Aspose导出word使用记录
背景:Aspose系列的控件,功能实现都比较强大,可以实现多样化的报表设计及输出。
通过这次业务机会,锂宝碳审核中业务功需要实现Word文档表格的动态导出功能,因此学习了相关内容,在学习和参考了官方API文档的帮助下,将学习和简单的使用记录在wiki中。下面由我来简单介绍这个控件在实际业务中的使用过程。
一、开发前准备
1. 问题产生: 在实际的开发过程中会遇到Aspose依赖无法导入的情况,如下图所示
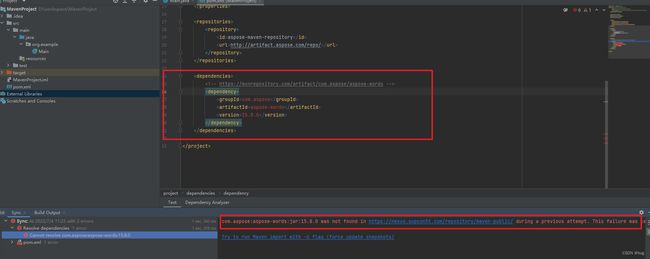
2. 原因分析: 主要原因是因为Maven的pom配置中使用的是阿里的镜像源,而阿里云镜像无法下载aspose依赖
3. 解决方法:
(1)先将 aspose的jar包 下载到本地,然后添加到本地的maven,再上传到公司的仓库(文档选择了第一种方式)
(2)提供aspose的仓库地址,将仓库地址加入nexusjar包下载地址

4. 方法步骤:
(1)在配置好后创建项目后,在配置文件需要引用依赖,可以选择本地依赖,而本地依赖需要导入, 所以就需要进行jar包的导入
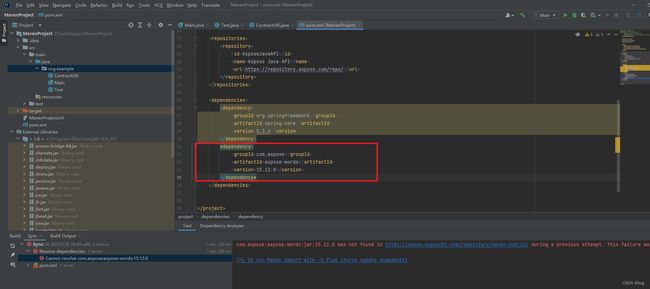
(2)导入包的语句:
mvn install:install-file "-Dfile=D:\software\Jar\aspose-words-15.12.0-jdk16.jar"
"-DgroupId=com.aspose"
"-DartifactId=aspose-words"
"-Dversion=15.12.0"
"-Dpackaging=jar"
(3)解释一下这些参数意思:
-Dfile: jar包所在本地的绝对路径
-DgroupId: 在导入包后会在本地仓库创建一个com.aspose的路径,包就会存放在jar里面
-DartifactId=spring: jar包的名字
-Dversion: jar包的版本
-Dpackaging: 导入包的类型
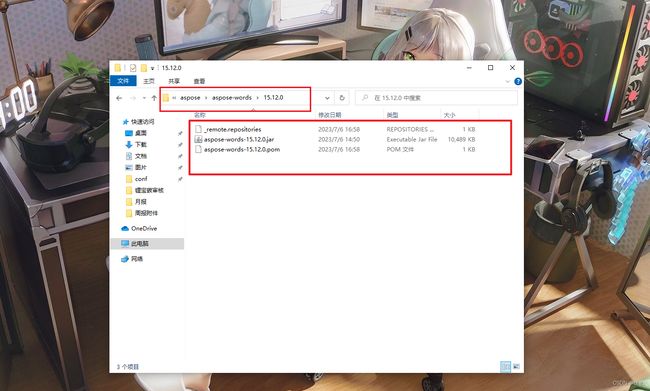
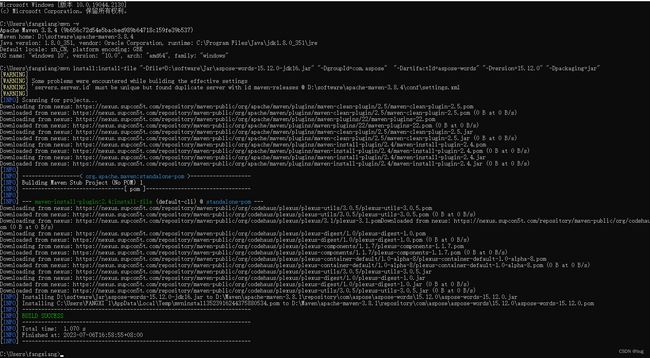
(4)进入cmd运行上面的命令:显示如下即加入成功!这就是Maven的下载和在IDEA的配置以及jar包的导入
二、word表格的基本操作
1. 建立word模板
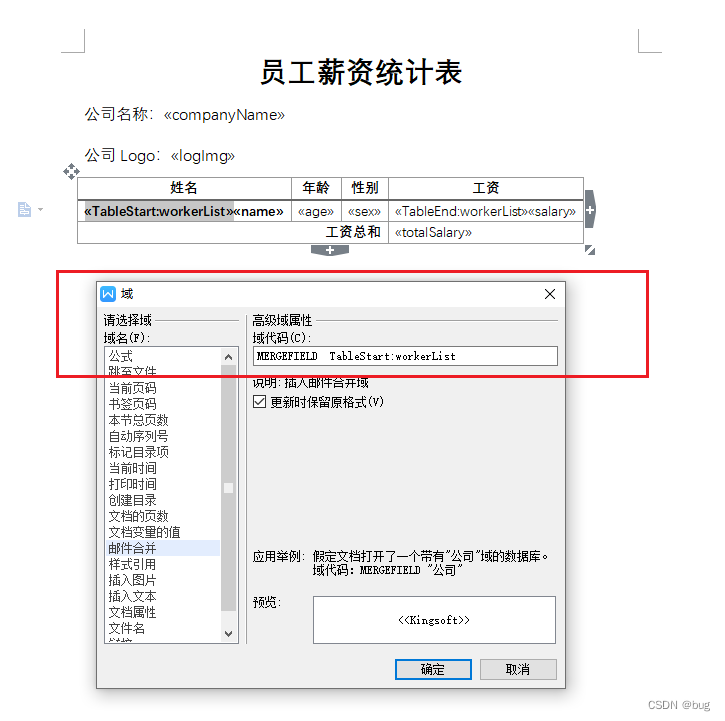
(1)在word文档中,在菜单栏中依次点击 插入 -> 域
(2)接着在弹出框中选择 邮件合并 域,在域属性中填写域名,该域名即为变量名,填写完毕后点击 确定 即可

(3)生成如图所示的样式,即为添加成功

2. 定义集合变量
当单一变量无法满足需求后,我们就需要定义集合变量,我就拿员工薪资统计来举例,一个表格里面会有多个数据。此时,我们应该插入
List数据到模板文件中
(1)模板关键字:TableStart:集合名称, TableEnd:集合名称
(2)同样的,在域中选择邮件合并,域名要用TableStart打头,紧接冒号:,再然后就是定义集合的名称。需要注意的是,TableStart意为集合的开始,所以我们再集合结束的地方,需要添加结束标识TableEnd
(3)TableStart 和 TableEnd 之间的变量,就是集合中每个属性的变量名称
(4)添加完毕之后,如图所示,模板 也可点击这里下载(5vy5)
3. 员工薪资数据插入Demo案例
3.1 导入工具类
package org.example;
import com.aspose.words.*;
import com.aspose.words.net.System.Data.DataRow;
import com.aspose.words.net.System.Data.DataTable;
import org.springframework.util.CollectionUtils;
import org.springframework.util.StringUtils;
import java.awt.*;
import java.awt.geom.AffineTransform;
import java.awt.image.BufferedImage;
import java.awt.image.ColorModel;
import java.awt.image.WritableRaster;
import java.beans.IntrospectionException;
import java.beans.PropertyDescriptor;
import java.io.*;
import java.lang.reflect.Field;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* @author fangxiang
* @date 2023/7/7 13:46
*/
public class ContractUtil {
private ContractUtil() {
}
/**
* 调整图片的大小格式属性
*
* @param source BufferedImage 原始image
* @param targetW int 目标宽
* @param targetH int 目标高
* @param flag boolean 是否同比例调整
* @return BufferedImage 返回新image
*/
public static BufferedImage resizeBufferedImage(BufferedImage source, int targetW, int targetH, boolean flag) {
int type = source.getType();
BufferedImage target = null;
// 计算缩放比例
double sx = (double) targetW / source.getWidth();
double sy = (double) targetH / source.getHeight();
// 根据保持纵横比的标志调整缩放比例
if (flag && sx > sy) {
sx = sy;
targetW = (int) (sx * source.getWidth());
} else if (flag && sx <= sy) {
sy = sx;
targetH = (int) (sy * source.getHeight());
}
// 创建目标BufferedImage
if (type == BufferedImage.TYPE_CUSTOM) {
ColorModel cm = source.getColorModel();
WritableRaster raster = cm.createCompatibleWritableRaster(targetW, targetH);
boolean alphaPremultiplied = cm.isAlphaPremultiplied();
target = new BufferedImage(cm, raster, alphaPremultiplied, null);
} else {
target = new BufferedImage(targetW, targetH, type);
}
// 绘制调整大小后的图像
Graphics2D g = target.createGraphics();
g.setRenderingHint(RenderingHints.KEY_RENDERING, RenderingHints.VALUE_RENDER_QUALITY);
g.drawRenderedImage(source, AffineTransform.getScaleInstance(sx, sy));
// 释放资源
g.dispose();
return target;
}
/**
* 使用对象数据填充Word模板
*
* @param modelWordByte Word模板的二进制数据
* @param obj 要填充的数据对象
* @return 填充数据后的Word二进制数据
*/
public static byte[] fillWordDataByDomain(byte[] modelWordByte, Object obj) {
try {
// 获取对象的Class
Class<?> aClass = obj.getClass();
// 获取对象的所有字段
Field[] fields = aClass.getDeclaredFields();
// 创建一个Map来存储字段名和字段值
Map<String, Object> data = new HashMap<>(fields.length);
// 遍历字段,获取字段值并存入Map中
for (Field field : fields) {
// 获取字段的属性描述器
PropertyDescriptor pd = new PropertyDescriptor(field.getName(), aClass);
// 获取字段的读取方法
Method method = pd.getReadMethod();
// 获取字段名
String key = field.getName();
// 调用读取方法获取字段值
Object value = method.invoke(obj);
// 如果字段值不为空,则将字段名和字段值存入Map中
if (value != null) {
data.put(key, value);
}
}
// 使用Map数据填充Word模板并返回填充后的Word二进制数据
return fillWordDataByBinary(modelWordByte, data);
} catch (Exception e) {
// 出现异常时返回空的字节数组
return new byte[0];
}
}
/**
* 填充 word 模板(map数据格式)
*
* @param file word二进制
* @param data 要填充的数据
* @return 组合数据之后的word二进制
*/
public static byte[] fillWordDataByBinary(byte[] file, Map<String, Object> data) throws Exception {
byte[] ret = null;
if (CollectionUtils.isEmpty(data)) {
return ret;
}
try (InputStream is = new ByteArrayInputStream(file);
ByteArrayOutputStream out = new ByteArrayOutputStream()) {
// 读取Word文档
Document doc = new Document(is);
// 用于存储需要替换的字段和对应的值
Map<String, String> toData = new HashMap<>();
// 遍历数据Map
for (Map.Entry<String, Object> en : data.entrySet()) {
String key = en.getKey();
Object value = en.getValue();
// 如果值是List类型,则填充表格数据
if (value instanceof List) {
//写入表数据
DataTable dataTable = fillListData((List) value, key);
doc.getMailMerge().executeWithRegions(dataTable);
}
String valueStr = String.valueOf(en.getValue());
// 如果值为空或者为字符串"null",则跳过该字段
if (StringUtils.isEmpty(value)) {
continue;
}
// 将字段和值存入toData
toData.put(key, valueStr);
}
// 将toData中的字段和值分别存入两个数组
String[] fieldNames = new String[toData.size()];
String[] values = new String[toData.size()];
int i = 0;
for (Map.Entry<String, String> entry : toData.entrySet()) {
fieldNames[i] = entry.getKey();
values[i] = entry.getValue();
i++;
}
// 执行合并数据操作
doc.getMailMerge().execute(fieldNames, values);
// 保存修改后的文档到输出流
doc.save(out, SaveOptions.createSaveOptions(SaveFormat.DOCX));
ret = out.toByteArray();
}
return ret;
}
/**
* 封装 list 数据到 word 模板中(word表格)
*
* @param list 数据
* @param tableName 表格列表变量名称
* @return word表格数据DataTable
*/
private static DataTable fillListData(List<Object> list, String tableName) throws IntrospectionException, InvocationTargetException, IllegalAccessException {
//创建DataTable,并绑定字段
DataTable dataTable = new DataTable(tableName);
// 遍历 list 中的每个对象
for (Object obj : list) {
// 创建DataRow,封装该行数据
DataRow dataRow = dataTable.newRow();
Class<?> objClass = obj.getClass();
Field[] fields = objClass.getDeclaredFields();
// 遍历对象的每个字段
for (int i = 0; i < fields.length; i++) {
Field field = fields[i];
// 将字段名添加到 dataTable 的列中
dataTable.getColumns().add(fields[i].getName());
// 通过反射获取字段的值,并将其设置到 dataRow 中
PropertyDescriptor pd = new PropertyDescriptor(field.getName(), objClass);
Method method = pd.getReadMethod();
dataRow.set(i, method.invoke(obj));
}
// 将 dataRow 添加到 dataTable 的行中
dataTable.getRows().add(dataRow);
}
return dataTable;
}
/**
* 利用反射将字段转为Map键值对
*
* @param obj
* @return
* @throws IntrospectionException
* @throws IllegalAccessException
* @throws InvocationTargetException
*/
public static Map<String, Object> getStringObjectMap(Object obj) throws IntrospectionException, IllegalAccessException, InvocationTargetException {
Class<?> aClass = obj.getClass();
Field[] fields = aClass.getDeclaredFields();
Map<String, Object> data = new HashMap<>(fields.length);
// 遍历对象的所有属性
for (Field field : fields) {
// 获取属性的名称
String fieldName = field.getName();
// 创建属性描述器,用于获取属性的读取方法
PropertyDescriptor pd = new PropertyDescriptor(fieldName, aClass);
// 获取属性的读取方法
Method method = pd.getReadMethod();
// 获取属性的值
Object value = method.invoke(obj);
// 如果属性的值不为空,则将属性名和属性值添加到Map中
if (value != null) {
data.put(fieldName, value);
}
}
return data;
}
/**
* 通过Map的方式填充word模板
*
* @param templatePath
* @param targetPath
* @param data
* @param fileType
*/
public static void fillWordDataByMap(String templatePath, String targetPath, Map<String, Object> data, int fileType) {
try (InputStream is = new FileInputStream(templatePath);
OutputStream out = new FileOutputStream(targetPath)) {
// 加载模板文件
Document doc = new Document(is);
DocumentBuilder builder = new DocumentBuilder(doc);
Map<String, String> toData = new HashMap<>();
// 遍历数据,填充模板
for (Map.Entry<String, Object> en : data.entrySet()) {
String key = en.getKey();
Object value = en.getValue();
if (key == null || value == null) {
continue;
}
if (value instanceof List) {
// 填充表格数据
DataTable dataTable = fillListData((List) value, key);
doc.getMailMerge().executeWithRegions(dataTable);
}
if (value instanceof BufferedImage) {
// 填充图像数据
builder.moveToMergeField(key);
builder.insertImage((BufferedImage) value);
}
String valueStr = String.valueOf(en.getValue());
toData.put(key, valueStr);
}
// 准备合并数据的数组
String[] fieldNames = new String[toData.size()];
String[] values = new String[toData.size()];
int i = 0;
for (Map.Entry<String, String> entry : toData.entrySet()) {
fieldNames[i] = entry.getKey();
values[i] = entry.getValue();
i++;
}
// 合并数据到模板
doc.getMailMerge().execute(fieldNames, values);
// 保存目标文件
doc.save(out, SaveOptions.createSaveOptions(fileType));
} catch (Exception e) {
throw new RuntimeException(e);
}
}
// private static License license = null;
// /**
// * 加载 license
// * 由于 aspose是商业组件,若没有license(可自行在网上查询license.xml),则会出现水印。
// */
// static {
// try {
// InputStream is = ContractUtil.class.getResourceAsStream("/license.xml");
// license = new License();
// license.setLicense(is);
// } catch (Exception e) {
// throw new RuntimeException("自动加载aspose证书文件失败!");
// }
// }
}
3.2 创建实体Bean
(1)首先,我们先定义和模板对应的数据,我们先定义列表里面的 员工薪资信息中 Worker 的数据
package VO;
import lombok.Data;
import lombok.AllArgsConstructor;
import lombok.Builder;
import java.math.BigDecimal;
import java.util.List;
/**
* 员工薪资信息
*
* @author fangxiang
* @date 2023/7/7 13:47
*/
@Data
@Builder
@AllArgsConstructor
public class Worker {
/**
* 员工姓名
*/
private String name;
/**
* 年龄
*/
private Integer age;
/**
* 性别
*/
private String sex;
/**
* 工资
*/
private BigDecimal salary;
}
(2)接着我们定义整个模板的基本数据:SalaryData
package VO;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.awt.image.BufferedImage;
import java.math.BigDecimal;
import java.util.List;
/**
* 文档模板数据
*
* @author fangxiang
* @date 2023/7/7 13:46
*/
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class SalaryData {
/**
* 公司名称
*/
private String companyName;
/**
* 员工薪资列表
*/
private List<Worker> workerList;
/**
* 工资总和
*/
private BigDecimal totalSalary;
/**
* 公司log
*/
private BufferedImage logImg;
}
(3)定义好以上数据之后,我们就可以开始进行数据的填充,工具类提供两种填充方法(代码案例是在本地执行的,所以记得替换本地的图片和文件地址)
1.一种是传递 Object 数据进行数据填充
2.另一种是传递 Map 数据进行数据填充
这里采用第一种方式进行数据的填充,个人也比较推荐使用domain数据
package org.example;
import VO.SalaryData;
import VO.Worker;
import com.aspose.words.SaveFormat;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.beans.IntrospectionException;
import java.io.FileInputStream;
import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
import java.math.BigDecimal;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
/**
*
* @author fangxiang
* @date 2023/7/7 13:47
* */
public class Test {
public static void main(String[] args) throws IOException, IntrospectionException, InvocationTargetException, IllegalAccessException {
// 封装员工薪资信息
Worker worker1 = Worker.builder()
.name("李雄")
.age(25)
.sex("男")
.salary(BigDecimal.valueOf(1000))
.build();
Worker worker2 = Worker.builder()
.name("李浩")
.age(25)
.sex("男")
.salary(BigDecimal.valueOf(2000))
.build();
List<Worker> workerList = Arrays.asList(worker1, worker2);
// 计算工资总和
BigDecimal totalSalary = workerList.stream()
.map(Worker::getSalary)
.reduce(BigDecimal.ZERO, BigDecimal::add);
// 读取图片
BufferedImage image = ImageIO.read(new FileInputStream("C:\\Users\\fangxiang\\Desktop\\鱼.png"));
BufferedImage bufferedImage = ContractUtil.resizeBufferedImage(image, 100, 100, true);
// 封装文档模板数据
SalaryData data = SalaryData.builder()
.companyName("上班不摸鱼有限公司")
.workerList(workerList)
.totalSalary(totalSalary)
.logImg(bufferedImage)
.build();
// 读取模板文件
Map<String, Object> dataMap = ContractUtil.getStringObjectMap(data);
String templatePath2 = "C:\\Users\\fangxiang\\Desktop\\模板.docx";
String docxPath = "C:\\Users\\fangxiang\\Desktop\\员工薪资统计表.docx";
ContractUtil.fillWordDataByMap(templatePath2, docxPath, dataMap, SaveFormat.DOCX);
}
}
3.3 结果展示
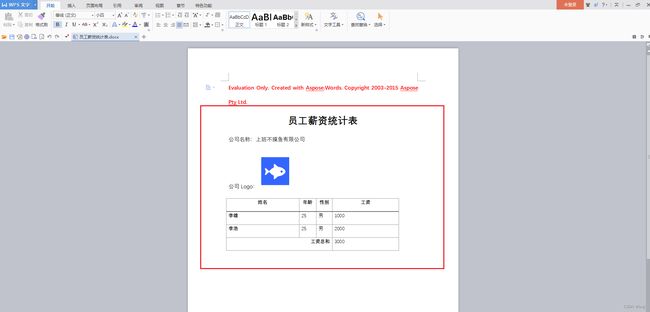
(1)水印说明
看上方的图相比大家也不难发现,文档生成的同时,也多了红色的一串字体。
由于aspose是商业组件的,所以想要去水印使用,需要添加 license.xml,由于实际业务中使用的是公司提供的凭证,所以我就不传上来了,如有需要,可以选择购买 aspose 的服务,或者上网搜一个 license.xml
(2)如何添加 license
我已经在工具类中提供了一个静态初始化方法,大家下载好 license.xml 之后,放入对应的目录,将注释部分去掉即可