PANAMA: 共享机器学习集群的网内聚合框架
随着深度学习训练规模的增长,在共享集群内同步训练数据的需求越来越多,怎样高效利用网络资源平衡各种负载的需求,也成了业界关注的课题。MIT的这篇论文提出了一种网内聚合框架,能够大幅降低并行数据作业的流量负载,从而优化各种类型流量的性能。原文: In-network Aggregation for Shared Machine Learning Clusters

摘要
我们提出了一种新的网内聚合框架PANAMA,用于在共享集群实现分布式机器学习(ML)训练,可服务于各种工作负载。PANAMA包含两个关键组件:(1)定制的网内硬件加速器,可以在不影响精度的前提下支持线性浮点梯度聚合; 以及(2)轻量级负载均衡和拥塞控制协议,该协议利用ML数据并行作业的独特通信模式,使不同作业之间公平共享网络资源,同时保障长期作业的高吞吐率以及短期作业和其他时延敏感作业的低时延。我们在10 Gbps收发器和大规模模拟的基础上创建了基于FPGA的原型,从而评估PANAMA的可行性。模拟结果表明,PANAMA能够将大型工作的平均训练时间减少1.34倍。更重要的是,通过大幅降低大型数据并行作业在网络上的负载,非聚合流量(特别是对延迟敏感的短期流量)也能获得明显的好处,其99%的完成时间提升了4.5倍。
1. 简介
对精确机器学习(ML)模型不断增长的需求导致了深度神经网络(DNN)数据集和模型规模的稳步增长。因此,训练现代DNN模型远远超出了单个设备的能力,今天训练大型模型需要数千个加速器(Huang et al.,2018; Lepikhin et al.,2020; Moritz et al.,2018; Sun et al.,2019)。
一些学术机构和公司最近提倡使用网内聚合(Costa et al.,2012; Mai et al,2014),以提高分布式数据并行ML训练工作负载的性能(Bloch, 2019; Klenk et al.,2020; Li et al.,2019; Sapio et al.,2021)。通过在网络交换机内部而不是在终端主机上聚合梯度,可以缓解数据并行训练的通信瓶颈,减少训练时间。
然而,现有建议侧重于相对简单的场景,将网内聚合限制在单个交换机(Lao et al.,2021; Sapio et al.,2021)、少量交换机(Li et al.,2019)或单个ML作业上。但在实践中,随着神经网络模型的普及和多样性的增长,为了减少成本和资源浪费,第一方和第三方训练工作负载都越来越多的向共享集群过渡(Abadi et al.,2016; Amazon, 2021; Azure, 2021; Google,2021; Jeon et al.,2019),跨越数百个机架并执行大量不同的ML作业。这些工作包括传统ML工作,如K-means聚类,以及最近的强化学习和深度学习等。从网络角度来看,这意味着有大量异构流,从几个KB到几十GB大小不等(Abadi et al.,2016; Azure, 2021; Google, 2021; Jeon et al.,2019),其中只有一小部分可能需要聚合。如果没有合适的机制来大规模有效共享网络资源,在更现实的情况下,网络内聚合的实际可行性就会变得令人怀疑,这一点在某些早期部署的情况下得到了证实: 例如,当在更大规模测试网络内聚合时,NVIDIA观察到由于拥塞造成吞吐量低于预期(Klenk et al.,2020)。
我们在本文中提出PANAMA(ProgrAmmable Network Architecture for ML Applications, ML应用程序可编程网络体系架构)来解决这一问题,这是一个为具有异构工作负载的共享环境量身定制的网络内聚合框架。PANAMA由两个主要部分组成。首先是一种全新设计的聚合硬件加速器,可以同时支持多个活跃的训练工作。现有的基于可配置匹配表(RMT, Reconfigurable Match Table)架构的可编程交换机(Bosshart et al.,2013),例如Tofino交换机(Intel,2018)可用于网内聚合(Lao et al.,2021; Sapio et al,2021),但缺乏浮点运算支持,并且流水线架构缺乏灵活性(Gebara et al.,2020),从而造成准确性和性能下降。相比之下,我们选择了一种串连模式(bump-in-the-wire) 方法,在这种方法中,网内加速器与交换机解耦。该设计的灵感来自于最近在云上部署的可编程网卡(NIC)(Firestone et al.,2018),在不牺牲训练精度并且不要求对交换机逻辑进行任何更改的情况下提供了最大的灵活性。我们的设计可以在线速(10-100 Gbps)下运行,并能够有效利用逻辑区域。
PANAMA的第二个组成部分是与轻量级拥塞控制协议相结合的负载均衡机制,允许在不同作业之间高效、公平的共享网络带宽。PANAMA将聚合流量分布在多个聚合树中,从而减少网络热点,提高网络性能。现有数据中心拥塞控制协议(Alizadeh et al.,2010; Kumar et al.,2020; Mittal et al.,2015; Zhu et al.,2015)不适合网内操作,因为需要假设服务器之间是点对点连接,而不是基于树的配置。相比之下,我们的新型拥塞控制协议利用了网内聚合的独特特性(和机会)来提高性能,同时确保加速器上有限的缓冲区空间被ML作业公平共享,而不会溢出。此外,我们的拥塞控制算法兼容现有数据中心使用的基于ECN的协议(Alizadeh et al.,2010; Zhu et al.,2015),从而能够与其他非网内聚合流量公平共享网络资源。
我们的工作揭示了以前没有注意到的网内聚合的好处,研究界怀疑网内聚合的实际价值,值得注意的是,梯度聚合只构成整个训练任务的一小部分,因此对整体训练时间的影响有限。我们认为,也许与直觉相反,网内聚合的真正动机与其说是为了提高训练工作本身的性能,不如说是为了减少数据并行梯度交换产生的通信量。将网络中的流量聚合在一起可以大幅降低网络使用量(单个数据并行作业在执行期间可以生成超过1 PB的数据),从而为其他流(包括非数据并行的ML作业和延迟敏感流)释放网络资源。
我们基于FPGA的原型演示了硬件加速器的可行性,并提供了广泛的模拟分析,以评估大规模的PANAMA负载均衡和拥塞控制的好处。结果表明,PANAMA缩短了99%时延敏感型任务的完成时间,提升幅度最高达4.5倍(平均为2倍),同时减少ML平均训练时间最高达1.34倍。
2. 网内聚合示例
最常见的分布式训练方法之一是数据并行训练,其中神经网络被复制到N个工作节点(或副本)上,每个工作节点处理一小部分训练数据(小批量)来计算其局部模型梯度。在每次迭代中,工作节点必须通过交换和聚合梯度来同步各自的模型,以确保收敛(Narayanan et al.,2019)。这个步骤被称为allreduce,可以使用参数服务器(Li et al., 2014)或Ring-AllReduce (Sergeev & Balso, 2018; Uber Eng., 2017)。
allreduce步骤对网络架构造成了很大的压力,因为在整个训练过程中,需要多次交换整组模型梯度。例如,对于有1000个工作节点的训练工作,需要1000次迭代才能达到目标精度的1 GB DNN模型,产生的总流量大约为2 PB,其中包括发送梯度,以及接收聚合值。最近的提议提倡使用网内聚合来提高ML训练工作负载的性能(Bloch, 2019; Klenk et al.,2020; Lao et al.,2021年; Li et al.,2019; Sapio et al., 2021)。直觉上,在allreduce步骤中减少网络上传输的数据量可以缩短通信时间,从而让训练更快。
然而,分析结果显示,网内聚合导致的整体训练时间改进只有1.01-1.8倍(Sapio et al., 2021中的表2)。这有两个原因。首先,计算时间占据了整体训练时间的很大一部分。因此,只有一小部分时间花在通信上,从而限制了可达到的最大收益。其次,即使通信时间包含了整个训练时间,与最先进的Ring-AllReduce策略相比,网内聚合理论上可以实现最大的改进是在大消息通信的情况下,通信时间减少2倍(Klenk et al.,2020)。
为了验证这一观察结果,我们使用第三代英伟达GPU(Pascal P100、Volta V100和最近推出的Ampere A100)来训练五个流行的图像分类模型。选择这些DNN模型是因为它们涵盖了广泛的规模和计算要求。我们使用TensorFlow框架和ImageNet数据集来训练这些模型,并在TensorFlow基准套件(TensorFlow, 2021)中指定了批量大小。
为了避免分布式训练框架或低效的网络栈造成的任何测量偏差,我们在单GPU节点上训练模型来测量每次迭代的计算时间,并将单次迭代中交换的梯度大小除以链路带宽来估计通信时间。为了在不同GPU之间保持一致,假设P100、V100和A100的链路带宽分别为10Gbps、40Gbps和100Gbps。
 图1. 单个网内聚合作业的预期加速受限于通信时间与总训练时间的比率。
图1. 单个网内聚合作业的预期加速受限于通信时间与总训练时间的比率。
图1a显示了不同DNN、GPU和网络带宽之间的通信时间与总训练时间(通信+计算)的比率。该图显示,用于通信的训练时间比例在0.11-0.70之间,随着网络速度的提高,这一比例也在降低。这表明网内聚合对数据并行作业的好处也在随着时间的推移而减少。图1b说明了这一点,它显示了网内聚合对具有100Gbps链接的A100 GPU的预期训练时间加速在1.06-1.28之间(而对具有10Gbps链接的P100来说是1.15-1.53)。事实上,我们假设网内聚合的最佳情况是梯度计算和通信之间没有重叠。这是非常保守的,因为现代分布式ML框架利用重叠来最小化通信对训练时间的影响,因此,我们预计减少通信的好处将不那么明显。
相反,在本文中,我们认为网内聚合的真正机会在于,通过减少注入网络的整体数据并行流量来提高共享集群中非数据并行作业的性能,从而为其他流量释放出网络带宽。如图2所示,共享的ML集群由一组异质流量组成,其传输速率从几KB到几百GB不等。图的左边部分(蓝条)显示了包含模型梯度的并行数据流的传输大小,我们称之为聚合流,以表明它们是网内聚合的良好候选者。图的右边(绿条)显示了不适合网内聚合的流量,即非聚合流,包括不需要任何聚合的流量,例如,(a)数据集传输和(b)由并行流水线(Huang et al.,2018; Narayanan et al.,2019)或并行模型(Shoeybi et al., 2020)产生的流量,以及需要聚合但网内聚合没有明显好处的短流,例如(c)由强化学习训练(RL)产生的流(Li et al.,2019; Moritz et al.,2018)和(d)更传统的ML作业,如k-means聚类(Rossi & Durut,2011)。
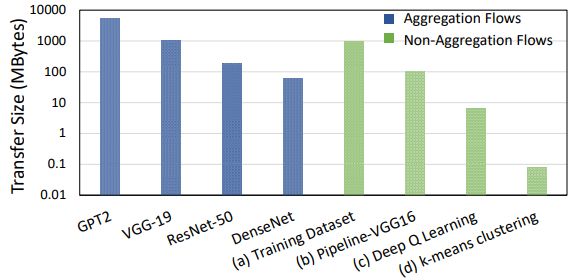 图2. 共享ML集群中的数据传输大小。
图2. 共享ML集群中的数据传输大小。
我们发现,虽然非聚合流不适合网内聚合,但可以间接的从网内聚合中受益。然而,现有的网内聚合解决方案并不是为在共享环境中运行而设计的。正如我们在第7节中所展示的,现在的数据中心解决方案只支持聚合和非聚合流的共享,但没有适当的负载均衡和拥塞控制机制来应对多租户环境。相比之下,PANAMA结合了对多个ML作业的原生硬件支持以及为网内聚合量身定制的拥塞控制协议,即使在大量聚合作业的情况下,也能接近非聚合流的理想性能,同时,减少聚合作业本身的训练时间。
3. PANAMA概述
本节将提供PANAMA的概要介绍,接下来在第4节和第5节中将详细介绍其关键组成部分。我们假设传统数据中心网络是类似于图3那样的多层CLOS拓扑结构(Al-Fares et al.,2008; Singh et al.,2015)。PANAMA集群中的每个交换机(PSwitch)包含一个传统交换机,例如Broadcom Tomahawk(Broadcom,2020),与串连聚合加速器相连。
① 工作节点安置。 当提交新的ML训练作业时,数据中心调度器确定最佳的分布式训练策略(Jia et al.,2019; Narayanan et al.,2019; Sergeev & Balso,2018),并将作业实例化在一组直接运行在集群服务器或虚拟机上的工作节点上。这些工作节点可能在同一个机架上,也可能分布在多个机架上,PANAMA对工作节点的安置不做任何假设。网内聚合的流量(聚合流量)的选择基于运营商的偏好,可以在控制器逻辑中配置。在我们的实验中,我们将所有大小超过40MB的reduce数据并行流标记为聚合流量。这个阈值是我们根据经验选择的,因为在较短的流量中看到的好处几乎可以忽略不计。
 图3. PANAMA高层工作流。
图3. PANAMA高层工作流。
② PSwitch的选择和初始化。 当PANAMA控制器为一项工作选择网内聚合时,需要初始化连接工作节点所有生成树的PSwitch。如果所有工作节点都在同一个机架上,这些树只是包含单一架顶(ToR)交换机,如果工作节点分布在多个机架上,则可能包括多层交换(见图3)。PANAMA利用现代数据中心的多路径连接,将单一工作的聚合流量分布在多个树上,从而提高网络效率,减少拥堵。
PANAMA控制器为每个聚合树生成唯一的IP组播地址,并沿着树的路径在PSwitch内配置转发条目。在上游方向,PSwitche被配置为向聚合树根部转发聚合数据包,而在下游方向,聚合数据包使用本地IP组播支持(如果可用)或通过在转发表中添加单个条目被路由回工作节点。PANAMA控制器还在路径上用作业状态和执行聚合所需的信息初始化网内聚合加速器(第5节)。
③ 工作节点设置。 最后,PANAMA控制器将选定的工作节点配置为使用网内聚合,并通知他们选定聚合树的IP组播地址。PANAMA不需要服务器上任何特定的硬件支持,PANAMA通信库可以取代主流ML框架所使用的通信库,例如NCCL和MPI(NVIDIA, 2021; The Open MPI Project, 2021)。PANAMA库将梯度封装成加速器支持的数据包格式(见图4)。
 图4. PANAMA聚合包格式。
图4. PANAMA聚合包格式。
4. 网络设计
本节我们将介绍PANAMA如何解决在一个由聚合流和非聚合流组成的共享环境中运行网内聚合的挑战(见图2)。这需要解决两个问题。首先是如何在多层数据中心中平衡聚合流量,以有效利用网络资源,并尽量减少非聚合流量的拥堵。PANAMA通过利用多个聚合树来解决这个问题。第二个问题是如何在聚合流和非聚合流之间公平分享网络带宽,而不会造成硬件加速器缓冲区溢出。为此,我们提出了一种基于ECN的拥塞控制算法,对聚合包和整个结构的PAUSE帧设置了拥塞窗口上限,以确保即使在拥堵的情况下,也能保证确定性的无损运行。
4.1. 路由和负载均衡
现在数据中心网络通常依靠等价多路径(ECMP, Equal Cost Multi Path)协议实现网络负载均衡,并确保属于某个TCP流的所有数据包通过相同的路径进行路由,从而避免接收方失序(Hopps,2000)。由于大多数数据中心的流量都很短(Alizadeh et al.,2010; 2013; Greenberg et al.,2009),ECMP通常足以确保流量在网络中合理分布。然而,聚合流量通常非常大,按照ECMP的要求,将这些流量限制在单一路径(聚合树)上,会造成严重的网络不平衡。这对争夺带宽的延迟敏感的短流量特别有害,它们将面临更多的排队延迟。为了避免这种情况,PANAMA在每个训练任务中使用多个聚合树,将流量分散到多个路径上,避免出现拥堵热点。
如前所述,PANAMA控制器向工作节点提供一组IP组播地址,代表为一项工作选择的聚合树,工作节点以轮询的方式将梯度包分配到不同的树上。例如,在图3的拓扑结构中,有四个聚合树 和8个ID为 的聚合包,假设工作节点开始向每个树发送单个数据包,我们的协议通过如下方式实现负载均衡: ,其中→表示每组数据包的目的地聚合树。例如,p1和p5被发送到 。注意,数据包的编号也反映了发送顺序,由于轮流发送,p5只有在前面的数据包被发送到其他树之后才被发送。这种机制平衡了各树的负载,并且由于顺序是确定的,因此不需要工作节点之间的协调。非聚合流量不受此影响,使用运营商定义的负载均衡协议进行转发。
4.2. 拥塞控制
本节我们将介绍PANAMA拥塞控制协议,首先概述聚合流量的拥塞控制协议需求,然后解释我们提出的协议如何满足这些需求。
4.2.1. 需求
对多点通信的支持。 传统拥塞控制协议假定在 (源、目的) 对之间进行单播、点对点通信。与此相反,网络内聚合涉及不同实体之间的多对多通信。因此,典型的基于丢包或拥塞通知的限速机制并不直接适用。一个天真的解决方案是在PSwitch中实施拥塞控制,用逐跳流量序列取代树状的多点流量。然而,这将浪费宝贵的芯片封装面积。
小型缓存。 由于硬件加速器需要在数百个端口上以线速运行,我们不能依靠DRAM之类的外部存储器,而只能使用片上缓存。片上存储器消耗了大量芯片面积,因此限制片上存储器的大小并通过在多个工作中公平分享有限的存储器并有效使用就显得至关重要。与传统网络的一个关键区别是,不仅因为拥堵需要缓存,而且还需要存储聚合包,直到来自所有工作的聚合包到达交换机。这就引入了流量之间的依赖性。由于只有在收到所有数据包后才能计算出结果,工作节点的发送速度必须匹配,否则,较快发送端的数据包必须被缓存,直到收到最慢发送端的数据包,从而浪费了可用于其他ML工作的资源。这一属性将网内聚合与表面上类似的co-flow抽象区分开来(Chowdhury & Stoica,2012),在后者中,单个流可以使用不同的速率。
与传统协议的兼容性。 协议的一个关键需求是能够与主流拥塞控制协议共存。特别是,该协议应该是TCP友好的,因为TCP是数据中心事实上的标准拥塞控制协议。在交换机上使用加权公平队列(WFQ, Weighted Fair Queues)来分离聚合流和非聚合流可能看起来是个简单的解决方案,但事实并非如此,它不能在属于不同工作的聚合流之间提供公平的共享,而且还涉及到动态选择分配给两个流量类别中每一个的最佳权重的复杂任务。
无损操作。 与传统TCP点对点流量不同,如果PANAMA中的某个聚合数据包丢失,就需要重新传输几个数据包,这可能会大大降低整个吞吐量。因此,即使在高网络负载下,确保缓冲区永不溢出也是至关重要的。
 图5. PANAMA拥塞控制算法。
图5. PANAMA拥塞控制算法。
4.2.2. 设计
接下来我们讨论PANAMA拥塞控制协议的关键特性,并解释如何满足上述需求。我们在图5中提供了协议的伪代码,该协议是终端主机上的PANAMA通信库的一部分,使用这一协议不需要对训练框架进行任何更改。
隐式确认。 现有数据中心拥塞控制机制利用网络交换机(如丢包或ECN标记)和终端主机(如RTT)的信号来检测拥堵的开始并调整发送方的数据包发送速率(Alizadeh et al.,2010; Dong et al.,2015; Ha et al.,2008; Handley et al.,2017; Mittal et al.,2015; Zhu et al.,2015)。然而,网内聚合不能复用这种机制,因为新的数据包是在网络内的每个交换机上通过将几个传入的数据包聚合成一个来构建的。这破坏了数据包和对应的确认消息之间的一对一映射。相反,我们的设计利用了网内聚合操作的独特属性。由于聚合结果的数量等于本地计算梯度的数量,每个工作节点都期望为每个发送的聚合数据包提供一个结果包。因此,工作节点可以将聚合结果包视为隐含的确认信号,以增加窗口大小,如图5所示。这就克服了在PSwitch( )上维持每个流量拥堵状态的需要。此外,拥塞控制在每个聚合树上单独运行,避免了在多条路径上重新排序数据包的需要,当与我们的负载均衡协议(4.1)相结合时,可以提供多路径拥塞控制协议的好处(Peng et al.,2013),而没有额外的复杂性。
ECN标记。 我们的拥塞控制协议受到DCTCP(Alizadeh et al.,2010)的启发,依靠IP头中的ECN标记对观察到的网络拥堵做出反应。在PANAMA中,我们扩展了这一机制,使聚合工作速率在工作节点之间同步。网内聚合的一个明显特征是,当数据包在聚合树中向上移动时,PSwitch必须在多个数据包中聚合梯度并产生聚合结果数据包,而这可能会导致丢失网络拥堵状态信息。然而,在PANAMA中,PSwitch内的聚合加速器保留了聚合数据包的ECN字段信息,每个硬件加速器对收到的数据包的ECN字段进行比特或(OR)操作,将ECN位镜像到生成的聚合数据包的IP头中(见图4)。因此,聚合数据包将携带ECN位返回给所有的工作节点。与传统的基于ECN的拥塞控制方案不同,因为结果包被用作隐式确认,因此不需要将ECN回传给发送端。工作节点检查结果包,如果ECN位被设置,就会调整发送速率,详见图5。这种机制确保每个聚合树的拥塞窗口在聚合树( )中的工作节点之间以同步的方式增长和缩小。此外,由于拥塞控制机制与DCTCP相匹配,可以保证与现有的传统协议兼容,正如我们在第7节的评估中显示的那样( )。
拥塞窗口的上限。 为了避免由于加速器缓冲区溢出而导致数据包丢失,PANAMA的拥塞协议对训练工作节点的拥塞窗口大小设置了上限,以匹配每个聚合树加速器中的最小可用缓冲空间,从而确保总是可以容纳传入的数据包,而不会因为缺乏可用的缓冲空间而被丢弃( )。为了维护最新的可用缓冲空间,硬件加速器使用一个称为cwnd_cap的字段更新每个聚合数据包。数据包中为cwnd_cap保留了16位,以便在聚合数据包上升到聚合树根部时,捕捉到加速器上存储数据包的最小可用内存。每个加速器根据活跃训练作业的数量(packet_memory/num_jobs)计算其可用内存,如果可用缓冲空间小于收到的聚合数据包的cwnd_cap,则覆盖cwnd_cap,否则保留最小cwnd_cap值。然后,最终值与梯度聚合结果一起被发送给所有工作节点。如上所述,收到聚合数据包被视为确认信号,使工作节点能够发送下一组数据包。类似于TCP协商窗口大小(数据包在工作节点创建时被假定为具有固定大小),cwnd_cap的值被用作每个工作节点当前最大可处理数据包数量的上限。我们依靠标准以太网流量控制机制,通过PAUSE帧确保网络内的加速器不会造成交换机缓冲区溢出,从而形成端到端无损架构。在数据包损坏或失败的情况下,仍然可能有丢包(Zhuo et al.,2017),但可以使用简单的超时机制来处理这个问题。由于我们协议的无损属性,超时值的设置不需要太激进,从而防止虚假重传。
5. 聚合加速器设计
接下来我们将介绍用于支持PSwitch中浮点线速聚合的硬件加速器架构(见图6a)。
① 包头解析器。 每个输入端口的解析器模块检查传入数据包的EtherType和DSCP字段(图4),以将聚合数据包从其他流量中分离出来。DSCP字段值为56的IPv4报文被认为是聚合报文,被发送到专用的聚合缓冲区,而其他数据包则直接转发到交换芯片,从而确保非聚合包不会因为聚合包发生行首阻塞,并且在通过加速器时只会经历最小的延迟。
② 控制逻辑。 加速器为作业保持以下状态: Ports_bitmap和Expected_VID。Ports_bitmap寄存器是由PANAMA控制器在配置作业的聚合树时设置的,标识了聚合中的加速器输入端口。Expected_VID寄存器用于纠正聚合以及错误引起的丢包检测,初始化为0。加速器依靠图4所示的作业ID(Job ID, JID)和树ID(Tree ID, TID)字段来识别执行聚合任务时必须使用的Ports_bitmap和Expected_VID。实践中,必须为每个作业维护一个Ports_bitmap,并且必须为作业中的每个聚合树维护一个Expected_VID。我们用图6a中的例子来说明加速器对于单个作业和单个聚合树的聚合控制逻辑。需要维护一个Ports_bitmap寄存器和一个Expected_VID寄存器。由于Ports_bitmap寄存器被设置为1111,控制器必须等待,直到四个输入端口中的每个端口至少有一个数据包可用。当这个要求被满足时,数据包的头被复制到头寄存器中,它们的VID字段与Expected_VID寄存器中的0值进行比较。因为工作节点在具有相同VID的数据包中封装了相同的梯度集,因此数据包上的VID字段可以作为梯度标识符。同时还可以充当数据包序列号,工作节点为聚合树中发送的数据包分配递增的VID。由于聚合树保证按顺序交付,加速器使用Expected_VID寄存器跟踪预期数据包,由此确保正确的梯度聚合,并允许检测由数据包损坏引起的丢包。当所有的VID字段与Expected_VID寄存器的当前值相匹配时,如图6a所示,梯度通过聚合数据路径内的加法树(adder tree) 传递,Expected_VID寄存器被递增。否则,缺失值的梯度将被丢弃,聚合将以下一个Expected_VID继续进行。工作节点通过设置数据包头的FIN位来通知加速器已经发送了所有聚合数据包,从而重置加速器状态。
浮点支持。 使网内聚合实用化的一个关键挑战是在当前数据速率(10Gbps和40Gbps)和未来数据速率(100Gbps)下支持浮点聚合。我们的设计是在假设一定的时钟速率(见附录A的图11)的前提下,通过调整从每个输入端口向每个输出端口传输数据的总线宽度来实现这一目标,以匹配所需的端口速率。聚合包有效载荷从参与工作的每个专用缓冲区流向多个加法树,并行加法树的数量与数据总线中可承载的梯度数量成正比。如图6a所示,从而实现SIMD架构,其中梯度被划分到两个加法树上,加法树并行工作,结果被串联起来并被送到输出端口。
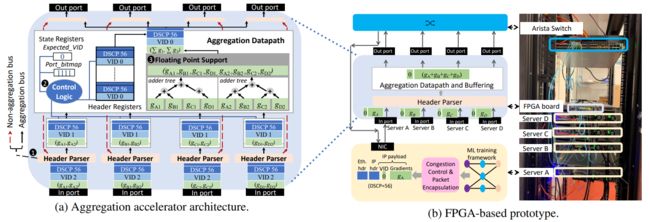 图6. PANAMA硬件设计细节。
图6. PANAMA硬件设计细节。
6. 基于FPGA的原型
我们评估了在配备有1个Xilinx Virtex-7 FPGA和4个10 Gbps收发器的NetFPGA-SUME板(Zilberman et al.,2014)上实现聚合加速器的可行性。我们将Xilinx LogiCORE IP核(Xilinx,2014)纳入设计,以支持浮点加法(与IEEE-754单精度标准完全兼容)。LogiCORE IP核将最大时钟速率限制在220MHz,因此我们实例化了两个加法树副本,以满足所需的线路速率(10 Gbps),并选择了200 MHz时钟速率。表1总结了加速器由非聚合数据包和聚合数据包观察到的快速转发时延。如图所示,加速器引入的延迟是最小的,甚至对聚合数据包也是如此。我们还测量了针对最近的VU19P FPGA板(Xilinx, 2021)的资源利用率(见附录A的表2)。结果显示,我们的设计具有较小的资源占用,对于触发器(FF, Flip-Flops)的可用查找表(LUT, Lookup-Tables)分别只使用了1%和0.26%。这一点很重要,表明我们的设计可以很容易的安装在小芯片上,从而有可能通过chipleg将其与主交换芯片共同封装。此外,还表明有空间通过实例化更多加法树来增加并行性,以维持更高的数据速率。初步分析表明,我们的设计可以扩展到100多个端口,基于FPGA实现每端口100Gbps,或者基于ASIC实现每端口400Gbps(见附录A)。
 表1. 原型的快速转发时延。
表1. 原型的快速转发时延。 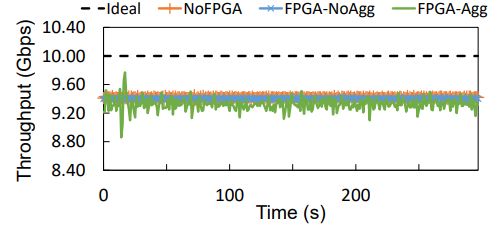 图7. 原型的聚合吞吐量。
图7. 原型的聚合吞吐量。
原型评估设置。 我们用4台Dell R740双核PowerEdge服务器、10 Gbps光收发器和一个Arista 7050S交换机构建了一个PANAMA测试平台,通过如图6b所示的串连配置将FPGA板连接到服务器和交换机之间。
功能正确性。 如图4所示,我们使用libtins库(libtins, 2021)来构造PANAMA包来评估架构的正确性。模拟ML作业生成的梯度的随机生成的浮点数被封装在PANAMA包中,并发送到PSwitch进行聚合。在所有实验中,我们观察所有收到的数据包中正确的聚合值。
吞吐量性能。 我们首先测量两台服务器在没有任何中间FPGA(NoFPGA)的情况下,通过交换机直接互连时可以达到的最大吞吐量。我们使用四个并行的iperf实例,以确保实验不受CPU的限制。然后,我们将FPGA连接到模拟PSwitch架构的交换机上(第3节),并使用相同的工作负载运行两个额外的实验来测量FPGA-noagg和FPGA-agg路径的吞吐量。为了与iperf兼容,我们修改了控制逻辑,使单一输入穿越聚合路径。我们将Port bitmap寄存器值初始化为0001,并将数据包生成服务器连接到加速器的第一个端口。我们使用UDP数据包而不是TCP数据包,因为在后者的聚合过程中,数据包的有效载荷会被聚合修改,因此,TCP校验会失败。图7显示,FPGA-noagg的吞吐量与NoFPGA的吞吐量接近,表明对于非聚合数据包,FPGA引入的开销可以忽略不计。然而,在FPGA-agg的情况下,吞吐量的变化稍大(在8.86Gbps到10.48Gbps之间震荡)。这是使用UDP而不是TCP的结果,因为UDP会导致流量激增。尽管如此,平均吞吐量与以前的实验一致,证实了我们的原型有能力支持10Gbps的聚合。
7. 大规模模拟
本节我们使用OMNeT++包级网络模拟器的定制版本(Ltd.,2021)评估PANAMA在大规模网络下的性能。模拟分析的主要收获是: (i)与最先进的Ring-AllReduce相比,PANAMA将99%的短流量(<40 MB)完成时间(FCT, flow completion time)降低了4.5倍,将长流量的吞吐量提高了1.33倍,并将聚合流量的训练时间加快了1.34倍。(ii)PANAMA更高的性能是由于它有能力减少网络上传输的数据量,以及有能力在拥堵期控制工作节点的数据包发送率。我们证明了PANAMA比没有我们的拥塞控制协议的基线要好3.5倍,减少了99%短流量的FCT。(iii)PANAMA的多树聚合技术可以平衡聚合流量对网络路径的负载。(iv)PANAMA的拥塞控制算法为所有流量提供了公平的带宽分配。
方法和设置。 在我们的实验中,假设网络为非阻塞的交叉CLOS拓扑结构(Al-Fares et al.,2008),包括1024台服务器通过10Gbps链接互连。我们将ECN标记阈值设置为85个数据包,并根据最先进的FPGA(Intel,2016; Xilinx,2021)的最大缓冲容量,将聚合加速器的缓冲容量限制在64MB。假设我们的工作负载由不同规模的聚合流量和非聚合流量组成,这些流量来自网络搜索和数据挖掘流量分布(Alizadeh et al.,2013; Greenberg et al.,2009)。流量到达时间采用指数分布(泊松过程),我们改变平均到达时间以模拟不同的网络负载。对于聚合流量,分配给每个作业的节点数量是随机选择的,范围从16到96,而DNN模型是从六个著名的图像分类模型(VGG16、AlexNet,Resnet152、Resnet50、Inceptionv3和GoogleNet)中使用加权随机分布选择的。为了对计算时间进行建模,我们在第2节的实验中使用P100 GPU测量的值。
调度作业。 我们的作业调度器将属于同一作业的节点尽可能靠近,以确保最佳的基线性能。非聚集流的源头和目的地是统一选择的(Alizadeh et al.,2013)。我们使用DCTCP(Alizadeh et al.,2010)作为非聚合流的默认传输层协议,并使用PANAMA拥塞控制来处理聚合流。
配置。 我们考虑五种网络配置: (1) Ideal: 理想设置,其中聚合流、短流和长流完全分离,并在各自的专用集群中提供服务,没有任何资源共享。(2) Ring-AllReduce: Horovod(Sergeev & Balso,2018)中使用的分布式训练的最先进技术。(3) SwitchML∗: 最近基于Tofino的网内聚合建议的增强版(Sapio et al.,2021)。我们的增强使SwitchML能够支持多租户、作业共享和负载均衡。然而,正如其最初的实现一样,它没有拥塞控制机制。(4) PANAMA: 我们的建议。(5) PANAMA-0.88和PANAMA-0.94: PANAMA的两个部分同步版本。数字0.88和0.94代表了PANAMA在每个迭代中同步的聚合节点的比例。这两种配置对于评估忽略最慢的链路和在收到工作节点的88%(或94%)的数据包后立即进行聚合的影响很有用。
PANAMA减少了聚合流量对短流量(<40MB)的影响。我们从基线网络(20%的负载由非聚合流量组成)开始,慢慢增加DNN训练作业的到达频率,将聚合流量引入网络,直到80%负载。图8a显示,随着聚合负载的增长,使用传统的Ring-AllReduce方法,短流量的99%-tile FCT明显增加。相比之下,PANAMA减轻了拥堵的影响,即使在高负载下也紧跟理想线。在最高负荷下(80%),PANAMA比Ring-AllReduce减少了4.5倍的FCT。PANAMA的收益来自于网内聚合与拥塞控制和负载均衡的结合。SwitchML∗执行了网内聚合,能够减少FCT,并进一步与负载均衡相结合。然而,它缺乏拥塞控制,因此无法与PANAMA相提并论,在牺牲短流量的FCT的情况下,给聚合流量带来了不公平的优势。同样,PANAMA-0.88和0.94的部分聚合也接近SwitchML∗,因为没有使工作节点的速度减慢到足以与拥挤的链接相匹配。
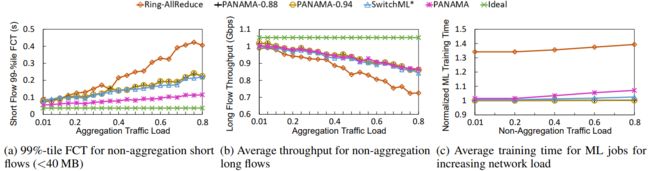 图8. 与其他训练计划相比,PANAMA在共享数据中心设置中的表现。
图8. 与其他训练计划相比,PANAMA在共享数据中心设置中的表现。
网内方案提高了长流量的吞吐量。 接下来,我们研究了聚合负载的增加对长流量的影响。图8b的结果表明与Ring-AllReduce相比,PANAMA能够将长流量的吞吐量提高到1.33倍。但是,由于长流量和聚合流较大(>40 MB),这种改进与其他网内方案相匹配,可以充分利用额外的可用带宽。
网内方案提升了ML作业的完成时间。 如图8c所示,PANAMA比基线Ring-AllReduce方法提高了1.34倍的ML作业训练时间,而SwitchML∗的表现仅略胜一筹,为1.05倍。SwitchML∗和其他PANAMA变体的表现优于PANAMA,因为它们忽略了网络内的拥堵,牺牲了短流量。然而,这些方法所测得的训练时间并没有考虑到由于SwitchML∗不支持浮点运算而产生的潜在精度损失(或迭代次数的增加),也没有考虑到PANAMA-0.88和PANAMA-0.94中忽略部分梯度的影响。
负载均衡的影响。 为了确定网络流量负载均衡的重要性,我们创建了图3所示的拓扑结构,并用8个工作节点运行聚合训练作业。我们通过增加产生长流量的节点数量来增加网络负载。与之前实验不同的是,我们考虑了训练工作的完成时间,在这个实验中,我们只考虑了在一个迭代中计算的聚合梯度的时间(聚合延迟)。图9显示了6种情况下的聚合延时: PANAMA,只有一棵聚合树的PANAMA(即标记为PANAMA-Agg1,..., PANAMA-Agg4的四个场景),以及Ring-AllReduce。如图所示,因为PANAMA使用了所有4个聚合树,因此其性能优于其他所有方案。有趣的是,使用单一聚合树的网内聚合的性能可能比Ring-AllReduce的性能差。与可以通过ECMP或数据包散射等路由技术实现多样化的终端主机路径不同,从每个工作节点到PSwitch的路径是唯一的,如果负载没有得到适当的平衡,聚合时间将受到严重影响。
 图9. 负载均衡的影响。
图9. 负载均衡的影响。
公平。 为了证明PANAMA的拥塞控制机制实现了跨流的公平速率分配,我们建立了一个实验,在聚合流和对延迟敏感的非聚合流之间共享瓶颈链路。我们从非聚合流开始,0.25秒之后启动聚合流。图10a显示PANAMA在两个流之间平均共享链路带宽。相比之下,图10b显示,如果没有PANAMA的拥塞控制协议,对延迟敏感的非聚合流会面临饥饿。
 图10. PANAMA在聚合流和非聚合流之间实现了公平的带宽分配。
图10. PANAMA在聚合流和非聚合流之间实现了公平的带宽分配。
8. 相关工作
我们的工作与SwitchML(Sapio et al.,2021)和ATP(Lao et al.,2021)密切相关,这两种方法都使用市面上的可编程交换机(Intel,2018)来执行梯度聚合。虽然使用可编程交换机简化了部署,但有两个重要的限制。首先,今天的可编程交换机只支持定点算术。因此,SwitchML和ATP需要仔细的将特定模型的浮点梯度转换为定点表示,这可能会影响达到目标精度所需的训练时间。其次,Tofino交换机在不同的流水线中不保持状态,并且每个流水线中的阶段数量有限(Gebara et al.,2020)。因此,SwitchML和ATP在单项工作可使用的端口数量方面是有限的,在最大数据包大小方面也是如此。相比之下,PANAMA的加速器设计很灵活,可以支持线速的浮点运算,并且可以扩展到数百个端口。Li等人提出了网内聚合,以加速强化学习工作,使用的设计是在单个FPGA内实现所需的聚合逻辑和交换功能(Li et al.,2019)。与我们不同的是,他们的建议假定了可以存储在片上的小规模模型(RL模型),但这使得他们的设计无法适用于今天具有数十亿参数的大规模DNN模型。此外,还要求网络的速度随着聚合线速的增长而成比例增长。Mellanox提出了一个名为Sharp(Bloch,2019)的网内聚合解决方案,使用交换机内专门用于集合还原操作(allreduce)的定制硬件。但由于没有公开设计,很难推测是如何实现的,以及是否/如何能够扩展到高数据率。此外,Sharp是面向HPC的,需要专属的网络访问,使得它不太适合今天云数据中心的共享ML集群。同样,Klenk等人提出了一个硬件单元,可以纳入交换机,以加速allreduce操作(以及其他集合原语)(Klenk et al.,2020)。然而,他们的解决方案依赖于共享内存原语,为了确保作业没有别名指针而引入了额外的复杂性。更广泛的说,与所有先前的工作不同,我们通过考虑现实的共享环境而不是专用集群,重点关注使用网内聚合对整个数据中心流量的影响。
9. 结论
最近的建议主张使用网内聚合来改善分布式ML训练时间。然而,由于缺乏有效的聚合硬件、路由和拥塞控制协议,这些方法的实际可行性受到了限制,不适合共享数据中心环境。本文迈出了填补这一空白的第一步,提出了PANAMA,作为在共享集群中运行的新型网内聚合框架。PANAMA利用网内聚合的独特属性,在不牺牲精度的情况下实现快速硬件加速,并有效和公平的使用网络资源。与通常的观点相反,我们证明了网内聚合的好处可以延伸到非聚合流量,并且不只限于数据并行的ML作业。
致谢
感谢我们的匿名评论者。这项工作得到了微软研究博士奖学金项目、英国EPSRC基金EP/L016796/1、NSF基金CNS-2008624、ASCENT2023468和SystemsThatLearn@CSAIL Ignite基金的部分支持。
参考资料
Abadi, M., Barham, P., Chen, J., Chen, Z., Davis, A., Dean, J., Devin, M., Ghemawat, S., Irving, G., Isard, M., Kudlur, M., Levenberg, J., Monga, R., Moore, S., Murray, D. G., Steiner, B., Tucker, P., Vasudevan, V., Warden, P., Wicke, M., Yu, Y., and Zheng, X. TensorFlow: A System for Large-Scale Machine Learning. In Proceedings of the 12th USENIX Conference on Operating Systems Design and Implementation (OSDI’16), pp. 265–283, USA, 2016. USENIX Association. ISBN 9781931971331.
Al-Fares, M., Loukissas, A., and Vahdat, A. A scalable, commodity data center network architecture. In Proceedings of the ACM SIGCOMM 2008 Conference on Data Communication (SIGCOMM’08), pp. 63–74, New York, NY, USA, 2008. Association for Computing Machinery. ISBN 9781605581750. doi: 10.1145/1402958.1402967. URL https://doi.org/10.1145/1402958.1402967.
Alizadeh, M., Greenberg, A., Maltz, D. A., Padhye, J., Patel, P., Prabhakar, B., Sengupta, S., and Sridharan, M. Data Center TCP (DCTCP). In Proceedings of the ACM SIGCOMM 2010 Conference (SIGCOMM’10), pp. 63–74, New York, NY, USA, 2010. Association for Computing Machinery. ISBN 9781450302012. doi: 10.1145/1851182.1851192. URL https://doi.org/10.1145/1851182.1851192.
Alizadeh, M., Yang, S., Sharif, M., Katti, S., McKeown, N., Prabhakar, B., and Shenker, S. Pfabric: Minimal near-optimal datacenter transport. In Proceedings of the ACM SIGCOMM 2013 Conference on SIGCOMM (SIGCOMM’13, pp. 435–446, New York, NY, USA, 2013. Association for Computing Machinery. ISBN 9781450320566. doi: 10.1145/2486001.2486031. URL https://doi.org/10.1145/2486001.2486031.
Amazon. Amazon Elastic Graphics. https://aws.amazon.com/ec2/elastic-graphics/, 2021.
Azure, M. GPU-ACCELERATED MICROSOFT AZURE. https://www.nvidia.com/en-us/data-center/gpu-cloud-computing/microsoft-azure/, 2021.
Bloch, G. Accelerating Distributed Deep Learning with In-Network Computing Technology, Aug. 2019. URL https://conferences.sigcomm.org/events/apnet2019/slides/Industrial_1_3.pdf.
Bosshart, P., Gibb, G., Kim, H.-S., Varghese, G., McKeown, N., Izzard, M., Mujica, F., and Horowitz, M. Forwarding Metamorphosis: Fast Programmable Match-Action Processing in Hardware for SDN. In Proceedings of the ACM SIGCOMM 2013 Conference on SIGCOMM (SIGCOMM’13), pp. 99–110, New York, NY, USA, 2013. Association for Computing Machinery. ISBN 9781450320566. doi: 10.1145/2486001.2486011. URL https://doi.org/10.1145/2486001.2486011.
Broadcom. BCM56990 25.6 Tb/s Tomahawk 4 Ethernet Switch. https://docs.broadcom.com/docs/12398014, 2020.
Chowdhury, M. and Stoica, I. Coflow: A Networking Abstractio for Cluster Applications. In HotNets, HotNetsXI, pp. 31–36, 2012.
Costa, P., Donnelly, A., Rowstron, A., and O’Shea, G. Camdoop: Exploiting In-network Aggregation for Big Data Applications. In Proceedings of the 9th USENIX Symposium on Networked Systems Design and Implementation (NSDI’12), 2012.
Dong, M., Li, Q., Zarchy, D., Godfrey, P. B., and Schapira, M. PCC: Re-Architecting Congestion Control for Consistent High Performance. In Proceedings of the 12th USENIX Conference on Networked Systems Design and Implementation (NSDI’15, pp. 395–408, USA, 2015. USENIX Association. ISBN 9781931971218.
Firestone, D., Putnam, A., Mundkur, S., Chiou, D., Dabagh, A., Andrewartha, M., Angepat, H., Bhanu, V., Caulfield, A., Chung, E., Chandrappa, H. K., Chaturmohta, S., Humphrey, M., Lavier, J., Lam, N., Liu, F., Ovtcharov, K., Padhye, J., Popuri, G., Raindel, S., Sapre, T., Shaw, M., Silva, G., Sivakumar, M., Srivastava, N., Verma, A., Zuhair, Q., Bansal, D., Burger, D., Vaid, K., Maltz, D. A., and Greenberg, A. Azure Accelerated Networking: SmartNICs in the Public Cloud. In 15th USENIX Symposium on Networked Systems Design and Implementation (NSDI 18), pp. 51–66, Renton, WA, April 2018. USENIX Association. ISBN 978-1-939133-01-4. URL https://www.usenix.org/conference/nsdi18/presentation/firestone.
Gebara, N., Lerner, A., Yang, M., Yu, M., Costa, P., and Ghobadi, M. Challenging the Stateless Quo of Programmable Switches. In ACM Workshop on Hot Topics in Networks (HotNets). ACM, November 2020. URL https://www.microsoft.com/en-us/research/publication/challenging-the-stateless-quo-of-programmable-switches
Google. Cloud GPUs. https://cloud.google.com/gpu/, 2021.
Greenberg, A., Hamilton, J. R., Jain, N., Kandula, S., Kim, C., Lahiri, P., Maltz, D. A., Patel, P., and Sengupta, S. VL2: A Scalable and Flexible Data Center Network. In Proceedings of the ACM SIGCOMM 2009 Conference on Data Communication (SIGCOMM’09), pp. 51–62, New York, NY, USA, 2009. Association for Computing Machinery. ISBN 9781605585949. doi: 10.1145/1592568.1592576. URL https://doi.org/10.1145/1592568.1592576.
Ha, S., Rhee, I., and Xu, L. CUBIC: A New TCP-Friendly High-Speed TCP Variant. SIGOPS Oper. Syst. Rev., 42(5):64–74, July 2008. ISSN 0163-5980. doi: 10.1145/1400097.1400105. URL https://doi.org/10.1145/1400097.1400105.
Handley, M., Raiciu, C., Agache, A., Voinescu, A., Moore, A. W., Antichi, G., and Wojcik, M. Re-architecting data-center networks and stacks for low latency and high performance. In Proceedings of the Conference of the ACM Special Interest Group on Data Communication (SIGCOMM’17), pp. 29–42, New York, NY, USA, 2017. Association for Computing Machinery. ISBN 9781450346535. doi: 10.1145/3098822.3098825. URL https://doi.org/10.1145/3098822.3098825.
Hopps, C. Analysis of an Equal-Cost Multi-Path Algorithm. RFC 2992, 2000. URL https://rfc-editor.org/rfc/rfc2992.txt.
Huang, Y., Cheng, Y., Chen, D., Lee, H., Ngiam, J., Le, Q. V., and Chen, Z. GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism. CoRR, abs/1811.06965, 2018. URL http://arxiv.org/abs/1811.06965.
Intel. Intel stratix 10 tx device overview. https://www.intel.com/content/dam/www/programmable/us/en/pdfs/literature/hb/stratix-10/s10_tx_overview.pdf, 2016.
Intel. P4-programmable Ethernet Tofino 2. https://www.intel.com/content/www/us/en/products/network-io/programmable-ethernet-switch/tofino-2-series/tofino-2.html/, 2018.
Jeon, M., Venkataraman, S., Phanishayee, A., Qian, u., Xiao, W., and Yang, F. Analysis of Large-Scale MultiTenant GPU Clusters for DNN Training Workloads. In Proceedings of the 2019 USENIX Conference on Usenix Annual Technical Conference (USENIX ATC ’19), pp. 947–960, USA, 2019. USENIX Association. ISBN 9781939133038.
Jia, Z., Zaharia, M., and Aiken, A. Beyond Data and Model Parallelism for Deep Neural Networks. In Talwalkar, A., Smith, V., and Zaharia, M. (eds.), Proceedings of Machine Learning and Systems, volume 1, pp. 1–13, 2019. URL https://proceedings.mlsys.org/paper/2019/file/c74d97b01eae257e44aa9d5bade97baf-Paper.pdf.
Klenk, B., Jiang, N., Thorson, G., and Dennison, L. An InNetwork Architecture for Accelerating Shared-Memory Multiprocessor Collectives. In 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA’20), pp. 996–1009, 2020.
Kumar, G., Dukkipati, N., Jang, K., Wassel, H. M. G., Wu, X., Montazeri, B., Wang, Y., Springborn, K., Alfeld, C., Ryan, M., Wetherall, D., and Vahdat, A. Swift: Delay is Simple and Effective for Congestion Control in the Datacenter. In Proceedings of the Annual Conference of the ACM Special Interest Group on Data Communication on the Applications, Technologies, Architectures, and Protocols for Computer Communication (SIGCOMM’20), pp. 514–528, New York, NY, USA, 2020. Association for Computing Machinery. ISBN 9781450379557. doi: 10.1145/3387514.3406591. URL https://doi.org/10.1145/3387514.3406591.
Lao, C., Le, Y., Mahajan, K., Chen, Y., Wu, W., Akella, A., and Swift, M. ATP: In-network Aggregation for Multi-tenant Learning. In 18th USENIX Symposium on Networked Systems Design and Implementation (NSDI 21). USENIX Association, April 2021. URL https://www.usenix.org/conference/nsdi21/presentation/lao.
Lepikhin, D., Lee, H., Xu, Y., Chen, D., Firat, O., Huang, Y., Krikun, M., Shazeer, N., and Chen, Z. GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding, 2020.
Li, M., Andersen, D. G., Park, J. W., Smola, A. J., Ahmed, A., Josifovski, V., Long, J., Shekita, E. J., and Su, B.-Y. Scaling Distributed Machine Learning with the Parameter Server. In Proceedings of the 11th USENIX Conference on Operating Systems Design and Implementation (OSDI’14), pp. 583–598, USA, 2014. USENIX Association. ISBN 9781931971164.
Li, Y., Liu, I.-J., Yuan, Y., Chen, D., Schwing, A., and Huang, J. Accelerating Distributed Reinforcement Learning with In-Switch Computing. In Proceedings of the 46th International Symposium on Computer Architecture (ISCA’19, ISCA ’19, pp. 279–291, New York, NY, USA, 2019. Association for Computing Machinery. ISBN 9781450366694.
libtins. libtins packet crafting and sniffing library. https://libtins.github.io/, 2021.
Ltd., O. OMNeT++ Discrete Event Simulator, 2021. https://omnetpp.org/.
Mai, L., Rupprecht, L., Alim, A., Costa, P., Migliavacca, M., Pietzuch, P. R., and Wolf, A. L. NetAgg: Using Middleboxes for Application-specific On-path Aggregation in Data Centres. In Seneviratne, A., Diot, C., Kurose, J., Chaintreau, A., and Rizzo, L. (eds.), Proceedings of the 10th ACM International on Conference on Emerging Networking Experiments and Technologies (CoNEXT ’14), pp. 249–262. ACM, 2014. doi: 10.1145/2674005.2674996. URL https://doi.org/10.1145/2674005.2674996.
Mittal, R., Lam, V. T., Dukkipati, N., Blem, E., Wassel, H., Ghobadi, M., Vahdat, A., Wang, Y., Wetherall, D., and Zats, D. TIMELY: RTT-Based Congestion Control for the Datacenter. In Proceedings of the 2015 ACM Conference on Special Interest Group on Data Communication (SIGCOMM’15), pp. 537–550, New York, NY, USA, 2015. Association for Computing Machinery. ISBN 9781450335423. doi: 10.1145/2785956.2787510. URL https://doi.org/10.1145/2785956.2787510.
Moritz, P., Nishihara, R., Wang, S., Tumanov, A., Liaw, R., Liang, E., Elibol, M., Yang, Z., Paul, W., Jordan, M. I., and Stoica, I. Ray: A Distributed Framework for Emerging AI Applications. In 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI18), 2018.
Narayanan, D., Harlap, A., Phanishayee, A., Seshadri, V., Devanur, N. R., Ganger, G. R., Gibbons, P. B., and Zaharia, M. Pipedream: Generalized pipeline parallelism for dnn training. In Proceedings of the 27th ACM Symposium on Operating Systems Principles (SOSP’19), pp. 1–15, New York, NY, USA, 2019. Association for Computing Machinery. ISBN 9781450368735. doi: 10.1145/3341301.3359646. URL https://doi.org/10.1145/3341301.3359646.
NVIDIA. NVIDIA Collective Communications Library (NCCL). https://docs.nvidia.com/deeplearning/nccl/, 2021.
Omkar R., D. and M., A. Asic implementation of 32 and 64 bit floating point alu using pipelining. International Journal of Computer Applications, 94:27–35, 05 2014. doi: 10.5120/16452-6184.
Peng, Q., Walid, A., and Low, S. H. Multipath TCP: analysis and design. CoRR, abs/1308.3119, 2013. URL http://arxiv.org/abs/1308.3119.
Rossi, F. and Durut, M. Communication challenges in cloud k-means. In ESANN, 2011.
Sapio, A., Canini, M., Ho, C., Nelson, J., Kalnis, P., Kim, C., Krishnamurthy, A., Moshref, M., Ports, D. R. K., and Richtarik, P. Scaling Distributed Machine Learning with In-Network Aggregation. In 18th USENIX Symposium on Networked Systems Design and Implementation (NSDI’21). USENIX Association, April 2021. URL https://www.usenix.org/conference/nsdi21/presentation/sapio.
Sergeev, A. and Balso, M. D. Horovod: fast and easy distributed deep learning in TensorFlow, 2018.
Shoeybi, M., Patwary, M., Puri, R., LeGresley, P., Casper, J., and Catanzaro, B. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism, 2020.
Singh, A., Ong, J., Agarwal, A., Anderson, G., Armistead, A., Bannon, R., Boving, S., Desai, G., Felderman, B., Germano, P., Kanagala, A., Provost, J., Simmons, J., Tanda, E., Wanderer, J., Holzle, U., Stuart, S., and Vahdat, A. Jupiter rising: A decade of clos topologies and centralized control in google’s datacenter network. In Proceedings of the 2015 ACM Conference on Special Interest Group on Data Communication (SIGCOMM’15), pp. 183–197, New York, NY, USA, 2015. Association for Computing Machinery. ISBN 9781450335423. doi: 10.1145/2785956.2787508. URL https://doi.org/10.1145/2785956.2787508.
Stillmaker, A. and Baas, B. Scaling equations for the accurate prediction of cmos device performance from 180nm to 7nm. Integration, 58:74–81, 2017. ISSN 0167-9260. doi: https://doi.org/10.1016/j.vlsi.2017.02.002. URL https://www.sciencedirect.com/science/article/pii/S0167926017300755.
Sun, P., Feng, W., Han, R., Yan, S., and Wen, Y. Optimizing Network Performance for Distributed DNN Training on GPU Clusters: ImageNet/AlexNet Training in 1.5 Minutes. CoRR, abs/1902.06855, 2019. URL http://arxiv.org/abs/1902.06855.
TensorFlow. TensorFlow Benchmarks. https://github.com/tensorflow/benchmarks, 2021.
The Open MPI Project. Open MPI:Open Source High Performance Computing. https://www.open-mpi.org/, 2021.
Uber Eng. Meet Horovod: Uber’s Open Source Distributed Deep Learning Framework for TensorFlow. https://eng.uber.com/horovod, 2017.
Xilinx. Logicore ip floating-point operator v7.0. https://www.xilinx.com/support/documentation/ip_documentation/floating_point/v7_0/pg060-floating-point.pdf, 2014
Xilinx. Ultrascale+ FPGAs Product Tables and Product Selection Guide. https://www.xilinx.com/support/documentation/selection-guides/ultrascale-plus-fpga-product-selection-guide.pdf, 2021
Zhu, Y., Eran, H., Firestone, D., Guo, C., Lipshteyn, M., Liron, Y., Padhye, J., Raindel, S., Yahia, M. H., and Zhang, M. Congestion Control for Large-Scale RDMA Deployments. In Proceedings of the 2015 ACM Conference on Special Interest Group on Data Communication (SIGCOMM ’15), pp. 523–536, New York, NY, USA, 2015. Association for Computing Machinery. ISBN 9781450335423. doi: 10.1145/2785956.2787484. URL https://doi.org/10.1145/2785956.2787484.
Zhuo, D., Ghobadi, M., Mahajan, R., Forster, K.-T., Krishnamurthy, A., and Anderson, T. Understanding and mitigating packet corruption in data center networks. In Proceedings of the Conference of the ACM Special Interest Group on Data Communication (SIGCOMM ’17), pp. 362–375, New York, NY, USA, 2017. ACM. ISBN 978-1-4503-4653-5. doi: 10.1145/3098822.3098849. URL http://doi.acm.org/10.1145/3098822.3098849.
Zilberman, N., Audzevich, Y., Covington, G., and Moore, A. W. Netfpga sume: Toward 100 gbps as research commodity. IEEE Micro, 34(05):32–41, sep 2014. ISSN 1937-4143. doi: 10.1109/MM.2014.61.
你好,我是俞凡,在Motorola做过研发,现在在Mavenir做技术工作,对通信、网络、后端架构、云原生、DevOps、CICD、区块链、AI等技术始终保持着浓厚的兴趣,平时喜欢阅读、思考,相信持续学习、终身成长,欢迎一起交流学习。
微信公众号:DeepNoMind
本文由 mdnice 多平台发布