XML——基本语法及使用规则
目录
1、XML简介
1.1、什么是XML?
1.2、XML和HTML之间的区别?
1.3、XML的作用
1.4、XML自定义标签
2、XML的语法结构
2.1、XML命名规则
2.2、XML声明
2.3、XML元素
2.4、XML注释
2.5、XML属性
2.6、CDATA区
3、XML约束
3.1、DTD约束
3.2、DTD约束抽取
3.3、DTD的属性
3.4、Schema约束
4、数据解析及常见解析XML方式
4.1、DOM方式
4.2、SAX方式
4.3、JDOM方式
4.4、DOM4J
1、XML简介
1.1、什么是XML?
XML 指可扩展标记语言(EXtensible Markup Language)。
XML 是一种很像HTML的标记语言。
XML 的设计宗旨是传输数据,而不是显示数据。
XML 标签没有被预定义。您需要自行定义标签。
XML 被设计为具有自我描述性。
XML 是 W3C 的推荐标准。
1.2、XML和HTML之间的区别?
XML不是HTML的替代,XML被设计是用来传输和存储数据的,其重点是数据的内容。
而HTML被设计是用来显示数据的,其重点是数据的外观样式。
XML 是独立于软件和硬件的信息传输工具
1.3、XML的作用
通常会把xml当作一个配置文件去使用。(在Spring Struts Hibernate Springmvc Mybatis等框架中作为配置文件)。
1.4、XML自定义标签
标签没有在任何 XML 标准中定义过(比如
和 )。这些标签是由 XML 文档的创作者发明的。XML 语言没有预定义的标签。HTML 中使用的标签都是预定义的。HTML 文档只能使用在 HTML 标准中定义过的标签(如 、
等等)。XML 允许创作者定义自己的标签和自己的文档结构。
2、XML的语法结构
2.1、XML命名规则
XML 元素必须遵循以下命名规则:
1、名称可以包含字母、数字以及其他的字符。
2、名称不能以数字或者标点符号开始。
3、名称不能以字母 xml(或者 XML、Xml 等等)开始。
4、名称不能包含空格。
5、可使用任何名称,没有保留的字词。
最佳命名习惯
使名称具有描述性。使用下划线的名称也很不错:
名称应简短和简单,比如:
避免 "-" 字符。如果您按照这样的方式进行命名:"first-name",一些软件会认为您想要从 first 里边减去 name。
避免 "." 字符。如果您按照这样的方式进行命名:"first.name",一些软件会认为 "name" 是对象 "first" 的属性。
避免 ":" 字符。冒号会被转换为命名空间来使用(稍后介绍)。
XML 文档经常有一个对应的数据库,其中的字段会对应 XML 文档中的元素。有一个实用的经验,即使用数据库的命名规则来命名 XML 文档中的元素。
在 XML 中,éòá 等非英语字母是完全合法的,不过需要留意,您的软件供应商不支持这些字符时可能出现的问题。
2.2、XML声明
XML 声明文件的可选部分,如果存在需要放在文档的第一行,如下所示:
2.3、XML元素
XML 元素指的是从(且包括)开始标签直到(且包括)结束标签的部分。
写法:<标签名>
在xml中,同样的去区分单标签和双标签
单标签 :<标签名 />
双标签:<标签名> 内容(文本,其他标签)
标签名是我们自己定义的。建议大家。采用标识符的命名规则去给一个标签起名字。(数字字母下划线,并且数字不能作为开头)
案例:
描述 书籍的信息。书名字,作者,单价。
标签的书写注意事项:
1、xml中的所有标签必须闭合。
2、xml中的标签名称严格区分大小写。
3、在xml标签名中间不要书写空格,或者 冒号 逗号 等符号。
标签的名字不要有空格一类特殊符号。
4、标签名不要以数字开始。(可以按照标识符的方式给标签去命名)
5、书写xml标签时 ,标签不能互相嵌套。
23zhangsan>
6、所有的xml文件只能有一个根标签。
7、我们可以通过浏览器来校验xml文件的格式是否正确。
三国演义
罗贯中
39.9
1.0
2.4、XML注释
xml中的注释和html中的注释的写法是一样的。
-------本身就是多行注释了。
注意:注释的内容,会在浏览器中显示出来。
书写注释的时候,内容尽可能的去避免 -- 字符
2.5、XML属性
属性:书写在标签内的。对标签的数据进行扩展。对标签的进一步描述。
写法:<标签名 属性名=“属性值” 属性名=“属性值”> 属性名也是自定义的。
注意问题:
1、如果是双标签,属性要书写在开始标签内
2、属性名不要出现空格,“;”“:” 特殊字符不要出现。
3、属性值必须用单引号,或者双引号包围起来。
2.6、CDATA区
CDATA区:可以输出特殊字符:原样的显示书写在CDATA的内容。会原封不动的显示出去。
我们可以使用预定义的实体,去替代一些特殊字符的输出。
注意实体的写法:&实体的名字;
| < | < | 小于 |
| > | > | 大于 |
| & | & | 和号 |
| &apos ; | ' | 单引 |
| " ; | "" | 双引 |
西游记
<吴承恩>
50
1.2
3、XML约束
什么是XML约束:对xml中的内容进行限制哪些怎么写有一定的约束限制,其实后面我都都是把xml作为配置文件来使用,所以我必须得看的懂xml中约束。
DTD目的: 可以看懂DTD文件,基于这个DTD文件可以写一个符合约束的xml文件。
XML约束分为两种: DTD约束、 Schema约束。
3.1、DTD约束
元素定义
| 语法 | 关键字 | 作用 | 示例 |
|---|---|---|---|
| #PCDATA | 代表文本元素,里面的内容必须是文本 | ||
| EMPTY | 不能包含任何子元素和文本,仅可以使用属性 | ||
| (e1,e2) | 代表混合元素,表示这个标签里面还有其他的节点 |
元素的限制
| 限制 | 格式 |
|---|---|
| 元素可以出现的次数 | 0或1:? 0~N:* 1~N:+ |
这个的元素次数指的是:例如下面案例books根目录下book这个标签能够出现的次数。
]>
当在xml文件中加入约束后,输入标签
3.2、DTD约束抽取
把DTD约束写到一个xml文件中有个弊端,就是只能这一个文件能够使用,为了方便以后多个文件可以共有这个DTD约束,我们需要把约束写到单独的一个.dtd文件中。
book.dtd文件
books.xml文件
西游记
吴承恩
29.9
水浒传
施耐庵
39.9
3.3、DTD的属性
定义标签中的属性
attribute list ,可以定义多个属性,为一个标签定义多个属性。
标签名:属性属于那个标签的。
属性名 属性的类型(CDATA (EN1|EN2) ) 属性的约束(REQUIRED)为了便于阅读。把多个属性进行换行。
属性名 属性的类型 属性的约束
属性名 属性的类型 属性的约束
| 值 | 解释 |
|---|---|
| CDATA | 表示文本 |
| #REQUIRED | 属性是必须的 |
| #IMPLIED | 属性非必须的 |
| #FIXED | 属性为固定字符串值 |
book.dtd文件
book.xml文件
西游记
吴承恩
29.9
水浒传
施耐庵
39.9
3.4、Schema约束
1、XML Schema是基于 XML 的 DTD 替代者。
2、XML Schema 符合XML语法结构,并且是可扩展的,后缀名为.xsd(xml schema document)。
3、XML Schema更容易地描述允许的文档内容,以及约束定义, 并支持名称空间。
配置xsd文件
引入xsd文件
红楼梦
曹雪芹
29.9
三国演义
罗贯中
39.9
4、数据解析及常见解析XML方式
4.1、DOM方式
DOM(Document Object Model). 是用与平台和语言无关的方式表示XML文档的官方W3C标准,将标记语言文档一次性加载进内存,在内存中形成一颗dom树。
优点
操作方便,可以对文档进行CRUD的所有操作
缺点
通常需要加载整个XML文档来构造层次结构,消耗资源大。
4.2、SAX方式
SAX处理的优点非常类似于流媒体的优点。分析能够立即开始,而不是等待所有的数据被处理。逐行读取,基于事件驱动的。
什么是事件驱动:一种基于回调机制的程序运行方法。由外至内一层一层解析。
优点
①不需要等待所有数据都被处理,分析就能立即开始。 ②只在读取数据时检查数据,不需要保存在内存中。 ③可以在某个条件得到满足时停止解析,不必解析整个文档。 ④效率和性能较高,能解析大于系统内存的文档。
缺点
只能读取,不能增删改
很难同时访问同一文档的不同部分数据,不支持XPath
4.3、JDOM方式
JDOM(Java-based Document Object Model)的目的是成为Java特定文档模型,它简化与XML的交互并且比使用DOM实现更快。
优点
①使用具体类而不是接口,简化了DOM的API。 ②大量使用了Java集合类,方便了Java开发人员。
缺点
①没有较好的灵活性。 ②性能较差。
4.4、DOM4J
dom4j是一个Java的XML API,类似于jdom,用来读写XML文件的。性能优异功能强大简单易用开放源代码。
优点
①大量使用了Java集合类,方便Java开发人员,同时提供一些提高性能的替代方法。 ②支持XPath。 ③有很好的性能。
缺点
大量使用了接口,API较为复杂
接下来我就演示一下使用DOM4J读取一下xml文件里的内容输出到控制台。
首先我们需要在目录下创建一个lib包,把下面的链接地址中的jar包放到lib包内,并手动添加到模块。
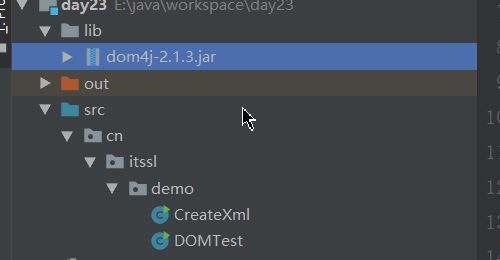
DOM4J的jar包链接如下:
链接:https://pan.baidu.com/s/1gwt_vNjALoae1ZsfKh-t_Q?pwd=6ly7
提取码:6ly7
Book.xml文件
西游记
吴承恩
29.9
水浒传
施耐庵
39.9
测试类
public class DOMTest {
public static void main(String[] args) throws DocumentException {
SAXReader reader=new SAXReader();
Document document = reader.read("Book.xml");
//获取根目录元素对象
Element dom = document.getRootElement();
//获取所有根目录下的子节点
List elements = dom.elements();
for (Element element : elements) {
//输出子节点的属性id值
System.out.println(element.attributeValue("id"));
//输出name值
System.out.println(element.elementText("name"));
//输出author值
System.out.println(element.elementText("author"));
//输出price值
System.out.println(element.elementText("price"));
System.out.println("----------------");
}
}
}