融合MMEdu和Transformers技术的视障出行智能辅助系统(上海浦育AI未来夏令营结题论文)
融合MMEdu和Transformers技术的视障出行智能辅助系统
摘要
面对社会生活中众多视障者对出行的需求,视障出行智能辅助系统融合MMEdu和Transformers技术为视障者提供实时路况分析。本系统利用图像分类、目标检测和深度估计等软件技术,对摄像头实时获取的每一帧图像进行分析,检测盲道有无、红绿灯颜色、前方障碍等情况,并通过语音播报给视障者。鉴于网络上原有的对盲人出行辅助设备的研究,我们的智能系统在技术运用上进行了创新,将多种AI技术结合,实现精准、实时的信息分析。基于现有的研究成果,本系统在未来也将不断地改进,将现在的.bat文件替换成打包的手机软件,调用手机摄像头进行识别,使设备更便携,并通过使用更加轻量化的模型等手段,加快程序运转速度,使程序更加灵敏。
关键词
视障出行智能辅助系统 图像分类 目标检测 深度估计 软件技术
一、引言
随着社会的不断发展,越来越多的人开始关注残疾人群体的生活质量,特别是视障人士。视障人士作为社会中的特殊群体,由于失去了视觉感知的能力,导致他们在日常生活中面临许多困难,尤其是出行方面。在过去,视障人士通常依赖导盲犬、盲杖等传统辅助工具进行导航和感知周围环境,但由于这些工具的局限性,它们往往只能提供有限的帮助,难以满足视障人士日益增长的需求。因此,如何提高视障人士的出行体验,让他们能够在更加安全、便捷的环境中自由穿梭,已经成为当今社会亟待解决的问题。
1.1 研究背景
近年来,随着人工智能技术的迅速发展,利用机器学习算法解决视障人士出行难题的研究也越来越受到关注。例如,基于目标检测、图像分类、深度估计等技术,建立起来的智能辅助系统可以帮助视障人士更好地感知周围环境和障碍物,提升他们的出行效率和安全性。然而,这些技术仍然存在一些局限性,比如无法处理复杂的场景、识别精度不够高等问题。因此,如何进一步优化和完善这些技术,提高它们的应用效果,成为了该领域的研究热点。
1.视障人士出行环境的现状
视障人士的出行环境面临着多重挑战。首先,盲道的缺失或被挤占正在逐渐成为一个严重问题(见图1.1),使得他们无法信任依靠盲道来找到正确路径;其次,红绿灯的信号对于他们来说往往难以辨别,导致通行马路困难;此外,由于无法准确判断前方是否障碍物,他们经常面临与行人、车辆等发生碰撞的风险。这些困难使得视障人士的出行变得异常艰难和不便。

图1.1 盲道被挤占/缺失情况
2.辅助方式的历史与现状
在过去的几十年里,视障人士的出行一直是一个重要的社会问题。传统上,他们通常依赖导盲犬、盲杖和其他辅助工具来导航和感知周围环境。然而,这些方法存在一些局限性,能检测到的障碍物较为有限,无法提供足够的实时信息和安全保障。此外,借助导盲犬等动物的帮助可能还会带来一系列高昂的开支。
近年来,随着技术的不断进步,解决视障人士的出行问题的方式愈发科技化,但这些方案仍存在部分缺陷,致使其难以被广泛地应用于视障人士的日常。例如,部分项目利用光电传感、红外线障碍检测等多种传感器,虽然能够精确探测周围环境,但其价格昂贵,不易普及[1]。
3.辅助方式的未来发展趋势
随着人工智能和机器学习的快速发展,目标检测、图像分类、深度估计等技术正在逐步走向成熟。我们可以预见,基于这些AI技术所搭建的智能辅助系统可能会成为视障人士的得力助手,帮助他们更好地融入社会,享受更多的独立性和自主性。
1.2 研究目的
1.提供全面、实时的出行帮助
以往,视障人士只能依靠手杖或导盲犬等传统工具来判断周围的障碍和路况。然而,这些工具的局限性很大,难以满足现代城市交通的复杂性。因此,我们希望借助先进的技术手段,让视障人士能够在任何环境下都能轻松掌握周围的情况。具体来说,我们计划通过融合MMEdu和Transformers技术,利用语音播报,向盲人全方面地阐述周遭环境的信息,包括环境中的障碍物类型、红绿灯亮灯情况等。同时,我们还将利用摄像头和多种模型进行实时检测及分析,使视障人士能够通过该系统获得准确、实时的环境描述。这样一来,无论他们身处何地,都能够感受到周边的变化,做出合适的决策。
2.增加出行安全和自主性
视障人士往往因为无法准确感知环境而感到不安和焦虑;因此,我们的智能辅助系统能够帮助他们更加自信地迈出每一步。我们的系统将能够帮助他们更准确地感知周围环境,避免与行人、车辆等障碍物发生碰撞;这将为他们提供更大的安全保障。同时,利用红绿灯检测帮助视障人士独立通行马路,摆脱依赖,从而增加他们在出行过程中的自主性;为视障人士创造更多的机会和自由,让他们能够更好地享受生活。
3.提供了实用、经济的解决方案
我们深知项目需要考虑到使用者的实际需求和经济承受能力。因此,我们将通过结合开源模型和自己训练的模型的方法来制作这项项目。一方面,开源模型已经过广泛的研究和验证,具有较高的准确性和可靠性;另一方面,自己训练的模型可以应对项目中一些比较小众的需求。如此一来既降低成本,又增强方案的普及度,为更多的视障人士带来便利和福祉。
1.3 研究价值
1.呼吁社会关注弱势群体
视障人士是社会中的弱势群体之一,他们在日常生活中面临许多困难和挑战,特别是在出行方面。由于视觉障碍,他们往往难以独立实现自己的日常的出行需求,需要依赖其他人的帮助或者特殊的辅助设备。因此,如何为视障人士提供更加便利、安全、舒适的出行服务,是一项非常重要的事务。
2.提升视障人士的出行体验
我们将设备轻量化,通过将设备搭载在日常使用的电子产品上,以提高设备的便携性;同时,设备通过利用摄像头和多种模型进行实时检测及分析,实现对环境的描绘,提升视障人士的便利性。
总而言之,本研究的价值不仅在于为视障人士提供了更加便捷的出行服务,向他们提供了独立行走的机会,让他们重新找回自信,摆脱依赖;拾起自己的生活和追求。还呼唤了整个社会对于弱势群体的关注和支持。通过加强社会各界的合作和共同努力,我们可以进一步推动社会的包容性和平等,为每一位公民创造一个更加美好、和谐、富有尊严的生活环境。
二、项目实现过程
2.1 使用方法及原理
1.使用方法
我们的功能主要通过MMEDu和Transformers库实现——分别利用MMEDu库中的MMclassification和MMdetection模块进行图像分类和目标检测;运用Transformers库的Pipeline模块进行深度估计。
2.方法原理
(1)MMEdu
MMEdu是一个计算机视觉方向的深度学习开发工具,是一个用来训练AI模型的工具。
表2.1 MMEdu的内置模块概述[2]
| 模块名称 |
简称 |
功能 |
| MMClassification |
MMCls |
图片分类 |
| MMDetection |
MMDet |
图片中的物体检测 |
| MMGeneration |
MMGen |
GAN,风格化 |
| MMPose |
MMPose |
骨架 |
| MMEditing |
||
| MMSegmentation |
像素级识别 |
①MMclassification
MMClassifiation(简称cls)的主要功能是对图像进行分类,内置了常见的图片分类网络模型,有LeNet、MobilNet、ResNet18、ResNet50等。

图2.1 图像分类原理
MMclassification模块支持的数据集要求文件夹中包含三个图片文件夹,分别是test_set,training_set,val_set,分别存储测试集,训练集和验证集的图片;以及三个txt文件,classes.txt记录该数据集的类别,test.txt和val.txt分别记录测试集和验证集的图片名。

图2.2 数据集文件结构[3]
②MMdetection
MMDetection(简称MMdet)的主要功能是输出图片或视频中出现的多个对象名称,同时用方框框出对象所在方形区域。其支持的SOTA模型有FasterRCNN、Yolov3、SSD_Lite等。

图2.3 目标检测原理
MMdetection模块支持的数据集要求文件夹中包含两个文件夹annotations和images,分别存储标注信息以及图片数据,每个文件夹下面有train和valid两个json文件。

图2.4 数据集文件结构[4]
(2)Pipeline from Transformers
深度估计,是通过识别同一个世界坐标系下的点在不同图像中的像素坐标差异,就是视差。不同图像之间的视差,可以换算出物体和拍摄点之间的距离,也就是深度。

图2.5 深度估计原理图1[5]
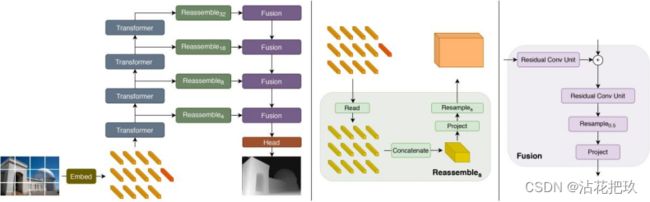
图2.6 深度估计原理图2[6]
2.2 开发过程
1.环境搭建
我们按照网址https://xedu.readthedocs.io/zh/latest/mmedu/installation.html提供的方法下载MMEdu库,搭建程序编写和模型训练的环境。
2.模型的选择与训练
我们首先选择了部分于我们而言训练较为困难,但应用普遍、具有较高的准确性和可靠性的开源模型进行下载[6][7];用于实现对障碍物的分类和对障碍物与视点距离进行深度估计。
然后对较为小众的功能需求进行相关的模型训练。
(1)盲道检测(图像分类)
首先通过网络搜索和实际拍摄,获得大量数据集图片(如图2.7)。
图2.7 盲道检测数据集源图片
然后利用预先编写好的程序进行模型训练,得到训练效果最好的权重文件(如图2.8)。

图2.8 模型训练
在进行模型训练时,需要根据反馈适当调整训练时的lr(学习率)和batch_size(批量大小)等超参数,以达到更高的训练效率,从而获得更好的训练效果。
最后将训练好的模型进行推理测验,检验模型的实际运用效果(如图2.9)。

图2.9 模型推理
若得到的模型推理效果不佳,则应重新训练。
(2)红绿灯检测(目标检测)
同样是通过网络查询和现场实拍的方式得到上百张数据集的源图片(如图2.10)。


图2.10 红绿灯灯效分类数据集源图片
随后对照片进行数据标注并转换为coco格式(如图2.11)。

图2.11 数据标注与转换
最后使用MMEdu对红绿灯的模型进行训练和推理验证。我们发现,该模型能够较准确地定位出红绿灯的位置,并识别出了灯效(如表2.2)。
表2.2 红绿灯灯效检测效果
| 原图 |
 |
 |
 |
| 推理结果 |
 |
 |
 |
3.程序编写
我们按照如图(见图2.12)思路进行程序编写。详细功能将在下文中进行介绍。

图2.12 程序编写技术路线图
三、项目创新点及功能展示
3.1 主要功能
1.图像的实时检测
在程序启动部分,就利用OpenCV开启摄像头,确保能以实时视频获取的形式使图像分析极具时效性。

图3.1 摄像头开启部分代码
2.道路类型分类和提醒
先导入道路的图像分类模型,利用BaseDeploy库判断所见的是否为盲道。如果不是,说明道路具有不确定性,不可靠;因此提醒盲人“小心前进,确保安全”。
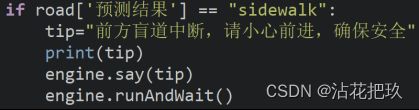
图3.2 道路类型分类关键代码展示
3.障碍物信息播报
先导入用于检测物品类别的ssdlite_mobilenetv2_scratch_600e_coco_20210629_110627-974d9307.pth(coco.onnx)模型,以及模型能检测的物品类别。

图3.3 障碍物监测-目标检测部分关键代码展示1

图3.4 模型能检测的物品类别(文本文档)
然后检测眼前所见的障碍物类型res,同时获取障碍物在图像中的位置coo。

图3.5 障碍物监测-目标检测部分关键代码展示2
同时导入用于深度估计的模型dpt-hybrid-midas,获取图像中每个像素点与视点的距离。

图3.6 障碍物监测-深度估计部分关键代码展示1
根据目标检测时获取到的障碍物坐标,获取到图像中障碍物部分与视点的最小距离,组合障碍物类型与远近的信息,构成播报给盲人的环境信息warn_sentence。
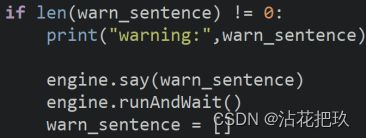
图3.7 障碍物监测-深度估计部分关键代码展示2
4.红绿灯分类和提醒
如果障碍物类型res包括代表信号灯的数字9,则利用light.onnx模型检测所见的红绿灯类型。如果识别到红灯(在模型训练时已设置标签0代表红灯),则播报“红灯,请止步”;反之,则播报“绿灯,请通行”。

图3.8 红绿灯分类部分关键代码展示1
如果在检测到绿灯的同时,检测到有车辆突然出现,则说明有紧急情况发生,设备先利用winsound库发出蜂鸣声,然后播报“紧急情况,后退避让”。

图3.9 红绿灯分类部分关键代码展示2
3.2 功能展示
表3.1 设备功能展示
| 红灯+非盲道 |
 |
| 绿灯 |
 |
| 环境监测+盲道 |
 |
3.3 创新点
1.探究创新 运用AI技术减少硬件的使用
如§1.1所述,大部分现有的避障辅助系统都运用了大量的硬件,而我们通过人工智能技术,替代了硬件原先的工作,简化了设备,但依然实现了预期的效果。
2.应用创新 将已知的人工智能技术与其他库结合,从而实现提醒功能
本系统面对盲人视力极弱的问题,使用pyttsx3库实现语音合成并通过扬声器来播报提醒,用winsound库进行蜂鸣警报,相较于安装语音合成模块/蜂鸣器等硬件的方式,更加简单便携;同时也贯彻了我们“运用AI技术减少硬件的使用”的理念。
3.组合创新 将多种技术结合,实现预期效果
本系统将目标检测、深度估计、图像识别等技术结合运用,实现对障碍物、盲道等物体的检测,且检测效果良好。
四、主题论证
视障出行智能辅助系统为视障者提供智能的出行帮助,旨在呼吁社会关注弱势群体,帮助视障者们找回自信,共建一个平等和谐的社会环境。利用开源的资源为这一项目提供灵感和技术支持,视障出行智能辅助系统借助人工智能软件技术对现实社会中的路况进行实时分析,实现对视障者的辅助。
图像分类、目标检测和深度估计是实现这一智能系统的核心技术。图像分类技术通过大量的模型训练,可以将图像分为多个类别;目标检测技术能够捕获图像中的目标信息;深度估计技术则对图像中各个像素点到摄像头的距离进行计算,用颜色的深浅呈现估计结果。在不同软件技术的相互支持下,智能系统对摄像头实时获取的每一帧图像进行分析,检测盲道有无、红绿灯颜色、前方障碍等情况,并通过语音播报给视障者。在实际运用中,图像分类技术检测盲道有无,帮助视障者规划出行路线;目标检测技术判断红绿灯情况和前方障碍,使视障者能及时避开障碍物以免发生事故;深度估计技术将障碍物到摄像头的距离播报给视障者,提高系统侦测障碍的精确度。视障者出行时借助这一智能系统可以得知前方路况,以达到辅助视障者出行,保障视障者安全的效果。
在实际测试中,本系统已经能够准确、实时地分析并播报路况,同时发挥了避免交通事故等意外情况发生的功能。这一实际运用效果在实现本系统基本功能之外,维护了社会生活的和谐稳定,也引发全社会对以视障者为代表的弱势群体的关注与支持。
五、项目成果及展望
5.1 项目成果
融合MMEdu和Transformers技术的视障出行智能辅助系统基本达到预期。
本文设计的融合MMEdu和Transformers技术的视障出行智能辅助系统,通过Thonny实现,具有以下突出特点:
1.能够为视障人士提供全面、实时的出行帮助;
2.增加了视障人士出行的安全和自主性;
3.为解决视障人士出行问题提供了实用、经济的解决方案;
4.成功运用AI技术减少传感器的使用;
5.成功将目标检测、图像分类、深度估计等技术结合,实现预期效果,读取环境信息;
6.最终效果能够直接双击执行,交互友好。
本项目的主要工作流程分为以下几个部分:
1.发现问题
2.背景调研
3.查阅现有研究、相关文献
4.设计解决方案
5.明晰系统的技术路线与运行逻辑
6.搜索数据集用图
7.寻找开源模型、训练模型
8.整合、编写程序并实验
9.撰写研究报告
5.2 未来展望
1.将系统搭载于手机上
现有的.bat文件虽然可以满足基本的需求,但由于该格式的文件自身搭载在Windows系统上,无法满足所有使用者外带的需求,便捷性仍有待提升。因此,我们希望将现有的代码转“.bat”文件的形式替换为将代码打包成手机软件、或制作成前端的形式,使使用者能够调用手机摄像头进行识别。
这种改变既使设备更加易于携带,同时又提升了用户体验:通过手机软件的方式,用户可以随时随地进行物体识别,无需再受限于固定的场所和设备。
2.加快程序运转速度
我们也希望通过使用更加轻量化的模型等手段,加快程序运转速度,使程序更加灵敏,为使用者带来更加灵活、高效的环境信息监测体验,让使用者能够更快速的了解周围环境。
六、参考文献
- 阮骁扬, 宋方舟. 一种基于 Arm技术的智能盲人出行辅助设备[J]. 电子技术与软件工程, 2016 (18): 138-138.
- MMEdu基本功能 — OpenXLabEdu 文档.
- 解锁图像分类模块:MMClassification — OpenXLabEdu 文档.
- 揭秘目标检测模块:MMDetection — OpenXLabEdu 文档.
- 单目深度估计方法综述 - 知乎.
- Intel/dpt-hybrid-midas · Hugging Face.
- https://github.com/open-mmlab/mmdetection/tree/main/configs/ssd.