keepalived工作原理
-
keepalived 简介
keepalived 负载均衡的框架是依赖于 Linux Virtual Server(LVS 的 ipvs)内核模块提供的 Layer 4上的负载均衡。
keepalived 实现了一套通过对服务器池(也就是Real Server 池,Server pool)健康状态来动态地、自动维护的管理被负载均衡的服务器池的 checker。
而 keepalived 高可用是通过 VRRP 协议来实现的,VRRP 在路由器的故障转移中非常常用,而 keepalived 实现了一套 hooks 为 VRRP finite state machine 提供底层,高速的协议互动。
keepalived 框架可以被用于独立的亦或者是全部一起使用来提供弹性服务的基础设施,并且是一个免费,开源的软件。总的来说它能为我们提供这样一些功能:
- 在 LVS 框架上扩展,二者具备良好的兼容性。
- 通过对服务器池的健康检查,对失效机器的故障隔离与通知。
- 通过 VRRP 实现的负载均衡器之间的切换,达到高可用
-
keepalived 框架
因为与 LVS 的深入嵌套,避免不了的使用到内核空间,所以整体来说,keepalived 分为两层结构:
- 用户空间
- 内核空间
官网上的框架设计:
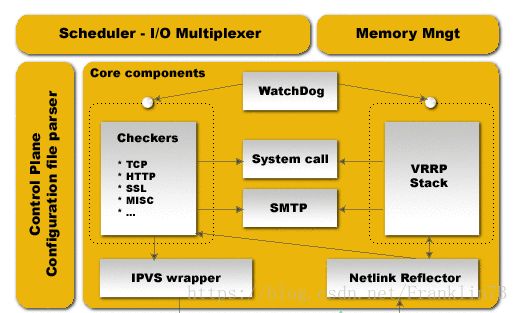
keepalived 涉及到内核空间的两个网络功能,分别是:
- IPVS:LVS 的 IP 负载均衡技术的使用
- NETLINK:提供高级路由及其他相关的网络功能
在用户空间主要分为4个部分,分别是Scheduler I/O Multiplexer、Memory Mangement、Control Plane 和Core components。
- Scheduler I/O Multiplexer:一个I/O复用分发调度器,它负责安排keepalived 所有内部的任务请求。
- Memory Management:一个内存管理机制,这个框架提供的访问内存的一些通用方法。
- Control Plane 是 keepalived 的控制面板,可以实现对配置文件进行编译和解析,keepalived的配置文件解析比较特殊,它只有在用到某模块时才解析相应的配置。
- Core components 是 keepalived 要核心组件,包含了一系列的功能模块,
而其中就会有这样的一些模块:
- WatchDog:监控checkers和VRRP进程的状况;
- Checkers:真实服务器的健康检查 health checking,是 keepalived 最主要的功能;
- VRRP Stack:负载均衡器之间的切换;
- IPVS wrapper : 设定规则到内核 ipvs 的接口;
- Netlink Reflector:设定 vrrp 的vip地址等路由相关的功能
-
keepalived 原理
通过上诉我们了解到 keepalived 主要功能实现还是依赖于 LVS 与 VRRP。LVS 我们已经知道是什么了。但是 VRRP 又是什么?
最早的 VRRP 是由 IETF 提出的解决局域网中配置静态网关出现单点失效现象的路由协议,使得在发生故障而进行设备功能切换时可以不影响内外数据通信,不需要再修改内部网络的网络参数。VRRP 协议需要具有IP地址备份,优先路由选择,减少不必要的路由器间通信等功能。
VRRP 协议的功能实现是将两台或多台路由器设备虚拟成一个设备,对外提供虚拟路由器IP,而在路由器组内部,通过算法多角度的选举此时的 MASTER 机器作为这个对外 IP 的拥有者,也就是 ARP 的解析,MASTER 的 MAC 地址与 IP 相互对应,其他设备不拥有该 IP,状态是 BACKUP,而 BACKUP 除了接收 MASTER 的 VRRP 状态通告信息外,不执行对外的网络功能。当主机失效时,BACKUP 将立即接管原先 MASTER 的网络功能。从而达到了无缝的切换,而用户并不会知道网络设备出现了故障。
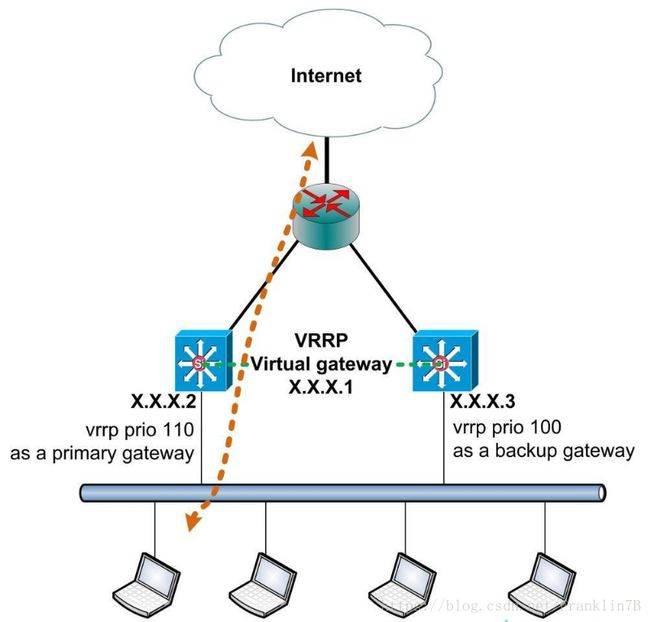
简单来说,vrrp 就是让外界认为只有一个网关在工作(在逻辑结构上将两台虚拟成一台设备),当一般情况下,所有的网络功能都通过 Master 来处理,而其突然出问题的时候,有一个备胎能够立马接替他的工作,而不用用户手动修改自己的电脑配置。
而上文所说的 Master,也就是我们的主路由是通过主备路由之间相互通信,通过其 route_id、优先级等来综合判定从而选举出来的,主路由会每隔 1 秒(这个值可以修改配置)发送 vrrp 包通知 Backup 路由自己还是健康的存活着,而 Backup 路由若是3秒(这个值可以修改)没有收到主路由的 vrrp 包,便会将自己切换成主路由来接替工作。
而若是原主路由突然复活了,在接收到当前主路由发来的 vrrp 包是会从中解析其优先级的值,若是自己的优先级较高便会将自己切换成主路由,并告知当前的主路由,然后开始工作。而当前的路由便会将自己切换成 Backup。
如果优先级相等的话,将比较路由器的实际IP,IP值较大的优先权高;
不过如果对外的虚拟路由器IP就是路由器本身的IP的话,该路由器始终将是MASTER,这时的优先级值为255。
当我们了解了 VRRP 的工作原理之后,我们会发现其实它与 LVS 的工作原理似乎差不多呀,都是虚拟出一个 IP 出来给别人,然后自己在内部通过某种机制来进行切换,这应该便是为什么它们有这么高的契合度的原因.
但是它们还是有区别的:
LVS 在后面的Server Pool 中每台都可以同时工作,而 VRRP 同时工作的机器只有一台,只有当一台出问题之后才会启用另外一台。
所以我们换着方式让两个工具相互结合,让 keepalived 工作在 Load Balancer 上,做好出口路由的高可用,LVS 在后端做好负载均衡,这样大大地提高了我们的服务质量,特别是在突然的大流量冲击下。