PixelSNAIL论文代码学习(1)——总体框架和平移实现因果卷积
文章目录
-
- 引言
- 正文
-
- 目录解析
- README.md阅读
-
- Setup配置
- Training the model训练模型
- Pretrained Model Check Point预训练的模型
- 训练方法
- train.py文件的阅读
- model.py文件阅读
-
- h12_noup_smallkey_spec模型定义
- _base_noup_smallkey_spec模型实现
- 一、定义因果卷积过程
-
- 通过平移实现因果卷积的原理讲解
-
- 一维向量实现因果卷积
- 二维矩阵实现因果卷积
- 平移实现因果卷积
- nn.down_shifted_conv2d下卷积
-
- 填充实现
- 权重归一化二维卷积实现
-
- 自定义实现权重归一化卷积层
- 使用pytorch自带的权重归一化修饰器
- nn.down_right_shifted_conv2d:右下移卷积
- nn.down_shift:下移
- nn.right_shift:右移
- 二、门控残差网络
- 三、因果自注意力机制实现
- 四、使用pytorch实现
- 总结
引言
- 阅读了PixelSNAIL的相关论文,具体链接如下,论文学习链接
- 这篇文章是一个自回归神经网络,将自注意力机制和因果卷积进行结合,我们在PixelCNN中学习过因果卷积的具体实现,并且结合了相关代码进行阅读,这里给出链接:
- PixelCNN的论文和代码学习连接
- PixelSNAIL的效果是远比PixelCNN的效果好的,而且,这里并不知道如何实现自注意力机制,所以需要好学习一下他的代码。
- 很烦,之前弄得深度学习环境因为系统快照的问题,需要重新安装,所以在做这个代码分析之前,还是得重新安装对应的tensorflow深度学习环境。
- 对应github项目的连接
正文
目录解析
- data
- cifar10_data.py 下载并加载相关的数据集
- cifar10_plotdata.py 绘制对应的图片
- imagenet_data.py 下载并加载相关的数据集
- pixel_cnn_pp
- linearize.py 优化tensorflow计算图的执行顺序
- model.py 模型定义函数
- nn.py 实现pixelCNN ++模型的实用函数和层,包括了自定义的损失函数
- plotting.py 绘制训练图
- train.py 训练以及测试文件
README.md阅读
Setup配置
- 需要运行这个代码,需要具有如下的内容
- 具有多个GPU的机器
- python3以上的编译器
- Numpy,TensorFlow
Training the model训练模型
- 使用train.py脚本去训练模型
Pretrained Model Check Point预训练的模型
- 直接在对应的连接上进行下载
- CIFAR10 model
- ImageNet model
训练方法
- CIFAR-10的训练脚本
python train.py \
--data_set=cifar \
--model=h12_noup_smallkey \
--nr_logistic_mix=10 \
--nr_filters=256 \
--batch_size=8 \
--init_batch_size=8 \
--dropout_p=0.5 \
--polyak_decay=0.9995 \
--save_interval=10
- ImageNet的训练脚本
python train.py \
--data_set=imagenet \
--model=h12_noup_smallkey \
--nr_logistic_mix=32 \
--nr_filters=256 \
--batch_size=8 \
--init_batch_size=8 \
--learning_rate=0.001 \
--dropout_p=0.0 \
--polyak_decay=0.9997 \
--save_interval=1
train.py文件的阅读
-
这个代码写的真的不敢苟同,所有的处理逻辑都放在一个train.p中,看起来很混乱。他的代码是tensorflow的,而且是1.0系列的代码,可读性并不是那么好,所以这里就不 投入太多关注了,仅仅阅读模型的生成部分。
-
调用并生成模型的代码
- 这里是调用了一个模型模板,传入了model文件,然后具体的模型名称是在训练脚本中指名的,是参数"model=h12_noup_smallkey"这个键值对
# 创建模型
model_opt = {'nr_resnet': args.nr_resnet, 'nr_filters': args.nr_filters,
'nr_logistic_mix': args.nr_logistic_mix, 'resnet_nonlinearity': args.resnet_nonlinearity}
# 生成一个模型模板,模型可以多次重复使用,不需要重复创建变量
model = tf.make_template('model', getattr(pxpp_models, args.model + "_spec"))
# 用于依赖于数据的参数初始化
with tf.device('/gpu:0'):
gen_par = model(x_init, h_init, init=True,
dropout_p=args.dropout_p, **model_opt)
- 综上所述,所以具体使用的模型是"h12_noup_smallkey_spec"
model.py文件阅读
- 鉴于上一个文件,这里直接从h12_noup_smallkey_spec这个函数开始看。
h12_noup_smallkey_spec模型定义
- 定义h12_noup_smallkey_spec的代码:
- functools.partial:用于固定某个函数的一些参数,然后生成一个新的函数
- 实现:创建了一个h12_noup_smalleky_spec的函数,这个函数的逻辑和_base_noup_smallkey_spc的逻辑一样,但是参数attn_rep是固定的12
h12_noup_smallkey_spec = functools.partial(_base_noup_smallkey_spec, attn_rep=12)
h12_pool2_smallkey_spec = functools.partial(_base_noup_smallkey_spec, attn_rep=12, att_downsample=2)
h8_noup_smallkey_spec = functools.partial(_base_noup_smallkey_spec, attn_rep=8)
- 所以,下一步,是仔细看_base_noup_smallkey_spec的具体实现逻辑。
_base_noup_smallkey_spec模型实现
-
参照论文,我们看一下整个模型基本的定义图,具体如下,主要是两个模块,分别是
- 门控残差网络的实现(左下角蓝色的模块)
- 自注意力机制的实现(右下角蓝色的模块)
-
具体执行逻辑如下图
- 将图片进行2*2的因果卷积得到A
- 重复执行一下模块M次
- 将A重复执行4次门控残差模块得到B,两步执行
- 步骤一:对B执行1*卷积,得到C
- 步骤二:对B执行因果注意力模块,得到D
- 将C和D进行拼接,程序例又执行了一次因果卷积,得到E,将E保存起来
- 然后最终进行输出
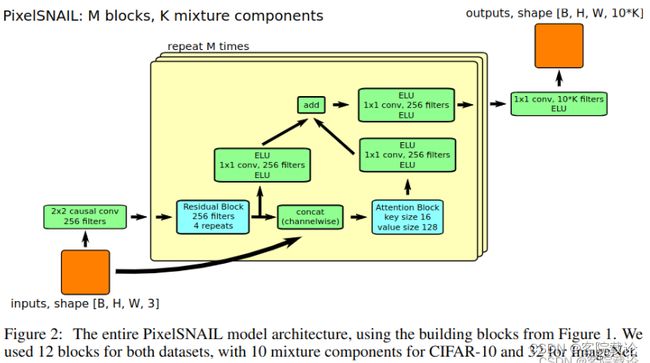
- 将A重复执行4次门控残差模块得到B,两步执行
-
下述为原程序代码
def h6_shift_spec(x, h=None, init=False, ema=None, dropout_p=0.5, nr_resnet=5, nr_filters=160, nr_logistic_mix=10, resnet_nonlinearity='concat_elu'):
"""
We receive a Tensor x of shape (N,H,W,D1) (e.g. (12,32,32,3)) and produce
a Tensor x_out of shape (N,H,W,D2) (e.g. (12,32,32,100)), where each fiber
of the x_out tensor describes the predictive distribution for the RGB at
that position.
'h' is an optional N x K matrix of values to condition our generative model on
"""
counters = {}
with arg_scope([nn.conv2d, nn.deconv2d, nn.gated_resnet, nn.dense, nn.nin, nn.mem_saving_causal_shift_nin], counters=counters, init=init, ema=ema, dropout_p=dropout_p):
# parse resnet nonlinearity argument
if resnet_nonlinearity == 'concat_elu':
resnet_nonlinearity = nn.concat_elu
elif resnet_nonlinearity == 'elu':
resnet_nonlinearity = tf.nn.elu
elif resnet_nonlinearity == 'relu':
resnet_nonlinearity = tf.nn.relu
else:
raise('resnet nonlinearity ' +
resnet_nonlinearity + ' is not supported')
with arg_scope([nn.gated_resnet], nonlinearity=resnet_nonlinearity, h=h):
# // up pass through pixelCNN
xs = nn.int_shape(x)
background = tf.concat(
[
((tf.range(xs[1], dtype=tf.float32) - xs[1] / 2) / xs[1])[None, :, None, None] + 0. * x,
((tf.range(xs[2], dtype=tf.float32) - xs[2] / 2) / xs[2])[None, None, :, None] + 0. * x,
],
axis=3
)
# add channel of ones to distinguish image from padding later on
x_pad = tf.concat([x, tf.ones(xs[:-1] + [1])], 3)
ul_list = [nn.causal_shift_nin(x_pad, nr_filters)] # stream for up and to the left
for attn_rep in range(6):
for rep in range(nr_resnet):
ul_list.append(nn.gated_resnet(
ul_list[-1], conv=nn.mem_saving_causal_shift_nin))
ul = ul_list[-1]
hiers = [1, ]
hier = hiers[attn_rep % len(hiers)]
raw_content = tf.concat([x, ul, background], axis=3)
key, mixin = tf.split(nn.nin(nn.gated_resnet(raw_content, conv=nn.nin), nr_filters * 2 // 2), 2, axis=3)
raw_q = tf.concat([ul, background], axis=3)
if hier != 1:
raw_q = raw_q[:, ::hier, ::hier, :]
query = nn.nin(nn.gated_resnet(raw_q, conv=nn.nin), nr_filters // 2)
if hier != 1:
key = tf.nn.pool(key, [hier, hier], "AVG", "SAME", strides=[hier, hier])
mixin = tf.nn.pool(mixin, [hier, hier], "AVG", "SAME", strides=[hier, hier])
mixed = nn.causal_attention(key, mixin, query, causal_unit=1 if hier == 1 else xs[2] // hier)
if hier != 1:
mixed = tf.depth_to_space(tf.tile(mixed, [1, 1, 1, hier * hier]), hier)
ul_list.append(nn.gated_resnet(ul, mixed, conv=nn.nin))
x_out = nn.nin(tf.nn.elu(ul_list[-1]), 10 * nr_logistic_mix)
return x_out
-
函数参数说明
- x:输入张量,形状为(N,H,W,D1),N为batch_size,H,W为图像的高和宽,D1为图像的通道数
- h:可选的N x K矩阵,用于在生成模型上进行条件,默认是不使用的。
- init:是否初始化,默认不进行初始化
- ema:是否使用指数移动平均,默认不进行指数平均
- dropout_p:dropout概率,默认为0.5
- nr_resnet:残差网络的数量,默认为5
- nr_filters:卷积核的数量,默认为256
- attn_rep:注意力机制的重复次数,默认重复12次
- nr_logistic_mix:logistic混合的数量,默认混合采样10次
- att_downsample:注意力机制的下采样,默认下采样一次
- resnet_nonlinearity:残差网络的非线性激活函数,默认使用“concat_elu”
-
下述将根据代码和流程图,列出因果卷积、门控残差网络和因果注意力模块的具体实现
一、定义因果卷积过程
-
这里因果卷积的定义方式和PixelCNN不一样,他是定义掩码,这里是定义了四种不同的卷积方式来实现因果卷积的,分别是,这个过程复杂的很。
- nn.down_shifted_conv2d:下移卷积:
- nn.down_right_shifted_conv2d:右下移卷积
- nn.down_shift:下移
- nn.right_shift:右移
-
在二维因果卷积过程中,要确保每一个输出像素仅受其左侧和上方元素的影响,通常经过一下几种方式实现
- 零填充:卷积之前,将输入矩阵的周围填充零,卷积操作从图像边缘开始,不会看到未来消息。
- 平移:在卷积之后,输出矩阵通常会沿着某个方向进行平移,确保因果性。这个平移是需要将原来移空的位置设置为0.
-
在作者的代码通过了两个方法来确保每一个像素点只能获得上面和左边的信息。
- 对矩阵的上面进行padding,然后再将,矩阵下移,来确保每一个元素只能获得上边的元素信息
- 对矩阵的左面进行padding,然后再将矩阵右移,来确保每一个元素只能获得左边的元素信息
-
通过上述两个方法的结合,确保元素只能获得左上部的未来信息。
通过平移实现因果卷积的原理讲解
一维向量实现因果卷积
-
一维输入序列 x = [ x 0 , x 1 , . . . , x n − 1 ] x = [x_0,x_1,...,x_{n-1}] x=[x0,x1,...,xn−1]
-
一维卷积核 h = [ h 0 , h 1 , . . . . , h m − 1 ] h = [h _0,h_1,....,h_{m-1}] h=[h0,h1,....,hm−1]
-
因果卷积的输出 y y y定义如下, y t = ∑ i = 0 m − 1 h i x t − i t > = i y_t = \sum_{i = 0}^{m-1} h_i x_{t-i} \ \ \ \ \ \ \ \ \ \ \ \ \ t >= i yt=i=0∑m−1hixt−i t>=i
-
具体样例如下
- 一维输入序列 x = [ x 0 , x 1 , x 2 , x 3 , x 4 ] x = [x_0,x_1,x_2,x_3,x_4] x=[x0,x1,x2,x3,x4]
- 一维卷积核 h = [ h 2 , h 1 , h 1 ] h = [h _2,h_1,h_1] h=[h2,h1,h1]
- 这个在卷积过程中,完全是按他的公式进行卷积的

二维矩阵实现因果卷积
- 二维卷积:因果性意味着输出矩阵中每一个元素只能依赖于其上方和左方的输入元素,通过pading和平移实现。

- 就是通过填充和平移来实现。
平移实现因果卷积
nn.down_shifted_conv2d下卷积
- 这里使用了自定义的Conv2d卷积,还有填充模式,这里逐个进行分析
填充实现
def down_shifted_conv2d(x, num_filters, filter_size=[2, 3], stride=[1, 1], **kwargs):
# 这里是对数据进行填充,总共有四个维度,分别是N,H,W,C
# 第一个维度不进行填充,他是batch_size
# 第二个维度H进行填充,开始的地方填充的大小是filter_size[0] - 1,结束的地方填充的大小是0,也就是仅仅扩充上部分
# 第三个宽度是W进行填充,开始的地方填充的大小是int((filter_size[1] - 1) / 2),结束的地方填充的大小是int((filter_size[1] - 1) / 2),也就是仅仅扩充左右两边
# 第四个维度不进行填充,他是channel
x = tf.pad(x, [[0, 0], [filter_size[0] - 1, 0], [int((filter_size[1] - 1) / 2), int((filter_size[1] - 1) / 2)], [0, 0]])
#
return conv2d(x, num_filters, filter_size=filter_size, pad='VALID', stride=stride, **kwargs)
- 假设原始输入的矩阵是68的,卷积核的大小是34,原矩阵、填充之后的矩阵和卷积之后的单个矩阵,效果如下
- 原矩阵,6*8

- 填充之后的矩阵8*10
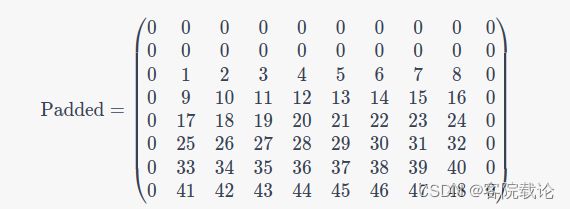
- 卷积之后的矩阵6*7

- 原矩阵,6*8
- 这里对于生成的序列在于需要将生成之后的矩阵和原来的矩阵进行对齐,然后按照位置进行比对的,这里有个样例将很好。具体截图如下。
- 上面一行是卷积之后的输出,下面一行是原始的数据集
- 左图是正确的,timeB的时间序列仅仅获取timeA和timeB的序列,但是右图就获取了timeC未来序列的数据,所以左图是符合因果卷积的效果的。

权重归一化二维卷积实现
-
这里作者自己定义了一个带有权重归一化的二维卷积层,因为正常卷积并不包含权重归一化的效果。
-
带权重归一化的二维卷积层的优势:
- 训练稳定:权重归一化之后,模型的训练更加稳定
- 快速收敛:权重归一化能够加速模型收敛
- 改进泛化:在特定的任务中,权重归一化有注意模型泛化
-
正常二维卷积的优势:
- 效率更高、操作简单、广泛应用
-
缩放因子 g g g和偏置权重 b b b的作用:
- 缩放因子 g g g:
-
使用广播机制,将放缩因子与权重矩阵中的每一个数字按位相乘 S c a l e d W e i g h t = g × N o r m a l i z e d W e i g h t Scaled \ Weight = g \times Normalized \ Weight Scaled Weight=g×Normalized Weight
-
主要是权重归一化之后,所有权重的范围 都是单位范围内,加上缩放因子能够适应更多范数。
-
注意,权重归一化,是在输出通道上进行操作的
-
- 偏置权重 b b b
- 是在卷积结果之后,加上偏置,让模型输出一个非零的值
- 具体公式如下 O u t p u t = C o n v 2 D ( x , S c a l e d W e i g h t ) + b Output = Conv2D(x,Scaled \ Weight) + b Output=Conv2D(x,Scaled Weight)+b
- 缩放因子 g g g:
-
这里我进行了两种实现方法,一种是通过pytorch自定义权重归一化卷积层,还有一种是通过pytorch内置的权重归一化装饰器实现类似的功能。
自定义实现权重归一化卷积层
- 这里需要继承nn.Moudle模块,自己定义forward模块实现相关功能
- 需要实现的基本步骤:
- 基本的init初始化函数
- forward前向传播函数自定义
- 计算缩放因子和偏置初值的函数,具体计算公式如下

# 权重归一化卷积层
class WeightNormConv2d(nn.Module):
def __init__(self, in_channels, out_channels,
kernel_size, stride=1, padding=0,
nonlinearity=None, init_scale=1.):
super(WeightNormConv2d, self).__init__()
# 指定非线性激活函数
self.nonlinearity = nonlinearity
self.init_scale = init_scale
# 定义卷积层
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
# 定义缩放因子g和偏置b
# 将g和b声明为需要优化的参数,卷积层默认的权重是(C-out,C-in,H,W)这四个维度
self.g = nn.Parameter(torch.ones(out_channels, 1, 1, 1))
self.b = nn.Parameter(torch.zeros(out_channels))
# 声明初始化参数
self.reset_parameters()
# 数据依赖的参数初始化
def reset_parameters(self):
# 初始化权重为正太分布
init.normal_(self.conv.weight, mean=0, std=0.05)
# 初始化偏置为0
init.zeros_(self.conv.bias)
# 使用一次随机输入,进行一次前向传播,以计算初始的g和b
with torch.no_grad():
x_init = F.conv2d(torch.randn(1, *self.conv.weight.shape[1:]),
self.conv.weight)
m_init, v_init = x_init.mean(), x_init.var()
# 计算缩放因子
scale_init = self.init_scale / torch.sqrt(v_init + 1e-8)
self.g.data.fill_(scale_init)
# 计算偏置
# 将张量所有的元素都设定为特定的元素
# data属性仅仅是修改对应的值,但是不会计入梯度的改变
self.b.data.fill_(-m_init * scale_init)
def forward(self, x):
# 应用权重归一化
W = self.conv.weight * (self.g / torch.sqrt((self.conv.weight ** 2).sum([1, 2, 3], keepdim=True)))
# 执行卷积操作
x = F.conv2d(x, W, self.b, self.conv.stride, self.conv.padding)
# 应用非线性激活
if self.nonlinearity is not None:
x = self.nonlinearity(x)
return x
# 测试函数
conv_layer = WeightNormConv2d(3, 16, [3, 3], stride=1, nonlinearity=F.relu)
x = torch.randn(8, 3, 64, 64) # NCHW格式
out = conv_layer(x)
print(out.shape)
使用pytorch自带的权重归一化修饰器
- 直接调用nn.utils中的weight.norm组件,包括原来的卷积层即可,具体如下
# 使用pytorch自定义的权重归一化层
import torch
from torch import nn
from torch.nn.utils import weight_norm
# 创建一个标准的 Conv2d 层
conv_layer = nn.Conv2d(3, 16, 3, 1)
# 应用权重归一化
conv_layer = weight_norm(conv_layer)
# 测试该层
x = torch.randn(8, 3, 64, 64) # 输入张量,形状为 [batch_size, channels, height, width]
out = conv_layer(x)
print(out.shape) # 输出张量的形状应为 [8, 16, 62, 62]
nn.down_right_shifted_conv2d:右下移卷积
- 这个和上一个方式基本上都是相同的,只不过对于W和这个维度而言,仅仅是填充了左边,并没有填充右边。就是在原来的代码上进行修改,同时填充的数量也不一样。具体不再讲解
@add_arg_scope
def down_right_shifted_conv2d(x, num_filters, filter_size=[2, 2], stride=[1, 1], **kwargs):
x = tf.pad(x, [[0, 0], [filter_size[0] - 1, 0],
[filter_size[1] - 1, 0], [0, 0]])
return conv2d(x, num_filters, filter_size=filter_size, pad='VALID', stride=stride, **kwargs)
nn.down_shift:下移
- 使用原始数据的一部分用零来替代,确保最终生成的数据是。将原始的张量往下移动n行,然后前n行全部替换成0

nn.right_shift:右移
- 具体实现和上面相同,仅仅是在矩阵的作伴部分进行添加,然后返回最终的矩阵
def right_shift(x, step=1):
xs = int_shape(x)
return tf.cobncat([tf.zeros([xs[0], xs[1], step, xs[3]]), x[:, :, :xs[2] - step, :]], 2)
二、门控残差网络
- 由于篇幅有限,这里具体看这篇文章和博客
- 门控残差网络的具体实现
三、因果自注意力机制实现
- 看对应文章的链接
- 因果自注意力机制实现
四、使用pytorch实现
- 之前每一个章节都有pytorch实现的版本,这里将对所有的内容进行汇总,使用pytorch对pixelSNAIL模型进行重构,具体代码如下
# 实现最终的模型
class PixelSNAIL(nn.Module):
'''
pixelSNAIL模型
'''
def __init__(self,nr_resnet=5, nr_filters=32, attn_rep=12, nr_logistic_mix=10, att_downsample=1):
super(PixelSNAIL,self).__init__()
# 声明类成员
self.nr_resnet = nr_resnet
self.nr_filters = nr_filters
self.attn_rep = attn_rep
self.nr_logistic_mix = nr_logistic_mix
self.att_downsample = att_downsample
# 声明定义模型对象
# 声明因果卷积的网络
self.down_shifted_conv2d = weight_norm(nn.Conv2d(3, self.nr_filters, kernel_size=(1, 3)))
self.down_right_shifted_conv2d = weight_norm(nn.Conv2d(3, self.nr_filters, kernel_size=(2, 1)))
# 声明包含若干门控残差网络的modulelist
self.gated_resnets = nn.ModuleList([GatedResNet(self.nr_filters) for _ in range(self.nr_resnet)])
# 声明线性模型
self.nin1 = nn.Linear(self.nr_filters, self.nr_filters // 2 + 16) # 假设q_size = 16
self.nin2 = nn.Linear(self.nr_filters, 16) # 假设q_size = 16
# 声明因果注意力模块
self.causal_attentions = nn.ModuleList([CausalAttention() for _ in range(self.attn_rep)])
# 最终的卷积网络
self.final_conv = nn.Conv2d(self.nr_filters, 10 * self.nr_logistic_mix, kernel_size=1)
def forward(self, x):
ul_list = []
# 加上一个是四个
# 按照左右上下的方式进行填充
down_shifted = F.pad(x, (1, 1, 0, 0)) # 自定义下移和右移操作
right_shifted = F.pad(x, (0, 0, 1, 0))
# 因果卷积
ds_conv = self.down_shifted_conv2d(down_shifted)
drs_conv = self.down_right_shifted_conv2d(right_shifted)
ul = ds_conv + drs_conv
ul_list.append(ul)
# 下采样,从右下角开始
for causal_attention in self.causal_attentions:
for gated_resnet in self.gated_resnets:
ul = gated_resnet(ul)
ul_list.append(ul)
print('attention module')
# 注意力机制
last_ul = ul_list[-1]
# 准备原始内容
raw_content = torch.cat([x, last_ul], dim=1) # 假设背景信息已经添加到x中
# 生成key和value
print(raw_content.shape)
raw = self.nin1(raw_content)
print('raw data shape',raw.shape)
key, mixin = raw.split(18, dim=1) # 假设q_size = 16
# 生成query查询键
raw_q = last_ul
query = self.nin2(raw_q)
# 计算注意力
print(mixin.shape)
print(query.shape)
mixed = causal_attention(key, mixin, query)
ul_list.append(mixed)
x_out = F.elu(ul_list[-1])
x_out = self.final_conv(x_out)
return x_out
x = torch.randn(64,3,32,32)
model = PixelSNAIL()
x_out = model(x)
print(x_out.shape)
- 这个代码多多少少有一点问题, 但是我并不想在投入时间了,因为我感觉我已经滞后了很多,有点慌张,这个模型完整的都已经知道了,具体的实现细节。pytorch的大概实现逻辑也给了,后续有空了,可以继续调整。
总结
- 激活函数,可以试一下concat_elu,能够识别更加复杂的特征。
- 这个PixelSNAIL用了差不多一周看完,虽然没有跑起来,没有调试,但是大部分代码自己都进行了重构,学到了很多。
- 以后在处理序列数据,可以使用因果注意力机制,而不仅仅是使用因果卷积。除此之外,对于query、key和value的生成理解还有一些问题,总是觉得怪怪的,门控残差进行卷积一定次数之后,设定特定的filter_num,直接输出,直接进行拆分,就可以获得key和value,然后在点乘,我想知道这个操作是怎么想出来的。
- 我想将我所有的代码都放到我的github上,现在还缺数据加载和最终生成模型的评价指标,下一步还是回归我们的那个基础的模型,然后将之模块化,主要是为了适应以后的模块替换。