HTTP协议初识·中篇
加上目录,会出现导向不正确的情况,可能是bug,目录一长就容易出错?
本篇主要讲解了:
网页分离(网页代码和.c文件分离)
html链接跳转
网页添加图片
确认并返回资源类型
填写正文长度属性
添加表单
临时重定向
补充知识:
前后端区别
浏览器是如何显示页面的
http各字段属性是什么意思
提交给指定的路径有什么意义?
http方法
http状态码
HTTP常见Header
写入cookie信息
源码
承接上文
HTTP协议初识·上篇_清风玉骨的博客-CSDN博客
第二点在上文中已经完成
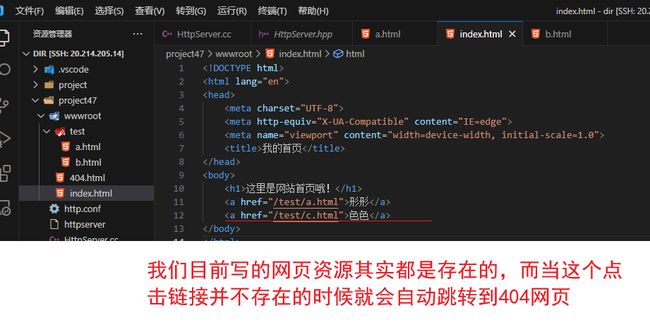
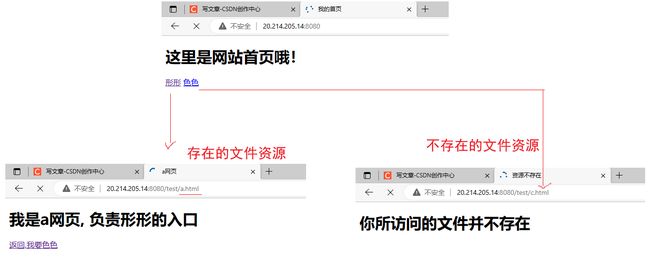
1:网页分离
网页分离1.0:404文件一定会存在
readFile函数1.1:读取文件中的内容
读取文件中的内容
404html文件
在vscode有快捷生成网页,!+ Tab键
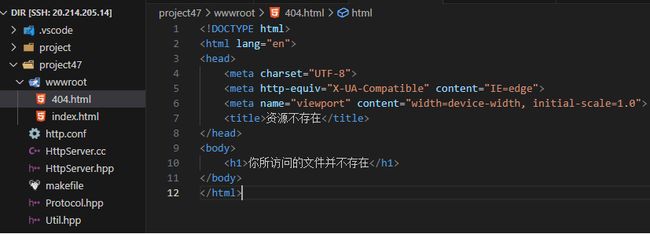
测试1:网页分离与404文件
成功
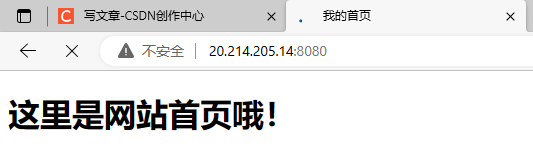
404访问
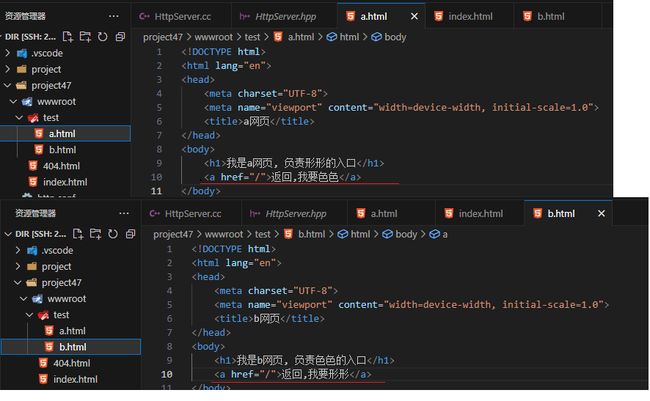
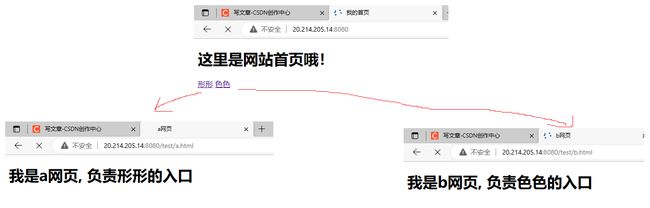
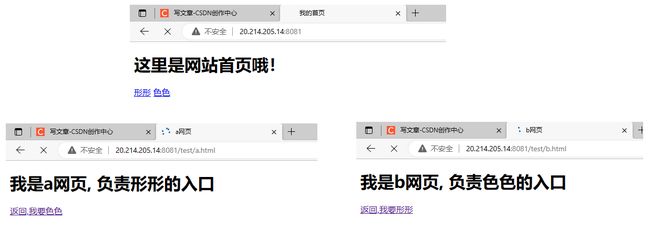
2:html链接跳转
2.0添加点击键与返回键
其实游览器的返回键可以直接使用,效果是一样的

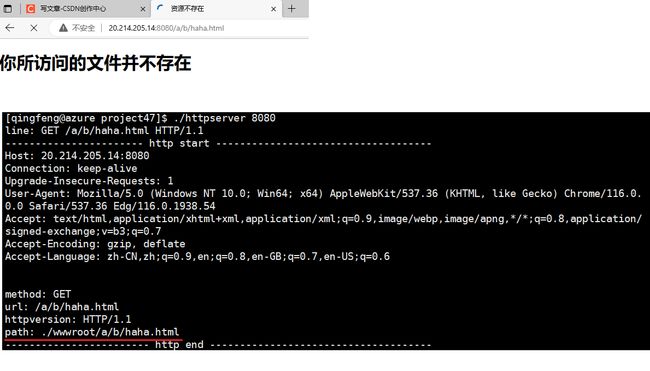
测试2:返回键与404测试
返回键
404(返回时候不存在)
故意写错
别人的404网页
高级一点……
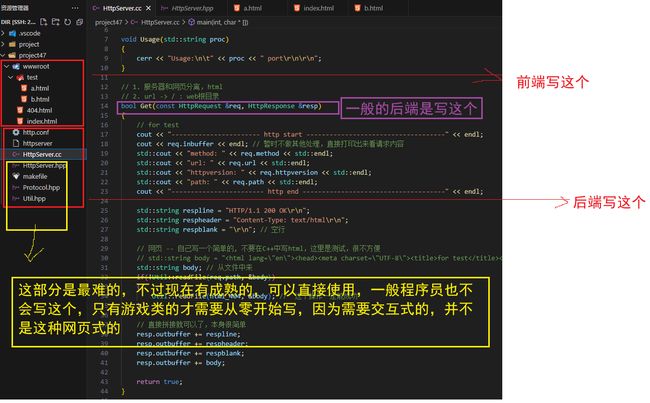
补充1:后端与前端区别做那些部分?
3:添加图片
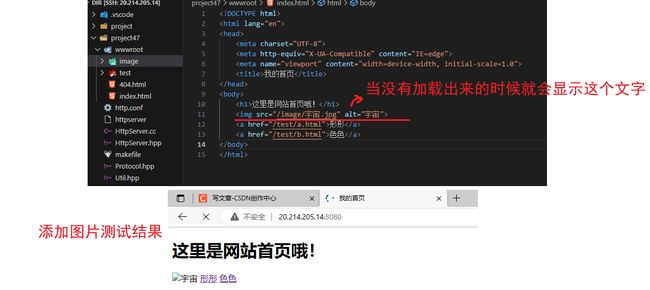
测试3:图片测试
在wwwroot下创建一个image文件夹,把图片放进去就行了,这里不显示的原因估计是云服务器配置太低,导致图片加载不出来,因为这个.jpg的格式一般都比较大,这边测试用的是大概200kb的图片,果然配置低了点
补充2:浏览器是如何显示网页的?
其实很简单,例如访问首页,就是把的全部资源下载下来,再组合显示过来就行了
即用户看到的网页结果,可能是多个资源组合而成的!所以要获取一张网页效果,浏览器一定会发起多次http请求,这也是为什么会有高并发访问原因
4:如何正确返回资源类型?
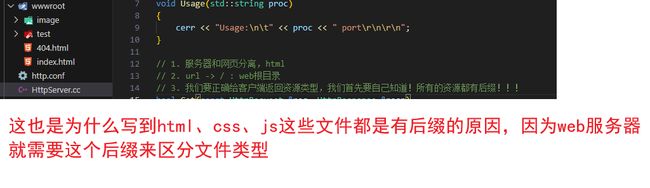
为了返回正确的文件信息,我们得填写Content-Type来,让它不要一直指向首页,这里直接搜索对照表即可找到相应的对照

suffixToDesc函数4.1后缀分离函数
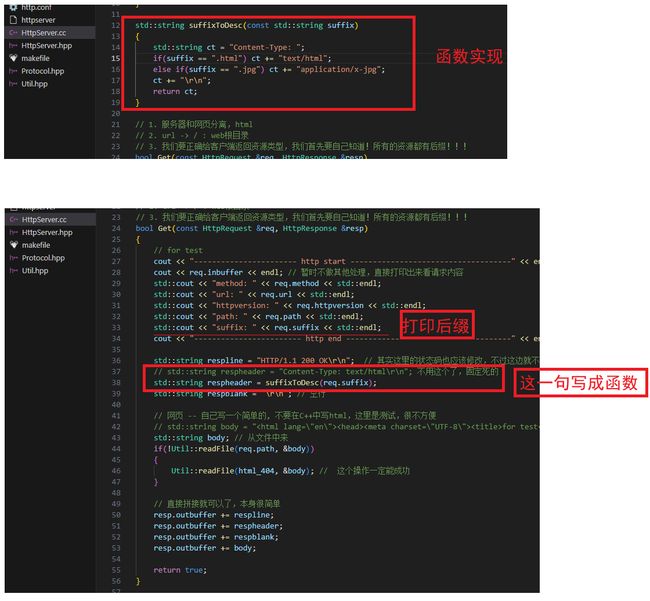
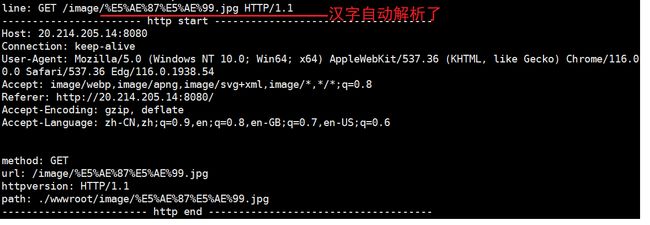
测试4:图片再测试
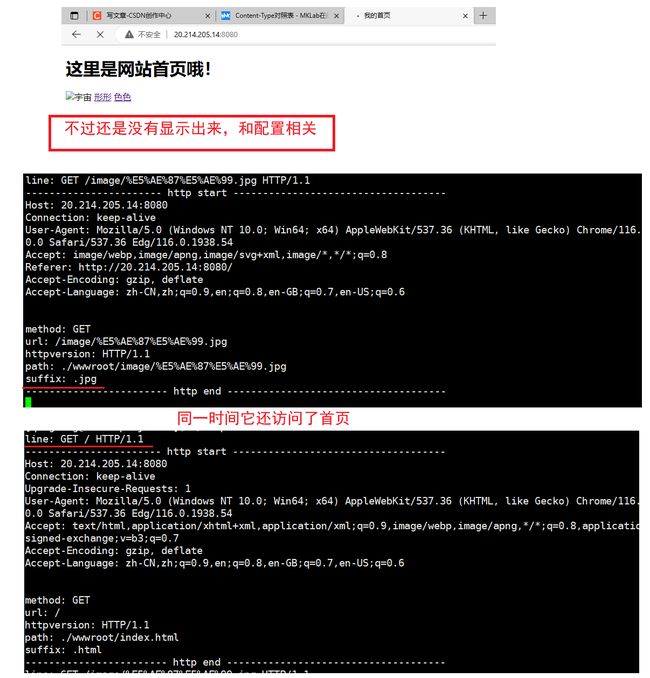
不过通常这类的图片音频之类的比较吃资源的文件一般并不会直接放置在服务器里面,而是放置在别的专门放置资源的服务器上,为了进一步测试,我们还可以使用别人的图床中的图片,走别人的服务器
这一次很幸运的显示出来的,要注意很多网站的图片其实并不能直接使用,视乎做了处理,这里就不深加讨论了
5:添加正文长度
认识系统调用stat

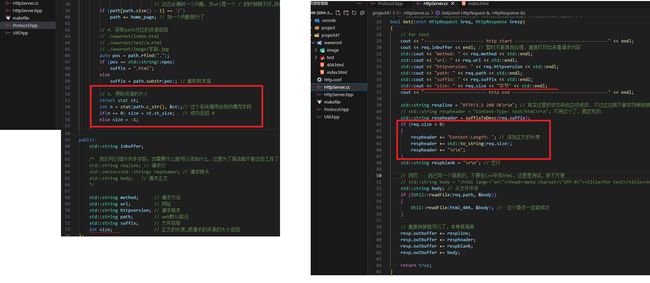
测试5:添加正文长度
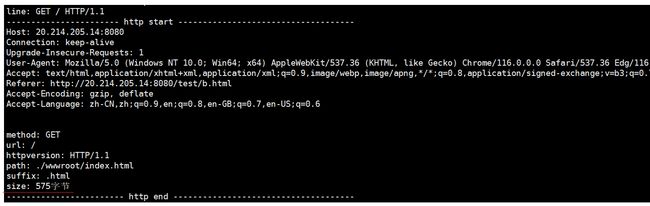
补充2:http各个字段的意思
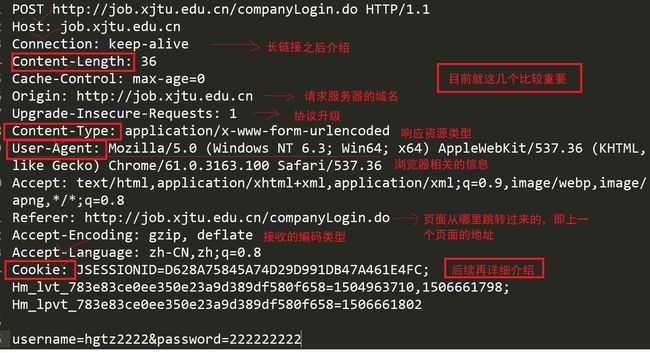
6:添加表单
目前我们写的都是单向的,无法做到交互,因为使用的是,为了做到可以交互我们得引用表单
补充6.0:表单各部分意思

测试6:表单测试
GET方法:数据拼接到url后面
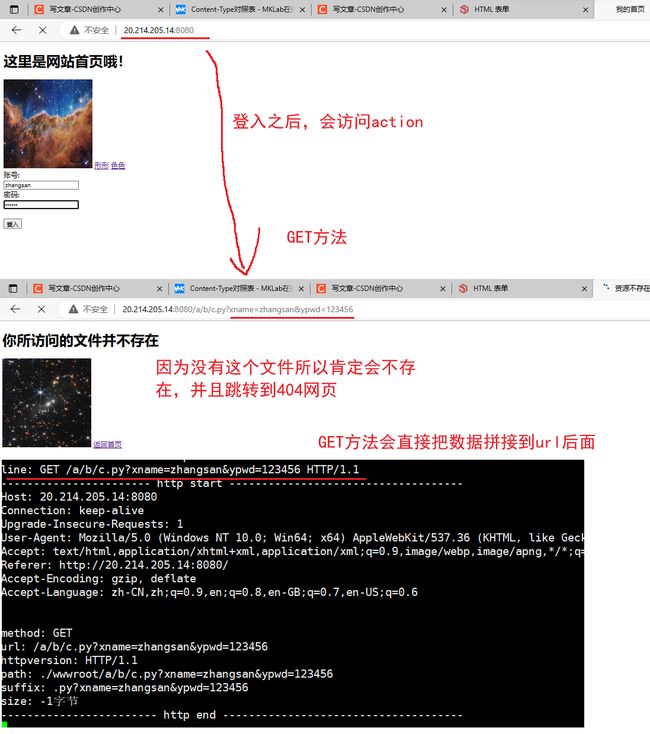
POST方法:数据放到正文部分

GET与POST方法只有私密性这一点不同

要想安全,得到https这一点我们后续再详谈
这里百度一下就是直接使用GET方法的

补充3:提交给指定的路径有什么意义?
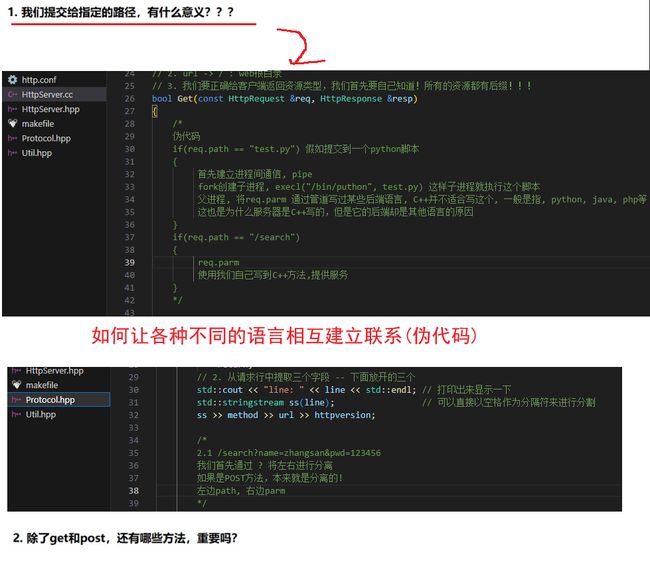
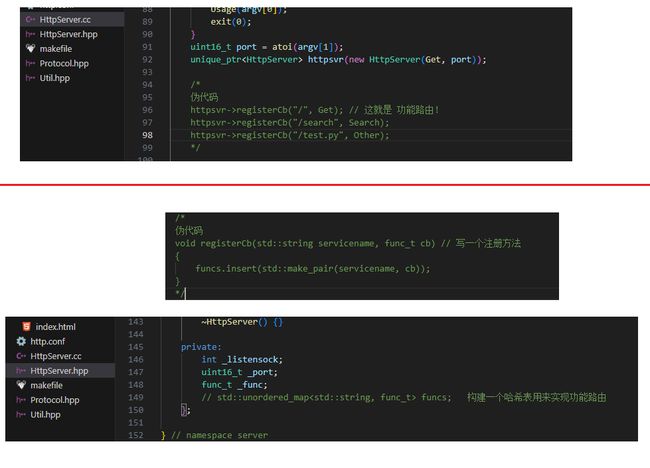
补充4:使用unordered_map进行修改可以实现功能路由
这里是伪代码,仅提供思路
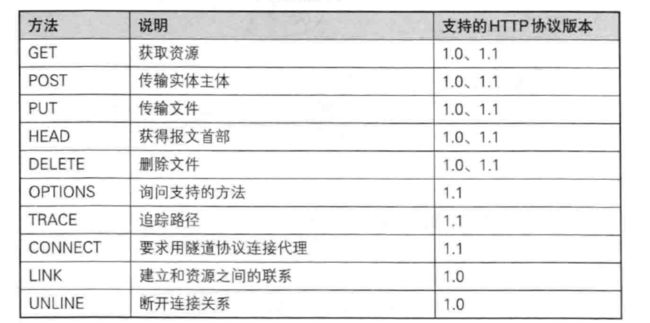
补充5:HTTP的方法
其实除了GET和POST方法我们常使用,其他的方法我们使用的频率并不高,所以我们这里也就不详谈了,不是重点
所以GET和POST相比
如果你只想单纯的从远端获取资源:GET
如果你想要提参:GET/POST
无私密性:GET(简单)
私密性:POST
补充6:HTTP的状态码
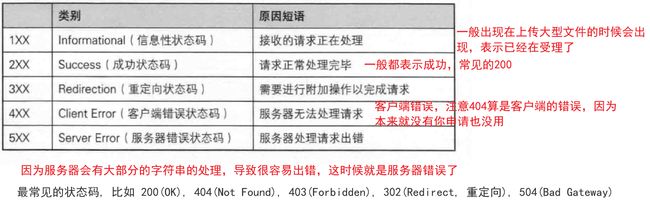
不过我们需要知道,虽然这些状态码是协议标准,不过解释权还是在写代码的人在操作,并且现在一般也不需要严格遵守,比如5开头的状态码我们平时就很少见,这一点想必大家都会意识到这一点,毕竟有点掉价,所以大部分服务器的错误,基本上都是返回4开头的状态码,因为这些错误要么就是很苛刻,要么就是大家都懂得,而且很重要的一点,根据5状态码的信息,一些非法分子可能就会利用这个错误码来进行攻击服务器,自然而然的这也成为了不成文规定了,基于这一点关于状态码与前端后端程序员对于状态码的认识注定是不一样的。
不过现在的浏览器很智能了,它一般也不会通过状态码来规定网页显示内容,一般都是通过正文部分来显示的,这一点做得很好了
补充7:3开头重定向状态码

301 永久重定向 307 临时重定向
重定向可能提出来会有些不了解,其实我们很容易见到这个的,比如当年点击这个网站的时候,就会跳转来一个广告页面,这就是重定向的一种,这种一般是临时重定向,那边是金主就给那边定向导流,这种强制重定向就是用3开头的状态码来实现的
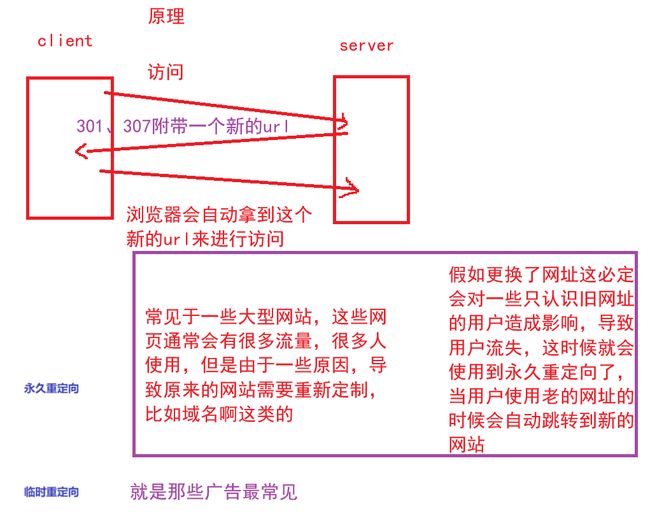
7:临时重定向
HTTP常见Header
Content-Type: 数据类型(text/html等)
Content-Length: Body的长度
Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
User-Agent: 声明用户的操作系统和浏览器版本信息;
Referer: 当前页面是从哪个页面跳转过Location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问;
Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能;
我们需要填写好Location这个报头属性
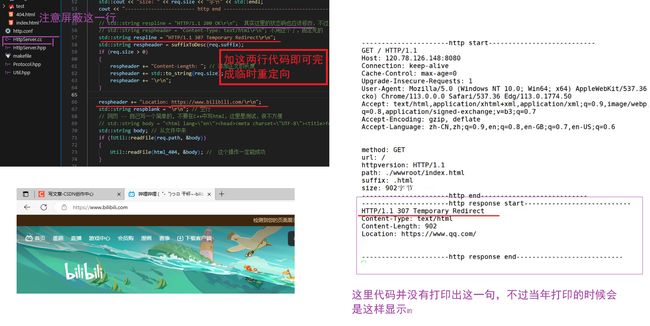
静态网页 -- 目前我们所写的,因为C++并不适合写网页,动态网页专注与交互,用C++来做比较麻烦,所以我们C++程序员一般也不适用写复杂网页
修正bug代码
之前的图片不显示bug已经修复,是之前的函数用错的原因,现在进行更正
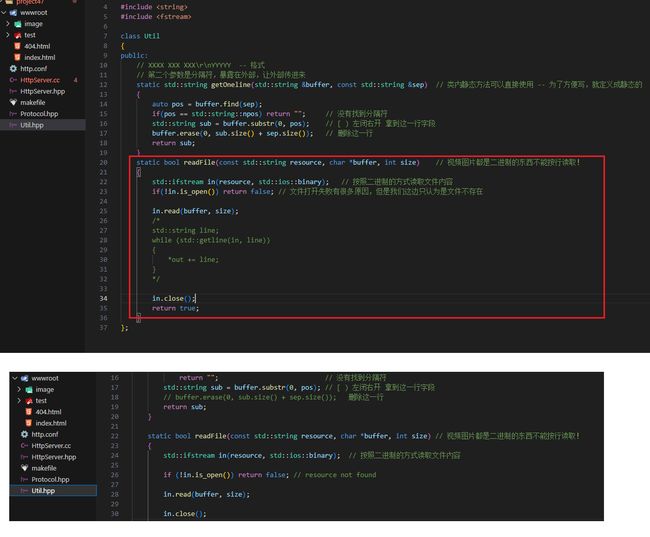
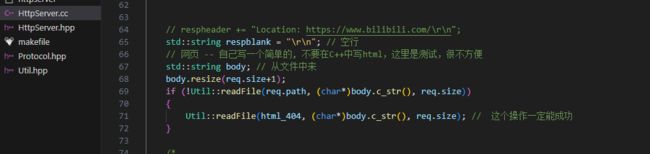
不过需要注意的是,这样会导致当资源不存在的时候,跳转的404页面将会跳转不成功,这个问题出现在添加的读取内容大小那边,因为当资源不存在的时候读取大小为-1(本程序设计),导致404页面读取失败,这里就不进行修正了,注意这一点就好了
源码
HttpServer.cc
#include "HttpServer.hpp"
#include
using namespace std;
using namespace server;
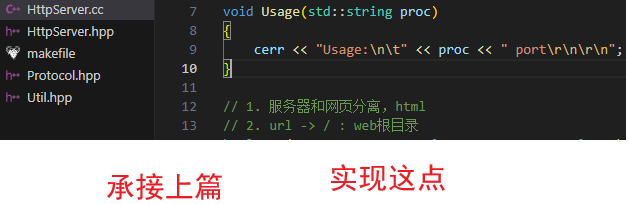
void Usage(std::string proc)
{
cerr << "Usage:\n\t" << proc << " port\r\n\r\n";
}
std::string suffixToDesc(const std::string suffix)
{
std::string ct = "Content-Type: ";
if (suffix == ".html")
ct += "text/html";
else if (suffix == ".jpg")
ct += "application/x-jpg";
ct += "\r\n";
return ct;
}
// 1. 服务器和网页分离,html
// 2. url -> / : web根目录
// 3. 我们要正确给客户端返回资源类型,我们首先要自己知道!所有的资源都有后缀!!!
bool Get(const HttpRequest &req, HttpResponse &resp)
{
/*
伪代码
if(req.path == "test.py") 假如提交到一个python脚本
{
首先建立进程间通信, pipe
fork创建子进程, execl("/bin/puthon", test.py) 这样子进程就执行这个脚本
父进程, 将req.parm 通过管道写过某些后端语言, C++并不适合写这个, 一般是指, python, java, php等
这也是为什么服务器是C++写的,但是它的后端却是其他语言的原因
}
if(req.path == "/search")
{
req.parm
使用我们自己写到C++方法,提供服务
}
*/
// for test
cout << "----------------------- http start ------------------------------------" << endl;
cout << req.inbuffer << endl; // 暂时不做其他处理,直接打印出来看请求内容
std::cout << "method: " << req.method << std::endl;
std::cout << "url: " << req.url << std::endl;
std::cout << "httpversion: " << req.httpversion << std::endl;
std::cout << "path: " << req.path << std::endl;
std::cout << "suffix: " << req.suffix << std::endl;
std::cout << "size: " << req.size << "字节" << std::endl;
cout << "------------------------ http end -------------------------------------" << endl;
// std::string respheader = "Content-Type: text/html\r\n"; 不用这个了,固定死的
std::string respline = "HTTP/1.1 200 OK\r\n"; // 其实这里的状态码也应该修改,不过这边就不做字符串拼接的过程了,就这样显示
// std::string respline = "HTTP/1.1 307 Temporary Redirect\r\n";
std::string respheader = suffixToDesc(req.suffix);
// 往后每次http请求,都会自动携带曾经设置的所有cookie,帮服务器进行鉴权行为
respheader += "Set-Cookie: name=1234567abcdefg; Max-Age=120\r\n"; // 有时间限制的120秒,时间到自动失效
// respheader += "Location: https://www.bilibili.com/\r\n";
std::string respblank = "\r\n"; // 空行
// 网页 -- 自己写一个简单的, 不要在C++中写html,这里是测试,很不方便
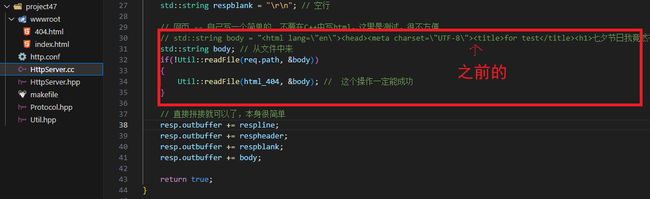
std::string body; // 从文件中来
body.resize(req.size+1);
if (!Util::readFile(req.path, (char*)body.c_str(), req.size))
{
Util::readFile(html_404, (char*)body.c_str(), req.size); // 这个操作一定能成功
}
/*
测试 -- 这个代码会导致本地图片显示不出来,因为视频图片都是二进制的东西不能按行读取!要用read
if (!Util::readFile(req.path, &body))
{
Util::readFile(html_404, &body); // 这个操作一定能成功
}
*/
/*
这里没用了,修正还是有错误,错误转移了
if (req.size > 0)
{
respheader += "Content-Length: "; 添加正文的长度
respheader += std::to_string(req.size);
respheader += "\r\n";
}
*/
// 直接拼接就可以了,本身很简单
respheader += "Content-Length: ";
respheader += std::to_string(body.size());
respheader += "\r\n";
resp.outbuffer += respline;
resp.outbuffer += respheader;
resp.outbuffer += respblank;
cout << "----------------------- http response start ------------------------------------" << endl;
std::cout << resp.outbuffer << std::endl;
cout << "----------------------- http response end ------------------------------------" << endl;
resp.outbuffer += body;
return true;
}
// ./httpServer 8080 -- 这里实际是80端口号,不过这里是为了测试就不用了,并且80也绑定不了,前一千多号基本内部资源无法绑定
int main(int argc, char *argv[])
{
if (argc != 2)
{
Usage(argv[0]);
exit(0);
}
uint16_t port = atoi(argv[1]);
unique_ptr httpsvr(new HttpServer(Get, port));
/*
伪代码
httpsvr->registerCb("/", Get); // 这就是 功能路由!
httpsvr->registerCb("/search", Search);
httpsvr->registerCb("/test.py", Other);
*/
httpsvr->initServer();
httpsvr->start();
return 0;
} HttpServer.hpp
#pragma once
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include "Protocol.hpp"
namespace server
{
enum
{
USAGE_ERR = 1,
SOCKET_ERR,
BIND_ERR,
LISTEN_ERR
};
static const uint16_t gport = 8080;
static const int gbacklog = 5; // 10、20、50都可以,但是不要太大比如5千,5万
using func_t = std::function; // 回调
class HttpServer
{
public:
HttpServer(func_t func, const uint16_t &port = gport) : _func(func), _listensock(-1), _port(port)
{
}
void initServer()
{
// 1. 创建socket文件套接字对象 -- 流式套接字
_listensock = socket(AF_INET, SOCK_STREAM, 0); // 第三个参数默认 0
if (_listensock < 0)
{
exit(SOCKET_ERR);
}
// 2.bind绑定自己的网路信息 -- 注意包含头文件
struct sockaddr_in local;
memset(&local, 0, sizeof(local));
local.sin_family = AF_INET;
local.sin_port = htons(_port); // 这里有个细节,我们会发现当我们接受数据的时候是不需要主机转网路序列的,因为关于IO类的接口,内部都帮我们实现了这一功能,这里不帮我们做是因为我们传入的是一个结构体,系统做不到
local.sin_addr.s_addr = INADDR_ANY; // 接受任意ip地址
if (bind(_listensock, (struct sockaddr *)&local, sizeof(local)) < 0)
{
exit(BIND_ERR);
}
// 3. 设置socket 为监听状态 -- TCP与UDP不同,它先要建立链接之后,TCP是面向链接的,后面还会有“握手”过程
if (listen(_listensock, gbacklog) < 0) // 第二个参数backlog后面再填这个坑
{
exit(LISTEN_ERR);
}
}
/*
伪代码
void registerCb(std::string servicename, func_t cb) // 写一个注册方法
{
funcs.insert(std::make_pair(servicename, cb));
}
*/
void HandlerHttp(int sock)
{
// 1. 读到完整的http请求
// 2. 反序列化
// 3. 反序列化后得到httprequest, 回调填写httpresponse, 利用_func(req, resp)
// 4. 序列化resp
// 5. send
char buffer[4096];
HttpRequest req;
HttpResponse resp;
size_t n = recv(sock, buffer, sizeof(buffer) - 1, 0); // 大概率我们直接能读取到完整的http请求
if(n > 0)
{
buffer[n] = 0;
req.inbuffer = buffer;
req.parse();
// funcs[req.path](req, resp); 有了哈希表就不需要下面这一句了, 使用路径绑定服务, 这里并没有实现
_func(req, resp); // 可以根据bool返回值进行判断,这里就不判断了
send(sock, resp.outbuffer.c_str(), resp.outbuffer.size(), 0);
}
}
void start()
{
for (;;) // 一个死循环
{
// 4. server 获取新链接
// sock 和 client 进行通信的fd
struct sockaddr_in peer;
socklen_t len = sizeof(peer);
int sock = accept(_listensock, (struct sockaddr *)&peer, &len);
if (sock < 0)
{
continue;
}
/* 这里直接使用多进程版的代码进行修改
version 2 多进程版(2) -- 注意子进程会继承父进程的一些东西,父进程的文件操作符就会被子进程继承,
即父进程的文件操作符那个数字会被继承下来,指向同一个文件,但是文件本身不会被拷贝一份
也就是说子进程可以看到父进程创建的文件描述符sock和打开的listensock */
pid_t id = fork();
if (id == 0) // 当id为 0 的时候就代表这里是子进程
{
/* 关闭不需要的文件描述符 listensock -- 子进程不需要监听,所以我们要关闭这个不需要的文件描述符
即使这里不关,有没有很大的关系,但是为了防止误操作我们还是关掉为好 */
close(_listensock);
if (fork() > 0) exit(0); // 解决方法1: 利用孤儿进程特性
HandlerHttp(sock);
close(sock);
exit(0);
}
/* 一定要关掉,否则就会造成文件描述符泄漏,但是这里的关掉要注意了,这里只是把文件描述符的计数-1
子进程已经继承过去了,所以这里也可以看做,父进程立马把文件描述符计数-1,只有当子进程关闭的时候,这个文件描述符真正的被关闭了
所以后面申请的链接使用的还是这个4号文件描述符,因为计算机太快了
close(sock); */
/* father
那么父进程干嘛呢? 直接等待吗? -- 显然不能,这样又会回归串行运行了,因为等待的时候会阻塞式等待
且这里并不能用非阻塞式等待,因为万一有一百个链接来了,就有一百个进程运行,如果这里非阻塞式等待
一但后面没有链接到来的话.那么accept这里就等不到了,这些进程就不会回收了 */
// 不需要等待了 version 2
waitpid(id, nullptr, 0);
}
}
~HttpServer() {}
private:
int _listensock;
uint16_t _port;
func_t _func;
// std::unordered_map funcs; 构建一个哈希表用来实现功能路由
};
} // namespace server makefile
cc=g++
httpserver:HttpServer.cc
$(cc) -o $@ $^ -std=c++11
.PHONY:clean
clean:
rm -f httpserverProtocol.hpp
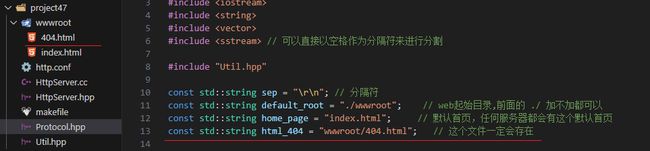
#pragma once
#include
#include
#include
#include // 可以直接以空格作为分隔符来进行分割
#include
#include
#include
#include "Util.hpp"
const std::string sep = "\r\n"; // 分隔符
const std::string default_root = "./wwwroot"; // web起始目录,前面的 ./ 加不加都可以
const std::string home_page = "index.html"; // 默认首页,任何服务器都会有这个默认首页
const std::string html_404 = "wwwroot/404.html"; // 这个文件一定会存在
class HttpRequest
{
public:
HttpRequest() {}
~HttpRequest() {}
void parse() // 解析
{
// 1. 从inbuffer中拿到第一行,分隔符\r\n
std::string line = Util::getOneline(inbuffer, sep);
if (line.empty())
return;
// 2. 从请求行中提取三个字段 -- 下面放开的三个
std::cout << "line: " << line << std::endl; // 打印出来显示一下
std::stringstream ss(line); // 可以直接以空格作为分隔符来进行分割
ss >> method >> url >> httpversion;
/*
2.1 /search?name=zhangsan&pwd=123456
我们首先通过 ? 将左右进行分离
如果是POST方法,本来就是分离的!
左边path, 右边parm
*/
// 3. 添加web默认路径
path = default_root; // 未来可以进行修改 变成 ./wwwroot
path += url; // 到这一步之后就会 变成 ./wwwroot/a/b/c.html
// 未来访问路径都会从这个路径下开始访问
// 这边会遇到一个问题,当url是一个 / 的时候就不行,拼接的时候会变成 ./wwwroot/ 没有具体目标
if (path[path.size() - 1] == '/')
path += home_page; // 加一个判断就行了
// 4. 获取path对应的资源后缀
// ./wwwroot/index.html
// ./wwwroot/test/a.html
// ./wwwroot/image/宇宙.jpg
auto pos = path.rfind(".");
if (pos == std::string::npos)
suffix = ".html";
else
suffix = path.substr(pos); // 截取到末尾
// 5. 得到资源的大小
struct stat st;
int n = stat(path.c_str(), &st);// 这个系统调用会自动填充字段
if(n == 0) size = st.st_size; // 成功返回 0
else size = -1;
}
public:
std::string inbuffer;
/* 我们可以细分许多字段,当需要什么就可以添加什么,这里为了简洁就不做这些工作了
std::string reqline; // 请求行
std::vector reqheader; // 请求报头
std::string body; // 请求正文
*/
std::string method; // 请求方法
std::string url; // 网址
std::string httpversion; // 请求版本
std::string path; // web默认路径
std::string suffix; // 文件后缀
int size; // 正文的长度,把请求的资源的大小返回
// std::string parm; 伪代码,用于放置 ? 右边的数据
};
class HttpResponse
{
public:
std::string outbuffer;
}; Util.hpp
#pragma once
#include
#include
#include
class Util
{
public:
// XXXX XXX XXX\r\nYYYYY -- 格式
// 第二个参数是分隔符,暴露在外部,让外部传进来
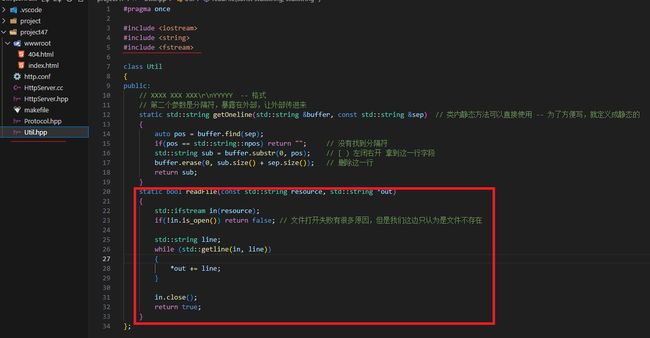
static std::string getOneline(std::string &buffer, const std::string &sep) // 类内静态方法可以直接使用 -- 为了方便写,就定义成静态的
{
auto pos = buffer.find(sep);
if (pos == std::string::npos)
return ""; // 没有找到分隔符
std::string sub = buffer.substr(0, pos); // [ ) 左闭右开 拿到这一行字段
// buffer.erase(0, sub.size() + sep.size()); 删除这一行
return sub;
}
static bool readFile(const std::string resource, char *buffer, int size) // 视频图片都是二进制的东西不能按行读取!
{
std::ifstream in(resource, std::ios::binary); // 按照二进制的方式读取文件内容
if (!in.is_open()) return false; // resource not found
in.read(buffer, size);
in.close();
return true;
}
/*
测试 -- 这个代码会导致本地图片显示不出来,因为视频图片都是二进制的东西不能按行读取!要用read
static bool readFile(const std::string resource, std::string *out) // 视频图片都是二进制的东西不能按行读取!
{
std::ifstream in(resource, std::ios::binary); // 按照二进制的方式读取文件内容
if (!in.is_open()) return false; // resource not found
std::string line;
while (std::getline(in, line))
{
*out += line;
}
in.close();
return true;
*/
}; 其他文件内容自行添加即可,这里为了简便篇幅就不粘贴了
未完持续更新中……