zookeeper介绍、zookeeper的安装与配置
1、zookeeper介绍
1.1 官网说明
官方地址:http://zookeeper.apache.org/
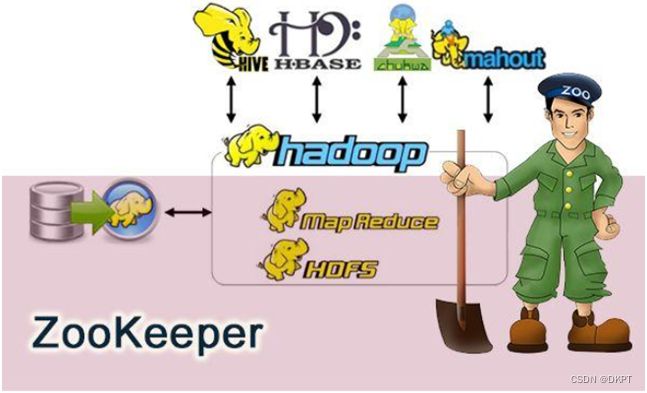
它是拿来管理 Hadoop、Hive、Pig的管理员, Apache Hbase和Apache Solr以及阿里的Dubbo等项目中都采用到了Zookeeper。
一句话:ZooKeeper是一个分布式协调技术、高性能的,开源的分布式系统的协调(Coordination)服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用程序一致性和分布式协调技术服务的软件。
2、zookeeper的安装与配置
2.1 linux下安装zookeeper
安装zookeeper之前需要安装好java环境。
2.1.1 官网下载安装包
下载地址:https://zookeeper.apache.org/releases.html#download
2.1.2 创建安装目录
[root@localhost ] mkdir /myzookeeper
2.1.3 拷贝进入到/myzookeeper目录下并解压
[root@localhost myzookeeper]# tar -zxvf zookeeper-3.4.14.tar.gz
2.1.4 进入conf文件夹,拷贝zoo_sample.cfg改为zoo.cfg
[root@localhost conf]# cp zoo_sample.cfg zoo.cfg
tickTime:通信心跳间隔,单位是毫秒,系统默认是2000毫秒,也就是间隔两秒心跳一次。
还可以控制Flower跟Leader的通信时间,默认情况下FL的会话时常是心跳间隔的两倍。
initLimit
集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)。
syncLimit:LF同步通信时限
集群中Leader与Follower之间的最大响应时间单位。
dataDir:数据文件目录+数据持久化路径
保存内存数据库快照信息的位置,如果没有其他说明,更新的事务日志也保存到数据库。
clientPort:客户端连接端口
监听客户端连接的端口。
2.1.5 启动zookeeper
注意:zookeeper 是java 语言编写的,所以启动zookeeper时,必须先有java 环境!
进入到bin 目录执行
启动命令:
[root@localhost bin]# ./zkServer.sh start
是否真正启动成功可以查看进程
# ps –ef | grep zookeeper

关闭命令:
[root@localhost bin]# ./zkServer.sh stop
查看状态:
[root@localhost bin]# ./zkServer.sh status
2.1.6 链接客户端
在bin 目录下面执行命令
[root@localhost bin]# ./zkCli.sh

退出:
# quit 命令

2.1.6.1 客户端基本命令使用
(1)ls / 查看+获得zookeeper服务器上的数据存储信息。

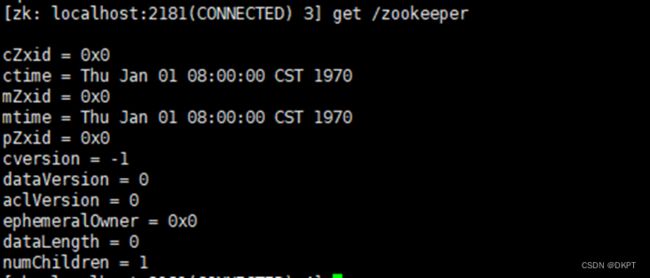
(2)get /zookeeper 获取节点数据。
2.1.6.2 文件系统
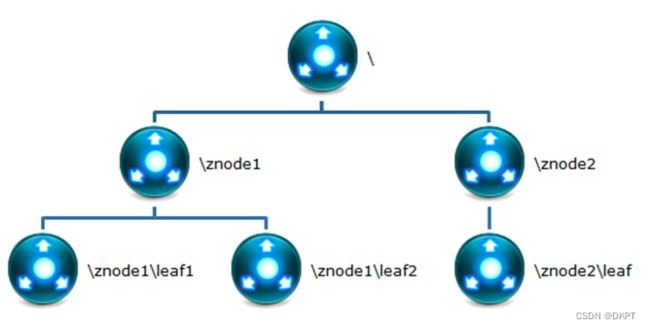
所使用的数据模型风格很像文件系统的目录树结构,简单来说,有点类似windows中注册表的结构,
有名称,
有树节点,
有Key(键)/Value(值)对的关系,
可以看做一个树形结构的数据库,分布在不同的机器上做名称管理。
2.1.6.3 znode节点