jdbc+前端基础
JDBC
一.JDBC的本质
本身是一个普通的java类,能够实现sun公司提供的一套接口规范:
java.sql.Driver
java.sql.Connection
java.sql.Statement
二.JDBC的七大操作步骤
//1.导入驱动包
//2.注册驱动--加载驱动类
Class.forName(com.mysql.jdbc.Driver);
//3.获取数据库的连接对象
Connection con = DriverManager.getConnection("jdbc:mysql://localhost:3306/库名","root","password")
//4.准备sql语句
String sql = "";
//5.通过connection连接对象获取数据库的执行对象
statement stmt = con.createStatement();
//6.执行sql语句
int count = stmt.executeUpdate(sql);
//7.释放资源
stmt.close();
con.close();
1.1JDBC所涉及的API
1)导包---导入msyql驱动包
2)注册驱动--->
Class.forName("com.mysql.jdbc.Driver") ; //为了向后兼容 ---在加载类
本身注册驱动需要用到java.sql.DriverManager:驱动管理类(管理诸如JDBC的服务)
提供静态功能:
1)注册驱动public static void registerDriver(Driver driver) throws SQLException
参数为:java.sql.Drvier---->需要接口的实现类---驱动jar包里面com.mysql.jdbc.Drvier
如果上面的写法使用 DriverManager.registerDriver(new com.mysql.jdbc.Driver());这种方式,会多注册一遍
com.mysql.jdbc.Driver的原码里面
public class Driver extends NonRegisteringDriver implements java.sql.Driver {
public Driver() throws SQLException {
}
static { //静态代码块
try {
DriverManager.registerDriver(new Driver()); //注册驱动了
} catch (SQLException var1) {
throw new RuntimeException("Can't register driver!");
}
}
}
获取数据库的连接对象,返回值 java.sql.Connection
2)public static Connection getConnection(String url,
String user,
String password)
throws SQLException
url: 协议://域名:端口/库名 (统一资源定位符号)
jdbc:mysql://localhost:3306/库名
user:mysql的用户名: root用户
password:密码
java.sql.Connection:与特定数据库连接会话 接口
Statement createStatement() throws SQLException; 获取执行对象
返回返回的数据库执行对象--->里面创建具体子实现类对象
public class StatementImpl implements Statement
java.sql.Statement:用于执行静态SQL语句并返回其生成的结果的对象。
静态sql语句:
弊端
1)硬编码
2)存在sql字符串拼接
String sql = "update account set balance = balance + 500 where id =1 " ;
两种通用操作
针对DDL语句(针对表/库相关的操作),DML语句i的nsert ,update,delete 更新操作
public int executeUpdate(String sql)
针对DQL语句:数据库查询语句 ,返回表示数据库结果集的数据表,通常通过执行查询数据库的语句生成。
ResultSet executeQuery(String sql) throws SQLException
java.sql.ResultSet 据库结果集的数据表
boolean next():是否下一个结果集
三.工具类(构造方法私有,目的就是为了让外界不能new对象)
3.1JdbcUtils工具类
public class JdbcUtils {
//成员变量声明三个变量
private static String url = null ;
private static String user = null ;
private static String password = null ;
private static String driverClass = null ;
//模拟 驱动jar包---Driver驱动类---提供静态代码块
static{
try {
//想办法获取这些参数---->提供配置文件 后缀名.properties---->放在src下面
//1)读取配置文件内容
InputStream inputStream = JdbcUtils.class.getClassLoader()
.getResourceAsStream("jdbc.properties");
//2)创建一个属性集合列表Properties
Properties prop = new Properties() ;
//System.out.println(prop) ;//测试 ---肯定空列表
//3)将1)获取资源文件的输入流对象---加载到属性集合列表中
prop.load(inputStream);
// System.out.println(prop) ; //测试--->有属性列表内容
//4)通过key获取value
driverClass = prop.getProperty("driverClass");
url = prop.getProperty("url") ;
user = prop.getProperty("user") ;
password = prop.getProperty("password") ;
//5)加载驱动类
Class.forName(driverClass) ;
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
private JdbcUtils(){}
/**
* 这个方法,获取数据库的连接对象
* @return
*/
public static Connection getConnection(){
try {
//需要驱动管理DriverManager获取连接对象
Connection connection = DriverManager.getConnection(url, user, password);//获取这三个参数的内容
return connection ;
} catch (SQLException throwables) {
throwables.printStackTrace();
}
return null ;
}
/**
* 释放资源,针对DQL语句操作释放的相关资源对象
* @param rs
* @param stmt
* @param conn
*/
public static void close(ResultSet rs,Statement stmt,Connection conn){
if(rs!=null){
try {
rs.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
if(stmt!=null){
try {
stmt.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
if(conn!=null){
try {
conn.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
}
/**
* 释放资源,针对DDL语句,DML语句
* @param stmt
* @param conn
*/
public static void close(Statement stmt,Connection conn){
close(null,stmt,conn);
}
public static void main(String[] args) {
Connection connection = JdbcUtils.getConnection();
System.out.println(connection);
}
}
封装步骤
1)准备配置文件 jdbc.properties
url=jdbc:mysql://localhost:3306/库名
driverClass=com.mysql.jdbc.Driver
user=root
password=123456
2)当前类中提供静态代码块
static{
1) 读取配置文件
InputStream inputStream = 前类名.class.getClassLoader().getResourceAsStream("jdbc.properties") ;
2)创建属性集合列表
Properties prop = new Properties() ;
//3)加载字节输入流对象到属性集合列表中
prop.load(inputStream) ;
//4)通过key获取value
//public String getProperty(String key)
获取四个key----给成员变量进行赋值
5)加载驱动
Class.forName(驱动类的全限定名称获取到);
}
3)静态方法----获取Connection
Connection conn = DriverManager.getConnection(三个参数直接传进去) ;
4)静态方法--->释放资源
针对DML语句 释放Statment以及Connection
针对DQL语句:释放ResultSet Statement,Connection
获取src下面的配置文件.properties内容
InputStream inputStrema = 前类名.class.getClassLoader().getResourceAsStream("jdbc.properties") ;
// 2)创建属性集合列表
Properties prop = new Properties() ;
//3)加载字节输入流对象到属性集合列表中
prop.load(inputStream) ;
//4)通过key获取value
//public String getProperty(String key)
3.2DruidJdbcUtils工具类
加入Druid连接池的工具类
1)现在目的就创建数据源--javax.sql.DataSource接口--->通过DruidDataSourceFactory创建数据源
2)模拟真实场景
public class DruidJdbcUtils {
//声明数据源
private static DataSource ds = null ;
//模拟线程 :每一个线程使用自己的Conneciton
private static ThreadLocal t1 = new ThreadLocal<>();
//构造方法私有化,外界类不能new
private DruidJdbcUtils(){}
//静态代码块
static{
try {
//当前工具类一加载,读取src下面的druid.properties配置文件
InputStream inputStream = DruidJdbcUtils.class.getClassLoader().
getResourceAsStream("druid.properties");
//创建属性集合列表,将配置文件资源输入流加载属性集合列表中
Properties prop = new Properties() ;
prop.load(inputStream) ;
//通过DruidDataSourceFactory创建DataSource对象---->DruidDataSource具体子实现类
给ds重写赋值
ds = DruidDataSourceFactory.createDataSource(prop);
} catch (IOException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 获取数据源,就是将配置文件的内容加载到了DataSource
* @return
*/
public static DataSource getDataSource(){
return ds ;
}
/**
* 从连接池中获取连接对象 ---->首先需要创建DataSource接口对象
* @return
*/
public static Connection getConnection(){
try {
//1)从当前线程获取Conection
Connection conn = t1.get();
if(conn==null){
//2)当前线程中没有连接对象
//需要从DataSource连接池获取连接对象
conn = ds.getConnection();
//3)将当前连接对象绑定在当前线程上
t1.set(conn);
}
return conn ;
} catch (SQLException throwables) {
throwables.printStackTrace();
}
return null ;
}
//释放资源 针对DQL语句
public static void close(ResultSet rs, PreparedStatement ps ,Connection conn){
if(rs!=null){
try {
rs.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
if(ps!=null){
try {
ps.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
if(conn!=null){
try {
conn.close(); //归还连接池中
//需要从当前线程ThreadLocal进行解绑
t1.remove();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
}
/**
* 针对DDL或者DML语句
* @param ps
* @param conn
*/
public static void close( PreparedStatement ps ,Connection conn){
close(null,ps,conn);
}
//开启事务 ---控制事务:连接对象必须使用同一个!
public static void setAutoCommit() throws SQLException {
//从连接池获取连接对象
Connection conn = getConnection();
conn.setAutoCommit(false) ; //手动提交
}
//回滚事务
public static void rollBackAndClose() throws SQLException {
Connection conn = getConnection();
conn.rollback(); //回滚
conn.close();
t1.remove(); //解绑
}
//提交事务
public static void commitAndClose() throws SQLException {
Connection conn = getConnection();
conn.commit(); //提交事务
conn.close();
t1.remove(); //解绑
}
public static void main(String[] args) {
// System.out.println(DruidJdbcUtils.getDataSource());
System.out.println(DruidJdbcUtils.getConnection());
}
}
通过DruidDataSourceFactory如何创建数据源
//1)读取连接池的配置文件
InputStream inputStream =当前类名.class.getClassLoader().getResourceAsStream("druid.properties") ;
//2)创建属性集合列表
Properties prop = new Properties() ;
//3)加载字节输入流到属性列表中
prop.load(inputStream) ;
//4)创建数据源
DataSource ds = DruidDataSourceFactory.createDataSource(prop) ; //方法本质就是创建的DruidDataSource子实现类对象
德鲁伊配置文件.properties
#德鲁伊的加载驱动的名称driverClassName
driverClassName=com.mysql.jdbc.Driver
#连接的库的地址
url=jdbc:mysql://localhost:3306/ee_2211_02
#用户名
username=root
#密码
password=123456
#连接池启用之后初始化的连接数量5个
initialSize=5
#连接池中最大激活数量10个
maxActive=10
#最大等待时间 3000毫秒(3秒),当连接池如果中的连接数数量超过了最大就激活数量,等待3秒中连接,如果超过3秒,拒绝连接对象进入连接池
maxWait=3000
四.Statement、PreparedStatement、dbutils
4.1Statement和PreparedStatement的区别
Statement执行sql的效率相对PreparedStatement非常低
1)每次书写一条sql就需要通过Statmeent将sql语句发送给数据库,效率低;同时,数据库的压力大!
2)发送的sql语句存在字符串拼接,就会出现安全问题--->SQL注入,恶意攻击数据库,造成安全漏洞!
PreparedStatement执行sql语句效率相对来说很高
1)将一条参数化 的sql语句发送给数据库,进行预编译将编译结果存储在预编译对象中,下一次直接赋值,
而且赋值很多次,发送一次sql,执行不同的参数!
2)参数化的sql语句不存在支持拼接,有效防止SQL注入,开发中使用PreparedStatement来对数据库CRUD
4.2使用Statement和JdbcUtils工具类执行DML语句
public class StatementExecuteDML {
public static void main(String[] args) throws Exception {
//1)直接获取连接对象
Connection conn = JdbcUtils.getConnection();
//2)准备sql语句DML语句
String sql = "" ;
//3)获取执行对象
Statement stmt = conn.createStatement();
//4)执行sql
int count = stmt.executeUpdate(sql);
System.out.println(count);
//释放
JdbcUtils.close(stmt,conn);
}
}
4.3使用Statement和JdbcUtils工具类执行DQL语句
public class StatementExecuteDQL {
public static void main(String[] args) throws Exception {
//1)直接获取连接对象
Connection conn = JdbcUtils.getConnection();
//2)准备sql语句
String sql = "select * from student" ;
//3)获取执行对象
Statement stmt = conn.createStatement();
//4)执行sql
ResultSet rs = stmt.executeQuery(sql);
System.out.println("学生的信息如下:");
while(rs.next()){
//通过列的名称获取 xxx getXXX(String columneLaber)
int id = rs.getInt("id");//第一例的名称
String name = rs.getString("name");//第二列名称
int age = rs.getInt("age");//第三列名称
String gender = rs.getString("gender");//第四列名称
String address = rs.getString("address");//第五列名称
System.out.println(id+" "+name+" "+gender+" "+address);
}
//释放
JdbcUtils.close(rs,stmt,conn);
}
}
4.4使用PreparedStatement和DruidJdbcUtils工具类执行DML语句
public void add(Employee employee) throws SQLException {
//获取数据库对象
Connection conn = DruidJdbcUtils.getConnection();
//准备sql语句
String sql = "insert into employee(name,age,gender,salary,birth) values (?,?,?,?,?) ";
//执行sql语句
PreparedStatement ps = conn.prepareStatement(sql);
ps.setString(1,employee.getName());
ps.setInt(2,employee.getAge());
ps.setString(3,employee.getGender());
ps.setDouble(4,employee.getSalary());
ps.setDate(5, (Date) employee.getBirth());
int count = ps.executeUpdate();
System.out.println(count);
//释放
DruidJdbcUtils.close(ps,conn);
}
4.5使用PreparedStatement和DruidJdbcUtils工具类执行DQL语句
public List<Employee> findAllemployee() throws SQLException {
QueryRunner qr = new QueryRunner(DruidJdbcUtils.getDataSource());
String sql = "select * from employee";
List<Employee> list = qr.query(sql, new BeanListHandler<>(Employee.class));
//创建list集合存储数据
List<Employee> list = new ArrayList<>();
//获取数据库集合对象
Connection conn = DruidJdbcUtils.getConnection();
//准备sql语句
String sql = "select * from employee";
PreparedStatement ps = conn.prepareStatement(sql);
ResultSet rs = ps.executeQuery();
Employee emp = null;
while (rs.next()){
emp = new Employee();
emp.setId(rs.getInt("id"));
emp.setName(rs.getString("name"));
emp.setAge(rs.getInt("age"));
emp.setGender(rs.getString("gender"));
emp.setSalary(rs.getDouble("salary"));
emp.setBirth(rs.getDate("birth"));
list.add(emp);
}
//释放资源
DruidJdbcUtils.close(rs,ps,conn);
return list;
}
4.6使用dbutils和DruidJdbcUtils工具类执行DML语句
public void updateEmp(Employee employee) throws SQLException {
//创建执行对象
QueryRunner qr = new QueryRunner(DruidJdbcUtils.getDataSource()) ;
//sql
String sql = "update employee set name =?,age =?,gender =?,salary =? where id = ?" ;
System.out.println(sql);
//针对增删改, 没有结果集的处理,影响表的记录
// public int update(String sql, Object... params) :自动提交模式
//参数1,sql语句
//参数2:实际参数
int count = qr.update(sql,
employee.getName(),
employee.getAge(),
employee.getGender(),
employee.getSalary(),
employee.getId());
System.out.println(count);
}
4.7使用dbutils和DruidJdbcUtils工具类执行DQL语句
Apache组织结构提供了开源工具类库,针对原生JDBC的一种简易封装,优化了代码,代码更加简洁!
https://commons.apache.org/ 官网地址
public class DbutilsDemo {
public static void main(String[] args) throws SQLException {
//1.导入核心包commons-dbutils-1.6/1.7 .jar
//2.创建这个执行器
// public QueryRunner(DataSource ds) :指定数据源(连接池中核心参数....)
DataSource dataSource = DruidJdbcUtils.getDataSource();
QueryRunner qr = new QueryRunner(dataSource) ;
//3.准备sql语句
//String sql = "select * from employee" ;
//执行sql
//public T query(String sql, ResultSetHandler rsh, Object... params)
//参数1:sql语句
//参数2:查询的结果集的处理接口 子实现类BeanListHandler---->将查询的结果集封装带List集合中,
//参数3:SQL语句的参数(赋值的实际参数)
// public BeanListHandler(Class type) :参数里面需要当前返回的实体类的字节码文件对象
/*List list = qr.query(sql, new BeanListHandler<>(Employee.class));
for(Employee employee:list){
System.out.println(employee);
}*/
//通过员工的id查询员工---查询某个员工
//String sql = "select * from employee where id = ?" ;
//执行sql语句
//public T query(String sql, ResultSetHandler rsh, Object... params)
//参数1:sql语句
//参数2:查询的结果集的处理接口 子实现类BeanHandler---->将查询的某条记录封装到实体类中
//参数3:SQL语句的参数(赋值的实际参数)
// Employee employee = qr.query(sql, new BeanHandler<>(Employee.class), 4);
// System.out.println(employee);
//查询员工表的记录数
String sql = "select count(*) from employee" ;
//public T query(String sql, ResultSetHandler rsh, Object... params)
//参数1:sql语句
//参数2:查询的结果集的处理接口 子实现类ScalarHandler--->将查询的结果集处理的时候返回的单行单列的数据
// 举例:统计总记录数
//参数3:SQL语句的参数(赋值的实际参数)
Object object = qr.query(sql, new ScalarHandler<>());
//将Object-- String的valueOf(任何类型数据)--->数字字符串->Integer.parseInt(数字字符串)-->int
String numbStr = String.valueOf(object);
int count = Integer.parseInt(numbStr);
System.out.println(count);
}
}
五.单元测试
1)导包junit的核心包以及依赖包
2)提供单元测试方法----->定义一个功能,没有返回值,没有参数,在方法上面@Test标记,它是一个单元测试方法
3)@Before,标记的方法是在单元测试方法之前先执行----->初始化的操作
4)@After,标记的方法是在用单元测试执行之后执行---->释放资源
六.实例
6.1需求:有一个学生类,学生编号,学生姓名,学生年龄,学生性别,学生住址属性,查询student表,将每一条数据封装到Student对象中,最终将Student对象添加List集合中,最终遍历List,获取学生信息数据!
分析:
1)定义一个学生类,学生编号,学生姓名,学生年龄,学生性别,学生住址属性私有化
2)定义一个功能---->返回List
2.1)创建一个ArrayList
2.2)JDBC操作---获取连接对象,准备sql,获取执行对象,查询
2.3)查询结果--->ResultSet结果集
2.4)不断的去封装学生对象,将学生对象,添加集合中
2.5)完成遍历
public class Test1 {
public static void main(String[] args) throws Exception {
//调用一个功能
List list = getAllStudent() ;
System.out.println("学生信息如下:");
if(list!=null){
for(Student s:list){
System.out.println(s.getId()+"---"+s.getName()+"---"+s.getAge()+"---"+s.getGender()+"---"+s.getAddress());
}
}
}
//定义通过查询所有学数据,将每一条数据封装学生对象中,最终添加集合中
public static List getAllStudent() throws Exception {
//创建List集合
List list = new ArrayList<>() ;
//JDBC操作
//获取数据库的连接对象
Connection conn = JdbcUtils.getConnection();
//准备sql
String sql = "select * from student" ;
//通过连接对象获取执行对象
Statement stmt = conn.createStatement();
//执行sql语句
ResultSet rs = stmt.executeQuery(sql);
//声明学生类型的变量
Student s = null ;
//遍历结果集
while(rs.next()){
//封装学生数据
s = new Student() ;
//编号
s.setId(rs.getInt("id") );
//姓名
s.setName(rs.getString("name"));
//年龄
s.setAge(rs.getInt("age"));
//性别
s.setGender(rs.getString("gender"));
//住址
s.setAddress(rs.getString("address"));
//将每一个学生对象添加到list集合中
list.add(s) ;
}
return list ;
}
}
6.2使用单元测试计算器类的功能add
计算器类
public class Calculator {
//方法
//求两个数据之和
public int add(int x,int y ){
// return x - y ;
return x + y ;
}
}
单元测试
public class CalculatorTest {
@After
public void close(){
System.out.println("释放系统系统资源代码...");
}
@Before
public void init(){
System.out.println("初始化操作");
}
//标记单个这个方法是单独运行的,单元测试方法
@Test
public void testAdd(){
//创建Calculator类对象
Calculator c = new Calculator() ;
int result = c.add(2, 3);//传入实际参数
System.out.println(result);
//使用org.junit.Assert类---断言提供很多功能
//断言两个结果是否相等,参数1:预期值 参数2:当前计算的实际值
Assert.assertEquals(5,result);
}
}
七.Java和sql中Date类型转换
String dateStr = "1997-5-23";
//日期格式
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
Date date = sdf.parse(dateStr);
java.sql.Date date1 = new java.sql.Date(date.getTime());
八.数据库连接池 Druid
8.1数据库连接池的作用
数据库连接池:
c3p0
dbcp
druid :德鲁伊
1)资源重复利用
使用连接池大大避免了不断的频繁创建连接对象,使用完毕关闭之后,造成的资源销毁大!
2)提高系统的响应速度
在程序启动的时候,提前了准备了的足够的连接对象,存储在"池"中,当用户访问比较多的时候,同时应用,可以直接从
连接池中取出连接对象,执行速度快!
3)控制连接对象
多个连接对象被多个线程在同一时刻使用的时候,连接池中对连接对象进行申请,利用,释放,归还连接池中等待下一次利用
8.2测试数据库连接池 Druid 获取连接对象的过程!
public class DruidTest {
public static void main(String[] args) throws Exception {
//1)导包核心连接池的jar包 druid.jar
//2)准备了druid.properties配置文件
//3)创建属性集合列表
Properties prop = new Properties() ;
//4)读取src下面的连接池的配置文件
InputStream inputStream = DruidTest.class.getClassLoader().getResourceAsStream("druid.properties");
//5)将字节输入流内容加载到属性集合列表中
prop.load(inputStream);
//6)从连接池获取连接对象
//com.alibaba.druid.pool.DruidDataSourceFactory
//提供了静态方法public static DataSource createDataSource(Properties properties)
//创建数据源DataSource数据源接口对象---->本质----DruidDataSource实现类
DataSource ds = DruidDataSourceFactory.createDataSource(prop);
for(int x = 1;x<=11;x++){
Connection conn = ds.getConnection();
if(x == 3){
conn.close();// 将连接对象归还连接池中
}
System.out.println(conn);
}
}
}
前端
一.HTML
1.1常用标签
1.1.1文本标签
换行
<br>
水平线
<hr>
标题
<h1> - <h6> 从大到小标记标题
段落
<p>文本内容p>
| 标签 | 描述 |
|---|---|
| 定义粗体文本。 | |
| 定义大号字。 | |
| 定义着重文字。 | |
| 定义斜体字。 | |
| 定义小号字。 | |
| 定义加重语气。 | |
| 定义下标字。 | |
| 定义上标字。 | |
| 定义插入字。 | |
| 定义删除字。 |
1.1.2 滚动标签
1.1.3原样输出标签
<pre>
内容
pre>
1.1.4上下标标签
上标
<sup>sup>
下标
<sub>sub>
1.1.5版权及商标标签
© 转义成©
® 转义成®
1.1.6超链接标签
<a href="跳转目标" target="目标窗口的弹出方式"> 文本或图像 a>
target self当前窗口打开
blank新窗口打开
自定义打开页面,name="xxx"
1.1.7图像标签
<img src="图像名" >
1.1.8表格标签
<table align="对齐方式" border="边框" cellpadding="单元格与内容之间的距离" cellspacing="单元格之间的距离">table>
1.1.9表单标签
表单提交中get和post的区别
get提交
1)get提交是将信息数据提交地址栏上
url?key1=value1&key2=value2
2)相对post来说,不适合隐私数据(密码/输入动态密令---加密)
3)get提交到地址栏上,数据大小有限制的!
post提交
1)post提交不会提交到地址栏上,直接在浏览器中F12 ---network网络可以查看到
2)相对get来说,安全一些
3)post提交不会将信息提交地址栏上,所以提交数据大小无限制!
1.1.10框架标签
-
通过使用框架,你可以在同一个浏览器窗口中显示不止一个页面。
-
内联框架
1. iframe 用于在网页内显示网页。 2. 语法: URL 指向隔离页面的位置。 -
框架与框架集(框架集又称框架结构)
- 框架标签frame 定义放置在每个框架中的HTML文档
- 框架集标签frameset 定义如何将窗口分割为框架,其属性rows/cols的值分别规定每行和每列的占屏幕的面积。
-
框架标签集frameset(不能放在body中)
cols:分列 rows: 分行 后面为各列占比,用 ,号隔开 <frameset cols="25%,75%"> <frame src="frame_a.htm"> <frame src="frame_b.htm"> frameset> 设置了一个两列的框架集。第一列被设置为占据浏览器窗口的 25%。第二列被设置为占据浏览器窗口的 75%。HTML 文档 "frame_a.htm" 被置于第一个列中,而 HTML 文档 "frame_b.htm" 被置于第二个列中
1.1.11
二.CSS
1.简介
CSS: cascading Style sheet 层叠样式表
CSS 是一种描述 HTML 文档样式的语言。
CSS 描述应该如何显示 HTML 元素。
2.分类
- 行内样式
- 内联样式
- 外联样式
5.CSS常用选择器
-
分类
-
简单选择器
-
元素(标签)选择器
div{ 属性 } -
id选择器
id值必须唯一 #id属性名{ 属性 } -
class选择器等
class 属性可以同名 .class属性名{ 属性 }
-
-
组合器选择器
- 后代选择器(以空格分隔)
- 子元素选择器(以大于号分隔 >)
- 相邻兄弟选择器(以加号分隔 +)
- 后续兄弟选择器(以破折号分隔 ~)
-
伪类选择器
-
子元素选择器
#di1 span{ 属性 } -
并集选择器
#di1,span{ 属性 } -
属性选择器
CSS [attribute=“value”] 选择器
[attribute=“value”] 选择器用于选取带有指定属性和值的元素。
下例选取所有带有 target=“_blank” 属性的 元素:
a[target="_blank"] { background-color: yellow; } 选取 title 属性包含 "flower" 单词的所有元素: [title~="flower"] { border: 5px solid yellow; } -
标签选择器
div{ 属性 }
-
-
优先级:id选择器>类(class)选择器>标签选择器
6.伪类选择器(锚伪类)
-
伪类用于定义元素的特殊状态。
-
1. link状态:鼠标未访问状态 2. hover状态:鼠标经过状态 3. active状态:鼠标获取焦点状态,激活了但没有松开,如超链接就是这种状态 4. visited状态:鼠标访问过了状态 -
注意(重复显示):
1. a:hover 必须在 CSS 定义中的 a:link 和 a:visited之后,才能生效! 2. a:active 必须在 CSS 定义中的 a:hover之后才能生效!伪类名称对大小写不敏感。 3. 顺序:link>visited>hover>active
7.CSS中常用的样式属性
7.1 文本
属性:
1.color
2.textalign 对齐方式
3.text-decoration 属性用于设置或删除文本装饰
underline:设置下划线
none:不设置装饰
overline:上划线
line-through:中划线
4.text-transform:指定文本中的大写和小写字母,它可用于将所有内容转换为大写或小写字母,或将每个单词的首字母大写
text-transform: uppercase; 全部大写
text-transform: lowercase; 全部小写
text-transform: capitalize; 首字母大写
5.text-indent 文本缩进
6.letter-spacing 属性用于指定文本中字符之间的间距。
7.2边框
- CSS
border属性指定元素边框的样式、宽度和颜色
最终简写方法:
border 属性是以下各个边框属性的简写属性:
顺序:
border-width
border-style(必需)
border-color
即:
最终简写
border: 3px solid blue;
1.顺序为:上 右 下 左
2.中间用空格隔开
3.如果某一边没有设置,默认设置为对边颜色/样式
可以只为一个边指定所有单个边框属性:
border-left: 5px solid black;
7.3 背景样式
- background-color:背景色
- background-imge:url():背景图片
- background-repeal:设置背景图片是否重复
- background-position:top left :设置图片起始位置
7.4 浮动样式
- 设置浮动 float:left/right
- 清除浮动 clear:left/right/both
7.5 表格样式
-
border-collepase 将边框线进行折叠
-
vertical-align 垂直对齐
-
padding 内边距
-
border-bottom 水平分隔线
-
响应式表格 overflow-x:auto
"overflow-x:auto;"> ... table content ...
7.6 列表样式
- list-style-type:设置列表项标记
- list-style-image:自定义列表项前面的图形
8.css定位属性
- 绝对定位:position
- 当前这个标签针对父元素进行移动
- 相对定位:relative
- 当前元素针对之前位置进行移动
- 固定定位:fixed
- 固定在页面固定位置
三.JavaScript
-
注意:
1. javaScript是弱类型语言 2. 对大小写敏感 3. JavaScript 使用 Unicode 字符集。 -
使用方式
-
内部方式
-
外部方式
-
-
常用函数
1. 弹框 alert("提示内容") 2.向浏览器输出内容 document.write("内容") 3.浏览器控制台打印内容 console.log("内容"); 4.带有一个消息和文本输入框 window. pprompt("请输入动态密令") -
定义变量及对象
1. 定义变量(可以重复定义) var a = 10; var a = 20; 2. 定义对象 var obj = new Object(); 3. 定义函数 function functionName(parameters) { 要执行的代码 } 4.查看数据类型 typeof(变量名) -
数据类型
1. number(数值类型):整数和小数 2. boolean:布尔类型 1:true 0:false 3. String:字符和字符串 4. object:对象 5. undefined:未定义类型 -
流程控制语句
1. 选择结构 if()中的数据类型可以自动转换,switch语句需要手动转换,String转换number:var res = pareInt(num) if(){ }else{ } if(){ }if else{ }else{ } switch(){ } 针对数组以及对象的属性进行遍历 for(var 变量名in 数组对象或对象名){} -
运算符
+,- ,*, /,&&,||
3.1javaScript 命名规范
1.项目命名
全部采用小写方式, 以下划线分隔。
示例:my_project_name
2.目录命名
参照项目命名规则;有复数结构时,要采用复数命名法。
示例:scripts, styles, images, data_models
3.JS文件命名
1.变量:必须采用小驼峰式命名法。
命名规范:前缀应当是名词。(函数的名字前缀为动词,以此区分变量和函数)
命名建议:尽量在变量名字中体现所属类型,如:length、count等表示数字类型;而包含name、title表示为字符串类型。
2.常量:必须采用全大写的命名,且单词以_分割,常量通常用于ajax请求url,和一些不会改变的数据
命名规范:使用大些字母和下划线来组合命名,下划线用以分割单词
3.函数:小驼峰式命名法
命名规范:前缀应当为动词
命名建议:可使用常见动词约定
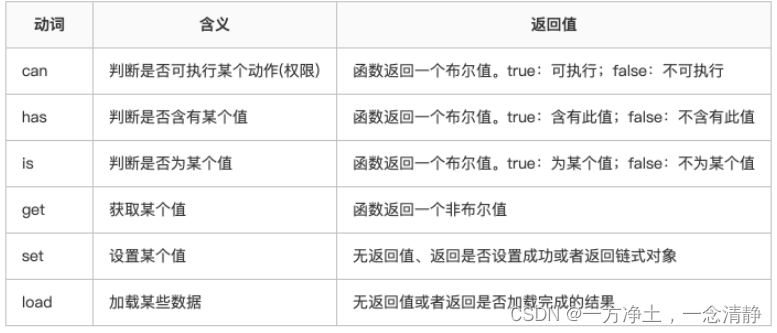
例子:
4.类 & 构造函数
命名方法:大驼峰式命名法,首字母大写。
命名规范:前缀为名称。
5.类的成员
公共属性和方法:跟变量和函数的命名一样
私有属性和方法:前缀为_(下划线),后面跟公共属性和方法一样的命名方式
6.注释规范
说明:行内注释两个斜杆开始,行尾结束
语法:code //这个是行内注释
使用方式://与代码之间一个空格 与 注释文字之间一个空格
命名建议:
// 用来显示一个解释的评论
// -> 用来显示表达式的结果
// > 用来显示console的输出结果
多行注释:/**/
函数(方法)注释:
说明:函数(方法)注释也是多行注释的一种,但是包含了特殊的注释要求:
1.不要保存this的引用,使用Function#bind
2.给函数命名,这在做堆栈轨迹时很有帮助。
3.如果你的文件到处一个类,你的文件名应该和类名完全相同。
4.模块
模块应该以 ! 开始。这样确保了当一个不好的模块忘记包含最后的分号时,在合并代码到生产环境后不会产生错误。详细说明文件应该以驼峰式命名,并放在同名的文件夹里,且与导出的名字一致增加一个名为 noConflict() 的方法来设置导出的模块为前一个版本并返回它。永远在模块顶部声明 ‘use strict’;。
5.构造函数
给对象原型分配方法,而不是使用一个新对象覆盖原型。覆盖原型将导致继承出现问题:重设原型将覆盖原有原型!方法可以返回 this 来实现方法链式使用.