ELK ② 索引, 创建, 查看, 删除, 分词器安装及使用, 映射, 创建, 查看, 修改,文档,增删改查及局部更新
管理索引
第1节 索引操作(创建、查看、删除)
1. 创建索引库
Elasticsearch采用Rest风格API,因此其API就是一次http请求,你可以用任何工具发起http请求
语法
PUT /索引名称
{
"settings": {
"属性名": "属性值"
}
}
settings:就是索引库设置,其中可以定义索引库的各种属性 比如分片数 副本数等,目前我们可以不设置,都走默认
示例
PUT /lagou-company-index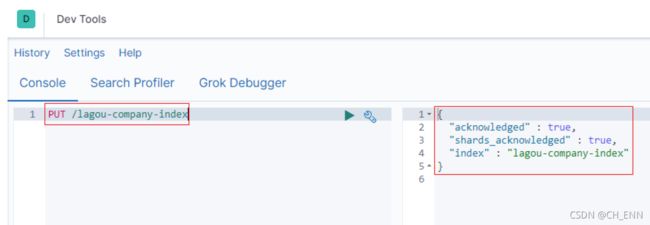
可以看到索引创建成功了。
2. 判断索引是否存在
语法
HEAD /索引名称示例
HEAD /lagou-company-index
3.查看索引
Get请求可以帮我们查看索引的相关属性信息,
格式:
查看单个索引
语法
GET /索引名称示例
GET /lagou-company-index 
批量查看索引
语法
GET /索引名称1,索引名称2,索引名称3,...示例
GET /lagou-company-index,lagou-employee-index 
查看所有索引
方式一
GET _all
方式二
GET /_cat/indices?v 
绿色:索引的所有分片都正常分配。
黄色:至少有一个副本没有得到正确的分配。
红色:至少有一个主分片没有得到正确的分配。
4. 打开索引
语法
POST /索引名称/_open
5.关闭索引
语法
POST /索引名称/_close
6. 删除索引库
删除索引使用DELETE请求
语法
DELETE /索引名称1,索引名称2,索引名称3...示例

再次查看,返回索引不存在

第2节 安装IK分词器
2.1 安装
使用root用户操作!!
每台机器都要配置。配置完成之后,需要重启ES服务
1 在elasticsearch安装目录的plugins目录下新建 analysis-ik 目录
#新建analysis-ik文件夹
mkdir analysis-ik
#切换至 analysis-ik文件夹下
cd analysis-ik
#上传资料中的 elasticsearch-analysis-ik-7.3.0.zip
#解压
unzip elasticsearch-analysis-ik-7.3.3.zip
#解压完成后删除zip
rm -rf elasticsearch-analysis-ik-7.3.0.zip
#分发到其它节点
cd ..
scp -r analysis-ik/ linux122:$PWD
scp -r analysis-ik/ linux123:$PWD注意:
-bash: unzip: command not found
yum install -y unzip2 重启Elasticsearch 和Kibana
#杀死es
ps -ef|grep elasticsearch|grep bootstrap |awk '{print $2}' |xargs kill -9
#启动
nohup /opt/lagou/servers/es/elasticsearch/bin/elasticsearch >/dev/null 2>&1 &
#重启kibana
cd /opt/lagou/servers/kibana/
/bin/kibana
2.2 测试
IK分词器有两种分词模式:ik_max_word和ik_smart模式。
- ik_max_word (常用), 会将文本做最细粒度的拆分
- ik_smart 会做最粗粒度的拆分
先不管语法,在Kibana测试一波输入下面的请求:
POST _analyze
{
"analyzer": "ik_max_word",
"text": "南京市长江大桥"
}ik_max_word 分词模式运行得到结果:
{
"tokens": [{
"token": "南京市",
"start_offset": 0,
"end_offset": 3,
"type": "CN_WORD",
"position": 0
}, {
"token": "南京",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 1
}, {
"token": "市长",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 2
}, {
"token": "长江大桥",
"start_offset": 3,
"end_offset": 7,
"type": "CN_WORD",
"position": 3
}, {
"token": "长江",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 4
}, {
"token": "大桥",
"start_offset": 5,
"end_offset": 7,
"type": "CN_WORD",
"position": 5
}]
}POST _analyze
{
"analyzer": "ik_smart",
"text": "南京市长江大桥"
}ik_smart分词模式运行得到结果:
{
"tokens": [{
"token": "南京市",
"start_offset": 0,
"end_offset": 3,
"type": "CN_WORD",
"position": 0
}, {
"token": "长江大桥",
"start_offset": 3,
"end_offset": 7,
"type": "CN_WORD",
"position": 1
}]
}
如果现在假如江大桥是一个人名,是南京市市长,那么上面的分词显然是不合理的,该怎么办?
2.3 词典使用
扩展词:就是不想让哪些词被分开,让他们分成一个词。比如上面的江大桥
停用词:有些词在文本中出现的频率非常高。但对本文的语义产生不了多大的影响。例如英文的a、an、the、of等。或中文的”的、了、呢等”。这样的词称为停用词。停用词经常被过滤掉,不会被进行索引。在检索的过程中,如果用户的查询词中含有停用词,系统会自动过滤掉。停用词可以加快索引的速度,减少索引库文件的大小。
扩展词与停用词集中存储到linux123服务器上,使用web服务器集中管理,避免每个节点维护一份自己的词典
Linux123部署Tomcat
以下操作使用es用户
1 上传tomcat安装包到linux123服务器
为了避免权限问题上传到此目录下:/opt/lagou/servers/es/
cd /opt/lagou/servers/es/2 解压
tar -zxvf apache-tomcat-8.5.59.tar.gz
mv apache-tomcat-8.5.59/ tomcat/3 配置自定义词典文件
- 自定义扩展词库
cd /opt/lagou/servers/es/tomcat/webapps/ROOT
vim ext_dict.dic- 添加:江大桥
自定义停用词
cd /opt/lagou/servers/es/tomcat/webapps/ROOT
vim stop_dict.dic添加:
的
了
啊4 启动tomcat
/opt/lagou/servers/es/tomcat/bin/startup.sh浏览器访问
http://linux123:8080/ext_dict.dic
5 配置IK分词器
添加自定义扩展,停用词典
使用root用户修改,或者直接把整个文件夹改为es用户所有!!
#三个节点都需修改
cd /opt/lagou/servers/es/elasticsearch/plugins/analysis-ik/config
vim IKAnalyzer.cfg.xml
IK Analyzer 扩展配置
http://linux123:8080/ext_dict.dic
http://linux123:8080/stop_dict.dic
6 重启服务
#杀死es
ps -ef|grep elasticsearch|grep bootstrap |awk '{print $2}' |xargs kill -9
#启动
nohup /opt/lagou/servers/es/elasticsearch/bin/elasticsearch >/dev/null 2>&1 &
#重启kibana
cd /opt/lagou/servers/kibana/
/bin/kibana第3节 映射操作
索引创建之后,等于有了关系型数据库中的database。Elasticsearch7.x取消了索引type类型的设置,不允许指定类型,默认为_doc,但字段仍然是有的,我们需要设置字段的约束信息,叫做字段映射(mapping)
字段的约束包括但不限于:
- 字段的数据类型
- 是否要存储
- 是否要索引
- 分词器
看下创建的语法。
1.创建映射字段
语法
PUT /索引库名/_mapping
{
"properties": {
"字段名": {
"type": "数据类型",
"index": true, //是否索引,不索引就无法针对这个字段查询
"store": false, //存储,默认不存储,_source:存储了文档的所有字段内容;从_source字段中可以获取所有字段,但是需要自己解析,如果对某个字段指定了存储,在查询时直接指定返回的字段会增加io开销。
"analyzer": "分词器"
}
}
}
https://www.elastic.co/guide/en/elasticsearch/reference/7.3/mapping-params.html
字段名:任意填写,下面指定许多属性,例如:
- type:类型,可以是text、long、short、date、integer、object等
- index:是否索引,默认为true
- store:是否存储,默认为false
- analyzer:指定分词器
示例
PUT /lagou-company-index发起请求:
PUT /lagou-company-index/_mapping/
{
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word"
},
"job": {
"type": "text",
"analyzer": "ik_max_word"
},
"logo": {
"type": "keyword",
"index": "false"
},
"payment": {
"type": "float"
}
}
}
响应结果:
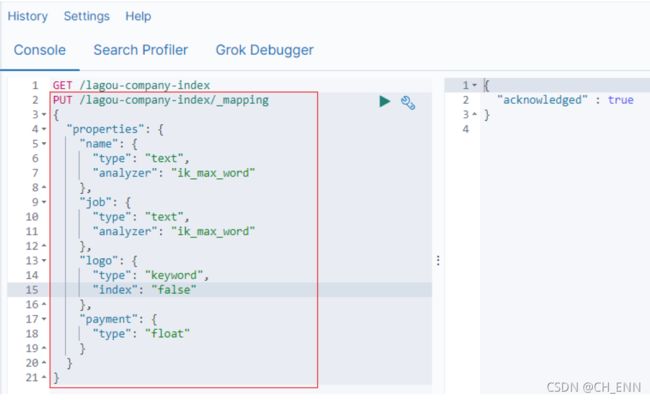
上述案例中,就给lagou-company-index这个索引库设置了4个字段:
- name:企业名称
- job: 需求岗位
- logo:logo图片地址
- payment:薪资
并且给这些字段设置了一些属性,至于这些属性对应的含义,我们在后续会详细介绍。
2.映射属性详解
1 type
Elasticsearch中支持的数据类型非常丰富: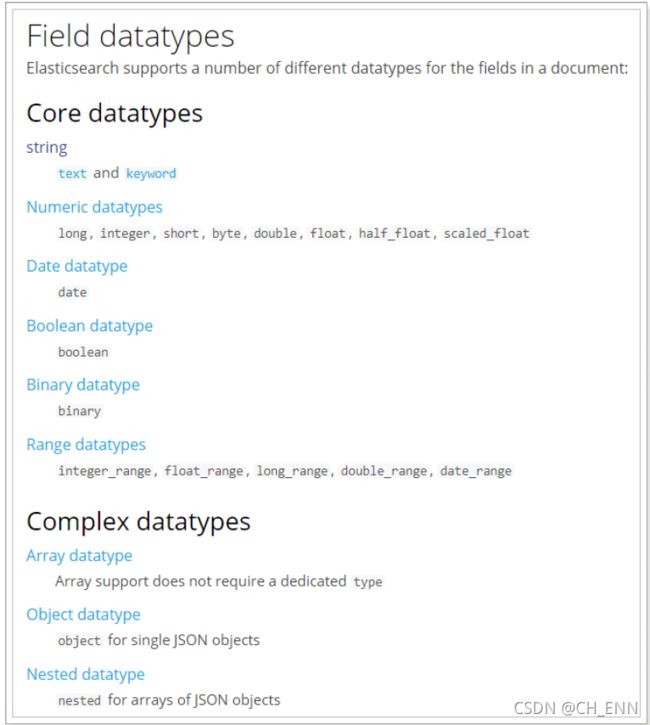
https://www.elastic.co/guide/en/elasticsearch/reference/7.3/mapping-types.html
几个关键的:
String类型,又分两种:
- text:可分词,不可参与聚合
- keyword:不可分词,数据会作为完整字段进行匹配,可以参与聚合
Numerical:数值类型,分两类
- 基本数据类型:long、interger、short、byte、double、float、half_float
- 浮点数的高精度类型:scaled_float, 需要指定一个精度因子,比如10或100。elasticsearch会把真实值乘以这个因子后存储,取出时再还原。
Date:日期类型
elasticsearch可以对日期格式化为字符串存储,但是建议我们存储为毫秒值,存储为long,节省空间。
Array:数组类型
- 进行匹配时,任意一个元素满足,都认为满足
- 排序时,如果升序则用数组中的最小值来排序,如果降序则用数组中的最大值来排序
Object:对象
{
"name": "Jack",
"age": 21,
"girl": {
"name": "Rose",
"age": 21
}
}如果存储到索引库的是对象类型,例如上面的girl,会把girl变成两个字段:girl.name和girl.age
2 index
index影响字段的索引情况。
- true:字段会被索引,则可以用来进行搜索。默认值就是true
- false:字段不会被索引,不能用来搜索
index的默认值就是true,也就是说你不进行任何配置,所有字段都会被索引。 但是有些字段是我们不希望被索引的,比如企业的logo图片地址,就需要手动设置index为false。
3 store
是否将数据进行独立存储。 原始的文本会存储在_source 里面,默认情况下其他提取出来的字段都不是独立存储的,是从_source 里面提取出来的。当然你也可以独立的存储某个字段,只要设置store:true即可,获取独立存储的字段要比从_source中解析快得多,但是也会占用更多的空间,所以要根据实际业务需求来设置,默认为false。
4 analyzer:指定分词器
一般我们处理中文会选择ik分词器 ik_max_word ik_smart
3.查看映射关系
查看单个索引映射关系
语法:
GET /索引名称/_mapping
查看所有索引映射关系
方式一
GET _mapping方式二
GET _all/_mapping
修改索引映射关系
语法
PUT /索引库名/_mapping
{
"properties": {
"字段名": {
"type": "类型",
"index": true,
"store": true,
"analyzer": "分词器"
}
}
}注意:修改映射只能是增加字段操作,做其它更改只能删除索引 重新建立映射 。
4.一次性创建索引和映射
刚才 的案例中我们是把创建索引库和映射分开来做,其实也可以在创建索引库的同时,直接制定索引库中的索引,
基本语法:
put /索引库名称
{
"settings": {
"索引库属性名": "索引库属性值"
},
"mappings": {
"properties": {
"字段名": {
"映射属性名": "映射属性值"
}
}
}
}案例
PUT /lagou-employee-index
{
"settings": {},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}第4节 文档增删改查及局部更新
文档,即索引库中的数据,会根据规则创建索引,将来用于搜索。可以类比做数据库中的一行数据。
1. 新增文档
新增文档时,涉及到id的创建方式,手动指定或者自动生成。
新增文档(手动指定id)
语法
POST /索引名称/_doc/{id}示例
POST /lagou-company-index/_doc/1
{
"name": "百度",
"job": "小度用户运营经理",
"payment": "30000",
"logo": "http://www.lgstatic.com/thubnail_120x120/i/image/M00/21/3E/CgpFT1kVdzeAJNbUAABJB7x9sm8374.png"
}
POST /lagou-company-index/_doc/2
{
"name": "百度",
"job": "小度用户运营经理",
"payment": "30000",
"logo": "http://www.lgstatic.com/thubnail_120x120/i/image/M00/21/3E/CgpFT1kVdzeAJNbUAABJB7x9sm83 74.png",
"address": "北京市昌平区"
}
POST /lagou-company-index/_doc/3
{
"name1": "百度",
"job1": "小度用户运营经理",
"payment1": "30000",
"logo1": "http://www.lgstatic.com/thubnail_120x120/i/image/M00/21/3E/CgpFT1kVdzeAJNbUAABJB7x9sm83 74.png",
"address1": "北京市昌平区"
}
新增文档(自动生成id)
语法
POST /索引名称/_doc
{
"field": "value"
}示例
POST /lagou-company-index/_doc/
{
"name": "百度",
"job": "小度用户运营经理",
"payment": "30000",
"logo": "http://www.lgstatic.com/thubnail_120x120/i/image/M00/21/3E/CgpFT1kVdzeAJNbUAABJB7x9sm83 74.png"
}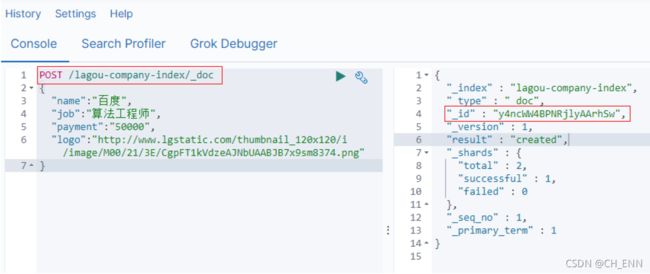
可以看到结果显示为: created ,代表创建成功。 另外,需要注意的是,在响应结果中有个_id 字段,这个就是这条文档数据的唯一标识,这个_id作为唯一标示,这里是Elasticsearch帮我们随机生成的id。
2. 查看单个文档
语法
GET /索引名称/_doc/{id}示例
GET /lagou-company-index/_doc/1
文档元数据解读

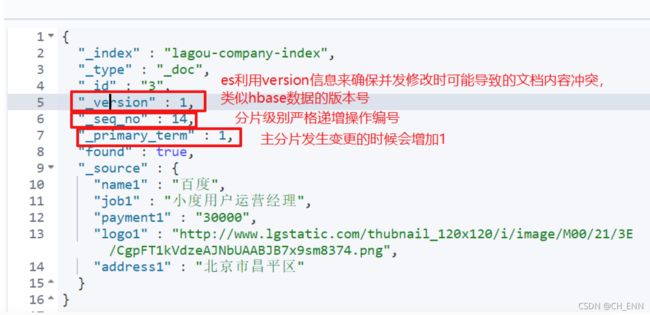
3. 查看所有文档
语法
POST /索引名称/_search
{
"query": {
"match_all": {}
}
}示例
POST /lagou-company-index/_search
{
"query": {
"match_all": {}
}
}4. _source定制返回结果
某些业务场景下,我们不需要搜索引擎返回source中的所有字段,可以使用source进行定制,如下,多个字段之间使用逗号分隔
GET /lagou-company-index/_doc/1?_source=name,job
5. 更新文档(全部更新)
把刚才新增的请求方式改为PUT,就是修改了,不过修改必须指定id
- id对应文档存在,则修改
- id对应文档不存在,则新增
比如,我们把使用id为4,不存在,则应该是新增
示例
PUT /lagou-company-index/_doc/5
{
"name": "百度",
"job": "大数据工程师",
"payment": "300000",
"logo": "http://www.lgstatic.com/thubnail_120x120/i/image/M00/21/3E/CgpFT1kVdzeAJNbUAABJB7x9sm83 74.png"
}{
"_index": "lagou-company-index",
"_type": "_doc",
"_id": "3",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 1
}可以看到是created ,是新增。
我们再次执行刚才的请求,不过把数据改一下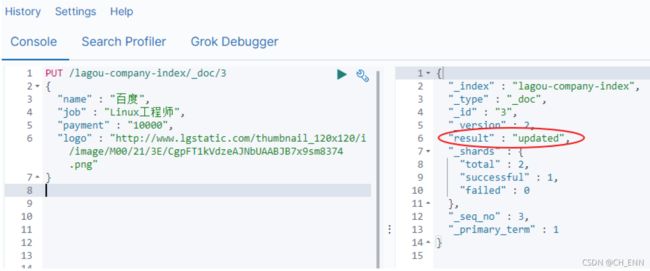
可以看到结果是: updated ,显然是更新数据
6. 更新文档(局部更新)
Elasticsearch可以使用PUT或者POST对文档进行更新(全部更新),如果指定ID的文档已经存在,则执行更新操作。
注意:
Elasticsearch执行更新操作的时候,Elasticsearch首先将旧的文档标记为删除状态,然后添加新的文档,旧的文档不会立即消失,但是你也无法访问,Elasticsearch会在你继续添加更多数据的时候在后台清理已经标记为删除状态的文档。
全部更新,是直接把之前的老数据,标记为删除状态,然后,再添加一条更新的(使用PUT或者POST) 局部更新,
只是修改某个字段(使用POST)
语法
POST /索引名/_update/{id}
{
"doc": {
"field": "value"
}
}示例
POST /lagou-company-index/_update/3
{
"doc": {
"name": "淘宝"
}

7. 删除文档
根据id进行删除:
语法
DELETE /索引名/_doc/{id}示例
DELETE /lagou-company-index/_doc/3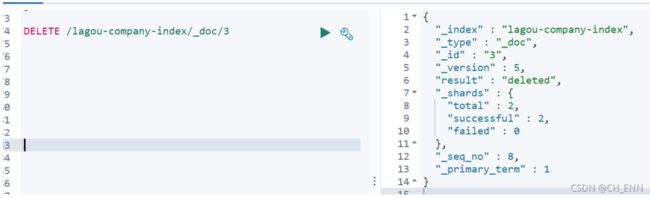
可以看到结果是: deleted ,显然是删除数据
根据查询条件进行删除
语法
POST /索引库名/_delete_by_query
{
"query": {
"match": {
"字段名": "搜索关键字"
}
}
}示例:
#查询name字段百度关键字的doc
POST / lagou - company - index / _search
{
"query": {
"match": {
"name": "百度"
}
}
}
#删除name字段百度关键字的doc
POST / lagou - company - index / _delete_by_query
{
"query": {
"match": {
"name": "百度"
}
}
}
结果
{
"took": 14,
"timed_out": false,
"total": 1,
"deleted": 1,
"batches": 1,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1.0,
"throttled_until_millis": 0,
"failures": []
}
删除所有文档
POST /索引名/_delete_by_query
{
"query": {
"match_all": {}
}
}