Java总结 - 基础知识
文章目录
- - - -计算机技术演化- - -
- 1 编程语言演化
-
- 1.1 写在最前
- 1.2 汇编
- 1.3 VB->C->C++
- 1.4 Java(Sun公司)
- 1.5 Java演变
- 2 技术思想
- - - -Java技术基础- - -
- 1 知识拓扑
- 2 面向对象
-
- 2.1 面向对象
- 2.2 类&对象
- 2.3 封装
- 2.4 继承
- 2.5 多态
- 3 反射
-
- 3.1 反射机制
-
- 3.1.1 Java代码运行过程
- 3.1.2 反射机制概念
- 3.2 Class对象及其方法
-
- 3.2.1 获取字节码对象
- 3.2.2 常用方法
- 3.3 反射机制应用a
-
- 3.3.1 案例分析
- 3.3.2 代码实现
- 3.4 反射机制应用b
- 4 异常&泛型&序列化&复制
-
- 4.1 异常
-
- 4.1.1 异常概念
- 4.1.2 异常分类
- 4.1.3 异常处理
- 4.1.4 使用@controllerAdvice处理异常
- 4.2 泛型
-
- 4.2.1 泛型概述
- 4.2.2 泛型使用
- 4.3 序列化
- 4.4 复制
- 5 数据结构与集合
-
- 5.1 数据结构
- 5.2 Java集合
-
- 5.2.1 集合类型及其特性
- 5.2.2 常见集合的特点
- 6 Java8新特性
-
- 6.1 Lambda表达式
-
- 6.1.1 概述
- 6.1.2 语法
- 6.1.3 函数式接口
- 6.1.4 Lambda表达式基本使用
- 6.1.5 变量捕获
- 6.1.6 Lambda表达式与集合
- 6.2 Stream
-
- 6.2.1 Stream概述
- 6.2.2 Stream的创建
- 6.2.3 类型说明
- 6.2.4 遍历/匹配(foreach/find/match)
- 6.2.5 筛选(filter)
- 6.2.6 聚合(max/min/count)
- 6.2.7 映射(map/flatMap)
- 6.2.8 归约(reduce)
- 6.2.9 收集(collect)
-
- 6.2.9.1 归集(toList/toSet/toMap)
- 6.2.9.2 统计(count/averaging)
- 6.2.9.3 分组(partitioningBy/groupingBy)
- 6.2.9.4 接合(joining)
- 6.2.9.5 归约(reducing)
- 6.2.10 排序(sorted)
- 6.2.11 提取/组合
- - -计算机技术演化- - -
1 编程语言演化
1.1 写在最前
此文用于个人总结,串接知识点,其整体结构为:
① 计算机技术演化;
② Java技术基础;
③ Java技术深入;
④ Spring技术;
⑤ DataBase;
⑥ 常用中间件。
1.2 汇编
举例:mov 、add
特点:程序量很大,几百行、几千行乃至几万行
1.3 VB->C->C++
面向过程->面向对象
特点:goto关键字、指针、内存管理、数据类型
1.4 Java(Sun公司)
特性:封装(封装成class)、继承(object)、多态(工厂模式、代理模式等)
JVM:编译流程、堆栈、类生成过程
GC:新生代、老年代、GC算法
1.5 Java演变
Applet,C/S架构的桌面程序
JSP + servlet,B/S架构
JavaEE、JavaSE,比较笨重,体量大
Spring,轻量化(高内聚 + 低耦合)
SSH,Struts、Spring和Hibernate(ORM框架)
SSI,Struts、Spring和iBatis(半ORM框架、轻量、灵活)
SSM,Spring、SpringMVC、Mybatis
SpringBoot
SpingCloud
2 技术思想
NoSQL思想:Redis、MongoDB
微服务思想:RPC、SpringCloud、Dubbo、Zookeeper
MQ思想:RocketMQ、RabbitMQ
心跳思想:Socket
- - -Java技术基础- - -
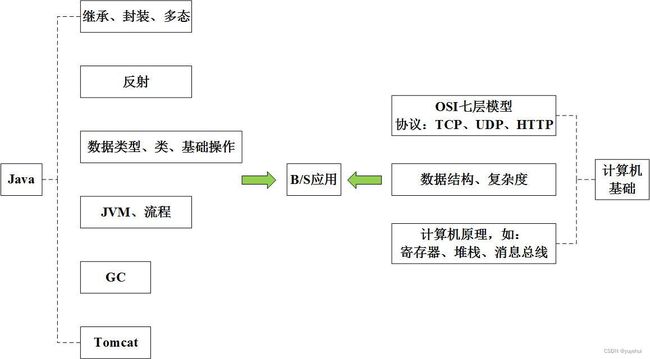
1 知识拓扑
Java知识拓扑
2 面向对象
2.1 面向对象
① 事物 -> 对象,万物皆对象;
② 把数据及其操作方法封装成一个整体,即对象;
③ 面向对象的思想为:A做XX事、B做XX事、C做XX事;
④ 面向过程的思想为:第1步做XX事、第2步做XX事、第3步做XX事。
2.2 类&对象
① 同类对象抽象出其共性,形成类;
② 类是对象的模板;
③ 对象是类的实例。
2.3 封装
① 定义:将对象的属性和行为封装成一个整体;
② 作用:封装私有成员数据,提供成员方法修改数据。
2.4 继承
① 定义:子类继承父类的特征和行为,class 子类 extends 父类 { };
② 特点:Java不支持多继承,支持多重继承;
③ 作用:提高了代码的复用性和维护性;
④ 作用:类和类产生了关系,是多态的前提。
2.5 多态
① 定 义:同一行为具有不同的表现形式,包括“方法多态”与“对象多态”;;
② 方法多态:包括“重载”和“重写”;
重载:单个类中,相同方法,参数不同,其功能不同;
重写:继承父类的多个子类中,相同方法,子类不同,其功能不同;
③ 对象多态:父类子类对象的转换,具体有“向上转型”和“向下转型”;
向上转型:子类对象变为父类对象,格式:父类 父类对象 = 子类实例;
向下转型:父类对象变为子类对象,格式:子类 子类对象 = (子类)父类实例;
④ 多态条件:继承、重写、父类引用指向子类对象;
⑤ 实现方式:重载与重写,抽象类与抽象方法,接口。
3 反射
3.1 反射机制
3.1.1 Java代码运行过程

如上图,Java代码在计算机中运行的三个阶段
① Source源代码阶段,java被编译成class文件;
② Class类对象阶段,类加载器将class文件加载进内存,并封装成Class类对象,将成员变量封装成Field[],将构造函数封装成Construction[],将成员方法封装成Method[];
③ RunTime运行时阶段,使用new创建对象的过程。
3.1.2 反射机制概念
1. 定义
在程序运行状态中,对于任意类或对象,都能获取其属性和方法(包括私有属性和方法),这种动态获取信息以及动态调用对象方法的功能就称为反射机制。
2. 优点
① 可以在程序运行过程中,操作这些对象;
② 可以解耦,提高程序的可扩展性。
3.2 Class对象及其方法
3.2.1 获取字节码对象
【Source源代码阶段】Class.forName(“全类名”):将字节码文件加载进内存,返回Class对象,多用于配置文件,将类名定义在配置文件中,读取配置文件加载类;
【Class类对象阶段】类名.class:通过类名的属性class获取,多用于参数的传递;
【Runtime运行时阶段】对象.getClass():该方法定义在Objec类中,所有的类都会继承此方法,多用于对象获取字节码。
3.2.2 常用方法
1. 获取包名 类名
clazz.getPackage().getName()//包名
clazz.getSimpleName()//类名
clazz.getName()//完整类名
2. 获取成员变量
getFields()//获取所有公开的成员变量,包括继承变量
getDeclaredFields()//获取本类定义的成员变量,包括私有,但不包括继承的变量
getField(变量名)
getDeclaredField(变量名)
3. 获取构造方法
getConstructor(参数类型列表)//获取公开的构造方法
getConstructors()//获取所有的公开的构造方法
getDeclaredConstructors()//获取所有的构造方法,包括私有
getDeclaredConstructor(int.class,String.class)
4. 获取成员方法
getMethods()//获取所有可见的方法,包括继承的方法
getMethod(方法名,参数类型列表)
getDeclaredMethods()//获取本类定义的的方法,包括私有,不包括继承的方法
getDeclaredMethod(方法名,int.class,String.class)
5. 反射新建实例
clazz.newInstance();//执行无参构造创建对象
clazz.newInstance(666,”海绵宝宝”);//执行含参构造创建对象
clazz.getConstructor(int.class,String.class)//获取构造方法
6. 反射调用成员变量
clazz.getDeclaredField(变量名);//获取变量
clazz.setAccessible(true);//使私有成员允许访问
f.set(实例,值);//为指定实例的变量赋值,静态变量,第一参数给null
f.get(实例);//访问指定实例变量的值,静态变量,第一参数给null
7. 反射调用成员方法
Method m = Clazz.getDeclaredMethod(方法名,参数类型列表);
m.setAccessible(true);//使私有方法允许被调用
m.invoke(实例,参数数据);//让指定实例来执行该方法
3.3 反射机制应用a
3.3.1 案例分析
1. 需求
实现"框架",要求不改变该类的任何代码,可以创建任意类的对象,并且执行类的任意方法。
2. 实现
① 配置文件;
② 反射机制.
3. 步骤
① 将需要创建的对象的全类名和需要执行的方法定义在配置文件中;
② 在程序中加载读取配置文件;
③ 使用反射技术把类文件加载进内存;
④ 创建对象;
⑤ 执行方法.
3.3.2 代码实现
1. 实体类
public class Person {
public void eat(){
System.out.println("eat...");
}
}
public class Student {
public void study(){
System.out.println("I am a Student");
}
}
2. 两种配置文件
//配置文件1
className = zzuli.edu.cn.Person
methodName = eat
//配置文件2
//className = zzuli.edu.cn.Student
//methodName = study
3. 框架
public class ReflectTest {
public static void main(String[] args) throws Exception {
//1.加载配置文件
//1.1创建Properties对象
Properties pro = new Properties();
//1.2加载配置文件
//1.2.1获取class目录下的配置文件(使用类加载器)
ClassLoader classLoader = ReflectTest.class.getClassLoader();
InputStream inputStream = classLoader.getResourceAsStream("pro.properties");
pro.load(inputStream);
//2.获取配置文件中定义的数据
String className = pro.getProperty("className");
String methodName = pro.getProperty("methodName");
//3.加载该类进内存
Class cls = Class.forName(className);
//4.创建对象
Object obj = cls.newInstance();
//5.获取方法对象
Method method = cls.getMethod(methodName);
//6.执行方法
method.invoke(obj);
}
}
4. 两种运行结果

3.4 反射机制应用b
通过反射创建任意类的对象,并且执行类的任意方法。
package com.yuEntity;
import lombok.Data;
@Data
public class Student {
public Student() {
}
public void show(){
System.out.println("I am a student!");
}
}
package com.yuEntity;
import lombok.Data;
@Data
public class Teacher {
private String name;
private int age;
public Teacher(String name, int age) {
this.name = name;
this.age = age;
}
public void show(){
System.out.println("I am a teacher!");
}
}
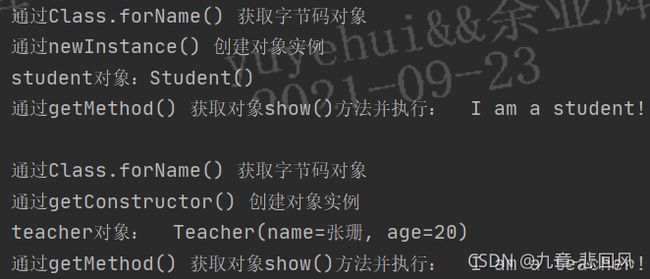
public class TestReflection {
@Test
public void testReflection() throws Exception {
System.out.println("通过Class.forName() 获取字节码对象");
Class clsStudent = Class.forName("com.yuEntity.Student");
System.out.println("通过newInstance() 创建对象实例");
Object student = clsStudent.newInstance();
System.out.println("student对象:" + student);
System.out.print("通过getMethod() 获取对象show()方法并执行: ");
Method method = clsStudent.getMethod("show");
method.invoke(student);
System.out.println("");
System.out.println("通过Class.forName() 获取字节码对象");
Class clsTeacher = Class.forName("com.yuEntity.Teacher");
Class[] teacherCls = new Class[]{String.class, int.class};
System.out.println("通过getConstructor() 创建对象实例");
Object teacher = clsTeacher.getConstructor(teacherCls).newInstance("张珊",20);
System.out.println("teacher对象: " + teacher);
System.out.print("通过getMethod() 获取对象show()方法并执行: ");
method = clsTeacher.getMethod("show");
method.invoke(teacher);
}
}
4 异常&泛型&序列化&复制
4.1 异常
4.1.1 异常概念
定义:程序运行过程中出现的错误,称为异常。
原因:
输入非法数据;
要打开的文件不存在;
网络通信时连接中断,或者JVM内存溢出。
4.1.2 异常分类
1. 分类

2. Error
JVM相关错误,无法处理,如系统崩溃,内存不足,方法调用栈溢等。
3. Exception
可处理的异常,可捕获且可能恢复。
4.1.3 异常处理

注意:
try/catch后面的finally块非强制性要求;
try后不能既没catch也没finally;
try, catch, finally块之间不能添加任何代码;
finally代码一定会执行(除了JVM退出)。
4.1.4 使用@controllerAdvice处理异常
4.2 泛型
4.2.1 泛型概述
1. 定义
泛型,即参数化类型。定义类、接口和方法时,其数据类型可被指定为参数。
2. 类型擦除
泛型在编译阶段有效,不进入运行阶段,编译生成的字节码文件不包含泛型中的类型信息,该过程称为类型擦除。如定义List< Object >和 List< String >,编译后变成List。
4.2.2 泛型使用
1. 泛型类
//在实例化泛型类时,必须指定T的具体类型
public class Generic<T>{
private T key;
public Generic(T key) {
this.key = key;
}
public T getKey(){
return key;
}
}
//泛型的类型参数是类类型(包括自定义类)
Generic<Integer> genericInteger = new Generic<Integer>(123456);
Generic<String> genericString = new Generic<String>("key_vlaue");
2. 泛型接口
//泛型接口
public interface Generator<T> {
public T next();
}
//未传入泛型实参,需将泛型的声明加到类中
class FruitGenerator<T> implements Generator<T>{
@Override
public T next() {
return null;
}
}
//传入泛型实参,T换成实参类型
public class FruitGenerator implements Generator<String> {
private String[] fruits = new String[]{"Apple", "Banana", "Pear"};
@Override
public String next() {
Random rand = new Random();
return fruits[rand.nextInt(3)];
}
}
3. 泛型通配符
操作类型时,若不使用类型具体功能,只使用Object类的功能,可用通配符“?”定义未知类型。
public void showKeyValue(Generic<Number> obj){
Log.d("泛型测试","key value is " + obj.getKey());
}
public void showKeyValue1(Generic<?> obj){
Log.d("泛型测试","key value is " + obj.getKey());
}
//Integer是Number的子类
Generic<Integer> gInteger = new Generic<Integer>(123);
Generic<Number> gNumber = new Generic<Number>(456);
showKeyValue(gNumber);
showKeyValue(gInteger);// 报错
showKeyValue1(gNumber);
showKeyValue1(gInteger);
4. 泛型方法
①基本泛型方法
public class GenericTest {
//泛型类
public class Generic<T>{
private T key;
public Generic(T key) {
this.key = key;
}
//getKey使用泛型,但不是泛型方法,普通的成员方法
public T getKey(){
return key;
}
/* setKey错误,类中并未声明泛型E
public E setKey(E key){
this.key = keu
}*/
}
/* showKeyName为泛型方法
public与返回值之间的必不可少,泛型数量可为多个,如:
public K showKeyName(Generic container){
}*/
public <T> T showKeyName(Generic<T> container){
System.out.println("container key :" + container.getKey());
T test = container.getKey();
return test;
}
//showKeyValue1为普通方法
public void showKeyValue1(Generic<Number> obj){
Log.d("泛型测试","key value is " + obj.getKey());
}
//showKeyValue2为普通方法
public void showKeyValue2(Generic<?> obj){
Log.d("泛型测试","key value is " + obj.getKey());
}
/*showKeyName错误,未声明泛型E
public T showKeyName(Generic container){
...
}*/
/*showkey错误,未声明泛型T
public void showkey(T genericObj){
...
}*/
public static void main(String[] args) {
}
}
②泛型类中的泛型方法
//泛型类
public class Generic<T>{
public void show_1(T t){
System.out.println(t.toString());
}
//泛型类中泛型方法,泛型E可与类中T不同
public <E> void show_2(E e){
System.out.println(e.toString());
}
//泛型类中泛型方法,泛型T是新类型,可以和泛型类中T不同
public <T> void show_3(T t){
System.out.println(t.toString());
}
}
③泛型方法的可变参数
public <T> void printMsg( T... args){
for(T t : args){
Log.d("泛型测试","t is " + t);
}
}
printMsg("111",222,"aaaa","2323.4",55.55);
④静态方法要使用泛型,必须定义成泛型方法
public class StaticGenerator<T> {
public static <T> void show1(T t){
}
//show2方法错误
public static void show2(T t){
}
}
5. 泛型上下边界
① 泛型方法的上下边界,必须与泛型声明在一起
//泛型方法添加上下边界时,必须在上添加上下边界
public <T extends Number> T showKeyName(Generic<T> container){
System.out.println("container key :" + container.getKey());
T test = container.getKey();
return test;
}
②泛型上边界,例1
public class Generic<T>{
private T key;
public Generic(T key) {
this.key = key;
}
public T getKey(){
return key;
}
}
public void showKeyValue1(Generic<? extends Number> obj){
Log.d("泛型测试","key value is " + obj.getKey());
}
Generic<String> generic1 = new Generic<String>("11111");
Generic<Integer> generic2 = new Generic<Integer>(2222);
Generic<Float> generic3 = new Generic<Float>(2.4f);
Generic<Double> generic4 = new Generic<Double>(2.56);
showKeyValue1(generic1);//报错,String不是Number的子类
showKeyValue1(generic2);
showKeyValue1(generic3);
showKeyValue1(generic4);
②泛型上边界,例2
public class Generic<T extends Number>{
private T key;
public Generic(T key) {
this.key = key;
}
public T getKey(){
return key;
}
}
Generic<String> generic1 = new Generic<String>("11111");//报错,String不是Number子类
4.3 序列化
1. 定义
Java序列化是指把Java对象转换为字节流,便于传输和保存;Java反序列化是指把字节流恢复为Java对象。
2. 实现
实现 java.io.Serializable接口。
4.4 复制
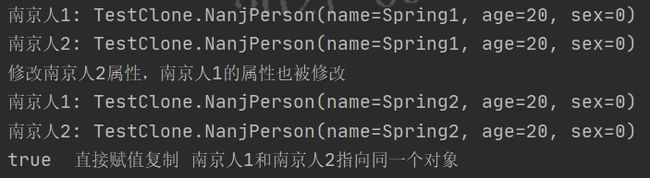
1. 直接赋值复制
直接赋值时, A a1 = a2; 实际上复制的是引用,也就是说a1和a2指向的是同一个对象,当a1变化时,a2的成员变量也会跟着变化。
@Data
public class NanjPerson{
private String name;
private int age;
private int sex;
public NanjPerson(String name, int age, int sex) {
this.name = name;
this.age = age;
this.sex = sex;
}
}
/*@description 一般复制*/
@Test
public void testNanjPersonClone(){
NanjPerson person1 = new NanjPerson("Spring1",20,0);
NanjPerson person2 = person1;
System.out.println("南京人1: " + person1.toString());
System.out.println("南京人2: " + person2.toString());
person2.setName("Spring2");
System.out.println("修改南京人2属性,南京人1的属性也被修改");
System.out.println("南京人1: " + person1.toString());
System.out.println("南京人2: " + person2.toString());
System.out.print( person1 == person2);
if(person1 == person2){
System.out.println(" 直接赋值复制 南京人1和南京人2指向同一个对象");
}else {
System.out.println(" 直接赋值复制 南京人1和南京人2指向不同的对象");
}
}
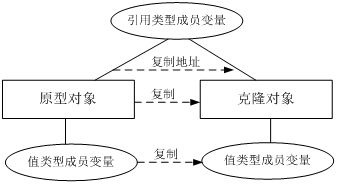
2. 浅拷贝
浅拷贝中,当对象被复制时只复制它本身和其中包含的值类型的成员变量,而引用类型的成员对象并没有复制。
@Data
public class AddressA{
private String addr;
public AddressA(String addrIn) {
this.addr = addrIn;
}
}
@Data
public class WuxPersonA implements Cloneable{
private String name;
private int age;
private int sex;
private AddressA address;
public WuxPersonA(String name, int age, int sex, AddressA address) {
this.name = name;
this.age = age;
this.sex = sex;
this.address = address;
}
@Override
public Object clone() {
WuxPersonA person = null;
try {
person = (WuxPersonA)super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return person;
}
}
/*浅拷贝*/
@Test
public void testWuxPersonAClone(){
WuxPersonA personA1 = new WuxPersonA("SpringA1",20,0,new AddressA("无锡A1"));
WuxPersonA personA2 = (WuxPersonA) personA1.clone();
System.out.println("无锡人A1: " + personA1.toString());
System.out.println("无锡人A2: " + personA2.toString());
personA2.setName("SpringA2");
personA2.address.setAddr("无锡A2");
System.out.println("修改无锡人A2属性 ,无锡人A1的属性里 WuxPersonA中AddressA类有问题 其他属性无问题");
System.out.println("无锡人A1: " + personA1.toString());
System.out.println("无锡人A2: " + personA2.toString());
System.out.print( personA1 == personA2);
if(personA1 == personA2){
System.out.println(" 浅拷贝 对象里面含有另一对象 无锡人A1和无锡人A2指向同一个对象");
}else {
System.out.println(" 浅拷贝 对象里面含有另一对象 无锡人A1和无锡人A2的WuxPersonA不是同一个对象 AddressA是同一个对象 ");
}
}

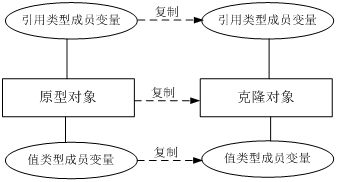
3. 深拷贝
深拷贝中,除了对象本身被复制外,对象所包含的所有成员变量也将复制。
@Data
public class AddressB implements Cloneable{
private String addr;
public AddressB(String addrIn) {
this.addr = addrIn;
}
@Override
public Object clone() {
AddressB addr = null;
try {
addr = (AddressB) super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return addr;
}
}
@Data
public class WuxPersonB implements Cloneable{
private String name;
private int age;
private int sex;
private AddressB addressB;
public WuxPersonB(String name, int age, int sex, AddressB addressB) {
this.name = name;
this.age = age;
this.sex = sex;
this.addressB = addressB;
}
@Override
public Object clone() {
WuxPersonB person = null;
try {
person = (WuxPersonB)super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
person.addressB = (AddressB) addressB.clone();
return person;
}
}
/*深拷贝*/
@Test
public void testWuxPersonBClone(){
WuxPersonB personB1 = new WuxPersonB("SpringB1",20,0,new AddressB("无锡B1"));
WuxPersonB personB2 = (WuxPersonB) personB1.clone();
System.out.println("无锡人B1: " + personB1.toString());
System.out.println("无锡人B2: " + personB2.toString());
personB2.setName("SpringB2");
personB2.addressB.setAddr("无锡B2");
System.out.println("修改无锡人B2属性,无锡人B1的属性保持不变 包括WuxPersonA中AddressA类无问题");
System.out.println("无锡人B1: " + personB1.toString());
System.out.println("无锡人B2: " + personB2.toString());
System.out.print( personB1 == personB2);
if(personB1 == personB2){
System.out.println(" 深拷贝 无锡人B1和无锡人B2指向同一个对象");
}else {
System.out.println(" 深拷贝 无锡人B1和无锡人B2指向不同的对象 包括WuxPersonA对象中AddressA对象");
}
}

4. 序列化深拷贝
@Data
public class Car implements Serializable{
private static final long serialVersionUID = -4694790051431625830L;
private String brand;
private int price;
public Car(String brand, int price) {
this.brand = brand;
this.price = price;
}
}
@Data
public class Person implements Serializable{
private static final long serialVersionUID = 7913723651426251020L;
private String name;
private int age;
private int sex;
private Car car;
public Person(String name, int age, int sex, Car car) {
this.name = name;
this.age = age;
this.sex = sex;
this.car = car;
}
}
/*序列化拷贝工具类*/
public static class CloneUtil{
public static <T extends Serializable> T clone(T obj) throws Exception{
//序列化 将obj对象的内容进行流化,转化为字节序列写到内存的字节数组中
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(obj);
//反序列化 读取内存中字节数组的内容,重新转换为java对象返回
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
return (T) ois.readObject();
}
}
/*序列化实现深拷贝*/
@Test
public void testPersonClone() throws Exception {
Person person1 = new Person("Spring1",20,0,new Car("奥迪",300000));
Person person2 = CloneUtil.clone(person1);
System.out.println("person2: " + person2.toString());
System.out.println("person2: " + person2.toString());
person2.setName("Spring2");
person2.getCar().setBrand("奔驰");
System.out.println("修改person2的属性 person1的属性保持不变 包括Person中car类无问题");
System.out.println("person1: " + person1.toString());
System.out.println("person2: " + person2.toString());
System.out.print( person1 == person2);
if(person1 == person2){
System.out.println(" 序列化实现深拷贝 person1和person2指向同一个对象");
}else {
System.out.println(" 序列化实现深拷贝 person1和person2指向不同的对象 包括Person中car对象");
}
}

5. 反射复制对象
@Data
public class Programmer {
private String corporation;
private String university; //学校名称
private Car car;
public Programmer(String corporation, String university, Car car) {
this.corporation = corporation;
this.university = university;
this.car = car;
}
}
@Data
public class Doctor {
private String corporation;
private int university; //学校编码
private Car car;
public Doctor() {}
public Doctor(String corporation, int university, Car car) {
this.corporation = corporation;
this.university = university;
this.car = car;
}
}
/*两个对象相同属性值复制*/
public static void CopyByReflection(Object source, Object dest) throws Exception {
//获取属性
BeanInfo sourceBean = Introspector.getBeanInfo(source.getClass(), java.lang.Object.class);
PropertyDescriptor[] sourceProperty = sourceBean.getPropertyDescriptors();
BeanInfo destBean = Introspector.getBeanInfo(dest.getClass(), java.lang.Object.class);
PropertyDescriptor[] destProperty = destBean.getPropertyDescriptors();
try {
for (int i = 0; i < sourceProperty.length; i++) {
for (int j = 0; j < destProperty.length; j++) {
if (sourceProperty[i].getName().equals(destProperty[j].getName())
&& sourceProperty[i].getPropertyType().equals(destProperty[j].getPropertyType())) {
//调用source的getter方法和dest的setter方法
destProperty[j].getWriteMethod().invoke(dest, sourceProperty[i].getReadMethod().invoke(source));
break;
}
}
}
} catch (Exception e) {
throw new Exception("属性复制失败:" + e.getMessage());
}
}
/*通过反射复制对象*/
@Test
public void testCloneByReflection() throws Exception {
Programmer programmer = new Programmer("Corporation-a","北京大学",new Car("奔驰",300000));
Doctor doctor = new Doctor();
CopyByReflection(programmer,doctor);
System.out.println("programmer对象: " + programmer.toString());
System.out.println("doctor对象: " + doctor.toString());
System.out.println("programmer对象和doctor对象,university的类型不同,故复制失败");
doctor.setCorporation("Corporation-b");
doctor.car.setBrand("宝马");
System.out.println("programmer对象: " + programmer.toString());
System.out.println("doctor对象: " + doctor.toString());
System.out.println("programmer对象中,car对象的复制,属于浅复制");
}

5 数据结构与集合
5.1 数据结构
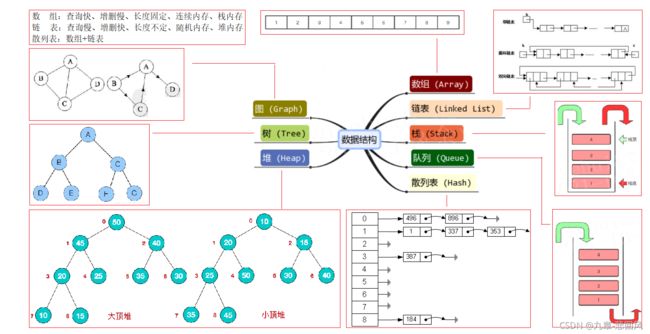
常见数据结构包括:数组、 链表、 栈、队列、树、散列表、图、堆,其结构如下图:
5.2 Java集合
5.2.1 集合类型及其特性
数组/Array:查询快、增删慢、长度固定、连续内存、栈内存
链表/LinkList:查询慢、增删快、长度不定、随机内存、堆内存
散列表/哈希表/HashTable:数组+链表
Map/键值对:HashMap、LinkedHashMap、TreeMap、HashTable
List/动态数组:ArrayList、LinkedList、Vector
set/去重:HashSet、LinkedHashSet、TreeSet
5.2.2 常见集合的特点
| 集合类型 | 安全性 | 有序性 | 结构 | 复杂度 |
|---|---|---|---|---|
| HashMap | 线程不安全 | 数据无序 | 数组+链表+红黑树 | 增删查/O(1)、O(n)、O(log(n)) |
| LinkedHashMap | 线程不安全 | 数据有序 | HashMap+双向链表 (双向链表记录插入顺序) |
增删查/O(1)、O(n)、O(log(n)) |
| TreeMap | 线程不安全 | 数据有序 可排序 | 红黑树 (根据主键自动排序) |
增删查/O(log(n)) |
| HashTable | 线程安全 | 数据无序 | 数组+链表 | 增删查/O(1)、O(n) |
| - | ||||
| ArrayList | 线程不安全 | 数据有序 | 数组 | 查询快/O(1)、非尾部增删慢/O(n) |
| LinkedList | 线程不安全 | 数据有序 | 双向链表 | 查询慢/O(n)、增删快/O(1) |
| vector | 线程安全 | 数据有序 | 数组 | 查询快/O(1)、非尾部增删慢/O(n) |
| - | ||||
| HashSet | 线程不安全 | 数据无序 | HashTable | 增删查/O(1)、O(n) |
| LinkedHashSet | 线程不安全 | 数据有序 | HashTable+链表 (链表记录插入顺序) |
增删查/O(1)、O(n) |
| TreeSet | 线程不安全 | 数据有序 可排序 | 红黑树 (根据主键自动排序) |
增删查/O(log(n)) |
6 Java8新特性
6.1 Lambda表达式
6.1.1 概述
Lambda表达式可理解为将代码块或者函数作为方法的参数进行传递,使代码更简洁。
6.1.2 语法
1. 语法
语法: (parameters) -> expression 或者 (parameters) ->{ statements; };
其中, -> 为Lambda 操作符,该操作符将Lambda表达式分为两部分,左侧为Lambda表达式的参数列表,右侧为Lambda体,即Lambda表达式要执行的功能,Lambda 表达式可以看作为匿名函数。
2. 语法精简
① 每个参数的类型均可省略;
② 若参数列表只有一个参数,可省略小括号;
③ 若方法体中只有一句代码,可省略大括号;
④ 若方法体中只有一句代码,且是return语句,可省略大括号和return关键字。
3. 示例
// 不需要参数,返回2
() -> 2
// 接收1个参数(数字类型),返回其2倍的值
x -> 2 * x
// 接受2个参数(数字),并返回他们的和
(x, y) -> x + y
// 接收2个int型整数,返回他们的乘积
(int x, int y) -> x * y
// 接受1个string对象,并在控制台打印,不返回任何值
(String s) -> System.out.print(s)
6.1.3 函数式接口
① 若接口只有一个抽象方法,则该接口为函数式接口;
② 在接口上添加 @FunctionalInterface 注解,编译器则按照函数式接口的定义检测该接口。
6.1.4 Lambda表达式基本使用
1. 无返回函数式接口
//无返回值无参数
@FunctionalInterface
interface NoParameterNoReturn {
void test();
}
//无返回值一个参数
@FunctionalInterface
interface OneParameterNoReturn {
void test(int a);
}
//无返回值两个参数
@FunctionalInterface
interface MoreParameterNoReturn {
void test(int a,int b);
}
public class TestDemo {
public static void main(String[] args) {
NoParameterNoReturn n = ()->{
System.out.println("无参数无返回值");
};
n.test();
OneParameterNoReturn o = (a)-> {
System.out.println("无返回值一个参数"+a);
};
o.test(666);
MoreParameterNoReturn m = (int a,int b)->{
System.out.println("无返回值两个参数"+a+" "+b);
};
m.test(666,999);
}
}
2. 有返回函数式接口
//有返回值无参数
@FunctionalInterface
interface NoParameterReturn {
int test();
}
//有返回值一个参数
@FunctionalInterface
interface OneParameterReturn {
int test(int a);
}
//有返回值多个参数
@FunctionalInterface
interface MoreParameterReturn {
int test(int a,int b);
}
public class TestDemo {
public static void main(String[] args) {
NoParameterReturn n = ()->{
return 666;
};
int ret1 = n.test();
System.out.println(ret1);
System.out.println("================");
OneParameterReturn o = (int a)->{
return a;
};
int ret2 = o.test(999);
System.out.println(ret2);
System.out.println("================");
MoreParameterReturn m = (int a,int b)-> {
return a+b;
};
int ret3 = m.test(10,90);
System.out.println(ret3);
}
}
6.1.5 变量捕获
匿名内部类中,只能捕获程序运行过程中没有发生改变的量,Lambda表达式,同样只能捕获程序运行过程中没有发生改变的量。
1. 匿名内部类变量捕获
class Test {
public void func(){
System.out.println("void func()");
}
}
public class TestDemo{
public static void main(String[] args) {
int a = 10;
new Test(){
//a = 20; error
@Override
public void func(){
System.out.println("捕获变量:"+a);
}
};
}
}
2. Lambda表达式变量捕获
@FunctionalInterface
interface NoParameterNoReturn {
void test();
}
public static void main(String[] args) {
int a = 10;
NoParameterNoReturn noParameterNoReturn = ()->{
// a = 99; error
System.out.println("捕获变量:"+a);
};
noParameterNoReturn.test();
}
6.1.6 Lambda表达式与集合
Java8中关于集合新增的方法有很多,本文介绍常用的如下。
使用forEach()遍历集合,包括List和Map,若要操作元素,需要实现 Consumer接口并重写accept()方法,accept()方法中为元素操作逻辑。使用sort()排序,需要实现Comparator接口并重写compare()方法。
1. List和foreach、sort
public class TestDemo {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you"));
System.out.println("Java7及以前 使用增强for循环实现");
for(String str : list){
System.out.println(str);
}
System.out.println("使用forEach()结合匿名内部类实现");
list.forEach(new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
});
System.out.println("使用forEach()结合Lambda表达式实现");
list.forEach( str -> {
System.out.println(str);
});
System.out.println("使用forEach()结合Lambda表达式实现 简化模式");
list.forEach(a-> System.out.println(a));
}
}
public class YuTest {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you"));
System.out.println("使用sort()结合匿名内部类实现");
list.sort(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o1.compareTo(o2);
}
});
System.out.println(list);
System.out.println("使用sort()结合Lambda表达式实现");
//Lambda方法
list.sort((o1,o2)->o2.compareTo(o1));
System.out.println(list);
}
}
2. HashMap和foreach
public static void main(String[] args) {
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
System.out.println("Java7以及之前迭代Map");
for(Map.Entry<Integer, String> entry : map.entrySet()){
System.out.println(entry.getKey() + "=" + entry.getValue());
}
System.out.println("使用forEach()结合匿名内部类实现");
map.forEach(new BiConsumer<Integer, String>(){
@Override
public void accept(Integer k, String v){
System.out.println(k + "=" + v);
}
});
System.out.println("使用forEach()结合Lambda表达式实现");
map.forEach((k,v)-> System.out.println("key = " + k + " value = " + v));
}
6.2 Stream
6.2.1 Stream概述
1. 定义
Stream将要处理的元素集合看作一种流,在流过程中,借助Stream API对流中的元素进行操作,比如:筛选、排序、聚合等,如下图。


2. 操作
Stream由数组或集合创建,流操作分为两种:① 中间操作,每次返回一个或多个新流;② 终端操作,每个流只能进行一次终端操作,终端操作结束后流无法再次使用,并产生一个新的集合或值。
3. 特性
① stream不存储数据,而是按照特定的规则对数据进行计算,一般会输出结果;
② stream不会改变数据源,通常情况下会产生一个新的集合或一个值;
③ stream具有延迟执行特性,只有调用终端操作时,中间操作才会执行。
6.2.2 Stream的创建
1. 创建
流创建有3种方式方式,分别为:① 通过 java.util.Collection.stream() 方法用集合创建;② 使用java.util.Arrays.stream(T[] array)方法用数组创建;③ 使用Stream的of()、iterate()、generate()方法创建。
List<String> list = Arrays.asList("a", "b", "c");
// 创建一个顺序流
Stream<String> stream = list.stream();
// 创建一个并行流
Stream<String> parallelStream = list.parallelStream();
int[] array={1,3,5,6,8};
IntStream stream = Arrays.stream(array);
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 6);
Stream<Integer> stream2 = Stream.iterate(0, (x) -> x + 3).limit(4);
stream2.forEach(System.out::println);
Stream<Double> stream3 = Stream.generate(Math::random).limit(3);
stream3.forEach(System.out::println);
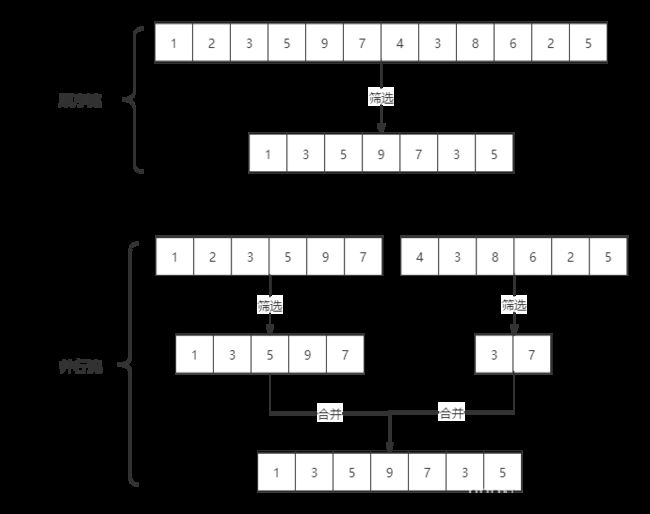
2. 顺序流和并行流
stream是顺序流,由主线程操作流,parallelStream是并行流,以多线程并行操作流,前提是流的数据处理没有顺序要求。例如筛选集合中奇数,两者处理不同,如下图。
通过parallel()可将顺序流转换成并行流。
Optional<Integer> findFirst = list.stream().parallel().filter(x->x>6).findFirst();
6.2.3 类型说明
Stream中元素类型是Optional,Optional类是一个可以为null的容器对象,如果值存,在则isPresent()方法会返回true,调用get()方法会返回该对象,案例使用实体类如下。
class Person {
private String name; // 姓名
private int salary; // 薪资
private int age; // 年龄
private String sex; //性别
private String area; // 地区
// 构造方法
public Person(String name, int salary, int age,String sex,String area) {
this.name = name;
this.salary = salary;
this.age = age;
this.sex = sex;
this.area = area;
}
}
6.2.4 遍历/匹配(foreach/find/match)
Stream类似集合,支持遍历和元素匹配,Stream的遍历、匹配非常简单,如下。
public class StreamTest {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(7, 6, 9, 3, 8, 2, 1);
// 遍历输出符合条件的元素
list.stream().filter(x -> x > 6).forEach(System.out::println);
// 匹配第一个
Optional<Integer> findFirst = list.stream().filter(x -> x > 6).findFirst();
// 匹配任意(适用于并行流)
Optional<Integer> findAny = list.parallelStream().filter(x -> x > 6).findAny();
// 是否包含符合特定条件的元素
boolean anyMatch = list.stream().anyMatch(x -> x > 6);
System.out.println("匹配第一个值:" + findFirst.get());
System.out.println("匹配任意一个值:" + findAny.get());
System.out.println("是否存在大于6的值:" + anyMatch);
}
}
6.2.5 筛选(filter)
筛选,按照一定的规则校验流中的元素,将符合条件的元素提取到新的流中的操作。
如下案例分别为:① 筛选并打印Integer集合中大于7的元素;② 筛选员工中工资高于8000的人形成新的集合,形成新集合依赖collect(收集)。
public class StreamTest {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(6, 7, 3, 8, 1, 2, 9);
Stream<Integer> stream = list.stream();
stream.filter(x -> x > 7).forEach(System.out::println);
}
}
public class StreamTest {
public static void main(String[] args) {
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("Tom", 8900, 23, "male", "New York"));
personList.add(new Person("Jack", 7000, 25, "male", "Washington"));
personList.add(new Person("Lily", 7800, 21, "female", "Washington"));
personList.add(new Person("Anni", 8200, 24, "female", "New York"));
personList.add(new Person("Owen", 9500, 25, "male", "New York"));
personList.add(new Person("Alisa", 7900, 26, "female", "New York"));
List<String> fiterList = personList.stream().filter(x -> x.getSalary() > 8000).map(Person::getName).collect(Collectors.toList());
System.out.print("高于8000的员工姓名:" + fiterList);
}
}
6.2.6 聚合(max/min/count)
MySQL中可使用max、min、count进行数据统计,Stream中也引入了这种用法,方便对集合、数组的数据进行统计。
如下案例分别为:① 获取集合中最长的元素;② 获取集合中的最大值;③ 获取员工工资最高的人;④ 计算集合中大于6的元素的个数。
public class StreamTest {
public static void main(String[] args) {
List<String> list = Arrays.asList("adnm", "admmt", "pot", "xbangd", "weoujgsd");
Optional<String> max = list.stream().max(Comparator.comparing(String::length));
System.out.println("最长的字符串:" + max.get());
}
}
public class StreamTest {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(7, 6, 9, 4, 11, 6);
// 自然排序
Optional<Integer> max = list.stream().max(Integer::compareTo);
// 自定义排序
Optional<Integer> max2 = list.stream().max(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o1.compareTo(o2);
}
});
System.out.println("自然排序的最大值:" + max.get());
System.out.println("自定义排序的最大值:" + max2.get());
}
}
public class StreamTest {
public static void main(String[] args) {
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("Tom", 8900, 23, "male", "New York"));
personList.add(new Person("Jack", 7000, 25, "male", "Washington"));
personList.add(new Person("Lily", 7800, 21, "female", "Washington"));
personList.add(new Person("Anni", 8200, 24, "female", "New York"));
personList.add(new Person("Owen", 9500, 25, "male", "New York"));
personList.add(new Person("Alisa", 7900, 26, "female", "New York"));
Optional<Person> max = personList.stream().max(Comparator.comparingInt(Person::getSalary));
System.out.println("员工工资最大值:" + max.get().getSalary());
}
}
public class StreamTest {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(7, 6, 4, 8, 2, 11, 9);
long count = list.stream().filter(x -> x > 6).count();
System.out.println("list中大于6的元素个数:" + count);
}
}
6.2.7 映射(map/flatMap)
将一个流按照规则映射到另一个流,映射有两种,分别为:① map,接收一个函数作为参数,将该函数应用到元素上,并将其映射成新元素;② flatMap,接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。
如下案例分别为:① 英字符串数组元素改为大写,整数数组每个元素加3;② 员工薪资增加1000;③ 将两个字符数组合并成一个新字符数组。
public class StreamTest {
public static void main(String[] args) {
String[] strArr = { "abcd", "bcdd", "defde", "fTr" };
List<String> strList = Arrays.stream(strArr).map(String::toUpperCase).collect(Collectors.toList());
List<Integer> intList = Arrays.asList(1, 3, 5, 7, 9, 11);
List<Integer> intListNew = intList.stream().map(x -> x + 3).collect(Collectors.toList());
System.out.println("每个元素大写:" + strList);
System.out.println("每个元素+3:" + intListNew);
}
}
public class StreamTest {
public static void main(String[] args) {
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("Tom", 8900, 23, "male", "New York"));
personList.add(new Person("Jack", 7000, 25, "male", "Washington"));
personList.add(new Person("Lily", 7800, 21, "female", "Washington"));
personList.add(new Person("Anni", 8200, 24, "female", "New York"));
personList.add(new Person("Owen", 9500, 25, "male", "New York"));
personList.add(new Person("Alisa", 7900, 26, "female", "New York"));
// 不改变原来员工集合的方式
List<Person> personListNew = personList.stream().map(person -> {
Person personNew = new Person(person.getName(), 0, 0, null, null);
personNew.setSalary(person.getSalary() + 10000);
return personNew;
}).collect(Collectors.toList());
System.out.println("一次改动前:" + personList.get(0).getName() + "-->" + personList.get(0).getSalary());
System.out.println("一次改动后:" + personListNew.get(0).getName() + "-->" + personListNew.get(0).getSalary());
// 改变原来员工集合的方式
List<Person> personListNew2 = personList.stream().map(person -> {
person.setSalary(person.getSalary() + 10000);
return person;
}).collect(Collectors.toList());
System.out.println("二次改动前:" + personList.get(0).getName() + "-->" + personListNew.get(0).getSalary());
System.out.println("二次改动后:" + personListNew2.get(0).getName() + "-->" + personListNew.get(0).getSalary());
}
}
public class StreamTest {
public static void main(String[] args) {
List<String> list = Arrays.asList("m,k,l,a", "1,3,5,7");
List<String> listNew = list.stream().flatMap(s -> {
// 将每个元素转换成一个stream
String[] split = s.split(",");
Stream<String> s2 = Arrays.stream(split);
return s2;
}).collect(Collectors.toList());
System.out.println("处理前的集合:" + list);
System.out.println("处理后的集合:" + listNew);
}
}
6.2.8 归约(reduce)
归约,也称缩减,可把一个流缩减成一个值,能实现对集合求和、求乘积、求最值。如下案例分别为:① 求Integer集合的元素之和、乘积和最大值;② 求所有员工的工资之和和最高工资。
public class StreamTest {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1, 3, 2, 8, 11, 4);
// 求和方式1
Optional<Integer> sum = list.stream().reduce((x, y) -> x + y);
// 求和方式2
Optional<Integer> sum2 = list.stream().reduce(Integer::sum);
// 求和方式3
Integer sum3 = list.stream().reduce(0, Integer::sum);
// 求乘积
Optional<Integer> product = list.stream().reduce((x, y) -> x * y);
// 求最大值方式1
Optional<Integer> max = list.stream().reduce((x, y) -> x > y ? x : y);
// 求最大值写法2
Integer max2 = list.stream().reduce(1, Integer::max);
System.out.println("list求和:" + sum.get() + "," + sum2.get() + "," + sum3);
System.out.println("list求积:" + product.get());
System.out.println("list求和:" + max.get() + "," + max2);
}
}
public class StreamTest {
public static void main(String[] args) {
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("Tom", 8900, 23, "male", "New York"));
personList.add(new Person("Jack", 7000, 25, "male", "Washington"));
personList.add(new Person("Lily", 7800, 21, "female", "Washington"));
personList.add(new Person("Anni", 8200, 24, "female", "New York"));
personList.add(new Person("Owen", 9500, 25, "male", "New York"));
personList.add(new Person("Alisa", 7900, 26, "female", "New York"));
// 求工资之和方式1:
Optional<Integer> sumSalary = personList.stream().map(Person::getSalary).reduce(Integer::sum);
// 求工资之和方式2:
Integer sumSalary2 = personList.stream().reduce(0, (sum, p) -> sum += p.getSalary(),
(sum1, sum2) -> sum1 + sum2);
// 求工资之和方式3:
Integer sumSalary3 = personList.stream().reduce(0, (sum, p) -> sum += p.getSalary(), Integer::sum);
// 求最高工资方式1:
Integer maxSalary = personList.stream().reduce(0, (max, p) -> max > p.getSalary() ? max : p.getSalary(),
Integer::max);
// 求最高工资方式2:
Integer maxSalary2 = personList.stream().reduce(0, (max, p) -> max > p.getSalary() ? max : p.getSalary(),
(max1, max2) -> max1 > max2 ? max1 : max2);
System.out.println("工资之和:" + sumSalary.get() + "," + sumSalary2 + "," + sumSalary3);
System.out.println("最高工资:" + maxSalary + "," + maxSalary2);
}
}
6.2.9 收集(collect)
收集,就是把一个流收集起来,最终可以是收集成一个值或者一个新的集合,collect主要依赖java.util.stream.Collectors类内置的静态方法。
6.2.9.1 归集(toList/toSet/toMap)
流不存储数据,在流中的数据完成处理后,需要将流中的数据重新归集到新的集合里。toList、toSet和toMap比较常用,另外还有toCollection、toConcurrentMap等复杂一些的用法。如下案例演示toList、toSet和toMap。
public class StreamTest {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1, 6, 3, 4, 6, 7, 9, 6, 20);
List<Integer> listNew = list.stream().filter(x -> x % 2 == 0).collect(Collectors.toList());
Set<Integer> set = list.stream().filter(x -> x % 2 == 0).collect(Collectors.toSet());
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("Tom", 8900, 23, "male", "New York"));
personList.add(new Person("Jack", 7000, 25, "male", "Washington"));
personList.add(new Person("Lily", 7800, 21, "female", "Washington"));
personList.add(new Person("Anni", 8200, 24, "female", "New York"));
Map<?, Person> map = personList.stream().filter(p -> p.getSalary() > 8000)
.collect(Collectors.toMap(Person::getName, p -> p));
System.out.println("toList:" + listNew);
System.out.println("toSet:" + set);
System.out.println("toMap:" + map);
}
}
6.2.9.2 统计(count/averaging)
Collectors提供了一系列用于数据统计的静态方法,分别为:① 计数count;
② 平均值averagingInt、averagingLong、averagingDouble;③ 最值maxBy、minBy;
④ 求和summingInt、summingLong、summingDouble;⑤ 统计以上所有:summarizingInt、summarizingLong、summarizingDouble。
如下案例分别为:统计员工人数、平均工资、工资总额、最高工资。
public class StreamTest {
public static void main(String[] args) {
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("Tom", 8900, 23, "male", "New York"));
personList.add(new Person("Jack", 7000, 25, "male", "Washington"));
personList.add(new Person("Lily", 7800, 21, "female", "Washington"));
// 求总数
Long count = personList.stream().collect(Collectors.counting());
// 求平均工资
Double average = personList.stream().collect(Collectors.averagingDouble(Person::getSalary));
// 求最高工资
Optional<Integer> max = personList.stream().map(Person::getSalary).collect(Collectors.maxBy(Integer::compare));
// 求工资之和
Integer sum = personList.stream().collect(Collectors.summingInt(Person::getSalary));
// 一次性统计所有信息
DoubleSummaryStatistics collect = personList.stream().collect(Collectors.summarizingDouble(Person::getSalary));
System.out.println("员工总数:" + count);
System.out.println("员工平均工资:" + average);
System.out.println("员工工资总和:" + sum);
System.out.println("员工工资所有统计:" + collect);
}
}
6.2.9.3 分组(partitioningBy/groupingBy)
① 分区:将stream按条件分为两个Map,比如员工按薪资是否高于8000分为两部分;② 分组:将集合分为多个Map,比如员工按性别分组。有单级分组和多级分组。
如下案例为:将员工按薪资是否高于8000分为两部分,将员工按性别和地区分组。
public class StreamTest {
public static void main(String[] args) {
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("Tom", 8900, "male", "New York"));
personList.add(new Person("Jack", 7000, "male", "Washington"));
personList.add(new Person("Lily", 7800, "female", "Washington"));
personList.add(new Person("Anni", 8200, "female", "New York"));
personList.add(new Person("Owen", 9500, "male", "New York"));
personList.add(new Person("Alisa", 7900, "female", "New York"));
// 将员工按薪资是否高于8000分组
Map<Boolean, List<Person>> part = personList.stream().collect(Collectors.partitioningBy(x -> x.getSalary() > 8000));
// 将员工按性别分组
Map<String, List<Person>> group = personList.stream().collect(Collectors.groupingBy(Person::getSex));
// 将员工先按性别分组,再按地区分组
Map<String, Map<String, List<Person>>> group2 = personList.stream().collect(Collectors.groupingBy(Person::getSex, Collectors.groupingBy(Person::getArea)));
System.out.println("员工按薪资是否大于8000分组情况:" + part);
System.out.println("员工按性别分组情况:" + group);
System.out.println("员工按性别、地区:" + group2);
}
}
6.2.9.4 接合(joining)
joining可以将stream中的元素用特定的连接符(没有的话,则直接连接)连接成一个字符串。
public class StreamTest {
public static void main(String[] args) {
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("Tom", 8900, 23, "male", "New York"));
personList.add(new Person("Jack", 7000, 25, "male", "Washington"));
personList.add(new Person("Lily", 7800, 21, "female", "Washington"));
String names = personList.stream().map(p -> p.getName()).collect(Collectors.joining(","));
System.out.println("所有员工的姓名:" + names);
List<String> list = Arrays.asList("A", "B", "C");
String string = list.stream().collect(Collectors.joining("-"));
System.out.println("拼接后的字符串:" + string);
}
}
6.2.9.5 归约(reducing)
Collectors类提供的reducing方法,相比于stream本身的reduce方法,增加了对自定义归约的支持。
public class StreamTest {
public static void main(String[] args) {
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("Tom", 8900, 23, "male", "New York"));
personList.add(new Person("Jack", 7000, 25, "male", "Washington"));
personList.add(new Person("Lily", 7800, 21, "female", "Washington"));
// 每个员工减去起征点后的薪资之和(这个例子并不严谨,但一时没想到好的例子)
Integer sum = personList.stream().collect(Collectors.reducing(0, Person::getSalary, (i, j) -> (i + j - 5000)));
System.out.println("员工扣税薪资总和:" + sum);
// stream的reduce
Optional<Integer> sum2 = personList.stream().map(Person::getSalary).reduce(Integer::sum);
System.out.println("员工薪资总和:" + sum2.get());
}
}
6.2.10 排序(sorted)
排序,中间操作,分为两种:① sorted(),自然排序,流中元素需实现Comparable接口;② sorted(Comparator com),Comparator排序器自定义排序。
如下案例为:将员工按工资由高到低(工资一样则按年龄由大到小)排序。
public class StreamTest {
public static void main(String[] args) {
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("Sherry", 9000, 24, "female", "New York"));
personList.add(new Person("Tom", 8900, 22, "male", "Washington"));
personList.add(new Person("Jack", 9000, 25, "male", "Washington"));
personList.add(new Person("Lily", 8800, 26, "male", "New York"));
personList.add(new Person("Alisa", 9000, 26, "female", "New York"));
// 按工资升序排序(自然排序)
List<String> newList = personList.stream().sorted(Comparator.comparing(Person::getSalary)).map(Person::getName).collect(Collectors.toList());
// 按工资倒序排序
List<String> newList2 = personList.stream().sorted(Comparator.comparing(Person::getSalary).reversed()).map(Person::getName).collect(Collectors.toList());
// 先按工资再按年龄升序排序
List<String> newList3 = personList.stream().sorted(Comparator.comparing(Person::getSalary).thenComparing(Person::getAge)).map(Person::getName).collect(Collectors.toList());
// 先按工资再按年龄自定义排序(降序)
List<String> newList4 = personList.stream().sorted((p1, p2) -> {
if (p1.getSalary() == p2.getSalary()) {
return p2.getAge() - p1.getAge();
} else {
return p2.getSalary() - p1.getSalary();
}
}).map(Person::getName).collect(Collectors.toList());
System.out.println("按工资升序排序:" + newList);
System.out.println("按工资降序排序:" + newList2);
System.out.println("先按工资再按年龄升序排序:" + newList3);
System.out.println("先按工资再按年龄自定义降序排序:" + newList4);
}
}
6.2.11 提取/组合
流也可以进行合并、去重、限制、跳过等操作。
public class StreamTest {
public static void main(String[] args) {
String[] arr1 = { "a", "b", "c", "d" };
String[] arr2 = { "d", "e", "f", "g" };
Stream<String> stream1 = Stream.of(arr1);
Stream<String> stream2 = Stream.of(arr2);
// concat:合并两个流 distinct:去重
List<String> newList = Stream.concat(stream1, stream2).distinct().collect(Collectors.toList());
// limit:限制从流中获得前n个数据
List<Integer> collect = Stream.iterate(1, x -> x + 2).limit(10).collect(Collectors.toList());
// skip:跳过前n个数据
List<Integer> collect2 = Stream.iterate(1, x -> x + 2).skip(1).limit(5).collect(Collectors.toList());
System.out.println("流合并:" + newList);
System.out.println("limit:" + collect);
System.out.println("skip:" + collect2);
}
}