每日一课 | 如何用双向链表实现LRU淘汰机制算法

03.
双向链表实现LRU淘汰机制算法
大家好,我是营长,上期给大家分享—— 单向链表、双向链表和循环链表图文解析
本期分享内容:如何用双向链表实现LRU淘汰机制算法
本期营长邀请的是春晨溅雨·4位算法工程师为我们分享《数据结构算法面试全解析》专栏。
数据结构算法面试
双向链表实现LRU淘汰机制算法
无论是应届生的春招、秋招还是社招,难以避免的一关都是要面对面试官来几个手撕算法,如果你参加过几次面试,就知道链表出现的频率是极其高的。
上一篇文章主要给大家讲解了链表的一些类型,包括:单向链表、双向链表以及循环链表,同时还给出了不同链表的代码实现,做一些简单的增删改查。
那么本章将提高一点难度,为你介绍常见的链表算法,包括一些 BAT 等大厂的笔试面试题,同时最后彩蛋里将详细的介绍可以称之为链表笔试面试史上最难的一道题:LRU 淘汰算法的实现。
1. 小试牛刀
接下来用各大厂商的面试真题带大家进一步的深入了解链表,掌握了下面的几道题,你就无敌了~
1.1 反转链表
题目:
反转一个单链表。
示例:
输入: 1->2->3->4->5->NULL
输出: 5->4->3->2->1->NULL
解题思路:
遇到链表的算法题时,我们首先需要简化题目,虽然示列的长度有 5,但是我们要假设长度就为 1,如 1-->null,对于这样的链表,反转链表只需要将 null 节点指向 1,即 null-->1,这样会简单很多。不要忘记在最后返回新的头引用!
解题代码:
public ListNode reverseList(ListNode head) {
ListNode prev = null;
ListNode curr = head;
while (curr != null) {
ListNode nextTemp = curr.next;
curr.next = prev;
prev = curr;
curr = nextTemp;
}
return prev;
}
复杂度分析:
时间复杂度:O(n),假设 nn 是列表的长度,时间复杂度是 O(n)O(n)。
空间复杂度:O(1)。
1.2 进阶版:反转链表 2
题目:
反转从位置 m 到 n 的链表。请使用一趟扫描完成反转。
说明:
1 ≤ m ≤ n ≤ 链表长度。
示例:
输入: 1->2->3->4->5->NULL, m = 2, n = 4
输出: 1->4->3->2->5->NULL
解题代码:
class Solution {
private boolean stop;
private ListNode left;
public void recurseAndReverse(ListNode right, int m, int n) {
if (n == 1) {
return;
}
right = right.next;
if (m > 1) {
this.left = this.left.next;
}
this.recurseAndReverse(right, m - 1, n - 1);
if (this.left == right || right.next == this.left) {
this.stop = true;
}
if (!this.stop) {
int t = this.left.val;
this.left.val = right.val;
right.val = t;
this.left = this.left.next;
}
}
public ListNode reverseBetween(ListNode head, int m, int n) {
this.left = head;
this.stop = false;
this.recurseAndReverse(head, m, n);
return head;
}
}
复杂度分析:
时间复杂度: O(N)。对每个结点最多处理两次。递归过程,回溯。在回溯过程中,我们只交换了一半的结点,但总复杂度是 O(N)。
空间复杂度: 最坏情况下为 O(N)。在最坏的情况下,我们需要反转整个链表。这是此时递归栈的大小。
1.3 旋转链表
题目:
给定一个链表,旋转链表,将链表每个节点向右移动 k 个位置,其中 k 是非负数。
示例 1:
输入: 1->2->3->4->5->NULL, k = 2
输出: 4->5->1->2->3->NULL
解释:
向右旋转 1 步: 5->1->2->3->4->NULL
向右旋转 2 步: 4->5->1->2->3->NULL
示例 2:
输入: 0->1->2->NULL, k = 4
输出: 2->0->1->NULL
解释:
向右旋转 1 步: 2->0->1->NULL
向右旋转 2 步: 1->2->0->NULL
向右旋转 3 步: 0->1->2->NULL
向右旋转 4 步: 2->0->1->NULL
解题思路:
算法实现很直接:
找到旧的尾部并将其与链表头相连 old_tail.next = head,整个链表闭合成环,同时计算出链表的长度 n。
找到新的尾部,第 (n - k % n - 1) 个节点 ,新的链表头是第 (n - k % n) 个节点。断开环 newtail.next = None,并返回新的链表头 newhead。
解题代码:
class Solution {
public ListNode rotateRight(ListNode head, int k) {
if (head == null) return null;
if (head.next == null) return head;
ListNode old_tail = head;
int n;
for (n = 1; old_tail.next != null; n++){
old_tail = old_tail.next;
}
old_tail.next = head;
ListNode new_tail = head;
for (int i = 0; i < n - k % n - 1; i++)
new_tail = new_tail.next;
ListNode new_head = new_tail.next;
new_tail.next = null;
return new_head;
}
}
复杂度分析:
时间复杂度:O(N),其中 NN 是链表中的元素个数
空间复杂度:O(1),因为只需要常数的空间
2. 2019 阿里面试真题:如何用双向链表实现 LRU 淘汰机制算法高阶案例讲解
常用的缓存淘汰策略有以下几种:
先进先出算法(FIFO)
Least Frequently Used(LFU):淘汰一定时期内被访问次数最少的页面,以次数作为参考
Least Recently Used(LRU)
LRU 缓存淘汰算法: 本章主要介绍 LRU,其英文全称为 Least Recently Used,翻译过来就是最近最少使用的。说白了就是该容器或者称之为缓存 cache 在容量一定的情况下,只存储你最近使用过的数据,我们可以称之为“热源”。最近一次使用的数据温度最高,最后一次使用的数据温度最低。
举个简单的例子:当你在使用手机时,当你打开一个软件比如:高铁管家,然后你没有关闭该软件,又打开了抖音,你会发现当你想要从后台清除正在运行的软件时,抖音会排在了第一个,高铁管家排在了第二位,当你再打开一个软件时,第一位又变成了你最近打开的软件。和 lru 不同的是,lru 是会自己判断内存是否达到上限,并自动清除你最后打开的软件,说到这里你应该能理解 lru 的淘汰策略。
那么 LRU 是基于什么样的需求背景出现的呢?从工业生产中我们会发现,因为物理机器的内存存储总是有限的,并且想通过简单粗暴的形式进行物理扩容代价是非常大的,所以在一些内存不够的场景下,我们会采用淘汰旧内容的策略。因为计算机体系结构中,最大的最可靠的存储是硬盘,它容量很大,并且内容可以固化,但是访问速度很慢,所以需要把使用的内容载入内存中;内存速度很快,但是容量有限,并且断电后内容会丢失,并且为了进一步提升性能,还有 CPU 内部的 L1 Cache,L2 Cache 等概念。因为速度越快的地方,它的单位成本越高,容量越小,新的内容不断被载入,旧的内容肯定要被淘汰,所以就有这样的使用背景。
链表如何实现 LRU? 那我们如何用数据结构高效率的去构建这样一个缓存容器呢?总结一个公式:双向链表+哈希表=LRU。显而易见的是我们每次在进行增删改查操作时,对当前操作的数据我们需要将其放在链表的第一个节点,这样,就能保证链表中的数据是按照使用时间进行排序的,最后一个节点一定是最后一次使用的数据。这种构造方式效率最高,具体效率高的原因将会在最后总结给大家。
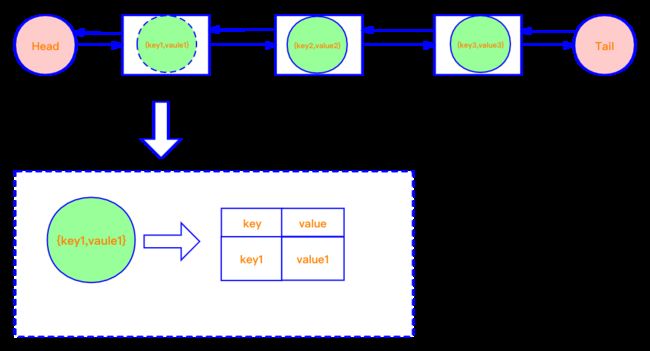
class DLinkedNode {
int key;
int value;
DLinkedNode prev;
DLinkedNode next;
}
private Hashtable cache =
new Hashtable();
private int size;
private int capacity;
private DLinkedNode head, tail;
/**
* LRU 构造函数
* @param capacity
*/
public LRU(int capacity) {
this.size = 0;
this.capacity = capacity;
head = new DLinkedNode();
// head.prev = null;
tail = new DLinkedNode();
// tail.next = null;
head.next = tail;
tail.prev = head;
}
private void addNode(DLinkedNode node) {
/**
* Always add the new node right after head.
*/
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
private void removeNode(DLinkedNode node){
/**
* Remove an existing node from the linked list.
*/
DLinkedNode prev = node.prev;
DLinkedNode next = node.next;
prev.next = next;
next.prev = prev;
}
private void moveToHead(DLinkedNode node){
/**
* Move certain node in between to the head.
*/
removeNode(node);
addNode(node);
}
private DLinkedNode popTail() {
/**
* Pop the current tail.
*/
DLinkedNode res = tail.prev;
removeNode(res);
return res;
}
public int get(int key) {
DLinkedNode node = cache.get(key);
if (node == null)
return -1;
// move the accessed node to the head;
moveToHead(node);
return node.value;
}
public void put(int key, int value) {
DLinkedNode node = cache.get(key);
if(node == null) {
DLinkedNode newNode = new DLinkedNode();
newNode.key = key;
newNode.value = value;
cache.put(key, newNode);
addNode(newNode);
++size;
if(size > capacity) {
// pop the tail
DLinkedNode tail = popTail();
cache.remove(tail.key);
--size;
}
} else {
// update the value.
node.value = value;
moveToHead(node);
}
}
在 LRU 类中,需要以下几个属性:
HashTable 是 Java 类中哈希表的封装类,作为存储单元存储 key,value 的数据结构。
private Hashtable
描述当前 LRU 容器的长度
private int size;
描述 LRU 容器的初试长度
private int capacity;
LRU 的头节点和尾节点,没有实际数据,为了获取头节点,和尾节点而定义
private DLinkedNode head, tail;
几个重要的核心方法:
put():每次往 LRU 中添加值调用的方法。添加调用 addNode 方法,addNode 方法每次都是将新节点数据放在链表的最左侧,即头节点的后面(图中红色圆圈 Head),然后根据当前 LRU 的长度 size 和容量 capacity 判断容器当前的容量是否已满,如果满了,调用 remove 方法,每次删除尾节点的前一个节点,同时 size 需要减一。
get():每次根据 key 获取元素,也需要将该元素移到头部,代表这是最新使用的数据,即 moveToHead 方法,该方法分两步:1.removeNode()删除当前节点 2.addNode()在头部增加当前节点
popTail()删除并返回尾部节点的上一个节点
核心操作的步骤:
save(key, value),首先在 HashMap 找到 Key 对应的节点,如果节点存在,更新节点的值,并把这个节点移动队头。如果不存在,需要构造新的节点,并且尝试把节点塞到队头,如果 LRU 空间不足,则通过 tail 淘汰掉队尾的节点,同时在 HashMap 中移除 Key。
get(key),通过 HashMap 找到 LRU 链表节点,因为根据 LRU 原理,这个节点是最新访问的,所以要把节点插入到队头,然后返回缓存的值。
复杂度分析: 时间复杂度:对于 put 方法,由于是对链表操作,所以其复杂度为 O(1) ,而 get 方法是从哈希表中获取,所以复杂度也是 O(1)。这就是上文所说的高效的原因。空间复杂度:因为哈希表和双向链表最多存储 capacity + 1 个元素,所以其空间复杂度应为 O(capacity)。
在工业生产中 LRU 算法在 redis 中用的尤为居多: 1.LRU 过期策略 这种策略是适用于当 Redis 存储内存值接近或者超过 maxmemory 参数(maxmemory_policy)设置时就会触发 LRU 策略。当 Redis 发生这种情况的时候系统提供了几种策略:
noeviction:拒绝写请求,正常提供读请求,这样可以保证已有数据不会丢失(默认策略);
volatile-lru:尝试淘汰设置了过期时间的 key,虽少使用的 key 被淘汰,没有设置过期时间的 key 不会淘汰;
volatile-ttl:跟 volatile-lru 几乎一样,但是他是使用的 key 的 ttl 值进行比较,最先淘汰 ttl 最小的 key;
volatile-random:其他同上,唯一就是他通过很随意的方式随机选择淘汰 key 集合中的 key;
allkeys-lru:区别于 volatile-lru 的地方就是淘汰目标是全部 key,没设置过期时间的 key 也不能幸免;
allkeys-random:这种方式同上,随机的淘汰所有的 key。
2.LRU 淘汰算法
它把设置了过期 key 的集合用链表的方式,按照使用频率是顺序排列。当这个链表空间满掉以后就会从最尾部剔除,将新加入的元素放在链表头部,或者当 key 被访问时也会将此 key 移动到链表头部,所以这样链表就是按照最多访问排列的先后顺序。
小结
数组链表优劣势。文章到此,链表的主要特性和算法都几乎已经介绍完毕。通过前三篇文章,大致可以总结为以下几点:
链表的一个重要特点是插入、删除操作灵活方便,不需移动结点,只需改变结点中指针域的值即可。
数组由于使用存储单元的邻接性体现数组中元素的逻辑顺序关系,因此,对数组进行插入和删除运算时,可能需要移动大量的元素,以保持这种物理和逻辑的一致性。例如,数组中有 m 个元素,往第 i(i
链表在实现缓存的结构以及数据容器中扮演了重要的作用,例如 LinkedList,HashMap,ConcurrentHashMap 等等。
今日内容有get吗,欢迎各位留言讨论!
下期预告:栈与队列的定义
以上专栏均来自CSDN GitChat专栏《数据结构算法面试全解析》,作者春晨溅雨·4位算法工程师,专栏详情可识别下方二维码查看哦!
了解更多详情
可识别下方二维码
