论文笔记:Integrating Semantic Segmentation and Retinex Model for Low Light Image Enhancement
来源:Proceedings of the 28th ACM International Conference on Multimedia (2020)
目录
-
- Contributions
- Mothology
-
- Architecture
- Information Extraction
-
- Image Decomposition
- Semantic Segmentation
- Reflectance Enhancement
- Illumination Adjustment
- EXPERIMENTS
-
- Evaluation on Synthesis Data
-
-
- Quantitative
-
- Evaluation on Real-Captured Data
-
-
- Quantitative
- Qualitative
-
- Ablation Study
- Notes
Contributions
- 提出了一种融合语义分割和Retinex模型的深度网络,用于微光图像的增强。利用语义先验和信号结构引导的能力,该模型能够成功地同时处理光照分布、中等噪声(moderate noise意思是?)和颜色失真的任务,并在弱光增强上有良好的视觉效果。
- 语义先验通过空间变换处理特征来指导光照和反射率的联合增强,从而提高区域恢复的恢复质量,如噪声抑制、颜色校正等。大量的实验表明了该方法的优越性和其各部分的有效性。
- 为了方便相关研究,我们建立了一种新的弱光图像合成模型,生成了2458张欠曝光图像数据集,每一幅图像都基于Cityscapes和Camvid数据集进行了gt图像的润色。在我们的合成过程中,曝光调整、噪音产生和颜色失真都被考虑在内。此外,还收集了100幅真实的微光图像(包含网络资源和亲自拍摄),以评估我们的方法和其他SOTA微光图像增强方法。
其他基于Retinex方法的局限性:
它们是用手工制作的约束条件构建的。因此,这些方法对不同类型的自然图像的复杂信号特性的捕捉都不具有足够的适应性。
Mothology
语义信息可以为微光增强提供丰富的信息。 例如,天空等平滑区域的噪声可以被强烈模糊,而不影响主观效果,而对于街道标识等细节丰富的区域,去噪时要小心,否则会破坏细节。然而,现有的微光增强方法忽视了语义信息的重要性,因而性能有限。
基于此,论文提出了一种新的语义感知的微光增强网络,利用语义信息更好地理解场景和恢复内在反射率(a novel semantic-aware low-light enhancement network, which leverages semantic information for better scene understanding and intrinsic reflectance restoration )。
Architecture
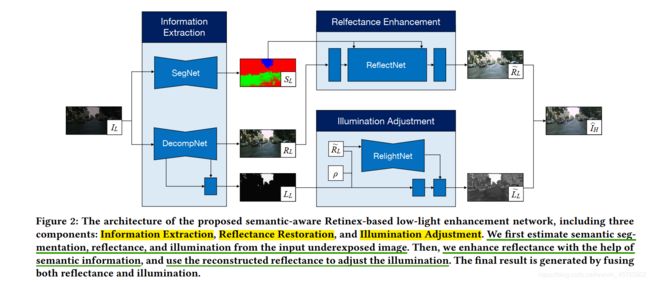
Information Extraction
Image Decomposition
思想:受RetinexNet和KinD的启发,沿用了Retinex理论,将图像 I I I分解为反射层 R R R和照明层 L L L,有 I = R ⋅ L I=R \cdot L I=R⋅L。这是个ill-posed问题,需要额外的约束。因为观察到相同物体在不同环境光下看起来不同,所以推测低光照下图像 I L I_L IL和对应正常光图像 I H I_H IH在反射层上有一致的结构。(排除照明层,所以就是反射层相同,是这个逻辑?)
结构:DecompNet,用于提取反射层 R R R和照明层 L L L。
训练过程:用成对图像训练,用到了 smoothness loss, reconstruction loss, and illumination smoothness loss 。
Semantic Segmentation
思想: S L S_L SL用于引导修复反射层。
结构:SegNet,用于提取语义信息 S L S_L SL。
训练过程:这里用到一个轻量级U-Net。训练时都用到了低光和正常图像。
S L S_L SL为 I L I_L IL的分割结果, S H S_H SH为 I H I_H IH的分割结果, S G T S_{GT} SGT为真实分割标注。 C E CE CE代表element-wise(pixel-wise?)计算交叉熵损失。与 S H S_H SH相比 S L S_L SL内物体更难检测, L 1 L_1 L1的目的是引导模型更精确地检测 S L S_L SL。
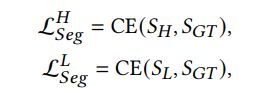
![]()
Reflectance Enhancement
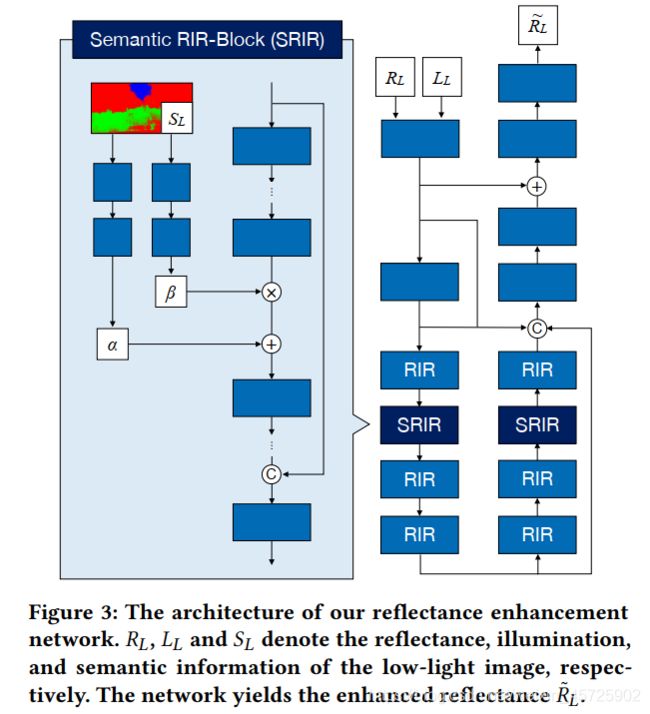
ReflectNet: 借助语义信息 S L S_L SL重建 R L R_L RL。
由一些 Residual In Residual (RIR) 块组成。在网络的前后两端,添加了一些 concatenation-based 和 addition-based 的跳跃连接。这种基于残差的结构,让ReflectNet具有很强的像素调节能力,有利于抑制噪声和修正颜色。
为了引进语义信息,设计了一种变体—— Semantic Residual In Residual (SRIR) 块,语义信息通过一个线性转换(a linear transformation),来调节 R L R_L RL的特征。如图,语义信息 S L S_L SL经过几个卷积层的处理,获得 α \alpha α和 β \beta β。 R L R_L RL的特征先后与 β \beta β相乘、与 α \alpha α相加。
训练时用到了对应正常图的反射层 R H R_H RH,用MSE、SSIM、Grad(Gradient Loss)测量损失。

Illumination Adjustment
RelightNet: 用 R ~ L \tilde{R}_L R~L和 ρ \rho ρ来重新平衡亮度分布。
用一个轻量级U-Net提取重建后反射层 R ~ L \tilde{R}_L R~L,这样,语义信息 S L S_L SL间接参与了照明调节过程。RelightNet的输出结果 L ~ L \tilde{L}_L L~L被sigmoid层限制在[0,1]之间。通过将 L ~ L \tilde{L}_L L~L和 R ~ L \tilde{R}_L R~L逐像素相乘,弱光图像增强网络生成最终结果 I ^ H = L ~ L × R ~ L \hat{I}_H=\tilde{L}_L \times \tilde{R}_L I^H=L~L×R~L。
在我们的训练数据集中,光照分布的范围很广,接近于真实的应用场景。但这对模型的训练带来了挑战。为了解决这一问题,引入了**比例参数 ρ \rho ρ**来指导调整过程。
对于训练, ρ \rho ρ是根据ground truth I H I_H IH的像素均值与输入 I L I_L IL的像素均值之比来定义的,而在测试阶段,我们使用固定的 ρ \rho ρ= 5.0。该比例也可让用户交互提供,来控制提亮程度。(可以运用到项目中)
为了更好的利用照明调节比 ρ \rho ρ,提出一个比率学习损失:

最终损失函数:
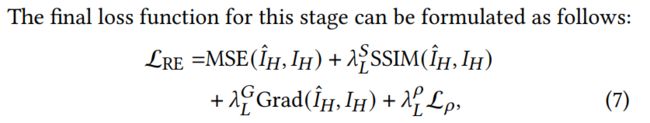
EXPERIMENTS
Evaluation on Synthesis Data
Quantitative

Evaluation on Real-Captured Data
Quantitative
use the no-reference metric NIQE

Qualitative
LIME提高整体亮度,但过度曝光某些区域。
MBLLEN产生相对自然的光照分布,但其结果仍然不够明亮。
RetinexNet造成严重的色彩和对比度失真,导致不自然的结果。
DeepUPE呈现了一种令人满意的对比度,而在欠曝光的地方有细节缺失。
EnlightenGAN产生区域性的颜色伪影,降低视觉质量。
KinD无法预测适当的光照增强,过度曝光使部分过亮,产生奇怪的白色伪影。
而且,大多数方法都会产生颜色失真。相比之下,我们的结果的颜色分布是自然的,这反映了我们在定量评价(怀疑论文有笔误,这里应为定性评价)中的优越表现。
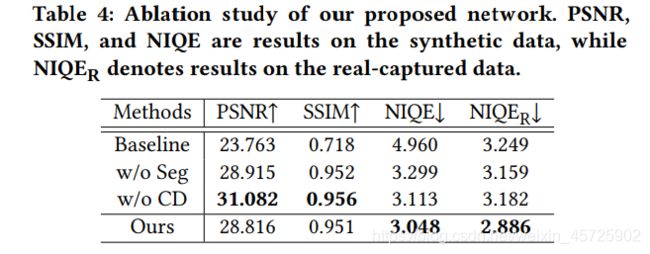
Ablation Study
使用RetinexNet作为baseline,RetinexNet也遵循Retinex分解的pipeline,但有不同的网络架构选择。
消融实验设置:

论文中的解释是
w/o Seg:Compared with the baseline, our new network architectures …
w/o CD:The injection of semantic information(论文的意思是:语义信息帮助学会去除颜色失真?)
对比结果:
Notes
这篇论文将语义分割引入了弱光增强领域,结合Retinex理论,用语义信息引导重建反射层、间接引导重建照明层。
在照明层调节的环节,引入了照明调节比 ρ \rho ρ,可借鉴之,让用户通过交互,自己控制增强程度。
另外,项目的数据集基于街景,可用于大创项目。