ELK安装、部署、调试(五)filebeat的安装与配置
1.介绍
logstash 也可以收集日志,但是数据量大时太消耗系统新能。而filebeat是轻量级的,占用系统资源极少。
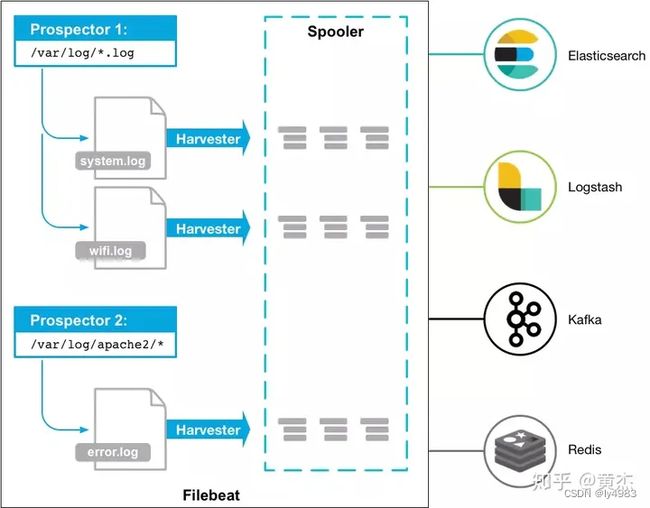
Filebeat 由两个主要组件组成:harvester 和 prospector。
采集器 harvester 的主要职责是读取单个文件的内容。读取每个文件,并将内容发送到 the output。 每个文件启动一个 harvester,harvester 负责打开和关闭文件,这意味着在运行时文件描述符保持打开状态。如果文件在读取时被删除或重命名,Filebeat 将继续读取文件。
查找器 prospector 的主要职责是管理 harvester 并找到所有要读取的文件来源。如果输入类型为日志,则查找器将查找路径匹配的所有文件,并为每个文件启动一个 harvester。每个 prospector 都在自己的 Go 协程中运行。
2.下载
下载地址:www.elastic.co/downloads/beats/filebeat
百度云elk
3.安装
tar -zxvf filebeat-7.9.3-linux-x86_64.tar.gz -C /usr/local
cd /usr/local/
mv filebeat-7.9.3-linux-x86_64 filebeat
cd filebeat/
[root@node1 filebeat]# ls -l
fields.yml filebeat filebeat.reference.yml filebeat.yml kibana
LICENSE.txt module modules.d NOTICE.txt README.mdfilebeat为应用程序
cd /usr/local/filebeat/filebeat.yml 是配置文件
modules.d的目录下放置的日志收集模板,实现了模块化的日志收集
[root@node1 modules.d]# ls
activemq.yml.disabled coredns.yml.disabled ibmmq.yml.disabled microsoft.yml.disabled
okta.yml.disabled squid.yml.disabled apache.yml.disabled crowdstrike.yml.disabled icinga.yml.disabled misp.yml.disabled osquery.yml.disabled suricata.yml.disabled
auditd.yml.disabled cylance.yml.disabled iis.yml.disabled mongodb.yml.disabled
panw.yml.disabled system.yml.disabled aws.yml.disabled elasticsearch.yml.disabled imperva.yml.disabled mssql.yml.disabled postgresql.yml.disabled tomcat.yml.disabled
azure.yml.disabled envoyproxy.yml.disabled infoblox.yml.disabled mysql.yml.disabled
rabbitmq.yml.disabled traefik.yml.disabled barracuda.yml.disabled f5.yml.disabled iptables.yml.disabled nats.yml.disabled radware.yml.disabled zeek.yml.disabled
bluecoat.yml.disabled fortinet.yml.disabled juniper.yml.disabled netflow.yml.disabled
redis.yml.disabled zscaler.yml.disabled cef.yml.disabled googlecloud.yml.disabled kafka.yml.disabled netscout.yml.disabled santa.yml.disabled
checkpoint.yml.disabled gsuite.yml.disabled kibana.yml.disabled nginx.yml.disabled
sonicwall.yml.disabled cisco.yml.disabled haproxy.yml.disabled logstash.yml.disabled o365.yml.disabled
sophos.yml.disabled4.配置
配置filebeat.yml
注意 以下使用“-” 为首字母的,要求前面不能使用tab做缩进,
filebeat.inputs: #定义日志输入的开始
- type: log
#注意格式,收集日志类型为日志,还可以是redis,UDP,TCP,docker,syslog,stdin等
enabled: true #使用手动模式,如果false将使用modules.d目录下的模块方式
paths: #要收集的日志的路径
- /var/log/messages
- /var/log/secure
#如果日志较多,可以模糊的填写,如 - /data/nginx/logs/ngix_*.log
# - /var/log/*.log 的配置会获取/var/log下所有子目录中以.log结尾的日志,而不会查找/var/log/目录下的.log文件。
fields:
log_topic:osmessages #osmessages是自己定义主体的名字
name: "10.10.10.56" #指定名字,不配置时默认使用主机名
output.kafka:
eanbled: true
hosts: ["10.10.10.71:9092","10.10.10.72:9092","10.10.10.73:9092"] #kafka集群的地址和端口号
version: 2.0.1 #kafka的版本号
topic: '%{[fields][log_topic]}' #也可以fields.log_topic的写法
partition.round_robin: #采用轮询的方式
reachable_only: true
worker: 2
required_acks: 1 #有1,2,3等可写,1最大限度保证
compression: gzip
max_message_bytes: 10000000
logging.level: debug #info,warming,error等可写,定义 日志级别
配置里还包含一些过滤条件,如行排除,行包含,文件排除等
exclude_lines: ['^DBG']
include_lines: ['^ERR', '^WARN']
exclude_files: ['.gz$']以上配置使用了kafka作为filebeat的输出,
配置
# ============================== Filebeat modules ==============================
filebeat.config.modules:
# Glob pattern for configuration loading
path: ${path.config}/modules.d/*.yml
# Set to true to enable config reloading
reload.enabled: false
# Period on which files under path should be checked for changes
#reload.period: 10s
# ======================= Elasticsearch template setting =======================
文档中还有一些模块的配置,如上
由于我们在
filebeat.inputs:
- type: log
enabled: true 这里我们设置为了true,使用了手动配置的方式,屏蔽了快速模块,这里配置为false时,才使用模块配
置
使用./filebeat test config 或者./filebeat -c filebeat.yml -configtest 对配置文件进行格式测试。检查启动filebeat
more filebeat.yml
nohup /usr/local/filebeat/filebeat -e -c /usr/local/filebeat/filebeat.yml &测试
tail -f nohup.out 查看收集的日志
"@timestamp": "2023-08-28T07:56:14.266Z", 时间戳
"@metadata": {
"beat": "filebeat",
"type": "_doc",
"version": "7.9.3"
},
"log": { 类型
"file": {
"path": "/var/log/secure"
},
"offset": 508431 位置,偏移量
},
"message": "Aug 28 15:56:12 node1 sshd[31513]: pam_limits(sshd:session): invalid line 'End of file' -
skipped",
"fields": { 自定义的域
"log_topic": "osmessages"
},
"input": { 类型
"type": "log"
},
"agent": {
"id": "a5a5cdf5-42f5-40a8-8c4c-068b76a2b22c",
"name": "10.10.10.56",
"type": "filebeat",
"version": "7.9.3",
"hostname": "node1",
"ephemeral_id": "826d8757-65f0-4838-b915-409eba0cd6bf"
},
"ecs": {
"version": "1.5.0"
},
"host": {
"name": "10.10.10.56"
}
}我们看到,很多信息都是filebeat附带的一些信息。 我们可以通过配置参数的过滤掉一些信息。
# ================================= Processors =================================
processors:
# - add_host_metadata:
# when.not.contains.tags: forwarded
# - add_cloud_metadata: ~
# - add_docker_metadata: ~
# - add_kubernetes_metadata: ~
- drop_fields:
fields: ["host","input","offset","ecs","log","agent.id"]drop_fields:所定义的就是不需要在日志中显示的filebeat自带的一些信息。
上面的配置信息agent.id ,因为agent下有很多个属性,仅过滤掉id这个属性
"agent": {
"id": "a5a5cdf5-42f5-40a8-8c4c-068b76a2b22c",
"name": "10.10.10.56",
"type": "filebeat",
"version": "7.9.3",
"hostname": "node1",
"ephemeral_id": 这样配置后,将在日志文件中过滤掉 以上属性的内容,仅显示留下的内容。
通过tail -f nohup.out查看本机产生的日志
通过在kafka机器上用过消费来开传到kafka上的日志
cd /usr/local/kafka/bin
./kafka-console-consumer.sh --bootstrap-server 10.10.10.71:9092,10.10.10.72:9092,10.10.10.73:9092 --topic
osmessages