13.107.最全的Hive 优化方案汇总:临时参数的作用域、切分大文件、合并小文件、设置 Map 和 Reduce 的内存大小、设置 Map 和 Reduce 的堆大小设置 等
13.107.最全的Hive 优化方案汇总:
1.1.8. 临时参数的作用域:
1.1.10.切分大文件
1.1.11.合并小文件
1.1.12.设置 Map 和 Reduce 的内存大小
1.1.13.设置 Map 和 Reduce 的堆大小设置
1.1.14.开启Combiner功能:在map端预聚合
1.1.15.拓扑图,优化并行执行
1.1.16. 万能方法1:一个MR,拆成多个(即纵向拆分),为了降低数据倾斜的压力。【比较少用】
1.1.17.万能方法2:case when 行转列
1.1.18.万能方法3:key变换,使得key均匀分布
1.1.19.指定大小表
1.1.20.Join 优化:【on优化、大表优化、小表优化、】
1.1.21.Group By 优化:multi-insert & multi group by:从一份基础表中按照不同的维度,一次组合出不同的数据
1.1.22. JVM重用(适用于有大量小文件的场景,避免频繁的开启和关闭JVM消耗大量资源)
1.1.23. 笛卡尔积:避免误漏on条件,Hive只能使用1个reducer来完成笛卡尔积。
1.1.24.Union all:减少MR的数量
13.107.最全的Hive 优化方案汇总:
1.1.8. 临时参数的作用域:
1)临时参数,执行SQL session 级别的临时。
执行SQL之前设定的参数,在当前会话中,之后的SQL也会使用这些参数。
关闭hive之后再重启失效。
1.1.9.设定 Map 和 Reduce 的数量
set mapred.map.tasks=200;
set mapred.reduce.tasks=100;
1.1.10.切分大文件
set mapreduce.map.memory.mb=1024;
set mapred.max.split.size=52428800;
set mapred.min.split.size.per.node=52428800; # 一个节点上split的至少的大小 ,决定了多个data node上的文件是否需要合并
set mapred.min.split.size.per.rack=52428800; # 一个交换机下split的至少的大小,决定了多个交换机上的文件是否需要合并
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; #这个参数表示执行前进行小文件合并
1.1.11.合并小文件
set hive.merge.mapfiles = true; # 在Map-only的任务结束时合并小文件,是否和并 Map 输出文件,默认为 True
set hive.merge.mapredfiles = true; # 在Map-Reduce的任务结束时合并小文件,是否合并 Reduce 输出文件,默认为 False
set hive.merge.size.per.task = 256*1024*1024; # 合并文件的大小
set hive.merge.smallfiles.avgsize=83886080; # 当输出文件的平均大小小于该值时,启动一个独立的map-reduce任务进行文件merge
1.1.12.设置 Map 和 Reduce 的内存大小
set mapreduce.map.memory.mb=3072; # map 任务内存总大小
set mapreduce.reduce.memory.mb=3072; # reduce 任务内存总大小
1.1.13.设置 Map 和 Reduce 的堆大小设置
set mapreduce.map.java.opts=-Xmx1024m; # map 堆大小
set mapreduce.reduce.java.opts=-Xmx1024m; # reduce 堆大小
1.1.14.开启Combiner功能:在map端预聚合
能大幅减少数据量,减少磁盘的IO,节省带宽。
- (1) 临时参数
set hive.map.aggr=true;
或(未测试)
set mapreduce.combiner.run.only.once=true;
- (2) 配置文件:
<property>
<name>mapreduce.combiner.run.only.oncename>
<value>truevalue>
property>
- (3) 详细说明:
对于Group操作,首先在map端聚合,最后在reduce端做聚合,hive默认是这样的,以下是相关的参数
hive.map.aggr = true是否在 Map 端进行聚合,默认为 True
hive.groupby.mapaggr.checkinterval = 100000在 Map 端进行聚合操作的条目数目
hive.map.aggr.hash.min.reduction=0.5(默认),预先取100000条数据聚合,如果聚合后的条数/100000>0.5,则不再聚合
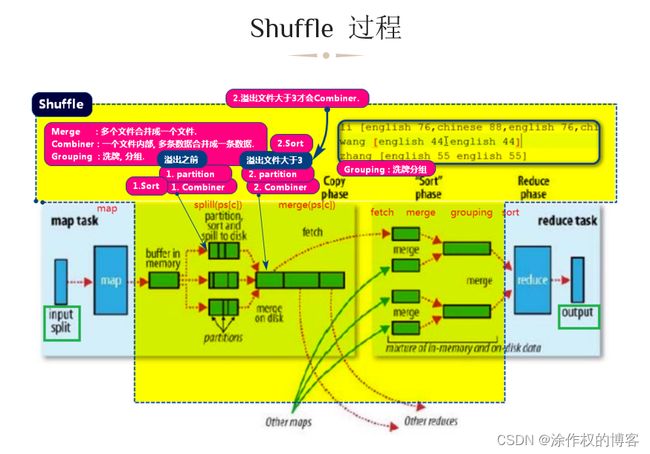
1.1.15.拓扑图,优化并行执行
set hive.exec.parallel=true;
遍历拓扑图,看哪些节点不依赖别的节点,可以直接跑起来。
1.1.16. 万能方法1:一个MR,拆成多个(即纵向拆分),为了降低数据倾斜的压力。【比较少用】
- (1) 参数:
set hive.groupby.skewindata=true;
(2) Multi-Count Distinct:一个MR,拆成多个的目的是为了降低数据倾斜的压力
– 必须设置参数:
set hive.groupby.skewindata=true;
select dt, count(distinct uniq_id), count(distinct ip)
from ods_log where dt=20170301 group by dt
(3) Bug:
- 其中,该设置下会出现的错误的是:
select a,count(*),count(distinct...) from ... group by a
- 解决方案,需要将语句修改为:
select a,sum(1),count(distinct …) from … group by a
(4) 哪些操作有效:
• Join
• Group by
• Count Distinct
(5) 出现数据倾斜的原因:
• key分布不均导致的
• 人为的建表疏忽
• 业务数据特点
(6) 症状:
• 任务进度长时间维持在99%(或100%),查看任务监控页面,发现只有少量(1个或几个)reduce子任务未完成。
• 查看未完成的子任务,可以看到本地读写数据量积累非常大,通常超过10GB可以认定为发生数据倾斜。
(7) 倾斜度:
• 平均记录数超过50w且最大记录数是超过平均记录数的4倍。
• 最长时长比平均时长超过4分钟,且最大时长超过平均时长的2倍。
(8) 不同语句在是否进行该设置下的执行对比:
使用hive的过程中,我们习惯性用set hive.groupby.skewindata=true来避免因数据倾斜造成的计算效率问题,
但是每个设置都是把双刃剑,最近调研了下相关问题,现总结如下:
从下表可以看出,skewindata配置真正发生作用,只会在以下三种情况下,能够将1个job转化为2个job:
• select count distinct … from …
• select a,count() from … group by a
• select count(),count(distinct …) from
不同语句在是否进行该设置下的执行对比
±----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| 语句 | job数 | Set hive.groupby.skewindata=true | job数 | Set hive.groupby.skewindata=false |
±----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| | | Groupby mode | | Groupby mode |
±----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| count | 1 | final | 1 | mergepartitial |
| count distinct | 2 | partitials+final | 1 | mergepartitial |
| count * … group by | 2 | partitials+final | 1 | mergepartitial |
| count distinct … group by | 1 | complete | 1 | mergepartitial |
| count *,count distinct | 2 | partitials+final | 1 | mergepartitial |
| count *,count distinct … group by | 1 | complete | 1 | mergepartitial |
| sum(1),count distinct … group by | 1 | complete | 1 | mergepartitial |
±----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1.1.17.万能方法2:case when 行转列
insert overwrite table POPULATION_INFO
select
cardid as idcard_no,
max(case when fields ='name' and value is not null then value else null end) as name,
max(case when fields ='gender' and value is not null then cast(value as int) else null end) as gender,
max(case when fields ='politics_status' and value is not null then cast(value as int) else null end) as politics_status,
max(case when fields ='nation' and value is not null then value else null end) as nation,
max(case when fields ='birtyday' and value is not null then value else null end) as birtyday,
max(case when fields ='age' and value is not null then cast(value as int) else null end) as age,
max(case when fields ='floating_population' and value is not null then cast(value as int) else null end) as floating_population,
max(case when fields ='faith' and value is not null then cast(value as int) else null end) as faith,
max(case when fields ='spiritpatient' and value is not null then cast(value as int) else null end) as spiritpatient,
max(case when fields ='withdisability' and value is not null then cast(value as int) else null end) as withdisability,
max(case when fields ='alcoholism' and value is not null then cast(value as int) else null end) as alcoholism,
max(case when fields ='gamble' and value is not null then cast(value as int) else null end) as gamble,
max(case when fields ='emergency' and value is not null then cast(value as int) else null end) as emergency,
max(case when fields ='income_source' and value is not null then cast(value as int) else null end) as income_source,
max(case when fields ='group_events' and value is not null then cast(value as int) else null end) as group_events
from temp_POPULATION_INFO_all_tags group by cardid;
1.1.18.万能方法3:key变换,使得key均匀分布
- 场景:很多userID为空或者为0,导致大量的倾斜。
- 解决方法:把空值或者Key变成一个字符串,加上随机数,把倾斜的数据分到不同的Reduce上,由于null值关联不上,处理后并不影响最终结果。
- on case when (x.uid = ‘-’ or x.uid = '0‘ or x.uid is null) then concat(‘dp_hive_search’,rand()) else x.uid end = f.user_id;
1.1.19.指定大小表
(1) 大小表关联:
*指定大表为流数据:/*+ streamtable(tablelist) /
而在reduce阶段的join,hive默认把左表数据放在缓存中,右边表的数据做流数据。
如果你想更改这种模式的话,就用/+streamtable(表名)/来指定你想要做为流数据的表。
*指定小表读入到内存:/*+ MAPJOIN(tablelist) /
顾名思义 MapJoin是在Map端完成Join操作,需要将Join操作中的小表读入到内存,在Map阶段拿另外一个表一个表的数据和内存中表数据做匹配,
这种情况下即使笛卡尔积也不会对任务运行速度造成太大的效率影响。
(2) 大大表关联:没有好的方法。只能通过业务逻辑去削减数据量。
- 2、场景1:业务削减。
- 案例
Select * from dw_log t join dw_user t1 on t.user_id=t1.user_id;
现象:两个表都上千万,跑起来很悬
-
思路
当天登陆的用户其实很少 -
方法
Select/*+MAPJOIN(t12)*/ *
from
dw_log t11
join (
select/*+MAPJOIN(t)*/ t1.*
from (
--选取当天登录的用户(数据量比较少)。
select user_id
from dw_log
group by user_id
) t
join dw_user t1 on t.user_id=t1.user_id
) t12
on t11.user_id=t12.user_id;
1.1.20.Join 优化:【on优化、大表优化、小表优化、】
- (1) 多表连接:如果join中多个表的join key是同一个,则join会转化为单个mr任务(很常用)
一个MR job
select a.val, b.val, c.val
from a
join b on (a.key = b.key1)
join c on (a.key = c.key1)
生成多个MR job
select a.val, b.val, c.val
from a
join b on (a.key = b.key1)
join c on (c.key = b.key1)
- (2) 指定表是小表,内存处理
指定表是小表,内存处理
SELECT /*+ MAPJOIN(tablelist) */ a.val, b.val, c.val
FROM a
JOIN b ON (a.key = b.key1)
JOIN c ON (c.key = b.key1);
- (3) 指定大表:/*+ streamtable(tablelist) */
select /*+ streamtable(a) */ a.val, b.val, c.val
from a
join b on (a.key = b.key1)
join c on (c.key = b.key1);
a表被视为大表
-
(4) Hive默认把左表数据放到缓存中,右边的表的数据做流数据
-
(5) 如果避免Join过程中出现大量结果,尽可能在on中完成所有条件判断
-
使用左连接或右连接:
左连接时,左表中出现的join字段都保留,右表没有连接上的都为空。 -
Join的结果出来之前先过滤:
执行顺序是,首先完成2表join,然后再通过where条件进行过滤,这样在join过程中可能会输出大量结果,
再对这些结果进行过滤,比较耗时。可以进行优化,将where条件放在on后,在join的过程中,
就对不满足条件的记录进行了预先过滤。 -
案例:
select a.val, b.val
from
a
left outer join b on (a.key=b.key)
where a.ds='2009-07-07' and b.ds='2009-07-07'
select a.val, b.val
from
a
left outer join b
on (a.key=b.key and b.ds='2009-07-07' and a.ds='2009-07-07')
1.1.21.Group By 优化:multi-insert & multi group by:从一份基础表中按照不同的维度,一次组合出不同的数据
-
即group by a, b, c
-
配置:
使用multi group by 之前必须配置参数:
<property>
<name>hive.multigroupby.singlemrname>
<value>truevalue>
property>
或:
hive.multigroupby.singlemar=true:当多个GROUP BY语句有相同的分组列,则会优化为一个MR任务。
- 概念说明:
从一份基础表中按照不同的维度,一次组合出不同的数据,减少Mapresuce的数量【将多个任务合并成1个任务】。
from from_statement
insert overwrite table tablename1 [partition (partcol1=val1)] select_statement1 group by key1
insert overwrite table tablename2 [partition(partcol2=val2 )] select_statement2 group by key2
- 案例:
multi group by 可以将查询中的多个group by操作组装到一个MapReduce任务中,起到优化作用
select Provice,city,county,count(rainfall) from area where data="2018-09-02" group by provice,city,count
select Provice,count(rainfall) from area where data="2018-09-02" group by provice
使用multi group by
from area
insert overwrite table temp1
select
Provice, city, county, count(rainfall)
from area
where data="2018-09-02"
group by provice,city,count
insert overwrite table temp2
select
Provice, count(rainfall)
from area
where data="2018-09-02"
group by provice
1.1.22. JVM重用(适用于有大量小文件的场景,避免频繁的开启和关闭JVM消耗大量资源)
-
(1) 方式1:JVM重用【mapred-site.xml】:(临时参数不生效,只能通过修改配置文件生效。)(默认是1)
将mapred.job.reuse.jvm.num.tasks设置成大于1的数,最多一个JVM能顺序执行多少个task。
这表示属于同一job的顺序执行的task可以共享一个JVM,也就是说第二轮的map可以重用前一轮的JVM,而不是第一轮结束后关闭JVM,第二轮再启动新的JVM。
mapred.job.reuse.jvm.num.tasks。如果设置成-1,那么只要是同一个job的task(无所谓多少个),都可以按顺序在一个JVM上连续执行。
如果task属于不同的job,那么JVM重用机制无效,不同job的task需要不同的JVM来运行。注意:
JVM重用技术不是指同一Job的两个或两个以上的task可以同时运行于同一JVM上,而是排队按顺序执行。
一个tasktracker最多可以同时运行的task数目由 mapred.tasktracker.map.tasks.maximum 和 mapred.tasktracker.reduce.tasks.maximum
决定,并且这两个参数在mapred-site.xml中设置。
其他方法,如在JobClient端通过命令行
-Dmapred.tasktracker.map.tasks.maximum=number或者conf.set(“mapred.tasktracker.map.tasks.maximum”,“number”)设置都是无效的。
说明:
1.在hive 可以动态设置该参数 set mapred.job.reuse.jvm.num.tasks=20 本参数好像yarn 失效,不支持重用 -
(2)方式2: JVM重用【yarn-site.xml】:Yarn的JVM重用功能——uber
用户可以通过启用uber组件来允许JVM重用——即在同一个container里面依次执行多个task。在yarn-site.xml文件中,改变一下几个参数的配置即可启用uber的方法:
参数| 默认值 | 描述-
mapreduce.job.ubertask.enable | (false) |
是否启用uber功能。如果启用了该功能,
则会将一个“小的application”的所有子task在同一个JVM里面执行,
达到JVM重用的目的。这个JVM便是负责该application的ApplicationMaster
所用的JVM(运行在其container里)。那具体什么样的application算是“小的application"呢?
下面几个参数便是用来定义何谓一个“小的application" -
mapreduce.job.ubertask.maxmaps | 9 |
map任务数的阀值,如果一个application包含的map数小于该值的定义,
那么该application就会被认为是一个小的application -
mapreduce.job.ubertask.maxreduces | 1 |
reduce任务数的阀值,如果一个application包含的reduce数小于该值的定义,
那么该application就会被认为是一个小的application。不过目前Yarn不支持该值大于1的情况
“CURRENTLY THE CODE CANNOT SUPPORT MORE THAN ONE REDUCE” -
mapreduce.job.ubertask.maxbytes | |
application的输入大小的阀值。默认为dfs.block.size的值。
当实际的输入大小不超过该值的设定,便会认为该application为一个小的application。 -
测试案例:【所有参数必须同时满足,才会启用JVM重用】
-
/home/admin/newbigdata/sqoop-1.4.6.bin.hadoop-2.0.4-alpha/bin/sqoop \
import \
-D mapreduce.map.memory.mb=1024 \
# 开启JVM重用功能
-D mapreduce.job.ubertask.enable=true \
# reduce小于该值,则被认为是小application。
-D mapreduce.job.ubertask.maxreduces=1 \
# map数量小于该值,则被认为是小application。
-D mapreduce.job.ubertask.maxmaps=9 \
--connect jdbc:mysql://192.168.110.244:3306/zz_test_sqoop \
--username root \
--password soa123456 \
--table czrk_test \
--fields-terminated-by '\001' \
# 设置为8 < 9,JVM重用生效;如果改成10 > 9,JVM重用功能为false;所有条件都必须同时满足。
-m 8 \
--lines-terminated-by '\n' \
--null-string '\\N' \
--null-non-string '\\N' \
--outdir sqoopcode/HBASE_21/mysqltest \
--map-column-java createdate=java.sql.Timestamp,name=String,content=String \
--map-column-hive createdate=TIMESTAMP \
--delete-target-dir \
--target-dir /HBASE_21/hiveWarehouse/importTempTargetDir_czrk_test \
--hive-drop-import-delims \
--hive-import \
--hive-overwrite \
--hive-database HBASE_21
1.1.23. 笛卡尔积:避免误漏on条件,Hive只能使用1个reducer来完成笛卡尔积。
使用join的时候,尽量有效的使用on条件
避免无效的笛卡尔积:Join时不要忘记on条件,或者出现无效on条件。
join的时候不加on条件或者无效的on条件,Hive只能使用1个reducer来完成笛卡尔积。
1.1.24.Union all:减少MR的数量
先把两张表union all,然后再做join或者group by,可以减少mr的数量。
union 和 union all区别:union相同记录去重,union all不去重,性能后者更优。