尚硅谷HBase
目录
一、HBase简介
1.1 HBase 定义
1.2 HBase 数据模型
1.2.1 HBase 逻辑结构
1.2.2 HBase 物理存储结构
1.2.3 数据模型
1.3 HBase 基本框架
二、HBase 快速入门
2.1 HBase Shell操作
2.1.1 基本操作
2.1.2 DDL
2.1.3 DML
三、HBase 进阶
3.1 架构原理
3.2 写流程
3.3 MemStore Flush
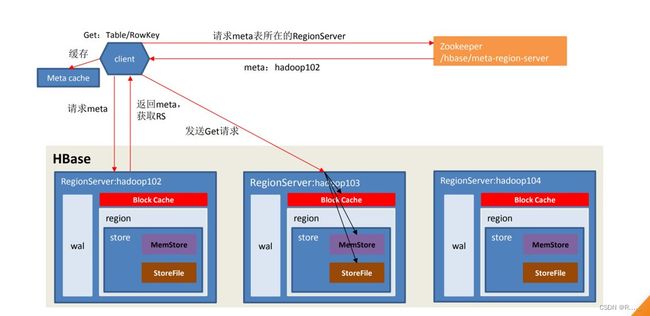
3.4 读流程
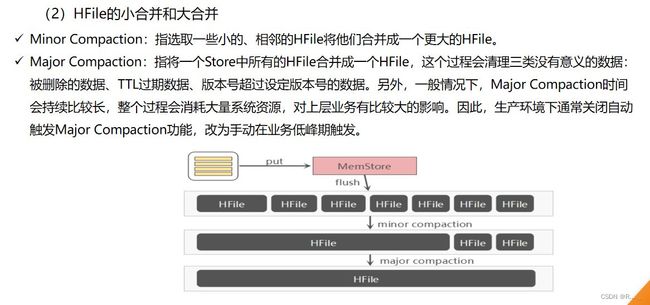
3.5 HBase的合并与拆分
3.5.1 StoreFile Compaction
3.5.2 Region Split
3.6 数据真正删除时间
四、HBase API
4.1 DDL
4.1.1 判断表是否存在
4.1.2 创建表
4.1.3 删除表
4.1.4 创建命名空间
4.2 DML
4.2.1 向表中插入数据
4.2.2 获取数据(get)
4.2.3 获取数据 (scan)
4.2.4 删除表中的数据
4.3.1 关闭资源
4.4.1 总的代码
一、HBase简介
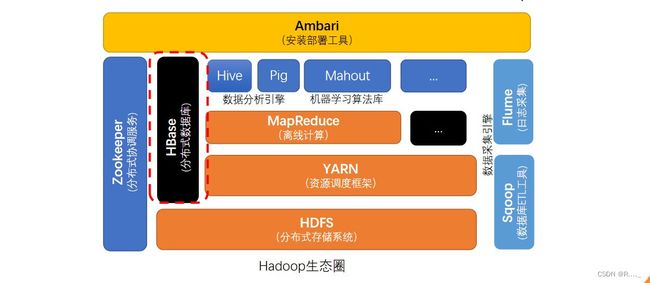
1.1 HBase 定义
HBase是一种分布式、可扩展、支持海量数据存储的NoSQL数据库。
1.2 HBase 数据模型
HBase 的设计理念依据 Google 的 BigTable 论文,论文中对于数据模型的首句介绍。
Bigtable 是一个稀疏的、分布式的、持久的多维排序 map。
对于映射的解释如下
该映射由行键、列键和时间戳索引;映射中的每个值都是一个未解释的字节数组。
最终 HBase 关于数据模型和 BigTable 的对应关系如下
HBase 使用与 Bigtable 非常相似的数据模型。用户将数据行存储在带标签的表中。数 据行具有可排序的键和任意数量的列。该表存储稀疏,因此如果用户喜欢,同一表中的行可 以具有疯狂变化的列。
最终理解 HBase 数据模型的关键在于稀疏、分布式、多维、排序的映射。其中映射 map 指代非关系型数据库的 key-Value 结构。
1.2.1 HBase 逻辑结构
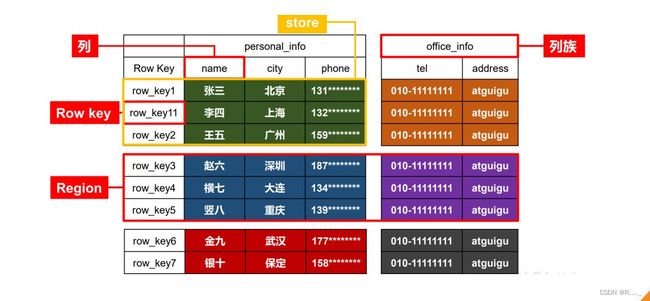
1.2.2 HBase 物理存储结构
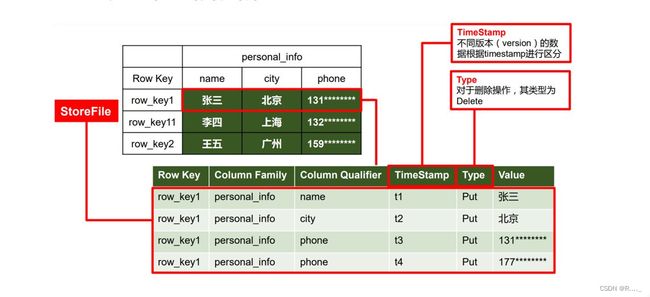
1.2.3 数据模型

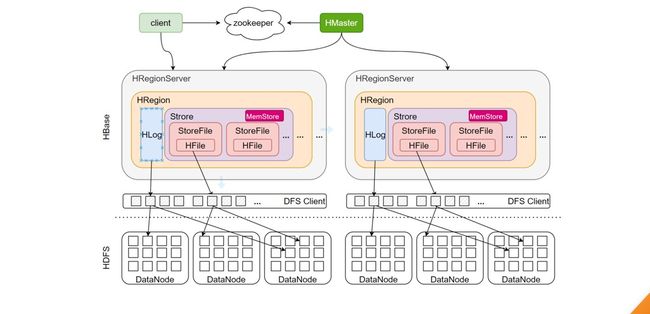
1.3 HBase 基本框架
Master
主要进程,具体实现类为HMaster,通常部署在namenode上。
功能:负责通过ZK监控RegionServer进程状态,同时是所有元数据变化 的接口。内部启动监控执行region的故障转移和拆分的线程。
RegionServer
主要进程,具体实现类为HRegionServer,部署在datanode上。 功能:主要负责数据cell的处理。同时在执行区域的拆分和合并的时候, 由RegionServer来实际执行。
二、HBase 快速入门
2.1 HBase Shell操作
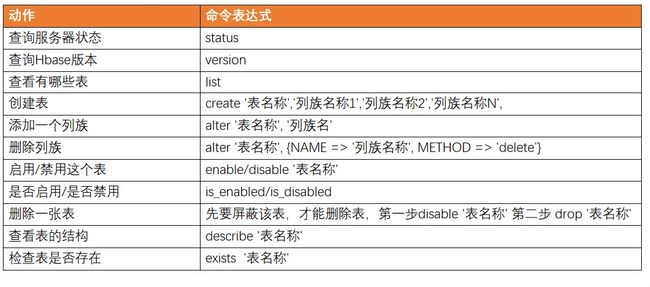
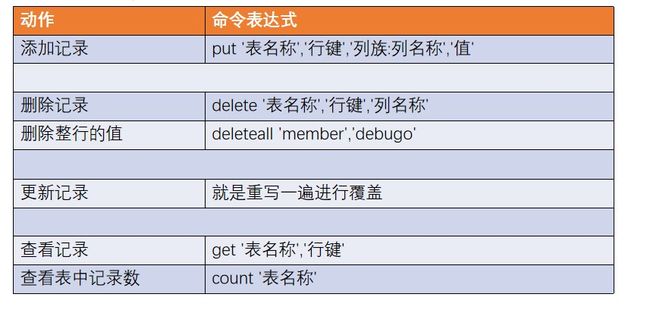
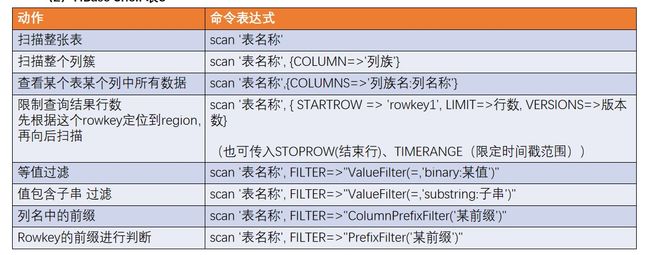
2.1.1 基本操作
1)进入Hbase客户端命令行

2)查看帮助命令

2.1.2 DDL
1)创建表
在 bigdata 命名空间中创建表格 student,两个列族。info 列族数据维护的版本数为 5 个, 如果不写默认版本数为 1。
hbase:005:0> create 'bigdata:student', {NAME => 'info', VERSIONS => 5}, {NAME => 'msg'}

如果创建表格只有一个列族,没有列族属性,可以简写。
如果不写命名空间,使用默认的命名空间 default。
hbase:006:0> create 'student1','info'
2)查看表
查看表有两个命令:list 和 describe
list:查看所有的表名
hbase:008:0> list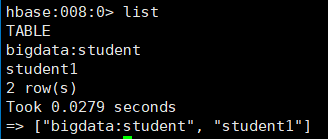
describe:查看一个表的详情
hbase:009:0> describe 'student1'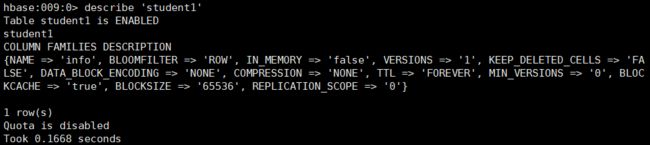
3)修改表
表名创建时写的所有和列族相关的信息,都可以后续通过 alter 修改,包括增加删除列 族。
(1)增加列族和修改信息都使用覆盖的方法
hbase:010:0> alter 'student1', {NAME => 'f1', VERSIONS => 3}
(2)删除信息使用特殊的语法
hbase:011:0> alter 'student1', NAME => 'f1', METHOD => 'delete'
hbase:012:0> alter 'student1', 'delete' => 'f1'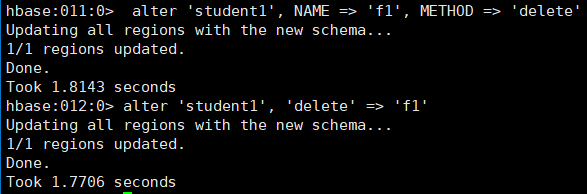
4)删除表
shell 中删除表格,需要先将表格状态设置为不可用
hbase:013:0> disable 'student1'
hbase:014:0> drop 'student1'
2.1.3 DML
1)写入数据
在 HBase 中如果想要写入数据,只能添加结构中最底层的 cell。可以手动写入时间戳指 定 cell 的版本,推荐不写默认使用当前的系统时间。
hbase:015:0> put 'bigdata:student','1001','info:name','zhangsan'
hbase:016:0> put 'bigdata:student','1001','info:name','lisi'
hbase:017:0> put 'bigdata:student','1001','info:age','18'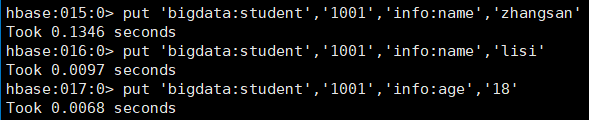
2)读取数据
读取数据的方法有两个:get 和 scan。
get 最大范围是一行数据,也可以进行列的过滤,读取数据的结果为多行 cell。
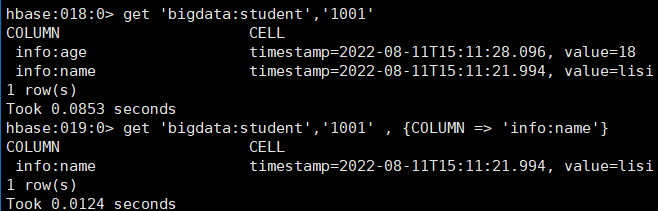
也可以修改读取 cell 的版本数,默认读取一个。最多能够读取当前列族设置的维护版本 数。

scan 是扫描数据,能够读取多行数据,不建议扫描过多的数据,推荐使用 startRow 和 stopRow 来控制读取的数据,默认范围左闭右开。

实际开发中使用 shell 的机会不多,所有丰富的使用方法到 API 中介绍
3)删除数据
删除数据的方法有两个:delete 和 deleteall。
delete 表示删除一个版本的数据,即为 1 个 cell,不填写版本默认删除最新的一个版本
hbase:023:0> delete 'bigdata:student','1001','info:name'
deleteall 表示删除所有版本的数据,即为当前行当前列的多个 cell。(执行命令会标记 数据为要删除,不会直接将数据彻底删除,删除数据只在特定时期清理磁盘时进行)
hbase:024:0> deleteall 'bigdata:student','1001','info:name'
三、HBase 进阶
3.1 架构原理

1)StoreFile
保存实际数据的物理文件,StoreFile以HFile的形式存储在HDFS上。每个Store会有一个或多个StoreFile,数据在每个StoreFile中都是有序的。
3.2 写流程

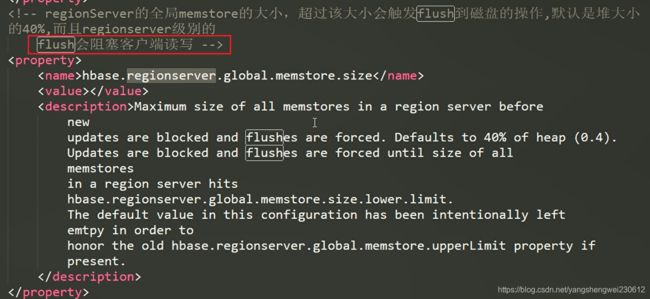
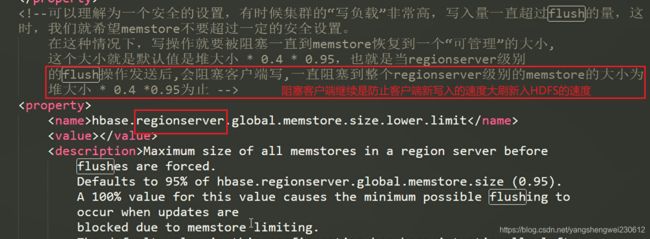
3.3 MemStore Flush

MemStore 刷写(flush)时机:


3.4 读流程

3.5 HBase的合并与拆分
3.5.1 StoreFile Compaction

3.5.2 Region Split
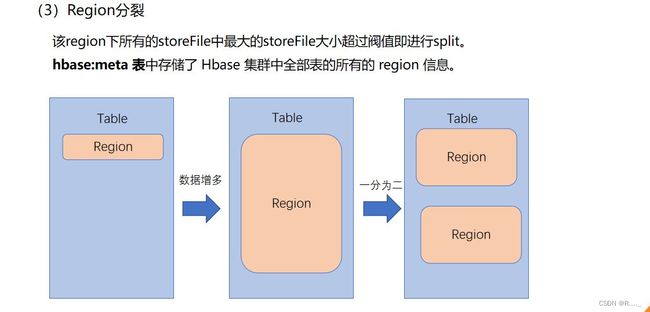
3.6 数据真正删除时间
1.Flash时也会删除数据put进两条数据,scan只显示一个时间戳大的,显示多版本才会出现两个这时flash表一下,显示多版本也只会显示一个时间戳大的。再put一条数据,刷写一下,显示多版本的时候会包括之前的那个Flash刷写时把同一个内存中的删除,刷写时只管内存空间,也就是刷写成功的写入磁盘的是不会删除的。
2.合并时会删除数据这时会把之前的旧版本都删除掉Major Compaction 会将一个 Store 下的所有的 HFile 合并成一个大 HFile,并且会清理掉过期和删除的数据。
总结:在Flash或者Major Compaction时会删除数据,Flash删除的时同一个内存的旧数据,不能删除跨越的多文件,Flash待删除的数据只能在同一个内存中。Major Compaction,将多个文件合并,在内存中都做过比较了。再put一条数据,把他删除掉,然后flash,显示多版本不会出现这个数据内容(在同一个内存flash会把他删除),但是会有这条数据的状态 type=deletecolumn。在合并的时候会删除掉这个状态。再合并时删除不在flash里删除是因为flash删除的只是在内存的数据。
例子:put 1 flash生成新文件put 2 flash生成新文件put 3 在内存时把他删掉,flash生成新文件,这里只要delete状态,如果这个时候删除掉delete状态flash新文件就会把put2的内容刷下来。所以在合并时在删除。其他数据会和删除标记就是那个状态比较不然会出现刷写到之前的文件数据。
四、HBase API
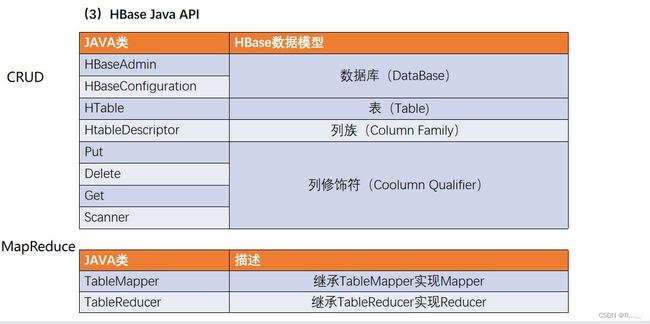

4.1 DDL
通用编写为静态代码块
private static Connection connection=null;
private static Admin admin=null;
static {
try {
//1.获取配置信息
//新的
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum","192.168.189.144,192.168.189.145,192.168.189.146");
//2.创建连接对象
connection=ConnectionFactory.createConnection(configuration);
//3.创建Admin对象
admin=connection.getAdmin();
} catch (IOException e) {
e.printStackTrace();
}
}
4.1.1 判断表是否存在
//1.判断表是否存在
public static boolean isTableExist(String tableName) throws IOException {
//1.获取配置文件信息
//过时的
//HBaseConfiguration configuration = new HBaseConfiguration();
//新的
// Configuration configuration = HBaseConfiguration.create();
// configuration.set("hbase.zookeeper.quorum","192.168.189.144,192.168.189.145,192.168.189.146");
//
// //2.获取管理员对象
// //过时的
// //HBaseAdmin hBaseAdmin = new HBaseAdmin(configuration);
//
// //新的
// Connection connection = ConnectionFactory.createConnection(configuration);
// Admin admin = connection.getAdmin();
//3.判断表是否存在
//boolean exists = admin.tableExists(tableName);
boolean exists = admin.tableExists(TableName.valueOf(tableName));
//4.关闭连接
//admin.close();
//5.返回结果
return exists;
}4.1.2 创建表
//2.创建表
public static void createTable(String tableName,String...cfs) throws IOException {
//1.判断是否存在列族信息
if(cfs.length<=0){
System.out.println("请设置列族信息!");
return;
}
//2.判断表是否存在
if(isTableExist(tableName)){
System.out.println(tableName+"表已经存在");
return;
}
//3.创建表描述器
HTableDescriptor hTableDescriptor = new HTableDescriptor(TableName.valueOf(tableName));
//4.循环添加列族信息
for(String cf:cfs){
//5.创建列族描述器
HColumnDescriptor hColumnDescriptor = new HColumnDescriptor(cf);
//6.添加具体的列族信息
hTableDescriptor.addFamily(hColumnDescriptor);
}
//7.创建表
admin.createTable(hTableDescriptor);
}
4.1.3 删除表
//3.删除表
public static void dropTable(String tableName) throws IOException {
//1.判断表是否存在
if(!isTableExist(tableName)){
System.out.println(tableName+"表不存在");
return;
}
//2.使表下线
admin.disableTable(TableName.valueOf(tableName));
//3.删除表
admin.deleteTable(TableName.valueOf(tableName));
}
4.1.4 创建命名空间
public static void createNameSpace(String ns){
//1.创建命名空间描述器
NamespaceDescriptor namespaceDescriptor = NamespaceDescriptor.create(ns).build();
//2.创建命名空间
try {
admin.createNamespace(namespaceDescriptor);
} catch (NamespaceExistException e) {
System.out.println(ns+"命名空间已存在");
}catch(IOException e){
e.printStackTrace();
}
System.out.println("我来了");
}4.2 DML
4.2.1 向表中插入数据
public static void putData(String tableName,String rowKey,String cf,String cn,String value) throws IOException {
//1.获取表对象
Table table = connection.getTable(TableName.valueOf(tableName));
//2.创建Put对象
Put put = new Put(Bytes.toBytes(rowKey));
//3.给Put对象赋值
put.addColumn(Bytes.toBytes(cf),Bytes.toBytes(cn),Bytes.toBytes(value));
put.addColumn(Bytes.toBytes(cf),Bytes.toBytes(cn),Bytes.toBytes(value));
put.addColumn(Bytes.toBytes(cf),Bytes.toBytes(cn),Bytes.toBytes(value));
put.addColumn(Bytes.toBytes(cf),Bytes.toBytes(cn),Bytes.toBytes(value));
//4.插入数据
table.put(put);
//5.关闭表连接
table.close();
}4.2.2 获取数据(get)
public static void getData(String tableName,String rowKey,String cf,String cn) throws IOException {
//1.获取表对象
Table table = connection.getTable(TableName.valueOf(tableName));
//2.创建Get对象
Get get = new Get(Bytes.toBytes(rowKey));
//2.1 指定获取的列族
get.addFamily(Bytes.toBytes(cf));
//2.2 指定获取的列族和列
get.addColumn(Bytes.toBytes(cf),Bytes.toBytes(cn));
//2.3 设置获取数据的版本数
get.setMaxVersions(5);
//3.获取数据
Result result = table.get(get);
//4.解析result并打印
for(Cell cell:result.rawCells()){
//5.打印数据
System.out.println("CF:"+Bytes.toString(CellUtil.cloneFamily(cell))+",CN:"+Bytes.toString(CellUtil.cloneQualifier(cell))+
",Value:"+Bytes.toString(CellUtil.cloneValue(cell)));
}
//6.关闭表连接
table.close();
}4.2.3 获取数据 (scan)
//7.获取数据 (scan)
public static void scanTable(String tableName) throws IOException {
//1.获取表对象
Table table = connection.getTable(TableName.valueOf(tableName));
//2.构建Scan对象
Scan scan = new Scan();
//3.扫描表
ResultScanner resultScanner = table.getScanner(scan);
//4.解析resultScanner
for(Result result:resultScanner){
//5.解析result并打印
for(Cell cell:result.rawCells()){
//6.打印数据
System.out.println("CF:"+Bytes.toString(CellUtil.cloneFamily(cell))+",CN:"+Bytes.toString(CellUtil.cloneQualifier(cell))+
",Value:"+Bytes.toString(CellUtil.cloneValue(cell)));
}
}
//7.关闭表连接
table.close();
}
4.2.4 删除表中的数据
//8.删除数据
public static void deleteData(String tableName,String rowKey,String cf,String cn) throws IOException {
//1.获取表对象
Table table = connection.getTable(TableName.valueOf(tableName));
//2.构建删除对象
Delete delete = new Delete(Bytes.toBytes(rowKey));
//2.1设置删除的列
delete.addColumns(Bytes.toBytes(cf),Bytes.toBytes(cn));
//3.执行删除操作
table.delete(delete);
//4.关闭表连接
table.close();
}4.3.1 关闭资源
//关闭资源
public static void close(){
if(admin!=null){
try {
admin.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(connection!=null){
try {
connection.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}4.4.1 总的代码
package com.git.test;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import sun.net.spi.nameservice.NameServiceDescriptor;
import java.io.IOException;
/*
* DDL
* 1.判断表是否存在
* 2.创建表
* 3.创建命名空间
* 4.删除表
*
*
*
* DML
* 5.插入数据
* 6.查数据(get)
* 7.查数据(scan)
* 8.删除数据
* */
public class TestAPI {
public static void main(String[] args) throws IOException {
//1.测试表是否存在
//System.out.println(isTableExist("stu1"));//true
//2.创建表测试
//createTable("0408:stu1","info1","info2");
//3.删除表测试
//dropTable("stu1");
//4.创建命名空间测试
//createNameSpace("0408");
//5.插入数据测试
//putData("stu","1001","info2","name","rqz");
//6.获取单行数据测试
//getData("stu","1002","info1","name");
//7.获取获取扫描数据测试
//scanTable("stu");
//8.删除表中的数据测试
deleteData("stu","1006","info1","name");
//3.
//System.out.println(isTableExist("stu1"));
//统一关闭资源
close();
}
private static Connection connection=null;
private static Admin admin=null;
static {
try {
//1.获取配置信息
//新的
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum","192.168.189.144,192.168.189.145,192.168.189.146");
//2.创建连接对象
connection=ConnectionFactory.createConnection(configuration);
//3.创建Admin对象
admin=connection.getAdmin();
} catch (IOException e) {
e.printStackTrace();
}
}
//1.判断表是否存在
public static boolean isTableExist(String tableName) throws IOException {
//1.获取配置文件信息
//过时的
//HBaseConfiguration configuration = new HBaseConfiguration();
//新的
// Configuration configuration = HBaseConfiguration.create();
// configuration.set("hbase.zookeeper.quorum","192.168.189.144,192.168.189.145,192.168.189.146");
//
// //2.获取管理员对象
// //过时的
// //HBaseAdmin hBaseAdmin = new HBaseAdmin(configuration);
//
// //新的
// Connection connection = ConnectionFactory.createConnection(configuration);
// Admin admin = connection.getAdmin();
//3.判断表是否存在
//boolean exists = admin.tableExists(tableName);
boolean exists = admin.tableExists(TableName.valueOf(tableName));
//4.关闭连接
//admin.close();
//5.返回结果
return exists;
}
//2.创建表
public static void createTable(String tableName,String...cfs) throws IOException {
//1.判断是否存在列族信息
if(cfs.length<=0){
System.out.println("请设置列族信息!");
return;
}
//2.判断表是否存在
if(isTableExist(tableName)){
System.out.println(tableName+"表已经存在");
return;
}
//3.创建表描述器
HTableDescriptor hTableDescriptor = new HTableDescriptor(TableName.valueOf(tableName));
//4.循环添加列族信息
for(String cf:cfs){
//5.创建列族描述器
HColumnDescriptor hColumnDescriptor = new HColumnDescriptor(cf);
//6.添加具体的列族信息
hTableDescriptor.addFamily(hColumnDescriptor);
}
//7.创建表
admin.createTable(hTableDescriptor);
}
//3.删除表
public static void dropTable(String tableName) throws IOException {
//1.判断表是否存在
if(!isTableExist(tableName)){
System.out.println(tableName+"表不存在");
return;
}
//2.使表下线
admin.disableTable(TableName.valueOf(tableName));
//3.删除表
admin.deleteTable(TableName.valueOf(tableName));
}
//4.创建命名空间
public static void createNameSpace(String ns){
//1.创建命名空间描述器
NamespaceDescriptor namespaceDescriptor = NamespaceDescriptor.create(ns).build();
//2.创建命名空间
try {
admin.createNamespace(namespaceDescriptor);
} catch (NamespaceExistException e) {
System.out.println(ns+"命名空间已存在");
}catch(IOException e){
e.printStackTrace();
}
System.out.println("我来了");
}
//5.向表中插入数据
public static void putData(String tableName,String rowKey,String cf,String cn,String value) throws IOException {
//1.获取表对象
Table table = connection.getTable(TableName.valueOf(tableName));
//2.创建Put对象
Put put = new Put(Bytes.toBytes(rowKey));
//3.给Put对象赋值
put.addColumn(Bytes.toBytes(cf),Bytes.toBytes(cn),Bytes.toBytes(value));
put.addColumn(Bytes.toBytes(cf),Bytes.toBytes(cn),Bytes.toBytes(value));
put.addColumn(Bytes.toBytes(cf),Bytes.toBytes(cn),Bytes.toBytes(value));
put.addColumn(Bytes.toBytes(cf),Bytes.toBytes(cn),Bytes.toBytes(value));
//4.插入数据
table.put(put);
//5.关闭表连接
table.close();
}
//6.获取数据(get)
public static void getData(String tableName,String rowKey,String cf,String cn) throws IOException {
//1.获取表对象
Table table = connection.getTable(TableName.valueOf(tableName));
//2.创建Get对象
Get get = new Get(Bytes.toBytes(rowKey));
//2.1 指定获取的列族
get.addFamily(Bytes.toBytes(cf));
//2.2 指定获取的列族和列
get.addColumn(Bytes.toBytes(cf),Bytes.toBytes(cn));
//2.3 设置获取数据的版本数
get.setMaxVersions(5);
//3.获取数据
Result result = table.get(get);
//4.解析result并打印
for(Cell cell:result.rawCells()){
//5.打印数据
System.out.println("CF:"+Bytes.toString(CellUtil.cloneFamily(cell))+",CN:"+Bytes.toString(CellUtil.cloneQualifier(cell))+
",Value:"+Bytes.toString(CellUtil.cloneValue(cell)));
}
//6.关闭表连接
table.close();
}
//7.获取数据 (scan)
public static void scanTable(String tableName) throws IOException {
//1.获取表对象
Table table = connection.getTable(TableName.valueOf(tableName));
//2.构建Scan对象
Scan scan = new Scan();
//3.扫描表
ResultScanner resultScanner = table.getScanner(scan);
//4.解析resultScanner
for(Result result:resultScanner){
//5.解析result并打印
for(Cell cell:result.rawCells()){
//6.打印数据
System.out.println("CF:"+Bytes.toString(CellUtil.cloneFamily(cell))+",CN:"+Bytes.toString(CellUtil.cloneQualifier(cell))+
",Value:"+Bytes.toString(CellUtil.cloneValue(cell)));
}
}
//7.关闭表连接
table.close();
}
//8.删除数据
public static void deleteData(String tableName,String rowKey,String cf,String cn) throws IOException {
//1.获取表对象
Table table = connection.getTable(TableName.valueOf(tableName));
//2.构建删除对象
Delete delete = new Delete(Bytes.toBytes(rowKey));
//2.1设置删除的列
delete.addColumns(Bytes.toBytes(cf),Bytes.toBytes(cn));
//3.执行删除操作
table.delete(delete);
//4.关闭表连接
table.close();
}
//关闭资源
public static void close(){
if(admin!=null){
try {
admin.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(connection!=null){
try {
connection.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}