JavaScript基础知识巩固
JavaScript基础
输入输出语法
输出:
document.write('要输出的内容')
alert('页面弹出警告窗')
console.log('控制台打印')
输入:
let value = prompt('用户输入的内容')
变量的本质
是程序在内存中申请的一块用来存放数据的空间
变量命名规范
不能用关键字
关键字:有特殊含义的字符,JavaScript 内置的一些英语词汇。例如:let、var、if、for等 Ø
只能用下划线、字母、数字、$组成,且数字不能开头
字母严格区分大小写,如 Age 和 age 是不同的变量
let、var 、const
var 现在开发中一般不再使用它,只是我们可能再老版程序中看到它。
let 为了解决 var 的一些问题。
var 声明:
-
可以先使用 在声明 (不合理)
-
var 声明过的变量可以重复声明(不合理)
-
比如变量提升、全局变量、没有块级作用域等等
使用 const 声明常量
当某个变量永远不会改变的时候,就可以使用 const 来声明,而不是let。
常量不允许重新赋值,声明的时候必须赋值(初始化)
不需要重新赋值的数据使用const
数据类型
基本数据类型:number、string、Boolean、undefined(未定义)、null(空)、NaN(也是一个数字类型)
引用数据类型:对象、数组、函数
-
NaN:not a number(不是一个数字,代表一个计算错误。它是一个不正确的或者一个未定义的数学操作所得到的结果)
-
undefined:只声明变量,不赋值的情况下,变量的默认值为 undefined,一般很少【直接】为某个变量赋值为 undefined
我们开发中经常声明一个变量,等待传送过来的数据。 如果我们不知道这个数据是否传递过来,此时我们可以通过检测这个变量是不是undefined,就判断用户是否有数据传递过来
像函数的形参,没有传递过来数据的时候就是undefined
-
null:仅仅是一个代表“空”或“值未知”的特殊值
-
null 和 undefined 区别: undefined 表示没有赋值; null 表示赋值了,但是内容为空
将来有个变量里面存放的是一个对象,但是对象还没创建好,可以先给个null
类型转换
JavaScript是弱数据类型
隐式转换:
- + 号两边只要有一个是字符串,都会把另外一个转成字符串
- 除了+以外的算术运算符 比如 - * / 等都会把数据转成数字类型(转换为数字类型发生错误就会得到一个NaN)
小技巧:
-
+号作为正号解析可以转换成数字型
-
任何数据和字符串相加结果都是字符串
显示转换:
Number(数据)
转成数字类型
如果字符串内容里有非数字,转换失败时结果为 NaN(Not a Number)即不是一个数字
NaN也是number类型的数据,代表非数字
parseInt(数据) 只保留整数
parseFloat(数据) 可以保留小数
一元运算符
自增运算符:
- 前置自增 ++ num
- 后置自增 num++
二者单独使用没有区别
参与计算的时候,
前置自增:先自加再使用(记忆口诀:++在前 先加)
后置自增:先使用再自加(记忆口诀:++在后 后加)
let i = 1
console.log(i++ + ++i + i)
// i++ 数值为1参与运算
// 此时i++ i为2
// ++i 数值为3参与运算
// 此时i为3
// +i
// 最终结果为
// i + 3 + 3 = 7
// 输出结果为:7
双等号()和三等号(=)
== 号比较值,比较时会发生隐式转换,隐式转换为number类型进行比较
=== 比较类型也比较值,没有隐式转换,开发中推荐使用 ===
从性能上来说,== 走了隐式转换那一层效率更低一些相较于 ===
Switch语句:
找到跟小括号里数据全等的case值,并执行里面对应的代码
若没有全等 === 的则执行default里的代
switch case语句一般用于等值判断,不适合于区间判断
switch case一般需要配合break关键字使用 没有break会造成case
不同类型的数据在内存中的分配情况


对象的增删改查

字符串遍历:for(let key of string) {console.log(key)}
对象的遍历:for(let key in obj) {console.log(key, obj[key])} // 属性名, 属性值
JavaScript包括:ECMAJavaScript(欧洲计算机制造者协会) + web APIs(DOM + BOM)
DOM基础
使用js操作DOM
根据CSS选择器获取DOM元素(重要)
择匹配到的第一个元素,如果没有匹配到,则返回null
document.querySelector('css选择器')
选择匹配的多个元素,返回的是一个伪数组
获取到的集合没有pop和push等方法,要是用for循环来获取每个元素对象
document.querySelectorAll('css选择器')
其他获取DOM元素的方法(了解)
document.getElementById('id名')通过id获取元素
document.getElementsBytagName('标签名')通过标签名来获取元素集合
document.getElementsByClassName('类名')通过类名获取元素集合
操作元素内容
元素.innerText = ''
将文本内容添加/更新到任意标签位置;
显示纯文本,不解析标签
元素.innerHTML = ''
会解析标签,多标签建议使用模板字符
操作元素普通属性
对象.属性 = '值'
操作元素样式属性
obj.style.color = '' 如果属性有使用 - 连接的使用小驼峰命名法
obj.className = '' 设置一个类名会覆盖先前的类名
obj.classList.append('') 添加一个类名,不影响已存在的类名
obj.classList.remove('') 移除一个类名,不影响其他类名
obj.classList.toggle('') 切换一个类名,覆盖之前的类名
操作表单元素属性
获取:DOM对象.属性
设置:DOM对象.属性 = '新值'
自定义属性H5推出
在标签上一律以data-开头
在DOM对象上面一律以dataset对象方式获取
定义:
获取:document.querySelector('div').dataset.id
循环定时器:
let timer = setInterval(function() {}, 1000) 回调函数、循环间隔时间
clearInterval(timer)
单次定时器:
let timer = setTimeout(function() {}, 1000)
clearTimeout(timer)
事件监听
on方式会被覆盖,addEventListener方式可绑定多次,拥有事件更多特性,推荐使用
元素对象.on事件类型 = function() {}
元素对象.addEventListener('事件类型', function(e) {})
时间类型:
- 鼠标单击事件:click
- 鼠标经过:mouseenter(mouseenter 和 mouseleave 没有冒泡效果 (推荐))
- 鼠标离开:mouseleave
- 获取焦点:focus
- 失去焦点:blur
- 键盘按下触发:keydown
- 键盘抬起触发:keyup
- 用户输入事件:input
- 鼠标经过:mouseover(mouseover 和 mouseout 会有冒泡效果)
- 鼠标离开:mouseout
- 手方法腿上:touchstart
- 手在大腿上来回摸:touchmove
- 手从大腿上挪开:touchleave
DOM进阶
事件流
假设页面里有个div,当触发事件时,会经历两个阶段,分别是捕获阶段、冒泡阶段
捕获阶段是 从父到子 冒泡阶段是从子到父
实际工作都是使用事件冒泡为主
document.addEventListener('事件类型', 回调函数, '是否使用捕获机制(默认为false)')
addEventListener第三个参数传入 true 代表是捕获阶段触发(很少使用)
若传入false代表冒泡阶段触发,默认就是false
若是用 on 事件监听,则只有冒泡阶段,没有捕获
当一个元素的事件被触发时,同样的事件将会在该元素的所有祖先元素中依次被触发。这一过程被称为事件冒泡
当一个元素触发事件后,会依次向上调用所有父级元素的 同名事件,事件冒泡是默认存在的
使用事件对象 阻止冒泡 / 阻止默认行为(a连接的点击跳转,表单域跳转均为默认事件)
元素对象.addEventListener(‘事件类型’, function(e) {
e.stopPropagation()阻止冒泡
e.stopDefault()阻止默认行为
})
解绑事件
btn.onClick = function() {}
btn.onClikc = null
btn.addEventListener('click', fn)
btn.removeEventListener('click', fn)
两种注册事件的区别
传统on注册(L0)
Ø 同一个对象,后面注册的事件会覆盖前面注册(同一个事件)
Ø 直接使用null覆盖偶就可以实现事件的解绑
Ø 都是冒泡阶段执行的
事件监听注册(L2)
Ø 语法: addEventListener(事件类型, 事件处理函数, 是否使用捕获)
Ø 后面注册的事件不会覆盖前面注册的事件(同一个事件)
Ø 可以通过第三个参数去确定是在冒泡或者捕获阶段执行
Ø 必须使用removeEventListener(事件类型, 事件处理函数, 获取捕获或者冒泡阶段)
Ø 匿名函数无法被解绑
事件委托
事件委托是利用事件流的特征解决一些开发需求的知识技巧
Ø 优点:减少注册次数,可以提高程序性能
Ø 原理:事件委托其实是利用事件冒泡的特点
Ø 给父元素注册事件,当我们触发子元素的时候,会冒泡到父元素身上,从而触发父元素的事件
Ø 实现:事件对象.target. tagName 可以获得真正触发事件的元素
页面加载事件、元素滚动事件、页面尺寸事件
页面加载事件
加载外部资源(如图片、外联CSS和JavaScript等)加载完毕时触发的事件
有些时候需要等页面资源全部处理完了做一些事情
Ø 老代码喜欢把 script 写在 head 中,这时候直接找 dom 元素找不到
事件名:load
监听页面所有资源加载完毕:window.addEventListener('load', function() {})
不光可以监听整个页面资源加载完毕,也可以针对某个资源绑定load事件
当初始的 HTML 文档被完全加载和解析完成之后,DOMContentLoaded 事件被触发
而无需等待样式表、图像等完全加载
事件名:DOMContentLoaded
监听页面DOM加载完毕:
Ø 给 document 添加 DOMContentLoaded 事件
document.addEventListener('DOMContentLoaded', function() {})
页面滚动事件
滚动条在滚动的时候持续触发的事件
Ø 很多网页需要检测用户把页面滚动到某个区域后做一些处理, 比如固定导航栏,比如返回顶部
事件名:scroll
监听整个页面滚动:
获取到整个页面上卷去的距离
window.addEventListener('scroll', function(e) {console.log(document.documentElement.scrollTop)})
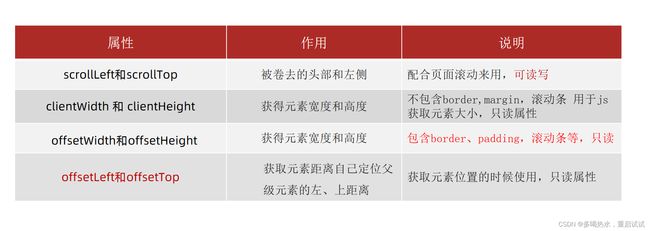
scrollLeft和scrollTop (属性)
Ø 获取被卷去的大小
Ø 获取元素内容往左、往上滚出去看不到的距离
Ø 这两个值是可读写的
scrollTo(X, Y) 方法可把内容滚动到指定的坐标
window.scrollTo(0, 0)
页面尺寸事件
会在窗口尺寸改变的时候触发事件
检测屏幕宽度
window.addEventListener('resize', function(e) {console.log(docuemnt.documentElement.clientWidth)})
获取元素的可见部分宽高(不包含边框,margin,滚动条等)
Ø clientWidth和clientHeight
offsetWidth和offsetHeight是得到元素什么的宽高?
Ø 内容 + padding + border
offsetTop和offsetLeft 得到位置以谁为准?
Ø 带有定位的父级
Ø 如果都没有则以 文档左上角 为准
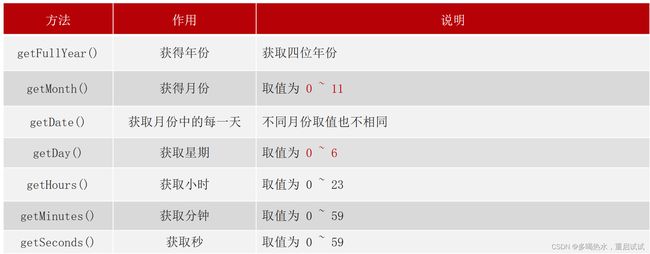
日期对象
const date = new Date()
时间戳,常用语计算倒计时
指1970年01月01日00时00分00秒起至现在的毫秒数,它是一种特殊的计量时间的方式
将来的时间戳 - 现在的时间戳 = 剩余时间毫秒数
Ø 剩余时间毫秒数 转换为 剩余时间的 年月日时分秒 就是 倒计时时间
获取时间戳:new Date().getTime() +new Date() Date.now()
转换公式:
Ø d = parseInt(总秒数/ 60/60 /24); // 计算天数
Ø h = parseInt(总秒数/ 60/60 %24) // 计算小时
Ø m = parseInt(总秒数 /60 %60 ); // 计算分数
Ø s = parseInt(总秒数%60); // 计算当前秒数
节点操作
查找节点:
子元素.parentNode: 查找父节点:
父元素.childNodes: 获得所有子节点、包括文本节点(空格、换行)、注释节点等
父元素.children: 仅获得所有元素节点, 返回的还是一个伪数组
元素节点.nextElementSibling: 下一个兄弟节点
元素节点.previousElementSibling: 上一个兄弟节点
添加节点:
父元素.appendChild(document.createElement('标签名')): 插入到父元素的最后
父元素.insertBefore(要插入的元素, 在哪个元素前面)
元素节点.cloneNode(boolean)
cloneNode会克隆出一个跟原标签一样的元素,括号内传入布尔值
Ø 若为true,则代表克隆时会包含后代节点一起克隆
Ø 若为false,则代表克隆时不包含后代节点
Ø 默认为false
删除节点:
父元素.removeChild(要删除的节点)
删除节点和隐藏节点(display:none) 有区别的: 隐藏节点还是存在的,但是删除,则从html中删除节点
BOM操作
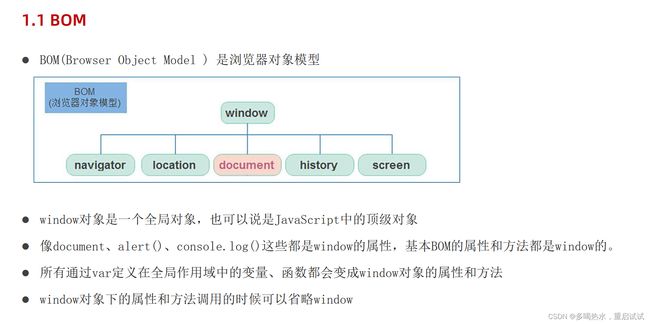
window对象
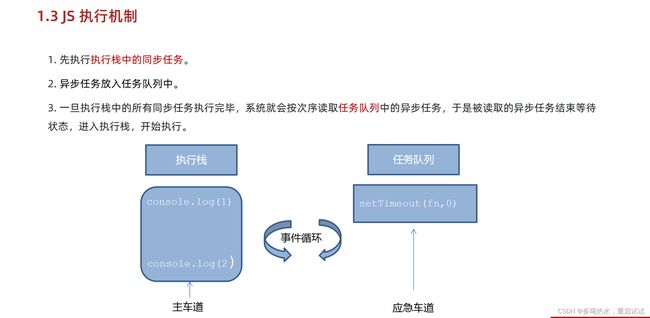
JS执行机制


location对象
常用属性和方法:
Ø href 属性获取完整的 URL 地址,对其赋值时用于地址的跳转
Ø search 属性获取地址中携带的参数,符号 ?后面部分
Ø hash 属性获取地址中的啥希值,符号 # 后面部分(配合可实现局部刷新)
后期vue路由的铺垫,经常用于不刷新页面,显示不同页面,比如 网易云音乐
Ø reload 方法用来刷新当前页面,传入参数 true 时表示强制刷新
navigator对象
navigator的数据类型是对象,该对象下记录了浏览器自身的相关信息
通过 userAgent 检测浏览器的版本及平台
/ 检测 userAgent(浏览器信息)
!(function () {
const userAgent = navigator.userAgent
// 验证是否为Android或iPhone
const android = userAgent.match(/(Android);?[\s\/]+([\d.]+)?/)
const iphone = userAgent.match(/(iPhone\sOS)\s([\d_]+)/)
// 如果是Android或iPhone,则跳转至移动站点
if (android || iphone) {
location.href = 'https://www.baidu.com'
}
})()
history对象
history 的数据类型是对象,主要管理历史记录, 该对象与浏览器地址栏的操作相对应,如前进、后退、历史记录等
history.forward() == history.go(1)前进
history.back() == history.go(-1)后退
本地存储
1、数据存储在用户浏览器中
2、设置、读取方便、甚至页面刷新不丢失数据
3、容量较大,sessionStorage和localStorage约 5M 左右
localStorage:
作用: 可以将数据永久存储在本地(用户的电脑), 除非手动删除,否则关闭页面也会存在
Ø 可以多窗口(页面)共享(同一浏览器可以共享)
Ø 以键值对的形式存储使用
localStorage.setItem('key', 'value')
localStorage.getItem('key')
localStorage.removeItem('key')
localStorage.clear()
sessionStorage:
生命周期为关闭浏览器窗口
Ø 在同一个窗口(页面)下数据可以共享
Ø 以键值对的形式存储使用
Ø 用法跟localStorage 基本相同
二者存储复杂数据类型时需要对value进行处理,转换为字符串存储,使用
JSON.stringify(对象)
JSON.parse(对象字符串)
正则表达式
正则表达式(Regular Expression)是用于匹配字符串中字符组合的模式。在 JavaScript中,正则表达式也是对象
使用场景:
1. 例如验证表单(匹配)
2. 过滤掉页面内容中的一些敏感词(替换)
3. 从字符串中获取我们想要的特定部分(提取)
语法:const 变量名 = /表达式/
其中 / / 是正则表达式字面量
test() 方法 用来查看正则表达式与指定的字符串是否匹配
exec() 方法 在一个指定字符串中执行一个搜索匹配
元字符:
边界符
^:表示匹配行首的文本(已谁开头)
$:表示匹配行尾的文本(已谁结束)
如果 ^ 和 $ 在一起,表示必须是精确匹配
量词:

元字符:
Ø [a-z] 表示 a 到 z 26个英文字母都可以
Ø [a-zA-Z] 表示大小写都可以
Ø [0-9] 表示 0~9 的数字都可以
(1) [ ] 里面加上 ^ 取反符号
比如:
Ø [^a-z] 匹配除了小写字母以外的字符
Ø 注意要写到中括号里面
(2) . 匹配除换行符之外的任何单个字符

修饰符:
Ø i 是单词 ignore 的缩写,正则匹配时字母不区分大小写
Ø g 是单词 global 的缩写,匹配所有满足正则表达式的结果(使用replaceAll的时候必须要添加修饰符g)
str.replace(正则表达式, '要替换的内容')
JavaScript进阶
作用域
作用域分为 局部作用域 和 全局作用域,
局部作用域又分为 函数作用域 和 块级作用域,
- 函数作用域的话,他是函数内部声明的变量,在函数外部无法被访问到,(当然,闭包除外,闭包联系到垃圾回收机制),函数的参数也是函数内部的局部变量,如果你的函数调用时形参没有传值,那么这个变量就是undefined,函数执行完毕后,函数内部的变量也就被清空了
- 块级作用域,也就是JavaScript中{}包裹的代码块,像if后边的代码块,for、while循环后面的代码块,立即执行函数的代码块,这些是块级作用域,其中let和const声明的变量才会产生块级作用域,var声明的变量不会产生会计作用于,不同代码块之间的变量无法相互访问。使用var声明变量会发生一些问题,在开发中还是以let 和 const为主
- 全局作用域是在js文件的最外层生声明的变量是全局变量,为window对象动态添加的属性默认也是全局变量,全局变量不会被js的垃圾回收机制回收,会造成变量常驻内存,不推荐,还有函数中未使用任何关键字声明的变量也为全局变量,全局变量非必要不声明
作用域链
作用域链的本质是底层变量的查找机制,
函数中在执行时,会优先查找当前函数的作用域中找寻要是用的变量,如果当前作用域为查找到,就会依次逐层查找父级作用域直到全局作用域,
这种嵌套关系的作用域串联起来就形成了我们说的作用域链,按着从小到大的规则查找变量,或者说就近原则,子作用域能够访问父级作用域的变量,父级作用域无法访问子作用域的变量
js垃圾回收机制
js中内存的分配和回收都是自动完成的,内存不在使用时会被垃圾回收机制回收,当然如果不了解垃圾回收机制,可能会在程序中造成内存泄漏
声明变量、函数、对象等的时候,系统会给他们分配内存,在程序运行的时候,他们会被使用,使用之后他们会被回收,全局变量和闭包一般不会被回收,只有在页面关闭的时候才回收。
垃圾回收机制有两种,引用计数法(已弃用);标记清除法(主流使用)
引用计数法:
IE采用的引用计数算法, 定义“内存不再使用”,就是看一个对象是否有指向它的引用,没有引用了就回收对象 算法: 1. 跟踪记录被引用的次数 2. 如果被引用了一次,那么就记录次数1,多次引用会累加 ++ 3. 如果减少一个引用就减1 – 4. 如果引用次数是0 ,则释放内存
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Nn4MVG8K-1690717228216)(JavaScript回顾.assets\image-20230730165644216.png)]
标记清除法:可以解决对象之间相互嵌套引用造成的内存泄漏
现代的浏览器已经不再使用引用计数算法了。 现代浏览器通用的大多是基于标记清除算法的某些改进算法,总体思想都是一致的。 核心: 1. 标记清除算法将“不再使用的对象”定义为“无法达到的对象”。 2. 就是从根部(在JS中就是全局对象)出发定时扫描内存中的对象。 凡是能从根部到达的对象,都是还需要使用的。 3. 那些无法由根部出发触及到的对象被标记为不再使用,稍后进行回收
闭包:
闭包等于,内部函数应用外部函数的变量,就形成的一个闭包
他可以把数据封装起来,实现数据私有,提供一些操作,可以在外部也访问到函数内部的变量,当然根据垃圾回收机制,他不会被垃圾回收机制回收,常驻内存可能会造成内存泄漏
函数提升
函数提升与变量提升比较类似,是指函数在声明之前即可被调用,和 var 的变量提升机制一样,函数提升也只出现的当前作用域中,但 var 的量提升调用为 undefined ,函数提升则是整个函数
函数参数:
- 动态参数
arguments只存在于函数内部是一个伪数组 - 剩余参数,不一般使用
...other来表示,他是一个真数组,就是把参数放在了这个数组中,使用...运算法把他展开了
解构赋值
数组结构、对象结构
构造函数
构造函数是用来快速创建多个类似的对象,以大写字母开头,
使用 new 关键字调用函数的行为被称为实例化
构造函数内部无需写return,返回值即为新创建的对象
使用new关键字实例化的过程都发生了哪些?
- 创建一个空对象
- 构造函数的this指向这个空对象
- 执行构造函数中的代码
- 把这个新创建的对象返回
实例化的对象身上的属性和方法是实例化属性和实例化方法
构造函数身上的属性和方法称叫做静态属性、静态方法
构造函数
基本数据类型: 字符串、数值、布尔、undefined、null
引用类型: 对象
但是,我们会发现有些特殊情况:
其实字符串、数值、布尔、等基本类型也都有专门的构造函数,这些我们称为包装类型。
引用类型 Object,Array,RegExp,Date 等
包装类型 String,Number,Boolean 等
Object
Object.keys(obj):获取对象中所有属性(键)
Object.values(obj):获取对象中所有属性值
Object.assign(newObj, obj)
常用于对象拷贝;经常使用的场景给对象添加属性
Array
forEach;filter;map;reduce;some;every;find;findIndex;join;concat;splice;slice;reverse;
String
str.length;
str.toUpperCase;
str.tolowerCase;
str.split();
str.subString();
str.includes();
str.indexOf()
str.startsWith()
str.endsWith()
str.replace()
str.match()
Number
num.toFixed()
编程思想
面向过程编程:
面向过程就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候再一个一个的依次 调用就可以了。
优点:性能比面向对象高,适合跟硬件联系很紧密 的东西,例如单片机就采用的面向过程编程。 缺点:没有面向对象易维护、易复用、易扩展
面向对象编程:
面向对象是把事务分解成为一个个对象,然后由对象之间分工与合作。
优点:易维护、易复用、易扩展,由于面向对象有封装 、继承、多态性的特性,可以设计出低耦合的系统,使 系统 更加灵活、更加易于维护 缺点:性能比面向过程低
原型
构造函数通过原型分配的函数是所有对象所 共享的。
JavaScript 规定,每一个构造函数都有一个 prototype 属性,指向另一个对象,所以我们也称为原型对象
这个对象可以挂载函数,对象实例化不会多次创建原型上函数,节约内存
我们可以把那些不变的方法,直接定义在 prototype 对象上,这样所有对象的实例就可以共享这些方法。
构造函数和原型对象中的this 都指向 实例化的对象
对象都有原型,构造函数有原型对象,对象的原型指向其构造函数的原型对象,原型对象上可以挂在共享的属性和方法,原型的设计之初也正是为了解决属性和方法的共享问题,减少不必要的内存浪费,
构造函数和原型对象中的this都指向其构造函数
原型链
原型链是对象属性方法的一个查找机制,类似于作用域链,对象使用属性或方法时先在自身查找,自身查找不到,到自己的原型上找,原型指向构造函数的原型对象,查找不到继续朝着构造函数的原型对象的原型去查找知道对上层Object原型对象的原型null为止
① 当访问一个对象的属性(包括方法)时,首先查找这个对象自身有没有该属性。
② 如果没有就查找它的原型(也就是 __proto__指向的 prototype 原型对象)
③ 如果还没有就查找原型对象的原型(Object的原型对象)
④ 依此类推一直找到 Object 为止(null)
⑤ __proto__对象原型的意义就在于为对象成员查找机制提供一个方向,或者说一条路线
⑥ 可以使用 instanceof 运算符用于检测构造函数的 prototype 属性是否出现在某个实例对象的原型链上
深浅拷贝
对于简单数据类型的拷贝就是直接传值,
复杂类型才有,深拷贝和浅拷贝
浅拷贝:
- 拷贝对象:Object.assgin() / 展开运算符 {…obj} 拷贝对象
- 拷贝数组:Array.prototype.concat() 或者 […arr]
浅拷贝如果是一层对象,不相互影响,如果出现多层对象拷贝还会 相互影响
浅拷贝时,拷贝的对象里面的属性如果是简单数据类型,则直接拷贝值,如果是引用数据类型,则拷贝的是地址
深拷贝
常见方法:
通过递归实现深拷贝
lodash/cloneDeep
通过JSON.stringify()实现
递归函数实现
function deepClone(obj) {
if (!obj instanceof Object) return obj
let newObj = obj instanceof Array ? [] : {}
for(let key in obj) {
let value = obj[key]
if (value instanceof Object) {
newObj[key] = deepClone(value)
} else {
newObj[key] = value
}
}
return newObj
}
处理this
普通函数this的指向:
普通函数的调用方式决定了 this 的值,即【谁调用 this 的值指向谁】
严格模式下指向undefined
箭头函数的this指向:
箭头函数中的 this 与普通函数完全不同,也不受调用方式的影响,事实上箭头函数中并不存在 this !
- 箭头函数会默认帮我们绑定外层 this 的值,所以在箭头函数中 this 的值和外层的 this 是一样的
- 箭头函数中的this引用的就是最近作用域中的this
- 向外层作用域中,一层一层查找this,直到有this的定义
改变this的指向
<!-- apply()使用-->
console.log((function (a, b, c) {
return a + b + c
}).apply(null, [1, 2, 3]));
//找最大值
console.log(Math.max(...[1, 2, 3, 5]));
console.log(Math.max.apply(null, [1, 2, 3, 5]))
//bind()使用
function say() {
console.log('hello', this)
}
let user = {
name: 'jsl',
age: 20
}
const sayHello = say.bind(user)
sayHello()
document.querySelector('button').addEventListener('click', function () {
this.disabled = true
window.setTimeout(function () {
this.disabled = false
}.bind(document.querySelector('button')), 2000)
})
节流和防抖
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Titletitle>
<style>
div {
height: 400px;
width: 400px;
margin: 0 auto;
background-color: #721c24;
text-align: center;
border-radius: 10%;
border: 2px solid greenyellow;
}
span {
color: green;
font-size: 20px;
line-height: 400px;
}
button {
height: 50px;
width: 120px;
border: 1px solid red;
border-radius: 10%;
background-color: transparent;
color: black;
font-size: 20px;
}
button:active {
background-color: #666666;
}
style>
head>
<body>
<div>
<span>span>
<button>点我加一button>
div>
body>
<script>
//如果你想要得到你从未拥有过的东西,那么你就必须去做你从未做过的事情
/*
// 防抖和节流
节流:就是指连续触发事件,但是在 n 秒中,只执行一次函数
* 比如说做核酸: 只有等到了上一个人做完核酸,整个动作完成了, 第二个人才能排队跟上
防抖:就是指触发事件后在 n 秒内函数只能执行一次,如果在 n 秒内又触发了事件,则会重新计算函数执行时间
*/
//节流
let num = 0
function fun() {
console.log(this)
document.querySelector('span').innerText = num++
}
//节流函数基于时间戳实现
function throttle(fun, delay = 500) {
let preTime = 0
return function () {
// debugger
let nowTime = new Date().getTime()
// Date.now()
if (nowTime - preTime >= delay) {
fun()
preTime = nowTime
}
}
}
//节流函数基于定时器实现
/*function throttle(fun, delay = 500) {
let timer = null
return function () {
if (!timer) {
timer = setTimeout(function () {
fun()
timer = null
}, delay)
}
}
}*/
document.querySelector('div').addEventListener('mousemove', throttle(fun, 1000))
//防抖基于定时器实现
function debounce(fun, delay = 500) {
let timer = null
return function () {
if (timer)
clearTimeout(timer)
timer = setTimeout(fun, delay)
}
}
document.querySelector('div button').addEventListener('click', debounce(fun, 1000))
/*
*
* 1. 节流和防抖的区别是?
节流: 就是指连续触发事件但是在 n 秒中只执行一次函数,比如
可以利用节流实现 1s之内 只能触发一次鼠标移动事件
防抖:如果在 n 秒内又触发了事件,则会重新计算函数执行时间
2. 节流和防抖的使用场景是?
节流: 鼠标移动,页面尺寸发生变化,滚动条滚动等开销比较大的情况下
防抖: 搜索框输入,设定每次输入完毕n秒后发送请求,如果期间还有输入,则从新计算时间
* 手机号、邮箱的输入检测
* */
// 默写
// 防抖 搜索框输入,设定每次输入完毕n秒后发送请求,如果期间还有输入,则从新计算时间
function debounce(fun, delay = 500) {
let timer = null
return function () {
if (timer) clearTimeout(timer)
timer = setTimeout(fun, delay)
}
}
//节流 鼠标移动,页面尺寸发生变化,滚动条滚动等开销比较大的情况下
function throttle(fun, delay = 500) {
let preTime = 0
return function () {
let nowTime = new Date().getTime()
if (nowTime - preTime >= delay) {
fun()
preTime = nowTime
}
}
}
function throttle2(fun, delay = 500) {
let timer = null
return function () {
if (!timer) {
timer = setTimeout(function() {
fun()
timer = null
}, delay)
}
}
}
script>
html>