OLAP之ClickHouse讲解
前言
- 首先Clickhouse在大方向上属于OLAP,列式存储,MPP。也就是指这三者的基础概念,属于前置知识,如果未曾了解,那么关于接下来对ClickHouse的认知与学习则事倍功半。
- 固穿插一部分前置知识,如果已经有所了解则跳过。
OLAP
OLAP与OLTP
提到OLAP,总是会与OLTP做比较。

OLTP联机事务分析
联机事务分析,强调事务性,并发。微量查询,每秒钟的查询次数较多,数百个甚至过千。SQL语句提交频繁,强调ACID。大多应用于传统的银行证券交易行为,针对某行数据的增删改查。
数据块变化频繁,随着数据量的增长以及计算型的函数参与SQL,消耗大量的CPU时间。
强调三范式。
一定程度上OLAP分析的数据都是由OLTP所产生的。
OLAP联机分析处理
OLAP又分为ROLAP与MOLAP与HOLAP
ROLAP关系型联机分析
关系型联机分析,以关系数据库为核心,以关系型结构进行多维数据的表示和存储。R即表示关系型(Relational)。
比较经典的有Doris,百度开源的产品,已经捐献至apache
将分析用的多维数据存储在关系数据库中,将常用的,频繁需求的直接封装入视图。减少了数据冗余,同时提高了应用的灵活性,模型轻量化。
######Doris
MOLAP多维联机分析
多维联机分析,所用到的多维数据物理上存储为多维数组的形式,形成"立方体"的结构。
kylin,Druid就是最经典MOLTP,核心理念空间换取时间。
主要通过一些软件工具或中间软件实现,维的属性值被映射成多维数组的下标值或下标的范围,而总结数据作为多维数组的值存储在数组的单元中。
缺点是配置过程繁琐(需要专业程度较高),需要配置模型设计,并配合适当的“剪枝”策略(kylin中的强制维度等),以实现计算成本与查询效率的平衡。

HOLAP混合数据模型
对于查询频繁而稳定但又耗时的那些SQL,通过预计算来提速;对于较快的查询、发生次数较少或新的查询需求,像ROLAP一样直接通过SQL操作事实表和维度表。
目前似乎没有开源的OLAP系统属于这个类型

列式存储
列式存储与行式存储
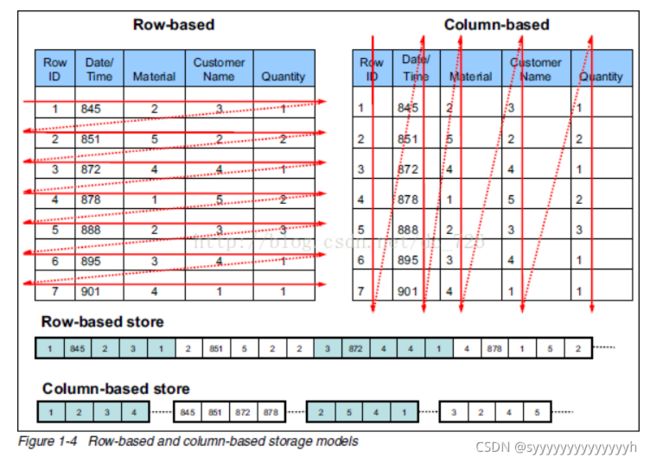
行式存储
所谓行式存储,顾名思义,数据在磁盘上的存储以行为最小单位。适应场景,也就是数据按行读写。
Mysql,Oracle为其中典例
行式存储,列数是固定的,字段没有数据,也就是空行,依旧会占用空间。每行数据的类型也不一致,所以压缩的效率不会太高。
适用于随即查询,通常行式存储也就是关系型数据库,都提供二级索引,在整行的读取上,效率较优。
缺点是,范围读取性能不佳,如果只取某几个字段则需要全表扫描。应用于BI的场景,如果不设计视图,效率注定不佳。
列式存储
所谓列式存储,也就是在磁盘上的数据按列存储,按列读写。更像一个Map,K,V。
国内知名度较高的有HBase,国外知名度较高的有Cassandra。
字段中没有数据,不会占用空间。每列的数据类型基本是一致的,所以压缩的效率极高。
适用于范围查询,批量查询,大规模数据的聚合操作。
例如HBase,弱化了列的概念,但并非完全不要求结构,列族需要提前定义。
缺点是,顺序读写效率低,表关联关系较为复杂。
Cassandra数据结构
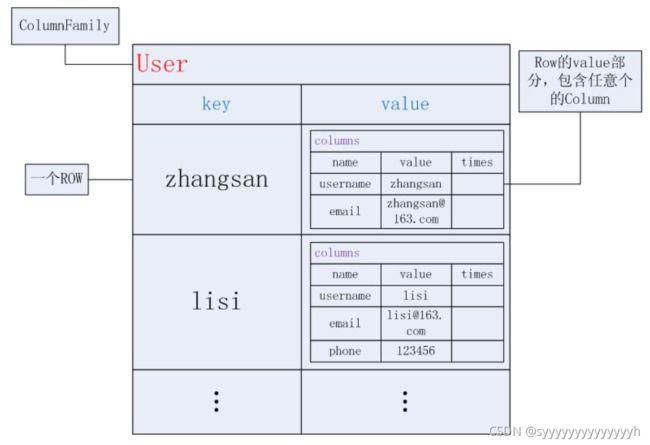
HBase数据结构

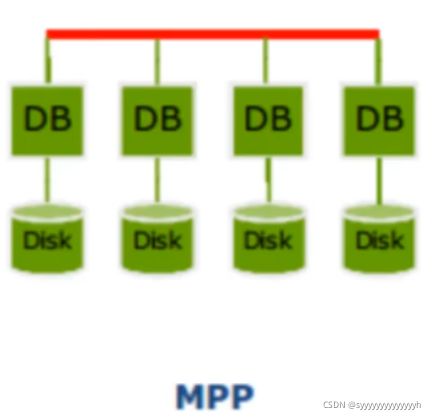
MPP
大规模并行处理系统
多个SQL数据库节点搭建的数据仓库系统。执行查询的时候,查询可以分散到多个SQL数据库节点上执行,然后汇总返回给用户.
比较经典的有Impala,Clickhouse,GreenPlum
每个节点都有自己独立的CPU,内存和磁盘资源。任务执行能力强,充分发挥本地计算的能力,数据无共享,无IO冲突,无锁资源竞争,计算速度快
缺点是,如果某个节点的计算迟迟无法完成,就出现短板效应。
Clickhouse
易观针对目前市面上OLAP所作报告 满分5分

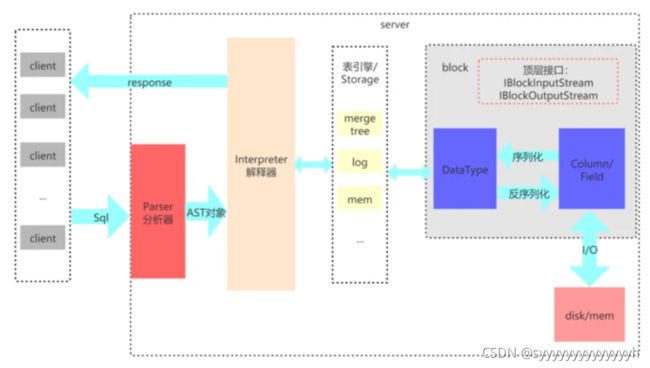
ClickHouse特性之数据压缩
数据压缩支持标记压缩,列级压缩。也就是指可以针对不同的列,采用不同的压缩,较为灵活。创表时实现。
create table database.db_name(
security_id String CODEC(LZ4),
gross_profit float64 CODEC(Gorilla,LZ4),
rang_pc float32 CODEC(T64,LZ4),
trade_date Date CODEC(DoubleDelta,LZ4)
)
ENGINE = ReplacingMergeTree
PARTITION BY toYYYYMMDD(trade_date)
ORDER BY (security_id,
trade_date)
编码方式
LowCardinality
不多于1万个值的字符串(低基数的),且字符串长度越长,效果提升越好
Delta
时间序列 增量编码存储连续值之间的差值。这种差异通常具有较小的字节大小和基数,特别是对于序列来说。以后可以使用LZ4或ZSTD有效地压缩它
DoubleDelta
通过这种编码,ClickHouse存储了连续增量之间的差异。对于缓慢变化的序列,它给出了更好的结果。用物理上的类比,Delta编码速度,而DoubleDelta编码加速。
Gorilla
灵感来源于,facebook的文章,对于不经常变化的值,Gorilla编码非常有效。它既适用于float数据类型,也适用于integer数据类型
T64
这种编码是ClickHouse独有的。它计算编码范围的最大值和最小值,然后通过转置64位矩阵(T64名称的来源)剥离较高的位。最后,我们得到了相同数据的更紧凑的位表示。对于整数数据类型,编码是通用的,并且不需要数据中的任何特殊属性,只需要值的位置
压缩方式
None
支持完全不压缩,好处是对cpu没有任何性能影响,压缩与解压消耗大量CPU,缺点是占用C盘空间太多。
LZ4
高效的压缩算法,压缩与解压的效率都很高,但是压缩比不太乐观,适用于日志压缩
LZ4HC
LZ4的高压缩率压缩算法,是LZ4的高压缩比改进版,更适用于非字符串类型,但写入的效率降低。可选压缩级别。level默认值为9,支持[1,12],推荐选用[4,9] LZ4HC(6)
ZSTD
与LZ4相比,对String类型的效果更好,解压和压缩的效率较低,但是压缩比提升将近30%,释放大量空间。可选压缩机别,level默认值为1,支持[1,22]。
全局配置
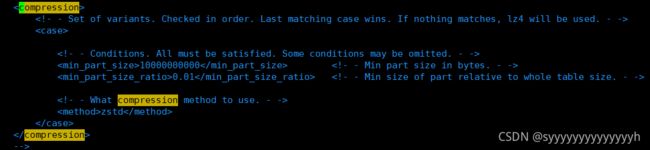
结论
LZ4HC(6)与ZSTD(15),编码LowCardinality,在部分公司表现最佳。
ClickHouse特性之磁盘存储
设计之初ClickHouse被设计用于工作在传统磁盘上的系统,它提供每GB更低的存储成本,但如果可以使用SSD和内存,它也会合理的利用这些资源。
ClickHouse支持在建表时,指定将数据按照某些列进行sort by。
排序后,保证了相同sort key的数据在磁盘上连续存储,且有序摆放。在进行等值、范围查询时,where条件命中的数据都紧密存储在一个或若干个连续的Block中,而不是分散的存储在任意多个Block, 大幅减少需要IO的block数量。
Clickhouse特性之多核心并行处理
单机情况下
ClickHouse将数据划分为多个partition,每个partition再进一步划分为多个index granularity,然后通过多个CPU核心分别处理其中的一部分来实现并行数据处理。
在这种设计下,单条Query就能利用整机所有CPU。极致的并行处理能力,极大的降低了查询延时。
分布式情况下
ClickHouse会自动将查询拆解为多个task下发到集群中,然后进行多机并行处理,最后把结果汇聚到一起。
在存在多副本的情况下,ClickHouse提供了多种query下发策略:
1.随机下发:在多个replica中随机选择一个;
2.最近hostname原则:选择与当前下发机器最相近的hostname节点,进行query下发。在特定的网络拓扑下,可以降低网络延时。而且能够确保query下发到固定的replica机器,充分利用系统cache。
3.in order:按照特定顺序逐个尝试下发,当前一个replica不可用时,顺延到下一个replica。
4.first or random:在In Order模式下,当第一个replica不可用时,所有workload都会积压到第二个Replica,导致负载不均衡。first or random解决了这个问题:当第一个replica不可用时,随机选择一个其他replica,从而保证其余replica间负载均衡。另外在跨region复制场景下,通过设置第一个replica为本region内的副本,可以显著降低网络延时。
ClickHouse特性之多服务器分布式处理
分片,副本的概念,较为灵活。shard与replica
一个三分片双副本的配置信息
1
true
192.168.0.81
9000
192.168.0.102
9000
1
true
192.168.0.102
9100
192.168.0.103
9000
1
true
192.168.0.81
9100
192.168.0.103
9100
::/0
192.168.0.81
2181
192.168.0.102
2181
192.168.0.103
2181
10000000000
0.01
lz4
ClickHouse特性之支持SQL
在许多情况下支持标准SQL,但相关子查询以及窗口函数等等暂不支持。并且连接查询性能也欠佳。
相关子查询与非相关子查询
#非相关
select * from table1
where age > (
select age from table2 where name = '张三' and id = '0001'
)
#相关 先执行主查询,再针对主查询返回的每一行数据执行子查询,如果子查询能够返回行,则这条记录就保留,否则就不保留
select * from table1 a
where age > (
select avg(age) from table2 b where a.sex = b.sex
)
ClickHouse特性之向量引擎
向量化与SIMD
ClickHouse实现了向量执行引擎(Vectorized execution engine),对内存中的列式数据,一个batch调用一次SIMD指令(而非每一行调用一次),不仅减少了函数调用次数、降低了cache miss,而且可以充分发挥SIMD指令的并行能力,大幅缩短了计算耗时。向量执行引擎,通常能够带来数倍的性能提升。
什么是向量化与SIMD
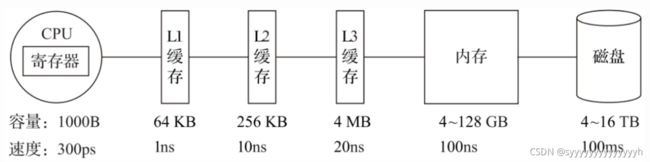
为了实现向量化执行,需要利用CPU的SIMD指令。SIMD的全称是Single Instruction Multiple Data,即用单条指令操作多条数据。现代计算机系统概念中,它是通过数据并行以提高性能的一种实现方式 ( 其他的还有指令级并行和线程级并行 ),它的原理是在CPU寄存器层面实现数据的并行操作。
在计算机系统的体系结构中,存储系统是一种层次结构。存储媒介距离CPU越近,则访问数据的速度越快。
ClickHouse特性之实时的数据更新
对于MergeTree引擎,ClickHouse表的主键(Primary Key)和排序键(Order By Key)相同。但是采用了汇总合并树引擎(SummingMergeTree)的表可以单独指定主键
主键定义了记录在存储中排序的顺序,允许重复。并且写入的过程中不会存在任何加锁的行为。所以数据可以持续不断地高效的写入到表中。
MergeTree 的order by语句

ClickHouse特性之索引
只有MergeTree系列的表引擎才支持主键索引,数据分区,数据副本,数据采样这样的特性,只有此系列的表引擎才支持ALTER操作
标准的MergeTree创表语句
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] ,
name2 [type2] ,
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
#分区
[PARTITION BY expr]
#排序 默认与主键相同作用
[ORDER BY expr]
#主键 默认与排序相同作用
[PRIMARY KEY expr]
#抽样表达式,或者说采样表达式,如果配置,则需要在主键中同样声明
#SAMPLE 0.1 意味着抽样十分之一的数据,假设结果求count() 手动乘十
#SAMPLE 100000000 意味着至少抽样这么多行数据
#SAMPLE 0.5 1/2 意味着从后一半取一半的数据
[SAMPLE BY expr]
#存活时间
[TTL ]
#配置项
#index_granularity=8192 意味着间隔8192行生成一个索引
#index_granularity_bytes = 1010241024 根据大小(10M)生成索引
[SETTINGS name=value, ...]
一级索引
除SummingMergeTree引擎外,一级索引就是主键也就是排序字段,根据稀疏索引,也就是SETTINGS来控制。
二级索引
MergeTree支持二级索引,也叫做跳数索引,是由数据的聚合信息构建而成。根据索引类型的不同,其聚合信息的内容也不同,但它的目的和一级索引是一致的,都是为了帮助查询时减少数据扫描范围
新版本中默认开启,允许使用,旧版本不够成熟,所以默认关闭。
一张表支持多个跳数索引。
INDEX sample_index (u64 * length(s)) TYPE minmax GRANULARITY 4
INDEX sample_index2 (u64 * length(str), i32 + f64 * 100, date, str) TYPE set(100) GRANULARITY 4
INDEX sample_index3 (lower(str), str) TYPE ngrambf_v1(3, 256, 2, 0) GRANULARITY 4
minmax
记录了极值,也就是最大最小值,超过范围认为不存在.
CREATE TABLE table_name
(
u64 UInt64,
i32 Int32,
s String,
...
INDEX a (u64 * i32, s) TYPE minmax GRANULARITY 3
) ENGINE = MergeTree()
set(max_row)
存储指定表达式的不重复值(不超过 max_rows 个,max_rows=0 则表示『无限制』)。这些信息可用于检查数据块是否满足 WHERE 条件
set索引会对所有函数生效
CREATE TABLE table_name
(
u64 UInt64,
i32 Int32,
s String,
...
#表示set索引值会取u64的值乘以s的长度当作唯一值,每个索引内最多有1000条记录
INDEX b (u64 * length(s)) TYPE set(1000) GRANULARITY 4
) ENGINE = MergeTree()
ngrambf_v1
ngrambf_v1(n, size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed)
n – 短语长度。
size_of_bloom_filter_in_bytes – 布隆过滤器大小,字节为单位。(因为压缩得好,可以指定比较大的值,如 256 或 512)。
number_of_hash_functions – 布隆过滤器中使用的哈希函数的个数。
random_seed – 哈希函数的随机种子。
tokenbf_v1
tokenbf_v1(size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed)
跟 ngrambf_v1 类似,但是存储的是token而不是ngrams。Token是由非字母数字的符号分割的序列
bloom_filter
bloom_filter(bloom_filter([false_positive])
为指定的列存储布隆过滤器
可选参数false_positive用来指定从布隆过滤器收到错误响应的几率。取值范围是 (0,1),默认值:0.025
支持的数据类型:Int*, UInt*, Float*, Enum, Date, DateTime, String, FixedString, Array, LowCardinality, Nullable
ClickHouse特性之在线查询
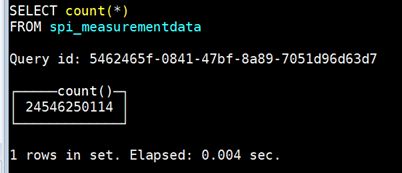
意味着在没有任何预计算的情况下,保持即席查询
单单在count(*)上效率就极高
ClickHouse特性之近似计算
在允许牺牲数据精度的情况下对查询进行加速的方法
比如上文讲过的抽样表达式SAMPLE
uniqCombined(id),代替 count(distinct id) 根据哈希值来做近似计算。对string做64位哈希,其他的类型做32位哈希。
官网提到的medians与quantiles指的是同一函数,不同别名。分位数函数
ClickHouse特性之数据复制数据完整
上文讲到过的副本策略。通过zookeeper进行数据同步,znode中保留sql语句,等待执行。中间视图
ClickHouse特性之角色的访问控制
通过对user.xm配置文件控制用户的访问权限,指定用户可以访问某些库,可操作某些库。
ClickHouse常用引擎之日志引擎
顾名思义,Log引擎,也就是常用于日志,所以支持的条数不会太多,为少于一百万行的场景而开发。
日志引擎之Log引擎
最轻量级的引擎,多用于演示或测试。标记的小文件与列文件存放在一起,并且含有便宜了。支持并发读,写入时将阻塞读操作。不支持索引,写入失败则表损坏。
日志引擎之TinyLog
最简单的表引擎。数据都存放在磁盘之中,写入时文件写入末尾。适用于一次写入,多次读取。单线程不支持并行查询。
日志引擎之StripeLog
将所有列存储至一个文件中对每一次 Insert 请求,ClickHouse 将数据块追加在表文件的末尾,逐列写入。数据文件与标记文件,标记文件中存储偏移量。查询时多线程工作。
ClickHouse常用引擎之集成引擎
可以集成MongoDB,RabitMQ,Kafka,Mysql,Postgres,jdbc,odbc,hdfs
ClickHouse常用引擎之核心引擎合并树家族
支持主键,分区,副本,分片,抽样。
最核心,最常用。MergeTree以及MergeTree的变种,或者延展。

- MergeTree
- ReplacingMergeTree
- SummingMergeTree
- AggregatingMergeTree
- CollapsingMergeTree
- VersionedCollapsingMergeTree
- GraphiteMergeTree
基本的建表语句
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
表达式中必须存在至少一个 `Date` 或 `DateTime` 类型的列,比如:
`TTL date + INTERVAl 1 DAY`
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]
合并树家族之MergeTree
适用于批量插入数据,而不是非常频繁地插入单行
数据的存储按主键分块。
MergeTree在写入一批数据时,数据会以数据片段的形式写入磁盘,且数据片段不可修改。为了避免片段过多,ClickHouse会通过后台线程,定期合并这些数据片段,属于相同分区的数据片段会被合成一个新的片段。
合并树家族之ReplacingMergeTree
该引擎和MergeTree的不同之处在于它会删除排序键值相同的重复项
使用ORDER BY排序键,作为判断数据是否重复的唯一键
数据的去重只会在数据合并期间进行。合并会在后台一个不确定的时间进行
删除重复数据,是以数据分区为单位。同一个数据分区的重复数据才会被删除,不同数据分区的重复数据仍会保留
合并树家族之SummingMergeTree
合并SummingMergeTree表的数据片段时,ClickHouse 会把所有具有相同主键的行合并为一行,该行包含了被合并的行中具有数值数据类型的列的汇总值。
ENGINE = SummingMergeTree([columns])
合并树家族之AggregatingMergeTree
ClickHouse 会将一个数据片段内所有具有相同主键(准确的说是排序键)的行替换成一行,这一行会存储一系列聚合函数的状态.
CREATE TABLE agg_table(
id String,
city String,
#code,value是聚合字段,等同于`UNIQ(code), SUM(value)`
code AggregateFunction(uniq,String),
value AggregateFunction(sum,UInt32),
create_time DateTime,
)ENGINE = AggregatingMergeTree
PARTITIION BY toYYYYMM(create_time)
#字段id, city 是聚合条件
ORDER BY (id,city)
PRIMARY KEY id
通常会新建一张物化视图用于操作
CREATE MATERIALIZED VIEW agg_view
ENGINE = AggregatingMergeTree()
PARTITION BY city
ORDER BY (id,city)
AS SELECT
id,
city,
uniqState(code) AS code,
sumState(value) AS value
FROM agg_table basic
GROUP BY id,city
副本引擎之ReplicatedMergeTree
只有 MergeTree 系列里的表可支持副本
- ReplicatedMergeTree
- ReplicatedSummingMergeTree
- ReplicatedReplacingMergeTree
- ReplicatedAggregatingMergeTree
- ReplicatedCollapsingMergeTree
- ReplicatedVersionedCollapsingMergetree
- ReplicatedGraphiteMergeTree
创建副本(本地)表
CREATE TABLE table_name `ON CLUSTER xxxxx`
(
EventDate DateTime,
CounterID UInt32,
UserID UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/table_name', '{replica}')
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
SAMPLE BY intHash32(UserID)
##由这部分替代
05
02
example05-02-1.yandex.ru
操作副本表
Distributed
分布式引擎本身不存储数据, 但可以在多个服务器上进行分布式查询。
读是自动并行的。读取时,远程服务器表的索引(如果有的话)会被使用。
分布式引擎参数:服务器配置文件中的集群名,远程数据库名,远程表名,数据分片键(可选)
#cluster 数据库 表明 分片键 根据哪个字段的hash分片
Distributed(logs, default, hits[, sharding_key])
ClickHouse特殊引擎之 Buffer
缓冲数据写入 RAM(主存,是与CPU直接交换数据的内部存储器) 中,周期性地将数据刷新到另一个表。在读取操作时,同时从缓冲区和另一个表读取数据
buffer 表没有索引
如果需要改为表结构,推荐先删除 Buffer 表,再改变目标表结构,再重建 Buffer 表
如果机器异常重启,则 Buffer 表内容会丢失
向 Buffer 表写数据时,这个 Buffer 区将会加锁,这时读请求会有延迟
CREATE TABLE merge.hits_buffer AS merge.hits ENGINE = Buffer(merge, hits, 16, 10, 100, 10000, 1000000, 10000000, 100000000)
创建了16个缓冲区。如果已经过了100秒,或者已写入100万行,或者已写入100 MB数据,则刷新每个缓冲区的数据;或者如果同时已经过了10秒并且已经写入了10,000行和10 MB的数据。