音视频入门基础理论知识
文章目录
- 前言
- 一、视频
-
- 1、视频的概念
- 2、常见的视频格式
- 3、视频帧
- 4、帧率
- 5、色彩空间
- 6、采用 YUV 的优势
- 7、RGB 和 YUV 的换算
- 二、音频
-
- 1、音频的概念
- 2、采样率和采样位数
-
- ①、采样率
- ②、采样位数
- 3、音频编码
- 4、声道数
- 5、码率
- 6、音频格式
- 三、编码
-
- 1、为什么要编码
- 2、视频编码
-
- ①、H.26X 系列
- ②、MPEG 系列
- ③、其他系列:
- 3、音频编码
-
- ①、ADIF
- ②、ADTS
- 4、硬解码和软解码
-
- ①、软解码
- ②、硬解码
- 5、音视频容器
前言
本节介绍了音视频的基本原理知识以及编码相关概念。
一、视频
1、视频的概念
视频(Video) 泛指将一系列静态影像以电信号的方式加以捕捉、 纪录、 处理、 储存、 传送与重现的各种技术。
连续的图像变化每秒超过 24 帧(frame,fps) 画面以上时, 根据视觉暂留原理, 人眼无法辨别单幅的静态画面; 看上去是平滑连续的视觉效果, 这样连续的画面叫做视频。
2、常见的视频格式
avi,mov,mp4,wmv,flv,mkv…
3、视频帧
帧 , 是视频的一个基本概念, 表示一张画面, 如翻页动画书中的一页, 就是一帧。一个视频就是由许许多多帧组成的。
4、帧率
帧率, 即单位时间内帧的数量, 单位为: 帧/秒 或 fps(frames per second) 。 如动画书中, 一秒内包含多少张图片,图片越多, 画面越顺滑, 过渡越自然。
帧率的一般以下几个典型值:
- 24/25 fps: 1 秒 24/25 帧, 一般的电影帧率;
- 30/60 fps: 1 秒 30/60 帧, 游戏的帧率, 30 帧可以接受, 60 帧会感觉更加流畅逼真。
85 fps 以上人眼基本无法察觉出来了, 所以更高的帧率在视频里没有太大意义。
5、色彩空间
这里我们只讲常用到的两种色彩空间。
- RGB: RGB 的颜色模式应该是我们最熟悉的一种, 在现在的电子设备中应用广泛。通过 R G B 三种基础色, 可以混合出所有的颜色;
- YUV: 这里着重讲一下 YUV, 这种色彩空间并不是我们熟悉的。 这是一种亮度与色度分离的色彩格式。
早期的电视都是黑白的, 即只有亮度值, 即 Y。 有了彩色电视以后, 加入了 UV 两种色度, 形成现在的 YUV, 也叫 YCbCr。
- Y: 亮度, 就是灰度值。 除了表示亮度信号外, 还含有较多的绿色通道量;
- U: 蓝色通道与亮度的 差值;
- V: 红色通道与亮度的差值。
问:为什么没有绿色通道与亮度的差值呢?
答:三基色原理是根据它们的比例显示不同的颜色,假如它们的总和为 1,那么有了蓝色和红色的比例值,就无需记录绿色了,因为 1 -(红色+绿色比例)= 绿色比例;因此我们用尽少的值来存储这些,存下来的值就是真正的一个像素点的值。
举个例子:
下图是正常的一张图像

下图是 Y,即亮度的值

下图是 U,即蓝色与亮度的差值

下图是 V,即红色与亮度的差值

6、采用 YUV 的优势
人眼对亮度敏感, 对色度不敏感, 因此减少部分 UV 的数据量, 人眼却无法感知出来, 这样可以通过压缩 UV 的分辨率, 在不影响观感的前提下, 减小视频的体积。
7、RGB 和 YUV 的换算
- Y = 0.299R + 0.587G + 0.114B
- U = -0.147R - 0.289G + 0.436B
- V = 0.615R - 0.515G - 0.100B
- R = Y + 1.14V
- G = Y - 0.39U - 0.58V
- B = Y + 2.03U
二、音频
1、音频的概念
音频数据的承载方式最常用的是脉冲编码调制, 即 PCM。在自然界中, 声音是连续不断的, 是一种模拟信号, 那怎样才能把声音保存下来呢?那就是把声音数字化, 即转换为数字信号。
我们知道声音是一种波, 有自己的振幅和频率, 那么要保存声音, 就要保存声音在各个时间点上的振幅。
而数字信号并不能连续保存所有时间点的振幅, 事实上, 并不需要保存连续的信号,就可以还原到人耳可接受的声音。
根据奈奎斯特采样定理: 为了不失真地恢复模拟信号, 采样频率应该不小于模拟信号频谱中最高频率的 2 倍。
根据以上分析, PCM 的采集步骤分为以下步骤:模拟信号 -> 采样 -> 量化 -> 编码 -> 数字信号
2、采样率和采样位数
①、采样率
采样率, 即采样的频率。
上面提到, 采样率要大于原声波频率的 2 倍, 人耳能听到的最高频率为 20kHz, 所以为了满足人耳的听觉要求, 采样率至少为 40kHz, 通常为 44.1kHz, 更高的通常为 48kHz。
注意: 人耳听觉频率范围[20Hz, 20KHz]
②、采样位数
涉及到上面提到的振幅量化。 波形振幅在模拟信号上也是连续的样本值, 而在数字信号中, 信号一般是不连续的, 所以模拟信号量化以后, 只能取一个近似的整数值, 为了记录这些振幅值, 采样器会采用一个固定的位数来记录这些振幅值, 通常有 8 位、 16 位、 32 位。
注意: 位数越多, 记录的值越准确, 还原度越高。 但是占用的硬盘空间越大。
| 位数 | 最小值 | 最大值 |
|---|---|---|
| 8 | 0 | 255 |
| 16 | -32768 | 32767 |
| 32 | -2147483648 | 2147483647 |
3、音频编码
由于数字信号是由 0,1 组成的, 因此, 需要将幅度值转换为一系列 0 和 1 进行存储, 也就是编码, 最后得到的数据就是数字信号: 一串 0 和 1 组成的数据。
整个过程如下:
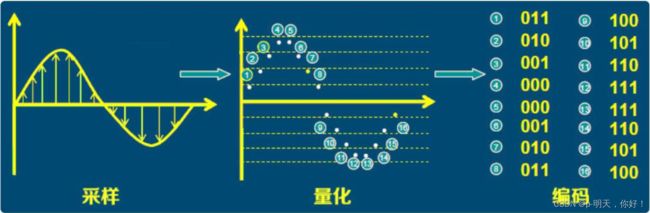
4、声道数
声道数, 是指支持能不同发声(注意是不同声音) 的音响的个数。
- 单声道:1 个声道
- 双声道:2 个声道
- 立体声道:默认为 2 个声道
- 立体声道(4 声道):4 个声道
5、码率
码率, 是指一个数据流中每秒钟能通过的信息量, 单位 bps(bit per second) 。
码率 = 采样率 * 采样位数 * 声道数
6、音频格式
常见的音频格式有: CD 格式、 WAVE(*.WAV) 、 AIFF、 MP3、 MIDI、 AAC、 WMA、OggVorbis。
三、编码
1、为什么要编码
这里的编码和上面音频中提到的编码不是同一个概念, 而是指压缩编码。
音视频中,其实包含了大量 0 和 1 的重复数据,因此可以通过一定的算法来压缩这些 0 和 1 的数据。
特别在视频中,由于画面是逐渐过渡的,因此整个视频中,包含了大量画面/像素的重复,这正好提供了非常大的压缩空间。因此, 编码可以大大减小音视频数据的大小, 让音视频更容易存储和传送。
未经编码的原始音视频, 数据量到底有多大?
以一个分辨率 1920×1280, 帧率 30 的视频为例:
共:1920×1280=2,073,600(Pixels 像素) ,每个像素点是 24bit;
也就是:每幅图片 2073600×24=49766400 bit,8 bit(位) =1 byte(字节);
所以:49766400bit=6220800byte ≈ 6.22MB。
这是一幅 1920×1280 图片的原始大小(6.22MB),再乘以帧率 30。
也就是说:每秒视频的大小是 186.6MB,每分钟大约是 11GB, 一部 90 分钟的电影,约是 1000GB。 。 。
2、视频编码
视频编码格式有很多,比如 H26x 系列和 MPEG 系列的编码。
- H26x(1/2/3/4/5) 系列由 ITU(International Telecommunication Union) 国际电讯联盟主导
- MPEG(1/2/3/4) 系列由 MPEG(Moving Picture Experts Group, ISO 旗下的组织)主导
现在主流的编码格式 H264, 当然还有下一代更先进的压缩编码标准 H265。
所谓视频编码方式就是指能够对数字视频进行压缩或者解压缩(视频解码)的程序或者设备。 通常这种压缩属于有损数据压缩。 也可以指通过过特定的压缩技术,将某个视频格式转换成另一种视频格式。
①、H.26X 系列
- H.261:主要在老的视频会议和视频电话产品中使用。
- H.263:主要用在视频会议、 视频电话和网络视频上。
- H.264: H.264/MPEG-4 第十部分,或称 AVC(Advanced Video Coding,高级视频编码),是一种视频压缩标准,一种被广泛使用的高精度视频的录制、压缩和发布格式。
- H.265:高效率视频编码(High Efficiency Video Coding, 简称 HEVC)是一种视频压缩标准,H.264/MPEG-4 AVC 的继任者。HEVC 被认为不仅提升图像质量,同时也能达到 H.264/MPEG-4 AVC 两倍之压缩率(等同于同样画面质量下比特率减少了50%),可支持 4K 分辨率甚至到超高画质电视,最高分辨率可达到 8192×4320(8K分辨率),这是目前发展的趋势。 直至 2013 年,Potplayer 添加了对于 H.265 视频的解码,尚未有大众化编码软件出现。
②、MPEG 系列
- MPEG-1 第二部分(MPEG-1 第二部分主要使用在 VCD 上,有些在线视频也使用这种格式。该编解码器的质量大致上和原有的 VHS 录像带相当。)
- MPEG-2 第二部分(MPEG-2 第二部分等同于 H.262,使用在 DVD、SVCD 和大多数数字视频广播系统和有线分布系统(cable distribution systems)中。)
- MPEG-4 第二部分(MPEG-4 第二部分标准可以使用在网络传输、广播和媒体存储上。 比起 MPEG-2 和第一版的 H.263,它的压缩性能有所提高。)
- MPEG-4 第十部分(MPEG-4 第十部分技术上和 ITU-TH.264 是相同的标准,有时候也被叫做“AVC”) 最后这两个编码组织合作,诞生了 H.264/AVC 标准。 ITU-T 给这个标准命名为 H.264, 而 ISO/IEC 称它为 MPEG-4 高级视频编码(Advanced VideoCoding, AVC) 。
③、其他系列:
AMV · AVS · Bink · CineForm · Cinepak · Dirac · DV · Indeo · Video · Pixlet · RealVideo ·RTVideo · SheerVideo · Smacker · Sorenson Video · Theora · VC-1 · VP3 · VP6 · VP7 · VP8 · VP9 · WMV。 因为以上编码方式不常用,不再介绍。
3、音频编码
和视频编码一样,音频也有许多的编码格式,如: WAV、 MP3、 WMA、 APE、 FLAC 等等。这里以 AAC 格式为例,直观的了解音频压缩格式。
AAC 是新一代的音频有损压缩技术,一种高压缩比的音频压缩算法。在 MP4 视频中的音频数据,大多数时候都是采用 AAC 压缩格式。
AAC 格式主要分为两种: ADIF、 ADTS。
①、ADIF
ADIF: Audio Data Interchange Format。 音频数据交换格式。
这种格式的特征是可以确定的找到这个音频数据的开始, 不需进行在音频数据流中间开始的解码, 即它的解码必须在明确定义的开始处进行。 这种格式常用在磁盘文件中。
ADIF 只有一个统一的头, 所以必须得到所有的数据后解码。
ADIF 数据格式:header | raw_data
②、ADTS
这种格式的特征是它是一个有同步字的比特流, 解码可以在这个流中任何位置开始。它的特征类似于 mp3 数据流格式。
ADTS 一帧 数据格式(中间部分,左右省略号为前后数据帧):

对比 ADIF 和 ADTS
ADTS 可以在任意帧解码,它每一帧都有头信息。
ADIF 只有一个统一的头,所以必须得到所有的数据后解码。
且这两种的 header 的格式也是不同的,目前一般编码后的都是 ADTS 格式的音频流。
4、硬解码和软解码
在手机或者 PC 上,都会有 CPU、GPU 或者解码器等硬件。通常,我们的计算都是在 CPU 上进行的,也就是我们软件的执行芯片,而 GPU 主要负责画面的显示(是一种硬件加速) 。
①、软解码
就是指利用 CPU 的计算能力来解码,通常如果 CPU 的能力不是很强的时候,一则解码速度会比较慢,二则手机可能出现发热现象。但是,由于使用统一的算法,兼容性会很好。
②、硬解码
指的是利用专门的解码芯片来加速解码。 通常硬解码的解码速度会快很多, 但是由于硬解码由各个厂家实现, 质量参差不齐, 非常容易出现兼容性问题。
5、音视频容器
前面我们介绍的各种音视频的编码格式,没有一种是我们平时使用到的视频格式,比如:mp4、rmvb、avi、mkv、mov…
这些我们熟悉的视频格式,其实是包裹了音视频编码数据的容器,用来把以特定编码标准编码的视频流和音频流混在一起, 成为一个文件。
例如: mp4 支持 H264、 H265 等视频编码和 AAC、 MP3 等音频编码。
mp4 是目前最流行的视频格式, 在移动端, 一般将视频封装为 mp4 格式。
我的qq:2442391036,欢迎交流!