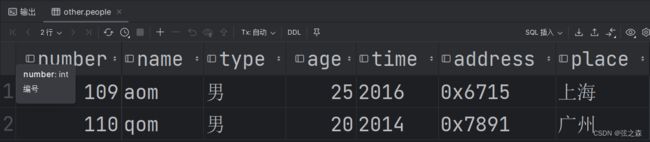
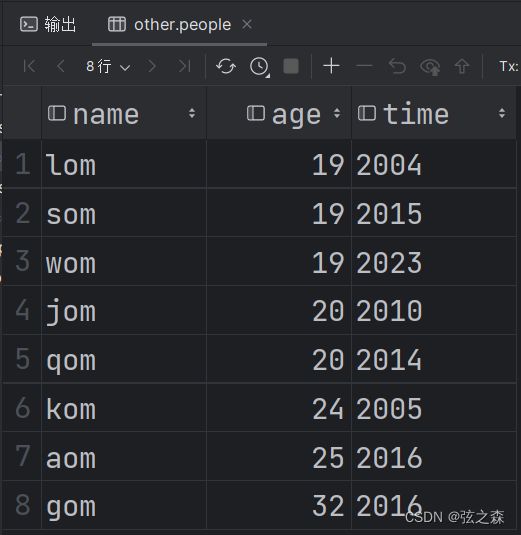
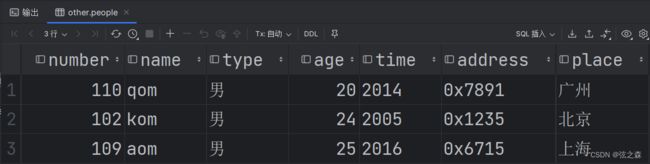
十二、MySQL(DQL)分组/排序/分页查询如何实现?
总括
select 字段列表 from 表名 [where 条件] (group by)/(order by)/(limit) 分组字段名分组查询
1、分组查询
(1)基础语法:
select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组之后的过滤条件]
(2)注意事项:

(3)理解:
select后的“字段列表”是由from后的参数决定的,where的执行时间在分组操作之前,having的执行时间在分组操作之后。
执行时间:where>分组操作>having
# 先根据“where”后参数,对表格进行初始过滤,得到新表格1,
# 再根据“group by”后参数对新表格1进行分组,根据分组结果得到一个新的数据类型,
# 将这个新的数据类型作为传入参数,传入having后的聚合函数,新的数据类型
2、实际操作:
(1)根据性别分组,并统计男女员工的数量
# 1、根据性别分组,并统计男员工数量,以及女员工数量
select count(*) from things group by type;
select type,count(*) from things group by type;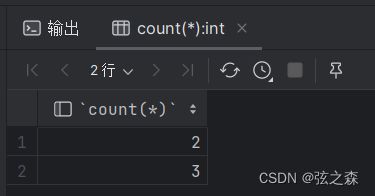

(2)根据性别分组,并统计男性员工和女性员工的平均年龄
# 2、根据性别分组,并统计男性员工和女性员工的平均年龄
select type,avg(age) from things group by type;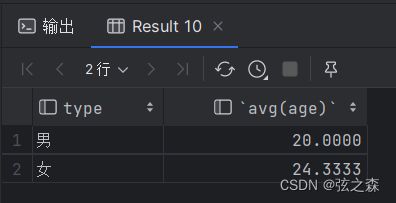
(3)查询年龄大于等于20岁的员工,再根据性别分组,最后得到员工数量大于3的性别
# 3、查询年龄大于等于20岁的员工,再根据性别分组,最后得到员工数量大于3的性别
select type,count(*) from things where age>=20 group by type having count(*)>=3;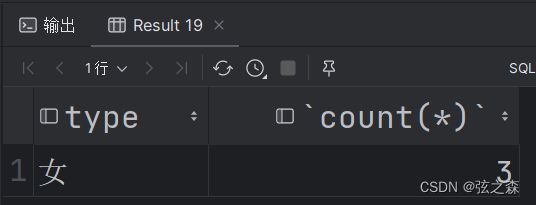
排序查询
1、基础语法:
先根据字段1进行排序,对于相同值,再根据字段2进行排序。
select 字段列表 from 表名 order by 字段1 排序方式,字段2 排序方式2,……
其中,排序方式分为ASC(升序,默认)和DESC(降序)两种
2、实际操作:
先根据time进行排序,对于time相同的数据,再根据age进行排序;
select * from people order by time,age;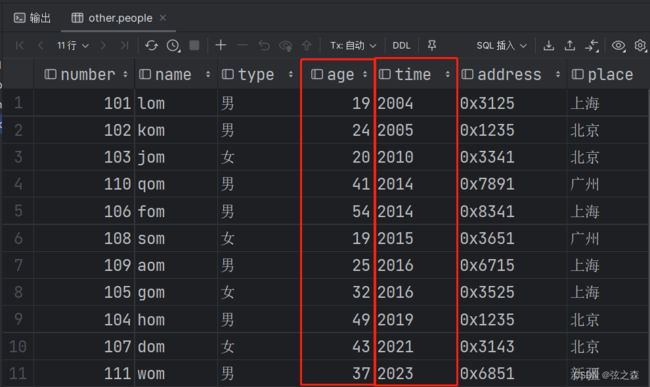
分页查询
1、基础语法:
select 字段列表 from 表名 limit 起始索引,查询记录数;
2、实际操作:
(1)初始表格:

(2)起始索引为0,每页显示5条数据
select * from people limit 0,5;
select * from people limit 8,5; # 起始索引是8,也就代表起始数据是第9条数据
实例操作
初始表格:

操作:
# 查询年龄为19和20岁的男性
select * from people where type='男' and age in(19,20);
# 查询性别为男,并且年龄在20~40岁之间,并且时间在2010~2025之间的员工
select * from people where type='男' and (time between 2010 and 2025) and (age between 20 and 40);
# 统计员工表中,年龄小于等于40岁,男性员工和女性员工的数量
select type,count(*) from people where age<=40 group by type;
# 查询所有年龄小于35岁员工的姓名和年龄,并对查询结果进行升序排列,如果年龄相同,则按照时间进行排序。
select name,age,time from people where age<35 order by age,time;
# 查询性别为男,且年龄在20~45之间前五个员工的信息,对查询结果按照升序排列,年龄相同按照时间排序
select * from people where type='男' and age between 20 and 45 order by age,time limit 0,5;