炸裂——关于Azure OpenAI的几个更新
感觉好久没有写随笔了,虽然从年初至今,一直被持续不断涌现的新 AI 消息震惊,也一直不断组织和参与各种 AI 相关的活动、直播,但确实挺久没有写文字了。今天是下半年的第一天,也是暑假的第一天,忙完家务,晚上正好趁着最近几个更新写几笔。
从 GPT-3 惊艳世界开始,到 Azure OpenAI 的发布,到 GPT-4…这段时间真的是——根本停不下来。首先容我得瑟一下,我应该算是第一批用上 AOAI 的、特别是 GPT-4 模型 AOAI 的人了。这需要感谢 Microsoft MVP 计划,以及 Azure 和 AI 奖励方向之下 PG 对我们的支持。正如大家知道的,OpenAI 在我生日那天(算上时差哈哈),发布了新的模型版本 0613,同时也提供了新的使用 GPT 的方式——Function calling。
得知这一消息后我第一时间就联系了 PG,他们反馈说月底这个模型版本就会部署到 AOAI 上,function calling 则还需要等一阵子。可惜限于 NDA 的约束,我不能公开这个好消息。今天,我终于把自己 AOAI 的模型部署升级到了 0613 版本。
Azure OpenAI Studio
先看看 AOAI 的工作室有些什么更新。
升级部署模型
有了 0613 版本,当然是要升级了。升级模型版本并不需要删除现有模型,也不需要部署一个新的,只需要“编辑部署”,然后在模型版本处,选择需要的模型版本就行。

当然,如果想省事情,直接选择自动更新也行。AOAI将会自动把模型更新到新版本。

上图可以看到,我把 GPT-3.5-turbo 和 GPT-4/32K 的几个模型都升级到最新的 0613 了。一会试试有什么不同。
调整内容过滤
细心的你可能发现了,在 Content Filter 这一列,有几个模型没有使用默认的值,取而代之的是一个另外的内容过滤器。内容过滤是 AOAI 使用多模态大语言模型模型的重要组成部分,负责对用户输入的提示,以及模型的输出内容进行筛选过滤,避免出现诸如仇恨、色情、自残和暴力等内容。
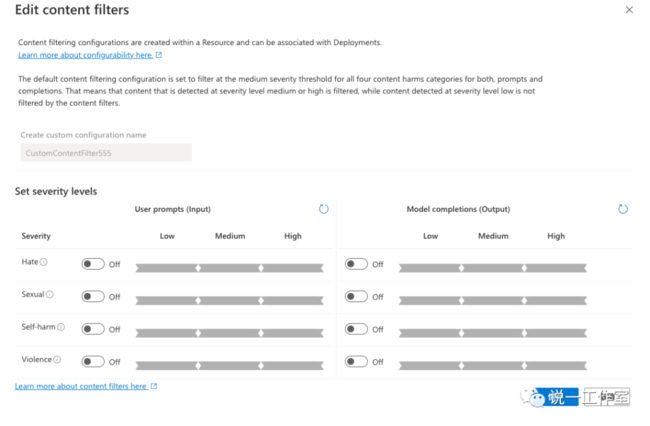
默认内容过滤是开启的,且不能被关闭。默认设置为低,可以改成中或高。内容过滤有效的避免了不适当的内容进入到人和模型的交互,对于运行在 Azure 的 OpenAI 模型,触发内容过滤还会导致微软的人工审核。但对于一些研究场景来说,可能需要观察未开启内容过滤的提示过程,或者设置调试自己的内容过滤流程或模型。因此微软也提供了自定义内容过滤的选项,前提是填表申请,通过之后就可以像上图一样,进行自定义设置了。
使用自己的数据
全称应该是“在 GPT 的 Chat Playground 通过认知搜索使用自己的数据”这么长吧……
这个功能在 Build 以及之前的 PGI 会议看到过。最早结合认知搜索的 GPT 使用示例其实是通过 Azure 模板等手动部署的,使用了很多 Python 代码和其他。所以一看到 AOAI Studio 里面可以直接配置,还是挺兴奋的,当时也是问 PG 什么时候可以使用——很快。于是现在我们就看到了~

我看了一下,不论是直接使用 Azure 认知搜索,或让认知搜索使用 Azure Blob 存储,还是上传文件到 Blob 存储再使用认知搜索(这不是差不多一码事么…)都离不开使用认知搜索服务。

直接使用配置好的 Azure 认知搜索,只要指定认知搜索服务实例,并指定索引。

选择使用 Azure Blob 存储的话,就需要指定已有 Blob 存储的实例和容器,然后连接到认知搜索实例上,指定索引。

如果选择上传文件,其实也是指定 Blob 存储实例。可以自动配置好 CORS 设置,然后连接到认知搜索实例,指定索引。
这几种方式,都需要使用非免费定价层的认知搜索(注意图中黄色提示)。所以我暂时都没创建。等开个非免费定价层的实例运行,再另外写一点吧。
直接发布WebApp
在我拿到 AOAI 的预览不久,我就很想把这个 GPT 模型做成一个 Web 应用,这样其他人就可以通过浏览器,而不需要通过访问 AOAI 工作室来使用 GPT 了。为了实现这个目的,我还特意用 Python 写了点代码放在 Hugging Face 上,通过 API 调用来实现。
( https://huggingface.co/spaces/haohoo/Azure-OpenAI-QuickDemo )
如今,做这件事就太简单了~

在 Azure OpenAI Studio 里,进入聊天的 Play Ground,在右上角可以看到多了一个 Deploy to 的按钮,通过它就可以直接将当前的 Playground 部署到 Web App。

整个部署过程都是自动的,需要说明的是,部署的 WebApp 会使用 Azure AD 作为用户验证方式。想让其他人来访问你的 Chat App,可以在 AAD 的控制台里添加用户和 B2B/B2C 账户。

看,不用写一行代码,你专用的 ChatGPT 站点就有了~整个具体的过程,到时候和使用自己的数据一起再开一篇吧。
Azure ML Studio
再看看机器学习工作室有啥更新吧。
我告诉你 Build 上被惊艳了之后,我就通过 PG 整了整“船新”的 ML Studio,可惜 NDA 不能说,只在 Build After Party 上偷偷秀了一下,可憋坏我了。现在终于发布 PuPr,也就是 Public Preview 了,那么就可以放开聊聊了。
模型目录
如以往的活动和文章介绍,机器学习工作室是学习使用机器学习的一站式工作环境。对于不同要求和基础的用户,提供记事本、脱拽式机器学习管道线设计器和自动化机器学习。现在,机器学习工作室又新增了模型目录功能。

如图所示,在新推出的模型目录中,除了由 Azure ML 提供的可用模型,也将很多开源社区 Hugging Face 的模型放进了模型目录。可以按照模型分类和许可类型筛选模型,也可以在搜索框里使用关键字查找模型。如果模型未出现在目录中,可以点击右上角“建议模型”建议微软将模型放入目录。
点击目录中的模型,会显示简介以及模型发布的链接,例如 Hugging Face 目录中的可以链接到模型卡。如果已经有示例部署,可以直接进行模型的尝试。模型的一些示例和性能参考也会提供,甚至有示例的记事本直接运行。如果觉得合适就可以直接部署,和以往机器学习工作室部署模型一样,部署模型可选实时终结点和批处理终结点。

而实际在 Hugging Face 站点上,也可以将 Azure ML 支持的(已经引入的)模型直接部署到 Azure ML 服务。

可以通过 AzureML Studio 按钮打开机器学习工作室、Python 代码或使用 YAML描述的 CLI Shell 进行部署。

Python 或 Shell 自动部署时,需要提供 Azure 订阅、资源组名称、ML 工作空间名称等信息。以 Python 为例:
import time
# follow steps here to connect to workspace: https://aka.ms/AzureML-WorkspaceHandlePython
ml_client = MLClient(
credential=DefaultAzureCredential(),
subscription_id="",
resource_group_name="",
workspace_name="",
)
# fetch model
registry_ml_client = MLClient(
credential=DefaultAzureCredential(), registry_name="HuggingFace"
)
foundation_model = registry_ml_client.models.get(
"", version=""
)
# create endpoint
endpoint_name = "hf-ep-" + str(
int(time.time())
) # endpoint name must be unique per Azure region, hence appending timestamp
ml_client.begin_create_or_update(ManagedOnlineEndpoint(name=endpoint_name)).wait()
# create deployment
ml_client.online_deployments.begin_create_or_update(
ManagedOnlineDeployment(
name="demo",
endpoint_name=endpoint_name,
model=foundation_model.id,
instance_type="Standard_DS2_v2",
instance_count=1,
)
).wait()
endpoint.traffic = {"demo": 100}
ml_client.begin_create_or_update(endpoint_name).result()
# go to Endpoints hub in AzureML Studio to get the endpoint URL and test your endpoint 提示流
更新的 Azure ML Studio 提供了提示流的预览。何谓提示流呢?如果你已经是 Azure 机器学习工作室的老司机,你肯定知道在设计器里,通过拖拽就能建立起机器学习的管道线。提示流就是将我们说的提示工程,使用这种可视化管道线的方式进行设计,然后运行起来。

光说肯定难理解,不如就看看提供的示例吧。下图是一个跟 Wikipedia 在线百科全书站点聊天的提示流示例。首先设置一个输入模块,提供会话历史和提出的问题。由于使用的 GPT 模型的 Chat 方式,会话历史和我们使用 API 调用 一样,需要 List。然后设置一个输出模块,用于显示 GPT 模型的输出。

在输入和输出之间,还有几个模块处理整个提示流。
首先是“从问题中解析查询”,通过 GPT 的完成方式,从自然语言的问题中,解析出需要查询的关键字。在示例里,使用了单样本提示,将传入的会话历史作为参考,将输入的提问作为人类输入,将 GPT 完成的输出作为 AI 的输出。
接下来是“获取搜索的URL”,使用 Wiki 自己的查询,将上一模块输出的查询关键字构造为 Wiki 的查询 URL,并且获取查询给出的 URL。
再下来是“URL的搜索结果”,通过前一步骤获得的 URL 访问 Wiki,并将内容转化为文本输出。
如果你也使用过 new Bing 的 chat 功能,估计看过对话回复中会提供引用内容的链接。所以在接下来的模块里,需要“处理搜索结果”,将前一步骤获得的内容加上引用的 URL。
内容有了,现在可以让 GPT 来聊天了。在这一模块里,使用 GPT 模型的 Chat 方式,对 system 角色进行定义,规范 GPT 的输出方式,然后引用前一模块的内容输出以及会话历史,构成完整的上下文。user 角色会添加输入模块的问题, assistant 角色会添加输出的答案。调用 GPT 的 Chat 方法,就能够输出关于查询 Wiki 之后,以自然语言表述对话的结果了。
这样的提示流基本上不用写代码,或只需要简单修改代码,即可完成一些常见的 ChatGPT 的要求,逻辑上说我们也可以基于这样的示例,做一个和 new Bing 差不多的聊天应用。可以看到,提示流的设计方式大大地降低了定制使用 GPT 的复杂度。
一篇随笔里放了不少惊艳的更新,可惜篇幅有限。后续看看把这些更新再单独做一些更详细的介绍吧~ 顺手把下面几个图标都点一下吧,哈哈哈多谢啦~