2024年java面试--redis(1)
系列文章目录
- 2024年java面试(一)–spring篇
- 2024年java面试(二)–spring篇
- 2024年java面试(三)–spring篇
- 2024年java面试(四)–spring篇
文章目录
- 系列文章目录
- 前言
-
- Redis数据类型
- Redis可用性
-
- 1、redis持久化
- 2、redis事务
- 3、redis失效策略
- 4、redis读写模式
- 5、多级缓存
- 一、缓存雪崩
- 二、缓存穿透
- 三、缓存击穿
- 四、数据不一致
- 五、数据并发竞争
- 六、热点key问题
- 七、BigKey问题
前言
Redis数据类型
| 类型 | 底层 | 应用场景 |
|---|---|---|
| String | SDS数组 | 验证码、计数器、订单重复提交令牌、热点商品卡片、分布式锁 |
| List | QuickList | 简单队列、最新评论列表、非实时排行榜:定时计算榜单 |
| Hash | 哈希 | 购物车、个人信息、商品详情 |
| Set | inSet | 交集、并集、差集操作,例如朋友关系、去重 |
| Sorted set | 跳跃表 | 去重后排序,适合排名场景 |
Redis可用性
1、redis持久化
持久化就是把内存中的数据持久化到本地磁盘,防止服务器宕机了内存数据丢失
Redis 提供两种持久化机制 RDB(默认) 和 AOF 机制,Redis4.0以后采用混合持久化,用 AOF 来保证数据不丢失,作为数据恢复的第一选择; 用 RDB 来做不同程度的冷备
RDB: 是Redis DataBase缩写快照
RDB是Redis默认的持久化方式。按照一定的时间将内存的数据以快照的形式保存到硬盘中,对应产生的数据文件为dump.rdb。通过配置文件中的save参数来定义快照的周期。
优点:
1)只有一个文件 dump.rdb,方便持久化;
2)容灾性好,一个文件可以保存到安全的磁盘。
3)性能最大化,fork 子进程来进行持久化写操作,让主进程继续处理命令,只存在毫秒级不响应请求。
4)相对于数据集大时,比 AOF 的启动效率更高。
缺点:
数据安全性低,RDB 是间隔一段时间进行持久化,如果持久化之间 redis 发生故障,会发生数据丢失。
AOF:持久化
AOF持久化(即Append Only File持久化),则是将Redis执行的每次写命令记录到单独的日志文件中,当重启Redis会重新将持久化的日志中文件恢复数据。
优点:
1)数据安全,aof 持久化可以配置 appendfsync 属性,有 always,每进行一次 命令操作就记录到 aof 文件中一次。
2)通过 append 模式写文件,即使中途服务器宕机,可以通过 redis-check-aof 工具解决数据一致性问题。
缺点:
1)AOF 文件比 RDB 文件大,且恢复速度慢。
2)数据集大的时候,比 rdb 启动效率低。
2、redis事务
事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。
Redis事务的概念
Redis 事务的本质是通过MULTI、EXEC、WATCH等一组命令的集合。事务支持一次执行多个命令,一个事务中所有命令都会被序列化。在事务执行过程,会按照顺序串行化执行队列中的命令,其他客户端提交的命令请求不会插入到事务执行命令序列中。总结说:redis事务就是一次性、顺序性、排他性的执行一个队列中的一系列命令。
Redis的事务总是具有ACID中的一致性和隔离性,其他特性是不支持的。当服务器运行在AOF持久化模式下,并且appendfsync选项的值为always时,事务也具有耐久性。
Redis事务功能是通过MULTI、EXEC、DISCARD和WATCH 四个原语实现的
事务命令:
MULTI: 用于开启一个事务,它总是返回OK。MULTI执行之后,客户端可以继续向服务器发送任意多条命令,这些命令不会立即被执行,而是被放到一个队列中,当EXEC命令被调用时,所有队列中的命令才会被执行。
EXEC: 执行所有事务块内的命令。返回事务块内所有命令的返回值,按命令执行的先后顺序排列。当操作被打断时,返回空值 nil 。
WATCH : 是一个乐观锁,可以为 Redis 事务提供 check-and-set (CAS)行为。可以监控一个或多个键,一旦其中有一个键被修改(或删除),之后的事务就不会执行,监控一直持续到EXEC命令。(秒杀场景)
DISCARD: 调用该命令,客户端可以清空事务队列,并放弃执行事务,且客户端会从事务状态中退出。
UNWATCH :命令可以取消watch对所有key的监控。
3、redis失效策略
内存淘汰策略
1)全局的键空间选择性移除
noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。(字典库常用)
allkeys-lru:在键空间中,移除最近最少使用的key。(缓存常用)
allkeys-random:在键空间中,随机移除某个key。
2)设置过期时间的键空间选择性移除
volatile-lru:在设置了过期时间的键空间中,移除最近最少使用的key。
volatile-random:在设置了过期时间的键空间中,随机移除某个key。
volatile-ttl:在设置了过期时间的键空间中,有更早过期时间的key优先移除。
缓存失效策略
定时清除: 针对每个设置过期时间的key都创建指定定时器
惰性清除: 访问时判断,对内存不友好
定时扫描清除: 定时100ms随机20个检查过期的字典,若存在25%以上则继续循环删除。
4、redis读写模式
CacheAside旁路缓存
写请求更新数据库后删除缓存数据。读请求不命中查询数据库,查询完成写入缓存
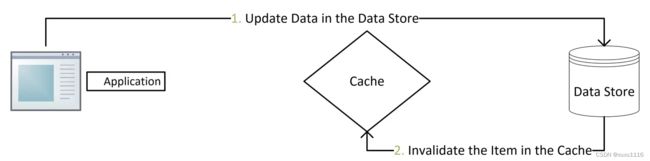

业务端处理所有数据访问细节,同时利用 Lazy 计算的思想,更新 DB 后,直接删除 cache 并通过 DB 更新,确保数据以 DB 结果为准,则可以大幅降低 cache 和 DB 中数据不一致的概率
如果没有专门的存储服务,同时是对数据一致性要求比较高的业务,或者是缓存数据更新比较复杂的业务,适合使用 Cache Aside 模式。如微博发展初期,不少业务采用这种模式
// 延迟双删,用以保证最终一致性,防止小概率旧数据读请求在第一次删除后更新数据库
public void write(String key,Object data){
redis.delKey(key);
db.updateData(data);
Thread.sleep(1000);
redis.delKey(key);
}
高并发下保证绝对的一致,先删缓存再更新数据,需要用到内存队列做异步串行化。非高并发场景,先更新数据再删除缓存,延迟双删策略基本满足了
- 先更新db后删除redis:删除redis失败则出现问题
- 先删redis后更新db:删除redis瞬间,旧数据被回填redis
- 先删redis后更新db休眠后删redis:同第二点,休眠后删除redis 可能宕机
- java内部jvm队列:不适用分布式场景且降低并发
Read/Write Though(读写穿透)
先查询缓存中数据是否存在,如果存在则直接返回,如果不存在,则由缓存组件负责从数据库中同步加载数据。

先查询要写入的数据在缓存中是否已经存在,如果已经存在,则更新缓存中的数据,并且由缓存组件同步更新到数据库中。

用户读操作较多.相较于Cache aside而言更适合缓存一致的场景。使用简单屏蔽了底层数据库的操作,只是操作缓存。
场景:
微博 Feed 的 Outbox Vector(即用户最新微博列表)就采用这种模式。一些粉丝较少且不活跃的用户发表微博后,Vector 服务会首先查询 Vector Cache,如果 cache 中没有该用户的 Outbox 记录,则不写该用户的 cache 数据,直接更新 DB 后就返回,只有 cache 中存在才会通过 CAS 指令进行更新。
5、多级缓存
浏览器本地内存缓存: 专题活动,一旦上线,在活动期间是不会随意变更的。
浏览器本地磁盘缓存: Logo缓存,大图片懒加载
服务端本地内存缓存: 由于没有持久化,重启时必定会被穿透
服务端网络内存缓存 :Redis等,针对穿透的情况下可以继续分层,必须保证数据库不被压垮
为什么不是使用服务器本地磁盘做缓存?
当系统处理大量磁盘 IO 操作的时候,由于 CPU 和内存的速度远高于磁盘,可能导致 CPU 耗费太多时间等待磁盘返回处理的结果。对于这部分 CPU 在 IO 上的开销,我们称为 iowait
一、缓存雪崩
指缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。
解决方案:
- Redis 高可用,主从+哨兵,Redis cluster,避免全盘崩溃
- 本地 ehcache 缓存 + hystrix 限流&降级,避免 MySQL 被打死。
- 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
- 逻辑上永不过期给每一个缓存数据增加相应的缓存标记,缓存标记失效则更新数据缓存
- 多级缓存,失效时通过二级更新一级,由第三方插件更新二级缓存。
二、缓存穿透
缓存穿透是指缓存和数据库中都没有的数据,导致所有的请求都落到数据库上,造成数据库短时间内承受大量请求而崩掉。
解决方案:
1)接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
2)从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒。这样可以防止攻击用户反复用同一个id暴力攻击;
3)采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被这个 bitmap 拦截掉,从而避免了对底层存储系统的查询压力。(宁可错杀一千不可放过一人)
三、缓存击穿
这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。和缓存雪崩不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案:
1)设置热点数据永远不过期,异步线程处理。
2)加写回操作加互斥锁,查询失败默认值快速返回。
3)缓存预热
系统上线后,将相关可预期(例如排行榜) 热点数据直接加载到缓存。
写一个缓存刷新页面,手动操作热点数据 (例如广告推广) 上下线。
四、数据不一致
在缓存机器的带宽被打满,或者机房网络出现波动时,缓存更新失败,新数据没有写入缓存,就会导致缓存和 DB 的数据不一致。缓存 rehash 时,某个缓存机器反复异常,多次上下线,更新请求多次 rehash。这样,一份数据存在多个节点,且每次 rehash 只更新某个节点,导致一些缓存节点产生脏数据。
- Cache 更新失败后,可以进行重试,则将重试失败的 key 写入mq,待缓存访问恢复后,将这些 key 从缓存删除。这些 key 在再次被查询时,重新从 DB 加载,从而保证数据的一致性
- 缓存时间适当调短,让缓存数据及早过期后,然后从 DB 重新加载,确保数据的最终一致性。
- 不采用 rehash 漂移策略,而采用缓存分层策略,尽量避免脏数据产生。
五、数据并发竞争
数据并发竞争在大流量系统也比较常见,比如车票系统,如果某个火车车次缓存信息过期,但仍然有大量用户在查询该车次信息。又比如微博系统中,如果某条微博正好被缓存淘汰,但这条微博仍然有大量的转发、评论、赞。上述情况都会造成并发竞争读取的问题。
- 加写回操作加互斥锁,查询失败默认值快速返回。
- 对缓存数据保持多个备份,减少并发竞争的概率
六、热点key问题
明星结婚、离婚、出轨这种特殊突发事件,比如奥运、春节这些重大活动或节日,还比如秒杀、双12、618 等线上促销活动,都很容易出现 Hot key 的情况。
如何提前发现HotKey?
- 对于重要节假日、线上促销活动这些提前已知的事情,可以提前评估出可能的热 key 来。
- 而对于突发事件,无法提前评估,可以通过 Spark,对应流任务进行实时分析,及时发现新发布的热点 key。而对于之前已发出的事情,逐步发酵成为热 key 的,则可以通过 Hadoop 对批处理任务离线计算,找出最近历史数据中的高频热 key。
解决方案:
- 这 n 个 key 分散存在多个缓存节点,然后 client 端请求时,随机访问其中某个后缀的 hotkey,这样就可以把热 key 的请求打散,避免一个缓存节点过载
- 缓存集群可以单节点进行主从复制和垂直扩容
- 利用应用内的前置缓存,但是需注意需要设置上限
- 延迟不敏感,定时刷新,实时感知用主动刷新
- 和缓存穿透一样,限制逃逸流量,单请求进行数据回源并刷新前置
- 无论如何设计,最后都要写一个兜底逻辑,千万级流量说来就来
七、BigKey问题
比如互联网系统中需要保存用户最新 1万 个粉丝的业务,比如一个用户个人信息缓存,包括基本资料、关系图谱计数、发 feed 统计等。微博的 feed 内容缓存也很容易出现,一般用户微博在 140 字以内,但很多用户也会发表 1千 字甚至更长的微博内容,这些长微博也就成了大 key
- 首先Redis底层数据结构里,根据Value的不同,会进行数据结构的重新选择
- 可以扩展新的数据结构,进行序列化构建,然后通过 restore 一次性写入
- 将大 key 分拆为多个 key,设置较长的过期时间