C++的基类和派生类构造函数
基类的成员函数可以被继承,可以通过派生类的对象访问,但这仅仅指的是普通的成员函数,类的构造函数不能被继承。构造函数不能被继承是有道理的,因为即使继承了,它的名字和派生类的名字也不一样,不能成为派生类的构造函数,当然更不能成为普通的成员函数。
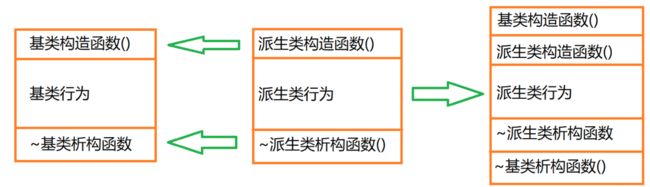
在设计派生类时,对继承过来的成员变量的初始化工作也要由派生类的构造函数完成,但是大部分基类都有 private 属性的成员变量,它们在派生类中无法访问,更不能使用派生类的构造函数来初始化。
这种矛盾在C++继承中是普遍存在的,解决这个问题的思路是:在派生类的构造函数中调用基类的构造函数。
下面的例子展示了如何在派生类的构造函数中调用基类的构造函数:
#include
using namespace std;
//基类People
class People{
protected:
char *m_name;
int m_age;
public:
People(char*, int);
};
People::People(char *name, int age): m_name(name), m_age(age){}
//派生类Student
class Student: public People{
private:
float m_score;
public:
Student(char *name, int age, float score);
void display();
};
//People(name, age)就是调用基类的构造函数
Student::Student(char *name, int age, float score): People(name, age), m_score(score){ }
void Student::display(){
cout< 运行结果为:小明的年龄是16,成绩是90.5。
请注意第 23 行代码:

Student::Student(char *name, int age, float score): People(name, age), m_score(score){ }People(name, age)就是调用基类的构造函数,并将 name 和 age 作为实参传递给它,m_score(score)是派生类的参数初始化表,它们之间以逗号,隔开。也可以将基类构造函数的调用放在参数初始化表后面:
Student::Student(char *name, int age, float score): m_score(score), People(name, age){ }但是不管它们的顺序如何,派生类构造函数总是先调用基类构造函数再执行其他代码(包括参数初始化表以及函数体中的代码),总体上看和下面的形式类似:
Student::Student(char *name, int age, float score){
People(name, age);
m_score = score;
}当然这段代码只是为了方便大家理解,实际上这样写是错误的,因为基类构造函数不会被继承,不能当做普通的成员函数来调用。换句话说,只能将基类构造函数的调用放在函数头部,不能放在函数体中。另外,函数头部是对基类构造函数的调用,而不是声明,所以括号里的参数是实参,它们不但可以是派生类构造函数参数列表中的参数,还可以是局部变量、常量等,例如
Student::Student(char *name, int age, float score): People("小明", 16), m_score(score){ }构造函数的调用顺序
从上面的分析中可以看出,基类构造函数总是被优先调用,这说明创建派生类对象时,会先调用基类构造函数,再调用派生类构造函数,如果继承关系有好几层的话,例如:
A --> B --> C
那么创建 C 类对象时构造函数的执行顺序为:
A类构造函数 --> B类构造函数 --> C类构造函数
构造函数的调用顺序是按照继承的层次自顶向下、从基类再到派生类的。还有一点要注意,派生类构造函数中只能调用直接基类的构造函数,不能调用间接基类的。
以上面的 A、B、C 类为例,C 是最终的派生类,B 就是 C 的直接基类,A 就是 C 的间接基类。
C++ 这样规定是有道理的,因为我们在 C 中调用了 B 的构造函数,B 又调用了 A 的构造函数,相当于 C 间接地(或者说隐式地)调用了 A 的构造函数,如果再在 C 中显式地调用 A 的构造函数,那么 A 的构造函数就被调用了两次,相应地,初始化工作也做了两次,这不仅是多余的,还会浪费CPU时间以及内存,毫无益处,所以 C++ 禁止在 C 中显式地调用 A 的构造函数。
基类构造函数调用规则
事实上,通过派生类创建对象时必须要调用基类的构造函数,这是语法规定。换句话说,定义派生类构造函数时最好指明基类构造函数;如果不指明,就调用基类的默认构造函数(不带参数的构造函数);如果没有默认构造函数,那么编译失败。请看下面的例子:
#include
using namespace std;
//基类People
class People{
public:
People(); //基类默认构造函数
People(char *name, int age);
protected:
char *m_name;
int m_age;
};
People::People(): m_name("xxx"), m_age(0){ }
People::People(char *name, int age): m_name(name), m_age(age){}
//派生类Student
class Student: public People{
public:
Student();
Student(char*, int, float);
public:
void display();
private:
float m_score;
};
Student::Student(): m_score(0.0){ } //派生类默认构造函数
Student::Student(char *name, int age, float score): People(name, age), m_score(score){ }
void Student::display(){
cout< 运行结果:xxx的年龄是0,成绩是0。
小明的年龄是16,成绩是90.5。
创建对象 stu1 时,执行派生类的构造函数Student::Student(),它并没有指明要调用基类的哪一个构造函数,从运行结果可以很明显地看出来,系统默认调用了不带参数的构造函数,也就是People::People()。
创建对象 stu2 时,执行派生类的构造函数Student::Student(char *name, int age, float score),它指明了基类的构造函数。
在第 27 行代码中,如果将People(name, age)去掉,也会调用默认构造函数,第 37 行的输出结果将变为:xxx的年龄是0,成绩是90.5。
如果将基类 People 中不带参数的构造函数删除,那么会发生编译错误,因为创建对象 stu1 时需要调用 People 类的默认构造函数, 而 People 类中已经显式定义了构造函数,编译器不会再生成默认的构造函数。