NoSQL-Redis学习1
前言:
学习视频地址:https://www.bilibili.com/video/BV1S54y1R7SB
redis的中文官网:http://www.redis.cn/
该篇文章主要用于扫盲
一.什么是redis
- Redis,即remote dictionary server,即远程字典服务
- 免费开源的
- C语言编写的
- 基于内存,可持久化的
- 支持网络
- Key-value数据库
- 提供多种语言的api
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings),散列(hashes),列表(lists),集合(sets), 有序集合(sorted sets) 与范围查询,bitmaps,hyperloglogs 和 地理空间(geospatial) 索引半径查询。Redis 内置了 复制(replication),LUA脚本(Lua scripting),LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence),并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
二.能干嘛
- 内存存储
- 持久化:RDB、AOF
- 用于高速缓存
- 发布订阅系统
- 地图信息分析
- 定时计数器:浏览量
三.特性
- 多样化的数据类型
- 持久化
- 集群
- 事务
四.windows安装
-
安装好之后,启动redis的服务端、客户端,并在客户端的命令行窗口执行如下图所示的操作

-
将redis在window操作系统中设置为一个service
windows中redis设置为服务、卸载服务、服务重命名的基本命令: - 安装服务 redis-server --service-install # 安装为服务后,便于后续操作 - 卸载服务 redis-server --service-uninstall - 服务重命名 redis-server --service-name server-name
五.Linux安装
此处略去一万字,查看网上安装教程,出门左拐
六.性能测试
-
redis-benchmark是一个压力测试工具(官方自带的)
-
参考文档:https://www.cnblogs.com/williamjie/p/11303965.html
-
操作及说明
# 在D:\java\software\install\redis目录下进入cmd窗口,执行如下命令 D:\java\software\install\redis>redis-benchmark -h 127.0.0.1 -p 6379 -c 100 -n 100000 -t set ====== SET ====== 写操作 100000 requests completed in 1.27 seconds # 10w个写请求在1.27秒内完成 100 parallel clients # 100个并发的客户端 3 bytes payload # 每次写入3byte的负载 keep alive: 1 # 只有一台服务器处理这些请求,即单机测试性能 55.16% <= 1 milliseconds # 1ms就处理了55.16% * 10w的写请求 98.49% <= 2 milliseconds # 2ms就处理了98.49% * 10w的写请求 99.66% <= 3 milliseconds 99.84% <= 4 milliseconds 99.88% <= 5 milliseconds 99.89% <= 6 milliseconds 99.90% <= 7 milliseconds 99.98% <= 8 milliseconds 100.00% <= 10 milliseconds 78492.93 requests per second # 每秒处理78492.93个写请求 -
redis是单线程,为啥还快?
官方数据显示:每秒的qps=10w+ 因为redis是基于内存操作的,全部数据都是放在内存里面的,CPU不是redis的性能瓶颈,他的瓶颈是内存和网络宽带。采用单线程不需要切换线程的上下文,因此不使用多线程,速度就快了。
七.基础知识
-
官方命令文档
https://www.redis.net.cn/order/
-
redis默认有16个数据库

-
默认使用的是第一个数据库,索引从零开始
127.0.0.1:6379> select 3 # 改为选择第4个数据库,使用该命令可以切换数据库,后面的数字表示数据库的索引号 OK 127.0.0.1:6379[3]> -
查看某个数据库的所有的key
127.0.0.1:6379[3]> keys * # 这里查看第四个数据库包含哪些key值 1) "pms:userMessage" 2) "pms:qa:list" 127.0.0.1:6379[3]> -
查看某个数据库的key的数量
127.0.0.1:6379[3]> dbsize # 这里查看第四个数据库中key的数量 (integer) 2 127.0.0.1:6379[3]> -
往某个数据库中添加键值对数据(或者将原本某个Key对应的value值进行覆盖)
127.0.0.1:6379[3]> set name zwt # 往第四个数据库中添加key=name value=zwt的键值对 OK 127.0.0.1:6379[3]> dbsize # 查看当前数据库中key的数量 (integer) 3 127.0.0.1:6379[3]> keys * # 查看当前数据库中的key都有哪些 1) "name" 2) "pms:userMessage" 3) "pms:qa:list" 127.0.0.1:6379[3]> get name # 查看key=name的对应的value值 "zwt" -
查看数据库中某个key值对应value值的类型
127.0.0.1:6379[3]> type name # 查看第四个数据库中key=name对应value值的类型 string -
清空某个数据库所有的键值对
127.0.0.1:6379> auth ejavashop # 验证密码 OK 127.0.0.1:6379> select 15 # 切换到第十六个数据库 OK 127.0.0.1:6379[15]> keys * # 查看第十六个数据库有无键值对 (empty list or set) 127.0.0.1:6379[15]> set girl axc # 添加键值对1 OK 127.0.0.1:6379[15]> get girl "axc" 127.0.0.1:6379[15]> set boy zwt # 添加键值对2 OK 127.0.0.1:6379[15]> keys * # 查看第十六个数据库的key包含哪些 1) "gril" 2) "boy" 127.0.0.1:6379[15]> flushdb # 清空第十六个数据库中所有的键值对 OK 127.0.0.1:6379[15]> keys * # 查看第十六个数据库的key包含哪些 (empty list or set) 127.0.0.1:6379[15]> -
清空redis16个数据库中所有的键值对
127.0.0.1:6379> flushall OK -
判断某个数据库中是否存在key=xx的键值对
127.0.0.1:6379> exists name # 判断第一个数据库中是否存在key=name的键值对 (integer) 1 # 返回1,说明存在;如果返回0,说明不存在 -
将某个键值对,从当前数据库,移动到其他数据库中
127.0.0.1:6379> keys * # 先查看第一个数据库中包含的键值,发现仅包含一个key=name的 1) "name" 127.0.0.1:6379> select 1 # 切换到第二个数据库 OK 127.0.0.1:6379[1]> keys * # 查看第二个数据库中包含的键值,发现此时为空 (empty list or set) 127.0.0.1:6379[1]> select 0 # 再切换到第一个数据库中 OK 127.0.0.1:6379> move name 1 # 将第一个数据库中的key=name的键值对,移动到第二个数据库中 (integer) 1 # 返回1,说明移动成功;返回0,说明移动失败 127.0.0.1:6379> keys * # 再查看下第一个数据库,发现已经没有键值对了 (empty list or set) 127.0.0.1:6379> select 1 # 切换到第二个数据库中 OK 127.0.0.1:6379[1]> keys * # 查看第二个数据库中的键值,发现刚刚第一个数据库迁移过来的键值 1) "name" 127.0.0.1:6379[1]> get name # 进一步查看这个对应的value值 "axc" 127.0.0.1:6379[1]> -
设置某个键值对的有效时间
127.0.0.1:6379[1]> keys * # 首先查看第二个数据库中的所有键值,发现仅有一个name 1) "name" 127.0.0.1:6379[1]> expire name 20 # 将key[name]-value[axc]的键值对设置20秒的有效时间 (integer) 1 # 返回1,说明设置成功;返回0,说明设置失败 127.0.0.1:6379[1]> ttl name # 查看key[name]的键值对距离失效时间的秒值 time to lose (integer) 17 # 发现还剩下17s失效,说明尚未失效 127.0.0.1:6379[1]> ttl name (integer) -2 # 发现还剩下-2s失效,说明已经失效 127.0.0.1:6379[1]> -
从某个数据库中移除某个键值对
127.0.0.1:6379[1]> set name zwt # 在第二个数据库中设置键值对key[name]-value[zwt] OK 127.0.0.1:6379[1]> keys * # 设置完成之后,查看 1) "name" 127.0.0.1:6379[1]> del name # 删除key[name]的键值对 (integer) 1 127.0.0.1:6379[1]> keys * # 删除完成之后,查看 (empty list or set) 127.0.0.1:6379[1]> -
总结一下命令:
1. auth ==密码== 2. ping 3. select ==数据库索引== 4. keys ==*== 5. dbsize 6. set ==key== ==value== 7. get ==key== 8. type ==key== 9. flushdb 10. flushall 11. exists ==key== 12. move ==key== ==数据库索引== 13. expire ==key== ==秒值== 14. ttl ==key== 15. del ==key==
八.五大基本数据类型
a. String(字符串)
0.前言
对应到redis中的结构就是:key-String
1.拼接字符串
append
127.0.0.1:6379[1]> set name zwt # 首先在第二个数据库中设置key[name]-value[zwt]的键值对
OK
127.0.0.1:6379[1]> set msg "hello " # 然后,在第二个数据库继续添加key[msg]-value["hello "]的键值对
OK
127.0.0.1:6379[1]> keys * # 查看第二个数据库中的键值
1) "msg"
2) "name"
127.0.0.1:6379[1]> get msg # 查看此时key[msg]对应的value值
"hello "
127.0.0.1:6379[1]> append msg "axc" # 在key[msg]对应的value值后面拼接字符串"axc"
(integer) 10 # 返回10,表示返回拼接后字符串的长度
127.0.0.1:6379[1]> get msg # 查看拼接后的字符串
"hello axc"
127.0.0.1:6379[1]>
2.数字类字符串-自增1、自增指定值、自减1、自减指定值
incr、incrby、decr、decrby
127.0.0.1:6379[1]> keys * # 此时第二个数据库中没有键值对
(empty list or set)
127.0.0.1:6379[1]> set num 0 # 在第二个数据库中,设置key[num]-value[0]的键值对,初始值0
OK
127.0.0.1:6379[1]> get num
"0"
127.0.0.1:6379[1]> incr num # 自增1,此时value为1
(integer) 1 # 返回自增结果值
127.0.0.1:6379[1]> get num # 确认下
"1"
127.0.0.1:6379[1]> incrby num 10 # 自增10,此时value为11
(integer) 11 # 返回增加结果
127.0.0.1:6379[1]> get num
"11"
127.0.0.1:6379[1]> decr num # 自减1,此时value=10
(integer) 10
127.0.0.1:6379[1]> get num
"10"
127.0.0.1:6379[1]> decrby num 5 # 自减5,此时value=5
(integer) 5
127.0.0.1:6379[1]> get num
"5"
127.0.0.1:6379[1]>
3.截取字符串
getrange
127.0.0.1:6379[1]> keys *
(empty list or set)
127.0.0.1:6379[1]> set msg "hello world"
OK
127.0.0.1:6379[1]> get msg
"hello world"
127.0.0.1:6379[1]> getrange msg 0 5 # 相当于"hello world".subString(0,5)
"hello "
127.0.0.1:6379[1]> getrange msg 1 4 # 相当于"hello world".subString(1,4)
"ello"
127.0.0.1:6379[1]> getrange msg 0 -1 # 相当于"hello world"
"hello world"
127.0.0.1:6379[1]> getrange msg 5 -1 # 相当于"hello world".subString(5)
" world"
127.0.0.1:6379[1]>
4.替换字符串
setrange
127.0.0.1:6379[1]> keys *
(empty list or set)
127.0.0.1:6379[1]> set msg "abcdef"
OK
127.0.0.1:6379[1]> get msg
"abcdef"
127.0.0.1:6379[1]> setrange msg 1 xx # 将“abcdef”中偏移量为1,即从b开始的字符,替换成xx
(integer) 6
127.0.0.1:6379[1]> get msg
"axxdef"
127.0.0.1:6379[1]>
5.添加键值对,同时设置有效时间
setex:set with expire
127.0.0.1:6379[1]> keys *
(empty list or set)
127.0.0.1:6379[1]> setex mykey 30 zwt # 设置key[mykey]-value[zwt],并且有效期30s
OK
127.0.0.1:6379[1]> ttl mykey # 查看距离失效时间还有多少秒
(integer) 25
127.0.0.1:6379[1]>
6.当数据库中某个key存在时,添加键值对失败;当数据库不存在某个key时,添加键值对成功
常用于分布式锁的操作中
setnx:if not exists, set
127.0.0.1:6379[1]> keys * # 首先,当前数据库为空
(empty list or set)
127.0.0.1:6379[1]> set mykey1 zwt # 先添加键值对key[mykey1]-value[zwt]
OK
127.0.0.1:6379[1]> setnx mykey1 zwt2 # 尝试添加键值对key[mykey1]-value[zwt2]
(integer) 0 # 0表示失败;1表示成功:因为此前已经添加过key[mykey1],因此提示失败
127.0.0.1:6379[1]> get mykey1
"zwt"
127.0.0.1:6379[1]> setnx mykey2 axc # 尝试添加键值对key[mykey2]-value[axc]
(integer) 1 # 0表示失败;1表示成功:因为此前没有添加过key[mykey2],因此提示成功
127.0.0.1:6379[1]> get mykey2
"axc"
127.0.0.1:6379[1]>
7.同时设置多个键值对、同时查看多个key对应的value值
mset
mget
msetnx:功能和setnx一样,不过可以一次性设置多个,注意这个是原子操作:要么全部成功;要么全部失败
127.0.0.1:6379[1]> keys *
(empty list or set)
127.0.0.1:6379[1]> mset k1 v1 k2 v2 k3 v3 # 在数据库中同时设置多个值
OK
127.0.0.1:6379[1]> keys *
1) "k1"
2) "k3"
3) "k2"
127.0.0.1:6379[1]> mget k1 k2 k3 # 在数据库中同时获取多个key对应的value值
1) "v1"
2) "v2"
3) "v3"
127.0.0.1:6379[1]> msetnx k1 v k4 v4
(integer) 0 # 返回0表示失败,那是因为msetnx和setnx功能一样
127.0.0.1:6379[1]> mget k1 k4
1) "v1" # 此处看到k1没有设置成v
2) (nil) # 此处看到k4没有设置成功
127.0.0.1:6379[1]>
127.0.0.1:6379[1]> keys *
(empty list or set)
127.0.0.1:6379[1]> mset user:1:name zwt user:1:age 27
OK
127.0.0.1:6379[1]> mget user:1:name user:1:age
1) "zwt"
2) "27"
127.0.0.1:6379[1]>

8.先get再set
getset
127.0.0.1:6379[1]> keys * # 此时数据库是空的
(empty list or set)
127.0.0.1:6379[1]> getset db mysql # 先取再设置
(nil) # 取到空值
127.0.0.1:6379[1]> get db
"mysql" # 看到设置的值
127.0.0.1:6379[1]> getset db redis # 先取再设置
"mysql" # 取到之前的值mysql
127.0.0.1:6379[1]> get db
"redis" # 看到设置的值redis
127.0.0.1:6379[1]>
9.总结一下命令
1. append
2. incr
3. incrby
4. decr
5. decrby
6. getrange
7. setrange
8. setex
9. setnx
10. mset
11. mget
12. msetnx
13. getset
使用场景说明:
1. 计数器 ==incr decr==
2. 统计多单位的数量 ==mset==
3. 粉丝数 ==incr decr==
4. 对象存储 ==mset==
b. List(列表)
1.前言
对应到redis中的结构就是:key-list
1. 在redis中可以把list玩成:栈、队列、阻塞队列
2. 所有的list相关命令都是,以L开头的
3. 这个list实则是一个链表
4. 可以做消息排队,即消息队列:LPUSH -> RPOP 或者 RPUSH -> LPOP
5. 可以作为一个栈:LPUSH -> LPOP 或者 RPUSH -> RPOP
2.往list中添加值、查看list中的值
LPUSH 列表名称 设置值 (left push:将值放在列表的头部,看查询结果那个先出)
RPUSH 列表名称 设置值 (right push:将值放在列表的尾部,看查询结果那个先出)
LRANGE 列表名称 起始位置 结束位置
127.0.0.1:6379[1]> keys * # 此处表明数据库为空
(empty list or set)
127.0.0.1:6379[1]> lpush myList axc #
(integer) 1
127.0.0.1:6379[1]> lpush myList zwt
(integer) 2
127.0.0.1:6379[1]> lpush myList py
(integer) 3
127.0.0.1:6379[1]> lrange myList 0 -1
1) "py"
2) "zwt"
3) "axc"
127.0.0.1:6379[1]> rpush myList wdp
(integer) 4
127.0.0.1:6379[1]> lrange myList 0 -1
1) "py"
2) "zwt"
3) "axc"
4) "wdp"
127.0.0.1:6379[1]>
| left | ——> | ——> | right |
|---|---|---|---|
| py | zwt | axc | wdp |
可以理解为:LPUSH是从管道的left方向往里面塞值、RPUSH是从管道的right方向往里面塞值、LRANGE是从管道的左侧一个一个的拿值。
3.移除List中的值
LPOP 列表名称 (从列表的左侧移除第一个值)
RPOP 列表名称(从列表的右侧移除第一个值)
127.0.0.1:6379[1]> lrange myList 0 -1 # 首先查看列表myList
1) "py"
2) "zwt"
3) "axc"
4) "wdp"
127.0.0.1:6379[1]> lpop myList # 从左边开始移除第一个值
"py" # 移除“py”成功
127.0.0.1:6379[1]> rpop myList # 从右边开始移除第一个值
"wdp" # 移除“wdp”成功
127.0.0.1:6379[1]> lrange myList 0 -1 # 首先查看列表myList
1) "zwt"
2) "axc"
127.0.0.1:6379[1]>
4.获取列表中指定索引的值
LINDEX 列表名称 索引
127.0.0.1:6379[1]> lrange myList 0 -1 # 先查看列表中所有的值
1) "zwt"
2) "axc"
127.0.0.1:6379[1]> lindex myList 0 # 从左侧开始,获取索引为0的值
"zwt"
127.0.0.1:6379[1]> lindex myList 1 # 从左侧开始,获取索引为1的值
"axc"
127.0.0.1:6379[1]> lindex myList 2 # 从左侧开始,获取索引为2的值
(nil) # 返回为空
127.0.0.1:6379[1]> rindex myList 0 # 不存在RINDEX这样的命令
(error) ERR unknown command 'rindex'
127.0.0.1:6379[1]>
5.获取列表的长度
LLEN 列表名称
127.0.0.1:6379[1]> lrange myList 0 -1 # 先查看列表中所有的值
1) "zwt"
2) "axc"
127.0.0.1:6379[1]> llen myList # 获取列表的长度
(integer) 2
127.0.0.1:6379[1]>
6.移除指定的值
LREM 列表名称 数量 值(从左侧移除指定数量的某个值)
127.0.0.1:6379[1]> lrange myList 0 -1 # 当前列表只有 "zwt" "axc" 两个值
1) "zwt"
2) "axc"
127.0.0.1:6379[1]> lpush myList axc # 往列表左边添加值"axc",结果为:"axc" "zwt" "axc"
(integer) 3
127.0.0.1:6379[1]> lrange myList 0 -1
1) "axc"
2) "zwt"
3) "axc"
127.0.0.1:6379[1]> lpush myList zwt # 往列表左边添加值"zwt",结果为:"zwt" "axc" "zwt" "axc"
(integer) 4
127.0.0.1:6379[1]> lrange myList 0 -1
1) "zwt"
2) "axc"
3) "zwt"
4) "axc"
127.0.0.1:6379[1]> lrem myList 1 axc # 往列表左边移除1个"axc",结果为:"zwt" "zwt" "axc"
(integer) 1
127.0.0.1:6379[1]> lrange myList 0 -1
1) "zwt"
2) "zwt"
3) "axc"
127.0.0.1:6379[1]> lrem myList 2 zwt # 往列表左边移除2个"zwt",结果为:"axc"
(integer) 2
127.0.0.1:6379[1]> lrange myList 0 -1
1) "axc"
127.0.0.1:6379[1]>
| left | right | ||
|---|---|---|---|
| zwt | axc | zwt | axc |
7.截取列表
LTRIM 列表名称 开始位置索引 结束位置索引
127.0.0.1:6379[1]> keys * # 数据库为空
(empty list or set)
127.0.0.1:6379[1]> rpush list a1 # 创建一个list,设置值a1,结果:a1
(integer) 1
127.0.0.1:6379[1]> rpush list a2 # 往list设置值a2,结果:a1 a2
(integer) 2
127.0.0.1:6379[1]> rpush list a3 # 往list设置值a3,结果:a1 a2 a3
(integer) 3
127.0.0.1:6379[1]> rpush list a4 # 往list设置值a4,结果:a1 a2 a3 a4
(integer) 4
127.0.0.1:6379[1]> lrange list 0 -1
1) "a1"
2) "a2"
3) "a3"
4) "a4"
127.0.0.1:6379[1]> ltrim list 1 2 # 从左侧开始,截取list,从下标1到下标2,结果:a2 a3
OK
127.0.0.1:6379[1]> lrange list 0 -1
1) "a2"
2) "a3"
127.0.0.1:6379[1]>
8.从列表右边开始,移除列表中第一个元素,并将该元素的值挪移到新的列表中
RPOPLPUSH 原始列表 目标列表
127.0.0.1:6379[1]> lrange list 0 -1 # 当前列表中的值:a2 a3
1) "a2"
2) "a3"
127.0.0.1:6379[1]> rpoplpush list list2 # 将list列表中右边的第一个值移除,并将该值添加到list2中
"a3"
127.0.0.1:6379[1]> lrange list 0 -1
1) "a2"
127.0.0.1:6379[1]> lrange list2 0 -1
1) "a3"
127.0.0.1:6379[1]>
9.判断数据库中存在某列表否?
和第七块中的基础知识中的exists一致
EXISTS 列表名称
127.0.0.1:6379[1]> keys * # 说明当前数据库为空
(empty list or set)
127.0.0.1:6379[1]> rpush list zwt # 在当前数据库中添加列表list,并从管道右边开始设置第一个值zwt,此时结果为: zwt
(integer) 1
127.0.0.1:6379[1]> rpush list gly # 从list右边开始,添加第二个值gly,结果为:zwt gly
(integer) 2
127.0.0.1:6379[1]> rpush list wxh # 从list右边开始,添加第三个值wxh,结果为:zwt gly wxh
(integer) 3
127.0.0.1:6379[1]> lrange list 0 -1 # 查看当前列表list中的元素(从左侧开始输出)
1) "zwt"
2) "gly"
3) "wxh"
127.0.0.1:6379[1]> exists list # 判断当前数据库中是否存在list
(integer) 1 # 返回1,说明存在
127.0.0.1:6379[1]> exists list2 # 判断当前数据库中是否存在list2
(integer) 0 # 返回0,说明不存在
127.0.0.1:6379[1]>
10.更新列表中指定索引的值
LSETT 列表名称 索引 待更新的值
127.0.0.1:6379[1]> keys * # 查看到当前数据库中仅有一个list
1) "list"
127.0.0.1:6379[1]> lrange list 0 -1 # 查看该list都有哪些值
1) "zwt"
2) "gly"
3) "wxh"
127.0.0.1:6379[1]> lset list 0 zwt2 # 从左侧开始,修改列表list中索引为0的值为zwt2
OK # 提示修改成功
127.0.0.1:6379[1]> lrange list 0 -1 # 查看一下,修改过后的结果
1) "zwt2"
2) "gly"
3) "wxh"
127.0.0.1:6379[1]>
注意:LSET这个命令,只能更新存在的list,并且待更新的索引必须存在,否则会报错。因此在使用该命令之前,可以先使用exists命令判断一下该list是否存在;其次,还要查看一下该列表的索引是否支持更换值
11.将某个元素插入到某个列表某个值的前面or后面
LINSERT 列表名称 before/after 值 待插入的值
127.0.0.1:6379[1]> lrange list 0 -1 # 查看列表list包含哪些元素:zwt gly wxh zwt
1) "zwt"
2) "gly"
3) "wxh"
4) "zwt"
127.0.0.1:6379[1]> linsert list before zwt one # 从list的左侧开始,在第一个zwt的前方(左侧)插入one
(integer) 5
127.0.0.1:6379[1]> lrange list 0 -1 # 插完结果:one zwt gly wxh zwt
1) "one"
2) "zwt"
3) "gly"
4) "wxh"
5) "zwt"
127.0.0.1:6379[1]> linsert list after zwt two # 从list的左侧开始,在第一个zwt的后方(右侧)插入two
(integer) 6
127.0.0.1:6379[1]> lrange list 0 -1 # 插完结果:one zwt two gly wxh zwt
1) "one"
2) "zwt"
3) "two"
4) "gly"
5) "wxh"
6) "zwt"
127.0.0.1:6379[1]>
c. set(集合)
1.前言
set中的值不能重复
对应到redis中的结构就是:key-set
2.创建set、并添加值、查看set
sadd set名称 添加的值
smembers set名称
127.0.0.1:6379[1]> keys * # 当前数据库为空
(empty list or set)
127.0.0.1:6379[1]> sadd myset zwt # 创建一个名叫myset的set,并添加第一个值zwt
(integer) 1 # 1表示添加成功
127.0.0.1:6379[1]> sadd myset zwt # 继续往myset中添加值zwt
(integer) 0 # 0表示添加失败
127.0.0.1:6379[1]> sadd myset gly # 继续往myset中添加值gly
(integer) 1
127.0.0.1:6379[1]> sadd myset wxh # 继续往myset中添加值wxh
(integer) 1
127.0.0.1:6379[1]> smembers myset # 查看myset中的成员
1) "zwt"
2) "gly"
3) "wxh"
127.0.0.1:6379[1]>
3.判断某个值是否在指定的set中
sismember 指定的set名称 某个值
127.0.0.1:6379[1]> keys * # 查看当前数据库中只有一个myset
1) "myset"
127.0.0.1:6379[1]> type myset # 查看key[myset]对应value值的类型
set # set类型
127.0.0.1:6379[1]> smembers myset # 查看myset的成员
1) "zwt"
2) "gly"
3) "wxh"
127.0.0.1:6379[1]> sismember myset zwt # 判断zwt这个值是否在myset中
(integer) 1 # 1表示在
127.0.0.1:6379[1]> sismember myset axc # 判断axc这个值是否在myset中
(integer) 0 # 0表示不在
127.0.0.1:6379[1]>
4.获取set的成员数量
scard set名称
127.0.0.1:6379[1]> keys * # 查看当前数据库中只有一个myset
1) "myset"
127.0.0.1:6379[1]> type myset # 查看key[myset]对应value值的类型
set # set类型
127.0.0.1:6379[1]> smembers myset # 查看myset的成员
1) "zwt"
2) "gly"
3) "wxh"
127.0.0.1:6379[1]> scard myset # 获取myset的成员数量
(integer) 3
127.0.0.1:6379[1]>
5.移除set中某个成员
srem set名称 待移除的成员
127.0.0.1:6379[1]> keys * # 查看当前数据库中只有一个myset
1) "myset"
127.0.0.1:6379[1]> smembers myset # 查看myset的成员
1) "zwt"
2) "gly"
3) "wxh"
127.0.0.1:6379[1]> srem myset zwt # 移除myset中的成员zwt
(integer) 1 # 1表示移除成功
127.0.0.1:6379[1]> srem myset zwt # 移除myset中的成员zwt
(integer) 0 # 0表示移除失败
127.0.0.1:6379[1]> smembers myset # 再查看下myset的成员
1) "gly"
2) "wxh"
127.0.0.1:6379[1]>
6.随机从set中抽出指定数量个元素
srandmember set名称 [指定数量]
说明:[]中的内容是缺省的,如果不写,默认抽1个
这个通常可以用来做抽奖什么的
127.0.0.1:6379[1]> keys * # 查看当前数据库中只有一个myset
1) "myset"
127.0.0.1:6379[1]> type myset # 查看key[myset]对应value值的类型
set # set类型
127.0.0.1:6379[1]> smembers myset # 查看myset的成员
1) "gly"
2) "axc"
3) "wxh"
4) "wdp"
5) "zwt"
6) "py"
127.0.0.1:6379[1]> srandmember myset # 从myset中随机获取1个成员
"wdp"
127.0.0.1:6379[1]> srandmember myset # 从myset中随机获取1个成员
"gly"
127.0.0.1:6379[1]> srandmember myset # 从myset中随机获取1个成员
"gly"
127.0.0.1:6379[1]> srandmember myset # 从myset中随机获取1个成员
"gly"
127.0.0.1:6379[1]> srandmember myset # 从myset中随机获取1个成员
"axc"
127.0.0.1:6379[1]> srandmember myset 2 # 从myset中随机获取2个成员
1) "wdp"
2) "gly"
127.0.0.1:6379[1]> srandmember myset 2 # 从myset中随机获取2个成员
1) "zwt"
2) "axc"
127.0.0.1:6379[1]>
7.随机从set中移除一个成员
spop set名称
127.0.0.1:6379[1]> keys * # 查看当前数据库中只有一个myset
1) "myset"
127.0.0.1:6379[1]> type myset # 查看key[myset]对应value值的类型
set
127.0.0.1:6379[1]> smembers myset # 查看myset的成员
1) "wdp"
2) "zwt"
3) "wxh"
4) "axc"
5) "py"
6) "gly"
127.0.0.1:6379[1]> spop myset # 随机移除myset中1个成员
"gly"
127.0.0.1:6379[1]> smembers myset
1) "wdp"
2) "zwt"
3) "wxh"
4) "axc"
5) "py"
127.0.0.1:6379[1]> spop myset # 随机移除myset中1个成员
"py"
127.0.0.1:6379[1]> smembers myset
1) "wdp"
2) "zwt"
3) "wxh"
4) "axc"
127.0.0.1:6379[1]>
8.将set中某个成员移动到另外一个set中
smove 源set 目标set 待移动的成员
127.0.0.1:6379[1]> keys * # 当前数据库包含两个键值对(已知value都是set类型的)
1) "set2"
2) "set1"
127.0.0.1:6379[1]> smembers set1 # 查看set1中元素
1) "zwt"
2) "gly"
3) "wxh"
4) "axc"
127.0.0.1:6379[1]> smembers set2 # 查看set2中元素
1) "py"
127.0.0.1:6379[1]> smove set1 set2 axc # 将set1中元素axc移动到set2中
(integer) 1
127.0.0.1:6379[1]> smembers set1 # 查看set1中元素
1) "zwt"
2) "gly"
3) "wxh"
127.0.0.1:6379[1]> smembers set2 # 查看set2中元素
1) "py"
2) "axc"
127.0.0.1:6379[1]>
9.差集、并集、交集
差集
sdiff 源set 待比较的set1 [待比较的set2…]
说明:源set 和其他待比较的set所特有的成员
并集
sunion 源set 待比较的set1 [待比较的set2…]
交集
sinter 源set 待比较的set1 [待比较的set2…]
注意:[]表示缺省,在这里表示任意数量集合的差集、并集、交集
应用场景:B站中共同关注,采用交集

127.0.0.1:6379[1]> keys * # 当前数据库有三个set: set1 set2 set3
1) "set2"
2) "set3"
3) "set1"
127.0.0.1:6379[1]> smembers set1 # set1中包含元素:a b c g
1) "c"
2) "b"
3) "a"
4) "g"
127.0.0.1:6379[1]> smembers set2 # set1中包含元素:b c d e
1) "c"
2) "b"
3) "e"
4) "d"
127.0.0.1:6379[1]> smembers set3 # set1中包含元素:c d f g
1) "c"
2) "g"
3) "f"
4) "d"
######################################################################################
127.0.0.1:6379[1]> sdiff set1 set2 set3 # set1 set2 set3中,set1中特有的元素
1) "a"
127.0.0.1:6379[1]> sdiff set1 set2 # set1 set2中,set1中特有的元素
1) "a"
2) "g"
127.0.0.1:6379[1]> sdiff set2 set1 set3 # set2 set1 set3中,set2中特有的元素
1) "e"
127.0.0.1:6379[1]> sdiff set2 set1 # set2 set1中,set2中特有的元素
1) "e"
2) "d"
######################################################################################
127.0.0.1:6379[1]> sunion set1 set2 # set1 set2中的并集
1) "c"
2) "b"
3) "e"
4) "a"
5) "d"
6) "g"
127.0.0.1:6379[1]> sunion set1 set2 set3 # set1 set2 set3中的并集
1) "c"
2) "b"
3) "e"
4) "a"
5) "f"
6) "d"
7) "g"
######################################################################################
127.0.0.1:6379[1]> sinter set1 set2 # set1 set2的交集
1) "c"
2) "b"
127.0.0.1:6379[1]> sinter set2 set3 # set2 set3的交集
1) "c"
2) "d"
127.0.0.1:6379[1]> sinter set3 set1 # set3 set1的交集
1) "c"
2) "g"
127.0.0.1:6379[1]> sinter set1 set2 set3 # set1 set2 set3的交集
1) "c"
127.0.0.1:6379[1]>
d. hash(哈希)
1.前言
将hash看成一个map即可,对应到redis中的结构就是:key-map,即key-结构
使用场景:更适合于对象的存储
2.创建hash、并添加值、查看值
创建hash,并添加一个值
hset hash名称 key值 value值
创建hash,并添加多个值
hmset hash名称 key1值 value1值 key2值 value2值 …
查看某个hash中某个key对应的value值
hget hash名称 key值
查看某个hash中某些key对应的value值
hmget hash名称 key1值 key2值 …
查看某个hash中所有的键值对
hgetall hash名称
127.0.0.1:6379[1]> keys * # 当前数据库为空
(empty list or set)
127.0.0.1:6379[1]> hset zwt age 12 # 在当前数据库创建hash[zwt],并设置key[age]-value[12]
(integer) 1
127.0.0.1:6379[1]> hget zwt age # 获取数据库中名叫zwt的hash中的key[age]对应的value值
"12"
127.0.0.1:6379[1]> hmset zwt gender male job java # 往hash[zwt]中设置key[gender]-value[male]、key[job]-value[java]这样两对键值对
OK
127.0.0.1:6379[1]> hmget zwt age gender job # 查看hash[zwt]中key[age]、key[gender]、key[job]对应的value值
1) "12"
2) "male"
3) "java"
127.0.0.1:6379[1]> hgetall zwt # 获取hash[zwt]中所有的键值对
1) "age" # key
2) "12" # value
3) "gender" # key
4) "male" # value
5) "job" # key
6) "java" # value
127.0.0.1:6379[1]> type zwt # 查看当前key[zwt]对应value的类型
hash # hash类型
127.0.0.1:6379[1]>
3.删除某个hash中的某个键值对
hdel hash名称 key值
127.0.0.1:6379[1]> keys * # 当前数据库中只有一个数据zwt
1) "zwt"
127.0.0.1:6379[1]> type zwt # 判断zwt对应的value值的类型
hash # hash类型
127.0.0.1:6379[1]> hgetall zwt # 获取zwt对应hash value中所有的键值对
1) "age"
2) "12"
3) "gender"
4) "male"
5) "job"
6) "java"
127.0.0.1:6379[1]> hdel zwt age # 删除zwt这个hash中key[age]的键值对
(integer) 1
127.0.0.1:6379[1]> hgetall zwt # 获取zwt对应hash value中所有的键值对
1) "gender"
2) "male"
3) "job"
4) "java"
127.0.0.1:6379[1]>
4.获取某个hash中键值对的个数
hlen hash名称
127.0.0.1:6379[1]> keys * # 当前数据库中只有一个数据zwt
1) "zwt"
127.0.0.1:6379[1]> type zwt # 判断zwt对应的value值的类型
hash # hash类型
127.0.0.1:6379[1]> hlen zwt # 获取zwt这个hash的键值对数量
(integer) 2
127.0.0.1:6379[1]> hgetall zwt # 为了验证对不对,查看zwt这个hash中键值对
1) "gender" # key
2) "male" # value
3) "job" # key
4) "java" # value
127.0.0.1:6379[1]>
5.判断某个Hash中是否存在key=指定值的键值对
hexists hash名称 指定名称的key
127.0.0.1:6379[1]> keys * # 当前数据库中只有一个数据zwt
1) "zwt"
127.0.0.1:6379[1]> type zwt # 判断zwt对应的value值的类型
hash
127.0.0.1:6379[1]> hgetall zwt # 获取zwt对应hash value中所有的键值对
1) "gender"
2) "male"
3) "job"
4) "java"
127.0.0.1:6379[1]> hexists zwt gender # 判断zwt这个hash是否存在key[gender]这样的键值对
(integer) 1 # 1表示存在
127.0.0.1:6379[1]> hexists zwt salary # 判断zwt这个hash是否存在key[salary]这样的键值对
(integer) 0 # 0表示不存在
127.0.0.1:6379[1]>
6.获取某个hash中所有的key、所有的value
获取某个hash中所有的Key值
hkeys hash名称
获取某个hash中所有的value值
hvals hash名称
127.0.0.1:6379[1]> keys * # 当前数据库中只有一个数据zwt
1) "zwt"
127.0.0.1:6379[1]> type zwt # 判断zwt对应的value值的类型
hash
127.0.0.1:6379[1]> hkeys zwt # 获取zwt这个hash中所有的Key值
1) "gender"
2) "job"
127.0.0.1:6379[1]> hvals zwt # 获取zwt这个hash中所有的value值
1) "male"
2) "java"
127.0.0.1:6379[1]> hgetall zwt
1) "gender"
2) "male"
3) "job"
4) "java"
127.0.0.1:6379[1]>
7.hash中某个键值对中value值的自增、自减
hash中某个键值对中value只的自增指定的数值
hincrby hash名称 key值 自增数量(正数)
hash中某个键值对中value只的自减指定的数值
hincrby hash名称 key值 自增数量(负数)
127.0.0.1:6379[1]> keys * # 当前数据库中只有一个数据movie
1) "movie"
127.0.0.1:6379[1]> type movie # 判断movie对应的value值的类型
hash
127.0.0.1:6379[1]> hgetall movie # 获取movie这个hash对应的键值对
1) "view"
2) "0"
127.0.0.1:6379[1]> hincrby movie view 10 # view从0增加10
(integer) 10 # 结果是10
127.0.0.1:6379[1]> hgetall movie
1) "view"
2) "10"
127.0.0.1:6379[1]> hincrby movie view -1 # view从10增加-1,即减1
(integer) 9 # 结果是9
127.0.0.1:6379[1]> hgetall movie
1) "view"
2) "9"
127.0.0.1:6379[1]>
8.hash中某个key存在时不设置键值对,key不存在时设置键值对
hsetnx hash名称 key值 value值
127.0.0.1:6379[1]> keys * # 当前数据库中只有一个数据movie
1) "movie"
127.0.0.1:6379[1]> type movie # 判断movie对应的value值的类型
hash
127.0.0.1:6379[1]> hgetall movie # 获取movie这个hash对应的键值对
1) "view"
2) "9"
127.0.0.1:6379[1]> hsetnx movie view 100 # 尝试给movie这个hash添加键值对key[view]-value[100]
(integer) 0 # 0表示失败
127.0.0.1:6379[1]> hsetnx movie amount 100w # 尝试给movie这个hash添加键值对key[amount]-value[100w]
(integer) 1 # 1表示成功
127.0.0.1:6379[1]> hgetall movie
1) "view"
2) "9"
3) "amount"
4) "100w"
127.0.0.1:6379[1]>
e. zset(有序集合)
1.前言
常用于排序
譬如说:公司员工薪资的存放、班级成绩表的存放、消息权重的、排行榜TOP N
2.创建zset、并添加值、查看值
创建zset,并添加值
zadd zset名称 分数 值1 [分数2 值2 …]
查看zset中的值(按照分数从小到大排序,不显示分数,仅显示值)
zrange zset名称 起始索引 结束索引
查看zset中的值(按照分数从大到小排序,不显示分数,仅显示值)
zrevrange zset名称 起始索引 结束索引
查看zset中的值(按照分数从小到大排序,显示分数,并显示值)
zrangebyscore zset名称 数轴左侧值 数轴右侧值 withscores
查看zset中的值(按照分数从小到大排序,不显示分数,仅显示值)
zrangebyscore zset名称 数轴左侧值 数轴右侧值
127.0.0.1:6379[1]> keys * # 当前数据库中没有任何值
(empty list or set)
127.0.0.1:6379[1]> zadd employee_salary 12000 zwt # 创建一个名叫employee_salary(员工薪资)的zset,并设置:zwt这个员工的薪资为12000
(integer) 1
127.0.0.1:6379[1]> zrange employee_salary 0 -1 # 查看employee_salary这个zset中都有哪些员工
1) "zwt"
127.0.0.1:6379[1]> zadd employee_salary 8000 axc 11500 gly 10000 wxh # 往employee_salary这个zset中设置:axc薪资8000、gly薪资11500、wxh薪资10000
(integer) 3
127.0.0.1:6379[1]> zrange employee_salary 0 -1 # 查看employee_salary这个zset中都有哪些员工(按照薪资从小到大排序)
1) "axc"
2) "wxh"
3) "gly"
4) "zwt"
127.0.0.1:6379[1]> zrevrange employee_salary 0 -1 # 查看employee_salary这个zset中都有哪些员工(按照薪资从大到小排序)
1) "zwt"
2) "gly"
3) "wxh"
4) "axc"
127.0.0.1:6379[1]> zrangebyscore employee_salary -inf inf withscores # 查看employee_salary这个zset中的员工薪资排序(按照薪资从小到大排序,其中-inf表示-∞、inf表示+∞)
1) "axc"
2) "8000"
3) "wxh"
4) "10000"
5) "gly"
6) "11500"
7) "zwt"
8) "12000"
127.0.0.1:6379[1]> zrangebyscore employee_salary 10000 inf withscores # 查看employee_salary这个zset中的员工薪资排序(即获取薪资在[10000,+∞)这个区间的,并且是从小到大的顺序的员工)
1) "wxh"
2) "10000"
3) "gly"
4) "11500"
5) "zwt"
6) "12000"
127.0.0.1:6379[1]> zrangebyscore employee_salary -inf 11500 withscores # 查看employee_salary这个zset中的员工薪资排序(即获取薪资在(-∞,11500]这个区间的,并且是从小到大的顺序的员工)
1) "axc"
2) "8000"
3) "wxh"
4) "10000"
5) "gly"
6) "11500"
127.0.0.1:6379[1]> zrangebyscore employee_salary 10000 11500 withscores # 查看employee_salary这个zset中的员工薪资排序(即获取薪资在[10000,11500]这个区间的,并且是从小到大的顺序的员工)
1) "wxh"
2) "10000"
3) "gly"
4) "11500"
127.0.0.1:6379[1]> zrangebyscore employee_salary 10000 11500 # 查看employee_salary这个zset中的员工薪资排序(即获取薪资在[10000,11500]这个区间的,并且是从小到大的顺序的员工,与上面的不一样,不展示薪资)
1) "wxh"
2) "gly"
127.0.0.1:6379[1]>
3.移除一个元素
zrem zset名称 移除的元素名称
场景:将公司某个员工辞退
127.0.0.1:6379[1]> keys * # 当前数据库中仅有一个数据 employee_salary
1) "employee_salary"
127.0.0.1:6379[1]> type employee_salary # 判断employee_salary的类型
zset
127.0.0.1:6379[1]> zrangebyscore employee_salary -inf inf withscores # 按照薪资从小到大顺序获取employee_salary中所有员工信息(包括薪资信息)
1) "axc"
2) "8000"
3) "wxh"
4) "10000"
5) "gly"
6) "11500"
7) "zwt"
8) "12000"
127.0.0.1:6379[1]> zrange employee_salary 0 -1 # 按照薪资从小到大顺序获取employee_salary中所有员工信息(不包括薪资信息)
1) "axc"
2) "wxh"
3) "gly"
4) "zwt"
127.0.0.1:6379[1]> zrem employee_salary axc # 移除employee_salary中的成员axc
(integer) 1
127.0.0.1:6379[1]> zrange employee_salary 0 -1 # 按照薪资从小到大顺序获取employee_salary中所有员工信息(不包括薪资信息)
1) "wxh"
2) "gly"
3) "zwt"
127.0.0.1:6379[1]> zrangebyscore employee_salary -inf inf withscores # 按照薪资从小到大顺序获取employee_salary中所有员工信息(包括薪资信息)
1) "wxh"
2) "10000"
3) "gly"
4) "11500"
5) "zwt"
6) "12000"
127.0.0.1:6379[1]>
4.获取zset中成员的个数
zcard zset名称
127.0.0.1:6379[1]> keys * # 当前数据库中仅有一个数据 employee_salary
1) "employee_salary"
127.0.0.1:6379[1]> type employee_salary # 判断employee_salary的类型
zset
127.0.0.1:6379[1]> zrange employee_salary 0 -1 # 按照薪资从小到大顺序获取employee_salary中所有员工信息(不包括薪资信息)
1) "wxh"
2) "gly"
3) "zwt"
127.0.0.1:6379[1]> zcard employee_salary # 获取employee_salary这个zset中成员的数量
(integer) 3
127.0.0.1:6379[1]>
5.获取zset中指定区间的数量
zcount zset名称 分数起始值 分数结束值
场景:获取薪资在[10000,11500]这个区间成员的数量
127.0.0.1:6379[1]> keys *
1) "employee_salary"
127.0.0.1:6379[1]> zrangebyscore employee_salary -inf inf withscores
1) "wxh"
2) "10000"
3) "gly"
4) "11500"
5) "zwt"
6) "12000"
127.0.0.1:6379[1]> zcount employee_salary 10000 11500 # 获取employee_salary这个zset中薪资在[10000,11500]区间的员工数量
(integer) 2
127.0.0.1:6379[1]>
九. 三种特殊类型数据
a. geo(地理位置)
1.前言
底层的实现原理:zset,因此可以使用zset相关命令操作geo
朋友的定位,附近的人,打车距离计算
中国城市经纬度查询网站:https://jingweidu.bmcx.com/
2.添加
将指定的地理空间位置(纬度、经度、名称)添加到指定的key中
命令:geoadd key 经度 纬度 value
说明:
- 我们一般会下载城市数据,直接通过java程序一次性全部导入
- 有效的经度:-180度到180度
- 有效的纬度:-85度到85度
127.0.0.1:6379> keys *
(empty list or set)
127.0.0.1:6379> geoadd china:city 116.23128 40.22077 beijing # 北京
(integer) 1
127.0.0.1:6379> geoadd china:city 121.48941 31.40527 shanghai 112.48699 37.94036 taiyuan # 上海、太原
(integer) 2
127.0.0.1:6379> geoadd china:city 120.21201 30.2084 hangzhou 114.02919 30.58203 wuhan # 杭州、武汉
(integer) 2
127.0.0.1:6379> geoadd china:city 113.6401 34.72468 zhenzhou 112.98626 28.25591 changsha # 郑州、长沙
(integer) 2
127.0.0.1:6379> geoadd china:city 110.30188 25.31402 guilin 106.54041 29.40268 chongqing # 桂林、重庆
(integer) 2
127.0.0.1:6379> geoadd china:city 113.27324 23.15792 guangzhou 113.88308 22.55329 shenzhen # 广州、深圳
(integer) 2
127.0.0.1:6379> geoadd china:city 114.16546 22.27534 hongkong 113.54913 22.19875 aomen # 香港、澳门
(integer) 2
127.0.0.1:6379> geoadd china:city 108.93425 34.23053 xian 103.71878 36.10396 lanzhou # 西安、兰州
(integer) 2
127.0.0.1:6379> geoadd china:city 91.13775 29.65262 lasa 88.31104 43.36378 wulumuqi # 拉萨、乌鲁木齐
(integer) 2
127.0.0.1:6379> geoadd china:city 113.6908 39.69873 hunyuan 113.14013 40.25585 datong # 浑源、大同
(integer) 2
127.0.0.1:6379> geoadd china:city 117.30983 39.71755 tianjin # 天津
(integer) 1
127.0.0.1:6379>
3.从给定的key中 获取指定城市的经纬度
geopos key member
127.0.0.1:6379> keys * # 看到当前数据库中仅有一个key
1) "china:city"
127.0.0.1:6379> geopos china:city beijing shanghai # 从key[china:city]中获取北京、上海的经纬度
1) 1) "116.23128265142440796"
2) "40.22076905438526495"
2) 1) "121.48941010236740112"
2) "31.40526993848380499"
127.0.0.1:6379>
4.返回两个指定城市之间的直线距离
geodist key member1 member2 [unit]
说明:
- key就是china:city
- member1就是第一个城市名称
- member2就是第二个城市名称
- []表示可选可不选,即缺省
- unit表示单位,不设置unit,获取到的距离是m(米),常用的单位有km(千米)、mi(英里)、ft(英尺)
27.0.0.1:6379> geodist china:city beijing shanghai
"1088644.3544" # 北京到上海的直线距离为1088644.3544米
127.0.0.1:6379> geodist china:city beijing shanghai km
"1088.6444" # 北京到上海的直线距离为1088.6444千米
127.0.0.1:6379>
5.以给定的经纬度为中心,找出某一半径内的元素
georadius key 经度 纬度 半径值 半径单位 [withdist] [withcoord] [count] [desc|asc]
说明:
- key就是china:city
- [withdist] 缺省值,带上后会将距离中心点的距离也展示出来
- [withcoord] 缺省值,带上后会将各个城市的经纬度展示出来
- [count]缺省值,限定返回结果的数量
- [desc|asc]缺省值,按照距离的大小顺序排序
127.0.0.1:6379> georadius china:city 116 30 500 km # 查找经纬度(116,30)为中心,半径为500km范围内城市的列表
1) "changsha"
2) "wuhan"
3) "hangzhou"
127.0.0.1:6379> georadius china:city 116 30 500 km withdist # 查找经纬度(116,30)为中心,半径为500km范围内城市的列表(并带上距离值)
1) 1) "changsha"
2) "351.2191"
2) 1) "wuhan"
2) "200.0396"
3) 1) "hangzhou"
2) "405.9331"
127.0.0.1:6379> georadius china:city 116 30 500 km withcoord # 查找经纬度(116,30)为中心,半径为500km范围内城市的列表(并带上经纬度值)
1) 1) "changsha"
2) 1) "112.98626035451889038"
2) "28.25590931465907119"
2) 1) "wuhan"
2) 1) "114.02918905019760132"
2) "30.58203052674790712"
3) 1) "hangzhou"
2) 1) "120.21200805902481079"
2) "30.20839995425554747"
127.0.0.1:6379> georadius china:city 116 30 500 km withcoord count 2 # 查找经纬度(116,30)为中心,半径为500km范围内城市的列表(并带上经纬度值,并限定返回两个)
1) 1) "wuhan"
2) 1) "114.02918905019760132"
2) "30.58203052674790712"
2) 1) "changsha"
2) 1) "112.98626035451889038"
2) "28.25590931465907119"
127.0.0.1:6379> georadius china:city 116 30 500 km withdist
1) 1) "changsha"
2) "351.2191"
2) 1) "wuhan"
2) "200.0396"
3) 1) "hangzhou"
2) "405.9331"
127.0.0.1:6379> georadius china:city 116 30 500 km withdist desc # 查找经纬度(116,30)为中心,半径为500km范围内城市的列表(并带上距离值,并按照距离的大小倒排)
1) 1) "hangzhou"
2) "405.9331"
2) 1) "changsha"
2) "351.2191"
3) 1) "wuhan"
2) "200.0396"
127.0.0.1:6379>
6.以给定的城市为中心,找出某一半径内的元素
georadiusbymember key member 半径值 半径单位 [withdist] [withcoord] [count] [desc|asc]
说明:
- key就是china:city
- [withdist] 缺省值,带上后会将距离中心点的距离也展示出来
- [withcoord] 缺省值,带上后会将各个城市的经纬度展示出来
- [count]缺省值,限定返回结果的数量
- [desc|asc]缺省值,按照距离的大小顺序排序
127.0.0.1:6379> georadiusbymember china:city beijing 1000 km withdist desc # 以北京为中心,1000km内城市,按照距离远近倒排
1) 1) "xian"
2) "927.5371"
2) 1) "zhenzhou"
2) "652.6135"
3) 1) "taiyuan"
2) "410.8418"
4) 1) "datong"
2) "262.4739"
5) 1) "hunyuan"
2) "224.2262"
6) 1) "tianjin"
2) "107.6344"
7) 1) "beijing"
2) "0.0000"
127.0.0.1:6379>
7.获取城市经纬度的geohash表示
geohash key member1 member2 …
127.0.0.1:6379> geohash china:city beijing shanghai
1) "wx4sucvncn0"
2) "wtw6st1uuq0"
127.0.0.1:6379>
8.使用zset相关命令操作geo
127.0.0.1:6379> keys * # 获取数据库中所有的key
1) "china:city"
127.0.0.1:6379> type china:city # 查看key[china:city]的类型
zset # 果然是zset类型
127.0.0.1:6379> zrange china:city 0 -1 # 查看china:city中包含的成员
1) "wulumuqi"
2) "lasa"
3) "guilin"
4) "chongqing"
5) "lanzhou"
6) "xian"
7) "taiyuan"
8) "aomen"
9) "shenzhen"
10) "hongkong"
11) "guangzhou"
12) "changsha"
13) "wuhan"
14) "hangzhou"
15) "shanghai"
16) "zhenzhou"
17) "hunyuan"
18) "tianjin"
19) "datong"
20) "beijing"
127.0.0.1:6379> zrem china:city wulumuqi # 移除china:city中的成员wulumuqi
(integer) 1
127.0.0.1:6379> zrange china:city 0 -1 # 查看china:city中包含的成员
1) "lasa"
2) "guilin"
3) "chongqing"
4) "lanzhou"
5) "xian"
6) "taiyuan"
7) "aomen"
8) "shenzhen"
9) "hongkong"
10) "guangzhou"
11) "changsha"
12) "wuhan"
13) "hangzhou"
14) "shanghai"
15) "zhenzhou"
16) "hunyuan"
17) "tianjin"
18) "datong"
19) "beijing"
127.0.0.1:6379>
b. hyperloglog(基数统计)
1.前言
1.什么是基数?
集合A{1,3,5,7,8}、集合B{1,3,5,8,10},那么基数=6
换句话说:基数就是去重后值的数量
2.redis中的hyperloglog是做基数统计的算法;
3.使用场景:比如网页访问UV,即统计某个网站访问用户的数量
4.优点:占用的内存是固定的,2^64个元素的计数,仅需要12kb
5.基数可以接受误差,存在0.81%的错误率
6.如果不允许误差,那么就使用set或者自己的数据类型即可
2.创建并添加、获取基数、合并
创建并添加
pfadd key element [element …]
获取基数
pfcount key [key …]
合并
pfmerge destkey sourcekey [sourcekey …]
127.0.0.1:6379> keys * # 当前数据库为空
(empty list or set)
127.0.0.1:6379> pfadd mykey a b c d e f g h i j # 创建第一组元素mykey
(integer) 1
127.0.0.1:6379> pfcount mykey # 统计mykey元素的基数=10
(integer) 10
127.0.0.1:6379> pfadd mykey2 i j k l m n o p q # 创建第二组元素mykey2
(integer) 1
127.0.0.1:6379> pfcount mykey2 # 统计mykey2元素的基数=9
(integer) 9
127.0.0.1:6379> pfmerge mykey3 mykey mykey2 # 合并两组元素 mykey mykey2,即取并集
OK
127.0.0.1:6379> pfcount mykey3 # 查看并集的基数=17
(integer) 17
127.0.0.1:6379> keys *
1) "mykey"
2) "mykey3"
3) "mykey2"
127.0.0.1:6379> type mykey
string
127.0.0.1:6379> type mykey2
string
127.0.0.1:6379> type mykey3
string
127.0.0.1:6379>
c. bitmap(位图)
1.前言
1.只有两个状态的,都可以使用位图
2.都是操作二进制来进行记录
2.使用场景:365天打卡,那么就使用365bit 1字节=8bit 那么就相当于46字节左右
2.创建,并设置值
setbit key offset value
- 设置或者清空key的value(字符串)在offset处的bit值。
- offset 表示bit的位置数,从0开始计,1字节的bit数组最大为7 。
- value只能是0或者1
举例说明1:
步骤一:SETBIT K1 1 1 :第1位上设置为1,即01000000
步骤二:SETBIT K1 7 1 :第7位设为1,即01000001
步骤三:SETBIT K1 9 1 : 第9位设为1。超出分1字节连接。即01000001 01000000
举例说明2(以365天打卡为例):
- offset 就是偏移量,譬如:一年中的第几天
- value 就是偏移量对应的值,譬如:这一天是否打卡
127.0.0.1:6379> keys *
(empty list or set)
127.0.0.1:6379> setbit record 1 0 # 打卡记录之:1[第一天]-0[未打卡]
(integer) 0
127.0.0.1:6379> setbit record 2 1 # 打卡记录之:2[第二天]-1[打卡]
(integer) 0
127.0.0.1:6379> setbit record 3 1 # 打卡记录之:3[第三天]-1[打卡]
(integer) 0
127.0.0.1:6379> setbit record 4 0 # 打卡记录之:4[第四天]-0[未打卡]
(integer) 0
127.0.0.1:6379> setbit record 5 1 # 打卡记录之:5[第五天]-1[打卡]
(integer) 0
127.0.0.1:6379> setbit record 6 1 # 打卡记录之:6[第六天]-1[打卡]
(integer) 0
127.0.0.1:6379> setbit record 7 0 # 打卡记录之:7[第七天]-0[未打卡]
(integer) 0
127.0.0.1:6379> setbit record 8 0 # 打卡记录之:8[第八天]-0[未打卡]
(integer) 0
127.0.0.1:6379> setbit record 9 1 # 打卡记录之:9[第九天]-1[打卡]
(integer) 0
127.0.0.1:6379> setbit record 90 1 # 打卡记录之:10[第十天]-1[打卡]
(integer) 0
127.0.0.1:6379>
3.查看某一天是否有打卡
getbit key offset
127.0.0.1:6379> getbit record 1
(integer) 0 # 未打卡
127.0.0.1:6379>
4.统计打卡的天数
bitcount key [start end]
说明:
- 统计字符串被设置为1的bit数。
- 一般情况下,给定的整个字符串都会被进行计数,通过指定额外的 start 或 end 参数,可以让计数只在特定的位上进行。
- start 和 end 参数的设置,都可以使用负数值:比如 -1 表示最后一个位,而 -2 表示倒数第二个位。
- start、end 是指bit组的字节的下标数,二者皆包含。
127.0.0.1:6379> bitcount record
(integer) 6 # 就是整个record中value值的累加,看1中的10天打卡记录中6个1,4个0,因此统计结果为6,小于10,说明缺勤了
127.0.0.1:6379>
十.Redis的事务
a.命令
- redis的事务常用的命令有:multi、exec、discard、watch、unwatch等
b.说明
MULTI命令用于开启一个事务,它总是返回OK。 参考下面的演示案例MULTI执行之后, 客户端可以继续向服务器发送任意多条命令, 这些命令不会立即被执行, 而是被放到一个队列中, 当EXEC命令被调用时, 所有队列中的命令才会被执行。- 通过调用
DISCARD, 客户端可以清空事务队列, 并放弃执行事务。参考下面的演示案例4 WATCH命令可以为 Redis 事务提供 check-and-set (CAS)行为(类似于mysql数据库中的version字段),即通过WATCH命令在redis中可以实现乐观锁。参考下面的演示案例5- 被
WATCH的键key会被监视,并会发觉这些键是否被改动过了。 如果有至少一个被监视的键在EXEC执行之前被修改了, 那么整个事务都会被取消,EXEC返回nil-reply来表示事务已经失败。参考演示案例5 UNWATCH命令,表示取消对某些键的WATCH- 当
EXEC被调用时, 不管事务是否成功执行, 对所有键的监视WATCH都会被取消。
c.事务中的错误
-
语法错误
在redis2.6.5版本之前,Redis 只执行事务中那些入队成功的命令,而忽略那些入队失败的命令
在redis2.6.5版本开始及之后,服务器会对命令入队失败的情况进行记录,并在客户端调用
EXEC命令时,拒绝执行并自动放弃这个事务。常见的语法错误,比如:命令错误
-
逻辑错误
常见的逻辑错误,比如:事务中的命令可能处理了错误类型的键,比如将列表命令用在了字符串键上面,诸如此类;1/0事件等等
d. redis不支持回滚
不支持回滚的优点:
- Redis 命令只会因为错误的语法而失败(并且这些问题不能在入队时发现),或是命令用在了错误类型的键上面:这也就是说,从实用性的角度来说,失败的命令是由编程错误造成的,而这些错误应该在开发的过程中被发现,而不应该出现在生产环境中。
- 因为不需要对回滚进行支持,所以 Redis 的内部可以保持简单且快速。
e.演示案例
下面的演示案例基于的redis版本是5.0.10
1.常规操作
127.0.0.1:6379> multi # 开启一个redis事务
OK # 事务开启成功
127.0.0.1:6379> set num 1 # 第一条命令
QUEUED # 第一条命令入队成功
127.0.0.1:6379> incr num # 第二条命令
QUEUED # 第二条命令入队成功
127.0.0.1:6379> incrby num 10 # 第三条命令
QUEUED # 第三条命令入队成功
127.0.0.1:6379> decr num # 第四条命令
QUEUED # 第四条命令入队成功
127.0.0.1:6379> decrby num 4 # 第五条命令
QUEUED # 第五条命令入队成功
127.0.0.1:6379> exec # 执行事务中的所有命令
1) OK # 第一条命令执行成功
2) (integer) 2 # 第二条命令执行成功,结果为2
3) (integer) 12 # 第三条命令执行成功,结果为12
4) (integer) 11 # 第四条命令执行成功,结果为11
5) (integer) 7 # 第五条命令执行成功,结果为7
127.0.0.1:6379>
2.语法错误
127.0.0.1:6379> multi # 开启一个redis事务
OK # 事务开启成功
127.0.0.1:6379> set num 1 # 第一条命令
QUEUED # 第一条命令入队成功
127.0.0.1:6379> incr num # 第二条命令
QUEUED # 第二条命令入队成功
127.0.0.1:6379> incrby num 10 # 第三条命令
QUEUED # 第三条命令入队成功
127.0.0.1:6379> de # 第四条命令(存在语法错误)
(error) ERR unknown command `de`, with args beginning with: # 第四条命令提示错误,入队失败
127.0.0.1:6379> decr num # 第五条命令
QUEUED # 第五条命令入队成功
127.0.0.1:6379> decrby num 4 # 第六条命令
QUEUED # 第六条命令入队成功
127.0.0.1:6379> exec # 执行事务中的所有命令
(error) EXECABORT Transaction discarded because of previous errors. # 提示事务被丢弃,即失败,因为第四条命令出现语法错误。都有语法错误了,不能忍,直接所有命令都不能执行
127.0.0.1:6379>
3.逻辑错误
127.0.0.1:6379> keys * # 此时数据库为空,没有key
(empty list or set)
127.0.0.1:6379> multi # 开启一个redis事务
OK # 事务开启成功
127.0.0.1:6379> set num 1 # 第一条命令,创建一个key[num],并设置value[1]
QUEUED # 第一条命令入队成功
127.0.0.1:6379> incr num # 第二条命令
QUEUED # 第二条命令入队成功
127.0.0.1:6379> discard # 清空当前事务队列,并放弃执行事务
OK # 放弃事务成功
127.0.0.1:6379> keys * # 再看一下当前数据库有没有Key
(empty list or set) # 没有key,说明刚刚事务中的第一条命令没有执行,换句话说,刚刚的事务放弃成功
127.0.0.1:6379>
4.取消事务
127.0.0.1:6379> multi # 开启一个redis事务
OK # 事务开启成功
127.0.0.1:6379> set a 12 # 第一条命令
QUEUED # 第一条命令入队成功
127.0.0.1:6379> lpop a # 第二条命令
QUEUED # 第二条命令入队成功
127.0.0.1:6379> exec # 执行事务中的所有命令
1) OK # 第一条命令执行成功
2) (error) WRONGTYPE Operation against a key holding the wrong kind of value # 第二条命令执行失败,这是因为在一个String类型的值上企图执行list相关的操作。
127.0.0.1:6379>
5.乐观锁
- 本段案例演示,模拟一个转账的过程:账户account1有1000元、账户account2有100元,打算从account1中转出500到account2中
# 这里定义两个账户account1 account2,其中account1中有1000元、account2中有100元
127.0.0.1:6379> keys *
1) "account2"
2) "account1"
127.0.0.1:6379> get account1
"1000"
127.0.0.1:6379> get account2
"100"
# 线程1先执行
127.0.0.1:6379> watch account1 account2 # 线程1监视account1、account2这两个账户
OK
127.0.0.1:6379> multi # 开启一个redis事务
OK
127.0.0.1:6379> decrby account1 500 # 第一条命令入队,命令内容:将account1的账户转出500块
QUEUED
127.0.0.1:6379> incrby account2 500 # 第二条命令入队,命令内容:将account2的账户转入500块
QUEUED
# 线程2执行
127.0.0.1:6379> set account1 0 # 线程2偷偷的将account1中的账户余额改为0
OK
127.0.0.1:6379>
# 线程1继续执行
127.0.0.1:6379> exec # 线程1继续执行命令exec
(nil) # 发现返回nil,不是OK! 这个事务执行失败,说明watch这个命令确实起到了监视的作用了
127.0.0.1:6379>
十一. 通过Jedis操作Redis
- 要使用我们的java来操作redis。jedis是官方推荐的java连接redis的开发工具,它是一个中间件。类似的还有lettuce
a.依赖
<dependencies>
<dependency>
<groupId>redis.clientsgroupId>
<artifactId>jedisartifactId>
<version>3.3.0version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>2.2.3version>
dependency>
dependencies>
b.代码测试
1.连接数据库
package com.zwt.jedis;
import redis.clients.jedis.Jedis;
public class TestConnection {
public static void main(String[] args) {
// 注意:这里创建的这个jedis的对象,其实就是对上述学到的redis命令、事务等概念的封装
Jedis jedis = new Jedis("127.0.0.1", 6379);
// 连接测试
System.out.println(jedis.ping()); // 输出PONG
}
}

2.事务案例
package com.zwt.jedis;
import com.alibaba.fastjson.JSONObject;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Transaction;
public class TestTx {
public static void main(String[] args) {
// 创建连接
Jedis jedis = new Jedis("127.0.0.1", 6379);
// 开启一个事务
Transaction multi = jedis.multi();
try {
// 创建用户1信息
JSONObject jsonObject1 = new JSONObject();
jsonObject1.put("name", "gly");
jsonObject1.put("age", 28);
String user1 = jsonObject1.toJSONString();
// 创建用户2信息
JSONObject jsonObject2 = new JSONObject();
jsonObject2.put("name", "wxh");
jsonObject2.put("age", 28);
String user2 = jsonObject2.toJSONString();
multi.set("user1", user1);
multi.set("user2", user2);
// 模拟测试逻辑错误,走放弃事务流程
// int i = 1/0;
// 执行事务
multi.exec();
} catch (Exception e) {
// 放弃事务
multi.discard();
e.printStackTrace();
} finally {
// 关闭连接
jedis.close();
}
}
}
十二. springboot集成redis
-
springboot2.x之后,原来使用的jedis被替换成了lettuce
-
jedis:采用的是直连,多个线程操作的话,是不安全的,如果想要避免不安全的,使用jedis pool连接池。基于BIO模型,性能低。
-
lettuce:采用的是Netty,实例实现了多个线程的共享,不存在多线程不安全的问题。基于NIO,性能高。
-
springboot所有配置类,都有一个自动配置类,自动配置类会绑定一个properties的配置文件
a. springboot中有关redis的自动配置类
/*
* Copyright 2012-2020 the original author or authors.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* https://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.springframework.boot.autoconfigure.data.redis;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.boot.autoconfigure.condition.ConditionalOnClass;
import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean;
import org.springframework.boot.autoconfigure.condition.ConditionalOnSingleCandidate;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisOperations;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.StringRedisTemplate;
/**
* {@link EnableAutoConfiguration Auto-configuration} for Spring Data's Redis support.
*
* @author Dave Syer
* @author Andy Wilkinson
* @author Christian Dupuis
* @author Christoph Strobl
* @author Phillip Webb
* @author Eddú Meléndez
* @author Stephane Nicoll
* @author Marco Aust
* @author Mark Paluch
* @since 1.0.0
*/
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass(RedisOperations.class)
@EnableConfigurationProperties(RedisProperties.class) // 该自动配置类绑定的properties配置文件
@Import({ LettuceConnectionConfiguration.class, JedisConnectionConfiguration.class })
public class RedisAutoConfiguration {
@Bean
@ConditionalOnMissingBean(name = "redisTemplate")
@ConditionalOnSingleCandidate(RedisConnectionFactory.class)
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<Object, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
@Bean
@ConditionalOnMissingBean
@ConditionalOnSingleCandidate(RedisConnectionFactory.class)
public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory redisConnectionFactory) {
StringRedisTemplate template = new StringRedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
}
b. RedisProperties类
由于该properties配置文件内容较多,因此仅仅猎取部分内容,如下
/*
* Copyright 2012-2020 the original author or authors.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* https://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.springframework.boot.autoconfigure.data.redis;
import java.time.Duration;
import java.util.List;
import org.springframework.boot.context.properties.ConfigurationProperties;
/**
* Configuration properties for Redis.
*
* @author Dave Syer
* @author Christoph Strobl
* @author Eddú Meléndez
* @author Marco Aust
* @author Mark Paluch
* @author Stephane Nicoll
* @since 1.0.0
*/
@ConfigurationProperties(prefix = "spring.redis") // 看到这些,基本上就知道怎么配置了
public class RedisProperties {
/**
* Database index used by the connection factory.
*/
private int database = 0;
/**
* Connection URL. Overrides host, port, and password. User is ignored. Example:
* redis://user:[email protected]:6379
*/
private String url;
/**
* Redis server host.
*/
private String host = "localhost";
/**
* Login username of the redis server.
*/
private String username;
/**
* Login password of the redis server.
*/
private String password;
/**
* Redis server port.
*/
private int port = 6379;
/**
* Whether to enable SSL support.
*/
private boolean ssl;
/**
* Read timeout.
*/
private Duration timeout;
/**
* Connection timeout.
*/
private Duration connectTimeout;
/**
* Client name to be set on connections with CLIENT SETNAME.
*/
private String clientName;
/**
* Type of client to use. By default, auto-detected according to the classpath.
*/
private ClientType clientType;
private Sentinel sentinel;
private Cluster cluster;
private final Jedis jedis = new Jedis();
private final Lettuce lettuce = new Lettuce();
c. properties配置
spring.redis.host=127.0.0.1
spring.redis.port=6379
# 连接池1
# spring.redis.jedis.pool.max-active=8
# spring.redis.jedis.pool.max-idle=8
# spring.redis.jedis.pool.max-wait=-1ms
# spring.redis.jedis.pool.min-idle=0
# spring.redis.jedis.pool.time-between-eviction-runs=
# 连接池2
# spring.redis.lettuce.pool.max-active=8
# spring.redis.lettuce.pool.max-idle=8
# spring.redis.lettuce.pool.max-wait=-1ms
# spring.redis.lettuce.pool.min-idle=0
# spring.redis.lettuce.pool.time-between-eviction-runs=
说明:我们可以配置redis的连接池。在旧版中,使用的连接池是jedis.pool如上连接池1;在springboot2.x之后,原来使用的jedis被替换成了lettuce,也就是使用了连接池2。我们可以从项目中引入的依赖、代码是否正常来判断出:用的究竟是jedis还是lettuce。
-
查看a中代码的两个方法,都包含入参RedisConnectionFactory,这是redis的连接工厂。点进去发现是一个接口,如下:
/* * Copyright 2011-2021 the original author or authors. * * Licensed under the Apache License, Version 2.0 (the "License"); * you may not use this file except in compliance with the License. * You may obtain a copy of the License at * * https://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ package org.springframework.data.redis.connection; import org.springframework.dao.support.PersistenceExceptionTranslator; /** * Thread-safe factory of Redis connections. * * @author Costin Leau * @author Christoph Strobl */ public interface RedisConnectionFactory extends PersistenceExceptionTranslator { /** * Provides a suitable connection for interacting with Redis. * * @return connection for interacting with Redis. */ RedisConnection getConnection(); /** * Provides a suitable connection for interacting with Redis Cluster. * * @return * @since 1.7 */ RedisClusterConnection getClusterConnection(); /** * Specifies if pipelined results should be converted to the expected data type. If false, results of * {@link RedisConnection#closePipeline()} and {RedisConnection#exec()} will be of the type returned by the underlying * driver This method is mostly for backwards compatibility with 1.0. It is generally always a good idea to allow * results to be converted and deserialized. In fact, this is now the default behavior. * * @return Whether or not to convert pipeline and tx results */ boolean getConvertPipelineAndTxResults(); /** * Provides a suitable connection for interacting with Redis Sentinel. * * @return connection for interacting with Redis Sentinel. * @since 1.4 */ RedisSentinelConnection getSentinelConnection(); } -
查看RedisConnectionFactory这个接口的实现类,如下图,会发现有两个

-
进入JedisConnectionFactory这个实现类,发现代码爆红,出错,这是因为相关的依赖未导入进入,即当前的springboot版本的redis并没有基于jedis;而LettuceConnectionFactory这个实现类,代码正常,没有爆红,这是因为相关的依赖导入了,即当前的springboot版本的redis基于lettuce


e.使用官方默认的RedisTemplate操作
-
这个RedisTemplate就是a中的自动配置类创建的Bean,可以直接拿来使用
package com.zwt.springbootredisdemo; import org.junit.jupiter.api.Test; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.data.redis.connection.RedisConnection; import org.springframework.data.redis.connection.RedisConnectionFactory; import org.springframework.data.redis.core.RedisTemplate; @SpringBootTest class SpringbootRedisDemoApplicationTests { @Autowired private RedisTemplate redisTemplate; /** * 基本上和API保持一致 * 我们常用的方法、事务、等操作都被封装到了redisTemplate中了 * */ @Test void contextLoads() { // 操作String redisTemplate.opsForValue(); // 操作List redisTemplate.opsForList(); // 操作Set redisTemplate.opsForSet(); // 操作Zset redisTemplate.opsForZSet(); // 操作Hash redisTemplate.opsForHash(); // 操作Geo redisTemplate.opsForGeo(); // 操作HyperLogLog redisTemplate.opsForHyperLogLog(); // 开启事务 redisTemplate.multi(); // 执行事务 redisTemplate.exec(); // 放弃事务 redisTemplate.discard(); // 监控 redisTemplate.watch("num"); // 放弃监控 redisTemplate.unwatch(); // 获取连接工厂 RedisConnectionFactory connectionFactory = redisTemplate.getConnectionFactory(); // 获取连接 RedisConnection connection = connectionFactory.getConnection(); // 清空当前数据库 connection.flushDb(); // 清空redis中所有数据库 connection.flushAll(); } } -
官方默认的RestTemplate使用的序列化是JdkSerializationRedisSerializer
可以查看RestTemplate的源码看到,如下截图


f.使用自定义的RestTemplate操作
-
在e中介绍了一些官方默认的RestTemplate内容,这个有很多不便,比如说泛型,默认的是Object-Object,我们更希望的是String-Object的;其次,默认采用的序列化器是JDK,我们希望使用Jackson的等等。
-
使用JDK的序列化器会出现如下情况
127.0.0.1:6379> keys * 1) "\xac\xed\x00\x05t\x00\x05user1" 127.0.0.1:6379>这个key完全看不懂是啥了,实际上这个key[user1],这是因为JDK序列化器处理的结果。因此为了方便查看,我们需要自定义序列化器。自定义序列化器,看下面的自定义RestTemplate
-
key-value[Object]中的value倘若要存放自定义类的对象,比如自定义了一个User类,我们创建一个User对象zwt,要将之放到缓存中,那么需要注意的一点是:该User类必须implement Serializable接口,否则会报错!

-
自定义RestTemplate
import com.fasterxml.jackson.annotation.JsonAutoDetect; import com.fasterxml.jackson.annotation.PropertyAccessor; import com.fasterxml.jackson.databind.ObjectMapper; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.data.redis.connection.RedisConnectionFactory; import org.springframework.data.redis.core.RedisTemplate; import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer; import org.springframework.data.redis.serializer.StringRedisSerializer; @Configuration public class RedisConfig { // 1.将泛型设置为String-Object // 2.序列化配置 // 这是一个固定模板,企业中可以直接使用 @Bean @SuppressWarnings("all") public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) { // 使用String-Object RedisTemplate<String, Object> template = new RedisTemplate<String, Object>(); template.setConnectionFactory(factory); // Json序列化的配置 Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class); ObjectMapper om = new ObjectMapper(); om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY); om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL); jackson2JsonRedisSerializer.setObjectMapper(om); // String的序列化 StringRedisSerializer stringRedisSerializer = new StringRedisSerializer(); // key采用String的序列化方式 template.setKeySerializer(stringRedisSerializer); // hash的key也采用String的序列化方式 template.setHashKeySerializer(stringRedisSerializer); // value序列化方式采用jackson template.setValueSerializer(jackson2JsonRedisSerializer); // hash的value序列化方式采用jackson template.setHashValueSerializer(jackson2JsonRedisSerializer); template.afterPropertiesSet(); return template; } } -
基于自定义的RedisConfig,创建自定义的redis工具类,封装redis相关API的操作,便于项目开发
import org.springframework.beans.factory.annotation.Autowired; import org.springframework.data.redis.core.RedisTemplate; import org.springframework.stereotype.Component; import org.springframework.util.CollectionUtils; import java.util.List; import java.util.Map; import java.util.Set; import java.util.concurrent.TimeUnit; /** * Redis工具类 */ @Component public final class RedisUtil { @Autowired private RedisTemplate<String, Object> redisTemplate; // =============================common============================ /** * 指定缓存失效时间 * @param key 键 * @param time 时间(秒) * @return */ public boolean expire(String key, long time) { try { if (time > 0) { redisTemplate.expire(key, time, TimeUnit.SECONDS); } return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** * 根据key 获取过期时间 * 从redis中获取key对应的过期时间; * 如果该值有过期时间,就返回相应的过期时间; * 如果该值没有设置过期时间,就返回-1; * 如果没有该值,就返回-2; * @param key 键 不能为null * @return 时间(秒) 返回0代表为永久有效 */ public long getExpire(String key) { return redisTemplate.getExpire(key, TimeUnit.SECONDS); } /** * 判断key是否存在 * @param key 键 * @return true 存在 false不存在 */ public boolean hasKey(String key) { try { return redisTemplate.hasKey(key); } catch (Exception e) { e.printStackTrace(); return false; } } /** * 删除缓存 * @param key 可以传一个值 或多个 */ @SuppressWarnings("unchecked") public void del(String... key) { if (key != null && key.length > 0) { if (key.length == 1) { redisTemplate.delete(key[0]); } else { redisTemplate.delete(CollectionUtils.arrayToList(key)); } } } // ============================String============================= /** * 普通缓存获取 * @param key 键 * @return 值 */ public Object get(String key) { return key == null ? null : redisTemplate.opsForValue().get(key); } /** * 普通缓存放入 * @param key 键 * @param value 值 * @return true成功 false失败 */ public boolean set(String key, Object value) { try { redisTemplate.opsForValue().set(key, value); return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** * 普通缓存放入并设置时间 * @param key 键 * @param value 值 * @param time 时间(秒) time要大于0 如果time小于等于0 将设置无限期 * @return true成功 false 失败 */ public boolean set(String key, Object value, long time) { try { if (time > 0) { redisTemplate.opsForValue().set(key, value, time, TimeUnit.SECONDS); } else { set(key, value); } return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** * 递增 * @param key 键 * @param delta 要增加几(大于0) * @return */ public long incr(String key, long delta) { if (delta < 0) { throw new RuntimeException("递增因子必须大于0"); } return redisTemplate.opsForValue().increment(key, delta); } /** * 递减 * @param key 键 * @param delta 要减少几(小于0) * @return */ public long decr(String key, long delta) { if (delta < 0) { throw new RuntimeException("递减因子必须大于0"); } return redisTemplate.opsForValue().increment(key, -delta); } // ================================Map================================= /** * HashGet * @param key 键 不能为null * @param item 项 不能为null * @return 值 */ public Object hget(String key, String item) { return redisTemplate.opsForHash().get(key, item); } /** * 获取hashKey对应的所有键值 * @param key 键 * @return 对应的多个键值 */ public Map<Object, Object> hmget(String key) { return redisTemplate.opsForHash().entries(key); } /** * HashSet * @param key 键 * @param map 对应多个键值 * @return true 成功 false 失败 */ public boolean hmset(String key, Map<String, Object> map) { try { redisTemplate.opsForHash().putAll(key, map); return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** * HashSet * @param key 键 * @param map 对应多个键值 * @return true 成功 false 失败 */ public boolean hmset2(String key, Map<String, String> map) { try { redisTemplate.opsForHash().putAll(key, map); return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** * HashSet 并设置时间 * @param key 键 * @param map 对应多个键值 * @param time 时间(秒) * @return true成功 false失败 */ public boolean hmset(String key, Map<String, Object> map, long time) { try { redisTemplate.opsForHash().putAll(key, map); if (time > 0) { expire(key, time); } return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** * 向一张hash表中放入数据,如果不存在将创建 * @param key 键 * @param item 项 * @param value 值 * @return true 成功 false失败 */ public boolean hset(String key, String item, Object value) { try { redisTemplate.opsForHash().put(key, item, value); return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** * 向一张hash表中放入数据,如果不存在将创建 * @param key 键 * @param item 项 * @param value 值 * @param time 时间(秒) 注意:如果已存在的hash表有时间,这里将会替换原有的时间 * @return true 成功 false失败 */ public boolean hset(String key, String item, Object value, long time) { try { redisTemplate.opsForHash().put(key, item, value); if (time > 0) { expire(key, time); } return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** * 删除hash表中的值 * @param key 键 不能为null * @param item 项 可以使多个 不能为null */ public void hdel(String key, Object... item) { redisTemplate.opsForHash().delete(key, item); } /** * 判断hash表中是否有该项的值 * @param key 键 不能为null * @param item 项 不能为null * @return true 存在 false不存在 */ public boolean hHasKey(String key, String item) { return redisTemplate.opsForHash().hasKey(key, item); } /** * hash递增 如果不存在,就会创建一个 并把新增后的值返回 * @param key 键 * @param item 项 * @param by 要增加几(大于0) * @return */ public double hincr(String key, String item, double by) { return redisTemplate.opsForHash().increment(key, item, by); } /** * hash递减 * @param key 键 * @param item 项 * @param by 要减少记(小于0) * @return */ public double hdecr(String key, String item, double by) { return redisTemplate.opsForHash().increment(key, item, -by); } // ============================set============================= /** * 根据key获取Set中的所有值 * @param key 键 * @return */ public Set<Object> sGet(String key) { try { return redisTemplate.opsForSet().members(key); } catch (Exception e) { e.printStackTrace(); return null; } } /** * 根据value从一个set中查询,是否存在 * @param key 键 * @param value 值 * @return true 存在 false不存在 */ public boolean sHasKey(String key, Object value) { try { return redisTemplate.opsForSet().isMember(key, value); } catch (Exception e) { e.printStackTrace(); return false; } } /** * 将数据放入set缓存 * @param key 键 * @param values 值 可以是多个 * @return 成功个数 */ public long sSet(String key, Object... values) { try { return redisTemplate.opsForSet().add(key, values); } catch (Exception e) { e.printStackTrace(); return 0; } } /** * 将set数据放入缓存 * @param key 键 * @param time 时间(秒) * @param values 值 可以是多个 * @return 成功个数 */ public long sSetAndTime(String key, long time, Object... values) { try { Long count = redisTemplate.opsForSet().add(key, values); if (time > 0) expire(key, time); return count; } catch (Exception e) { e.printStackTrace(); return 0; } } /** * 获取set缓存的长度 * @param key 键 * @return */ public long sGetSetSize(String key) { try { return redisTemplate.opsForSet().size(key); } catch (Exception e) { e.printStackTrace(); return 0; } } /** * 移除值为value的 * @param key 键 * @param values 值 可以是多个 * @return 移除的个数 */ public long setRemove(String key, Object... values) { try { Long count = redisTemplate.opsForSet().remove(key, values); return count; } catch (Exception e) { e.printStackTrace(); return 0; } } // ===============================list================================= /** * 获取list缓存的内容 * @param key 键 * @param start 开始 * @param end 结束 0 到 -1代表所有值 * @return */ public List<Object> lGet(String key, long start, long end) { try { return redisTemplate.opsForList().range(key, start, end); } catch (Exception e) { e.printStackTrace(); return null; } } /** * 获取list缓存的长度 * @param key 键 * @return */ public long lGetListSize(String key) { try { return redisTemplate.opsForList().size(key); } catch (Exception e) { e.printStackTrace(); return 0; } } /** * 通过索引 获取list中的值 * @param key 键 * @param index 索引 index>=0时, 0 表头,1 第二个元素,依次类推;index<0时,-1,表尾,-2倒数第二个元素,依次类推 * @return */ public Object lGetIndex(String key, long index) { try { return redisTemplate.opsForList().index(key, index); } catch (Exception e) { e.printStackTrace(); return null; } } /** * 将list放入缓存 * @param key 键 * @param value 值 * @return */ public boolean lSet(String key, Object value) { try { redisTemplate.opsForList().rightPush(key, value); return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** * 将list放入缓存 * @param key 键 * @param value 值 * @param time 时间(秒) * @return */ public boolean lSet(String key, Object value, long time) { try { redisTemplate.opsForList().rightPush(key, value); if (time > 0) expire(key, time); return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** * 将list放入缓存 * @param key 键 * @param value 值 * @return */ public boolean lSet(String key, List<Object> value) { try { redisTemplate.opsForList().rightPushAll(key, value); return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** * 将list放入缓存 * * @param key 键 * @param value 值 * @param time 时间(秒) * @return */ public boolean lSet(String key, List<Object> value, long time) { try { redisTemplate.opsForList().rightPushAll(key, value); if (time > 0) expire(key, time); return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** * 根据索引修改list中的某条数据 * @param key 键 * @param index 索引 * @param value 值 * @return */ public boolean lUpdateIndex(String key, long index, Object value) { try { redisTemplate.opsForList().set(key, index, value); return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** * 移除N个值为value * @param key 键 * @param count 移除多少个 * @param value 值 * @return 移除的个数 */ public long lRemove(String key, long count, Object value) { try { Long remove = redisTemplate.opsForList().remove(key, count, value); return remove; } catch (Exception e) { e.printStackTrace(); return 0; } } }
十三. redis配置文件详解
- 我们启动redis服务,就是使用redis的配置文件来启动的
a. 配置文件:单位

b. 配置文件:包含
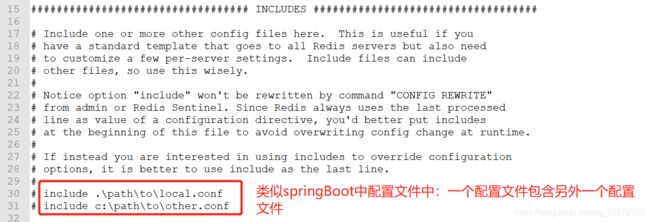
c. 配置文件:通用
################################ GENERAL #####################################
# 注意在windows中不支持守护进程,但是在Linux中支持
# On Windows, daemonize and pidfile are not supported.
# However, you can run redis as a Windows service, and specify a logfile.
# The logfile will contain the pid.
# Accept connections on the specified port, default is 6379.
# If port 0 is specified Redis will not listen on a TCP socket.
port 6379
# By default Redis listens for connections from all the network interfaces
# available on the server. It is possible to listen to just one or multiple
# interfaces using the "bind" configuration directive, followed by one or
# more IP addresses.
#
# Examples:
#
# bind 192.168.1.100 10.0.0.1
bind 127.0.0.1
# Close the connection after a client is idle for N seconds (0 to disable)
timeout 0
# 日志级别
# Specify the server verbosity level.
# This can be one of:
# debug (a lot of information, useful for development/testing)
# verbose (many rarely useful info, but not a mess like the debug level)
# notice (moderately verbose, what you want in production probably)
# warning (only very important / critical messages are logged)
loglevel notice
# 生成的日志文件名称在此设置
# Specify the log file name. Also 'stdout' can be used to force
# Redis to log on the standard output.
logfile ""
# 默认设置的数据库数量是16个
# Set the number of databases. The default database is DB 0, you can select
# a different one on a per-connection basis using SELECT where
# dbid is a number between 0 and 'databases'-1
databases 16
d. 配置文件:快照
1. 快照,即持久化:在规定的时间内,执行多少次操作,则会持久化到文件中
2. 持久化的文件包含两类:rdb文件、aof文件
3. redis是内存数据库,如果没有持久化,就会在断电的时候丢失数据,因此需要持久化
################################ SNAPSHOTTING ################################
# 持久化规则如下
# Save the DB on disk:
#
# save
#
# Will save the DB if both the given number of seconds and the given
# number of write operations against the DB occurred.
#
# In the example below the behaviour will be to save:
# after 900 sec (15 min) if at least 1 key changed
# after 300 sec (5 min) if at least 10 keys changed
# after 60 sec if at least 10000 keys changed
#
# Note: you can disable saving completely by commenting out all "save" lines.
#
# It is also possible to remove all the previously configured save
# points by adding a save directive with a single empty string argument
# like in the following example:
#
# save ""
save 900 1 # 如果在900秒内,至少1个key进行了修改,那么进行持久化操作
save 300 10 # 如果在300秒内,至少10个key进行了修改,那么进行持久化操作
save 60 10000 # 如果在60秒内,至少10000个key进行了修改,那么进行持久化操作
# 持久化出错,是否继续工作,这里默认是yes即继续工作
# However if you have setup your proper monitoring of the Redis server
# and persistence, you may want to disable this feature so that Redis will
# continue to work as usual even if there are problems with disk,
# permissions, and so forth.
stop-writes-on-bgsave-error yes
# 默认的rdb文件名称
# The filename where to dump the DB
dbfilename dump.rdb
# 是否压缩rdb文件,默认是;不过压缩rdb文件需要消耗一些cpu的资源
# Compress string objects using LZF when dump .rdb databases?
# For default that's set to 'yes' as it's almost always a win.
# If you want to save some CPU in the saving child set it to 'no' but
# the dataset will likely be bigger if you have compressible values or keys.
rdbcompression yes
# 保存rdb文件的时候,是否需要校验一下
# Since version 5 of RDB a CRC64 checksum is placed at the end of the file.
# This makes the format more resistant to corruption but there is a performance
# hit to pay (around 10%) when saving and loading RDB files, so you can disable it
# for maximum performances.
#
# RDB files created with checksum disabled have a checksum of zero that will
# tell the loading code to skip the check.
rdbchecksum yes
# rdb文件存放的目录,默认是./,即当前目录
# The working directory.
#
# The DB will be written inside this directory, with the filename specified
# above using the 'dbfilename' configuration directive.
#
# The Append Only File will also be created inside this directory.
#
# Note that you must specify a directory here, not a file name.
dir ./
e. 配置文件:主从复制
################################# REPLICATION #################################
# Master-Slave replication. Use slaveof to make a Redis instance a copy of
# another Redis server. A few things to understand ASAP about Redis replication.
#
# 1) Redis replication is asynchronous, but you can configure a master to
# stop accepting writes if it appears to be not connected with at least
# a given number of slaves.
# 2) Redis slaves are able to perform a partial resynchronization with the
# master if the replication link is lost for a relatively small amount of
# time. You may want to configure the replication backlog size (see the next
# sections of this file) with a sensible value depending on your needs.
# 3) Replication is automatic and does not need user intervention. After a
# network partition slaves automatically try to reconnect to masters
# and resynchronize with them.
#
# 如果要将当前的redis配置成为某台redis的从节点,就在这里配置对应的master的信息
# slaveof <主节点IP> <主节点端口号>
# slaveof
# If the master is password protected (using the "requirepass" configuration
# directive below) it is possible to tell the slave to authenticate before
# starting the replication synchronization process, otherwise the master will
# refuse the slave request.
# 如果对应的主节点有设置过密码,那么在此处添加主节点的密码
# masterauth f. 配置文件:安全
################################## SECURITY ###################################
# 设置redis的安全密码,默认是没有密码的
# Require clients to issue AUTH before processing any other
# commands. This might be useful in environments in which you do not trust
# others with access to the host running redis-server.
#
# This should stay commented out for backward compatibility and because most
# people do not need auth (e.g. they run their own servers).
#
# Warning: since Redis is pretty fast an outside user can try up to
# 150k passwords per second against a good box. This means that you should
# use a very strong password otherwise it will be very easy to break.
#
# requirepass foobared
requirepass ""
127.0.0.1:6379> config set requirepass "ejavashop"
OK
127.0.0.1:6379> ping
(error) NOAUTH Authentication required.
127.0.0.1:6379> auth ejavashop
OK
127.0.0.1:6379> ping
PONG
127.0.0.1:6379>
g. 配置文件:限制
################################### LIMITS ####################################
# 设置redis最大的连接的客户端数量
# Set the max number of connected clients at the same time. By default
# this limit is set to 10000 clients, however if the Redis server is not
# able to configure the process file limit to allow for the specified limit
# the max number of allowed clients is set to the current file limit
# minus 32 (as Redis reserves a few file descriptors for internal uses).
#
# Once the limit is reached Redis will close all the new connections sending
# an error 'max number of clients reached'.
#
# maxclients 10000
# redis配置的最大内存容量
# maxmemory h. 配置文件:aof
############################## APPEND ONLY MODE ###############################
# 默认是不开启aof模式的,默认使用的是rdb方式进行持久化。因为大部分情况,rdb完全够用
# aof 即append only mode,基本逻辑就是:追加
appendonly no
# 持久化的文件名称
# The name of the append only file (default: "appendonly.aof")
appendfilename "appendonly.aof"
# 持久化规则:
# appendfsync always # 每次修改都会持久化。消耗性能
appendfsync everysec # 每秒执行一次持久化,但是可能会丢失这1秒的数据
# appendfsync no # 不执行持久化,这个时候操作系统自己同步数据,速度最快
# 设置每个aof文件的体积,默认是64mb,如果超过了64mb,就会fork一个新的进程创建一个新的文件
# Automatic rewrite of the append only file.
# Redis is able to automatically rewrite the log file implicitly calling
# BGREWRITEAOF when the AOF log size grows by the specified percentage.
#
# This is how it works: Redis remembers the size of the AOF file after the
# latest rewrite (if no rewrite has happened since the restart, the size of
# the AOF at startup is used).
#
# This base size is compared to the current size. If the current size is
# bigger than the specified percentage, the rewrite is triggered. Also
# you need to specify a minimal size for the AOF file to be rewritten, this
# is useful to avoid rewriting the AOF file even if the percentage increase
# is reached but it is still pretty small.
#
# Specify a percentage of zero in order to disable the automatic AOF
# rewrite feature.
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
十四. redis的持久化
-
项目中使用Redis做缓存,方便多个业务进程之间共享数据。由于Redis的数据都存放在内存中,如果没有配置持久化,redis重启后数据就全丢失了,于是需要开启redis的持久化功能,将数据保存到磁盘上,当redis重启后,可以从磁盘中恢复数据。
-
redis提供两种方式进行持久化,一种是RDB持久化(原理是将redis在内存中的数据库记录定时dump到磁盘上的RDB文件中),另外一种是AOF持久化(原理是将redis的操作日志以追加的方式写入文件)。
a. rdb持久化(redis data base)

-
在指定的时间间隔内将 内存中的数据集快照写入到磁盘中,也就是Snapshot快照,它恢复时是将快照文件直接读到内存中
-
redis会单独创建fork一个子进程进行持久化,会将数据写入到一个临时的rdb文件中,待持久化的过程结束之后,再用这个临时文件替换上次持久化好的文件。整个过程,父进程是不进行任何IO操作的。这就确保了高性能。如果需要进行大规模数据的恢复,且对数据恢复的完整性不是很敏感,那么rdb方式比aof方式更加高效。rdb的缺点是最后一次持久化的数据可能会丢失。我们默认采用的持久化方式就是rdb,一般情况下不需要修改。
-
rdb保存的文件是dump.rdb
-
rdb文件生成触发条件
1.满足十三中d.配置文件:快照的save规则,就会生成dump.rdb文件 2.执行flushall命令,也会生成dump.rdb文件 3.退出redis,也会生成dump.rdb文件 4.直接敲save命令,也可以创建当前数据库的备份,该命令将在 redis 安装目录中创建dump.rdb文件(如下) 5.创建 redis 备份文件也可以使用命令 BGSAVE,该命令在后台执行# 直接敲save命令 127.0.0.1:6379> save OK 127.0.0.1:6379># 创建 redis 备份文件也可以使用命令 BGSAVE,该命令在后台执行 127.0.0.1:6379> bgsave Background saving started 127.0.0.1:6379> -
如何恢复rdb文件
只需要将rdb文件放入到redis的启动目录下,redis启动的时候会自动检查dump.rdb文件,将其中数据恢复 -
redis启动目录
# 使用这个命令可以查看启动目录在哪里 127.0.0.1:6379> config get dir 1) "dir" 2) "D:\\java\\software\\install\\redis_new\\5.0.10" # 如果这个目录下有dump.rdb文件,就会在启动的时候自动恢复其中的数据 127.0.0.1:6379> -
优点
1.适合大规模数据的恢复 2.对数据的完整性要求不高 -
缺点
1.需要一定的时间间隔进程操作,如果redis意外宕机了,那么最后一次的数据就丢失了 2.fork进程的时候,需要占用一定的内存空间
b. aof持久化(append only file)

-
将我们的所有命令都记录下来,相当于一个history文件
-
以日志的形式记录每一个写操作(读操作不记录),只能追加文件,不能修改文件旧的记录,redis重启之后读取改文件重新构建数据。
-
redis重启的话,就根据日志文件中的内容将写指令重新执行一遍完成数据的恢复工作,因此效率较低
-
默认的aof是不开启的,需要修改

-
aof文件的生成规则
1.配置好aof生效后,每次重启redis都会生成一个appendonly.aof文件 2.满足十三中h.配置文件:aof的持久化规则,就会生成appendonly.aof文件 -
aof文件中保存的内容一览

-
如果aof文件存在错误,这个时候redis是启动不起来的,我们需要修复一下。执行如下程序即可修复(一般是删除掉错误的命令)

-
优点
1.每一次修改都同步,文件的完成性比较好 2.每秒同步一次,可能丢失1秒的数据 -
缺点
1.修复速度比rdb慢 2.aof文件运行效率也不高
十五.redis订阅发布
-
redis的发布订阅是一种消息通信模式:pub(消息发送者)、sub(消息订阅者)
-
redis客户端可以订阅任意数量的频道
-
订阅发布的模式
-
订阅
下图展示了频道 channel1 , 以及订阅这个频道的三个客户端 —— client2 、 client5 和 client1 之间的关系
-
发布
当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:
-
-
测试
# 订阅端:先订阅 127.0.0.1:6379> SUBSCRIBE zwt # 此处使用SUBSCRIBE命令,订阅zwt这个channel Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "zwt" 3) (integer) 1# 发布端:在zwt这个channel中发布消息“hello zwt” 127.0.0.1:6379> PUBLISH zwt "hello zwt" (integer) 1 127.0.0.1:6379>127.0.0.1:6379> SUBSCRIBE zwt Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "zwt" 3) (integer) 1 # 订阅端:查看到发布端发布的消息 1) "message" 2) "zwt" 3) "hello zwt" -
原理
1.通过SUBSCRIBE命令订阅某个频道(channel)后,redis-server中就维护一个字典。字典的键就是一个个的频道!而字典的值则是一个链表。链表中保存了所有订阅这个channel的客户端。SUBSCRIBE命令就是将客户端添加到指定channel的订阅链表中。 2.通过PUBLISH命令向订阅者发布消息,redis-server会使用指定的频道作为键,在他维护的channel字典中查找订阅了该频道的所有客户端列表,遍历这个链表,将消息发布给所有的订阅者 3.适用于普通的即时聊天,群聊功能
-
稍微复杂的场景,最好还是使用专业的消息中间件来做
十六.redis集群
a. Redis主从复制概念
- 主从复制就是将一台redis服务器的数据,复制到其他redis服务器中。前者称为主节点(master/leader),后者称为从节点(slave/follower);
- 数据的复制是单向的:只能从主节点复制到从节点
- 主节点以写为主,从节点以读为主
- 一个主节点可以有多个从节点,一个从节点只能有一个主节点
- 默认情况下:每台redis服务器都是主节点。但可以通过认主人的方式,降格为从节点

b. Redis主从复制作用
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的另一种数据冗余方式
- 故障恢复:当主节点出现故障后,可以让从节点提供服务,实现快速的故障恢复;实际上是一种服务冗余
- 负载均衡:在主从复制的基础上,配合读写分离,可以让主节点提供写服务,从节点提供读服务,分担服务器的负载;尤其是在写少读多的场景下,可以通过多个从节点分担读的压力,可以大幅度的提升redis的并发量。一般一个应用20%的写操作;80%的读操作。
- 高可用基石:除了上述作用之外,主从复制还是哨兵、集群能够实施的基础,因此说主从复制是redis的高可用基础。
- 一般来说,将redis应用于项目中,仅仅使用一台redis的话是解决不了问题的,原因有两点:
- 从结构上来看,单个redis服务器容易发生单点故障,并且单台redis服务器负载较大
- 从容量上来看,单个redis服务器的内存容量有限,就算是一台redis服务器的内存容量为256G,也不能将所有的内存作为redis的内存使用,一般来说,单台redis的最大使用内存不应该超过20G
- 因此一般最少三台redis服务器,即1主2从
c. 环境配置(windows)
-
仅需要配置从库,不用配置主库
-
查看当前redis服务器的集群信息
127.0.0.1:6379> info replication # 查看主/从复制信息 # Replication role:master # 当前角色:主节点 connected_slaves:0 # 没有从节点 master_replid:e4bb4fdb798b260aab37d859af54e8be6dfa593f master_replid2:0000000000000000000000000000000000000000 master_repl_offset:0 second_repl_offset:-1 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0 127.0.0.1:6379> -
根据配置文件启动多个redis服务器,因此需要修改配置文件
- 复制三个redis相关的配置文件,如下图

- 修改配置文件中的port值



- 修改配置文件中的logfile值



-
修改配置文件中的dbfilename值


d. 启动redis服务端+客户端
-
开第一个cmd窗口,开启6379服务端

-
开第二个cmd窗口,开启6380服务端

-
开第三个cmd窗口,开启6381服务端

-
开第四个cmd窗口,开启6379客户端-连接redis-server6379

-
开第五个cmd窗口,开启6380客户端-连接redis-server6380

-
开第六个cmd窗口,开启6381客户端-连接redis-server6381

e. 配置主从
-
在d步骤我模拟配置了三台redis,端口号分别是6379/6380/6381。在各自连接的客户端,查看下主从复制信息,发现三台redis都是master,如下所示:
127.0.0.1:6379> info replication # 查看端口号6379的redis-server # Replication role:master # 当前角色为主节点 connected_slaves:0 # 没有从节点 master_replid:48cbbb342c6e89c4528d106cebb4a12e5590a928 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:0 second_repl_offset:-1 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0 127.0.0.1:6379>127.0.0.1:6380> info replication # 查看端口号6380的redis-server # Replication role:master # 当前角色为主节点 connected_slaves:0 # 没有从节点 master_replid:15f97d43b4901f799e8b118c82e4fa7e8bdcf111 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:0 second_repl_offset:-1 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0 127.0.0.1:6380>127.0.0.1:6381> info replication # 查看端口号6380的redis-server # Replication role:master # 当前角色为主节点 connected_slaves:0 # 没有从节点 master_replid:0a835b1157b235716cd6fddcbed2d358f894e081 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:0 second_repl_offset:-1 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0 127.0.0.1:6381> -
将6380/6381设置为6379的从节点



-
倘若想要将某台slave角色的redis-server恢复成master角色,可以执行命令slaveof no one

-
注意:上述步骤中在命令行中敲定的slaveof ip port,将当前的redis-server设置为指定redis-server的从节点,但是这个是暂时的,不是永久的。倘若想要永久的将该redis-server固定的设置为另一台redis-server的从节点,需要修改配置文件,这个参考模块十三-e.配置文件:主从复制
-
注意:将6379设置为master,将6380、6381设置为slave后,那么从节点就只能不能进行写操作了,只有master节点才能执行写操作。其次,master写入的东西,在slave中都能看得到
127.0.0.1:6380> set k1 v1 # 因为6380此时是6371的slave,因此会有如下的操作失败提示 (error) READONLY You can't write against a read only replica. 127.0.0.1:6380> -
注意:
-
6379(master)-6380(slave0)、6381(slave1)。
-
倘若将6379(master)断掉,此处模拟master宕机。那么此时6380/6381还都可以获取到对应的键keys,但是没有了写操作。如果再将该6379(master)启动起来,继续写一些新的key,6380/6381还是可以获取到这些新的key
-
倘若6379(master)正常,而将6380(slave0)断掉,此处模拟slave宕机。此时在6379写入了新的Key,然后在启动6380(slave0),6380是获取不到这个新的key,因为新启动的6380的role已经恢复成为master,它不是6379的从节点,所以获取不到这个新的key。但是可以将6380执行slaveof 127.0.0.1 6379命令,将6380再次变成6379的从节点,就可以获取到这个新的Key。
-
上述的2和3就是redis确保高可用的基础
-
注意3中有一个概念:复制原理
slave启动成功连接到master后会发送一个sync同步命令
master接到命令后,启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕后,master将传送整个数据文件到slave,并完成一次完全同步。
全量复制:slave服务在接收到数据库文件数据后,将其存盘并加载到内存中
增量复制:master继续将新搜集到的修改命令一次传递给各个slave,完成同步。
但是只要是重新连接到master,一次完全同步(全量复制)将被自动执行
-
f. 哨兵模式
-
主从切换技术的方法是:当主服务宕机后,需要手动把一台服务器切换为主服务器,这就需要人工干预,费时费力,还会造成一段时间内服务的不可用。这不是一种推荐的方式,更多的时候,我们优先考虑哨兵模式。redis从2.8开始正式提供了Sentinel(哨兵)架构来解决这个问题。
-
哨兵模式能够后台监控主机是否出故障,如果故障了,根据投票数自动将从库设置为主库
-
哨兵模式是一种特殊的模式,首先redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送指令,等待redis服务器的响应,从而监控运行多个redis实例
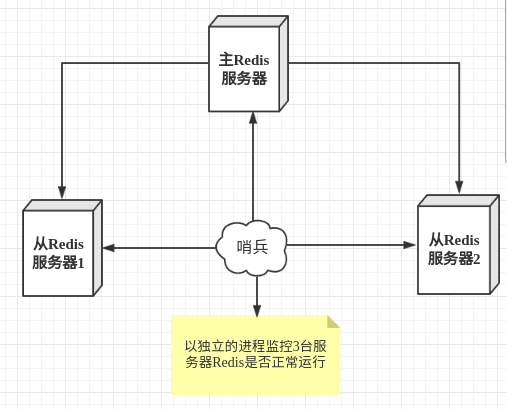
-
上图中哨兵说明:
-
通过发送命令,让redis服务器返回监控其运行状态,包括主服务器、从服务器
-
当哨兵检测到master宕机后,会自动的将slave切换成master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让他们切换主机。
-
-
然而单个哨兵,可能出现单点故障,因此哨兵可以集群,形成多哨兵模式
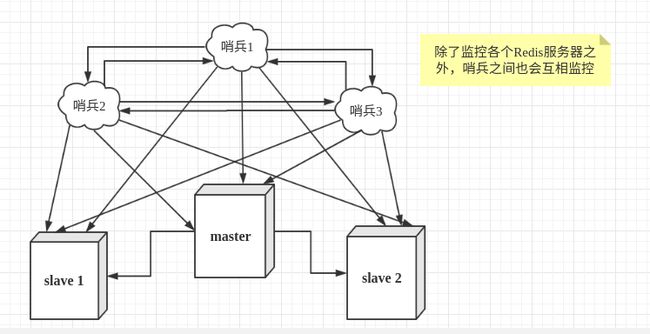
-
假设主服务器宕机,哨兵1先检测到该结果,系统并不会马上进行failover过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象叫做主观下线。当后面的哨兵也监测到该主服务器不可用,并且数量达到一定值,那么哨兵之间就就会进行一次投票,投票的结果由一个哨兵发起,进行failover(故障转移)操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程成为客观下线
十七. 缓存穿透、击穿、雪崩
a. 缓存穿透
1.概念
用户查询一个数据,发现redis缓存中不存在,于是向数据库查询,发现数据库也没有,于是本次查询失败。当用户量足够可观时,针对该数据的查询就会有大量的请求直接穿透缓存,抵达数据库,这个就会给数据库中造成很大的压力,这种现象就是缓存穿透
2.解决方案
-
使用布隆过滤器
布隆过滤器是一种数据结构,对所有可能的查询的参数以hash形式存储,在控制层先进行校验,不符合则丢弃,从而避免了对底层系统的查询压力。

-
缓存空对象
当存储层没有命中后,即使返回空对象也要将其缓存起来,同时设置一个过期时间,之后再访问这个数据库才会从缓存中获取,保护了后端数据库

但是中方法存在两个问题:
其一:如果空值被存储起来,那就意味着缓存需要更多的空间存储键值,这其中还有不少空值的键。
其二:即使是空值设置了过期时间,还是会存在缓存层和存储层的数据不一致的时间窗口,这对于一个需要保持一致性的业务是有影响的。
b. 缓存击穿
1.概念
是指一个key非常热点,在不停的扛着高并发,高并发集中对这一点进行访问,当这个key在失效的瞬间,持续的高并发就会穿破缓存,直接请求数据库,就像在一个屏障上凿开一个洞。
2.解决方案
-
设置热点数据永不过期
-
加互斥锁
分布式锁:使用分布式锁,保证对于每个key同时只能有一个线程查询后端服务,其他线程没有获取到分布式锁的权限,因此只需要等待即可。这种方式将高并发的压力转移到了分布式锁,因此对分布式锁的考验很大。
c. 缓存雪崩
1.概念
就是在某一个时间段,缓存集中过期失效。比如说宕机!
产生雪崩的原因之一,比如双十二零点,很快就会迎来一波抢购,这波商品时间比较集中的放入缓存中,假设缓存一个小时。那么到凌晨1点的时候,这批商品的缓存都过期了。而对这批商品的访问查询,都落到数据库上,对于数据库而言,就会产生周期性的压力波峰。于是所有的请求都到了存储层,存储层的调用量暴增,造成存储层也会挂掉的情况。

其实缓存集中过期,倒不是非常致命。比较致命的是缓存服务器的某个节点宕机或者断网
2.解决方案
-
redis高可用
既然redis有可能挂掉,那么我就对redis进行集群。这样一台挂掉之后还可以继续工作。异地多活
-
限流降级
在缓存失效后,通过加锁或者队列来控制数据库读写缓存的线程数量
-
数据预热
在正式部署之前,我可以先把可能的数据预先访问一遍,这样部分可能大量访问的数据就会加载到缓存中了。在即将发生大并发的访问前,手动触发加载缓存的不同的key,设置不同的过期时间,让缓存的失效时间点尽量均匀些。