如何使用 Amazon EMR 在 Amazon EKS 上构建可靠、高效、用户友好的 Spark 平台

这是 SafeGraph 技术主管经理 Nan Zhu 与亚马逊云科技高级解决方案架构师 Dave Thibault 共同撰写的特约文章。
SafeGraph 是一家地理空间数据公司,管理着全球超过 4100 万个兴趣点(POI,Point of Interest),提供品牌隶属关系、高级类别标签、开放时间,以及人们如何与这些场所互动等方面的详细信息。我们使用 Apache Spark 作为主要数据处理引擎,每天有 1000 多款 Spark 应用程序运行海量的数据。这些 Spark 应用程序实施我们的业务逻辑,包括数据转换、机器学习(ML)模型推理和运维任务等广泛的应用。
SafeGraph 发现其现有 Spark 供应商的 Spark 环境并不理想。他们的成本不断上升。在竞价型实例终止时,其作业会频繁重试。开发人员花费太多的时间进行故障排除和更改作业配置,没有足够的时间来开发具有业务价值的代码。SafeGraph 需要控制成本、提高开发人员迭代速度和改进作业可靠性。最终,SafeGraph 选择 Amazon EKS 上的 Amazon EMR 来满足他们的需求,与之前的 Spark 托管服务供应商相比,成本节省了 50%。
所谓“工欲善其事必先利其器”,在为产品构建 Spark 应用程序时,Spark 平台就是这个“器”。下图展示了使用 Spark 时的工程设计工作流,Spark 平台需要支持和优化工作流中的每个操作。工程师通常先编写和构建 Spark 应用程序代码,然后将应用程序提交到计算基础设施,最后调试 Spark 应用程序来结束循环。此外,平台和基础设施团队需要持续运维,并优化工程设计工作流中的三个步骤。
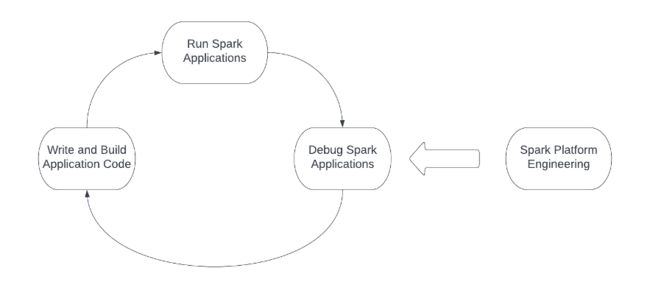
构建 Spark 平台时,每个操作都涉及多种挑战:
可靠的依赖项管理 – 复杂的 Spark 应用程序通常会引入许多依赖项。要运行 Spark 应用程序,我们需要确定所有依赖项,解决任何冲突,可靠地打包依赖项库,并将它们传输到 Spark 集群。依赖项管理是工程师面临的最大挑战之一,尤其是在他们使用 PySpark 应用程序时。
可靠的计算基础设施 – 托管 Spark 应用程序的计算基础设施必须具有可靠性,这是整个 Spark 平台的基础。不稳定的资源预置不仅会对工程设计效率造成负面影响,而且还会因重新运行 Spark 应用程序而增加基础设施成本。
面向 Spark 应用程序的便捷调试工具 – 工程师能否在 Spark 应用程序上快速进行迭代,调试工具的作用非常关键。要想提高开发人员迭代速度,高性能访问 Spark 历史服务器(SHS,Spark History Server)是一个必要条件。反过来说,糟糕的 SHS 性能会减慢开发人员的速度,并增加软件公司销售产品的成本。
可管理的 Spark 基础设施 – 成功的 Spark 平台工程设计涉及到多个方面,例如 Spark 分发版本管理、计算资源 SKU 管理和优化等。这在很大程度上取决于 Spark 服务供应商是否为平台团队提供了合适的底层供他们使用。例如,对分发版本和计算资源的错误抽象化可能会显著降低平台工程设计的 ROI。
SafeGraph 遇到了上述所有挑战。为了解决这些问题,我们探索了市场,发现依托 Amazon EKS 上的 Amazon EMR 来构建新的 Spark 平台,这种方法可以解决我们面临的障碍。在这篇文章中,我们分享了构建最新 Spark 平台的旅程,以及 EKS 上的 EMR 如何为这个旅程提供了强大而有效的底层。
可靠的 Python 依赖项管理
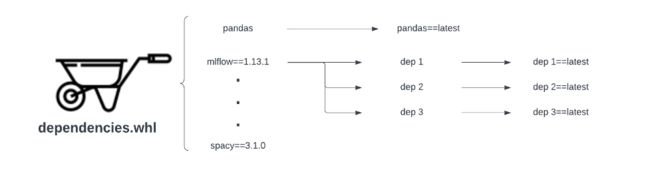
用户在编写和构建 Spark 应用程序代码时,面临的最大挑战之一是难以可靠地管理依赖项,尤其是对于 PySpark 应用程序。我们大多数与机器学习相关的 Spark 应用程序都是使用 PySpark 构建的。之前的 Spark 服务供应商只支持一种管理 Python 依赖项的方法,那就是使用 wheel 文件。尽管基于 wheel 的依赖项管理得到了广泛的应用,但它其实很脆弱。下图显示了基于 wheel 的依赖项管理面临的两种类型的可靠性问题:
未固定的直接依赖项 – 如果 .whl 文件无法确定某个直接依赖项的版本(在此示例中为 Pandas),它将始终从上游拉取最新版本,其中可能包含破坏性的更改并导致 Spark 应用程序中断。
未固定的传递依赖项– 第二种可靠性问题更是我们无法控制的。即使我们在构建 .whl 文件时固定了直接依赖项版本,但直接依赖项本身可能无法确定传递依赖项版本(在本例中为 MLFlow)。在这种情况下,直接依赖项总是会拉取这些传递依赖项的最新版本,而这些依赖项中可能包含破坏性的更改并可能导致管道中断。
我们遇到的另一个问题是,在每次 Spark 应用程序初始化时,会不必要地安装 wheel 文件引用的所有 Python 包。在我们之前的设置中,需要在启动时运行安装脚本来为每个 Spark 应用程序安装 wheel 文件,即使依赖项没有变化。此安装将 Spark 应用程序的启动时间从 3 到 4 分钟延长到至少 7 到 8 分钟。这种拖沓的速度非常影响体验,尤其是我们的工程师正在积极迭代变更时。
通过迁移到 EKS 上的 EMR,我们能够使用 pex(Python 可执行文件)来管理 Python 依赖项。.pex 文件考虑到虚拟环境,打包 PySpark 应用程序在可执行 Python 环境中的所有依赖项(包括直接依赖项和传递依赖项)。
下图展示了将上图中的 wheel 文件转换为.pex 文件后的文件结构。与基于 wheel 的工作流相比,我们不再有传递依赖项拉取或自动获取最新版本的操作。构建 .pex 文件时,依赖项的所有版本都固定为 x.y.z、a.b.c 等。对于给定的.pex 文件,所有依赖项都已固定,这样我们就不会再遇到基于 wheel 的依赖项管理中的缓慢或脆弱性问题。构建 .pex 文件的成本也是一次性成本。
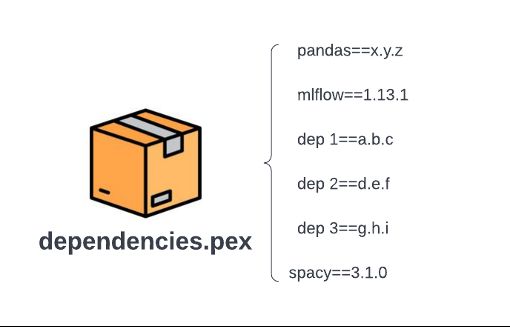
可靠、高效的资源预置
资源预置是 Spark 平台为 Spark 应用程序获取计算资源的过程,是整个 Spark 平台的基础。在云中构建 Spark 平台时,使用竞价型实例进行成本优化使得资源预置更具挑战性。竞价型实例是可供您使用的备用计算容量,相比按需价格最多可节省 90%。但是,当对某些实例类型的需求突然增长时,可能会终止竞价型实例以优先满足这些需求。由于这些终止,我们在之前版本的 Spark 平台中遇到了一些挑战:
不可靠的 Spark 应用程序 – 当竞价型实例终止时,由于重试计算阶段,Spark 应用程序的运行时间显著延长。
糟糕的开发人员体验 – 竞价型实例不稳定的供应状态导致 Spark 应用程序的性能遇到不可预测和低成功率的问题,严重影响了工程师的体验并减缓了开发迭代速度。
昂贵的基础设施账单 – 由于作业需要重试,我们的云基础设施账单大幅增加。为了缓解问题,我们不得不购买具有更大容量且在多个可用区中运行的昂贵 Amazon Elastic Compute Cloud(Amazon EC2)实例,但这随之又带来了跨可用区流量的高成本。
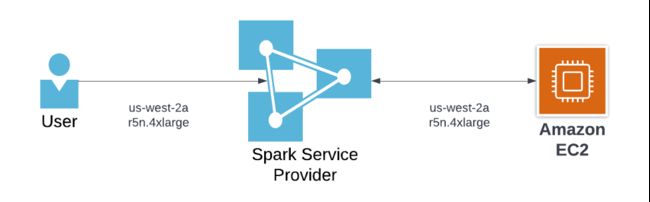
Spark 服务提供商(SSP,Spark Service Provider),如 EKS 上的 EMR 或其他第三方软件产品,是用户和竞价型实例池之间的中间人,在确保竞价型实例的充足供应方面发挥着关键作用。如下图所示,用户通过 SSP 使用作业编排工具、笔记本或服务启动 Spark 作业。SSP 实施自己的内部功能,以访问亚马逊云科技等云服务的竞价型实例池中未使用的实例。使用竞价型实例的最佳实践之一是使用多样化的实例类型(有关更多信息,请参阅使用 EC2 竞价型实例进行成本优化:https://aws.github.io/aws-emr-containers-best-practices/cost-optimization/docs/cost-optimization/)。具体而言,SSP 可以通过两个关键功能实现实例多样化:
SSP 应该能够访问亚马逊云科技的竞价型实例池中所有类型的实例
SSP 应为用户提供相应的功能,让他们能够在启动 Spark 应用程序时使用尽可能多的实例类型
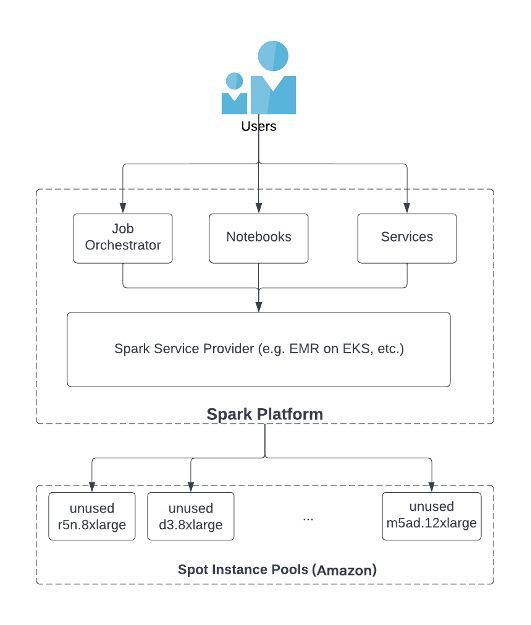
我们的上一个 SSP 没有针对这两点提供所需的解决方案。他们只支持一组有限的竞价型实例类型,并且默认情况下,在启动 Spark 作业时,只允许选择一种竞价型实例类型。因此,每个 Spark 应用程序只能运行容量较小的竞价型实例,并且容易受到竞价型实例终止的影响。
EKS 上的 EMR 使用 Amazon Elastic Kubernetes Service(Amazon EKS)访问亚马逊云科技中的竞价型实例。Amazon EKS 支持所有可用的 EC2 实例类型,为我们带来了更高的容量池。我们使用 Amazon EKS 托管节点组、节点选择器以及污点等功能,将每个 Spark 应用程序分配到一个由多种实例类型组成的节点组。在迁移到 EKS 上的 EMR 后,我们看到了以下好处:
减少了竞价型实例终止的频率,缩短了 Spark 应用程序的运行时间并且保持稳定。
工程师发现应用程序行为的可预测性得到改善,因此能够更快地进行迭代。
基础设施成本大幅下降,因为我们不再需要昂贵的解决方法,同时,我们在 Amazon EKS 的每个节点组中都有精打细算的实例选择。我们能够节省大约 50% 的计算成本,而无需采用在多个可用区中运行之类的解决方法,同时提供预期的可靠性水平。
流畅的调试体验
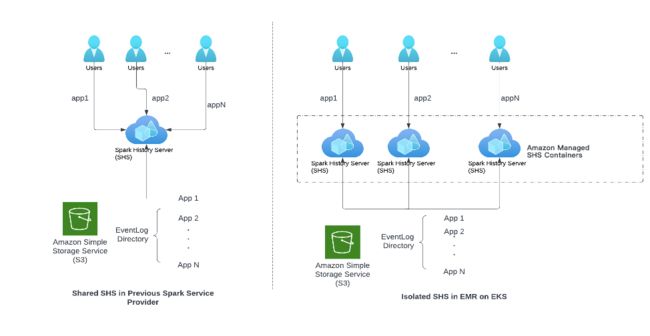
对于工程设计工作流循环的结束环节来说,有一个能够支持工程师方便地调试 Spark 应用程序的基础设施至关重要。Apache Spark 使用事件日志记录 Spark 应用程序的活动,例如任务开始和完成。这些事件采用 JSON 格式,由 SHS 用来重新呈现 Spark 应用程序的 UI。工程师可以访问 SHS 来调查任务故障原因或调试性能问题。
SafeGraph 工程师面临的主要挑战是 SHS 中的可扩展性问题。如下图左侧所示,我们之前的 SSP 强制所有工程师共享同一个 SHS 实例。结果,由于许多工程师同时进行访问以调试应用程序,或者如果 Spark 应用程序需要渲染大型事件日志,SHS 面临着巨大的资源压力。在迁移到 EKS 上的 EMR 之前,我们经常遇到 SHS 缓慢或 SHS 彻底崩溃的情况。
如下图所示,对于每个查看 Spark 历史记录 UI 的请求,EKS 上的 EMR 都会在亚马逊云科技管理的环境中启动一个独立的 SHS 实例容器。此架构的好处有两方面:
不同的用户和 Spark 应用程序不再争夺 SHS 资源。因此,我们再也没有遇到 SHS 缓慢或崩溃的情况。
所有 SHS 容器均由亚马逊云科技管理;用户无需支付额外的财务或运维成本,就能享受到可扩展的架构。
易于管理的 Spark 平台
如工程设计工作流所示,构建 Spark 平台不是一次性的工作,平台团队需要管理 Spark 平台并不断优化工程师开发工作流中的每个步骤。SSP 的作用是提供适当的便利,来尽可能减轻运维负担。尽管运维任务有很多类型,但在本文中我们重点介绍其中的两个:计算资源 SKU 管理和 Spark 发行版版本管理。
计算资源 SKU 管理是指 Spark 平台在允许用户选择不同大小的计算实例方面,进行的设计和处理。这样的设计和处理在很大程度上依赖于 SSP 实施的相关功能。
下图显示了我们之前 SSP 的 SKU 管理。
下图显示了 EKS 上的 EMR 中的 SKU 管理。

在与我们之前的 SSP 合作时,作业配置仅允许明确指定单个竞价型实例类型,如果该类型没有可用的竞价容量,则作业会切换到按需实例,或者出现可靠性问题。这让平台工程师要么选择更改 Spark 作业实例集的设置,要么需要承担预算和售出产品的成本意外飙升的风险。
EKS 上的 EMR 使平台团队可以更轻松地管理计算 SKU。在 SafeGraph,我们在用户与 EKS 上的 EMR 之间嵌入了 Spark 服务客户端。Spark 服务客户端仅向用户公开不同层级的资源(例如小型、中型和大型)。每一层级都映射到在 Amazon EKS 中配置的特定节点组。这种设计带来了以下好处:
在价格和容量发生变化时,我们很容易更新节点组中的配置,而用户并不会知道。用户不用执行任何更改,甚至不会有任何感觉,就可以继续享受稳定的资源配置,同时我们还能尽可能降低成本和运维开销。
在为 Spark 应用程序选择合适的资源时,最终用户无需进行任何猜测,因为通过简化的配置可以轻松进行选择。
我们从 EKS 上的 EMR 中获得的另一个好处是改进了 Spark 发行版管理。在使用 EKS 上的 EMR 之前,我们的 SSP 存在不透明发布 Spark 发行版的问题。每隔 1-2 个月,Spark 发行版就会向用户发布一个新的补丁版本。这些版本都通过 UI 向用户公开。这导致工程师选择了各种版本的发行版,其中一些版本未经过我们的内部工具测试。这大幅增加了我们的管道和内部系统的中断率,并对平台团队带来了很大的支持负担。我们希望在使用 EKS 上的 EMR 架构后,Spark 发行版的风险可降至最低,并且对用户透明。
EKS 上的 EMR 遵循最佳实践,使用包含固定版本的 Spark 发行版的稳定基础 Docker 映像。对于 Spark 发行版的任何更改,我们都必须明确地重建并推出 Docker 映像。借助 EKS 上的 EMR,在使用内部工具和系统对新版本的 Spark 发行版进行测试并正式发布之前,我们可以对用户隐藏该版本。
总结
在这篇文章中,我们分享了依托 EKS 上的 EMR 构建 Spark 平台的过程。将 EKS 上的 EMR 作为 SSP,为我们的 Spark 平台奠定了坚实的基础。借助 EKS 上的 EMR,我们得以解决了依赖项管理、资源预置和调试体验等各种挑战,并且得益于可用性更高的竞价型实例类型和大小,我们还显著降低了计算成本,削减达到 50%。
我们希望这篇文章能够在社区中分享一些见解,帮助企业选择合适的 SSP。详细了解 EKS 上的 EMR(https://aws.amazon.com/emr/features/eks/),包括其益处、功能和入门方法。
Original URL:
https://aws.amazon.com/blogs/big-data/how-safegraph-built-a-reliable-efficient-and-user-friendly-spark-platform-with-amazon-emr-on-amazon-eks/
本篇作者

Nan Zhu
SafeGraph 平台团队的技术主管经理。他领导团队构建广泛的基础设施和内部工具,以提高 SafeGraph 工程设计流程的可靠性、效率和生产力,例如内部 Spark 生态系统、指标存储和大型单一存储库的 CI/CD 等。他还参与了多个开源项目,如 Apache Spark、Apache Iceberg、Gluten 等。

Dave Thibault
一位资深解决方案架构师,为亚马逊云科技的独立软件供应商(ISV)客户提供服务。他热衷于使用无服务器技术和机器学习进行构建,推动亚马逊云科技客户加快实现业务成功。加入 亚马逊云科技之前,Dave 在生命科学公司工作了 17 年,为研究、开发和临床制造部门开展 IT 和信息学工作。他的爱好包括滑雪、户外油画写生,还喜欢与家人共度时光。

听说,点完下面4个按钮
就不会碰到bug了!
