【Redis】Redis 的学习教程(六)Redis 的缓存问题
在服务端中,数据库通常是业务上的瓶颈,为了提高并发量和响应速度,我们通常会采用 Redis 来作为缓存,让尽量多的数据走 Redis 查询,不直接访问数据库。
同时 Redis 在使用过程中(高并发场景下)也会出现各种各样的问题,面对这些问题我们该如何处理:
- 缓存穿透
- 缓存击穿
- 缓存雪崩
- 缓存污染
- 数据一致性
1. 缓存穿透
缓存穿透:当缓存和数据中都没有对应记录,但是客户端却一直在查询,导致所有的查询压力全部给到了数据库。
比如:黑客攻击系统,不断的去查询系统中不存在的用户,查询时先走缓存,缓存中没有,再去查数据库;或者电商系统中,用户搜索某类商品,但是这类商品再系统中根本不存在,这次的搜索应该直接返回空
解决方案:
- 网关层增加校验,进行用户鉴权,黑名单控制,接口流量控制
- 对于同一类查询,如果缓存和数据库都没有获取到数据,那么可用用一个空缓存记录下来,设置过期时间(如:5s),下次遇到同类查询,直接取出缓存中的空数据返回即可
比如:查询一个用户:先查询缓存中是否存在该用户,如果存在则直接返回。否则,再查询数据库,并将查询结果进行缓存
@GetMapping("/queryById")
public User queryById(Integer id) {
String userKey = "user:" + id;
Object obj = redisUtil.get(userKey);
if (Objects.nonNull(obj)) {
return (User)obj;
}
User user = userService.getById(id);
if (Objects.isNull(user)) {
throw new RuntimeException("该用户不存在");
}
redisUtil.set(userKey, user);
return user;
}
如果项目的并发量不大,这样写的话几乎没啥问题。
如果项目的并发量很大,那么这就存在一个隐藏问题:如果在访问了一个不存在的用户(这个用户已经在后台可能是被删除),那么就会导致所有的请求全部需要到数据库中进行查询,从而给数据库造成压力,甚至造成宕机
解决方案:缓存空对象
针对缓存穿透问题缓存空对象可以有效避免所产生的影响,当查询一条不存在的数据时,在缓存中存储一个空对象并设置一个过期时间(设置过期时间是为了避免出现数据库中存在了数据但是缓存中仍然是空数据现象),这样可以避免所有请求全部查询数据库的情况
@GetMapping("/queryById")
public User queryById(Integer id) {
String key = "user::" + id;
Object obj = redisUtil.get(userKey);
if (Objects.nonNull(obj)) {
return (User)obj;
}
User user = userService.getById(id);
if (Objects.isNull(user)) {
// 缓存空对象
redisUtil.set(userKey, "", 5L);
} else {
redisUtil.set(userKey, user);
}
return user;
}
缺点:在于无论数据存不存在都需要查询一次数据库,并且 Redis 中存储了大量的空数据。
这个时候可以采用布隆过滤器来解决
- 使用布隆过滤器,布隆过滤器可以用来判断某个元素是否存在于集合中,利用布隆过滤器可以过滤掉一大部分无效请求
布隆过滤器(Bloom Filter)是一种数据结构,用于快速检查一个元素是否属于某个集合中。它可以快速判断一个元素是否在一个大型集合中,且判断速度很快且不占用太多内存空间
布隆过滤器的主要原理:
使用一组哈希函数,将元素映射成一组位数组中的索引位置。当要检查一个元素是否在集合中时,将该元素进行哈希处理,然后查看哈希值对应的位数组的值是否为1。如果哈希值对应的位数组的值都为1,那么这个元素可能在集合中,否则这个元素肯定不在集合中。由于哈希函数的映射可能会发生冲突,因此布隆过滤器可能会出现误判
布隆过滤器的实现:
在使用布隆过滤器时有两个核心参数,分别是预估的数据量size以及期望的误判率fpp,这两个参数我们可以根据自己的业务场景和数据量进行自主设置
在实现布隆过滤器时,有两个核心问题,分别是 hash 函数的选取个数 n 、确定 bit 数组的大小 len:
-
根据预估数据量 size 和误判率 fpp,可以计算出 bit 数组的大小 len
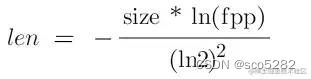
-
根据预估数据量 size 和 bit 数组的长度大小 len,可以计算出所需要的 hash 函数个数 n
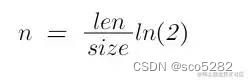
1. 单机版布隆过滤器
目前单机版的布隆过滤器实现方式有很多:Guava 提供的 BloomFilter,Hutool 工具包中提供的 BitMapBloomFilter 等
这里以 Guava 为例,引入依赖:
<dependency>
<groupId>com.google.guavagroupId>
<artifactId>guavaartifactId>
<version>21.0version>
dependency>
布隆过滤器工具类:闯将布隆过滤器
public class BloomFilterUtil {
public static BloomFilter<Integer> localBloomFilter = BloomFilter.create(Funnels.integerFunnel(),10000L,0.01);
}
将需要筛选的数据同步到过滤器中
// 单机版布隆过滤器数据初始化
@PostConstruct
public void initUserDataLocal(){
List<User> users = userService.lambdaQuery().select(User::getId).list();
if(!CollectionUtils.isEmpty(users)){
users.stream().map(User::getId).forEach(id -> BloomFilterUtil.localBloomFilter.put(id));
}
}
使用布隆过滤器:
@GetMapping("/queryById")
public User queryById(Integer id) {
boolean mightContain = BloomFilterUtil.localBloomFilter.mightContain(id);
//是否有可能存在于布隆过滤器中
if(!mightContain) {
log.info("==== select from bloomFilter , data not available ====");
return null;
}
String userKey = "user:" + id;
// ...
}
2. 自定义分布式版布隆过滤器
自定义分布式布隆过滤器的存储依赖于 Redis 的 Bitmap 数据结构来实现,另外还需要定义四个参数,分别为预估数据量 size,误判率 fpp,数组大小 bitNum 以及 hash 函数个数 hashNum。其中,预估数据量和误判率需要配置在 yml 文件中。
application.yml
bloom:
filter:
size: 10000
fpp: 0.01
布隆过滤器工具类:
@Component
public class BloomFilterUtil {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
/**
* 预估数据量
*/
@Value("${bloom.filter.size}")
private long size;
/**
* 误判率
*/
@Value("${bloom.filter.fpp}")
private double fpp;
/**
* 数组大小len
*/
private long bitNum;
/**
* hash函数个数size
*/
private int hashNum;
@PostConstruct
private void initBloom() {
this.bitNum = getNumOfBits(size, fpp);
this.hashNum = getNumOfHashFun(size, bitNum);
//借助 Redis 的 Bitmap 来实现二进制数组
redisTemplate.opsForValue().setBit("bloom::filter", bitNum, false);
}
/**
* 计算bit数组大小
*
* @author zzc
* @date 2023/8/30 15:15
* @param size
* @param fpp
* @return long
*/
private long getNumOfBits(long size, double fpp) {
return (long) (-size * Math.log(fpp) / (Math.log(2) * Math.log(2)));
}
/**
* 计算所需的hash个数
*
* @author zzc
* @date 2023/8/30 15:15
* @param size
* @param numOfBits
* @return int
*/
private int getNumOfHashFun(long size, long numOfBits) {
return Math.max(1, (int) Math.round((double) numOfBits / size * Math.log(2)));
}
/**
* 向自定义布隆过滤器中添加元素
*
* @author zzc
* @date 2023/8/30 15:17
* @param key
*/
public void putBloomFilterRedis(String key) {
long hash64 = HashUtil.metroHash64(key.getBytes());
int hash1 = (int) hash64;
int hash2 = (int) (hash64 >>> 32);
for (int i = 1; i <= hashNum; i++) {
/**
* 上面不是说,要使用n个hash函数吗??为啥这里直接用一个动态变量取乘积了呢???
* 不用担心,请看《Less Hashing, Same Performance: Building a Better Bloom Filter》,
* 里面论述了这种操作不会影响布隆过滤器的性能,毕竟hash的代价还是很大的,这算是个有效的优化手段吧:
* A standard technique from the hashing literature is to use two hash
* functions h(x) and h(x) to simulate additional hash functions of the form g(x) = h(x) + ih(x) .
*/
int combinedHash = hash1 + i * hash2;
if (combinedHash < 0) {
//如果为负数,则取反(保证结果为正数)
combinedHash = ~combinedHash;
}
// 计算出数组下标,并将下标值置为1
int bitIdx = (int) (combinedHash % bitNum);
redisTemplate.opsForValue().setBit("bloom::filter", bitIdx, true);
}
}
/**
* 判断自定义布隆过滤器中元素是否有可能存在
*
* @author zzc
* @date 2023/8/30 15:16
* @param key
* @return boolean
*/
public boolean existBloomFilterRedis(String key) {
long hash64 = HashUtil.metroHash64(key.getBytes());
int hash1 = (int) hash64;
int hash2 = (int) (hash64 >>> 32);
for (int i = 1; i <= hashNum; i++) {
int combinedHash = hash1 + i * hash2;
if (combinedHash < 0) {
combinedHash = ~combinedHash;
}
int bitIdx = (int) (combinedHash % bitNum);
//判断下标值是否为1,如果不为1直接返回false
Boolean bit = redisTemplate.opsForValue().getBit("bloom::filter", bitIdx);
if (!bit) {
return false;
}
}
return true;
}
}
使用布隆过滤器:
@Slf4j
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserService userService;
@Autowired
private RedisUtil redisUtil;
@Autowired
private BloomFilterUtil bloomFilterUtil;
@GetMapping("/queryById")
public User queryById(Integer id) {
String key = "user::" + id;
boolean mightContain = bloomFilterUtil.existBloomFilterRedis(key);
//是否有可能存在于布隆过滤器中
if(!mightContain) {
log.info("==== select from bloomFilter , data not available ====");
return null;
}
Object obj = redisUtil.get(key);
// ...
}
/**
* 单机版布隆过滤器数据初始化
*
* @author zzc
* @date 2023/8/30 14:44
*/
@PostConstruct
public void initUserDataLocal(){
List<User> users = userService.lambdaQuery().select(User::getId).list();
if (!CollectionUtils.isEmpty(users)) {
users.stream().map(user -> "user::" + user.getId()).forEach(id -> bloomFilterUtil.putBloomFilterRedis(id));
}
}
}
不存在的数据成功被拦截掉了,避免再去查询数据库,即使存在一定的误判率,也几乎不会有啥影响,最多就是查询一次数据库
虽然布隆过滤器可以有效的解决缓存穿透问题,并且实现的算法查找效率也很快。但是,也存在一定的缺点,由于存在 hash 冲突的原因,一方面存在一定的误判率(某个在过滤器中并不存在的 key,但是通过 hash 计算出来的下标值都为 1)。另一方面,删除比较困难(如果将一个数组位置为0,那么这个位置有可能也代表其他 key 的值,会影响到其他的 key)
2. 缓存击穿
缓存击穿:缓存中某个热点数据失效,在高并发情况下,所有用户的请求全部都打到数据库上,短时间造成数据库压力过大
解决方案:
- 接口限流、熔断
- 热点数据不设置过期时间:适用于不严格要求缓存一致性的场景
- 互斥锁,当第一个用户请求到时,如果缓存中没有,其他用户的请求先锁住,第一个用户查询数据库后立即缓存到 Redis,然后释放锁,这时候其他用户就可以直接查询缓存
如果是单机部署的环境下可以使用 synchronized 或 lock 来处理,保证同时只能有一个线程来查询数据库,其他线程可以等待数据缓存成功后在被唤醒,从而直接查询缓存即可。如果是分布式部署,可以采用分布式锁来实现互斥
互斥锁工具类:
@Component
public class RedisLockUtil {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
/**
* 模拟互斥锁
* @author zzc
* @date 2023/8/30 16:29
* @param key
* @param value
* @param exp
* @return boolean
*/
public boolean tryLock(String key, String value, long exp) {
Boolean absent = redisTemplate.opsForValue().setIfAbsent(key, value, exp, TimeUnit.SECONDS);
if (Boolean.TRUE.equals(absent)) {
return true;
}
// 如果线程没有获取锁,则在此处循环获取
return tryLock(key, value, exp);
}
/**
* 释放锁
*
* @author zzc
* @date 2023/8/30 16:29
* @param key
* @param value
*/
public void unLock(String key, String value) {
Object obj = redisTemplate.opsForValue().get(key);
if (Objects.nonNull(obj) && (StrUtil.equals((String) obj, value))) {
// 避免锁被其他线程误删
redisTemplate.delete(key);
}
}
}
使用互斥锁:在查询数据库前进行加锁,读取完成后在释放锁
@Slf4j
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserService userService;
@Autowired
private RedisUtil redisUtil;
@Autowired
private BloomFilterUtil bloomFilterUtil;
@Autowired
private RedisLockUtil redisLockUtil;
@GetMapping("/queryById")
public User queryById(Integer id) {
String key = "user::" + id;
boolean mightContain = bloomFilterUtil.existBloomFilterRedis(key);
//是否有可能存在于布隆过滤器中
if(!mightContain) {
log.info("==== select from bloomFilter , data not available ====");
return null;
}
Object obj = redisUtil.get(key);
if (Objects.nonNull(obj)) {
log.info("==== select from cache ====");
return (User)obj;
}
// 给锁加个标识,避免误删
String s = UUID.randomUUID().toString();
String lockKey = key + "::lock";
//尝试加锁
boolean lock = redisLockUtil.tryLock(lockKey, s, 60);
User user = null;
if (lock) {
try {
// 如果加锁成功,先再次查询缓存,有可能上一个线程查询并添加到缓存了
obj = redisUtil.get(key);
if (Objects.nonNull(obj)) {
log.info("==== select from cache ====");
return (User)obj;
}
log.info("==== select from db ====");
user = userService.getById(id);
if (Objects.nonNull(user)) {
redisUtil.set(key, user, 5);
}
} finally {
// 解锁
redisLockUtil.unLock(lockKey, s);
}
}
return user;
}
/**
* 单机版布隆过滤器数据初始化
*
* @author zzc
* @date 2023/8/30 14:44
*/
@PostConstruct
public void initUserDataLocal(){
List<User> users = userService.lambdaQuery().select(User::getId).list();
if (!CollectionUtils.isEmpty(users)) {
users.stream().map(user -> "user::" + user.getId()).forEach(id -> bloomFilterUtil.putBloomFilterRedis(id));
}
}
}
3. 缓存雪崩
缓存雪崩:对热点数据设置了相同的过期时间,在同一时间这些热点数据key大批量发生过期,请求全部转发到数据库,从而导致数据库压力骤增,甚至宕机
与缓存击穿不同,击穿是指一个 key 过期,雪崩是指很多 key 同时过期。
解决方案:
- 缓存过期时间设置随机的过期时间
if (Objects.nonNull(user)) {
//生成一个随机数
int randomInt = RandomUtil.randomInt(2, 10);
redisUtil.set(key, user, 5 + randomInt);
}
- 缓存过期时间不设置过期时间:在更新数据库数据时,同时也需要更新缓存数据。适用于不严格要求缓存一致性的场景
- 搭建高可用集群:缓存服务故障时,也会触发缓存雪崩,为了避免因服务故障而发生的雪崩,推荐使用高可用的服务集群,这样即使发生故障,也可以进行故障转移
4. 缓存污染
缓存污染:由于历史原因,缓存中有很多 key 没有设置过期时间,导致很多 key 其实已经没有用了,但是一直存放在 redis 中,时间久了,redis 内存就被占满了
解决方案:
- 缓存尽量设置过期时间
- 设置缓存淘汰策略为最近最少使用的原则,然后将这些数据删除
5. 数据一致性
通常情况下,使用缓存的直接目的是为了提高系统的查询效率,减轻数据库的压力。一般情况下使用缓存是下面这几步骤:
- 查询缓存,数据是否存在
- 如果数据存在,直接返回
- 如果数据不存在,再查询数据库
- 如果数据库中数据存在,那么将该数据存入缓存并返回。如果不存在,返回空
这么搞好像看上去并没有啥问题,那么会有一个细节问题:当一条数据存入缓存后,立刻又被修改了,那么这个时候缓存该如何更新呢。不更新肯定不行,这样导致了缓存中的数据与数据库中的数据不一致。
一般情况下对于缓存更新有以下情况:
- 先更新缓存,再更新数据库
- 先更新数据库,再更新缓存
- 先删除缓存,再更新数据库
- 先更新数据库,再删除缓存
1、先更新缓存,再更新数据库
先更新缓存,再更新数据库:如果业务执行正常,不出现网络等问题,这么操作不会有啥问题,两边都可以更新成功。
但是,如果缓存更新成功了,但是当更新数据库时或者在更新数据库之前出现了异常,导致数据库无法更新。这种情况下,缓存中的数据变成了一条实际不存在的假数据。
2、先更新数据库,再更新缓存
这种情况跟上面情况基本一致。如果失败,会导致数据库中是最新的数据,缓存中是旧数据。
还有一种极端情况:在高并发情况下容易出现数据覆盖的现象:A 线程更新完数据库后,在要执行更新缓存的操作时,线程被阻塞了,这个时候线程 B 更新了数据库并成功更新了缓存,当 B 执行完成后线程A继续向下执行,那么最终线程 B 的数据会被覆盖。
3、先删除缓存,再更新数据库
先删除缓存,再更新数据库这种情况,如果并发量不大用起来不会有啥问题。但是在并发场景下会有这样的问题:线程 A 在删除缓存后,在写入数据库前发生了阻塞。这时线程 B 查询了这条数据,发现缓存中不存在,继而向数据库发起查询请求,并将查询结果缓存到了 Redis。当线程 B 执行完成后,线程 A 继续向下执行更新了数据库,那么这时缓存中的数据为旧数据,与数据库中的值不一致
4、先更新数据库,再删除缓存
先更新数据库,再删除缓存也并不是绝对安全的。在高并发场景下,如果线程 A 发起读请求:查询一条在缓存中不存在的数据(这条数据有可能过期被删除了),查询数据库后在要将查询结果缓存到 Redis 时发生了阻塞。这个时候线程 B 发起了更新请求:先更新了数据库,再次删除了缓存。当线程 B 执行成功后,线程 A 继续向下执行,将查询结果缓存到了 Redis 中,那么此时缓存中的数据与数据库中的数据发生了不一致。
解决数据不一致方案
延时双删
延时双删:延时双删,即在写数据库之前删除一次,写完数据库后,再删除一次,在第二次删除时,并不是立即删除,而是等待一定时间在做删除
这个延时的功能可以使用 mq 来实现,这里为了省事,偷个懒,本地测试使用的延时队列来模拟 mq 达到延时效果。
1、定义一个队列元素对象 DoubleDeleteTask:
@Data
public class DoubleDeleteTask implements Delayed {
/**
* 需要删除的key
*/
private String key;
/**
* 需要延迟的时间 毫秒
*/
private long time;
public DoubleDeleteTask(String key, long time) {
this.key = key;
this.time = time;
}
@Override
public long getDelay(TimeUnit unit) {
return unit.convert(time - System.currentTimeMillis(), TimeUnit.MILLISECONDS);
}
@Override
public int compareTo(Delayed o) {
return Long.compare(time, ((DoubleDeleteTask) o).time);
}
}
2、定义一个队列并交给 Spring 管理:
@Configuration
public class DoubleDeleteQueueConfig {
@Bean(name = "doubleDeleteQueue")
public DelayQueue<DoubleDeleteTask> doubleDeleteQueue() {
return new DelayQueue<>();
}
}
3、设置一个独立线程,特意用来处理延时的任务:
@Slf4j
@Component
public class DoubleDeleteTaskRunner implements CommandLineRunner {
@Resource
private DelayQueue<DoubleDeleteTask> doubleDeleteQueue;
@Resource
private RedisTemplate<String, Object> redisTemplate;
/**
* 失败重试次数
*/
private static final int RETRY_COUNT = 3;
@Override
public void run(String... args) {
Runnable runnable = () -> {
try{
while (true) {
DoubleDeleteTask doubleDeleteTask = doubleDeleteQueue.take();
String key = doubleDeleteTask.getKey();
try {
redisTemplate.delete(key);
log.info("====延时删除key:{}====", key);
} catch (Exception e) {
int count = 1;
for (int i = 1; i <= RETRY_COUNT; i++) {
if (count < RETRY_COUNT) {
log.info("====延时删除key:{},失败重试次数:{}====", key, count);
Boolean aBoolean = redisTemplate.delete(key);
if (aBoolean) {
break;
} else {
count++;
}
} else {
break;
}
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
};
new Thread(runnable, "double-delete-task").start();
}
}
如果数据删除失败,可以自定义重试次数以保证数据的一致性,但是也会带来一定的性能影响,如果在实际项目中,建议还是以异步的方式来实现重试。
4、使用延时队列,处理延时双删:
@Autowired
private DelayQueue<DoubleDeleteTask> doubleDeleteTask;
@PostMapping("/update")
public String update(@RequestBody User user) {
String key = "user::" + user.getId();
// 更新缓存
redisUtil.set(key, JSON.toJSONString(user), 5);
// 更新数据库
userService.updateById(user);
// 延迟删除缓存
doubleDeleteTask.add(new DoubleDeleteTask(key, 2000L));
return "update";
}
最后
在高并发的场景下,使用 Reids 还是存在很多坑的,稍不注意就会出现缓存穿透,缓存雪崩等情况,严重的话可以直接造成服务宕机。所以,在以后的开发中需要注意(如果项目没啥并发量的话,可以不用考虑)