Apache Flink 课外阅读
Apache Flink
Flink 概述
首先大数据存储和分析引擎Hadoop自2006年诞生。谈及Hadoop大家自然不会对 MapReduce感到陌生,它将计算分为两个阶段,分别为 Map 和 Reduce。MapReduce计算框架虽然借鉴了函数式编程和矢量编程的思想完成了分布式计算。但不得不承认MapReduce在矢量编程结构过于简单,在完成一些比较复杂的高阶计算(例如:机器学习线性回归)的时候,需要将多个MapReduce任务串联起来才能完成一个复杂的计算逻辑,因此在早期人们需要在编写完多个job任务之后还需要Job的调用流程。

伴随着大数据的发展人们发现以Hadoop为首的静态批处理框架在应为实时在线的数据无能为力。因此2010年12月Storm的流处理的方案开始在BackType项目中被Nathan提出,2011年4月年Storm在BackType项目中问世,2011年五月BackType被Twitter收购与此同时Storm首次开源。2013年7月Storm开始在Apache孵化直到2014年9月Storm成为Apache顶级项目。成为了当时最为主流的实时流处理框架。
Storm以其低延迟高吞吐以及精准一次语义的处理,迅速的在各大互联网公司得到推广和应用,例如 twitter、阿里巴巴、百度、爱奇艺等快速的普及和实践,尤其是阿里巴巴中基于Storm封装了JStorm分支,并使用Storm处理阿里巴巴旗下的淘宝电商中的绝大多数的流处理业务。早期的应对大数据分析场景主流的选择方案:静态批处理:MapReduce;实时流处理:Storm因此通常我们将Hadoop和Storm称为第一代大数据处理方案。
由于Map Reduce计算模型总是把结果存储到磁盘中,每次迭代都需要将数据磁盘加载到内存,这就为后续的迭代带来了更多延长。2009年Spark在加州伯克利AMP实验室诞生,2010首次开源后该项目就受到很多开发人员的喜爱,2013年6月份开始在Apache孵化,2014年2月份正式成为Apache的顶级项目。Spark发展如此之快是因为Spark在计算层方面明显优于Hadoop的Map Reduce这磁盘迭代计算,因为Spark可以使用内存对数据做计算,而且计算的中间结果也可以缓存在内存中,这就为后续的迭代计算节省了时间,大幅度的提升了针对于海量数据的计算效率。

不仅仅如此,Spark提出了先进的DAG计算理念和RDD计算模型极大地简化了大数据的开发难度,于此同时Spark设计者在RDD批处理技术之上开始封装了流处理方案Spark Streaming,由于Spark Streaming底层分装了Spark批处理模型,所以在使用Spark的API操作流处理和批处理几乎是一模一样,降低了流处理程序员的开发门槛,使得Spark很快的受到了业内绝大多数开发人员的一致好评,使得Spark项目在大家的欢呼声中迅速成长。
Spark 掀开了内存计算的先河,也以内存为赌注,赢得了内存计算的飞速发展。Spark 的火热或多或少的掩盖了其他分布式计算的系统身影。就像 Flink,也就在这个时候默默的发展着。由于Spark的设计虽然赢得了一片掌声但是Spark在流处理领域上的实时性有点差强人意,主要是因为Spark Streaming计算是构建在RDD之上的微观批处理在计算的实时性上甚至不如Storm实时性,因此Spark在流处理领域的地位就显得非常尴尬(也许是Spark RDD API的友善性,使得Spark Streaming被人们所青睐)。但是易用性只能为企业节省用人成本,但是解决不了实际的生产过程中对流计算框架的实时性要求。通常将Spark称为第二代大数据处理方案。

伴随着流计算的任务越来越多,人们对低延迟和高吞吐要求也来越高,这个时候人们开始把视线转移到Flink之上。Flink 起源于 Stratosphere 项目,Stratosphere 是在 2010~2014 年由 3 所地处柏林的大学和欧洲的一些其他的大学共同进行的研究项目。当时,这个项目已经吸引了一个较大的社区,一部分原因是它出现在了若干公共开发者研讨会上,比如在柏林举办的 Berlin Buzzwords,以及在科隆举办的 NoSQL Matters,等等。强大的社区基础是这个项目适合在 Apache 软件基金会中孵化的一个原因。
2014 年 4 月,Stratosphere 的代码被复制并捐献给了 Apache 软件基金会,参与这个孵化项目的初始成员均是 Stratosphere 系统的核心开发人员。不久之后,创始团队中的许多成员离开大学并创办了一个公司来实现 Flink 的商业化,他们为这个公司取名为 data Artisans。在孵化期间,为了避免与另一个不相关的项目重名,项目的名称也发生了改变。Flink 这个名字被挑选出来,以彰显这种流处理器的独特性:在德语中,flink 一词表示快速和灵巧。项目采用一只松鼠的彩色图案作为 logo,这不仅因为松鼠具有快速和灵巧的特点,还因为柏林的松鼠有一种迷人的红棕色。

这个项目很快完成了孵化,并在 2014 年 12 月一跃成为 Apache 软件基金会的顶级项目。作为 Apache 软件基金会的 5 个最大的大数据项目之一,Flink 在全球范围内拥有 200 多位开发人员,以及若干公司中的诸多上线场景,有些甚至是世界 500 强的公司。
Flink和Spark相似采用先进的DAG模型做任务拆分完成数据的内存计算,但是Flink是一个纯流式计算引擎。不同于Spark在批处理之上构建流处理。Flink设计恰恰和Spark相反,Flink是在流计算上构建批处理。
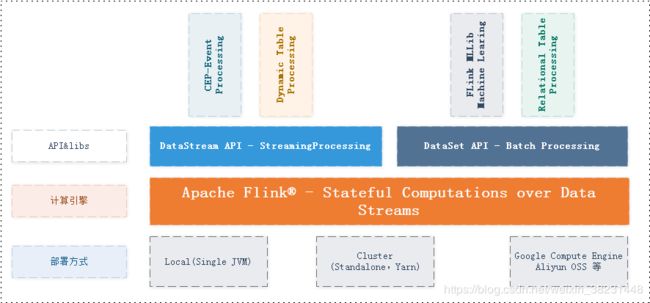
不难看出Flink在架构的设计优雅程度上其实和Spark是非常相似的。资源管理上Flink同样可以运行在Standalone和yarn、k8s等,在上层上抽象出 流处理和批处理两个维度数据的处理方式分别处理unbound和bounded数据。并且在DataStream和DateSet API之上均有对应的实现例如SQL处理、CEP-Event (Complex event processing)、MachineLearing等,也自然被称为第三代大数据处理方案。
执行与架构
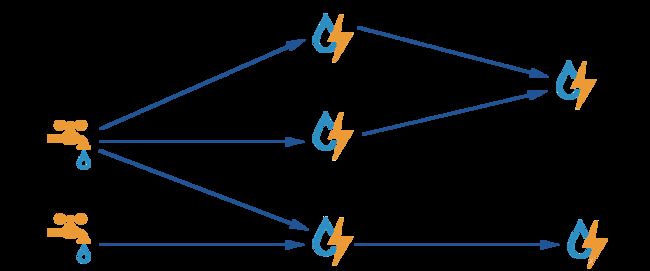
针对于分布式环境下,Flink会尝试链式优化用户操作,将一些操作合并到一些Task任务中,这种优化有点类似于Spark的Stage的划分。如下图所示:

整个执行过程需要5个Thread完成整个计算过程。
Flink的架构主要包含两种服务进程Task Manager和Job Manager
-
其中JobManagers (也称为masters)协调任务的执行. 主要包含 schedule tasks, coordinate checkpoints, coordinate recovery on failures等。
There is always at least one Job Manager. A high-availability setup will have multiple JobManagers, one of which one is always the leader, and the others are standby.
-
TaskManagers (也称为 workers) 执行Dataflow中的tasks (更准确的说 subtasks) ,缓存以及是对数据进行传送。
There must always be at least one TaskManager.
JobManagers和TaskManagers可以通过各种方式启动:直接在机器上作为standalone方式,在容器中,或由YARN或Mesos等资源框架管理。TaskManagers连接到JobManagers,宣布自己可用,并被分配工作。Client不是运行时程序执行的一部分,但用于准备数据流并将数据流发送到JobManager。之后,客户端可以断开连接或保持连接以接收进度报告。客户端既可以作为触发执行的Java / Scala程序的一部分运行,也可以在命令行进程中运行./bin/flink run ...

每个worker(TaskManager)都是一个JVM进程,可以在不同的线程中执行一个或多个子任务。并且将Worker节点计算能力按照task slots(at least one)进行均分。每个Task Slot代表TaskManager的固定资源子集。例如,具有3个Task Slots的TaskManager将其1/3的托管内存专用于每个task slot.切分资源的目的是为了对一个任务的执行做资源隔离,也就意味着当前任务的执行一旦分配完slot之后,不会被其他job任务侵占。如果一个TaskManager 拥有多个Task Slots意味着更多Sub Tasks 共享同一个JVM。

默认情况下,Flink允许子任务共享Task slot,即使它们是不同任务的子任务,只要它们来自同一个job即可。一个Slot槽可以保存Job的的整个工作流程。允许此Task Slots共享有两个主要好处:
- Flink集群需要与作业中使用的TaskSlots总数。无需计算程序总共包含多少任务。
- 更好的资源利用率。允许一个job中共享Task Slots 也就意味着系统可以更加充分的使得资源得到合理的利用。没有Task Slot共享,非密集源/ map()子任务将阻止与资源密集型 window subtasks一样多的资源。通过Task slot,将示例中的基本并行性从2增加到6可以充分利用时隙资源,同时确保繁重的子任务在TaskManagers之间公平分配.

服务安装
Flink Streaming
ApacheFlink® - 是针对于数据流的状态计算,Flink具有特殊类DataSet和DataStream来表示程序中的数据。您可以将它们视为可以包含重复项的不可变数据集合。在DataSet的情况下,数据是有限的,而对于DataStream,元素的数量可以是无限的。
快速入门
package com.jiangzz
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
//导入隐式转换,否则系统无法正常使用
import org.apache.flink.streaming.api.scala._
object FlinkExecutionEnviromentDemo {
def main(args: Array[String]): Unit = {
var jars="flinkstream/target/flinkstream-1.0-SNAPSHOT.jar"
//远程发布任务
val env = StreamExecutionEnvironment.createRemoteEnvironment("localhost",8081,jars)
//读取SocketTextStreaming
env.socketTextStream("localhost",9999)
.flatMap(line => line.split("\\s+"))
.map(word=>(word,1))
.keyBy(_._1)
.sum(1)
.print()
//执行任务
env.execute("wordcount")
}
}
计算的方式
- 远程jar包部署方式
var streamEnv = StreamExecutionEnvironment.getExecutionEnvironment()
- 本地执行
var streamEnv = StreamExecutionEnvironment.createLocalEnvironment()
- 跨平台提交
var streamEnv = StreamExecutionEnvironment.createRemoteEnvironment("CentOS",8081,"jarFiles")
用户可以更具需求自行抉择选择哪种方式测试或者运行代码。
Data Sources
DataSource是flink计算读取数据的输入,用户可以通过env.addSource(...)定制用户输入。Flink内建了一些预定义的DataSource的实现,但是用户也可以通过实现SourceFunction或者ParallelSourceFunction接口实现自定义的DataSource.
File-Based(基于文件)
- readTextFile(path) - 读取文本文件,等价制定了TextInputFormat,line-by-line读取方式。
- readFile(fileInputFormat,path) - 按照指定的格式一次性读取所有在指定目录下的文件。
- readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo) - 该方法是以上两个方法的实现,该方法按照给定的fileInputFormat读取path路径下的文件。watchType指定了读取的方式FileProcessingMode.PROCESS_CONTINUOUSLY或者FileProcessingMode.PROCESS_ONCE,前者是定时的检测文件中是否有新的文本行数据产生,后者则读取一次。
以上的实现,Flink会将文件的读取分为两个sub-tasks,分比为namely directory monitoring和Data Reading.其中Monitoring实现是单线程的Task,然而Reading是由多线程实现的。读取的并行度和Job的并行度一致。monitoring任务的作用就是扫描目录(定期或者Once取决于WatchType)监测文件的修改,并且将文件拆分成split然后将这些Split文件传递给下游的Reader任务。Reader负责读取实际的数据,每个切片会有一个Reader负责读取,一个Reader可以逐次的读取多个切片。
提示:
- 如果watctype被设置为PROCESS_CONTINUOUSLY,当文件被检测到修改的时候,系统会将文件完整的重新处理一次。这种方式可能会阻碍
exactly-once语义。- 如果watchtype被设置为PROCESS_ONCE系统只会扫描一次然后退出。后续Reader程序会读取文件。
- readTextFile
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
//1.获取执行env
val env = StreamExecutionEnvironment.createLocalEnvironment(3)
//2.指定输入源
var filePath="/Users/jiangzz/Desktop/t_user.txt"
val streams:DataStream[String] = env.readTextFile(filePath)
//3.执行打印输出
streams.print()
//4.执行任务
env.execute("fileread")
提示:如果读取来自HDFS上的文件数据,还需添加如下依赖:
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>2.9.2version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>2.9.2version>
dependency>
- readFile(fileInputFormat,path)
import org.apache.flink.api.java.io.TextInputFormat
import org.apache.flink.core.fs.Path
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.scala._
//1.获取执行env
val env = StreamExecutionEnvironment.createLocalEnvironment(3)
//2.指定输入源
var filePath="hdfs:///user/logs/t_user.txt"
val inputFormat = new TextInputFormat(new Path(filePath))
val streams:DataStream[String] = env.readFile(inputFormat,filePath)
//3.执行打印输出
streams.print()
//4.执行任务
env.execute("fileread")
- readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo)
import org.apache.flink.api.java.io.TextInputFormat
import org.apache.flink.core.fs.Path
import org.apache.flink.streaming.api.functions.source.FileProcessingMode
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment, _}
//1.获取执行env
val env = StreamExecutionEnvironment.createLocalEnvironment(3)
//2.指定输入源
var filePath="hdfs:///user/logs/t_user.txt"
val inputFormat = new TextInputFormat(new Path(filePath))
val streams:DataStream[String] = env.readFile(inputFormat,filePath,FileProcessingMode.PROCESS_CONTINUOUSLY,1000)
//3.执行打印输出
streams.print()
//4.执行任务
env.execute("fileread")
Socket-Based
- socketTextStream - 读取来自Socket中的数据。
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
//1.获取执行env
val env = StreamExecutionEnvironment.createLocalEnvironment(3)
//2.指定输入源
val streams = env.socketTextStream("localhost",9999)
//3.执行打印输出
streams.print()
//4.执行任务
env.execute("socket")
Collection-based:
- fromCollection(Seq) /fromCollection(Iterator)- 从集合中获取元素,但是要求集合的元素类型必须一致。
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
//1.获取执行env
val env = StreamExecutionEnvironment.createLocalEnvironment(3)
//2.指定输入源
val streams = env.fromCollection(List(User(1,"zhangsan"),User(2,"李四")))
//3.执行打印输出
streams.print()
//4.执行任务
env.execute("formCollection")
- fromElements(T …)
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
//1.获取执行env
val env = StreamExecutionEnvironment.createLocalEnvironment(3)
//2.指定输入源
val streams = env.fromElements(User(1,"zhangsan"),User(2,"李四"))
//3.执行打印输出
streams.print()
//4.执行任务
env.execute("fromElements")
Kafka Source
- FlinkKafkaConsumer
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
//1.获取执行env
val env = StreamExecutionEnvironment.createLocalEnvironment(3)
val properties = new Properties()
properties.setProperty("bootstrap.servers", "localhost:9092")
properties.setProperty("group.id", "test")
//2.指定输入源
val streams = env.addSource(new FlinkKafkaConsumer[String]("topic01",new SimpleStringSchema(),properties))
//3.执行打印输出
streams.print()
//4.执行任务
env.execute("kafkasource")
提示:需要额外引入kafka依赖
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-kafka_2.11artifactId>
<version>1.8.1version>
dependency>
Flink Sinks
Data Sinks 用于消费DataStream中的数据并且将数据写入到文件、网络或者外围系统。Flink 提供了各种各样的内建的输出格式封装在DataStreams中。
- writeAsText()/TextOutputFormat - 将元素以行的形式写到文件中,默认系统会调用被写出元素的toString方法。
- writeAsCsv(…)/CsvOutputFormat - 将元素以逗号的形式隔开,行和fields的分隔符可以配置。
- print()/printError() - 将流中的元素打印到控制台的标准输出/错误输出。通常可以选择性给个"prefix(msg)"用于区分是由哪个流输出的。如果输出的任务并行度数目不为1,则还会在前缀加人任务的Id
- writeUsingOutputFormat()/ FileOutputFormat - 自定义输出,支持字节到对象的转换。
- writeToSocket - 更具SerializationSchema将元素写出到socket网络套接字中。
Note:所有的write*的方法大多主要用于测试过程。这些写出的数据并不会参与flink的checkpoint(容错过程)。这也就意味着这些操作只能保证at-least-once语义的保证。数据写到外围系统取决于OutputFormat实现,也就意味着所有写到OutputFormat中的数据并不一定立即写出到目标系统。也就是说在系统故障的时候这些没有来得及写入到外围系统的数据就可能丢失。因此为了可靠性并且保证exactly-once 语义将数据写入到文件系统可以使用flink-connector-filesystem模块,当然自定义的实现的类也可以通过.addSink(…)方法用于实现flink的exactly-once语义的sink实现。
writeAsText/Csv
将数据写入到文件系统中,通常用于测试案例。
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.core.fs.FileSystem.WriteMode
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import org.apache.kafka.clients.consumer.ConsumerConfig
object FlinkExecutionDataSink {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.createLocalEnvironment()
val props = new Properties()
props.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092")
props.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "g1")
env.addSource(new FlinkKafkaConsumer[String]("topic01",new SimpleStringSchema(),props))
.flatMap(line => for( i <- line.split(" ")) yield (i,1))
.keyBy(_._1)
.reduce((in1,in2)=>(in1._1,in1._2+in2._2))
.writeAsCsv("file:///Users/jiangzz/Desktop/results/csv",WriteMode.OVERWRITE).setParallelism(1)
//.writeAsText("hdfs://localhost:9000/result",WriteMode.OVERWRITE).setParallelism(1)
env.execute("word counts")
}
}
注意如果需要将统计的测试数据写入到hdfs文件系统,还需要导入如下依赖
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>2.9.2version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>2.9.2version>
dependency>
为了可靠,准确地将流传送到文件系统,请使用flink-connector-filesystem。此外,通过该.addSink(...)方法的自定义实现可以参与Flink的精确一次语义检查点。
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import org.apache.flink.streaming.connectors.fs.bucketing.{BucketingSink, DateTimeBucketer}
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import org.apache.kafka.clients.consumer.ConsumerConfig
object FlinkExecutionDataSink02 {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.createLocalEnvironment()
val props = new Properties()
props.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092")
props.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "g1")
val bucketingSink = new BucketingSink[(String,Int)]("hdfs:///bucketingSink")
bucketingSink.setBucketer(new DateTimeBucketer[(String, Int)]("yyyy-MM-dd-HH-mm"))
bucketingSink.setBatchSize(1024)
env.addSource(new FlinkKafkaConsumer[String]("topic01",new SimpleStringSchema(),props))
.flatMap(line => for( i <- line.split(" ")) yield (i,1))
.keyBy(_._1)
.reduce((in1,in2)=>(in1._1,in1._2+in2._2))
.addSink(bucketingSink)
env.execute("word counts")
}
提示
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-filesystem_2.11artifactId>
<version>1.8.1version>
dependency>
Redis Sink
参考:https://bahir.apache.org/docs/flink/current/flink-streaming-redis/
<dependency>
<groupId>org.apache.bahirgroupId>
<artifactId>flink-connector-redis_2.11artifactId>
<version>1.0version>
dependency>
val env = StreamExecutionEnvironment.createLocalEnvironment()
val props = new Properties()
props.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092")
props.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "g1")
val conf = new FlinkJedisPoolConfig.Builder().setHost("localhost").setPort(6379).build()
env.addSource(new FlinkKafkaConsumer[String]("topic01",new SimpleStringSchema(),props))
.flatMap(line => for( i <- line.split(" ")) yield (i,1))
.keyBy(_._1)
.reduce((in1,in2)=>(in1._1,in1._2+in2._2))
.addSink(new RedisSink[(String, Int)](conf,new RedisWordMapper))
env.execute("word counts")
RedisWordMapper
import org.apache.flink.streaming.connectors.redis.common.mapper.{RedisCommand, RedisCommandDescription, RedisMapper}
class RedisWordMapper extends RedisMapper[(String,Int)]{
override def getCommandDescription: RedisCommandDescription = {
new RedisCommandDescription(RedisCommand.HSET,"words")
}
override def getKeyFromData(t: (String, Int)): String = {
t._1
}
override def getValueFromData(t: (String, Int)): String = {
t._2.toString
}
}
集群
FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder()
.setNodes(new HashSet(Arrays.asList(new InetSocketAddress(5601)))).build();
哨兵
val conf = new FlinkJedisSentinelConfig.Builder()
.setMasterName("master")
.setSentinels(...)
.build()
stream.addSink(new RedisSink[(String, String)](conf, new RedisExampleMapper))
Kafka Sink
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-kafka_2.11artifactId>
<version>1.8.1version>
dependency>
val env = StreamExecutionEnvironment.createLocalEnvironment()
val props = new Properties()
props.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092")
props.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "g1")
val conf = new FlinkJedisPoolConfig.Builder().setHost("localhost").setPort(6379).build()
val props1 = new Properties()
props1.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "CentOS:9092,CentOS:9093,CentOS:9094")
val flinkKafkaProducer = new FlinkKafkaProducer[(String,Int)]("topic02",new TupleSerializationSchema(),props)
env.addSource(new FlinkKafkaConsumer[String]("topic01",new SimpleStringSchema(),props))
.flatMap(line => for( i <- line.split(" ")) yield (i,1))
.keyBy(_._1)
.reduce((in1,in2)=>(in1._1,in1._2+in2._2))
.addSink(flinkKafkaProducer)
env.execute("word counts")
TupleSerializationSchema
import org.apache.flink.streaming.util.serialization.KeyedSerializationSchema
class TupleSerializationSchema extends KeyedSerializationSchema[(String,Int)]{
override def serializeKey(element: (String, Int)): Array[Byte] = {
element._1.getBytes()
}
override def serializeValue(element: (String, Int)): Array[Byte] = {
element._2.toString.getBytes()
}
override def getTargetTopic(element: (String, Int)): String = null
}