爬虫项目十一:用Python爬下微博博主所有视频、所有微博数据、获取评论数据
文章目录
- 前言
- 一、微博数据
-
- 1.分析页面
- 2.分析url
- 3.解析数据
- 4.实现翻页
- 二、爬取视频
-
- 1.加载数据
- 2.获取视频详情url
- 3.获取视频url
- 4.下载视频
- 三、评论数据
前言
用Python爬下微博博主的所有微博数据,下载所有视频,爬下单个微博的评论数据,以papi酱为例
提示:以下是本篇文章正文内容,下面案例可供参考
一、微博数据
用python爬下papi酱的所有原创微博数据,有标题、点赞数、评论数、转发数
1.分析页面
我们打开页面观察页面,向下滑动可以发现有部分数据属于动态加载
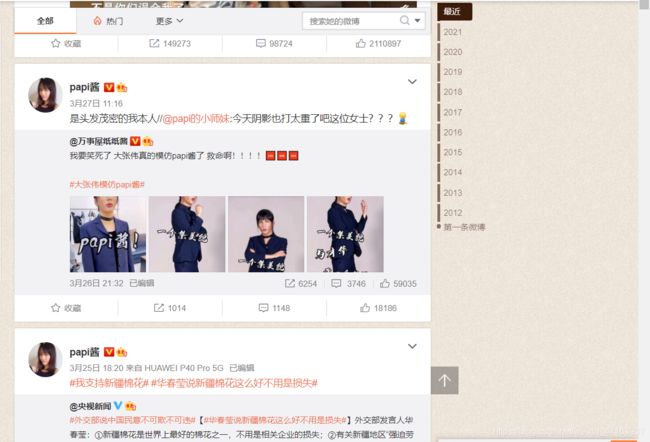
我尝试利用requests单纯的访问页面并且保存到本地html文件,发现一条数据都没有

所以对于爬取微博数据将会用selenium爬取
2.分析url
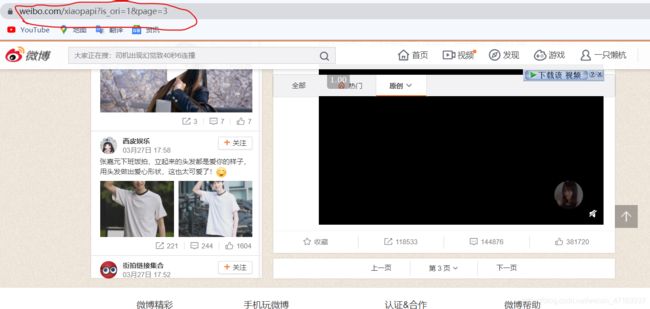
我们复制出前三页的url,观察一下
第一页:https://weibo.com/xiaopapi?profile_ftype=1&is_ori=1#_0
第二页:https://weibo.com/xiaopapi?is_search=0&visible=0&is_ori=1&is_tag=0&profile_ftype=1&page=2#feedtop
第三页:https://weibo.com/xiaopapi?is_search=0&visible=0&is_ori=1&is_tag=0&profile_ftype=1&page=3#feedtop
我们尝试去除一些参数看看能不能正常的访问页面,最后 经过我的测试,精简后的url,其中is_ori表示的就是显示原创微博,page就是页数
https://weibo.com/xiaopapi?is_ori=1&page=3
3.解析数据
我们明白了数据属于动态加载,找到了url的规律,现在我们来解析数据,右键检查元素,我们看到数据都在div中,其中有一点要注意,就是第一个div和第最后一个div是不表示数据的,所以再解析数据需要剔除
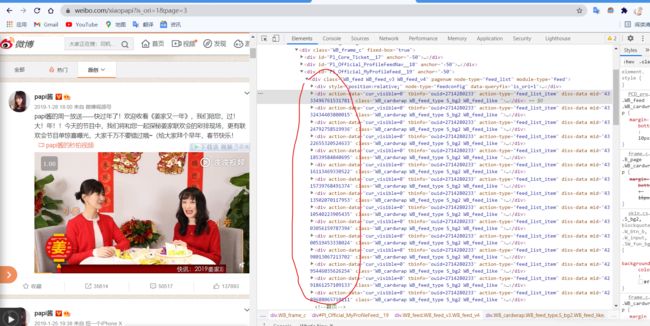
实例代码如下:
def Parser_Home_page_Data(self):
html=etree.HTML(self.bro.page_source)
div_list=html.xpath('//div/div[@module-type="feed"]/div')[1:-1]
for div in div_list:
dic={}
try:
dic["author"]=div.xpath('.//div[@class="WB_detail"]/div[@class="WB_info"]/a[1]/text()')[0]
except:
dic["author"]=""
try:
dic["icon_member"]=div.xpath('.//div[@class="WB_detail"]/div[@class="WB_info"]/a[last()]/em/@class')[0]
except:
dic["icon_member"]=""
try:
dic["title"]="".join(div.xpath('.//div[@class="WB_detail"]/div[@node-type="feed_list_content"]//text()')).replace("\n","").replace(" ","").replace("\u200b","")
except:
dic["title"]=""
try:
dic["forward_num"]=div.xpath('.//div[@class="WB_handle"]/ul[1]/li[2]//span[@class="line S_line1"]/span[1]/em[last()]/text()')[0]
except:
dic["forward_num"]=""
try:
dic["comment_num"]=div.xpath('.//div[@class="WB_handle"]/ul[1]/li[3]//span[@class="line S_line1"]/span[1]/em[last()]/text()')[0]
except:
dic["comment_num"]=""
try:
dic["like_num"]=div.xpath('.//div[@class="WB_handle"]/ul[1]/li[4]//span[@class="line S_line1"]/span[1]/em[last()]/text()')[0]
except:
dic["like_num"]=""
try:
dic["equipment"]=div.xpath('.//div[@class="WB_detail"]/div[@class="WB_from S_txt2"]/a[last()]/text()')[0]
except:
dic["equipment"]=""
try:
dic["time"]=div.xpath('.//div[@class="WB_detail"]/div[@class="WB_from S_txt2"]/a[1]/text()')[0]
except:
dic["time"]=""
在我们解析数据之前我们需要先将数据加载出来,即selenium模拟向下滑动
for i in range(3):
sleep(2)
self.bro.execute_script('window.scrollTo(0, document.body.scrollHeight)') # 向下滑动一屏
sleep(7)
self.Parser_Home_page_Data()
4.实现翻页
我们根据上面的操作就可以获取一页的数据,现在我们来实现翻页,分析url时我们就已经知道了规律,page,现在我们就可以根据这一特点实现翻页
实例代码如下:
def Get_Homepage_Data(self):
start_page=input("请输入起始页数:")
end_page=input("请输入结束页数:")
for i in range(int(start_page),int(end_page)+1):
url="https://weibo.com/xiaopapi?is_ori=1&page=%d"%(int(i))
self.bro.get(url)
sleep(3)
for i in range(3):
sleep(2)
self.bro.execute_script('window.scrollTo(0, document.body.scrollHeight)') # 向下滑动一屏
sleep(7)
self.Parser_Home_page_Data()
self.bro.quit()
最后我考虑到大家自身需求,所以再利用input实现输入用户昵称采集数据,我们来看一下url
修改前:https://weibo.com/昵称?is_ori=1&page=页数
修改后:
nickname=input("请输入用户昵称:")
start_page=input("请输入起始页数:")
end_page=input("请输入结束页数:")
url="https://weibo.com/%s?is_ori=1&page=%d"%(nickname,int(i))
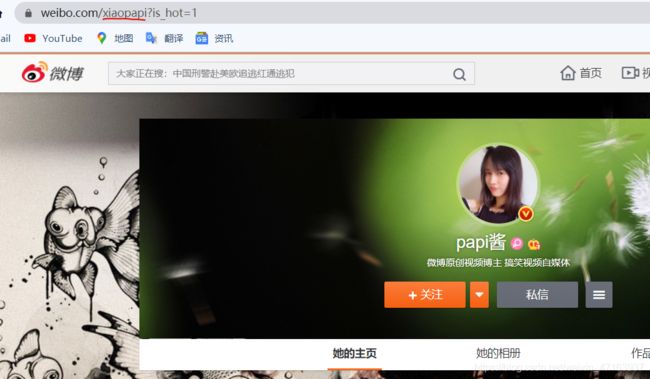
这个用户昵称改怎么获取的,我以papi酱为例,打开微博papi酱首页,看url,划住的地方到?截至就是他的昵称
现在我们看一下效果

二、爬取视频
现在我们来爬取博主的所有视频数据,我以papi酱为例,打开他的相册视频,向下滑动,发现url没有变化,数据属于动态加载,所以依旧使用selenium来模拟滑动
现在我们来找一下视频url在哪,找到他我们利用requests保存二进制数据就把他给下载下来了,我们点击一个视频右键检查元素,就可以找到视频url
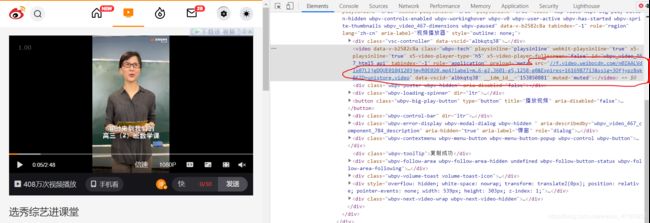
现在我们思路是,通过selenium模拟滑动加载出全部数据之后定位每一个视频,拿到每个视频的详情url,视频详情页就是上图页,根据视频详情url获取视频url,把全部的url存储,最后二进制保存为视频
1.加载数据
现在我们来来想怎么把他的数据全部加载出来,我们找到向下滑动找到最后一个视频,复制他的标题,写一个while循环当最后一个标题的内容出现在page_source中就停止循环否则便一直向下滑动
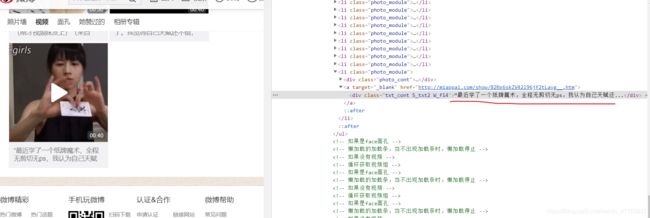
注意此时需要登录微博,才能加载出数据,否则不能加载出完整数据,我这里是直接手动的点击登录、扫码登录
实例代码如下:
def Laod_Video_Data(self):
self.bro.get("https://weibo.com/p/1004062714280233/photos?type=video#place")
print("-"*30+"请点击登录按钮登录账号"+"-"*30)
sleep(20)
num=0
while True:
if "最近学了一个纸牌魔术,全程无剪切无ps,我认为自己天赋" in self.bro.page_source:
break
else:
sleep(0.5)
self.bro.execute_script('window.scrollTo(0, document.body.scrollHeight)') # 向下滑动一屏
num=num+1
print("-"*30+"共滑动%d次"%(int(num))+"-"*30)
2.获取视频详情url
加载出完整数据数据之后,我们定位每个视频元素,获取视频详情url
右键检查元素,可以看到数据都在li标签中

def Get_Video_Detail(self):
video_detail=[]
li_list = self.bro.find_elements_by_xpath('//div[@class="PCD_photo_album_v2"]/ul[1]/li')
for li in li_list:
try:
url=li.find_element_by_xpath('.//a[@target="_blank"]').get_attribute("href")
video_detail.append(url)
except:
pass
return video_detail
3.获取视频url
我们在获取视频url时,可能会遇到这种情况,两种url,对应这两种情况应该有不同的操作
def Get_Video_Link(self,url):
if "show" in url:
self.bro.get(url)
try:
name=self.bro.find_element_by_xpath('//div[@class="Detail_wrap_IZQWz"]/div[1]').text
url=self.bro.find_element_by_xpath('//video[@class="wbpv-tech"]').get_attribute('src') #获取视频url
self.names.append(name)
self.urls.append(url)
except:
pass
if "miaopai" in url:
self.bro.get(url)
try:
self.bro.find_element_by_xpath('//*[@id="app"]/div/header/div[2]/div/div/div[1]/div[2]/img[1]').click()
name=self.bro.find_element_by_xpath('//div[@class="title_wrapper"]/p[1]').text
url=self.bro.find_element_by_xpath('//video[@controls="controls"]').get_attribute('src')
self.names.append(name)
self.urls.append(url)
except:
pass
4.下载视频
def Dowload_Video(self,url,name):
content=requests.get(url,headers=self.head).content
with open("./video/%s.mp4"%(name),"wb") as f:
f.write(content)
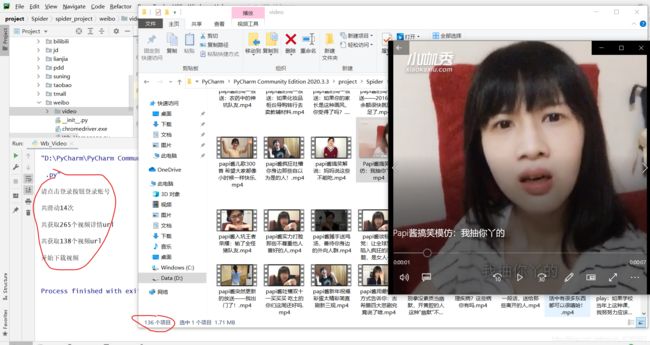
最后,看一下效果
三、评论数据
对于评论数据的抓取,我没有什么好的办法,找不到接口 只能用selenium了,仅供参考,如果那你有好的办法,欢迎在底下评论区留言
我们打开页面查看数据,发现微博评论数据是通过点击“展开更多”实现加载数据,我们需要利用selenium模拟点击这个按钮,就可以加载出更多的数据
我以点击三次展开更多按钮为例
def Load_Comment_Data(self):
self.bro.get("https://weibo.com/2714280233/I41GZdKsp?filter=hot&root_comment_id=0&type=comment")
while True:
try:
self.bro.find_element_by_xpath('//a[@action-type="click_more_comment"]')
break
except:
self.bro.execute_script('window.scrollTo(0, document.body.scrollHeight)') # 向下滑动一屏
for i in range(3):
sleep(0.5)
self.bro.find_element_by_xpath('//a[@action-type="click_more_comment"]').click()
加载完成数据就是就开始解析数据,看图我们可以知道数据都在div标签中
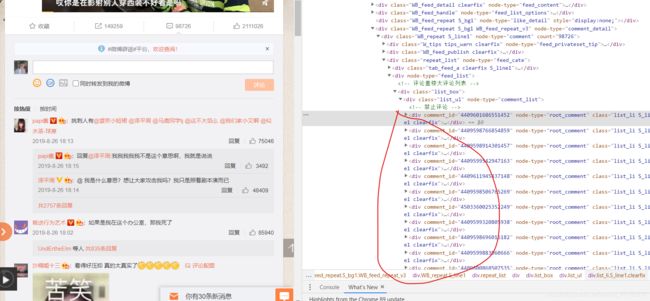
实例代码如下:
def Parser_Comment_Data(self):
html=etree.HTML(self.bro.page_source)
div_list=html.xpath('//div[@class="list_box"]/div[1]/div')
for div in div_list:
dic={}
try:
dic["name"]=div.xpath('./div[2]/div[1]/a[1]/text()')[0]
except:
dic["name"]=""
try:
dic["icon_member"]=div.xpath('./div[2]/div[1]/a[3]/em/@class')[0]
except:
dic["icon_member"]=""
try:
dic["comment"]="".join(div.xpath('./div[2]/div[1]//text()')).replace(dic["name"]+":","").replace(" ","").replace("\n","")
except:
dic["comment"]=""
try:
dic["time"]=div.xpath('./div[2]/div[3]/div[2]/text()')[0]
except:
dic["time"]=""
with open(".//comment.csv", "a+", encoding="utf-8") as f:
writer = csv.DictWriter(f, dic.keys())
writer.writerow(dic)
到这里总算是结束了,完整代码 在公众号“阿虚学Python”中回复“微博”获取,评论代码写的不好,抛砖引玉

谢谢大家的观看,如果觉得这篇文章不错就点个赞吧
转载请标明出处