SQL 语句学习总结:
1. 四范式&&范式好处:
数据库范式是数据表设计的规范,在范式规范下,数据库里每个表存储的重复数据降到最少(这有助于数据的一致性维护),同时在数据库范式下,表和表之间不再有很强的数据耦合,可以独立的增长 (ie. 比如汽车引擎的增长和汽车的增长是完全独立的). 范式带来了很多好处,
1. 基本结构:

1. distinct 关键字:
select distinct col1, col2, col3 from table1 ;
要求distinct 只能放在列名的前面,且会修饰每一个语句中涉及的列,即,会要求 col1,col2,col3都是唯一的
2. limit offset 关键字:
可以不指定offset从哪里截取,默认从结果返回出截取,只指定截取多少个的limit值
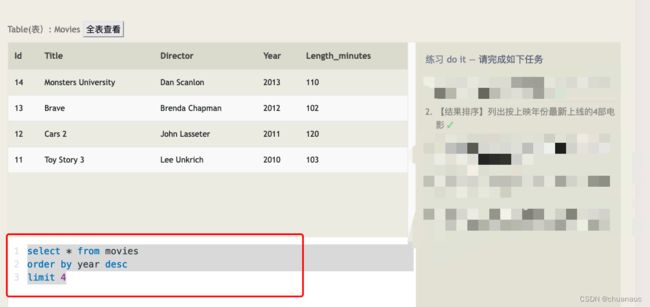
limit 和 offset 搭配 :获得 第x个内容:
如果按片长排列,John Lasseter导演导过片长第3长的电影是哪部,列出名字即可 :
select title from movies
where director='John Lasseter'
order by Length_minutes desc
limit 1 offset 23. order by :
字符串也是有序的,按照升序排列
4. 字符串的模糊匹配使用的是 like :
select * from movies
where title like 'arch%' 5. 在输出时不想要空值:


select distinct building from employees
where building != 'NULL'5. 连表查询:
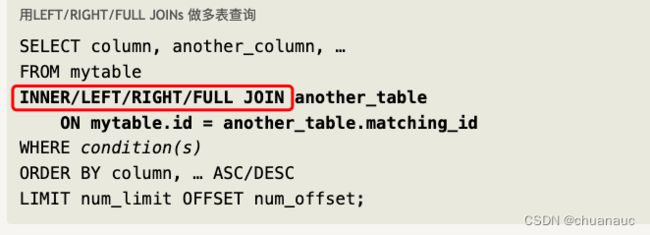
inner join :交集

想获得两个表中所有项 可以直接 : select * from XXX inner join YYY ON XXX.id = YYY.id
因为连表操作就是先会把所有列拼接在一起,并且对应的项如果不指定不会去除:

由于是left join 那么:会满足以下几个原则:(left join 是以主表为主)
【下图 未命名3 是主表;未命名2 是从表 ; 未命名是 返回结果】
(1)作为主表的内容即使与其他表不相匹配,也会把主表的内容留下来,不匹配的内容值值为NULL
(2)对于从表可以匹配的就按照要求匹配,匹配不上的就不会被返回了,如从表画×部分

6. 在查询中使用表达式并定义变量,在同一个语句中使用这个变量 【使用 as 关键字】
题目 :John Lasseter导演的每部电影每分钟值多少钱,告诉我最高的3个电影名和价值就可以
==》定义 val 变量,并在排序的时候直接使用
select title,(Domestic_sales+International_sales)/Length_minutes as val
from movies
inner join boxoffice
on id = movie_id
where director = 'John Lasseter'
order by val desc
limit 38. 统计函数 :
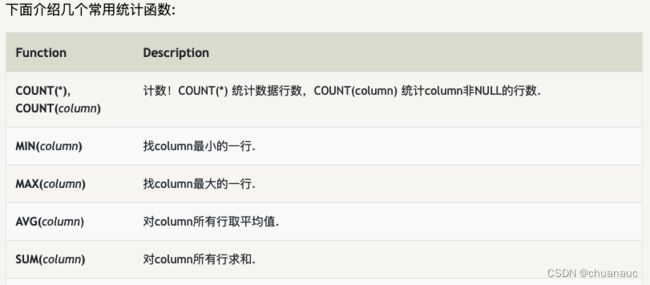
9. 聚合函数(avg sum max min)的一些使用要求:
因为聚合函数通过作用于一组数据而只返回一个单个值:
因此,在SELECT语句中 : select AA,BB,sum(CC) 中 的 AA和BB应该也是与sum(CC)对应的一个单个值 ==》sum(CC)由于可能被划分成m个组,因此会有m个sum(CC)的值,因此,AA和BB应该被划分后也是有m个,若AA或BB被划分后内容不是m个,那MySQL就会报错呀
==》因此,可以简记为:select 中的 内容,要么为一个聚合函数的输入值,要么为GROUP BY语句的参数,否则会出错。(因为自从 mysql 5.7开始:ONLY_FULL_GROUP_BY 就默认打开 ,这个属性就要求了我们select内容要么是聚合值要么是group by 参数)
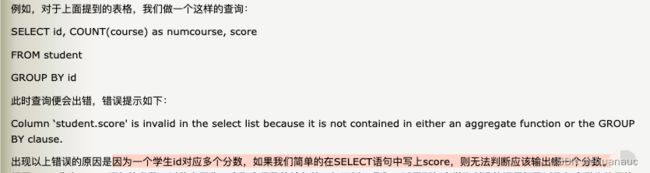
【注意】where语句中不可以使用聚合函数:
(where之所以不能使用聚合函数是因为 执行流程要求 先通过 where把数据范围确定下来,此时的数据表中条目具体是啥都没定下来,根本也不可能执行的了 聚合函数)
==》但 ,偏要使用聚合函数中的某些值怎么办? -- 用子查询:
如果想要:查询TEACHER表中年纪最大的教师的教工号、姓名、性别等信息。
需要用到子查询:
实例代码:
SELECT TNAME, DNAME, TSEX, SAL, AGE
FROM TEACHER
WHERE AGE=(SELECT MAX (AGE) FROM TEACHER)
10. select 作为输出内容可以执行一些计算处理:
例如 :
select count(*) as cnt ,building is not Null
from table111. group by 和 where 和 having 的配合 :
已知:
① 执行顺序是:先where确定数据表内容,再group by 分组,最后根据 having 再次对输出进行处理,获得最终的结果
② `group by col ` 的含义:根据 col 属性的值来确定如何分组,假设col在where后的表中可以有5个取值(包括Null),那么,就会被分为 5个组
`group by col1,col2` 的含义:根据col1,col2 实际在表中存在多少种不同的组合去分组
==》例如,col1可以取值11,12,14 ;col2可以取值 23,24,25,26 ;
然鹅,在where后的表中存在 col1,col2取值为(11,23)(11,24)(11,25)(12,24)(14,25)(14,26),
那么,根据col1,col2的group by 就只会将 表内容分为 6 组,而不是3*4=12 个分组
③ having 的出现是为了弥补 where中不允许使用 聚合函数 的缺陷 :
(where之所以不能使用聚合函数是因为 执行流程要求 先通过 where把数据范围确定下来,此时的数据表中条目具体是啥都没定下来,根本也不可能执行的了 聚合函数)
==》having 中也可以使用 非聚集函数,但是,如果having中使用非聚集函数,和 where中使用非聚集函数没有区别
例如:select count(*) where age >5 group by age
等价于
select count(*) group by age having age>5
【注意】【格式要求】:GROUP BY子句中的分组依据列必须是表中存在的列名,不能使用AS子句指派的结果集列的别名
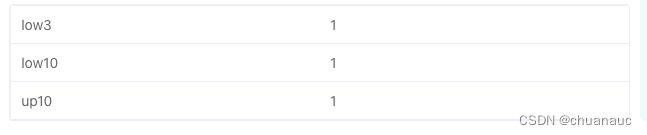
11.优雅得分组展示各块内容:

注意 :各个分组方式的名字要被 ' ' 包括住
输出是:
12. 执行顺序
14. 建表,建索引,等操作:
自学SQL网(教程 视频 练习全套) ==>执行顺序的那个
数据库的高级查询二:聚合函数(SUM、MAX,MIN,AVG,COUNT)_聚合函数sum_小懒羊爱吃草的博客-CSDN博客