Python基础篇三——字符串
目录
- 01 学习目标
- 02 重点难点
- 03 学习任务
-
- 一,字符串
-
- 1,什么是字符串
- 2,转义字符
- 3,原始字符串
- 4,长字符串
- 二,字符串的输出和输入
-
- 1,字符串的输出
- 2,字符串的输入
- 三,访问字符串中的值
-
- 1,字符串的存储方式
- 2,什么是切片
- 3,使用切片截取字符串
- 四,字符串内建函数
-
- 1,大小写字母转换
- 2,,左中右对齐
- 3,字符串的查找
- 4,替换
- 5,判断和检测
- 6,截取
- 7,分割
- 五,字符串运算符
-
- 1,字符串运算符
- 04 文章小结
01 学习目标
1,了解字符串操作符的使用
2,掌握字符串的输入和输出
3,掌握且能熟练使用字符串的各种内建函数
4,了解转义字符的使用
02 重点难点
重点:
1,转义字符
2,切片操作
3,字符串运算符
4,字符串的各种内建函数!!!
难点:
1,切片
2,字符串内建函数!!!
03 学习任务
一,字符串
1,什么是字符串
目前为止,我们所认知的字符串就是引号内的一切东西。
字符串也称为文本,是一种表示文本数据的类型。
文本和数字是截然不同的。
使用单引号:
'泽某'
'520'
使用双引号:
"泽某人"
"520"
使用三引号:
"""
泽某
"""
注意:以上引号,不论是我们的单引号,双引号还是三引号,都必须是英文输入法的引号,中文输入法是错误的!!!
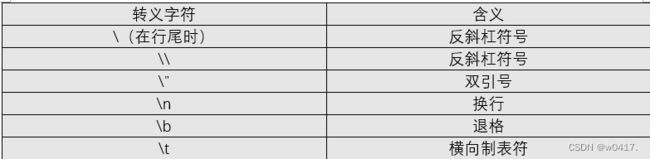
2,转义字符
对于单引号或者双引号等这些特殊符号,我们可以对其进行转义。
举个栗子~
>>>'let\'s go!' #输入
'let's go!' #输出
3,原始字符串
在字符串前边加一个英文字母r就是原始字符串。
原始字符串的用途是什么呢?一般情况下是在一个字符串中有很多个反斜杠时才会使用原始字符串~
举个栗子:
>>>string = r"I Like 唱跳rap和篮球"
>>>string
'I Like 唱跳rap和篮球'
>>>print(string)
I Like 唱跳rap和篮球
4,长字符串
假如我们希望得到一个跨越多行的字符串,例如:
我是泽
今年18
身高?185!
头发茂盛的程序猿(傲娇~)
我独爱Python
人生苦短,我爱Python!
用我们学过的办法打印就需要使用多个换行符:
>>>print("我是泽\n今年18\n身高?185!\n头发茂盛的程序猿(傲娇~)\n我独爱Python\n人生苦短,我用Python\n")
对于这种长字符串有一个简便的方法:
>>>print("""
我是泽
今年18
身高?185!
头发茂盛的程序猿(傲娇~)
但我独爱Python
人生苦短,我爱Python!
""") #使用三引号字符串("""内容""")就阔以了~
二,字符串的输出和输入
1,字符串的输出
现有如下代码:
print("劳资蜀道一")
print("劳资蜀道二")
pringt("劳资蜀道三")
能否简化这个代码呢?答案是当然可以咯~看下面代码:
name = "小哥"
age = 18
print("大家好,我是%s,今年%d岁"%(name, age))
这便是字符串的格式化输出啦~
常见的格式化符号:
| 格式化符号 | 转换 |
|---|---|
| %s | 通过str()字符串转换来格式化 |
| %d | 有符号的十进制整数 |
| %f | 浮点实数 |
2,字符串的输入
Python3为用户提供了input()函数从标准输入读取一行文本,默认标准输入是键盘。input()可以接收一个Python表达式作为输入,并将运算结果返回。
>>>username = input("请输入您的用户名")
>>>print(username)
三,访问字符串中的值
1,字符串的存储方式
字符串中的每个字符都有对应的一个下标索引,下标索引的编号是从0开始的,即第一个字符的下标索引为0,第二个字符下标索引为1,第三个字符下标索引为2,第四个字符下标索引为3,以此类推

2,什么是切片
切片的语法格式如下:
[起始 :结束 : 步长]
用一个冒号把两个索引值隔开,冒号左边是开始位置,冒号右边是结束位置。切片选取的区间属于左闭右开型,即就是说从“起始位”开始到“结束位”的前一位结束。 不包含结束位本身!
3,使用切片截取字符串
(1)省略开始位置:Python会从下标索引值为0的位置开始截取,到指定结束的下标索引位置结束截取。
(2)省略结束位置:同理,Python会从指定的的下标索引值位置开始截取,到列表末尾的最后一个元素结束截取。
(3)省略起始和结束位:如果步进值为正数,则按照步进值的多少正向截取;如果步进值为负数,则按照步进值的多少反向截取;
举个栗子:
>>>name = "a, b, c, d, e, f"
>>>name[3: 5] #正常情况下的切片形式
d, e
>>>name[: 3] #情况(1)
a, b, c
>>>name[2:] #情况(2)
>c, d, e, f
>>>name[1: -1] #截取下标索引值是1的元素至下标索引值是倒数第一的元素
b, c, d, e
>>>name[::-2] #情况(3)
f, d, b
四,字符串内建函数
1,大小写字母转换
(1)capitalize()函数:将字符串的首字母变为大写,其他字母变为小写。
给大家举栗子:
>>>x = "i like Python"
>>>x.capitalize()
"I like python" #将整个字符串的首字母大写。和(3)有区别
(2)casefold()函数:返回一个所有字母都是小写的新字符串。
举个栗子:
>>>x = "i like Python"
>>>x.casefold()
"i like python"
(3)title()函数:将字符串中每个单词的首字母全部变为大写,该单词的其他字母都变为小写。
举个栗子:
>>>x = "i like Python"
>>>x.title()
"I Like Python" #和(1)有区别。
(4)swapcase()函数:将字符串中所有字母大小写互相转换(大写变为小写,小写变为大写)。
举个栗子:
>>>x = "i like Python"
>>>x.swapcase()
"I LIKE pYTHON"
(5)upper函数():将所有字母都变为大写。
举个栗子:
>>>x = "i like Python"
>>>x.upper()
"I LIKE PYTHON"
(6)lower函数():将所有字母都变为小写。
举个栗子:
>>>x = "I like Python"
>>>x.lower()
"i like python"
2,,左中右对齐
总共有四个方法,且四个方法都必须要有一个width参数。 注意:width参数用来指定整个字符串的宽度。如果指定的宽度小于或等于源字符串的宽度,那么直接输出源字符串。
且前三种方法还支持fillchar参数,默认为空格,即就是说,如果我们不设置它,它就用空格自动填充,所以我们可以任意修改这个填充的字符。
(1)center()函数:返回一个width参数指定宽度且居中对齐的字符串.
str.center(width[, fillchar])
参数说明:
width:字符串的总宽度。
fillchar:填充字符
举个栗子:
>>>str = "阿里嘎多美羊羊桑"
>>>str.center(5) #传入的width参数值是5,而字符串str共有8个字符,小于源字符串的宽度,直接输出了源字符串
"阿里嘎多美羊羊桑"
>>>str.center(12) #传入的width参数值是12,而字符串str共有8个字符,大于源字符串的宽度,那么就会将源字符串居中放置,左右两边各用两次空格填充,共四次。
" 阿里嘎多美羊羊桑 "
(2)ljust函数():左对齐。使用空格填充至指定长度的新字符串。str.ljust(width[, fillchar])
参数说明:
width:指定字符串的宽度。
fillchar:填充字符,默认为空格
举个栗子:
>>>str = "沸羊羊你八嘎呀路"
>>>str.ljust(12)
"沸羊羊你八嘎呀路 " #字符串左对齐,右边用空格填充至12个字符,空格此时有4格
(3)rjust()函数:右对齐。使用空格填充至指定长度的新字符串。str.ljust(width[, fillchar])
参数说明:
width:指定字符串的宽度。
fillchar:填充字符,默认为空格
举个栗子:
>>>str = "哎呀你干嘛~"
>>>str.rjust(8) #width参数的值为8
" 哎呀你干嘛~" #字符串右对齐,左边用空格填充2个字符,空格此时有2格。
(4)zfill()函数:用0填充左侧至指定长度的新字符串。
str.zfill(width)
参数说明:
width:指定字符串的宽度。
举个栗子:
>>>str = "只因你太美~"
>>>str.zfill(8) #width参数的值为8
"00只因你太美~" #用0填充左侧
zfill方法在做数据报表等工作时较方便
例如:
>>>"1100".zfill(5) #要求数据宽度是5个字符
01100 #用0填充
>>>"-520".zfill(5) #处理负数
"-0520" #负号挪至左边,剩下的用0填充
3,字符串的查找
(1)find函数():用于定位string参数指定的子字符串在字符串中的下标索引值。
str.find(string, beg = 0, end = len(str))
注意:find函数是从左往右查找。
参数说明:
str:指定检索的字符串。
beg:开始索引,默认为0。
end:结束索引,默认为字符串的长度。
返回索引,如果找不到,结果是-1
举个栗子:
>>>str = "上海自来水来自海上"
>>>str.find("海") #从左往右查找str字符串第一个“海”字出现时的下标索引
1 #从左至右第一个“海”字出现时的下标索引值是1
>>>str.find("坤") #在字符串str中找一个字符“坤”
-1 #找不到,返回-1
(2)rfind函数():用于定位string参数指定的子字符串在字符串中的下标索引值。
str.rfind(string, beg = 0, end = (str))
注意:rfind函数是从右往左查找。
参数说明:
str:指定检索的字符串。
beg:开始索引,默认为0。
end:结束索引,默认为字符串的长度。
返回索引,如果找不到,结果是-1
举个栗子:
>>>str = "上海自来水来自海上"
>>>str.rfind("海") #从右往左查找str字符串第一个“海”字出现时的下标索引
7 #从右至左第一个“海”字出现时的下标索引值是7
>>>str.rfind("坤") #在字符串str中找一个字符“坤”
-1 #找不到,返回-1
(3)index()函数:用于定位string参数指定的子字符串在字符串中的下标索引值。
str.index(string, beg = 0, end = len(str))
注意:index()函数是从左往右查找。
参数说明:
str:指定检索的字符串。
beg:开始索引,默认为0。
end:结束索引,默认为字符串的长度。
返回索引,如果找不到则会报错。
举个栗子:
>>>str = "上海自来水来自海上"
>>>str.index("坤") #在字符串str中找一个字符“坤”
...... #Python报错
(4)rindex函数():用于定位string参数指定的子字符串在字符串中的下标索引值。
str.index(string, beg = 0, end = len(str))
注意:rindex函数是从右往左查找。
参数说明:
str:指定检索的字符串。
beg:开始索引,默认为0。
end:结束索引,默认为字符串的长度。
返回索引,如果找不到则会报错。
栗子同上,这里就不在赘述了
(5)count函数():查找sub参数指定的子字符串在字符中出现的次数。
str.count(sub, start = 0, end = len(str))
参数说明:
sub:搜索的子字符串。
start:字符串开始搜索的位置。
end:字符串结束搜索的位置。
举个栗子~
str = "上海自来水来自海上"
>>>str.count("海") #查找“海”这个字在字符中出现的总次数
2
剩下的两个参数start和end用于指定查找的起始和结束位置!
>>>str.count("海", 0, 5) #0是起始查找位置,5是结束查找的位置,0和5都是下标索引值
1
4,替换
(1)replace函数():返回一个将old参数指定的所有子字符串替换为new参数指定的新字符串。max参数指定替换的次数,默认值为-1,即就是说,如果不设置max参数,相当于替换全部。
str.replace(old, new[,max])
参数说明:
old:旧字符串,即被替换的字符串。
new:新字符串,用于替换旧字符串。
max:可选字符串,替换不超过max次。
举个栗子~
"****沸羊羊,劳资可是懒大王!".replace("****", "Q*MD") #****是旧字符串,Q*MD是新字符串
"Q*MD沸羊羊,劳资可是懒大王!"
(2)translate函数():返回一个根据table参数转换后的新字符串。参数名字叫table,是表格的意思。用来指定一个转换规则的表格。str.translate(table)
5,判断和检测
(1)startswith函数():用于判断参数string指定的子字符串是否出现在字符串的起始位置。
str.startswith(string, beg = 0, end = len(str))
参数说明:
str:检测的字符串。
beg:可选参数。用于设置字符串检测的起始位置。
end:可选参数。用于设置字符串检测的结束位置。
给大家表演一段博主练习了两年半的才艺:
>>>str = "只因......"
>>>str.startswith("只") #"只"位于变量str的起始位置,返回True
True
>>>str.startswith("ikun") #同理,返回False
False
(2)endswith函数():与(1)相反,用于判断参数string指定的子字符串是否出现在字符串的结束位置。
str.endswith(suffix[,start[,end]])
参数说明:
suffix:该参数可以是一个字符串也可以是一个元素。
start:可选参数。用于设置字符串检测的起始位置。
end:可选参数。用于设置字符串检测的结束位置。
>>>str = "只因你太美"
>>>str.endswith("只") #"只"位于变量str的起始位置,返回False
False
>>>str.endswith("美") #同理,返回True
True
(3)isupper()函数:判断一个字符串中所有的字母是否都为大写。str.isupper()
举栗:
>>>str = "I like Python"
>>>str.isupper()
False #like和Python两个单词的字母都不全是大写,输出False
(4)islower函数():判断所有字母是否都为小写。
str.islower()
(5)istitle函数():判断一个字符串中的所有单词是否都是以大写字母开头,而其余字母都为小写。
str.istitle()
举栗:
>>>str = "I like Python"
>>>str.istitle()
False #因为单词like的首字母l未大写,所以返回False
(6)isalpha函数():判断一个字符串是否只由字母构成。str.isalpha()
举栗:
>>>str = "只因你太美"
>>>str.isalpha()
False
>>>"ilikepython".endswith()
True
6,截取
(1)strip函数():截掉字符串左右两边的空白或指定的字符。str.strip([chars])
参数说明:chars:默认为None,(None在Python中表示什么都没有,在此处的意思就是去除空白。下同)移除字符串左右两边(即首尾)指定的字符。
(2)lstrip函数():截掉字符串左边的空白或指定的字符。str.lstrip([chars])
参数说明:chars:移除左侧空白部分
(3)rstrip函数():截掉字符串右边的空白或指定的字符。str.rstrip([chars])
参数说明:chars:移除右侧空白部分
举栗:
>>>" 左右两边不要留空白 ".strip()
"左右两边不要留空白"
>>>" 左边不要留空白".lstrip()
"左边不要留空白"
>>>"右边不要留空白 ".rstrip()
"右边不要留空白"
7,分割
(1)split函数():通过指定分隔符对字符串进行切片。
str.split(string = “”, num = str.count(string))
参数说明:
str:分隔符。
num:分割的次数,默认为-1,生成列表。
五,字符串运算符
1,字符串运算符
| 操作符 | 描述 |
|---|---|
| + | 字符串连接(拼接) |
| * | 字符串重复输出(复制) |
| [ ] | 通过索引获取字符串中的字符 |
| [:] | 截取字符串中的一部分 |
and:
| 操作符 | Column 2 |
|---|---|
| in | 成员运算符。如果字符串中包含给定的字符,则返回True |
| not in | 成员运算符。如果字符串中不包含给定的字符,则返回True |
| r\R | 原始字符串。所有的字符串都是按字面意思直接使用,没有转义特殊或不能打印的字符 |
04 文章小结
本文主要为大家讲解了字符串的相关知识。首先给大家讲解了什么是字符串以及转义字符还有另外两种字符串,其次是字符串的格式化输入输出,接着是切片操作(此为本篇的重难点!)最后是字符串的各种内建函数,主要有大小写互相转换,左中右对齐,查找,替换,截取等等。希望大家通过本文的学习能对字符串有一个更深的理解和学习,如有错误之处欢迎读者指出和批评,谢谢~