Java流式编程详细介绍
文章目录
- 1. 流式编程介绍
- 2. 过滤
-
- 2.1 filter
- 2.2 distinct
- 2.3 limit
- 2.4 sorted
- 2.5 skip
- 3. 映射
-
- 3.1 map
- 3.2 flatmap
- 4 查找
-
- 4.1 allMatch
- 4.2 anyMatch
- 4.3 noneMatch
- 4.4 findFirst
- 4.5 findAny
- 5. 归约
- 6. 收集
-
- 6.1 counting
- 6.2 maxBy,minBy
- 6.3 summingInt、summingLong、summingDouble
- 6.4 averageInt、averageLong、averageDouble
- 6.5 summarizingInt、summarizingLong、summarizingDouble
- 6.6 joining
- 6.7 groupingBy
- 7. 构建流
-
- 7.1 由值构建流
- 7.2 由数组创建流
- 7.3 由文件生成流
- 7.4 由函数生成流:创建无限流
- 8 构建流
-
- 8.1 由值构建流
- 8.2 由数组创建流
- 8.3 由文件生成流
- 8.4 由函数生成流:创建无限流
1. 流式编程介绍
流是从支持数据处理操作的源生成的元素序列。
流的操作特点如下:
- 元素序列:就像集合一样,流也提供了一个接口,可以访问特定元素类型的一组有序值
- 源:流会使用一个提供数据的源,如集合、数组或输入/输出资源
- 数据处理操作:流的数据处理功能支持类似于数据库的操作,以及函数式编程语言中的常用操作,如filter、map、reduce、find、match、sort等
- 流水线:很多流操作本身会返回一个流,这样多个操作就可以链接起来,形成一个大的流水线
- 内部迭代:与使用迭代器显式迭代的集合不同,流的迭代操作是在背后进行的
- 流只能遍历一次
以下数据进行举例,
List<User> list = new ArrayList<User>(){
{
add(new User(1l,"张三",10, "清华大学"));
add(new User(2l,"李四",12, "清华大学"));
add(new User(3l,"王五",15, "清华大学"));
add(new User(4l,"赵六",12, "清华大学"));
add(new User(5l,"田七",25, "北京大学"));
add(new User(6l,"小明",16, "北京大学"));
add(new User(7l,"小红",14, "北京大学"));
add(new User(8l,"小华",14, "浙江大学"));
add(new User(9l,"小丽",17, "浙江大学"));
add(new User(10l,"小何",10, "浙江大学"));
}
};
其中 User 定义如下:
@Data
@AllArgsConstructor
class User {
private Long id; //主键id
private String name; //姓名
private Integer age; //年龄
private String school; //学校
}
2. 过滤
2.1 filter
我们希望过滤赛选处所有学校是清华大学的user:
System.out.println("学校是清华大学的user");
List<User> userList1 = list.stream()
.filter(user -> "清华大学".equals(user.getSchool()))
.collect(Collectors.toList());
userList1.forEach(user -> System.out.print(user.name + '、'));
2.2 distinct
去重,我们希望获取所有user的年龄(年龄不重复)
System.out.println("所有user的年龄集合");
List<Integer> userAgeList = list.stream()
.map(User::getAge)
.distinct()
.collect(Collectors.toList());
System.out.println("userAgeList = " + userAgeList);
2.3 limit
返回前n个元素的流,当集合的长度小于n时,则返回所有集合。
如获取年龄是偶数的前2名user:
System.out.println("年龄是偶数的前两位user");
List<User> userList3 = list.stream()
.filter(user -> user.getAge() % 2 == 0)
.limit(2)
.collect(Collectors.toList());
userList3.forEach(user -> System.out.print(user.name + '、'));
2.4 sorted
排序,如现在我想将所有user按照age从大到小排序:
System.out.println("按年龄从大到小排序");
List<User> userList4 = list.stream()
.sorted((s1,s2) -> s2.getAge() - s1.getAge())
.collect(Collectors.toList());
userList4.forEach(user -> System.out.print(user.name + '、'));
2.5 skip
跳过n个元素后再输出,如输出list集合跳过前两个元素后的list
System.out.println("跳过前面两个user的其他所有user");
List<User> userList5 = list.stream()
.skip(2)
.collect(Collectors.toList());
userList5.forEach(user -> System.out.print(user.name + '、'));
3. 映射
3.1 map
/*
* 先找出集合中的偶数 再将这些偶数进行平方操作
*/
List<Integer> numbers=Arrays.asList(1,2,3,4,5,6,7,8,9);
List<Integer> evenNumbers=numbers.stream()
.filter(x->x%2==0)//寻找偶数
.map(x->x*x)
.collect(toList());
System.out.println(evenNumbers);//[2,4,6,8]->[4, 16, 36, 64]
3.2 flatmap
流的扁平化,相当于将流变为一维的数组。
List<String> words=Arrays.asList("Monday","Tuesday");
List<String> characters=words.stream()
.map(word->word.split(""))//将每个单词转化为一个字符串数组
.flatMap(Arrays::stream)//将每个字符数组扁平化
.collect(toList());
System.out.println(characters);//[M, o, n, d, a, y, T, u, e, s, d, a, y]
除了上面这类基础的map,java8还提供了 mapToDouble(ToDoubleFunction mapper),mapToInt(ToIntFunction mapper),mapToLong(ToLongFunction mapper),这些映射分别返回对应类型的流,java8为这些流设定了一些特殊的操作,比如查询学校是清华大学的user的年龄总和:
System.out.println("学校是清华大学的user的年龄总和");
int userList7 = list.stream()
.filter(user -> "清华大学".equals(user.getSchool()))
.mapToInt(User::getAge)
.sum();
System.out.println( "学校是清华大学的user的年龄总和为: "+userList7);
4 查找
4.1 allMatch
用于检测是否全部都满足指定的参数行为,如果全部满足则返回true,例如我们判断是否所有的user年龄都大于9岁,实现如下:
System.out.println("判断是否所有user的年龄都大于9岁");
Boolean b = list.stream()
.allMatch(user -> user.getAge() >9);
System.out.println(b);
输出为:
判断是否所有user的年龄都大于
9岁true
4.2 anyMatch
anyMatch则是检测是否存在一个或多个满足指定的参数行为,如果满足则返回true,例如判断是否有user的年龄大于15岁,实现如下:
System.out.println("判断是否有user的年龄是大于15岁");
Boolean bo = list.stream()
.anyMatch(user -> user.getAge() >15);
System.out.println(bo);
输出为:
判断是否有user的年龄是大于
15岁true
4.3 noneMatch
noneMatch用于检测是否不存在满足指定行为的元素,如果不存在则返回true,例如判断是否不存在年龄是15岁的user,实现如下:
System.out.println("判断是否不存在年龄是15岁的user");
Boolean boo = list.stream()
.noneMatch(user -> user.getAge() == 15);
System.out.println(boo);
输出如下:
判断是否不存在年龄是
15岁的userfalse
4.4 findFirst
findFirst用于返回满足条件的第一个元素,比如返回年龄大于12岁的user中的第一个,实现如下:
System.out.println("返回年龄大于12岁的user中的第一个");
Optional<User> first = list.stream()
.filter(u -> u.getAge() > 10)
.findFirst();
User user = first.get();
System.out.println(user.toString());
输出如下:
返回年龄大于
12岁的user中的第一个User{id=
2, name='李四', age=12, school='清华大学'}
4.5 findAny
findAny相对于findFirst的区别在于,findAny不一定返回第一个,而是返回任意一个,比如返回年龄大于12岁的user中的任意一个:
System.out.println("返回年龄大于12岁的user中的任意一个");
Optional<User> anyOne = list.stream()
.filter(u -> u.getAge() > 10)
.findAny();
User user2 = anyOne.get();
System.out.println(user2.toString());
输出如下:
返回年龄大于
12岁的user中的任意一个User{id=
2, name='李四', age=12, school='清华大学'}
5. 归约
归约即使用 reduce 函数,该函数使用用来求和的例子如下:
/*
* reduce的第一个参数:初始值 相当于给求和一个初值
* reduce的第二个参数:一个BinaryOperator来将两个元素结合起来产生一个新值
*/
List<Integer> numbers=Arrays.asList(4,3,5,9);
int sum=numbers.stream()
.reduce(0, (a,b)->a+b);
System.out.println("sum="+sum);//21
其执行的流程如下:
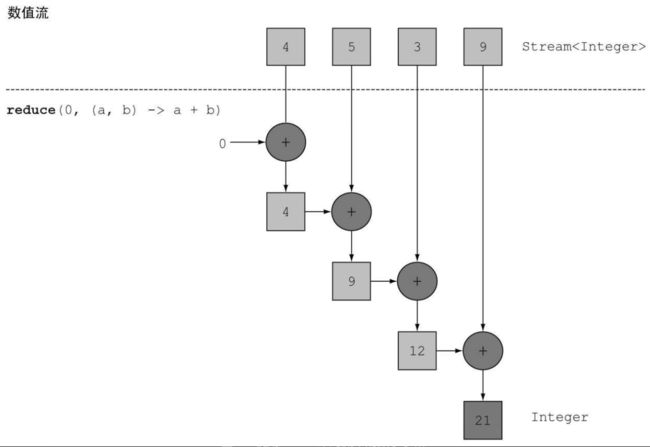
除此之外,reduce 还有另一个重载的方法,可以用来求最大值最小值等问题,示例如下,
/*
* reduce重载的变体
* 它不接受初始值,但是会返回一个Optional对象
*/
List<Integer> numbers=Arrays.asList(4,3,5,9);
Optional<Integer> maxNum=numbers.stream()
.reduce((x,y)->x>y?x:y);
Optional<Integer> minNum=numbers.stream()
.reduce((x,y)->x<y?x:y);
System.out.println("maxNum="+maxNum);//maxNum=Optional[9]
System.out.println("minNum="+minNum);//minNum=Optional[3]
6. 收集
前面利用 collect(Collectors.toList()) 是一个简单的收集操作,是对处理结果的封装,对应的还有 toSet、toMap,以满足我们对于结果组织的需求。这些方法均来自于java.util.stream.Collectors,我们可以称之为收集器。
收集器也提供了相应的归约操作,但是与reduce在内部实现上是有区别的,收集器更加适用于可变容器上的归约操作,这些收集器广义上均基于 Collectors.reducing() 实现。
6.1 counting
计算个数,如我现在计算user的总人数,实现如下:
System.out.println("user的总人数");
long COUNT = list.stream()
.count();//简化版本
long COUNT2 = list.stream()
.collect(Collectors.counting());//原始版本
System.out.println(COUNT);//10
System.out.println(COUNT2);//10
6.2 maxBy,minBy
计算最大值和最小值,如我现在计算user的年龄最大值和最小值:
System.out.println("user的年龄最大值和最小值");
Integer maxAge =list.stream()
.collect(Collectors.maxBy((s1, s2) -> s1.getAge() - s2.getAge()))
.get()
.getAge();
Integer maxAge2 = list.stream()
.collect(Collectors.maxBy(Comparator.comparing(User::getAge)))
.get()
.getAge();
Integer minAge = list.stream()
.collect(Collectors.minBy((S1,S2) -> S1.getAge()- S2.getAge()))
.get()
.getAge();
Integer minAge2 = list.stream()
.collect(Collectors.minBy(Comparator.comparing(User::getAge)))
.get()
.getAge();
System.out.println("maxAge = " + maxAge);//25
System.out.println("maxAge2 = " + maxAge2);//25
System.out.println("minAge = " + minAge);//10
System.out.println("minAge2 = " + minAge2);//10
6.3 summingInt、summingLong、summingDouble
总和,如计算user的年龄总和:
System.out.println("user的年龄总和");
Integer sumAge =list.stream()
.collect(Collectors.summingInt(User::getAge));
System.out.println("sumAge = " + sumAge);//145
6.4 averageInt、averageLong、averageDouble
平均值,如计算user的年龄平均值:
System.out.println("user的年龄平均值");
double averageAge = list.stream()
.collect(Collectors.averagingDouble(User::getAge));
System.out.println("averageAge = " + averageAge);
6.5 summarizingInt、summarizingLong、summarizingDouble
一次性查询元素个数、总和、最大值、最小值和平均值,
System.out.println("一次性得到元素个数、总和、均值、最大值、最小值");
long l1 = System.currentTimeMillis();
IntSummaryStatistics summaryStatistics = list.stream().collect(Collectors.summarizingInt(User::getAge));
long l111 = System.currentTimeMillis();
System.out.println("计算这5个值消耗时间为" + (l111-l1));
System.out.println("summaryStatistics = " + summaryStatistics);
输出如下:
一次性得到元素个数、总和、均值、最大值、最小值
计算这
5个值消耗时间为``3summaryStatistics = IntSummaryStatistics{count=
10, sum=145, min=10, average=14.500000, max=25}
6.6 joining
字符串拼接,如输出所有user的名字,用“,”隔开
System.out.println("字符串拼接");
String names = list.stream()
.map(User::getName)
.collect(Collectors.joining(","));
System.out.println("names = " + names);
输出如下:
字符串拼接
names = 张三,李四,王五,赵六,田七,小明,小红,小华,小丽,小何
6.7 groupingBy
分组,如将user根据学校分组、先按学校分再按年龄分、每个大学的user人数、每个大学不同年龄的人数:
System.out.println("分组");
Map<String, List<User>> collect1 = list.stream()
.collect(Collectors.groupingBy(User::getSchool));
Map<String, Map<Integer, Long>> collect2 = list.stream()
.collect(Collectors.groupingBy(User::getSchool, Collectors.groupingBy(User::getAge, Collectors.counting())));
Map<String, Long> collect3 = list.stream()
.collect(Collectors.groupingBy(User::getSchool, Collectors.counting()));
Map<String, Map<Integer, Map<String, Long>>> collect4 = list.stream()
.collect(Collectors.groupingBy(User::getSchool, Collectors.groupingBy(User::getAge, Collectors.groupingBy(User::getName,Collectors.counting()))));
System.out.println("collect1 = " + collect1);
System.out.println("collect2 = " + collect2);
System.out.println("collect3 = " + collect3);
System.out.println("collect4 = " + collect4);
输出如下:
分组
collect1 = {浙江大学=[User{id=
8, name='小华', age=14, school='浙江大学'}, User{id=9, name='小丽', age=17, school='浙江大学'}, User{id=10, name='小何', age=10, school='浙江大学'}], 北京大学=[User{id=5, name='田七', age=25, school='北京大学'}, User{id=6, name='小明', age=16, school='北京大学'}, User{id=7, name='小红', age=14, school='北京大学'}], 清华大学=[User{id=1, name='张三', age=10, school='清华大学'}, User{id=2, name='李四', age=12, school='清华大学'}, User{id=3, name='王五', age=15, school='清华大学'}, User{id=4, name='赵六', age=12, school='清华大学'}]}collect2 = {浙江大学={
17=1,10=1,14=1}, 北京大学={16=1,25=1,14=1}, 清华大学={10=1,12=2,15=1}}collect3 = {浙江大学=
3, 北京大学=3, 清华大学=4}collect4 = {浙江大学={
17={小丽=1},10={小何=1},14={小华=1}}, 北京大学={16={小明=1},25={田七=1},14={小红=1}}, 清华大学={10={张三=1},12={李四=1, 赵六=1},15={王五=1}}}
7. 构建流
7.1 由值构建流
使用静态方法 Stream.of,通过显式值创建一个流。
Stream<String> stream=Stream.of("Java","Python","Go");
stream.forEach(System.out::println);
7.2 由数组创建流
使用静态方法 Arrays.stream 从数组创建一个流。
int[] numbers= {1,2,3,4,5,6};
IntStream stream=Arrays.stream(numbers);
stream.forEach(System.out::println);
7.3 由文件生成流
Stream<String> lines=null;
try {
lines=Files.lines(Paths.get("data.txt"),Charset.defaultCharset());
lines.forEach(System.out::println);
} catch (IOException e) {
e.printStackTrace();
}finally {
lines.close();
}
7.4 由函数生成流:创建无限流
其迭代的一般格式如下:
/*
* iterate方法接受一个初始值(在这里是0),还有一个依次应用在每个产生的新值上的Lambda(UnaryOperator类型)
* 这里,我们使用Lambda n-> n+2,返回的是前一个元素加上2
*/
Stream.iterate(0,n->n+2)
.limit(10)
.forEach(System.out::println);
例如,如果需要迭代产生斐波那契数列,其代码如下:
Stream.iterate(new int[] {0,1},t->new int[] {t[1],t[0]+t[1]})
.limit(10)
.forEach(t->{System.out.println(t[0]+" "+t[1]);});
还有一种情况是生成,例如其生成10个随机数的代码如下,
Stream.generate(Math::random)
.limit(10)
.forEach(System.out::println);
1, 25=1, 14=1}, 清华大学={10=1, 12=2, 15=1}}
collect3 = {浙江大学=
3, 北京大学=3, 清华大学=4}collect4 = {浙江大学={
17={小丽=1},10={小何=1},14={小华=1}}, 北京大学={16={小明=1},25={田七=1},14={小红=1}}, 清华大学={10={张三=1},12={李四=1, 赵六=1},15={王五=1}}}
8 构建流
8.1 由值构建流
使用静态方法 Stream.of,通过显式值创建一个流。
Stream<String> stream=Stream.of("Java","Python","Go");
stream.forEach(System.out::println);
8.2 由数组创建流
使用静态方法 Arrays.stream 从数组创建一个流。
int[] numbers= {1,2,3,4,5,6};
IntStream stream=Arrays.stream(numbers);
stream.forEach(System.out::println);
8.3 由文件生成流
Stream<String> lines=null;
try {
lines=Files.lines(Paths.get("data.txt"),Charset.defaultCharset());
lines.forEach(System.out::println);
} catch (IOException e) {
e.printStackTrace();
}finally {
lines.close();
}
8.4 由函数生成流:创建无限流
其迭代的一般格式如下:
/*
* iterate方法接受一个初始值(在这里是0),还有一个依次应用在每个产生的新值上的Lambda(UnaryOperator类型)
* 这里,我们使用Lambda n-> n+2,返回的是前一个元素加上2
*/
Stream.iterate(0,n->n+2)
.limit(10)
.forEach(System.out::println);
例如,如果需要迭代产生斐波那契数列,其代码如下:
Stream.iterate(new int[] {0,1},t->new int[] {t[1],t[0]+t[1]})
.limit(10)
.forEach(t->{System.out.println(t[0]+" "+t[1]);});
还有一种情况是生成,例如其生成10个随机数的代码如下,
Stream.generate(Math::random)
.limit(10)
.forEach(System.out::println);