项目:点餐系统2
httplib的思想简单总结;
- 使用线程池来处理请求
- 由用户定义处理函数,告诉httplib哪个请求应该使用哪个函数处理
- 线程接收请求并解析请求后调用处理函数
一、服务器搭建
get主要是用来获取资源的,post主要是客户端提交数据的。
#include"httplib.h"
void Hello(const httplib::Request& req, httplib::Response& rsp) {
rsp.body = "hello";
rsp.status = 200;
return;
}
void Numbers(const httplib::Request& req, httplib::Response& rsp) {
std::string num = req.matches[1];
rsp.body = num;
rsp.status = 200;
}
void Dish(const httplib::Request& req, httplib::Response& rsp) {
rsp.body = req.body;
rsp.status = 200;
}
int main() {
httplib::Server srv;
//当客户端请求的是一个静态的实体文件资源的时候,就会直接读取文件数据进行响应
srv.set_mount_point("/", "./wwwroot");
//设置静态资源根目录/index.html->./wwwroot/index.html
srv.Get("/hi", Hello);
srv.Get(R"(/numbers/(\d+)", Numbers);
srv.Post("/dish", Dish);
//搭建tcp服务器,开始监听,获取新连接,接收http请求数据,进行解析,调用对应处理函数,组织响应
srv.listen("0.0.0.0", 10000);
return 0;
}1.实例化Server对象
get_handlers,post_handlers
这就是俩张表(正则表达式,函数指针)
2.设置静态资源根目录
srv.set_mount_point("/", "./wwwroot");
3.接收http请求数据,进行解析,调用对应处理函数,组织响应
srv.Get("/hi", Hello);
srv.Post("/dish", Dish);
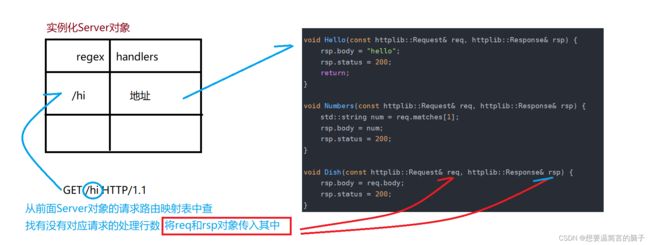
给Server对象中的请求路由表中添加映射信息
get_handler就是针对GET请求的指定资源/hi,映射一个处理函数
4.启动tcp(http)服务器开始监听
srv.listen("0.0.0.0", 10000);
当有新的连接到来,则将获取新连接,抛入线程池中
二、线程池的工作内容:
1.逐行从套接字读取数据
2.对读取的数据以http请求格式进行解析(请求方法、url、查询字符串、头部字段、正文)
3.定义了俩个对象Request req、Request rsp。向rsp中填充解析后的请求信息
4.从前面Server对象的请求路由映射表中查找有没有对应请求的处理行数
如果没有,则返回404,表示请求的资源不存在
如果有,则表示这个请求有对应的处理函数,则调用该函数,并且将req和rsp对象传入其中
struct Request{
std::string method;请求方法
std::string path;资源路径
Headers headers;头部字段
std::string body;请求正文
Params params;url中的查询字段
MultipartFormDataMap files;文件上传所用的
Match matches;资源路径中用正则表达式捕获的数据
}
struct Response{
std::string version;版本协议
int status = -1;响应状态码
Headers headers;头部字段
std::string body;响应正文
}
处理函数是程序员自己编写的,根据传入的请求信息进行分辨是什么请求,进行对应的业务处理
业务处理完后,填充rsp对象(填充的是要响应的信息——状态码、正文、头部字段)
等待这个处理函数运行完后,线程就得到一个填充完整的rsp对象
根据rsp对象中的数据以及http响应格式,组织http响应数据发送给客户端
本次请求完毕。
如果没有找到指定请求的处理函数:
这个请求有可能是个实体资源请求
1.给资源路径加上我们设置的静态资源根目录
/index.html->./wwwroot/index.html
/ -> ./wwwroot/
2.如果请求是 / 结尾,则加上index.html
3.判断是否真的有这个文件的存储
4.如果有,则读取文件内容作为响应正文
5.如果没有,响应404
总结:
1.先判断有没有对应请求的处理函数,有则处理及响应
2.判断是否是一个静态资源请求(前提是设置了静态资源根目录),有则处理及响应
3.没有就响应404