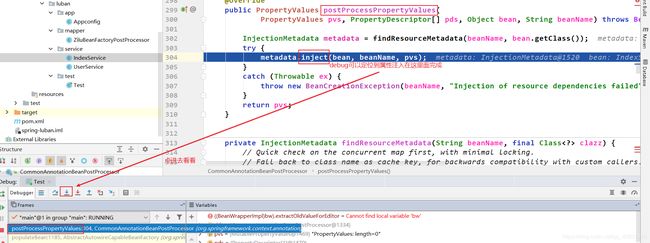
定位到postProcessPropertyValues()中的inject()完成属性注入
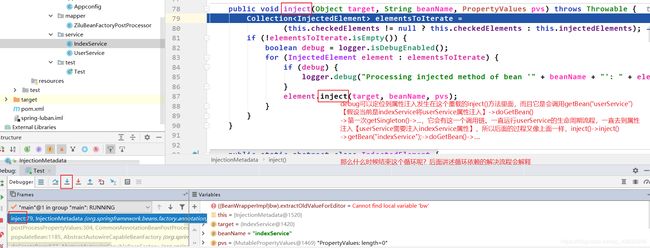
定位到inject()里面还有一个重载的inject()方法,属性注入在里面完成。
4.8.4 总结
由于参考的b站的spring源码视频没有更加深入第二个inject(),笔者这里也直接给出第二个inject()方法到底是实现了什么,如下图: 从图中了解个大概,后面就能更容易理解循环依赖的解决方案。
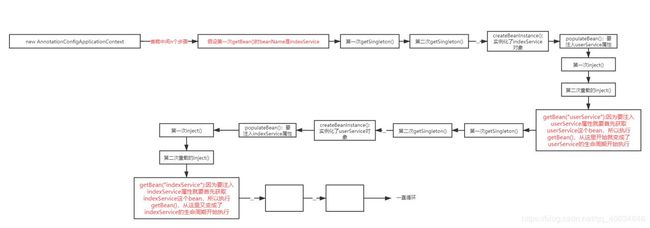
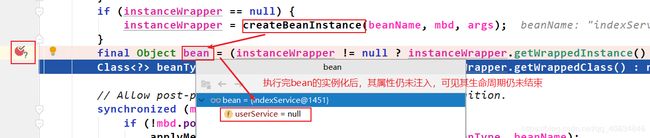
解释:当前beanName是indexService,完成了实例化,成为了一个indexService对象。实例化后就是进行属性注入,进入populateBean()。获取所有的后置处理器,遍历每个后置处理器,符合条件(当拿到的后置处理器是InstantiationAwareBeanPostProcessor的实例对象时,会进入if判断,因为indexService是用@Autowired注解自动装配的,所以拿到后置处理器为AutowiredAnnotationBeanPostProcessor),就会执行postProcessPropertyValues()->inject()->重载的inject()进行属性注入。因为属性注入就是要获取到userService这个bean,然后注入进indexService的userService属性。所以进重载的inject()会调用getBean(“userService”)去getBean(),进而现在就变成执行userService的生命周期。getBean(“userService”)->doGetBean()->第一次getSingleton()->第二次getSingleton()->getObject()->createBean->doCreateBean()->createBeanInstance()->populateBean,现在就又变成了userService需要注入属性indexService,所以又像上面那样执行getBean(“indexService”)->doGetBean()->…一直循环,所以第二inject()后面发生的总体调用就是这样。那么这个循环什么时候结束呢?
4.9 Spring如何解决循环依赖的?
4.9.1 回顾
4.8.3的图中粗略地写出了属性注入会从inject()->调用到getSingleton()方法。
解决循环依赖最重要的方法就是getSingleton()方法。 同样以debug分析源码
4.9.2 代码
代码同样是使用上面4.8节的代码:
IndexService.java
package com.luban.service;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
@Component
public class IndexService {
@Autowired
UserService userService;
public IndexService(){
System.out.println("Constructor from indexService");
}
public void getService(){ //为了测试是否装配了userService
System.out.println(userService);
}
@PostConstruct
public void aa(){
System.out.println("init.");
}
}
UserService.java
package com.luban.service;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class UserService {
@Autowired
IndexService indexService;
public UserService(){
System.out.println("Constructor from userService");
}
}
AppConfig.java
package com.luban.app;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
@Configuration
@ComponentScan("com.luban")
public class Appconfig {
}
Test.java
package com.luban.test;
import com.luban.app.Appconfig;
import com.luban.service.IndexService;
import com.luban.service.UserService;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
public class Test {
public static void main(String[] args) {
AnnotationConfigApplicationContext ac =
new AnnotationConfigApplicationContext(Appconfig.class);
}
}
4.9.3 debug分析Spring如何解决循环依赖
在如下打断点并step into:
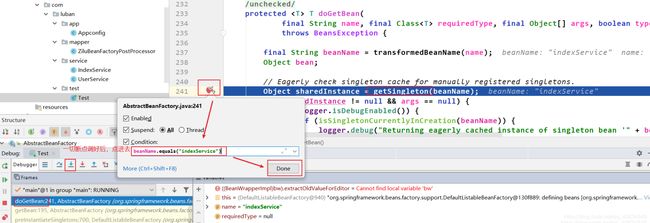
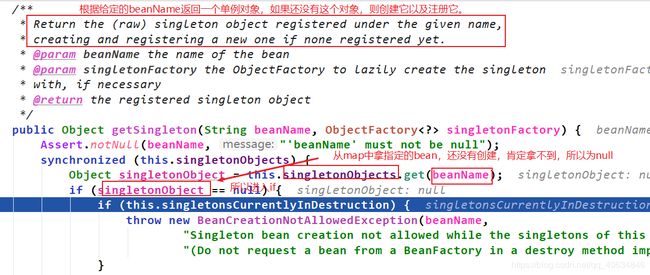
进入第一次的getSingleton()方法,从单例池拿bean,拿不到。Set集合singelCurrentlyCreation里面也没有indexService(因为当前indexService连实例化都没有进行,所以不属于正在创建的单例bean),所以为空,所以最终返回的singletonObject为null。
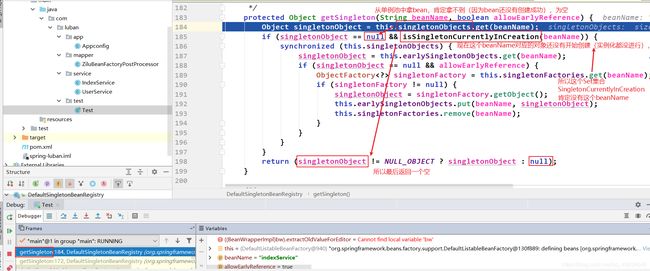
接下来在第二个getSingleton()中会遇到解决循环依赖的关键:beforeSingletonCreation()
原来doGetBean()中第一次getSingleton()里面的Set集合singletonsCurrentlyInCreation 是在 doGetBean()中第二次的getSingleton()中的beforeSingletonCreation()中添加“indexService”的。
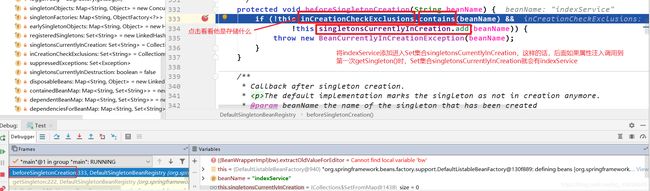

显然上上图中因为if条件判断不成立,所以不会进入if语句, 但是if条件判断的时候已经将“indexService”添加进入Set集合singletonsCurrentlyInCreation。**
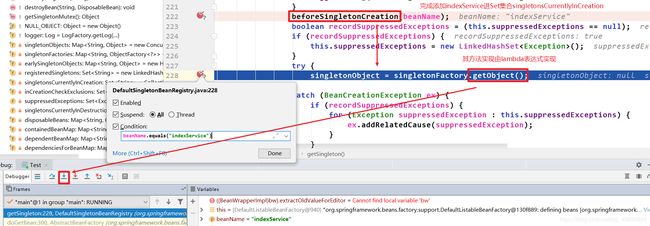
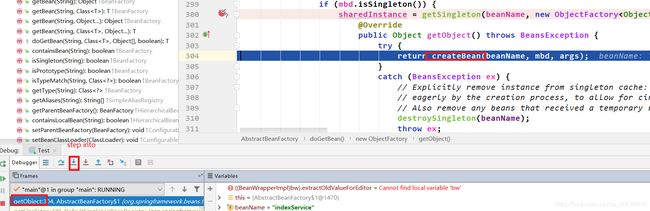
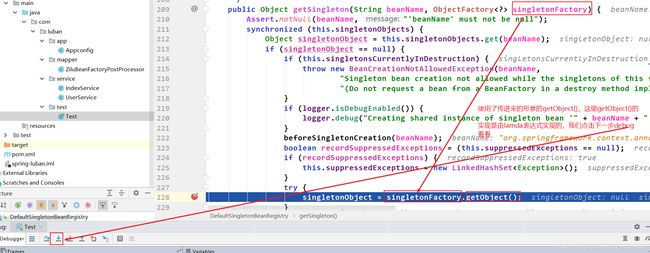
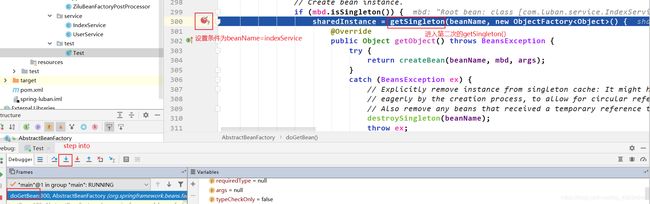
在doCreateBean()中,populateBean之前,又有一个循坏依赖解决的关键!!!,如下:
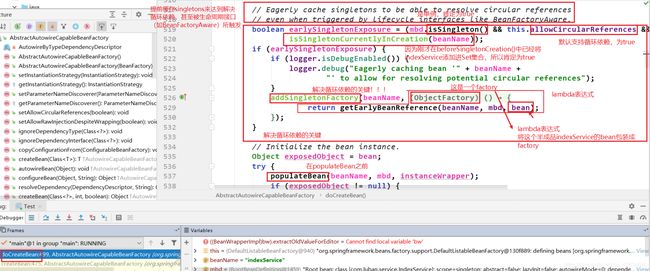
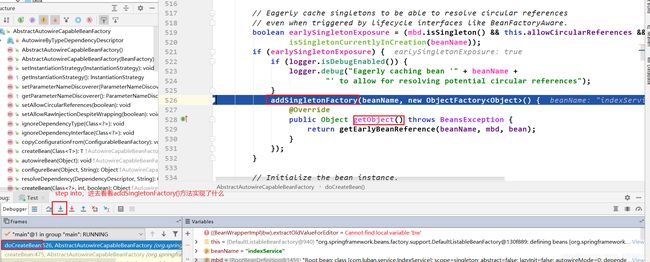
addSingletonFactory()方法中,出现了2个map。Spring中用3个map来缓存单例。第一个map,是getSingleton()中出现的singletonObjects。第二个map是addSingletonFactory()中的singletonFactories。第三个map也是addSingletonFactory()中出现的earlySingletonObjects。其实这三个map均同时出现在doGetBean()中的第一次getSingleton()方法里面 以及 doCreatebean()中的addSingleFactory()里面。这三个map是解决循环依赖的关键
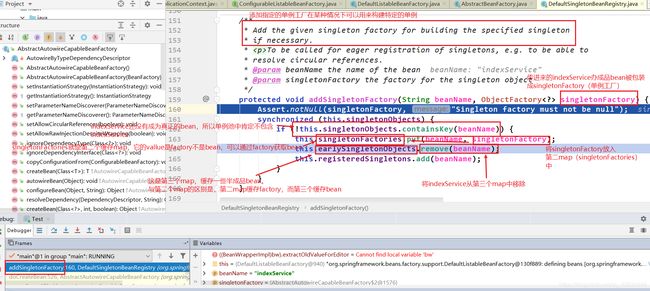
执行完毕后,开始执行populateBean,进入循环依赖属性注入了。
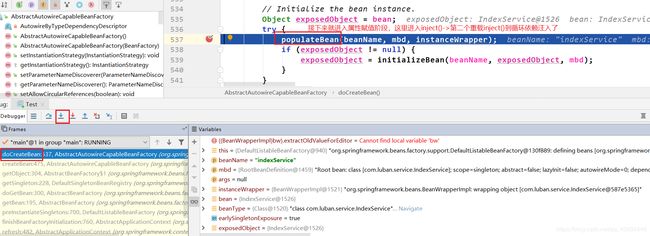
来到postProcessPropertyvalues():
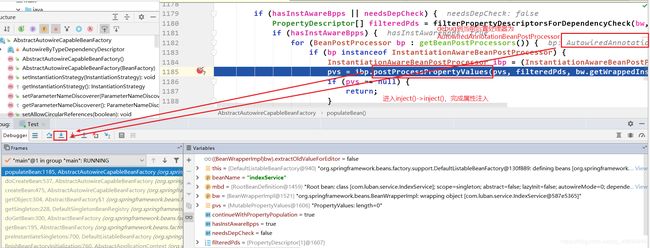
来到第一个inject():
来到第二个inject():
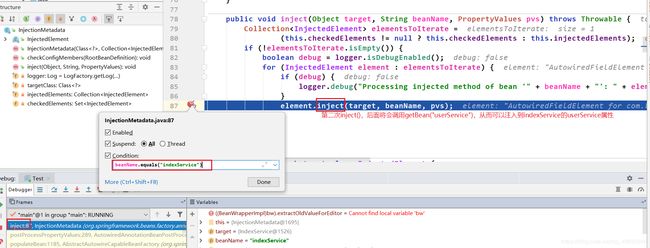
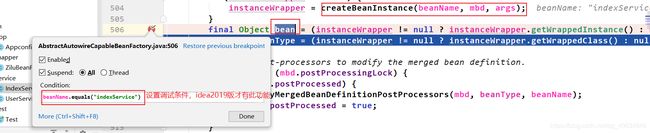
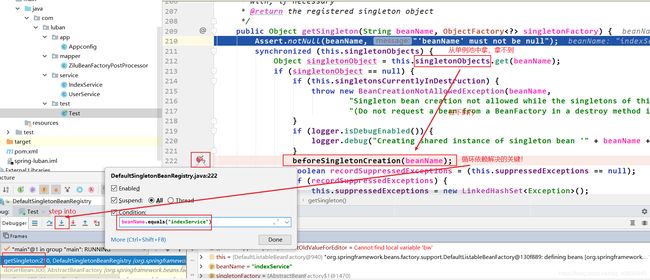
执行到第二次inject(),然后再去doGetBean()中第一次getSingleton()打断点,添加调试条件为
beanName.equals("userService")。依据上面给出的属性注入流程,当执行到第二次inject()后,就会执行getBean(), 所以接下来我们点击执行到下一个断点就会跳到如下界面:
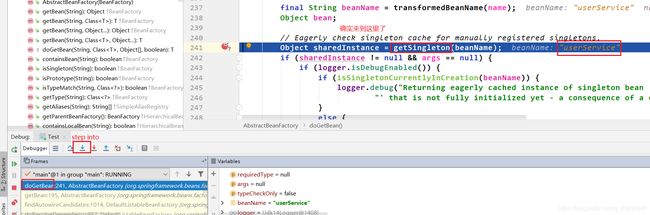
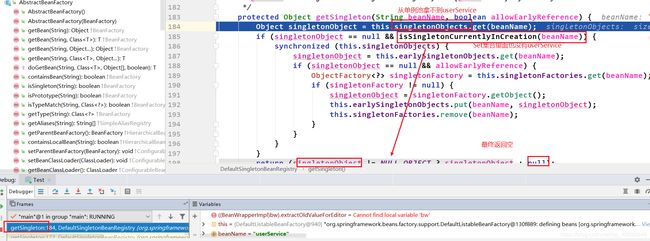
接下来的方法调用链完全是在进行userService的生命周期,直到执行到doGetBean()的第二次getSingleton()中的beforeSingletonCreation():也是将userService添加进Set集合
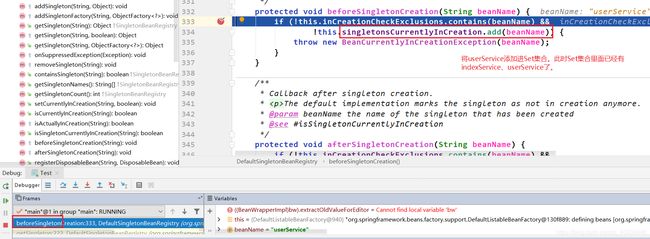
后面的过程就是执行userService的生命周期,直到执行到createBeanInstance()实例化userService对象,接着判断是否支持循环依赖,进入addSingletonFactory(),如下:
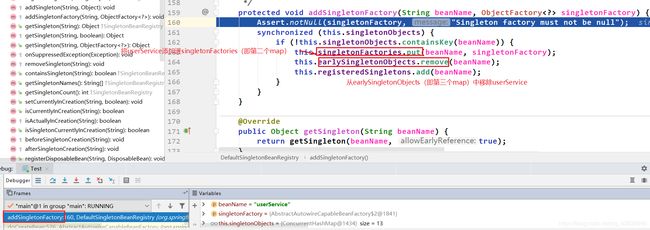
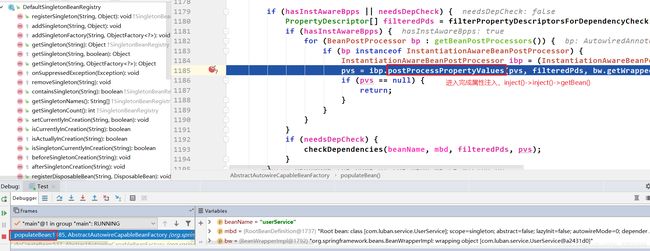
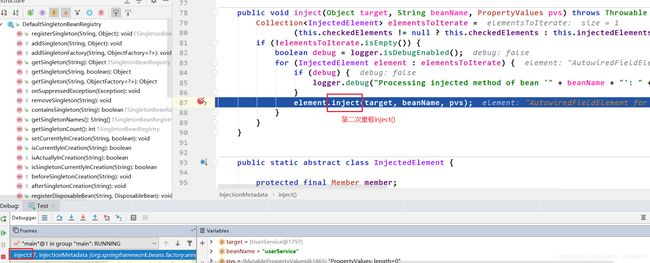
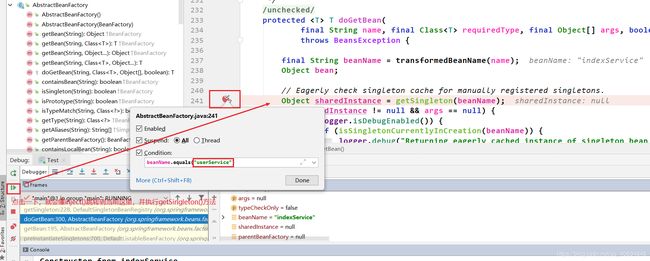
执行到第二次inject(),然后再去doGetBean()中第一次getSingleton()打断点,添加调试条件为
beanName.equals("indexService")。 依据上面给出的属性注入流程,当执行到第二次inject()后,就会执行getBean(),所以接下来我们点击执行到下一个断点就会跳到如下界面:
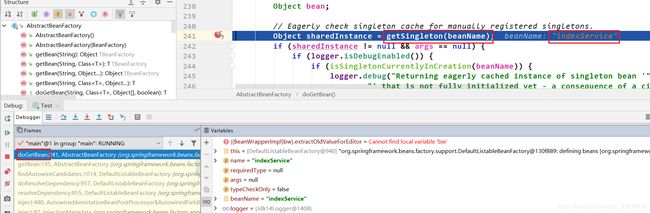
最最最关键解决循环依赖在下图 :getSingleton()
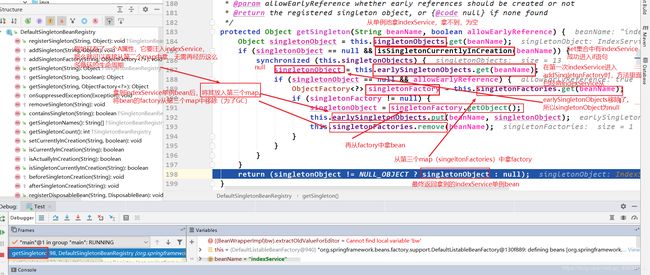
后面的调用也是像上面这样,最终在getSingleton()中得到单例bean,成功完成循环依赖的属性注入!!!
4.9.4 总结
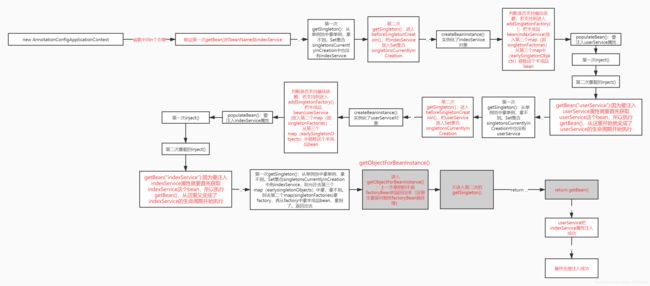
4.10 解决循环依赖的3个map
这三个map分别是singletonObjects;singletonFactories;earlySingletonObjects。前面在研究spring如何解决循环依赖的过程中,核心方法getSingleton()中出现了这3个map。
4.10.1 3个map的作用
首先给出结论,后面再探讨为什么这些map对应的功能要这么做?
三个map的作用如下:
- singletonObjects:第一个map,作用是存放已经完成整个生命周期的bean。专业术语叫作单例池。
- singletonFactories:第二个map,作用是存放beanFactory,通过这个factory,可以拿到想要的bean。
- earlySingletonObjects:第三个map,作用是存放未走完完整生命周期的bean。常称它为第三级缓存。
注:其实这3个map都可以叫作缓存,源码的注解也是用到了cache这个单词。
4.10.2 为什么要有三级缓存?(即第三个map存在的原因是什么)
这3个map出现在doGetBean()的第一次getSingleton()方法中,getSingleton()又调用了一次 getSingleton(beanName, allowCircularReference:true);重载方法。这里第二个入参被spring写死为true了。大家必须知道这一点。
首先阐述当前情况(看不懂可以查看上面4.9.4的总结图),后面再列出源码:indexService、userService都已经存在Set集合singletonsCurrentlyInCreation中了。此时userService要注入indexService,所以getBean(“indexService”),一直运行到getSingleton。即下面贴出的代码处。
然后开始看getSingleton()的源码:
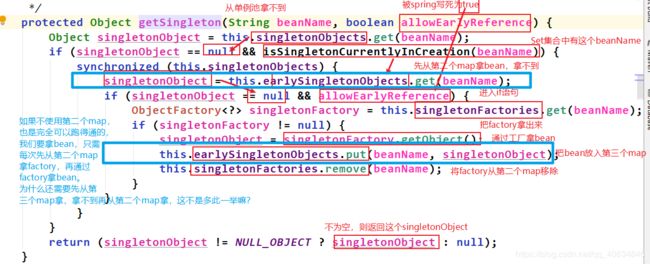
如上图中的蓝色字,为什么呢?因为可能存在重复创建的情况,有第三个map,可以提高性能。
试想假如有indexService,indexService2,indexService3,indexService4,indexService5,他们都有属性userService。如果每次注入userService都要从第二个map中拿factory再拿bean,这得耗费多少时间?假如有1000个要注入userService呢?而且,通过factory拿bean的过程(即singletonFactories.getObject())是非常耗时间的,因为这个过程有一个for循环。这个for循环在哪里呢?如下图:
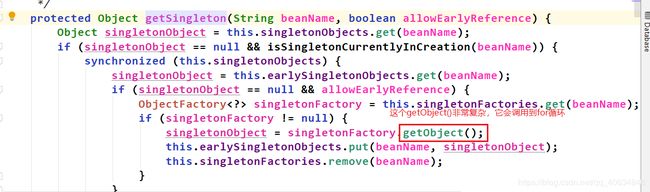
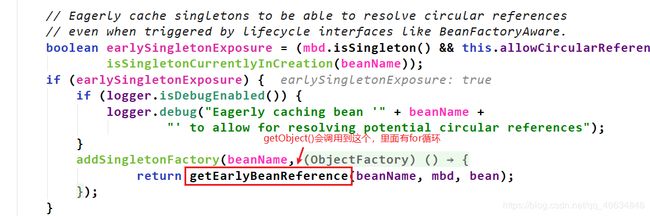
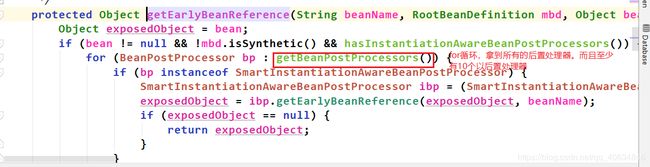
所以如果每次都从第二个map拿factory再拿到bean,会调用for循环,假如一个for循环要10ms,那么如果有10个对象要注入该属性,就得用10*10ms=100ms。非常耗费性能。这时如果我从factory拿到bean后,把它存入第三个map中,那么后面要拿该bean就只需直接从第2个map拿即可,无需经历for循环。
注:第一个map存的是完整的bean,第二个map存的是factory,第三个map存的是半成品bean
4.10.3 为什么第二个map存的是factory(即存工厂,而不是对象)?
这里涉及到aop。我们先提前给出结论,再进行验证分析。
答案是:存factory,我们可以对bean做另外一些操作,比如代理,使我们从factory拿到的bean是一个代理bean对象。总之我们使用第二个map存工厂,可以做一些我们自己想做的东西。如果第二个map直接存对象,那么就只能直接拿到这个bean对象了,无法做出其他处理。
4.10.3.1 引入后面验证分析需要用到的知识(储备知识)
这些储备知识大致了解即可,无需背下来。在这里引入,只是为了方便后面讲解验证分析。
我们对生命周期的过程已经有所了解,过程如下:
- 实例化(new一个对象)
- 属性注入(populate)
- init初始化(生命周期的回调方法,比如执行@PostConstruct的方法)
- 代理(aop)
- 放入单例池(put singletonObjects)
4.10.3.2 代码
为了阐述为什么第二个map放factory,我们需要搭建情景,其中涉及aop。
如果忘记了怎么写aop,可以看如下 一些步骤快速搭建aop:

工程目录如下:
IndexService.java
package com.luban.service;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class IndexService {
public IndexService(){
System.out.println("Constructor from indexService");
}
public UserService getUserService(){ //为了测试是否装配了userService
System.out.println("service logic");
return null;
}
}
UserService.java
package com.luban.service;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class UserService {
@Autowired
IndexService indexService;
public UserService(){
System.out.println("Constructor from userService");
}
public IndexService getIndexService() {
return indexService;
}
}
Appconfig.java
package com.luban.app;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.EnableAspectJAutoProxy;
@Configuration
@ComponentScan("com.luban")
@EnableAspectJAutoProxy
public class Appconfig {
}
NotVeryUsefulAspect.java
package com.luban.app;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.springframework.stereotype.Component;
@Component
@Aspect
public class NotVeryUsefulAspect {
@Pointcut("execution(* com.luban.service.IndexService.*(..))")
public void anyPublicMethod(){
}
@Before("anyPublicMethod();")
public void before(){
System.out.println("----------------------aop-------------------");
}
}
Test.java
package com.luban.test;
import com.luban.app.Appconfig;
import com.luban.service.IndexService;
import com.luban.service.UserService;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
public class Test {
public static void main(String[] args) {
AnnotationConfigApplicationContext ac =
new AnnotationConfigApplicationContext(Appconfig.class);
IndexService bean = ac.getBean(IndexService.class);
System.out.println(bean.getClass());
bean.getUserService();
}
}
4.10.3.3 分析以及验证
上述代码测试结果如下:

分析:得到的结果是从userService中得到的indexService,已经被代理了。如果按照前面阐述的生命周期过程,userService注入属性indexService,然后getBean("indexService“)->…->getSingleton()。然后从第二个map(即singletonFactories)拿factory,再通过factory拿到indexService。再结合上图的测试结果,indexService已经被代理了,不是原本的indexService。所以结论就是,通过factory拿indexService的时候,进行了aop处理。使得从factory拿到的是代理bean。所以这就是为什么第二个map存factory而不是对象。我存factory可以对bean做处理再返回结果出去。factory对bean起到了升华的作用。
如下图:

4.11 再次分析属性注入
从上面的一些列分析直到属性注入发生在populateBean()中。下面再次分析属性注入的源码,发现新的知识点。
下面为源码分析:
进入populateBean()方法,首先是进行判断是否继续进行属性注入,有如下:

往下执行,来到真正进行属性注入的地方:
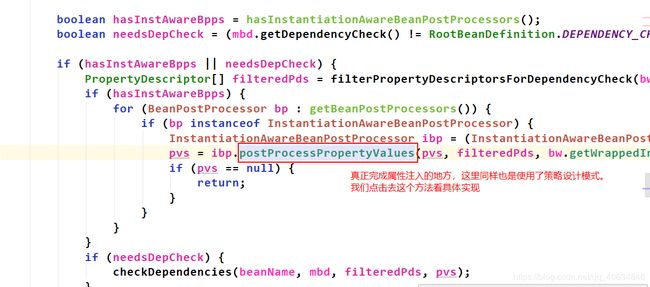

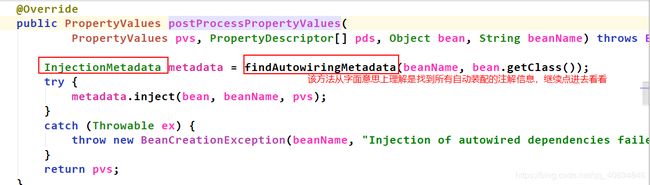
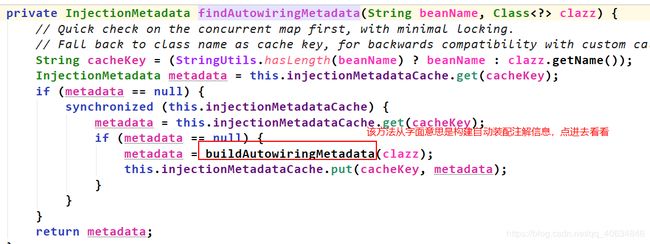
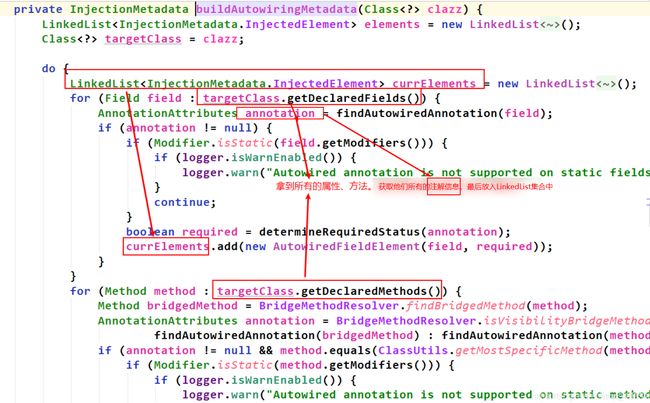
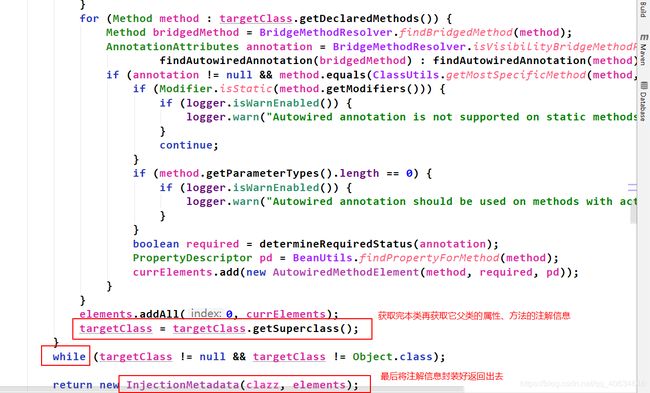
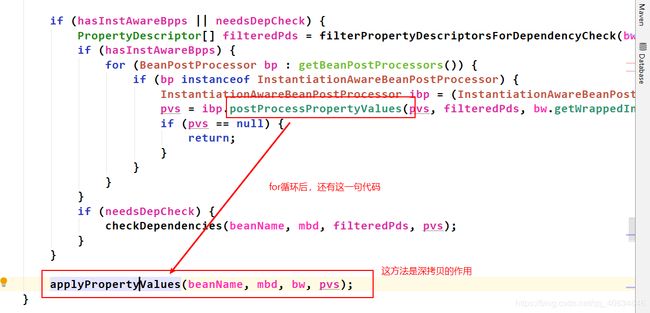
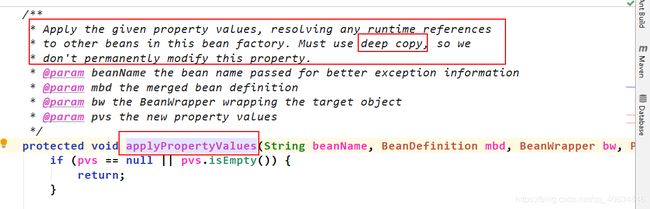
最后完成属性注入。
总结:属性注入的阶段,里面很多地方都用到了策略设计模式。
4.12 分析InitializeBean()(即分析生命周期的回调方法)
4.12.1 生命周期的回调方法的三种方式
注解方式;实现接口方式;xml方式
官方文档的介绍如下:
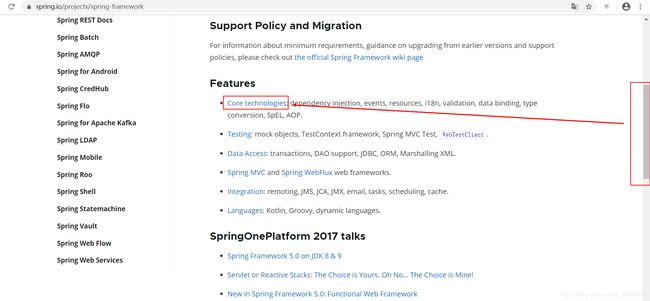
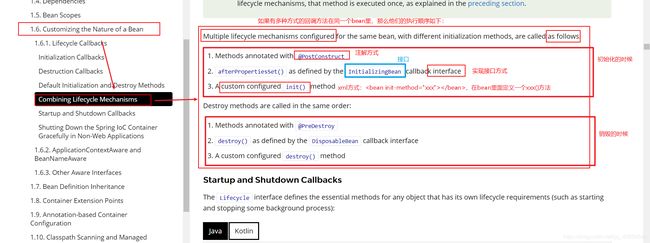
总结:首先执行的是注解方式,其次是实现接口方式,最后是xml方式。
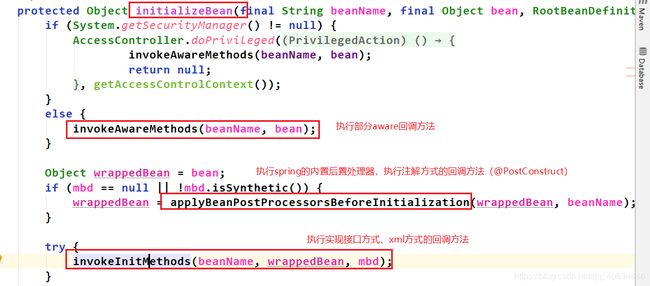
4.12.2 InitializeBean()里面的实现
生命周期的回调方法都在InitializeBean()里面。

4.13 spring bean完整生命周期总结
如下图,有点长,可以右击“在新建标签页打开”:
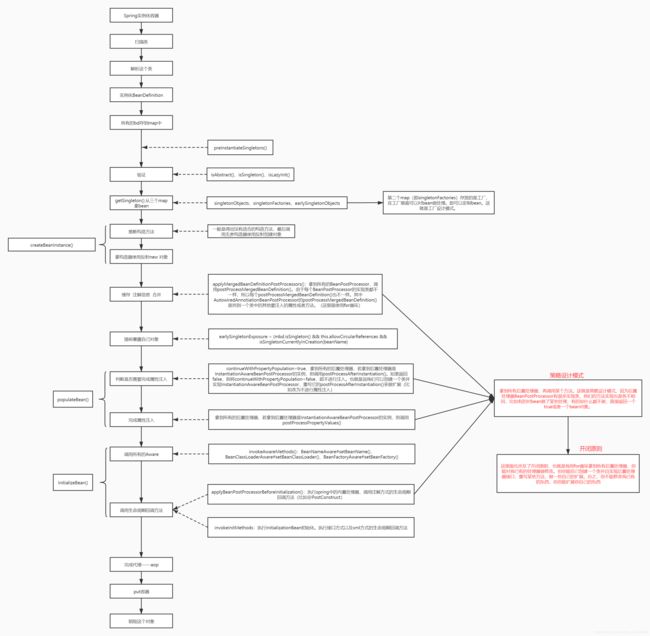
4.14 面试题:为什么需要3级缓存?
总结式回答:
- singletonObjects:单例池。单例对象只会实例化一次,所以需要一个单例池来缓存,原型(prototype)就不需要这个缓存
- singletonFactories:缓存的是一个工厂。主要为了解决循环依赖,利用工厂设计模式、策略设计模式生成一个合格的bean
- earlySingletonObjects:提高性能,解决重复创建的问题。
然后再根据本博客分析的详细阐述一下。