从字符串模式匹配到有穷自动机
前言
字符串问题往往具有复杂的条件判断和特殊情况,可谓是面向用例编程的典范。
有穷自动机【DFA】正是针对这类问题的好手。
据说,字符串正则匹配的底层就是使用的DFA实现。
今天,让我们从正则匹配开始,推导一个简单的DFA实现。
总纲
直接切题,给出网上说的字符串DFA的实现步骤:
1)根据字符串的特征,构造模式匹配串;
2)根据模式匹配串提炼DFA状态转化图;
3)根据状态转化图编写字典,总结状态转换关系,在某个时刻无法得到下个有效状态时匹配失败;直到一个合法出站点时匹配成功。
例子: 表示数值的字符串
https://leetcode-cn.com/problems/biao-shi-shu-zhi-de-zi-fu-chuan-lcof/submissions/

其实,这里还有一些用例没说到,比如".3" “3.” “3.e1" " “+.3e1""也都合法。
1. 书写模式匹配串
简单正则规则描述:
- 三种括号:
- []:表示一个词典,其中有多个字符,[]表示对[]中的字符匹配任意一个;【只能书写字符,若需要字符串需要借助于()】
- {}: 表示前面一个字符出现的次数,使用
,隔开,,逗号左边是下界,右边是上界,没有则视为任意;若只有一个数字,表示刚好这个数量;- (): 表示或的关系,多个字符串使用|隔开
例子:匹配1个或者2个abc或者ee或者bb: (abc|[eb]{2}){1,2}- 三类统配符:
- ?:表示0个或者1个前面那个字符(块)
- * :表示0个或者多个前面那个字符(块)
- + : 表示1个或者多个前面那个字符(块)
- 两个边界符
- ^:表示开始
- $:表示结束
- \d表示数字【1~9】,在java正则串中,涉及转义符
\必须写成\\, 所以是\\d
于是,根据前面的题设描述,我们可以得到regex串:
String regex = "^[ ]*[+-]?(\\d+|\\d+\\.\\d*|\\d*\\.\\d+)([eE][+-]?\\d+)?[ ]*$";
然后,直接使用str.matches(regex)就能获取是否匹配了。
另外一种获取是否匹配的方式是通过Pattern和Matcher对象
Pattern pattern = Pattern.of(regex);
Matcher matcher = pattern.matcher(str);
return matches.matches();
逐一分析这个奇怪的regex是怎么得到的:
1. 因为字符串边界是明确的,所以二话不说用^和$包裹起来;=> ^$
2. 开头和结尾都能够是0到多个空格,则可用[ ]*来表示;=> ^[ ]*[ ]*$
3. 一个可有可无的正号或者负号,很简单: [+-]? => ^[ ]*[+-]?[ ]*$
4. 最难的地方:一个小数或者整数
1. 整数
1. 很好写,\\d+ 【这题没有特殊要求,001,000这种都算是合法的】;
2. 小数
小数有三种形式:x.y, .y, x. 都是合法的,其中,第一种只是后两种的特殊情况,可以合并到后两种中
1. 第二种:\\d*\\.\\d+
2. 第三种:\\d+\\.\\d*
只要这两种情况*不取0,那么就符合第一种
3. 我们把整数和小数的两种情况使用或连接起来,就是第3部分; => (\\d+|\\d+\\.\\d*|\\d*\\.\\d+)
=> ^[ ]*[+-]?(\\d+|\\d+\\.\\d*|\\d*\\.\\d+)[ ]*$
4. 可有可无的对数部分
1. 既然是“可有可无”,二话不说使用()?包起来
2. 假设是“有”的话,那么e或者E必须有: [e|E]
3. 又是一个可有可无的正负号,和前面一样: [+-]?
4. 必须有的整数,和前面一样:\\d+
填充进“可有可无”结构 => ([e|E][+-]?\\d+)?
综合起来,就是:^[ ]*[+-]?(\\d+|\\d+\\.\\d*|\\d*\\.\\d+)([eE][+-]?\\d+)?[ ]*$
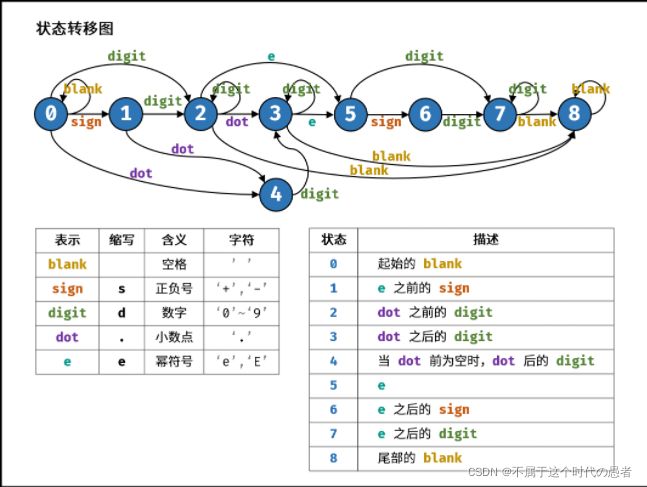
2. 分析有穷状态机的所有状态
这个我也没系统学过,只能参考别人+按照感觉来。。。
我的直觉是:每个同等性质的字符块一种状态
再拿出之前的模式串:
^[ ]*[+-]?(\\d+|\\d+\\.\\d*|\\d*\\.\\d+)([eE][+-]?\\d+)?[ ]*$
从左到右的元素块有:
-
开头的空格;【0】
-
整数或者小数的正负号;【1】
-
接下来是三个或结构的分支,为了简化DFA,我们可以总结其中的公共部分:(小数点前或者是非小数的)整数【2】
-
小数点【3】
-
小数点后,对数部分之前的整数【4】
-
对数符号【5】
-
对数的正负号【6】
-
对数的整数部分【7】
-
结尾的空格【8】
3. 分析有穷状态机的状态转移【重点】
合法的起始状态:0,1,2,3
合法的结束状态:2, 3, 4, 7, 8
【起始和结束状态都有2,3。
2没有什么问题,3是一个bug,可以直接通过一个去掉" . "的特殊情况(实在很不优雅。。。)】
分析各个状态可以转化什么状态,以及转化的条件:
-
状态0:
- 0:继续出现空格
- 1:出现正负号
- 2:出现数字
- 3:出现小数点
-
状态1:
-
2:出现数字
-
3:出现小数点
-
-
状态2:
- 2:继续出现数字
- 3:出现小数点
- 5: 出现对数符号
- 8:出现空格
-
状态3:
- 4:出现数字
- 5: 出现对数符号
- 8:出现空格
-
状态4:
- 4: 继续出现数字
- 5: 出现对数符号
- 8: 出现空格
-
状态5:
- 6:出现正负号
- 7:出现数字
-
状态6:
- 7:出现数字
-
状态7:
- 7:继续出现数字
- 8:出现空格
-
状态8:
- 8:继续出现空格
把这些转态描绘为状态转换图就是:

4. 根据状态转换写代码
如何表示一个状态转化关系:使用Map数组
- 数组的下标表示状态i下的拥有的状态转化;
- Map的每个Entry表示一个状态转换关系【我们是处于x状态,接收到下个字符c,因此转化到y状态,因此,这种转化的Map就是Map
从k神那里抄来的一个优化点:
比如,表示数字的转化关系实在是太多了,有0~9这么多,我们可以直接用一个’d’表示所有的数字,Map就能简化很多;同样正负号用’s’, 对数符号用’e’
- Map的每个Entry表示一个状态转换关系【我们是处于x状态,接收到下个字符c,因此转化到y状态,因此,这种转化的Map就是Map
从k神那里抄来的一个优化点:
比如,表示数字的转化关系实在是太多了,有0~9这么多,我们可以直接用一个’d’表示所有的数字,Map就能简化很多;同样正负号用’s’, 对数符号用’e’
然后在遍历字符时做一下转化就行了。
参考K神写的代码:
class Solution {
// @SuppressWarnings("uncheck")
public boolean isNumber(String s) {
String tmp = s.trim();
if (tmp.isEmpty() || ".".equals(tmp) || tmp.startsWith(".e") || tmp.startsWith(".E") || tmp.startsWith("-.") || tmp.startsWith("+.")) {
//排除掉只有.而缺少数字和各种符号组合的特殊情况,很不优雅的方式。。。
return false;
}
Map[] states = {
new HashMap<>(){{put(' ', 0); put('s', 1); put('d', 2); put('.', 3);}},
new HashMap<>(){{put('d', 2); put('.', 3);}},
new HashMap<>(){{put('d', 2); put('.', 3); put('e', 5); put(' ', 8);}},
new HashMap<>(){{put('d', 4); put('e', 5); put(' ', 8);}},
new HashMap<>(){{put('d', 4); put('e', 5); put(' ', 8);}},
new HashMap<>(){{put('s', 6); put('d', 7);}},
new HashMap<>(){{put('d', 7);}},
new HashMap<>(){{put('d', 7); put(' ', 8);}},
new HashMap<>(){{put(' ', 8);}}
};
char[] cs = s.toCharArray();
//记录经过转化后的字符
char cur;
//初始状态设为0 【为什么可以设为0? 我们看0状态下的模式就知道了,[ ]*表示0个或者多个空格
//我们设置刚开始为空串,是符合0状态的定义的,并且也能考虑到之后的所有状态转化。】
int p = 0;
for (char c: cs) {
if (c >= '0' && c <= '9') {
cur = 'd';
} else if (c == '+' || c == '-') {
cur = 's';
} else if (c == 'E' || c == 'e') {
cur = 'e';
} else if (c == ' ' || c == '.') {
cur = c;
} else {
//没有定义的特殊情况,直接算是错了
cur = '?';
}
if (!states[p].containsKey(cur)) {
//当前状态下,这并不是一个合法的转换
return false;
}
p = (int)states[p].get(cur);
}
//符合合法结束条件中的一种
return p == 2 || p == 3 || p == 4 || p == 7 || p == 8;
}
}
K神的状态4定义比我完善,可以参考他的,也就不需要刚开头那样的“面向用例编程“了:
总结
- 字符串问题确实很恶心,基本上思路很清晰,但是总是被各种特殊用例击倒,直接变成“面向用例编程”;
- 即使很恶心,在付出一条红之后还是可以求解的,并且除了心态也没什么损失;
- 不要用DFA! 不要用DFA! 不要用DFA!
要说为什么,搞了这么多步骤耍三四题的时间都有了,实在划不来,而且照样会被各种特殊用例击倒。。。

不然你以为我刚开头的if怎么来的。。。
算辣,当初觉得这样的解法很装比,算是满足年少时的一个未完成的心愿顺带巩固一下正则表达式吧。
加上这篇博客,大约弄了3个小时,不给个赞犒劳一下?