前言
代码覆盖率(Code coverage)是软件测试中的一种度量方式,用于反映代码被测试的比例和程度。
在软件迭代过程中,除了应该关注测试过程中的代码覆盖率,用户使用过程中的代码覆盖率也是一个非常有价值的指标,同样不可忽视。因为伴随着业务扩展和功能更新,产生了大量过时和废弃的代码,这些代码或者很少甚至完全不再使用,或者“年久失修”,缺少维护,不仅对应用包体积有影响,还可能带来稳定性风险。此时,能够采集生产环境的代码覆盖率,了解线上代码的使用情况,为下线无用代码提供依据,就十分重要了。
目标
我们的目标很明确:根据云端配置,采集线上每个类的触达和使用频次,上传到云端,在平台进行处理,并提供查询和报表展示能力。
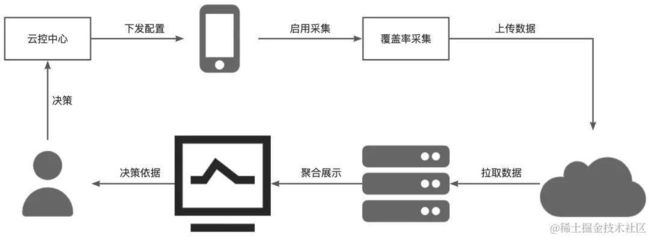
如上图所示,我们期望代码覆盖率数据能在平台上进行查询和直观的展示,在需要时可以直接查看,为下线旧代码、资源调度和分配等提供决策依据,最终为用户提供更小的App安装包,更好的功能使用体验。
通过云控中心,我们可以控制是否启用覆盖率采集,也可以根据覆盖率(类使用频次)动态调整App中金刚位、线程等资源的调度分配策略。其中覆盖率采集方案是最为重要的一环,业界也有很多成熟的方案,但都有各自适合的场景,而我们的诉求是在尽量不影响用户使用和App运行的前提下,采集类粒度的代码使用覆盖率。使用的采集方案应该少Hack,实现简单,兼顾稳定性和性能,同时也不会侵入打包流程,带来包体积影响等,在经过深入探索后,我们自研出了一套完美满足这些要求的全新方案。
方案对比
下表为常见方案与自研方案的各项指标对比,绿色表示更优。

从表格中可以看出:
Jacoco方案
类似的还有Emma、Cobertura等,他们都通过插桩实现,可以支持所有版本所有粒度的采集,但是插桩带来了一定的包体积和性能影响,不适合线上大范围使用。
Hook PathClassLoader方案
实现简单,无源码侵入,且支持所有Android版本,但Hook PathClassLoader不仅带来了性能影响,甚至可能波及App稳定性。
Hack访问ClassTable方案
能够按需采集,对App性能几乎没有影响,但Hack可能带来兼容性问题,且实现较复杂。
自研方案
- 性能优异,支持按需采集,无损App性能
- 实现简单,未使用任何“黑科技”,稳定性和兼容性极好
- 支持跨进程和插件采集
对比得知自研方案能更好的满足我们采集线上代码覆盖率的诉求,因为它不仅有着很好的稳定性,而且有着优异的性能,几乎不会对用户产生任何影响。那么它是如何做到高性能和高稳定性的呢?请看下文介绍。
方案介绍
原理
要采集类粒度的代码覆盖率,其实就是要知道在App运行过程中,加载和使用了哪些类。在Java应用中,这可以通过调用ClassLoader的findLoadedClass方法直接查询得到,而在Android App中却没那么简单。原因是Android系统做了这样一个优化:
为了提升启动性能,对于App自定义的类,即PathClassLoader加载的类,如果直接调用findLoadedClass进行查询,即使这个类没有加载,也会执行加载操作。
这不是我们期望的。
虽然我们没办法直接调用FindLoadedClass方法查询类的加载状态,但是经过深入研究和分析,我们发现ClassLoader最终是通过查询它的ClassTable字段得到类加载状态的,如果我们也能访问ClassTable,问题不就迎刃而解了吗?沿着这个思路,我们创新性地提出了复制ClassTable指针,通过标准API间接访问类加载状态的方案。
该方案巧妙地实现了对ClassTable的无Hack访问;同时完美绕开了我们不需要的类加载优化,寥寥数行代码就实现了类加载情况的获取,巧妙且简洁,同时它还具备以下优势:
- 采集速度是普通方案的5倍以上,性能优异
- 使用标准API访问ClassTable,兼容性与稳定性极佳
- 仅使用一次反射,无任何“黑科技”,简单稳定
- 不影响类加载及App运行
- 完美支持多进程和插件的采集
不过有一点需要注意:
ClassTable字段是从Android N开始引入的,所以该方法只适用于Android N及以上。出于必要性和ROI考虑,我们也未对Android N以下版本进行适配。
采集流程
基于上述的方案,我们设计了完整的代码覆盖率采集功能,关键流程如下:
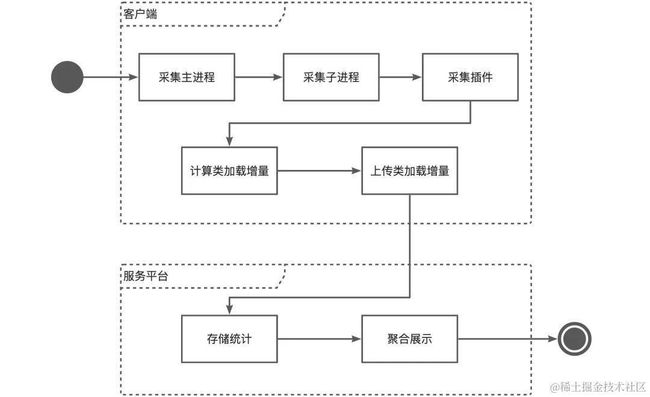
可以看到整个端侧的采集流程是串行的,非常便于流程控制和数据整合。下面说明一下设计思路:
- 采集时将App分为两部分,一部分是主进程和子进程使用的宿主类数据,另一部分是插件类数据。
- 基于查询方式采集,主进程、子进程、插件分别提供查询类加载状态的接口。
- 流程基于串行方式,由主进程控制,依次调用相应的接口采集主进程、子进程和插件的数据。
- 每个版本只采集和上报未加载过的类数据,首次采集时,以类全集为输入;后续的每次采集,以上一版本未加载的类为输入,采集次数越多,需要查询的类越少。
- 主进程和子进程依次查询,查询都以上一次查询后剩余的未加载类为输入,因此越靠后的子进程所需查询的数量越少,同一个插件在不同进程的实例的查询也与此类似。
如下图所示:
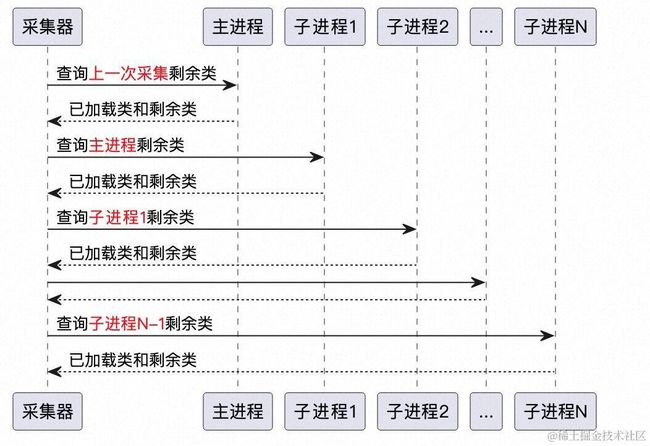
- 采集结束时,会生成一份宿主类数据和N份插件类数据(假如有N个插件)。这些数据会分别与之前的采集结果做Diff,将增量数据上传服务。
- 服务平台进行存储、解Mapping、模块关联等处理,最后以报表形式聚合展示。
值得注意的是:
- 主进程与子进程使用的类都属于宿主,采集结果应该合并为一份数据;同理,一个插件无论在多少个进程加载,最后也只应生成一份该插件的数据。
- 采集时我们将数据分为两部分,这样可以提高采集效率,也方便后续解混淆;在平台展示时,合并展示更有意义。
版本管理
Android App的代码大都会经过混淆处理,混淆后的类名会因版本而异,这就需要根据App版本来管理覆盖率数据。
按版本管理数据后,每个版本会清除上一版本的数据,避免数据错乱;一个特定的类,在当前版本已经使用过之后,会记录下来,后续此版本的采集不再重复查询它的使用情况。
每个版本首次采集时,需要以App的类名全集作为输入,每一次采集会产生一个未使用类的集合,作为下一次采集的输入。这样,一个版本中每次采集需要关注的类数量会逐步减少,可避免无意义的查询,提升采集性能。
类名数据获取
类名数据可以通过两种方式获取:
1.从安装包获取
安装包内的类名数据可以从PathClassLoader中获取,插件则可以从对应的BaseDexClassLoader中获取,使用如下方法即可:
public static List getClassesFromClassLoader(BaseDexClassLoader classLoader) throws ClassNotFoundException, IllegalAccessException {
//类名数据位于BaseDexClassLoader.pathList.dexElements.dexFile中,可以通过反射获取
//先获取pathList字段
Field pathListF = ReflectUtils.getField("pathList", BaseDexClassLoader.class);
pathListF.setAccessible(true);
Object pathList = pathListF.get(classLoader);
//获取pathList中的dexElements字段
Field dexElementsF = ReflectUtils.getField("dexElements", Class.forName("dalvik.system.DexPathList"));
dexElementsF.setAccessible(true);
Object[] array = (Object[]) dexElementsF.get(pathList);
//获取dexElements中的dexFile字段
Field dexFileF = ReflectUtils.getField("dexFile", Class.forName("dalvik.system.DexPathList$Element"));
dexFileF.setAccessible(true);
ArrayList classes = new ArrayList<>(256);
for (int i = 0; i < array.length; i++) {
//获取dexFile
DexFile dexFile = (DexFile) dexFileF.get(array[i]);
//遍历DexFile获取类名数据
Enumeration enumeration = dexFile.entries();
while (enumeration.hasMoreElements()) {
classes.add(enumeration.nextElement());
}
}
return classes;
}
这种方式简单直接,不过会一次性将DexFile中的所有类名加载到内存中,而根据我们的测试,每一万个类大约占0.8mb内存,对于动辄数万个类的大型App来说,会是一个不小的内存开销。所以还可以考虑第二种方式。
2.云化下载
从构建平台获取类名数据,上传到云化平台,App在需要的时候下载使用。
至于选用哪种方式,直接根据类数量来选取就好。类数量特别多时,如大型App场景,建议使用云化方式;普通App或插件,直接从安装包类获取即可。
子进程采集
主进程未加载的类,我们会交给子进程再次查询。这就需要子进程提供支持跨进程调用的查询接口,我们选择了简单可靠,且容易复用的AIDL方案来实现。
具体做法是:
通过AIDL定义查询接口,并定义对应的Action,在Service的onBind方法中根据Action返回查询接口的Binder实现类用于远程调用。
同时考虑到跨进程的成本较高,如果对每个类都调用一次查询接口,无疑是难以接受的。于是我们想到了文件+批量查询的方式:利用文件作为数据载体,将已加载的类和未加载的类都写入到文件中,在接口间传递文件路径。文件操作还可以采用BufferedReader和BufferedWriter以提升性能。
调用过程如图:
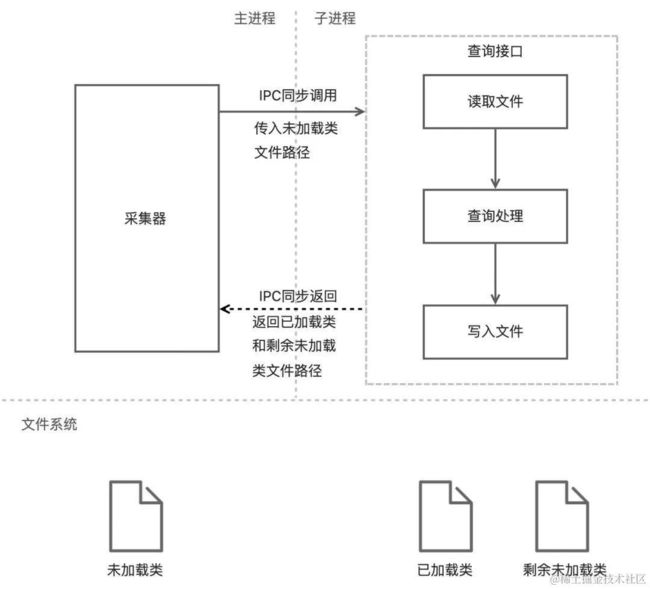
这样做的好处也显而易见:
- 采集一个进程仅需一次跨进程调用,成本极低
- 避免数据序列化的内存开销
- 绕开大数据无法直接跨进程传递的问题
- 采集流程更简单,可按需采集需要的进程
- 方便数据过滤,避免重复查询已加载类,提升采集性能
插件采集
对于宿主类,查询PathClassLoader对应的ClassTable即可。
而插件一般通过BaseDexClassLoader或其派生类进行加载,需要查询相应ClassLoader的ClassTable。
对于在子进程中使用的插件,只是多了跨进程接口调用,将已加载类和剩余类返回给主进程进行处理的操作。
采集步骤如下:
- 查询子进程类时,会同时查询该进程中运行的插件类,将数据写入按插件名划分的文件。
- 对主进程插件的采集是整个流程的最后一个环节,此时会检测每个插件对应的数据文件(子进程生成),并进行合并处理,最后将数据文件删除。
- 最后再处理剩余的插件数据文件,这部分文件属于只在子进程运行的插件。
到此,就得到了所有插件的类加载数据。
解Mapping
查看代码覆盖率数据时,我们期望看到原始的类名,所以解Mapping是必经之路。
解Mapping操作可以在端上进行,也可以在服务侧进行,出于安全性考虑,我们选择了服务侧。
Mapping文件由打包过程生成,每个安装包对应一份。我们的做法是在构建平台打正式包的时候通过脚本生成混淆类与明文类的映射文件,服务端在需要的时候通过App版本信息获取对应的映射文件,反解出原始类名,并与模块进行关联。
最终展示到平台的就是解完Mapping,并与模块、插件完成关联的代码覆盖率数据。
数据存储及增量计算
采集的数据需要存储起来,为了方便计算增量数据,我们选择了数据库作为存储方案,因为它天生具备去重及排序功能,而且性能也不错。具体的做法是:
- 创建一张数据表,只需包含一个名为class的列就行,该列声明为主键,不接受空值和重复。
- 每次采集前,获取其中的行数,采集过程中,将已加载的类名数据更新到表中,让数据库自动完成去重。采集完成后,再次获取数据行数,与采集前的行数相减得出的offset就是增量部分,我们只需要将这部分数据上传到服务。
性能和稳定性
经过我们的反复测试和调优,对5w+类的采集平均耗时约0.5s/次,采集期间内存增长在500kb左右,CPU无明显上涨。
同时也经过高德地图线上多个版本验证,未发现相关崩溃及ANR。
其他
绕开黑灰名单
Android P以后,官方将ClassTable成员变量加入了黑灰名单,在使用反射访问之前,需绕开SDK限制。我们采用的是元反射+设置豁免的方式,具体的实现可以参考GitHub上的开源项目FreeReflection,想要了解更多可自行Google查询。
采集时机和频率
虽然采集过程短暂无感,但为了最小的影响App的运行,我们将采集工作放在子线程中,并选择在App退后台一段时间后开始执行。
同时由于我们只需要知道代码使用的比例和大致情况,每次冷启后只采集一次即可。
多位用户多次冷启后的数据,已经足以反映真实的代码使用情况了。如果需要每个类的使用频次数据,在服务端聚合统计也能得到。
写在最后
代码覆盖率作为一种度量方式,不仅能为我们下线旧代码提供依据,同时还能反映某个功能的使用热度,可以为资源分配、调度决策等提供依据,是软件开发中一项不可或缺的重要工具。
我们这套全新的方案,简洁而不简单,巧妙地实现了无Hack采集,在保证高稳定性和不侵入源码的前提下,优雅地实现了生产环境代码覆盖率的高性能采集,已经过高德地图多版本验证,是一套成熟、稳定且高效的方案。在此分享出来,希望能为有同样诉求的同学提供一些借鉴和思路。