使用Docker配置深度学习的运行环境
文章目录
- 推荐
- 实验环境
- 前言
- docker安装
- docker操作
- docker配置
-
- 常见方法(安装包、联网、程序管理器)安装驱动的前提要求
- 传统方法安装驱动程序
-
- 程序管理器安装
- 联网安装
- deb包安装
- 安装完成后的设置
- 非传统方法安装-通过容器安装驱动的前提要求
-
- 安装NVIDIA-Container-Toolkit应用程序的前提要求
- 安装NVIDIA-Container-Toolkit应用程序
- 非传统方法-通过容器安装驱动
- 反复报错
- 之前反复重装时卸载步骤
- 最终结果
推荐
- 在linux系统中进行操作,最重要的就是意识到用户权限,这在通过不同方式安装不同应用中非常重要,不然你就会导致一些用户无法使用。
- 除了用户权限的问题还有就是程序的安装位置,不同的安装位置的程序的启动方式是不同的,安装在
/usr/local/bin目录下的程序,如果启动文件是在这个目录下,在任意位置都可以直接启动,如果启动文件是在子目录下,需要链接一下才能在任意位置启动。在其他位置则需要连接一下才能在任意位置使用。 - 如果一些应用是希望开机自启动的,类似于下面的alist,就需要编辑守护进程,这样系统在启动的时候会自动调用守护进程。
建议在尝试Linux之前首先参考一下相关文献:
- Ubuntu:Install Ubuntu desktop
- Linux 101:软件安装与文件操作
- 码农教程:Linux操作系统查看系统信息
实验环境
参考:
- PHP中文网:linux如何查看版本信息
- 阿里云:ubuntu查看硬件信息
查看系统信息的指令:
cat /proc/version
uname -a
sudo lshw
gnome-shell --version
| 项目 | 内容 |
|---|---|
| 系统 | Ubuntu 22.04(jammy) |
| 内存 | 12GiB |
| 处理器 | Intel® Core™ i5-6300HQ CPU @ 2.30GHz × 4 |
| 图形 | Intel® HD Graphics 530 & GM107M [GeForce GTX 960M] |
| GNOME | GNOME Shell 42.9 |
| 操作系统类型 | 64位 |
| 磁盘 | 128GB |
前言
在进行科研工作时,很多时候都需要对代码进行复现。复现很简单,问题的难点在于环境的配置,环境配置好了,实验自然就能够复现,环境配置错误,往往会不停报错。因此为了省去配置环境的麻烦,我们选择把环境连同系统一起打包,即采用docker,实现快速可迁移的代码复现。
docker安装
在电脑上安装Docker,切记安装的是Docker engine!!!Docker desktop-小孩子的玩具,狗都不用(里面功能有缺陷,无法挂载GPU,还要配合engine使用才行,官网说desktop包含engine,狗屁!害我装了好几遍desktop配置)!!!,安装Docker engine参见官网教程。
 安装好以后docker帮助命令如下所示。
安装好以后docker帮助命令如下所示。
docker -h
Flag shorthand -h has been deprecated, please use --help
Usage: docker [OPTIONS] COMMAND
A self-sufficient runtime for containers
Common Commands:
run Create and run a new container from an image
exec Execute a command in a running container
ps List containers
build Build an image from a Dockerfile
pull Download an image from a registry
push Upload an image to a registry
images List images
login Log in to a registry
logout Log out from a registry
search Search Docker Hub for images
version Show the Docker version information
info Display system-wide information
Management Commands:
builder Manage builds
buildx* Docker Buildx (Docker Inc., v0.11.0)
compose* Docker Compose (Docker Inc., v2.19.1)
container Manage containers
context Manage contexts
dev* Docker Dev Environments (Docker Inc., v0.1.0)
extension* Manages Docker extensions (Docker Inc., v0.2.20)
image Manage images
init* Creates Docker-related starter files for your project (Docker Inc., v0.1.0-beta.6)
manifest Manage Docker image manifests and manifest lists
network Manage networks
plugin Manage plugins
sbom* View the packaged-based Software Bill Of Materials (SBOM) for an image (Anchore Inc., 0.6.0)
scan* Docker Scan (Docker Inc., v0.26.0)
scout* Command line tool for Docker Scout (Docker Inc., 0.16.1)
system Manage Docker
trust Manage trust on Docker images
volume Manage volumes
Swarm Commands:
swarm Manage Swarm
Commands:
attach Attach local standard input, output, and error streams to a running container
commit Create a new image from a container's changes
cp Copy files/folders between a container and the local filesystem
create Create a new container
diff Inspect changes to files or directories on a container's filesystem
events Get real time events from the server
export Export a container's filesystem as a tar archive
history Show the history of an image
import Import the contents from a tarball to create a filesystem image
inspect Return low-level information on Docker objects
kill Kill one or more running containers
load Load an image from a tar archive or STDIN
logs Fetch the logs of a container
pause Pause all processes within one or more containers
port List port mappings or a specific mapping for the container
rename Rename a container
restart Restart one or more containers
rm Remove one or more containers
rmi Remove one or more images
save Save one or more images to a tar archive (streamed to STDOUT by default)
start Start one or more stopped containers
stats Display a live stream of container(s) resource usage statistics
stop Stop one or more running containers
tag Create a tag TARGET_IMAGE that refers to SOURCE_IMAGE
top Display the running processes of a container
unpause Unpause all processes within one or more containers
update Update configuration of one or more containers
wait Block until one or more containers stop, then print their exit codes
Global Options:
--config string Location of client config files (default
"/home/stu/.docker")
-c, --context string Name of the context to use to connect to the
daemon (overrides DOCKER_HOST env var and
default context set with "docker context use")
-D, --debug Enable debug mode
-H, --host list Daemon socket to connect to
-l, --log-level string Set the logging level ("debug", "info",
"warn", "error", "fatal") (default "info")
--tls Use TLS; implied by --tlsverify
--tlscacert string Trust certs signed only by this CA (default
"/home/stu/.docker/ca.pem")
--tlscert string Path to TLS certificate file (default
"/home/stu/.docker/cert.pem")
--tlskey string Path to TLS key file (default
"/home/stu/.docker/key.pem")
--tlsverify Use TLS and verify the remote
-v, --version Print version information and quit
Run 'docker COMMAND --help' for more information on a command.
For more help on how to use Docker, head to https://docs.docker.com/go/guides/
docker操作
参考:
- 菜鸟教程:Docker教程
#查看本地镜像
docker images
| 名字 | 属性 |
|---|---|
| REPOSITORY | 表示镜像的仓库源 |
| TAG | 镜像的标签 |
| IMAGE ID | 镜像ID |
| CREATED | 镜像创建时间 |
| SIZE | 镜像大小 |
#查看所有容器
docker ps -a
| 名字 | 属性 |
|---|---|
| CONTAINER ID: | 容器 ID。 |
| IMAGE | 使用的镜像。 |
| COMMAND | 启动容器时运行的命令。 |
| CREATED | 容器的创建时间。 |
| STATUS | 容器状态。 |
| PORTS | 容器的端口信息和使用的连接类型(tcp\udp)。 |
| NAMES | 自动分配的容器名称。 |
常见操作指令如下所示:
#拉取镜像
docker pull
#运行镜像为容器
docker run -it ubuntu /bin/bash
#退出终端
exit
#启动容器
docker start 1e560fca3906
#进入容器
docker exec 1e560fca3906
#停止容器
docker stop 1e560fca3906
#重启容器
docker restart 1e560fca3906
#导出容器
docker export 1e560fca3906 > ubuntu.tar
#导入容器
docker import ubuntu.tar test/ubuntu:v1
#删除容器
docker rm -f 1e560fca3906
docker配置
1. 启动的容器要想正常使用还需要安装一些软件
比如要想让启动的容器可以通过ssh连接进行访问,就需要在容器中安装ssh服务。当我们需要在云服务器中安装docker容器又想要在外部可以直接访问这个容器而不是先登录服务器然后再打开docker容器,我们可以把docker容器的ssh端口映射到服务器的某个端口上,这样我们可以通过ssh直接访问内部的docker容器。
参考:
- 知乎:OpenSSH安装与使用-Linux
- 腾讯云开发者社区:ubuntu系统启用root用户远程登陆
- SegmentFault:VsCode轻松使用docker容器-Remote Containers
- 菜鸟教程:容器互联
#在容器内安装ssh方便通过ssh访问容器
apt install ssh
----------------------------------------------------------------------------------------
#在容器内添加用户密码方便通过ssh登陆时访问
passwd root
123
----------------------------------------------------------------------------------------
#容器内设置端口映射,将容器端口22映射到宿主机的某个端口
/etc/init.d/ssh start %启动ssh
/etc/init.d/ssh stop %关闭ssh
/etc/init.d/ssh restart %重启ssh
----------------------------------------------------------------------------------------
#容器内修改配置文件,允许用户通过密码登陆root用户
/etc/ssh/sshd_config
PermitRootLogin yes
----------------------------------------------------------------------------------------
#其它主机通过ssh连接容器
ssh -p port user@ip
123
2. 在实现远程登录以后要想用于深度学习人工智能开发还需要安装pytorch。
在实现容器能够通过ssh连接以后要想用于深度学习开发还需要配置好深度学习环境。
Prompt:服务器深度学习环境配置?
参考:
- CSDN:深度学习服务器环境配置总结
- 知乎:给Linux服务器配置深度学习环境
- 腾讯云:cuda卸载与安装
- CSDN:实现Linux服务器配置深度学习环境并跑代码完整步骤
上述最后一个参考还是有可取之处的,虽然不是很正确。
深度学习服务器比较好的管理方式是采用分配账户的方式来提高服务器的利用率。其中cuda最好是通过全局的方式安装到机器上的,也就是所有用户都可以访问,nvidia驱动和cudnn是直接安装在全局上的,这个没什么疑问。Anaconda和pytorch/tensorflow是需要每个用户自行安装的,每个用户根据自己不同的需要安装不同的包。
#安装相应的pytorch版本
pip3 install torch torchvision torchaudio
3. 安装pytorch之前还需要检查一下看能不能使用宿主机的显卡。不然的话就没办法进行深度学习人工智能训练。
Prompt:怎么让容器能够访问宿主机的GPU显卡?
参考:
- 稀土掘金:ubuntu如何查看硬件信息
- CSDN:linux(ubuntu)查看硬件设备命令
#查看硬件设备信息
sudo lshw
sudo lshw -C display
#如果找不到此命令就安装:apt install lshw
%系统
# uname -a # 查看内核/操作系统/CPU信息
# head -n 1 /etc/issue # 查看操作系统版本
# cat /proc/cpuinfo # 查看CPU信息
# hostname # 查看计算机名
# lspci -tv # 列出所有PCI设备
# lsusb -tv # 列出所有USB设备
# lsmod # 列出加载的内核模块
# env # 查看环境变量
%资源
# free -m # 查看内存使用量和交换区使用量
# df -h # 查看各分区使用情况
# du -sh <目录名> # 查看指定目录的大小
# grep MemTotal /proc/meminfo # 查看内存总量
# grep MemFree /proc/meminfo # 查看空闲内存量
# uptime # 查看系统运行时间、用户数、负载
# cat /proc/loadavg # 查看系统负载
%磁盘和分区
# mount | column -t # 查看挂接的分区状态
# fdisk -l # 查看所有分区
# swapon -s # 查看所有交换分区
# hdparm -i /dev/hda # 查看磁盘参数(仅适用于IDE设备)
# dmesg | grep IDE # 查看启动时IDE设备检测状况
%网络
# ifconfig # 查看所有网络接口的属性
# iptables -L # 查看防火墙设置
# route -n # 查看路由表
# netstat -lntp # 查看所有监听端口
# netstat -antp # 查看所有已经建立的连接
# netstat -s # 查看网络统计信息
%进程
# ps -ef # 查看所有进程
# top # 实时显示进程状态
%用户
# w # 查看活动用户
# id <用户名> # 查看指定用户信息
# last # 查看用户登录日志
# cut -d: -f1 /etc/passwd # 查看系统所有用户
# cut -d: -f1 /etc/group # 查看系统所有组
# crontab -l # 查看当前用户的计划任务
%服务
# chkconfig --list # 列出所有系统服务
# chkconfig --list | grep on # 列出所有启动的系统服务
%程序
# rpm -qa # 查看所有安装的软件包
经过检查发现,这个容器无法识别宿主机的显卡,所以也就没办法运行深度学习,我们需要手动把GPU挂载上去才可以。
4. 怎么把宿主机的GPU显卡挂载到容器上?
Prompt:ubuntu服务器怎么挂载GPU到docker中?
要想让容器能够使用GPU,还需要安装container-toolkit,但是问题在于toolkit安装在哪里?安装在容器中还是宿主机中?感觉应该是安装在宿主机中。
在官方指导中,可以通过官网下载安装包安装,也可以通过在线联网安装,也可以通过系统自带的程序管理器也就是additional driver应用程序来安装,还可以把驱动程序安装在容器中,这样容器方便迁移,驱动也就方便迁移。还真有人把驱动放进容器中,这也太神奇了。
常见方法(安装包、联网、程序管理器)安装驱动的前提要求
在使用上述常见方法安装显卡驱动时,有一些前提要求。前提要求是否满足可以参考以下官方链接进行检查
- NVIDIA:Pre-installation Actions
- 腾讯云:linux查看内核版本_ubuntu查看内核版本号
- 博客园:ubuntu—查看、安装、切换内核
- CSDN:ubuntu16查看\下载\切换内核
主要检查的就是有没有显卡,gcc是否安装,以及内核版本和内核头部是否匹配。如果不匹配要安装相应的内核头部。因为有了匹配的内核头部,安装应用程序的时候才能正常通过校验。验证指令如下所示:
#查看GPU是否可以用nvidia的驱动及cuda
lspci | grep -i nvidia
#检查系统版本
uname -m && cat /etc/*release
#检查gcc是否安装了
gcc --version
#查看内核版本
lsb_release -a
uname -a
hostnamectl
cat /proc/version
cat /etc/issue
lsb_release -a
#查看内核头文件的版本
dpkg --get-selections | grep linux 或者 dpkg --list |grep linux
#linux-image-版本号:内核映像文件
#linux-headers-版本号:内核头文件
#linux-image-extra-版本号:内核扩展文件
#最后一步比较复杂,就是要检查内核头文件版本和内核版本是否对应。如果不对应,需要进行修改,
当内核版本跟内核头部文件不匹配时,需要安装相应的内核版本。并修改配置文件使得按照要求的内核运行。
#安装内核版本
sudo apt install linux-image-版本号-generic
#查看配置文件中的内核启动顺序
grep menuentry /boot/grub/grub.cfg
#修改配置文件设置内核启动顺序
sudo gedit /etc/default/grub
#把GRUB_DEFAULT=0修改为 GRUB_DEFAULT=”Ubuntu,Linux 4.4.0-21-generic“ 这种类型的, 当然内核版本应该是你想要的.
#修改完成后更新使生效
sudo update-grub
#再修改配置文件
sudo gedit /boot/grub/grub.cfg
#大概在148行有个........,把版本号改为你需要的版本号,修改好以后保存退出.
#然后重启电脑
#检验是否安装成功
uname -r
当上述要求满足以后就可以按照常见方法中给定的安装步骤进行安装驱动程序。
传统方法安装驱动程序
下述方法进行之前最好检查以上前提要求是否满足!
安装显卡driver的方法参考:
- NVIDIA:NVIDIA Driver Installation Quickstart Guide
- myfreax:如何在 Ubuntu 20.04 安装 Nvidia 驱动程序
程序管理器安装
首先是最简单的通过additional driver安装驱动。对于Ubuntu系统来说,如果你的计算机有NVIDIA GPU,那么系统会自动安装开源驱动程序 Nouveau 和 NVIDIA专有驱动程序,你可以自己选择,通过桌面上的附加驱动(一块电路板图标)来更改使用的驱动。
默认情况下,Ubuntu 使用的 Nouveau 驱动程序通常比专有驱动程序慢得多,并且不支持最新的硬件和软件技术。所以通过additional driver可以更改GPU使用的驱动程序。
这种方法安装的驱动程序跟通过命令行安装的具有同样效力。通过命令行安装驱动如下所示:
#检查有什么驱动及对应的驱动程序
ubuntu-drivers devices
#安装想使用的版本的驱动
sudo apt install nvidia-driver-版本号
#当然这样安装的是ubuntu软件源默认提供的驱动程序,如果想使用最新的驱动程序,可以从NVIDIA官网上导入PPA来安装。
#重启使生效
sudo reboot
#检查安装情况
nvidia-smi
联网安装
BASE_URL=https://us.download.nvidia.com/tesla
DRIVER_VERSION=450.80.02
curl -fSsl -O $BASE_URL/$DRIVER_VERSION/NVIDIA-Linux-x86_64-$DRIVER_VERSION.run
sudo sh NVIDIA-Linux-x86_64-$DRIVER_VERSION.run
deb包安装
sudo apt-get install linux-headers-$(uname -r)
distribution=$(. /etc/os-release;echo $ID$VERSION_ID | sed -e 's/\.//g')
wget https://developer.download.nvidia.com/compute/cuda/repos/$distribution/x86_64/cuda-keyring_1.0-1_all.deb
sudo dpkg -i cuda-keyring_1.0-1_all.deb
sudo apt-get update
sudo apt-get -y install cuda-drivers
#下载好deb安装包后进行安装
sudo dpkg -i *.deb
安装完成后的设置
安装完成后还有一些设置需要完成,包括设置环境变量等,参考:
- NVIDIA:Post-installation Actions
不过在使用deb包安装nvidia驱动时,deb包里面包含了配置环境变量的脚本,所以会自动进行环境变量配置,其他的安装方式我还不知道。
非传统方法安装-通过容器安装驱动的前提要求
在系统中安装容器版本的驱动程序,参考:
- NVIDIA:NVIDIA Driver Containers
安装容器版本的驱动程序也有一定的要求,包括禁用开源驱动程序,GPU架构,container toolkit的设置,内核模块的开启等,具体检查方法,如下所示:
#禁用Nouveau,启用IPMI
Prompt:ubuntu如何禁用Nouveau?
## 禁用Nouveau
sudo tee /etc/modules-load.d/ipmi.conf <<< "ipmi_msghandler" \
&& sudo tee /etc/modprobe.d/blacklist-nouveau.conf <<< "blacklist nouveau" \
&& sudo tee -a /etc/modprobe.d/blacklist-nouveau.conf <<< "options nouveau modeset=0"
----------------------------------------------------------------------------------------
#查看GPU架构>Fermi(2.1)
## 安装查看GPU的工具
sudo apt install gpustat
##查看GPU的状态、温度、功率、显存使用情况
gpustat
----------------------------------------------------------------------------------------
#设置NVIDIA Container Toolkit for docker为root权限级别,
##根据官方文档中的意思就是:
##先安装好container toolkit,然后修改里面的配置,使得当启动容器时,导入的GPU驱动指向的是驱动容器内的驱动。
##所以container toolkit程序的作用就是设置:当启动容器并挂载GPU时,对应的GPU驱动程序去哪里找?通过修改container toolkit的配置文件可以修改驱动程序的位置,进而让挂载GPU时有不同的位置设置。
##所以我用常见方法安装好驱动以后,要想在容器中使用GPU,也需要下载container toolkit来指定容器去哪里找驱动程序,否则容器无法使用驱动程序。
##设置container toolkit应用程序的权限
sudo sed -i 's/^#root/root/' /etc/nvidia-container-runtime/config.toml
----------------------------------------------------------------------------------------
#启用i2c_core内核模块
## 如果是aws核,需要启用此模块,其他的版本就不用了
sudo tee /etc/modules-load.d/ipmi.conf <<< "i2c_core"
----------------------------------------------------------------------------------------
# 更新使得配置生效
sudo apt-get dist-upgrade
sudo update-initramfs -u
# 重启生效
sudo reboot
即安装驱动容器之前要先安装好NVIDIA-Container-Toolkit,安装NVIDIA-Container-Toolkit可以参考:
- NVIDIA:Installation Guide
安装NVIDIA-Container-Toolkit应用程序的前提要求
参考:
- NVIDIA:Installation Guide
安装这个应用程序也有前提要求,包括要先安装NVIDIA驱动程序,以及其他要求,如下所示:
#kernel version > 3.10
uname -a
----------------------------------------------------------------------------------------
#Docker >=19.03
docker -v
----------------------------------------------------------------------------------------
#GPU architecture >=Kepler
gpustat
----------------------------------------------------------------------------------------
#NVIDIA driver >=418.81.07
nvidia-smi
除了这些前提要求以外,官网还提到了CDI,但是介绍不是很详细,可以参考:
Github:CDI - The Container Device Interface
官网上的意思好像是说,安装好这个NVIDIA-Container-Toolkit以后,可以用于Container Device Interface (CDI) Support,也可以用于Docker;Docker的安装参考:Docker:Docker install,Docker安装好以后,我们可以在宿主机上安装NVIDIA-Container-Toolkit,从而让docker的容器可以使用GPU。
安装NVIDIA-Container-Toolkit应用程序
参考:
- NVIDIA:Installation Guide
- 简书:在docker容器中使用tensorflow-gpu
- CSDN:linux中在docker container中使用宿主机的GPU资源
#设置gpg-key
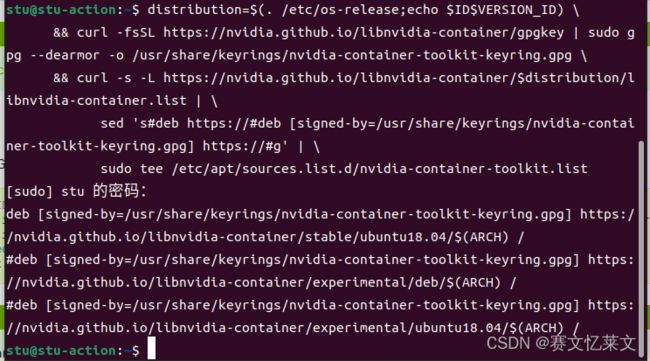
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
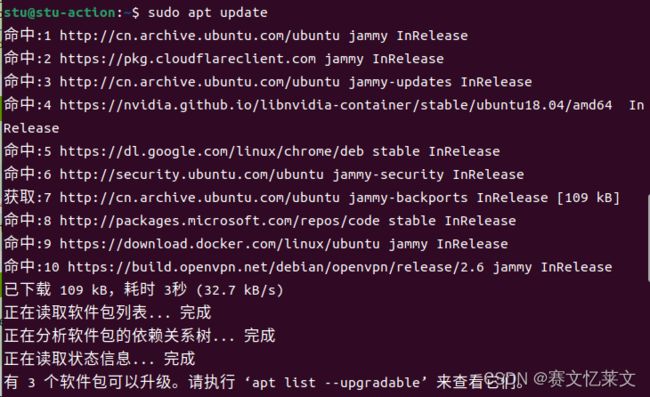
#更新及安装
sudo apt-get update
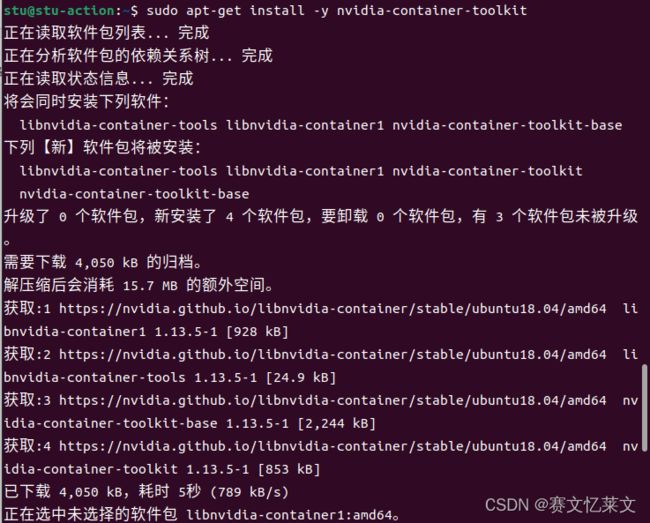
sudo apt-get install -y nvidia-container-toolkit
#配置container-toolkit的守护进程
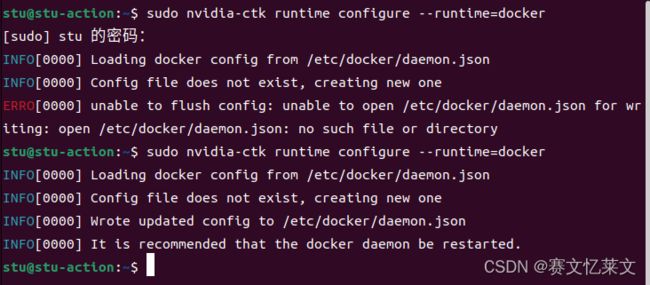
sudo nvidia-ctk runtime configure --runtime=docker
##上述命令不太行,我们修改一下
sudo dockerd --add-runtime=nvidia=/usr/bin/nvidia-container-runtime [...]
##或者
sudo mkdir -p /etc/systemd/system/docker.service.d
sudo tee /etc/systemd/system/docker.service.d/override.conf <<EOF
[Service]
ExecStart=
ExecStart=/usr/bin/dockerd --host=fd:// --add-runtime=nvidia=/usr/bin/nvidia-container-runtime
EOF
sudo systemctl daemon-reload \
&& sudo systemctl restart docker
#重启docker
sudo systemctl restart docker
Failed to restart docker.service: Unit docker.service is masked.
#通过运行基本的CUDA容器来验证工作设置
sudo docker run --rm --runtime=nvidia --gpus all nvidia/cuda:11.6.2-base-ubuntu20.04 nvidia-smi
#要想使用vscode连接容器,需要安装三个插件
Docker #Makes it easy to create, manage, and debug containe
Remote - ssh #Open any folder on a remote machine using SSH and
Dev containers #Open any folder or repository inside a Docker contai
##这样在启动容器以后就可以通过右键容器选择“attach visual studio code”来连接容器
----------------------------------------------------------------------------------------
#通过vscode连接远程服务器并将上述三个拓展也安装到服务器上
##如果访问不了docker就是用户权限问题
sudo gpasswd -a <当前登陆用户名> docker
### 例如: sudo gpasswd -a xuxiaocong docker
### 从用户组中删除: sudo gpasswd -d <当前登陆用户名> docker
##链接上以后,再添加三个拓展,然后再重启就可以使用docker了
sudo reboot
----------------------------------------------------------------------------------------
#当配置好上述设置以后每次登陆还需要输入密码为了省略上述操作我们可以生成ssh-key,然后把公钥上传到远程服务器的
##/home/hph/.ssh/authorized_keys中
----------------------------------------------------------------------------------------
#怎么把宿主机的GPU显卡挂载到容器中?
#要想把宿主机的GPU挂载到容器中,需要在宿主机中安装一个NVIDIA-Container-toolkit组件
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
sudo systemctl restart docker
#安装好以后将GPU挂载到容器中的命令就是:
sudo docker run -e NVIDIA_VISIBLE_DEVICES=all nvidia/cuda:10.0-base nvidia-smi
命令执行过程中如下图所示:

参考:
- CSDN:docker: Error response from daemon: Unknown runtime specified nvidia.
上面反复错误就是因为我用的是Docker desktop,导致缺少docker.service文件,连systemctl都找不到docker.service在哪里,更开不了守护进程daemon。
如果还有问题可以参考:
- 简书:在docker容器中使用tensorflow-gpu
- CSDN:ubuntu20.04下安装Docker和NVIDIA Container Toolkit教程
- 稀土掘金:安装NVIDIA Container Toolkit
非传统方法-通过容器安装驱动
在满足上面提到的要求以后,我们可以启动一个驱动容器,也就是专门用来运行驱动程序的容器,
#启动此驱动容器
sudo docker run --name nvidia-driver -d --privileged --pid=host \
-v /run/nvidia:/run/nvidia:shared \
-v /var/log:/var/log \
--restart=unless-stopped \
nvidia/driver:450.80.02-ubuntu18.04
----------------------------------------------------------------------------------------
for pkg in docker.io docker-doc docker-compose podman-docker containerd runc; do sudo apt-get remove $pkg; done
#在驱动容器启动完成后,我们就可以在深度学习容器中挂载GPU了
sudo docker run --gpus all nvidia/cuda:11.0-base nvidia-smi
sudo docker run --gpus all nvidia/cuda:11.8.0-devel-ubuntu22.04 nvidia-smi
sudo apt autoremove
#systemctl --user enable docker-desktop
#service文件位置
#/etc/systemd/system/multi-user.target.wants/docker.service
在驱动容器启动以后,我们可以运行能够挂载GPU的容器了。
反复报错
Docker desktop安装以后,Docker相关命令正常运行,但是就是没有Service服务和Daemon守护进程。

![]()

参考:
- stackoverflow:docker-desktop does not launch on ubuntu [Failed to start docker-desktop.service: Unit docker-desktop.service is masked]
之前反复重装时卸载步骤
- 卸载客户端
sudo apt remove docker-desktop
- 删除配置文件
rm -r $HOME/.docker/desktop
sudo rm /usr/local/bin/com.docker.cli
sudo apt purge docker-desktop
- 删除无用的软链接
最终结果
# 查看系统内版本
#uname -a不行
cat /etc/issue
# 拉取python镜像
docker pull python:3.11@sha256:7d57b1fef9b7fda8bf331b971a3ca96c3214313666fafdf26d33f1d0e6399222
# 运行python容器
docker run -it --runtime=nvidia --gpus all --name python3-test python:3.11@sha256:7d57b1fef9b7fda8bf331b971a3ca96c3214313666fafdf26d33f1d0e6399222
# 拉取ubuntu镜像
docker pull ubuntu:jammy-20230624@sha256:b060fffe8e1561c9c3e6dea6db487b900100fc26830b9ea2ec966c151ab4c020
# 运行ubuntu容器
docker run -it --runtime=nvidia --gpus all --name ubuntu-test ubuntu:jammy-20230624@sha256:b060fffe8e1561c9c3e6dea6db487b900100fc26830b9ea2ec966c151ab4c020
#拉取Pytorch镜像
docker pull bitnami/pytorch:2.0.1
# 启动pytorch容器
docker run -it --runtime=nvidia --gpus all --name pytorch-test bitnami/pytorch:2.0.1
# 拉取18.0镜像
docker pull ubuntu:bionic-20230530@sha256:dca176c9663a7ba4c1f0e710986f5a25e672842963d95b960191e2d9f7185ebe
# 拉取正版pytorch镜像
docker pull pytorch/pytorch:2.0.1-cuda11.7-cudnn8-devel
# 运行正版pytorch镜像
docker run -itd --gpus all --name myenv pytorch/pytorch:2.0.1-cuda11.7-cudnn8-devel
Docker官方收了多少广告费,搜索Pytorch竟然第一个不是Pytorch社区开发的Pytorch镜像包,而是bitnami下面的。要是能用我就不说什么了,关键还不好用。按下载量排名也轮不上bitnami啊。
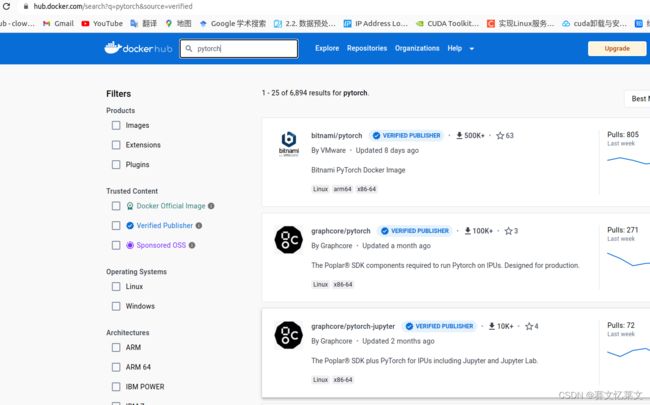 真正的pytorch镜像应该是:
真正的pytorch镜像应该是:
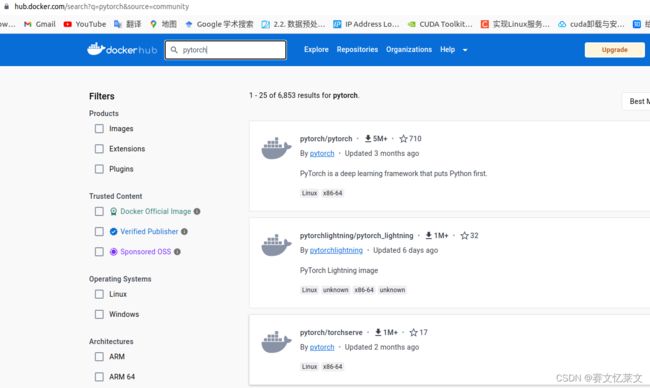
参考:
- CSDN:docker容器部署pytorch模型,gpu加速部署运行
- CSDN:史上最详细解决“搭建GPU版Pytorch Docker镜像”教程
- Docker hub:镜像
狗官方,要是搜索直接显示社区版本的,我也就不用走这么多弯路了,真狗!!!