【kubernetes系列】Calico原理及配置
概述
Calico是针对容器,虚拟机和基于主机的本机工作负载的开源网络和网络安全解决方案。
Calico支持广泛的平台,包括Kubernetes,OpenShift,Docker EE,OpenStack和裸机服务。
Calico在每个计算节点都利用Linux Kernel实现了一个高效的vRouter来负责数据转发。每个vRouter都通过BGP协议把在本节点上运行的容器的路由信息向整个Calico网络广播,并自动设置到达其他节点的路由转发规则。
Calico将灵活的网络功能与无处不在的安全性实施相结合,以提供具有本地Linux内核性能和真正的云原生可扩展性的解决方案。
Calico为开发人员和集群运营商提供了一致的经验和功能集,无论是在公共云中还是本地运行,在单个节点上还是在数千个节点集群中运行。
Calico架构

Calico网络模型主要工作组件:
-
Felix:calico的核心组件,运行在每一台 Host 的 agent 进程,主要的功能有接口管理、路由规则、ACL规则和状态报告
- 接口管理:Felix为内核编写一些接口信息,以便让内核能正确的处理主机endpoint的流量。特别是主机之间的ARP请求和处理ip转发。
- 路由规则:Felix负责主机之间路由信息写到linux内核的FIB(Forwarding Information Base)转发信息库,保证数据包可以在主机之间相互转发。
- ACL规则:Felix负责将ACL策略写入到linux内核中,保证主机endpoint的为有效流量不能绕过calico的安全措施。
- 状态报告:Felix负责提供关于网络健康状况的数据。特别是,它报告配置主机时出现的错误和问题。这些数据被写入etcd,使其对网络的其他组件和操作人员可见。
-
etcd:分布式键值存储,主要负责网络元数据一致性,确保Calico网络状态的准确性,可以与kubernetes共用;
-
bird(BGP Client):BGP客户端,Calico在每个节点上的都会部署一个BGP客户端,当 Felix 将路由写入 kernel FIB中时 BGP Client 将通过 BGP 协议广播告诉剩余 calico 节点,从而实现网络互通。
-
confd:通过监听etcd以了解BGP配置和全局默认值的更改(例如:AS number、日志级别、IPAM信息)。Confd根据ETCD中数据的更新,动态生成BIRD配置文件。当配置文件更改时,confd触发BIRD重新加载新文件。
Calico两种网络模式
Calico本身支持多种网络模式,从overlay和underlay上区分。Calico overlay 模式,一般也称Calico IPIP或VXLAN模式,不同Node间Pod使用IPIP或VXLAN隧道进行通信。Calico underlay 模式,一般也称calico BGP模式,不同Node Pod使用直接路由进行通信。在overlay和underlay都有nodetonode mesh(全网互联)和Route Reflector(路由反射器)。如果有安全组策略需要开放IPIP协议;要求Node允许BGP协议,如果有安全组策略需要开放TCP 179端口;官方推荐使用在Node小于100的集群,我们在使用的过程中已经通过IPIP模式支撑了100-200规模的集群稳定运行。
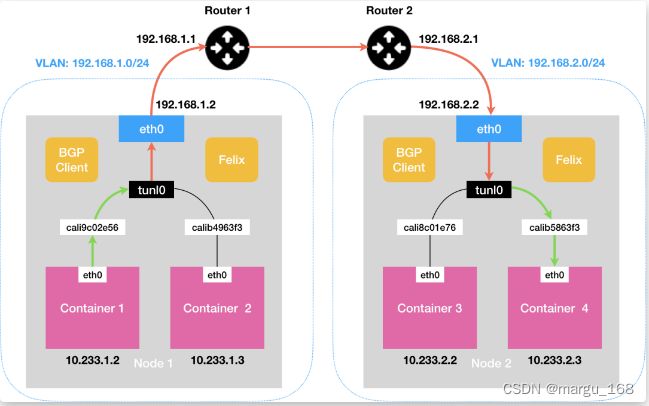
IPIP网络
流量:tunl0设备封装数据,形成隧道,承载流量。
适用网络类型:适用于互相访问的Pod所在宿主机不在同一个网段中,跨网段访问的场景,外层封装的IP能够解决跨网段的路由问题
效率:流量需要tunl0设备封装,效率略低
BGP网络
流量:使用主机路由表信息导向流量
适用网络类型:适用于互相访问的Pod所在宿主机在同一个网段。
效率:原生hostGW,效率高。

路由更新速率问题
为什么要考虑路由更新速率?在Calico默认的使用模式中,Calico每个Node一个分配一个Block,每个Block默认为64个IP,当单个Node启动的Pod超过64时,才会分配下一个Block。Calico BGP client默认只向外通告聚合后的Block的路由,默认配置,只有在Node上下线、Node上Pod数量超过Block size的倍数才会出现路由的更新,路由的条目数量是Node级别的。
而实际业务在使用的过程中,会针对一个服务或者一个deployment分配一个IP Pool,这种使用模式会导致Calico的IP Pool没有办法按照Node聚合,出现一些零散的无法聚合的IP地址,最差的情况,会导致每个Pod产生一条路由,会导致路由的条目变为Pod级别。
在默认情况下,交换机设备为了防止路由震荡,会对BGP路由进行收敛保护。但是Kubernetes集群中,Pod生命周期短,变化频繁,需要关闭网络设备的路由变更保护机制才能满足Kubernetes的要求;对于不同的网络设备,路由收敛速度也是不同的,在大规模Pod扩容和迁移的场景,或者进行双数据中心切换,除了考虑Pod的调度时间、启动时间,还需要对网络设备的路由收敛速度进行性能评估和压测。
路由黑洞问题
使用Calico Downward Default模型组网时,Node使用EBGP模式与Node建立邻居关系。当Pod使用的IP地址为内部统一规划的地址,出现Pod IP地址紧张的时候,会出现Pod之间不能正常访问的情况。(注:只会在EBGP模式下才会出现)
Calico分配IP地址的原则为,将整个IPPool分为多个地址块,每个Node获得一个Block,当有Pod调度到某个Node上时,Node优先使用Block内的地址。如果每个新增的Node分不到一个完整的地址块(也就是说Node无法获得整个网段64个IP),Calico IP地址管理功能会去使用其他Node的Block的IP,此时,就会出现Pod无法访问的现象。
如下图所示,Pod 10.168.73.82无法访问Pod 10.168.73.83。

查看Node 10.0.0.70的路由表,其中“blackhole 10.168.73.80/28 proto bird”为黑洞路由。如果没有其他优先级更高的路由,主机会将所有目的地址为10.168.73.80/28的网络数据丢弃掉。所以在Node 10.0.0.70上ping Pod 10.168.73.84会报“参数不合法”的错误。此时,在Downward Default模式下,Calico配置的这一条黑洞路由使得Node 10.0.0.70不能够响应其他Node上PodIP在10.168.73.80/28网段发起的网络请求。
要解决路由黑洞问题问题,首先,除了对整个Calico 的IP Pool总量进行监控外,还需要对可用的IP Block进行监控,确保不会出现IP Block不够分的情况,或者或者IP地址Block借用的情况;也可以通过在规划时计算IP地址总量,以及在kubelet配置参数中指定maxPods来规避这个问题;(注:一般我们会配置子网为/16也就是说能容纳65536个POD。如果一台主机一个block块(64个IP)那么也要1024个主机。为什么是1024,因为65536/64=1024,用总的IP数除以一个block块的IP数可以计算出总共有多少个block,上面也提到过当一个新的主机无法获得一个完整的block的时候才会出现路由黑洞。所以只要主机不超过1024台或者block块不超过1024个就不会出现。)
Calico 数据流向测试
IPIP模式(VXLAN模式,overlay模式)
IPIP模式部署
下载所需版本,如此次实验选择3.8版本的calico,注意版本匹配。
[root@k8s-m1 k8s-total]# curl https://docs.projectcalico.org/v3.8/manifests/calico.yaml -O
修改相应配置,主要修改参数为IP_AUTODETECTION_METHOD,CALICO_IPV4POOL_CIDR,分别是网卡名字(最好指定一下),集群pod所规划使用的网段。默认模式CALICO_IPV4POOL_IPIP为IPIP模式,不用修改。
[root@k8s-m1 k8s-total]# vim calico.yaml
......
- name: IP_AUTODETECTION_METHOD
value: "interface=en.*"
......
- name: CALICO_IPV4POOL_CIDR
value: "10.244.0.0/16"
[root@k8s-m1 k8s-total]# kubectl apply -f calico.yaml
IPIP模式抓包分析
#pod是在网络部署好后部署的哈,不然不生效
[root@k8s-m1 k8s-total]# kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
liveness-exec-pod 1/1 Running 0 31s 10.244.81.129 k8s-m2 <none> <none>
my-nginx-7ff446c4f4-4mxf7 1/1 Running 0 31s 10.244.81.130 k8s-m2 <none> <none>
my-nginx-7ff446c4f4-68qgf 1/1 Running 0 31s 10.244.11.1 k8s-m3 <none> <none>
my-nginx-7ff446c4f4-crg2t 1/1 Running 0 31s 10.244.42.130 k8s-m1 <none> <none>
#用不在同一节点的pod进行ping测试,用k8s-m2节点上的liveness-exec-pod去pingk8s-m1上的my-nginx-7ff446c4f4-crg2t
[root@k8s-m1 k8s-total]# kubectl exec -it liveness-exec-pod -- /bin/sh
/ # cat /sys/class/net/eth0/iflink
44
/ # ping 10.244.42.130
PING 10.244.42.130 (10.244.42.130): 56 data bytes
64 bytes from 10.244.42.130: seq=0 ttl=62 time=0.924 ms
64 bytes from 10.244.42.130: seq=1 ttl=62 time=0.515 ms
64 bytes from 10.244.42.130: seq=2 ttl=62 time=0.311 ms
64 bytes from 10.244.42.130: seq=3 ttl=62 time=0.408 ms
64 bytes from 10.244.42.130: seq=4 ttl=62 time=0.336 ms
64 bytes from 10.244.42.130: seq=5 ttl=62 time=0.373 ms
64 bytes from 10.244.42.130: seq=6 ttl=62 time=0.327 ms
64 bytes from 10.244.42.130: seq=7 ttl=62 time=0.324 ms
到相应节点k8s-m2查看44对应的网卡
[root@k8s-m2 tmp]# ip a
......
44: cali1aedec25590@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1440 qdisc noqueue state UP group default
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 6
......
抓各网卡的包
#抓对应的calico网卡的包
[root@k8s-m2 tmp]# tcpdump -i cali1aedec25590 -p icmp -nn -vv
tcpdump: listening on cali1aedec25590, link-type EN10MB (Ethernet), capture size 262144 bytes
11:26:53.726278 IP (tos 0x0, ttl 64, id 45828, offset 0, flags [DF], proto ICMP (1), length 84)
10.244.81.129 > 10.244.42.130: ICMP echo request, id 293, seq 0, length 64
11:26:53.726934 IP (tos 0x0, ttl 62, id 47729, offset 0, flags [none], proto ICMP (1), length 84)
10.244.42.130 > 10.244.81.129: ICMP echo reply, id 293, seq 0, length 64
11:26:54.726569 IP (tos 0x0, ttl 64, id 46533, offset 0, flags [DF], proto ICMP (1), length 84)
10.244.81.129 > 10.244.42.130: ICMP echo request, id 293, seq 1, length 64
11:26:54.726941 IP (tos 0x0, ttl 62, id 48017, offset 0, flags [none], proto ICMP (1), length 84)
10.244.42.130 > 10.244.81.129: ICMP echo reply, id 293, seq 1, length 64
11:26:55.726715 IP (tos 0x0, ttl 64, id 46783, offset 0, flags [DF], proto ICMP (1), length 84)
10.244.81.129 > 10.244.42.130: ICMP echo request, id 293, seq 2, length 64
11:26:55.726947 IP (tos 0x0, ttl 62, id 48359, offset 0, flags [none], proto ICMP (1), length 84)
10.244.42.130 > 10.244.81.129: ICMP echo reply, id 293, seq 2, length 64
^C
6 packets captured
6 packets received by filter
0 packets dropped by kernel
抓取tunl0网卡的包
[root@k8s-m2 tmp]# tcpdump -i tunl0 -p icmp -nn -vv
tcpdump: listening on tunl0, link-type RAW (Raw IP), capture size 262144 bytes
11:27:03.728072 IP (tos 0x0, ttl 63, id 51052, offset 0, flags [DF], proto ICMP (1), length 84)
10.244.81.129 > 10.244.42.130: ICMP echo request, id 293, seq 10, length 64
11:27:03.728396 IP (tos 0x0, ttl 63, id 52657, offset 0, flags [none], proto ICMP (1), length 84)
10.244.42.130 > 10.244.81.129: ICMP echo reply, id 293, seq 10, length 64
11:27:04.728226 IP (tos 0x0, ttl 63, id 51353, offset 0, flags [DF], proto ICMP (1), length 84)
10.244.81.129 > 10.244.42.130: ICMP echo request, id 293, seq 11, length 64
11:27:04.728427 IP (tos 0x0, ttl 63, id 53519, offset 0, flags [none], proto ICMP (1), length 84)
10.244.42.130 > 10.244.81.129: ICMP echo reply, id 293, seq 11, length 64
^C
4 packets captured
4 packets received by filter
0 packets dropped by kernel
#抓宿主机网卡ens32的包
[root@k8s-m2 tmp]# tcpdump -i ens32 -p icmp -nn -vv
tcpdump: listening on ens32, link-type EN10MB (Ethernet), capture size 262144 bytes
11:27:10.213820 IP (tos 0x0, ttl 63, id 41514, offset 0, flags [DF], proto ICMP (1), length 84)
192.168.2.141 > 14.119.104.189: ICMP echo request, id 1, seq 25836, length 64
11:27:10.251297 IP (tos 0x0, ttl 54, id 41514, offset 0, flags [DF], proto ICMP (1), length 84)
14.119.104.189 > 192.168.2.141: ICMP echo reply, id 1, seq 25836, length 64
11:27:11.019276 IP (tos 0xc0, ttl 64, id 19115, offset 0, flags [none], proto ICMP (1), length 68)
192.168.2.141 > 192.168.2.140: ICMP 192.168.2.141 protocol 112 unreachable, length 48
IP (tos 0xc0, ttl 255, id 39093, offset 0, flags [none], proto VRRP (112), length 40)
192.168.2.140 > 192.168.2.141: vrrp 192.168.2.140 > 192.168.2.141: VRRPv2, Advertisement, vrid 47, prio 100, authtype none, intvl 3s, length 20, addrs: 192.168.2.250
^C
3 packets captured
5 packets received by filter
0 packets dropped by kernel
通过以上抓包可以看到IPIP模式下,不同节点上的pod服务器通信时流量要经过tunl0隧道。
BGP模式(underlay模式)
BGP模式部署
下载所需版本,如此次实验选择3.8版本的calico
[root@k8s-m1 k8s-total]# curl https://docs.projectcalico.org/v3.8/manifests/calico.yaml -O
修改相应配置,主要修改参数为IP_AUTODETECTION_METHOD,CALICO_IPV4POOL_IPIP,CALICO_IPV4POOL_CIDR,分别是网卡名字(最好指定一下),calico模式(默认为IPIP),集群pod所规划使用的网段。
[root@k8s-m1 k8s-total]# vim calico.yaml
......
- name: IP_AUTODETECTION_METHOD
value: "interface=en.*"
# Enable IPIP
- name: CALICO_IPV4POOL_IPIP
value: "NEVER"
......
- name: CALICO_IPV4POOL_CIDR
value: "10.244.0.0/16"
[root@k8s-m1 k8s-total]# kubectl apply -f calico.yaml
BGP模式抓包分析
# 改变模式后,pod需要重启或者重新部署
[root@k8s-m1 ~]# kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
liveness-exec-pod 1/1 Running 1 23d 10.244.81.137 k8s-m2 <none> <none>
my-nginx-7ff446c4f4-4tlvq 1/1 Running 1 23d 10.244.11.6 k8s-m3 <none> <none>
my-nginx-7ff446c4f4-ctc4z 1/1 Running 1 23d 10.244.42.136 k8s-m1 <none> <none>
my-nginx-7ff446c4f4-pzt57 1/1 Running 1 23d 10.244.81.133 k8s-m2 <none> <none>
#ping不在同一节点的pod,用k8s-m2节点上的liveness-exec-pod去ping k8s-m1上的my-nginx-7ff446c4f4-ctc4z
```bash
[root@k8s-m1 k8s-total]# kubectl exec -it liveness-exec-pod -- /bin/sh
/ # route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 169.254.1.1 0.0.0.0 UG 0 0 0 eth0
169.254.1.1 0.0.0.0 255.255.255.255 UH 0 0 0 eth0
/ # cat /sys/class/net/eth0/iflink
22
/ # ping 10.244.42.136
PING 10.244.42.136 (10.244.42.136): 56 data bytes
64 bytes from 10.244.42.136: seq=0 ttl=62 time=0.886 ms
64 bytes from 10.244.42.136: seq=1 ttl=62 time=0.310 ms
64 bytes from 10.244.42.136: seq=2 ttl=62 time=0.363 ms
^C
--- 10.244.42.136 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.310/0.519/0.886 ms
需要到相应节点 k8s-m2查看22对应的网卡
[root@k8s-m2 tmp]# ip a
.......
22: cali1aedec25590@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1440 qdisc noqueue state UP group default
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 7
#查看路由
[root@k8s-m2 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.2.254 0.0.0.0 UG 0 0 0 ens32
10.244.11.0 192.168.2.142 255.255.255.192 UG 0 0 0 tunl0
10.244.42.128 192.168.2.140 255.255.255.192 UG 0 0 0 tunl0
10.244.81.128 0.0.0.0 255.255.255.192 U 0 0 0 *
10.244.81.131 0.0.0.0 255.255.255.255 UH 0 0 0 calie36faad9b67
10.244.81.132 0.0.0.0 255.255.255.255 UH 0 0 0 calia58b0be7967
10.244.81.133 0.0.0.0 255.255.255.255 UH 0 0 0 cali22acb9107e2
10.244.81.134 0.0.0.0 255.255.255.255 UH 0 0 0 califdbaebb8b47
10.244.81.136 0.0.0.0 255.255.255.255 UH 0 0 0 cali47a9b4d2641
10.244.81.137 0.0.0.0 255.255.255.255 UH 0 0 0 cali1aedec25590
169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 ens32
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
172.18.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker_gwbridge
192.168.2.0 0.0.0.0 255.255.255.0 U 0 0 0 ens32
可以看到到10.244.42.128网段(ping的IP为10.244.42.136)的网关地址就是该网段所在宿主机的IP地址192.168.2.140(上面路由的第3条,类似于flannel的host-gw模式)
对相应网卡进行抓包
[root@k8s-m2 ~]# tcpdump -i cali1aedec25590 -p icmp -nn
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on cali1aedec25590, link-type EN10MB (Ethernet), capture size 262144 bytes
10:56:36.282426 IP 10.244.81.137 > 10.244.42.136: ICMP echo request, id 7946, seq 52, length 64
10:56:36.282755 IP 10.244.42.136 > 10.244.81.137: ICMP echo reply, id 7946, seq 52, length 64
10:56:37.282571 IP 10.244.81.137 > 10.244.42.136: ICMP echo request, id 7946, seq 53, length 64
10:56:37.282842 IP 10.244.42.136 > 10.244.81.137: ICMP echo reply, id 7946, seq 53, length 64
10:56:38.282715 IP 10.244.81.137 > 10.244.42.136: ICMP echo request, id 7946, seq 54, length 64
10:56:38.283000 IP 10.244.42.136 > 10.244.81.137: ICMP echo reply, id 7946, seq 54, length 64
^C
6 packets captured
6 packets received by filter
0 packets dropped by kernel
#宿主机k8s-m2出口网卡抓包
[root@k8s-m2 ~]# tcpdump -i ens32 -p icmp -nn
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens32, link-type EN10MB (Ethernet), capture size 262144 bytes
10:56:20.166420 IP 192.168.2.141 > 14.119.104.254: ICMP echo request, id 1, seq 22952, length 64
10:56:20.199014 IP 14.119.104.254 > 192.168.2.141: ICMP echo reply, id 1, seq 22952, length 64
10:56:21.166566 IP 192.168.2.141 > 14.119.104.254: ICMP echo request, id 1, seq 22953, length 64
10:56:21.194721 IP 14.119.104.254 > 192.168.2.141: ICMP echo reply, id 1, seq 22953, length 64
10:56:22.166716 IP 192.168.2.141 > 14.119.104.254: ICMP echo request, id 1, seq 22954, length 64
10:56:22.194896 IP 14.119.104.254 > 192.168.2.141: ICMP echo reply, id 1, seq 22954, length 64
10:56:22.365897 IP 192.168.2.141 > 192.168.2.140: ICMP 192.168.2.141 protocol 112 unreachable, length 48
^C
7 packets captured
7 packets received by filter
0 packets dropped by kernel
通过以上抓包可以看到BGP模式下,不同节点上的pod服务器通信时流量通过 cali****直接到服务器物理网卡,不用进过tunl0 网卡进行转发。
以上两种模式,我们看到不管是容器也好还是主机也好都有一些奇怪的地方,从容器路由表可以知道 169.254.1.1 是容器的默认网关,MAC地址也是一个无效的MAC地址ee:ee:ee:ee:ee:ee 为什么会这这样呢,其实这些都是calico写死了的。Calico利用了网卡的proxy_arp功能,具体的,是将/proc/sys/net/ipv4/conf/cali1aedec25590/proxy_arp置为1。当设置这个标志之后,就开启了proxy_arp功能。主机就会看起来像一个网关,会响应所有的ARP请求,并将自己的MAC地址告诉客户端。
也就是说,当容器(POD)发送ARP请求时,cali1aedec25590网卡会告诉容器,我拥有169.254.1.1这个IP,我的MAC地址是XXX,这样当容器去访问外部服务时其实是访问的是cali1aedec25590。然后在由cali1aedec25590代替容器去访问外部服务然后把结果返回给容器这样就看起来网络就通了。
通过tcpdump抓包可以看到首先容器会发送一个arp广播问169.254.1.1的MAC地址是多少,告诉10.244.81.137 这IP。其实这个IP就是当前Pod自己的IP,也就是告诉自己。然后cali1aedec25590 响应这个ARP请求,并回复告诉容器我拥有这个IP的MAC,它的MAC地址是ee:ee:ee:ee:ee:ee。如果你想验证你可以使用ip link set dev cali03d85d58f77 address ee:ee:ee:ee:11:11修改cali1aedec25590 网卡的MAC地址,然后你在抓包看看效果。
[root@k8s-m2 ~]# tcpdump -i cali1aedec25590 -p arp -nn
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on cali1aedec25590, link-type EN10MB (Ethernet), capture size 262144 bytes
11:05:52.384358 ARP, Request who-has 10.244.81.137 tell 192.168.2.141, length 28
11:05:52.384351 ARP, Request who-has 169.254.1.1 tell 10.244.81.137, length 28
11:05:52.384375 ARP, Reply 169.254.1.1 is-at ee:ee:ee:ee:ee:ee, length 28
11:05:52.384383 ARP, Reply 10.244.81.137 is-at 1e:e6:26:3f:61:f2, length 28
修改mac地址
[root@k8s-m2 ~]# ip link set dev cali1aedec25590 address ee:ee:ee:ee:11:11
[root@k8s-m2 ~]# tcpdump -i cali1aedec25590 -p arp -nn
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on cali1aedec25590, link-type EN10MB (Ethernet), capture size 262144 bytes
11:09:42.432344 ARP, Request who-has 169.254.1.1 tell 10.244.81.137, length 28
11:09:43.434386 ARP, Request who-has 169.254.1.1 tell 10.244.81.137, length 28
11:09:44.436361 ARP, Request who-has 169.254.1.1 tell 10.244.81.137, length 28
11:09:46.421510 ARP, Request who-has 169.254.1.1 tell 10.244.81.137, length 28
11:09:46.421546 ARP, Reply 169.254.1.1 is-at ee:ee:ee:ee:11:11, length 28
11:09:51.424352 ARP, Request who-has 10.244.81.137 tell 192.168.2.141, length 28
11:09:51.424396 ARP, Reply 10.244.81.137 is-at 1e:e6:26:3f:61:f2, length 28
^C
7 packets captured
7 packets received by filter
0 packets dropped by kernel
[root@k8s-m2 ~]# kubectl exec -it liveness-exec-pod -- /bin/sh
/ # ip neigh
169.254.1.1 dev eth0 lladdr ee:ee:ee:ee:11:11 used 0/0/0 probes 4 STALE
192.168.2.141 dev eth0 lladdr ee:ee:ee:ee:11:11 used 0/0/0 probes 0 STALE
部署过程中注意的问题
NetworkManage配置
1)确保Calico可以在主机上进行管理cali和tunl接口,如果主机上存在NetworkManage,请配置NetworkManager。
NetworkManager会为默认网络名称空间中的接口操纵路由表,在该默认名称空间中,固定了Calico veth对以连接到容器,这可能会干扰Calico代理正确路由的能力。
在以下位置创建以下配置文件,以防止NetworkManager干扰接口:
vim /etc/NetworkManager/conf.d/calico.conf
[keyfile]
unmanaged-devices=interface-name:cali*;interface-name:tunl*
选择数据存储方式
Calico同时支持Kubernetes API数据存储(kdd)和etcd数据存储。建议在本地部署中使用Kubernetes API数据存储,它仅支持Kubernetes工作负载。etcd是混合部署的最佳数据存储。(注意:使用Kubernetes API数据存储安装Calico时calico超过50个节点)需要做如下设置。我在此次测试中使用的是kubernetes作为数据存储。
其他设定
然后更改 CALICO_IPV4POOL_IPIP 为 Never 使用 BGP 模式,另外增加 IP_AUTODETECTION_METHOD 为 interface 使用匹配模式,默认是first-found模式,在复杂网络环境下还是有出错的可能,还有CALICO_IPV4POOL_CIDR 设置为kubeadm初始化时设置的podSubnet参数。
# Cluster type to identify the deployment type
- name: CLUSTER_TYPE
value: "k8s,bgp"
# Auto-detect the BGP IP address.
- name: IP
value: "autodetect"
- name: IP_AUTODETECTION_METHOD
value: "interface=en.*"
# Enable IPIP
- name: CALICO_IPV4POOL_IPIP
value: "Never"
# no effect. This should fall within `--cluster-cidr`.
- name: CALICO_IPV4POOL_CIDR
value: "10.244.0.0/16"
calicoctl客户端
calicoctl安装
有时候,我们需要安装calicoctl客户端对服务进行检查或者修改相关配置。以下进行calicoctl客户端安装,本次测试使用的calico3.8版本
[root@k8s-m1 ~]# curl \-O \-L https://github.com/projectcalico/calicoctl/releases/download/v3.8.0/calicoctl
[root@k8s-m1 ~]# chmod +x calicoctl
[root@k8s-m1 ~]# mv calicoctl /usr/bin/
[root@k8s-m1 ~]# DATASTORE_TYPE=kubernetes KUBECONFIG=~/.kube/config calicoctl get nodes
NAME
k8s-m1
k8s-m2
k8s-m3
[root@k8s-m1 ~]# DATASTORE_TYPE=kubernetes KUBECONFIG=~/.kube/config calicoctl node status
Calico process is running.
IPv4 BGP status
+---------------+-------------------+-------+------------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+---------------+-------------------+-------+------------+-------------+
| 192.168.2.141 | node-to-node mesh | up | 2023-08-28 | Established |
| 192.168.2.142 | node-to-node mesh | up | 2023-08-28 | Established |
+---------------+-------------------+-------+------------+-------------+
IPv6 BGP status
No IPv6 peers found.
模式选择
- 全互联模式(node-to-node mesh)
全互联模式,每一个BGP Speaker都需要和其他BGP Speaker建立BGP连接,这样BGP连接总数就是N^2,如果数量过大会消耗大量连接。如果集群数量超过100台官方不建议使用此种模式。 - 路由反射模式Router Reflection(RR)
RR模式中会指定一个或多个BGP Speaker为RouterReflection,它与网络中其他Speaker建立连接,每个Speaker只要与Router Reflection建立BGP就可以获得全网的路由信息。在calico中可以通过Global Peer实现RR模式。
上面通过使用calicoctl命令查看calico当前使用模式为node-to-node mesh全互联模式(full mesh)会造成路由条目过大,无法在大规模集群中部署。所以在大规模集群中使用BGP RR(中心化)的方式交换路由,能够有效降低节点间的连接数。
BGP RR模式配置(使用node充当路由反射器)
在生产集群中建立使用两个路由反射器,这意味着即使我们取消一个路由反射器节点进行维护,也可以避免单点故障。
由于本次实验环境有限,我只选择了一个节点用作反射节点,并对该个节点执行以下操作:
[root@k8s-m1 ~]#DATASTORE_TYPE=kubernetes KUBECONFIG=~/.kube/config calicoctl get node k8s-m1 -o yaml --export > k8s-m1-node.yaml
##大致修改如下内容
[root@k8s-m1 ~]# vim k8s-m1-node.yaml
labels:
beta.kubernetes.io/arch: amd64
beta.kubernetes.io/os: linux
kubernetes.io/arch: amd64
kubernetes.io/hostname: k8s-m1
kubernetes.io/os: linux
node-role.kubernetes.io/master: ""
calico-route-reflector: ""
name: k8s-m1
spec:
bgp:
routeReflectorClusterID: 224.0.0.1
ipv4Address: 192.168.2.140/24
ipv4IPIPTunnelAddr: 10.244.42.128
~
重新应用YAML
[root@k8s-m1 ~]# DATASTORE_TYPE=kubernetes KUBECONFIG=~/.kube/config calicoctl apply -f k8s-m1-node.yaml
Successfully applied 1 'Node' resource(s)
配置 BGPPeer
将所有非反射器节点配置为与所有路由反射器对等
[root@k8s-m1 ~]# DATASTORE_TYPE=kubernetes KUBECONFIG=~/.kube/config calicoctl apply -f - <
kind: BGPPeer
apiVersion: projectcalico.org/v3
metadata:
name: peer-to-rrs
spec:
nodeSelector: "!has(calico-route-reflector)"
peerSelector: has(calico-route-reflector)
EOF
将所有路由反射器配置为彼此对等
[root@k8s-m1 ~]# DATASTORE_TYPE=kubernetes KUBECONFIG=~/.kube/config calicoctlapply -f - <
kind: BGPPeer
apiVersion: projectcalico.org/v3
metadata:
name: rrs-to-rrs
spec:
nodeSelector: has(calico-route-reflector)
peerSelector: has(calico-route-reflector)
EOF
[root@k8s-m1 ~]# DATASTORE_TYPE=kubernetes KUBECONFIG=~/.kube/config calicoctl get bgppeer
NAME PEERIP NODE ASN
peer-to-rrs !has(calico-route-reflector) 0
rrs-to-rrs has(calico-route-reflector) 0
禁用默认的node-to-node mesh模式
[root@k8s-m1 ~]# DATASTORE_TYPE=kubernetes KUBECONFIG=~/.kube/config calicoctl create -f - <
apiVersion: projectcalico.org/v3
kind: BGPConfiguration
metadata:
name: default
spec:
nodeToNodeMeshEnabled: false
asNumber: 64512
EOF
[root@k8s-m1 ~]# DATASTORE_TYPE=kubernetes KUBECONFIG=~/.kube/config calicoctl get bgpconfig -o wide
NAME LOGSEVERITY MESHENABLED ASNUMBER
default false 64512
此时在反射器节点上使用 calicoctl node status 应该能看到类似如下输出:
[root@k8s-m1 ~]# DATASTORE_TYPE=kubernetes KUBECONFIG=~/.kube/config calicoctl node status
Calico process is running.
IPv4 BGP status
+---------------+---------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+---------------+---------------+-------+----------+-------------+
| 192.168.2.141 | node specific | up | 02:09:17 | Established |
| 192.168.2.142 | node specific | up | 02:09:17 | Established |
+---------------+---------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.
在非反射器节点上,应该只看到上面我们设置的对等体。
[root@k8s-m2 ~]# DATASTORE_TYPE=kubernetes KUBECONFIG=~/.kube/config calicoctl node status
Calico process is running.
IPv4 BGP status
+---------------+---------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+---------------+---------------+-------+----------+-------------+
| 192.168.2.140 | node specific | up | 02:09:18 | Established |
+---------------+---------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.
Calico Overlay网络
在Calico Overlay网络中有两种模式可选(仅支持IPV4地址)
- IP-in-IP (使用BGP实现)
- Vxlan (不使用BGP实现)
解释如下:
Calico支持两种类型的封装:VXLAN和IP-in-IP。VXLAN在一些IP中的IP不支持的环境中得到支持(例如Azure)。VXLAN的每个数据包开销略高,因为报头更大,但除非您运行的是网络密集型工作负载,否则您通常不会注意到这种差异。这两种类型的封装之间的另一个小区别是Calico的VXLAN实现不使用BGP,而Calico的IP-in-IP实现在Calico节点之间使用BGP。(官网原文翻译)
两种模式均支持如下参数
- Always: 永远进行 IPIP 封装(默认)
- CrossSubnet: 只在跨网段时才进行 IPIP 封装,适合有 Kubernetes 节点在其他网段的情况,属于中肯友好方案
- Never: 从不进行 IPIP 封装,适合确认所有 Kubernetes 节点都在同一个网段下的情况(配置此参数就开启了BGP模式)
环境中具体使用参数可以通过kubectl get ippool -o yaml或者DATASTORE_TYPE=kubernetes KUBECONFIG=~/.kube/config calicoctl get ippool default-ipv4-ippool -o yaml查看
在默认情况下,默认的 ipPool 启用了 IPIP 封装(至少通过官方安装文档安装的 Calico 是这样),并且封装模式为 Always;这也就意味着任何时候都会在原报文上封装新 IP 地址,在这种情况下将外部流量如果路由到 RR 节点,RR 节点再转发进行 IPIP 封装时,可能出现网络无法联通的情况;此时我们可以尝试调整 IPIP 封装策略为 CrossSubnet
直接编辑ippool
[root@k8s-m1 ~]# kubectl edit ippool default-ipv4-ippool
或者使用calicolctl对ippool进行 配置
[root@k8s-m1 ~]# DATASTORE_TYPE=kubernetes KUBECONFIG=~/.kube/config calicoctl get ippool default-ipv4-ippool -o yaml > ippool.yaml
#修改 ipipMode 值为 CrossSubnet
apiVersion: projectcalico.org/v3
kind: IPPool
metadata:
creationTimestamp: 2023-08-04T06:39:45Z
name: default-ipv4-ippool
resourceVersion: "92505999"
uid: 2436d7f2-249d-492e-b1df-30cc438181e0
spec:
blockSize: 26
cidr: 10.244.0.0/16
ipipMode: CrossSubnet
natOutgoing: true
nodeSelector: all()
vxlanMode: Never
重新使用 DATASTORE_TYPE=kubernetes KUBECONFIG=~/.kube/config calicoctl apply -f ippool.yaml应用既可。
更多关于kubernetes的知识分享,请前往博客主页。编写过程中,难免出现差错,敬请指出