Python 基础之标准库操作(五)
标准库非常庞大,所提供的组件涉及范围十分广泛,使用标准库我们可以让您轻松地完成各种任务。
以下是一些 Python3 标准库中的模块:
| 模块名称 | 模块描述 |
|---|---|
| os 模块 | os 模块提供了许多与操作系统交互的函数,例如创建、移动和删除文件和目录,以及访问环境变量等。 |
| sys 模块 | sys 模块提供了与 Python 解释器和系统相关的功能,例如解释器的版本和路径,以及与 stdin、stdout 和 stderr 相关的信息。 |
| time 模块 | time 模块提供了处理时间的函数,例如获取当前时间、格式化日期和时间、计时等。 |
| datetime 模块 | datetime 模块提供了更高级的日期和时间处理函数,例如处理时区、计算时间差、计算日期差等。 |
| random 模块 | random 模块提供了生成随机数的函数,例如生成随机整数、浮点数、序列等。 |
| re 模块 | re 模块提供了正则表达式处理函数,可以用于文本搜索、替换、分割等。 |
| json 模块 | json 模块提供了 JSON 编码和解码函数,可以将 Python 对象转换为 JSON 格式,并从 JSON 格式中解析出 Python 对象。 |
| urllib 模块 | urllib 模块提供了访问网页和处理 URL 的功能,包括下载文件、发送 POST 请求、处理 cookies 等。 |
文件操作
1. 什么是文件
计算机文件是一个存储在存储器上的数据序列,可以包含任何数据内容。
概念上,文件是数据的集合和抽象。
用文件形式组织和表达数据更有效也更为灵活。
文件包括两种类型:文本文件和二进制文件。
文件本质上都是存储在存储器上的二进制数据。
2. 字符编码
计算机底层只能表示二进制信息,不能直接表示文字。计算机显示给我们看的文字可以看做是很小的一张张字符的图片。但如果文字都以图片进行存储和传输,图片体积非常大,从而效率会变得很低。
2.1 ascii码
总共127个字符,因此使用一个字节(8位二进制)来表示,也即是一个字符占一个字节的大小。
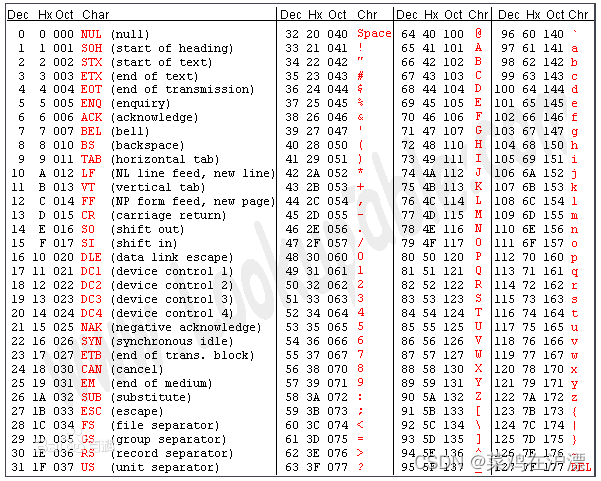
2.2 gb2312
可以看到ascii码里只有英文字母和常见字符,没有中文,以及世界上其他国家的文字。随着计算机的发展,各国都创建了自己国家的计算机字符编码。
1980年中国发布了gb2312, GB2312是一个简体中文字符集,由6763个常用汉字和682个全角的非汉字字符组成。
gb2312使用两个字节表示一个汉字。
通过字符串的encode方法可以根据字符编码进行编码
print('华'.encode('gb2312'))
运行结果:b'\xbb\xaa'
2.3 gbk
GB2312的出现,基本满足了汉字的计算机处理需要,但对于人名、古汉语等方面出现的罕用字,GB 2312不能处理,这导致了后来GBK及GB18030汉字字符集的出现。
GBK即汉字内码扩展规范,K为扩展的汉语拼音中“扩”字的声母。GBK编码标准兼容GB2312,共收录汉字21003个、符号883个,并提供1894个造字码位,简、繁体字融于一库。
gbk也是使用两个字节表示一个汉字。
print('华'.encode('gbk'))
运行结果: b'\xbb\xaa'
print('徻'.encode('gbk'))
运行结果: b'\x8f\xda'
2.4 utf-8
为了提高Unicode的编码效率,于是就出现了UTF-8编码。UTF-8可以根据不同的符号自动选择编码的长短。比如英文字母可以只用1个字节就够了。"汉"字的Unicode编码是U+00006C49,然后把U+00006C49通过UTF-8编码器进行编码,最后输出的UTF-8编码是E6B189。utf-8中汉字使用3个字节存储。
print('华'.encode('utf-8'))
运行结果: b'\xe5\x8d\x8e'
3. 操作文件
提供内置函数 open() 实现对文件的操作。
python对文本文件和二进制文件采用统一的操作步骤,和把大象放冰箱里的一样分三步,“打开-操作-关闭。”
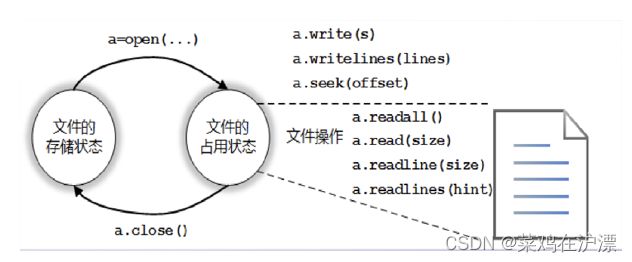
3.1 open函数
语法:
open(file, mode=‘r’, encoding=None)
打开文件并返回对应的 file 。如果该文件不能打开,则触发OSError。
- file 包含文件名的字符串,可以是绝对路径,可以是相对路径。
- mode 一个可选字符串,用于指定打开文件的模式。默认值r表示文本读。
- encoding 文本模式下指定文件的字符编码。
mode的取值:
| 字符 | 意义 |
|---|---|
| r | 文本读取(默认) |
| w | 文本写入,并先清空文件(慎用),文件不存在则创建 |
| x | 文本写,排它性创建,如果文件已存在则失败 |
| a | 文本写,如果文件存在则在末尾追加,不存在则创建 |
与mode组合的字符
| 字符 | 意义 |
|---|---|
| b | 二进制模式,例如:'rb’表示二进制读 |
| t | 文本模式(默认),例如:rt一般省略t |
| + | 读取与写入,例如:‘r+’ 表示同时读写 |
4. 读文本文件
在当前目录下创建一个名为 text.txt 的文本文件,(注意编码方式)文件中写入下面的内容:
静夜思
床前明月光,疑是地上霜。
举头望明月,低头思故乡。
4.1 操作基本步骤
# 打开使用 可读模式,打开文件;并把句柄赋值给 fb
fb = open(file='text.txt',mode='r',encoding='utf-8')
# 读取文件内容
print(fb.read())
#关闭句柄
fb.close()
运行结果:
静夜思
床前明月光,疑是地上霜。
举头望明月,低头思故乡。
注意:上面这种操作经常会忘记关闭文件句柄,造成资源浪费,所以处理文件是往往使用with语句进行上下文管理。
4.2 with 上下文管理
# 使用可读模式 打开 文件。
with open(file='text.txt',mode='r',encoding='utf-8') as fb:
# 读取全部文件内容
print(fb.read())
运行结果:
静夜思
床前明月光,疑是地上霜。
举头望明月,低头思故乡。
注意: with语句执行完毕会自动关闭文件句柄。
4.3 逐行读取
readline
在读取文本文件时,经常需要按行读取,文件对象提供了多种方法进行按行读取。
# 使用可读模式 打开 文件。
with open(file='text.txt',mode='r',encoding='utf-8') as fb:
# 读取每行文件内容
print(fb.readline())
运行结果:
静夜思
readlines
以列表的形式返回文件中所有的行。
# 使用可读模式 打开 文件。
with open(file='text.txt',mode='r',encoding='utf-8') as fb:
# 读取所有文件内容,并通过列表返回;
print(fb.readlines())
运行结果:
['静夜思\n', '床前明月光,疑是地上霜。\n', '举头望明月,低头思故乡。']
迭代
要从文件中读取行,还可以循环遍历文件对象。这是内存高效,快速的,并简化代码:
# 使用可读模式 打开 文件。
with open(file='text.txt',mode='r',encoding='utf-8') as fb:
# 读取每行的文件内容
for i in fb:
print(i)
运行结果:
静夜思
床前明月光,疑是地上霜。
举头望明月,低头思故乡。
5. 读二进制文件
任何文件都可以以二进制读的方式打开,读取text.txt的二进制内容。
# 使用可读模式 打开 文件。
with open(file='text.txt',mode='rb') as fb:
print(fb.read())
运行结果:
b'\xe9\x9d\x99\xe5\xa4\x9c\xe6\x80\x9d\n\xe5\xba\x8a\xe5\x89\x8d\xe6\x98\x8e\xe6\x9c\x88\xe5\x85\x89'
6. 写文本文件
6.1 清除写w
案例:将 ‘测试’ 2个字写入 test.txt 文件中;
# 使用清除写模式写入文件内容。
with open(file='text.txt',mode='w',encoding='utf-8') as fb:
print(fb.write('测试'))
运行结果: 2
注意: 运行后会发现之前写有静夜思的test.txt内容修改为 测试,因为w模式会清除原文件内容,所以小心使用。
6.2 追加写 a
案例:将 ‘小伙伴’ 3个字追加到test.txt文件中;
# 使用追加写模式写入文件内容。
with open(file='text.txt',mode='a',encoding='utf-8') as fb:
print(fb.write('小伙伴'))
运行结果: 3
6.3 排他写x
案例:创建 text.txt 文件,不存在则创建,并写入内容。存在就报错;
# 使用排他写模式创建文件并写入内容。
with open(file='text1.txt',mode='x',encoding='utf-8') as fb:
print(fb.write('xxxxx'))
运行结果: 5
7. 写二进制文件
在写模式后加b即是写二进制模式,这种模式下写入内容为字节数据。
例如:将爬到的图片二进制信息写入文件中。
import requests
url = 'https://pics0.baidu.com/feed/4610b912c8fcc3cecb4d9b7265a5b284d63f20ca.jpeg@f_auto?token=aa7f3a1118fbf2cf8499e6c0c3408533'
response = requests.get(url)
print(response.content)
with open('刘亦菲.jpeg', 'wb') as f:
f.write(response.content)
print(f)
运行结果: b'\xff\xd8\xff\xe0\x00\x10JFIF\x00\x01\........
8. 读写文件
有时候需要能够同时读写文件,在模式后面加上+号即可给读模式添加写,给写模式添加读。
# 使用读写模式,为 text.txt 增加 !
with open(file='text.txt',mode='r+',encoding='utf-8') as f:
print(f.read())
print(f.write('!'))
运行结果:
测试小伙伴!
1
os 模块
os 模块提供了许多与操作系统交互的函数,例如创建、移动和删除文件和目录,以及访问环境变量等。
os.getcwd()
含义:输出当前工作目录;
import os
print(os.getcwd()) # 输出当前工作目录
运行结果:/Users/xxxx/PycharmProjects/demo
os.listdir(path)
含义:输出当前工作目录下所有文件名称;
import os
print(os.listdir()) # 输出当前工作目录下所有文件名称
运行结果:['test', 'qa.json', 'test1', 'text.txt', 'main.py', '.idea']
import os
print(os.listdir("/Users/xxxx/PycharmProjects/demo/test")) # 输入某个路径,输出该路径下的所有文件
os.walk(path)
含义 :传入任意一个path路径,深层次遍历指定路径下的所有子文件夹,返回的是一个由路径、文件夹列表、文件列表组成的元组。我代码中写的方式属于元组拆包;
import os
path = "/Users/xxxx/PycharmProjects/demo/test"
for path,dirs,files in os.walk(path):
print(path)
print(dirs)
print(files)
运行结果:
/Users/xxxx/PycharmProjects/demo/test
[]
['2.py', '1.py']
os.path.exists(path)
含义:判断该路径是否存在,存在返回True,不存在返回False;
import os
print(os.path.exists(path = "/Users/xxxx/PycharmProjects/demo/test")) # 判断该路径是否存在,存在返回True,不存
运行结果:True
import os
print(os.path.exists(path = "/Users/xxxx/PycharmProjects/demo/test2")) # 判断该路径是否存在,存在返回True,不存
运行结果:False
os.mkdir(path)
含义:在当前工作目录创建文件夹内;
import os
print(os.mkdir('test1')) # 在当前工作目录创建文件夹内
运行结果:None
print(os.mkdir('/Users/xxxx/PycharmProjects/demo/test/test2')) # 在指定的目录内创建文件夹内
运行结果:None
os.makedirs(path)
含义:创建递归文件夹;
import os
print(os.makedirs('test3/test4')) # 创建递归文件夹
运行结果:None
os.rmdir()
含义:删除某个目录内的文件夹;
import os
print(os.rmdir("/Users/xxxx/PycharmProjects/demo/test/test2")) # 删除某个目录内的文件夹
运行结果:None
os.path.join(path,path)
含义:把两个路径拼接在一起;
import os
print(os.path.join("/Users/xxx/PycharmProjects/demo/test","main.py")) # 把两个路径拼接在一起
运行结果:/Users/xxxx/PycharmProjects/demo/test/main.py
os.path.split()
含义:输入路径,从最后进行拆分成 绝对路径和 文件名;
import os
print(os.path.split("/Users/xxxx/PycharmProjects/demo/test/1.py")) # 输入路径,从最后进行拆分成 绝对路径和 文件名;
运行结果:('/Users/xxxx/PycharmProjects/demo/test', '1.py')
os.path.dirname(path)
含义:输出该文件的绝对路径;
import os
print(os.path.dirname("/Users/xxxx/PycharmProjects/demo/test/1.py")) # 输出该文件的绝对路径;
运行结果:/Users/xxxx/PycharmProjects/demo/test
print(os.path.dirname(__file__)) # 输出工作目录;
运行结果:/Users/xxxx/PycharmProjects/demo
os.path.abspath(path)
含义:获取当前文件的绝对路径;
import os
print(os.path.abspath(__file__)) # 获取当前文件的绝对路径;
运行结果:/Users/tankaihua/PycharmProjects/demo/main.py
os.path.basename(path)
含义:获取路径文件夹的文件名,从最后进行分割;
import os
print(os.path.basename("/Users/xxxx/PycharmProjects/demo/test/1.py")) # 获取路径文件夹的文件名;
运行结果:1.py
os.path.isdir(path)
含义:判断该路径是否是文件夹;
import os
print(os.path.isdir("/Users/xxxx/PycharmProjects/demo/test")) # 判断该路径是否是文件夹;
运行结果:True
os.path.isfile(path)
含义:判断该路径是否是文件;
import os
print(os.path.isfile("/Users/xxxx/PycharmProjects/demo/test/1.py")) # 判断该路径是否是文件;
运行结果:True
os.path.getsize(path)
含义:输出文件大小;
import os
print(os.path.getsize("/Users/xxxx/PycharmProjects/demo/qa.json")) # 输出文件大小;
运行结果:20
sys 模块
sys 模块提供了与 Python 解释器和系统相关的功能,例如解释器的版本和路径,以及与 stdin、stdout 和 stderr 相关的信息。
sys.version
含义:获取 python 版本以及详细信息
import sys
print(sys.version)
运行结果:3.7.10 (default, Feb 26 2021, 10:16:00)
sys.platform
含义:获取操作系统信息
import sys
print(sys.platform)
运行结果:darwin
sys.getdefaultencoding()
含义:获取python编码方式
import sys
print(sys.getdefaultencoding())
运行结果:utf-8
sys.argv
含义:获取当前路径,并返回列表
import sys
print(sys.argv)
运行结果:['/Users/xxxx/PycharmProjects/demo/main.py']
sys.exit()
含义:中断下面代码执行
import sys
print(sys.exit())
sys.path
含义:该变量存储了python寻找模块的路径
import sys
print(sys.path)
运行结果:['/Users/xxxxx/PycharmProjects/demo', '/Users/xxxxx/PycharmProjects/demo', '/Applications/PyCharm.app/Contents/plugins/python/helpers/pycharm_display', '/Users/xxxxx/opt/anaconda3/lib/python37.zip', '/Users/xxxxx/opt/anaconda3/lib/python3.7', '/Users/xxxxx/opt/anaconda3/lib/python3.7/lib-dynload', '/Users/xxxxx/opt/anaconda3/lib/python3.7/site-packages', '/Users/xxxxx/opt/anaconda3/lib/python3.7/site-packages/aeosa', '/Applications/PyCharm.app/Contents/plugins/python/helpers/pycharm_matplotlib_backend']
sys.modules.keys()
含义:返回导入的模块
import sys
print(sys.modules.keys())
运行结果:dict_keys(['abc', '_signal', 'sitecustomize', 'sys', '_collections_abc', '_weakrefset', '_sitebuiltins', '_weakref', 'sysconfig', 'encodings.utf_8', '__main__', 'apport_python_hook', '_sysconfigdata_m', 'posixpath', 'site', 'readline', 'stat', 'encodings', 'encodings.latin_1', 'zipimport', 'encodings.aliases', '_frozen_importlib_external', 'io', '_frozen_importlib', '_imp', 'atexit', 'os', '_stat', '_sysconfigdata', 'os.path', '_codecs', '_thread', 'posix', 'marshal', 'codecs', '_warnings', 'builtins', 'errno', 'genericpath', 'rlcompleter', '_io'])
time 模块
time 模块提供了处理时间的函数,例如获取当前时间、格式化日期和时间、计时等。
time.time()
含义:输出当前时间戳;
import time
print(time.time()) # 输出本地时间戳
运行结果:1687932698.276453
time.localtime()
含义:将时间戳的秒数转化为时间元组格式;
元组格式:
tm_year: 年
tm_mon: 月,范围为[1,12]
tm_mday: 一个月的第几天,范围为[1,31]
tm_hour: 小时,范围为[0,23]
tm_min: 分, 范围为[0,59]
tm_sec: 秒,范围为[0,59]
tm_wday: 一周中的第几天,范围是[0,6],周一为0
tm_yday: 一年中的第几天,范围是[1,366]
tm_isdat: 1代表夏令时
import time
print(time.localtime(1687932902.080519)) # 根据时间戳转换成 时间元组
运行结果: time.struct_time(tm_year=2023, tm_mon=6, tm_mday=28, tm_hour=14, tm_min=15, tm_sec=2, tm_wday=2, tm_yday=179, tm_isdst=0)
print(time.localtime()) # 输出当前时间转换成 时间元组
运行结果: time.struct_time(tm_year=2023, tm_mon=6, tm_mday=28, tm_hour=14, tm_min=17, tm_sec=43, tm_wday=2, tm_yday=179, tm_isdst=0)
time.ctime()
含义:可以将时间戳的秒数转换字符串的时间格式;
import time
print(time.ctime(1687932902.080519)) # 根据时间戳转换成 字符串时间格式;
运行结果: Wed Jun 28 14:15:02 2023
print(time.ctime()) # 输出当前时间的字符串时间格式;
运行结果: Thu Jun 29 12:21:36 2023
time.asctime(tuple)
含义: 可以将时间元组转换成字符串的时间格式;
import time
print(time.asctime(time.localtime())) # 根据当前时间元组转换成时间字符串;
运行结果: Thu Jun 29 12:32:35 2023
print(time.asctime()) # 输出当前时间的字符串;
运行结果: Thu Jun 29 12:32:35 2023
print(time.asctime((2023,3,4,14,58,59,7,8,9))) # 根据自定义元祖,输出时间字符串格式
运行结果: Mon Mar 30 14:58:59 2023
time.mktime(tuple)
含义:以将时间元组转换成时间戳的秒数,注意该方法括号内必须要有时间元组参数;
import time
print(time.mktime(time.localtime())) # 根据当前时间元祖转换成时间戳;
运行结果:1688013381.0
time.strftime(format [,tuple])
含义:可以将时间元组定制化输出到时间字符串,其中的时间字符串可以定制格。
| 格式控制符 | 含义 |
|---|---|
| %Y | 四位数的年份,取值范围为0001~9999,如1900 |
| %m | 月份(01~12),例如10 |
| %d | 月中的一天(01~31)例如:25 |
| %B | 本地完整的月份名称,比如January |
| %b | 本地简化的月份名称,比如Jan |
| %a | 本地简化的周日期,Mon~Sun,例如Wed |
| %A | 本地完整周日期,”Monday~Sunday,例如Wednesday |
| %H | 24小时制小时数(00~23),例如:12 |
| %M | 分钟数(00~59),例如26 |
| %S | 秒(00~59),例如26 |
| %l | 12小时制小时数(01~12),例如:7 |
| %p | 上下午,取值为AM或PM |
import time
print(time.strftime("%Y-%m-%d",time.localtime(time.time()))) # 根据当前时间元组,输出 年月日
print(time.strftime("%Y-%m-%d")) # 输出 年月日
time.sleep()
含义:等待时间;
import time
print(time.sleep(1)) # 等待1秒
总结
总的来说time模块中时间可以有3种格式:时间戳,时间元组和时间字符串,其中时间字符串可以自行定制格式。
datetime 模块
datetime 模块提供了更高级的日期和时间处理函数,例如处理时区、计算时间差、计算日期差等。
datetime.now()
含义:输出当前时间,年月日时分秒毫秒
import datetime
print(datetime.datetime.now())
运行结果:2023-07-05 12:46:36.254961
datetime.date(2023,4,24)
含义:输入整数,输出年月日
import datetime
print(datetime.date(2023,4,24))
运行结果:2023-04-24
date.today()
含义:输出当天年月日
import datetime
print(datetime.date.today())
运行结果:2023-07-05
datetime.now().date()
含义:输出当天年月日
import datetime
print(datetime.datetime.now().date())
运行结果:2023-07-05
datetime.now().timetuple()
含义:输出时间格式组
import datetime
print(datetime.datetime.now().timetuple())
运行结果:time.struct_time(tm_year=2023, tm_mon=7, tm_mday=5, tm_hour=12, tm_min=49, tm_sec=2, tm_wday=2, tm_yday=186, tm_isdst=-1)
datetime.now().strftime(“%Y-%m-%d %H:%M:%S”)
含义:获取本地时间并进行格式化
import datetime
print(datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
运行结果:2023-07-05 12:50:01
datetime.fromtimestamp(1564229940.623349)
含义:时间戳转换成相对应的时间日期;
import datetime
print(datetime.datetime.fromtimestamp(1564229940.623349))
运行结果:2019-07-27 20:19:00.623349
random 模块
random 模块提供了生成随机数的函数,例如生成随机整数、浮点数、序列等。
randrange()
含义:从 randrange(start, stop, step) 返回一个随机选择的元素(半区间,不包含2);
import random
print(random.randrange(1,2))
运行结果: 1
randint(a, b)
含义:从 randint(start, stop,) 返回一个随机选择的元素(全区间,包含2);
import random
print(random.randint(1,2))
运行结果:2
random()
含义:返回 (0.0, 1.0) 范围内的下一个随机浮点数;
import random
print(random.random())
运行结果: 0.6311033846287252
shuffle(list)
含义: 把序列类型随机打乱;
import random
ls = [1,2,3,4,5,6,7]
random.shuffle(ls)
print(ls)
运行结果:[1, 5, 6, 4, 3, 2, 7]
sample()
含义:自定义返回序列类型中的元素数量;
import random
print(random.sample([1,2,3,4,5],3)) # 列表、元组、集合
运行结果:[5, 3, 1]
re 模块
re 模块提供了正则表达式处理函数,可以用于文本搜索、替换、分割等。
split()
含义:根据某个 字样进行分割;
demo = 'www.baidu.com'
print(demo.split('.')) # 根据 . 进行分割,并返回列表;
运行结果: ['www', 'baidu', 'com']
demo = 'www.baidu.com'
print(demo.split('.')[-1]) # 根据 . 进行分割,并获取最后一个参数;
运行结果: com
match(pattern, string)
含义:用于从字符串的开始处进行匹配,如果在起始位置匹配成功,则返回 Match 对象,否则返回 None。
参数说明:
pattern:表示模式字符串,由要匹配的正则表达式转换而来。
string:表示要匹配的字符串。
| 标志 | 说明 |
|---|---|
| A 或 ASCII | 对于 \w、\W、\b、\B、\d、\D、\s 和 \S 只进行 ASCII 匹配(仅适用于Python3.x) |
| I 或 IGNORECASE | 执行不区分字母大小写的匹配 |
| M 或 MULTILINE | 将 ^ 和 $ 用于包括整个字符串的开始和结尾的每一行(默认情况下,仅适用于整个字符串的开始和结尾处) |
| S 或 DOTALL | 使用(.)字符匹配所有字符,包括换行符 |
| X 或 VERBOSE | 忽略模式字符串中未转义的空格和注释 |
import re
string = 'MY_PHONE my1_phone my2_phone my_phone' # 要匹配的字符串
match = re.match(r'my_\w+', string,re.IGNORECASE) # 匹配字符串,设置为不区分大小写
print('匹配数据:', match.group())
运行结果:
匹配数据: my_phone
search(pattern, string)
含义:用于在整个字符串中搜索第一个匹配的值,如果匹配成功,则返回 Match 对象,否则返回 None。
参数说明:
pattern:表示模式字符串,由要匹配的正则表达式转换而来。
string:表示要匹配的字符串。
import re
string = 'MY1_PHONE my1_phone my2_phone my_phone' # 要匹配的字符串
match = re.search(r'my_\w+', string) # 匹配字符串,设置为不区分大小写
print('要匹配的字符串:', match.string)
print('匹配数据:', match.group())
运行结果:
要匹配的字符串: MY1_PHONE my1_phone my2_phone my_phone
匹配数据: my_phone
findall(pattern, string,)
参数说明:
pattern:表示模式字符串,由要匹配的正则表达式转换而来。
string:表示要匹配的字符串。
含义:用于在整个字符串中搜索所有符合正则表达式的字符串,并以列表的形式返回所有符合条件的结果。
\d
含义:匹配任意数字,并进行返回匹配到的数字;
import re
print(re.findall('\d','re.match与re.search的区别
'))
运行结果: ['h2', 'h2']
\D
含义:匹配任意非数字,并进行返回匹配到的内容;
import re
print(re.findall('\D','re.match与re.search的区别
'))
运行结果: [', '2>', 're', '.m', 'at', 'ch', '与r', 'e.', 'se', 'ar', 'ch', '的区', '别<', '/h', '2>']
\w
含义:匹配数字字母下划线;
import re
print(re.findall('\w','<_2>re.match与re.search的区别<2>'))
运行结果: ['_', '2', 'r', 'e', 'm', 'a', 't', 'c', 'h', '与', 'r', 'e', 's', 'e', 'a', 'r', 'c', 'h', '的', '区', '别', '2']
\W
含义:匹配非数字字母下划线;
import re
print(re.findall('\W','<_2>re.match与re.search的区别<2>'))
运行结果:['<', '>', '.', '.', '<', '>']
特殊符号
import re
case = '{"email": "#email#","password": "#password#"}'
print(re.findall('(#(.+?)#)',case))
运行结果: [('#email#', 'email'), ('#password#', 'password')]
json模块
Json 模块提供了 JSON 编码和解码函数,可以将 Python 对象转换为 JSON 格式,并从 JSON 格式中解析出 Python 对象。
json的定义
JSON 指的是 JavaScript 对象表示法(JavaScript Object Notation)
JSON 是轻量级的文本数据交换格式
JSON 独立于语言
JSON 具有自我描述性,更易理解
json.dumps
含义:json.dumps()将Python的dict数据类型转成json的str数据类型;
case = {
"title": 1,
"name": "获取",
"url": "https://www.baidu.com/",
"method": "get",
"requests":{
"headers": {"Host": "www.baidu.com"},
}
}
print(type(case)) # 查看 case 数据类型;
运行结果: <class 'dict'>
dps = json.dumps(case) # 使用 dumps 对 case 进行编码,并赋值给 dps;
print(type(dps),dps) # 查看 dps 数据类型,并输出 编码后的 dps
运行结果: <class 'str'> {"title": 1, "name": "\u83b7\u53d6", "url": "https://www.baidu.com/", "method": "get", "requests": {"headers": {"Host": "www.baidu.com"}}}
json.loads
含义:json.loads()将json的str数据类型转换成Python的dict数据类型;
case = {
"title": 1,
"name": "获取",
"url": "https://www.baidu.com/",
"method": "get",
"requests":{
"headers": {"Host": "www.baidu.com"},
}
}
dps = json.dumps(case) # 使用 dumps 对 case 进行编码,并赋值给 dps;
lds = json.loads(dps) # 使用 loads 对 dps 进行解码。并赋值给 lds
print(type(lds),lds) # 查看 lds 数据类型,并输出解码后的 lds
运行结果:
<class 'dict'> {'title': 1, 'name': '获取', 'url': 'https://www.baidu.com/', 'method': 'get', 'requests': {'headers': {'Host': 'www.baidu.com'}}}
json.dump
含义:json.dump()将数据以json的数据类型写入文件中;
import json
# 要写入的 内容
name = '小伙伴'
# 使用 清除写 模式 把 小伙伴 写到json文件内。
with open('qa.json','w') as f:
json.dump(name, f)
# 含义:name 表示 要写入的内容,f 表示句柄
json.load
含义:json.load()从json文件中读取数据;
import json
# 使用 可读模式,读取 json文件
with open('qa.json','r') as f:
print(json.load(f))
运行结果:小伙伴
urllib 模块
urllib 模块提供了访问网页和处理 URL 的功能,包括下载文件、发送 POST 请求、处理 cookies 等。
string 模块
string模块主要包含关于字符串的处理函数;
digits
含义:生成0~9数字;
import string
print(string.digits)
运行结果:0123456789
ascii_letters
含义:生成52个大小写字母
import string
print(string.ascii_letters)
运行结果:abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ
ascii_lowercase
含义:生成26个小写字母
import string
print(string.ascii_lowercase)
运行结果:abcdefghijklmnopqrstuvwxyz
ascii_uppercase
含义:生成26个大写字母
import string
print(string.ascii_uppercase)
运行结果:ABCDEFGHIJKLMNOPQRSTUVWXYZ
whitespace
含义:制表符
import string
print(string.whitespace)
运行结果:输出四个空格
punctuation
含义:生成特殊字符
import string
print(string.punctuation)
运行结果:!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
printable
含义:数字+52个大小写字母+特殊字符
import string
print(string.printable)
运行结果:0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
octdigits
含义:生成0~7
import string
print(string.octdigits)
运行结果:01234567
hexdigits
含义:输出0~9 a~f A~F
import string
print(string.hexdigits)
运行结果:0123456789abcdefABCDEF
随机生成用户名
# 方法1
import string
import random
res = random.sample(string.ascii_letters + string.digits,5)
print(''.join(list(res)))
运行结果:qWzEx
# 方法2
import string
import random
def user():
return ''.join(random.sample(string.ascii_letters + string.digits,5))
print(user())
运行结果:XpYKI