【论文精读】Masked Autoencoders Are Scalable Vision Learners
Masked Autoencoders Are Scalable Vision Learners
- 前言
- Abstract
- 1. Introduction
- 2. Related Work
-
- Masked language modeling
- Autoencoding
- Masked image encoding
- Self-supervised learning
- 3. Approach
-
- Masking
- MAE encoder
- MAE decoder
- Reconstruction target
- Simple implementation
- 4. ImageNet Experiments
-
- 4.1. Main Properties
- 4.2. Comparisons with Previous Results
- 4.3. Partial Fine-tuning
- 5. Transfer Learning Experiments
- 6. Discussion and Conclusion
- 阅读总结
前言
来自大神何凯明团队的工作,发表在CVPR2022,作为ViT的续作,解决了ViT的自监督学习问题,将通用的Transformer在CV领域再一次推进,文章的写作和思路都很值得借鉴,简单的方法也可以很硬核。
Paper: https://openaccess.thecvf.com/content/CVPR2022/papers/He_Masked_Autoencoders_Are_Scalable_Vision_Learners_CVPR_2022_paper.pdf
Code: https://github.com/facebookresearch/mae
Abstract
本文表明MAE是计算机视觉可扩展的自监督学习者。MAE的方法很简单:随机mask图像patch并重建丢失的像素。它基于两个核心设计:
- 设计一个非对称的编码器-解码器架构,编码器仅对可见的像素操作,解码器根据潜在的表征和mask tokens重建原始图像。
- mask高比例(如75%)的图像会产生不平凡且有意义的自监督任务。
将这两个方法结合起来可以高效训练大模型并提升准确性。在ViT-Huge模型上仅基于ImageNet-1K就能达到87.8%的准确率,优于监督预训练结果。
1. Introduction
由于模型和算力的快速发展,百万级别的数据已经无法满足当前的模型,需要上亿级别的标签数据。这种对数据的需求在NLP领域已经通过自监督学习的方式得到了解决,典型的模型有BERT和GPT。这些方法可以训练包含超过1000亿个参数的通用模型。
同样的思想也很自然应用到CV领域,但是应用起来却远远落后于在NLP中的效果。因此作者提出疑问:究竟是什么造成掩码自编码在CV和NLP领域的不同?作者尝试从以下几点进行回答:
- 架构不同。卷积一直占据CV领域主要地位,但是将mask标记或者位置信息集成到卷积中并不容易(掩码的部分卷着卷着可能就没了,很难单独拎出来)。好在ViT解决了这个问题。
- 信息密度不同。在NLP中,一个词就是一个高度语义的实体,缺失部分很容易产生歧义。但是在图片中,像素是冗余的,缺失很容易通过插值法复原。为了缓解差异,作者展示了一个简单的策略:随机掩码大部分图像块。这可以大大减少冗余,增大模型学习难度。


上述图片展示的是经过大量掩码后的图片通过MAE修复后与原图的对比结果。可以看到随机掩码75%的图像块基本可以复原原始图像语义信息,但是更大的掩码比例会在一定程度上丢失部分语义信息。
- 解码器层在文本和图像中发挥不同的作用。在视觉中,解码器重构像素,因此其输出的语义级别要低于常见的识别任务。而对于自然语言,解码器预测包含丰富语义信息的缺失单词。因此NLP中解码器只需要一层MLP,而CV需要更复杂的结构。
基于上述分析,本文提出简单、有效、可扩展的MAE,用于视觉的表示学习。MAE随机掩码图像块,并在像素空间进行重建。它具有非对称的编码器-解码器设计,解码器部分只操作未掩码图像块,轻量级的解码器重建掩码图像块,整个流程如下图所示:
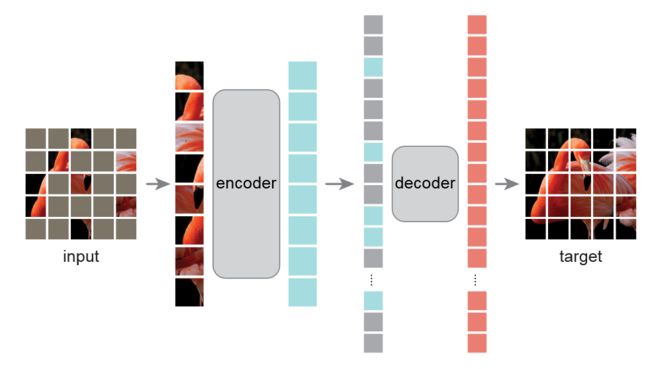
高掩码率的设计即可以提高模型的准确率,又可以减少预训练的时间和内存消耗。
MAE可以学习到泛化能力强的模型。在ImageNet-1K上训练ViT-Large/Huge,性能优于在百倍监督数据集下预训练的ViT。在目标检测、实体分割和语义分割的实验上也取得了比监督预训练更好的效果。更重要的是,模型的可扩展性和NLP中自监督训练有着一致的表现。
2. Related Work
Masked language modeling
掩码语言建模BERT和自回归模型GPT在NLP预训练方法中取得成功。这些方法已被证实具有良好的可扩展性,可以推广到各种下游任务。
Autoencoding
自编码是学习表征的经典方法。经典的自编码器包括PCA和k-means。去噪自编码器DAE是自编码器,它先破坏原始的输入信号,然后学习重建损坏的信号。MAE虽然也是去噪自编码器,但是很多方面与DAE不同。
Masked image encoding
通过对图像进行掩码学习表征。开创性工作如DAE,上下文编码器使用卷积网络修复大的缺失区域。最近的方法都是基于Transformer,如IGPT对像素序列操作并预测未知像素,ViT研究了自监督学习掩码图像块预测。最近,BEiTher提出预测离散token。
Self-supervised learning
最近对比学习很流行,对两个或多个图像之间的相似性或相异性建模,它主要依赖数据增强。而自编码器的自监督学习和对比学习是不一样的。
3. Approach
MAE是一个简单的自编码方法,可以根据部分观察结果重建原始信号。MAE有一个编码器将信号映射到潜在表征,一个解码器从潜在表征中重建原始信号。但是和典型的自编码器又有不同,采用不对称设计,编码器部分只对未掩码的token进行操作,而解码器采用轻量级设计,从潜在表征和掩码token重建信号。
Masking
遵循ViT的形式,我们将一张图片划分为互不相交的图像块。接着对图像块进行不放回随机采样,并对剩余图像块进行掩码。高掩码率让模型无法通过相近图像块轻松外推像素,高度稀疏的输入也有助于设计高效的编码器。
MAE encoder
编码器部分采用ViT,只对未掩码的图像块建模。首先将图像块线性映射为embedding再加入位置信息,然后通过一系列Transformer块处理。未掩码的图像块只占整个图像的小部分(25%),因此允许模型使用小部分计算和内存去训练大的编码器模型。
MAE decoder
解码器输入是完整的图像块序列。所有的掩码token通过一个共享的、可学习的向量表示,同时加入为所有的token加入位置信息。解码器部分只在预训练重建图像的时候使用,因此可以灵活设计解码器架构。作者采用计算量只有编码器10%的解码器,这样的非对称设计显著减少了预训练时间。
Reconstruction target
MAE通过预测掩码图像块的像素值来重建输入。输出的是每个图像块的像素向量,通过线性投影映射回原始的图像块大小。损失函数采用MSE,仅在掩码图像块上计算损失。
此外,作者还研究了重建目标是每个图像块的归一化像素值。具体来说,作者计算图像块中所有像素的平均值和标准差,使用它们来归一化该图像块。
这里其实只能在训练的时候采用该方法,因为训练时图像已知,可以计算出均值和方差,但是在预测时如何计算是个问题。
Simple implementation
整体过程如下:
- 为每个输入图像块生成embedding并加入位置信息。
- 随机打乱顺序进行掩码。
- 将未掩码的图像块输入到编码器中。
- 编码后将图像块序列恢复,让token与原始位置对齐,并加入位置信息。
- 输入解码器中对mask的图像块进行重建。
4. ImageNet Experiments
作者在ImageNet-1K数据集上进行自监督预训练,然后分别在端到端和最后线性层上进行微调。
Baseline: ViT-LArge. 下面是重头开始训练的ViT-L与微调MAE的比较:

从头开始训练ViT-L并非易事,但是ViT-L加上强正则化可以显著提升效果。尽管如此,MAE还是要高于ViT-L的结果。
4.1. Main Properties
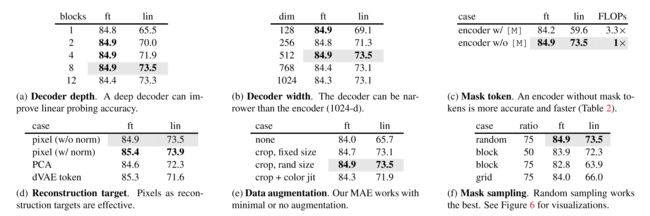
消融实验见上表,有如下的观察结果。
Masking ratio.

上表展示了mask比例对微调结果的影响,可以看到75%对于两种微调方式都是有利的。这与BERT观察到的结果形成鲜明的对比,BERT只有15%的掩码率。此外,上表还表明端到端微调和线性层微调遵循不同的趋势。后者对掩码比例明显更为敏感。
Decoder design.
解码器可以灵活设计,如4.1表中a和b。对于端到端微调来说,解码器的层数对结果几乎没有影响,单层Transformer就可以达到84.8%的出色表现,这可以显著加快训练速度。而足够深的解码器对线性层微调极为重要(最高能提升8%)。
表1b研究了解码器维度对性能的影响,512的维度在两个微调条件下都能表现良好。
Mask token.
MAE的一个重要设计是在编码器阶段跳过掩码图像块,并在解码器阶段应用。表1c研究了这种设计,可以发现,如果编码器加入了掩码token,效果会变差,可能原因是掩码的图像块并不真实存在, 这限制了编码器的性能。因此不添加掩码图像块是一举两得的操作,既能提高模型性能,又大大减少了计算量和内存消耗,实现了2.8倍的加速,对于更大的模型,加速效果更明显。

Reconstruction target.
表1d比较了不同的重建目标。经过标准化的像素可以提高准确性。另一种变体在图像块空间执行PCA并采用最大的PCA系数,这样做会降低准确性。
此外MAE还与BEiT进行了对比,比起tokenizer的方法,MAE不仅简单,而且性能更好。
Data augmentation.
表1e研究了数据增强对MAE预训练的影响。MAE仅在裁剪增强上性能会更好。这一属性和对比学习的相关方法显著不同,后者严重依赖数据增强。在MAE中,每次迭代掩码不同,都是新的数据,因此不满足数据增强的场景(训练数据不足)。
Mask sampling strategy.
表1f比较了不同的掩码采样策略,效果如下图所示:

大块掩码在50%的掩码率下最好,但是重建结果仍很模糊。网格采样掩码表示质量很低。因此,简单的随机采样最适合MAE。它允许更高的掩码比例,具有加速优势,同时准确性也更好。
Training schedule.
到目前为止都是基于800轮的预训练,下图显示了训练长度的影响:
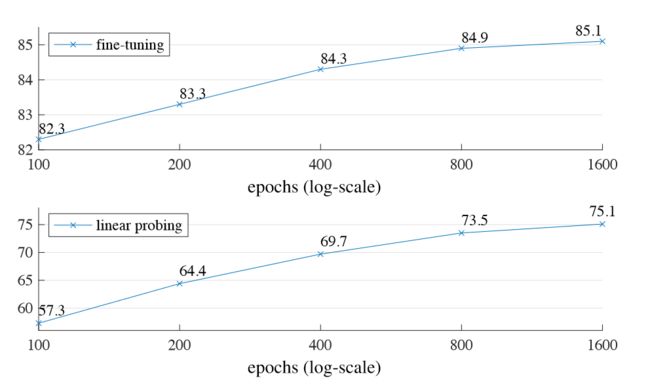
随着训练时间的延长,准确性稳步提高。甚至到1600轮仍未见饱和。
4.2. Comparisons with Previous Results
Comparisons with self-supervised methods.
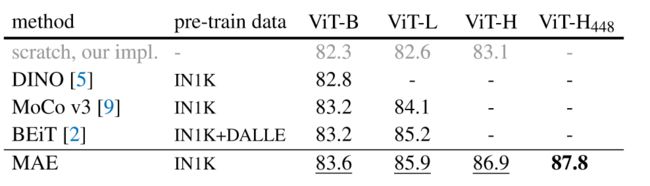
上表不同方法在ViT模型下的微调结果。随着模型越大,方法之间的差异增大,说明更大的模型面临着过拟合的问题。在ViT-H448上进行微调,MAE可以达到87.8%的准确率。比当前最先进的技术有着显著提升。
与BEiT相比,MAE更准确、更简单、更快速。结果见表1c。
Comparisons with supervised pre-training.

和最初的ViT-L相比,MAE的监督学习效果会更好,但准确性会饱和。MAE遵循JFT300M上进行监督预训练的趋势,这表明MAE可以帮助扩大模型的大小。
4.3. Partial Fine-tuning
表1显示了端到端微调和最后一层微调的巨大差距,但是这种差异的变化也是值得注意的。

上图展示了结果,值得注意的是,仅微调一个Transformer块即可将准确度从73.5%提高到81.0%。此外如果只微调Transformer块中的MLP层,也能获得79.1%的准确度。上图还和MoCo v3进行比较,MoCo线性微调效果好, 但是MAE具有更强的非线性特征,因此微调Transformer块效果会更好。
这些观察都表明线性层并不是评估表示质量的唯一标准,并且线性层和迁移学习性能没有相关性。
5. Transfer Learning Experiments

在目标检测任务上,MAE效果是最好的。

在语义分割任务上,MAE效果也是最好的。

在分类任务的迁移学习上,MAE表现出模型越大,准确性越高的趋势。大大优于SOTA。

上表比较了像素重建和token重建的差异,可以看出性能没有明显的差异,而重建token更为简单,因此MAE的方法无需进一步优化为dMAE。
6. Discussion and Conclusion
在NLP中,简单的自监督学习方法可以从指数可扩展的模型中受益。在CV中,尽管自监督学习取得进展,但是还是监督学习占据主导。本文在ImageNet和迁移学习上观察发现,自编码器可以类似NLP自监督学习方法提供可扩展的优势,自监督学习可能成为CV领域的新趋势。
另一方面,作者注意到图像和文本信息是有差异的,文本中一个词是语义单元,包含信息更多,而图像块常常不是特定的物体,可能是一个物体或者多个物体的一部分。尽管如此,MAE仍能重建像素,这说明MAE学习到了很多视觉上的概念,这对未来的工作将具有一定的启发意义。
阅读总结
简单的方法,优秀的性能,丰富的实验,再加上条理清晰的论文,这就是一个优秀工作所具备的品质。本文的引言部分以提问题的方法,一步步的寻求答案,让本文的方法浮出水面,这样的写作思路可以更好将读者带入故事中,帮助读者理解工作的细节。
MAE相当于是ViT的续作,解决了ViT中自监督学习方法的不足,也让我对做文章有了更深的认识,每篇文章,或多或少都有不足,有的会指出,有的不会,但说到底,如果读者能够做到精读论文,相信工作的不足你一定能够发现,那么这就是之后可以关注的重点,只要解决不足,不就又是一篇好的工作了,这样的效率可比盲目空想来的快多了。